基于自动构建提示学习映射器的方面类别检测方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及基于自动构建提示学习映射器的方面类别检测方法,属于方面级情感分析领域。
背景技术
对社交媒体平台上的评论进行情感分析是近些年NLP领域的研究热点。方面类别检测(Aspect Category Detection,ACD)作为方面级情感分析的一项子任务,旨在从预定义的方面类别集合中检测出评论所包含的类别。例如:句子“无论如何,食物本身还是相当不错的。”包含的方面类别为“食物”;句子“但工作人员的服务态度太差了”包含方面类别“服务”。现有的解决ACD任务的优秀方法大多为[pre-train,fine-tuning]范式,其效果很大程度上依赖标记数据的规模。而社交媒体上的评论更新较快,方面类别并不是固定不变的,总是为新出现的类别提供足够的标记数据比较困难。因此,当仅有少量标记样本时,上述方法的性能会大幅下降。
为了在少样本和零样本条件下也可以激发预训练语言模型发挥更大的性能,研究人员受GTP-3和LAMA的启发,提出使用提示将分类任务转换成完形填空任务,即将下游任务和PLMs统一为相同的模式,以最大化地利用预训练语言模型的先验知识。Verbalizer作为提示学习模型的重要组件之一,包含类别提示词到最终方面类别的映射关系。
目前的Verbalizer大致分为三种:手动构造、基于搜索和连续可学习。这些方法或者需要密集的人工工作,或者需要标签数据的支持,才能获取优秀的类别词集,因此都无法以较小的成本处理零样本任务。也有研究者提出从外部知识库中搜索提示词,这极大地扩展了映射范围。但成熟的知识库并不总是容易获取,在非英文数据集上缺少能达到相应性能的外部知识库,因此模型不易迁移至其他领域。除此之外,在实验中还发现,这些方法在语义模糊的类别例如“miscellaneous”上都存在一些问题。手动构造的词集仅包含类别词本身,导致覆盖面不够。基于搜索的方法没有考虑单词混淆问题,即一个单词可能出现在不同类别词集中。而从外部知识中搜索到的词很多不会出现在预训练语言模型词表中,这是由于外部知识库的词集与预训练语言模型词表设计不同,二者重合度欠缺。
为了解决这些问题,我们提出了一种新颖的基于提示的零样本和少样本ACD方法。我们的方法利用类别标签的语义扩展作为自动获取初始verbalizer的提示。此外,我们引入了自动verbalizer过滤的指示机制,无需人工干预即可为每个类别选择重要且可靠的提示词。
发明内容
本发明提供了基于自动构建提示学习映射器的方面类别检测方法,以用于解决当缺少标签数据时方面类别检测的问题,本发明在零样本和少样本情况下均提高了方面类别检测效果。
本发明的技术方案是:基于自动构建提示学习映射器的方面类别检测方法,所述方法的具体步骤如下:
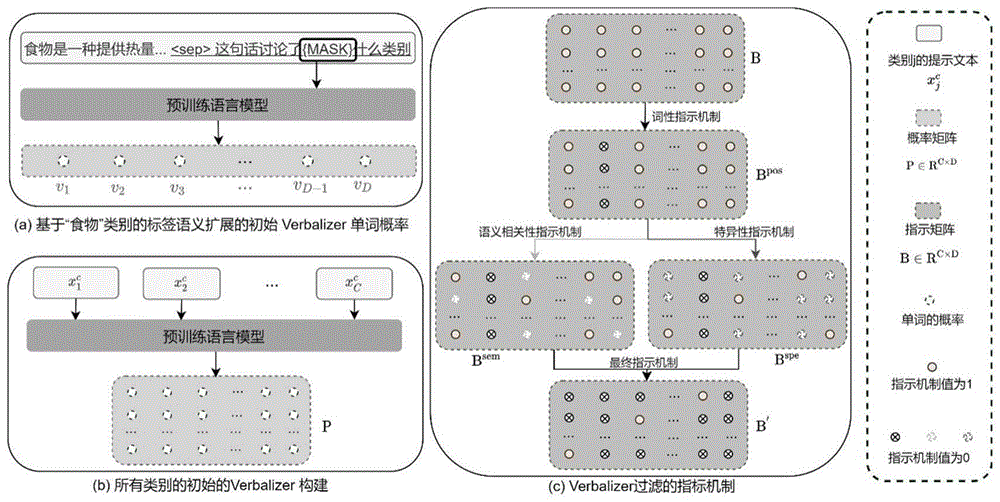
Step1、利用类别词的语义扩展句和特定于任务的模板组成提示,以获取预训练语言模型词表中所有token的被预测概率;
Step2、通过设计一种自动过滤机制,在词表中搜索最合适的提示词组成各类别词的提示词集;
Step3、在类别预测过程中,由映射器将提示词映射到最终的类别标签上。
进一步地,所述步骤Step1中,采用类别词的语义扩展,即维基百科网站上对于类别词的定义语句,和特定于任务的带有
进一步地,所述步骤Step2中,提出了一种自动过滤机制来改进映射器,自动过滤机制具体为:为概率矩阵P中的每个概率p
进一步地,所述通过词性、类别语义相关性和类别特异性三个方面来细化指示矩阵得到最终的指示矩阵的具体步骤如下:
Step2.1、对词表V进行“去噪”,即通过词性标注方法过滤掉无实义词,首先使用nltk包中的pos_tag方法定义词表V中匹配名词、动词、形容词的token集合为{pos},然后调整指示矩阵B中对应的元素值,通过公式1得到指示矩阵B
其中,b
Step2.2、根据类别语义相关性进一步修改指示矩阵B
其中MAX_M(.)表示向量中第M大的概率值,
Step2.3、根据类别特异性调整矩阵B
其中α是阈值,表示超过该阈值的词具有类别特异性;
Step2.4、最后,细化后的最终的指示矩阵B′为:
其中°代表两个矩阵的hadamard乘积。
进一步地,所述步骤Step3中,将待预测的评论句x
对于少样本场景,为提示词集中每个提示词设置一个权重参数并进一步训练,则句子x
其中
本发明的有益效果是:
本发明提出了一种在缺少标签样本的情况下基于提示学习的方面类别检测的方法,通过类别词的语义扩展获取预训练语言模型词表中所有token的预测概率,并设计一种指示机制搜索提示词,最终提高了零样本和少样本情况下方面类别检测的效果。在国际语义评测任务(Semeval)上的餐厅(Restaurant)数据集和亚马逊(Amazon)数数据集的三个不同领域(靴子领域、键盘领域、电视领域)上进行了理论与技术的验证,实验结果证明了该方法的有效性。
附图说明
图1为本发明中基于自动构建提示学习映射器的方面类别检测模型框架;
图2为本发明中的不同消融模型在四个数据集上的实验;
其中,(a)表示不同消融模型在“餐厅”数据集上的实验结果,(b)表示不同消融模型在“靴子”数据集上的实验结果,(c)表示不同消融模型在“键盘”数据集上的实验结果,(d)表示不同消融模型在“电视”数据集上的实验结果;
图3为本发明中关于“杂项”类别的实验;其中,(a)表示零样本实验的宏F1(%)结果,(b)表示少样本实验的宏F1(%)结果。
具体实施方式
实施例1:如图1-图3所示,基于自动构建提示学习映射器的方面类别检测方法,所述方法的具体步骤如下:
Step1、采用类别词的语义扩展,即维基百科网站上对于类别词的定义语句,和特定于任务的带有
Step2、通过设计一种自动过滤机制,自动过滤机制具体为:为概率矩阵P中的每个概率p
所述通过词性、类别语义相关性和类别特异性三个方面来细化指示矩阵得到最终的指示矩阵的具体步骤如下:
Step2.1、对词表V进行“去噪”,即通过词性标注方法过滤掉无实义词,首先使用nltk包中的pos_tag方法定义词表V中匹配名词、动词、形容词的token集合为{pos},然后调整指示矩阵B中对应的元素值,通过公式1得到指示矩阵B
其中,b
Step2.2、根据类别语义相关性进一步修改指示矩阵B
其中MAX_M(.)表示向量中第M大的概率值,
Step2.3、根据类别特异性调整矩阵B
其中α是阈值,表示超过该阈值的词具有类别特异性;
Step2.4、最后,细化后的最终的指示矩阵B′为:
其中°代表两个矩阵的hadamard乘积。
Step3、将待预测的评论句x
对于少样本场景,为提示词集中每个提示词设置一个权重参数并进一步训练,则句子x
其中
为了验证本发明所提出的模型的有效性,选择了与本发明相关的提示学习模型作为基线模型,主要是基于prompt的文本分类模型,具体如下:
Fine-Tuning(FT):与一众提示学习方法作为对比,传统的微调方法在预训练语言模型后添加分类层,获取[CLS]的隐藏向量,输入分类层并进行预测。
Manual prompts:手动构造的verbalizer包含的类别相关词有限,这里用类别词本身代表该类的唯一相关词。
WARP:该模型用连续向量而非单个词表示类别,同样
PETAL:该模型使用标签数据和未标签数据从预训练语言模型修剪过的词表中自动搜索类别相关词,通过使似然函数最大化,选择出现频率更高的单词。
Auto-L:该模型先在训练数据
KPT:该方法借助外部知识对verbalizer进行扩充,之后在支持集上对挑选的类别词进行多种方式的细化。使用其包含所有细化方法的变体。
针对本发明提出的方法在国际语义评测任务(Semeval)上的餐厅(Restaurant)数据集和亚马逊(Amazon)数据集的三个不同领域(靴子领域、键盘领域、电视领域)上进行实验。
本发明实验环境为Windows系统下Python 3.7,使用OpenPrompt工具包实现所有提示学习方法。在少样本实验中,遵循大多数少样本学习的设置,采用Nway K shot的训练模式,每个类别随机选取K条数据,且验证集与训练集规模相同,即|D
表1不同模型在4个数据集上的实验结果
表1包含4个数据集的所有实验结果,其中AVG表示各模型在4个数据集上的平均性能,Restaurant、Boots、Keyboards、TV分别代表餐厅(Restaurant)数据集和亚马逊(Amazon)数据集的三个不同领域(靴子领域、键盘领域、电视领域)。如表所示,本发明模型在所有设置下均取得最好结果。对比次好模型,在零样本任务中(表1中第2、3、4、5行),本发明模型在4个数据集上分别增长9.3%、5.9%、4.7%、9.9%,增长幅度尤为明显。说明使用本发明方法从预训练语言模型词表中搜索到的提示词可以较好的表示类别标签。在少样本任务(表1中第11行、第16行、第21行)的不同K值下,本发明模型对比次好模型的平均性能(AVG)增长为2.2%、2.8%、2.0%。这说明为每个提示词引入权重并进一步训练有利于映射过程的优化。在仅有少量标注数据的情况下,在不同领域数据集都保持一定程度的性能增长,说明本发明模型具有一定的泛化性。
为了评估模型中一些设计对最终效果的影响,进行了消融实验。分别在4个数据集上检测了指示过滤机制的三个方面的影响,结果如图2所示,“w/o pos”表示不使用词性标注去除无实义token;“w/o spe”表示不使用类别特异性指示搜索过程;“w/o sem”表示不使用类别特异性。
对比完整模型,三个消融模型实验结果的显著下降说明了指示机制的这三个方面可保证最大程度地为每个类别搜索到最合理的提示词,从而保证模型性能。除此之外,可明显观察到:1)“w/o pos”模型在4个数据集上均表现最差,且增长速度也仍低于其他模型。观察实验过程后发现,从未经过去噪的词表中挑选到的提示词集中包含较多的无实义token,且这些token在填入{MASK}位置时具有较高的预测概率,导致verbalizer映射性能的下降。2)“w/o sem”和“w/o spe”模型性能近似,说明在搜索提示词时类别特异性和类别语义相似性同等重要,二者的共同约束使得最终每个类别词集不仅具备尽量充足的提示词且避免了不同类别之间的映射矛盾,有利于后续进一步的映射优化。
除此之外,进一步定量和定性地评估了不同模型在“miscellaneous”和“general”类别上的作用,其中Amazon数据集包含“general”类别,为了方便表述,以下将两种标签统一称为“miscellaneous”。图3显示了分别在零样本和少样本条件下各模型在这两种类别上的实验结果。表2中展示了由不同模型获取的这两种类别的提示词。
表2“miscellaneous”类别的提示词
(中间划横线的词表示该token无法被预训练语言模型识别;下面划横线的词表示该token出现在其他类别中)
在不同设置中,本发明模型都显示出了优秀的结果,尤其在零样本任务中,提升效果明显,在4个数据集上对比次优模型分别提升了14.1%,10.6%,6.9%,11.1%,如图2所示。参照表2数据,推测由于“miscellaneous”类别的句子没有明显的特征,且语义表达范围较宽泛,因此Manual Prompt仅使用类别词作为提示词,显然无法覆盖该类别的所有数据,结果不理想。KPT虽然扩大了映射范围,但为该类别从外部知识库中搜索的提示词种类更丰富,根据表2中数据,这些丰富的提示词大多不常见且无法被PLMs识别,导致在该类别上性能提升较少。基于搜索的模型虽然不会出现这两种问题,但其忽略了类别间的混淆问题,在预测过程中容易造成模型的误判。本发明模型着重解决了上述问题后,在“miscellaneous”等语义模糊的类别可显示出不错的能力。除此之外,从语义层面出发,本发明获取的提示词与“miscellaneous”具有较高的相关性,因此可以更准确的表示类别。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 基于多任务框架的方面词和方面类别联合抽取和检测方法
- 一种基于提示学习和上下文感知的关系类别推断系统及方法