基于密度聚类的露天矿卡车车流密度提醒方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明卡车运输技术领域,特别涉及一种基于密度聚类的露天矿卡车车流密度提醒方法。
背景技术
卡车运输是露天矿的一种主流运输方式。矿用卡车尺寸大、自重大,相较于民用车辆灵活性差;同时挡土墙、出入沟的存在使得露天矿道路结构复杂,且矿山生产过程扬尘严重,运输安全问题尤为突出。
传统的依靠GPS/北斗定位信息进行车流密度提醒方法的一般思路是:(1)采集每一台设备的实时位置数据;(2)逐一计算每一台卡车到当前卡车的距离;(3)统计小于一定距离的卡车数量;(4)当数量大于一定范围,向卡车发出报警。这种方法十分直观,但缺点也十分明显,当设备数量巨大时,逐一计算距离其计算复杂度指数型上升,下发的提醒信息往往会有延迟。
发明内容
针对现有技术存在的不足,本发明的目的是提供一种基于密度聚类的露天矿卡车车流密度提醒方法。
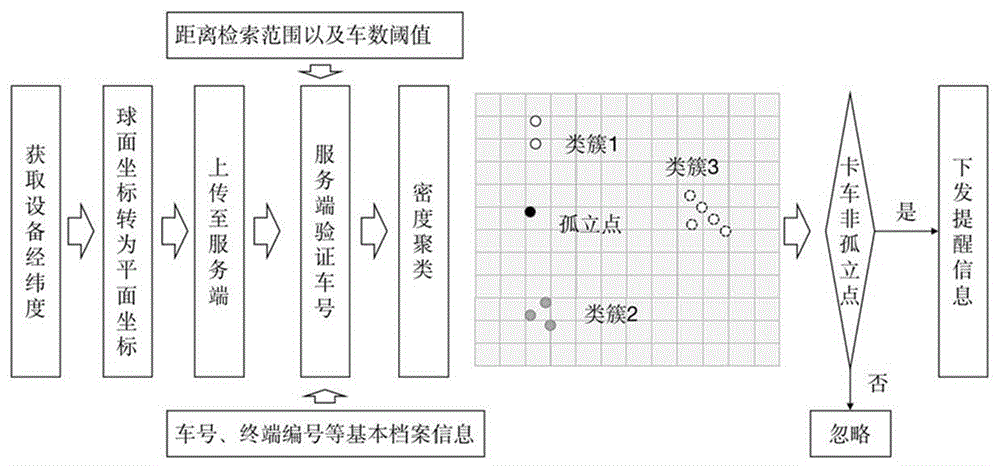
发明所采用的技术方案是:一种基于密度聚类的露天矿卡车车流密度提醒方法,其技术要点是,包括以下步骤:
步骤1,服务端应至少录入车辆车号、车载终端编号信息,同时设置距离检索范围以及车数阈值;
步骤2,矿区内车辆安装配备定位模块与通信模块的车载终端,并保证通信与定位情况良好;
步骤3,确保服务端开启,且信号畅通;
步骤4,车辆行驶过程中不断接受定位信息,并将其转化为平面坐标,发送至服务端;
步骤5,服务端轮询获得每一台车的位置信息;
步骤6,对这些车辆的位置信息进行密度聚类,获得多个车辆组成的集群;
步骤7,检索集群中每台车辆的终端编号,并向其发送提醒信息。
所述的密度聚类的过程为:
步骤1:首先以所有卡车位置信息作为输入,设置距离检索范围以及车数阈值;
步骤2:随机选取一台车,若其距离检索范围内的车数超过车数阈值,则认为该点为核心点;
步骤3:选择其距离检索范围内其他点继续执行该操作,直到新点不再是核心点,此时选取其他点重复以上操作;
步骤4:对于核心点检索距离范围内的,暂时都认为是一类,称为临时聚类簇;而后检查不同的临时聚类簇中是否有相同核心点,如存在, 则合并这些临时聚类簇;
步骤5:查询每个位置信息对应的车辆编号;
步骤6:最终获得矿区内车流密度较大的车队有哪些,每部分有多少辆车,都是哪些车。
本发明的有益效果是:该基于密度聚类的露天矿卡车车流密度提醒方法,方法为:服务端应至少录入车辆车号、车载终端编号信息;车辆行驶过程中不断接受定位信息,并将其转化为平面坐标,发送至服务端;服务端轮询获得每一台车的位置信息;同时设置距离检索范围以及车数阈值;对这些车辆的位置信息进行密度聚类,获得多个车辆组成的集群,查询每个位置信息对应的车辆编号。该方法通过有限次数的迭代,将所有卡车按照其距离远近自动分组,被分组的卡车其附近的车流密度也大,并向组内卡车同时预警。对比传统方法,该方法计算复杂度低,响应速度快,能够适用于大规模设备集群的车流密度提醒。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可根据这些附图获得其他的附图。
图1为本发明实施例一种基于密度聚类的露天矿卡车车流密度提醒方法的流程图;
图2为本发明实施例时间复杂度曲线示意图。
实施方式
使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图1-2和具体实施方式对本发明作进一步详细的说明。
本实施例采用的一种基于密度聚类的露天矿卡车车流密度提醒方法,具体步骤如下:
步骤1:服务端应录入车辆车号、车载终端编号基本信息,同时设置距离检索范围以及车数阈值。
步骤2:矿区内车辆安装配备定位模块与通信模块的车载终端,并保证通信与定位情况良好。本实施例利用安装在露天矿卡车上的车载定位模块,实时地获得矿区内每一台卡车当前的经纬度信息。
步骤3:确保服务端开启且信号畅通。
步骤4:车辆行驶过程中不断接受定位信息,并将其转化为平面坐标,发送至服务端。本实施例利用车载定位模块返回的经纬度不论是WGS84坐标系,还是CGCS2000坐标系,其本质上都是球面坐标,并不能直接用来计算距离,尤其是在高纬度地区,其距离将严重失真。因此需要将球面坐标转化为平面坐标。转化方法可以采用高斯克吕格投影、米勒投影等多种方式。考虑到一般车载定位模块多为简易模块,其定位精度普遍不高,本实施例采用米勒投影方法进行平面坐标的转化。
步骤5:服务端轮询获得每一台车的位置信息;
步骤6:对这些位置信息进行密度聚类,本实施例采用DBSCAN算法进行聚类,车数阈值设为2-3台,距离检索范围建议设为车辆安全行驶距离,将车辆根据聚集密度分为若干集群,具体方法为:
步骤6.1:首先以所有转换后的卡车平面坐标作为输入,设置距离检索范围以及车数阈值;
步骤6.2:随机选取一台车,若其距离检索范围内的车数超过车数阈值,则认为该点为核心点;
步骤6.3:选择其距离检索范围内其他点继续执行步骤6.2的操作,直到新点不再是核心点,此时选取其他点重复以上操作;
步骤6.4:对于核心点检索距离范围内的,暂时都认为是一类,称为临时聚类簇;而后检查不同的临时聚类簇中是否有相同核心点,如存在,则合并这些临时聚类簇;
步骤6.5:查询每个位置信息对应的车辆编号;
步骤6.6:最终获得矿区内车流密度较大的车队,该车队有多少辆车,都是哪些车。
本实施例中的距离检索范围是指卡车安全行驶距离,该距离根据卡车行驶速度、自重、载重各有不同,一般小车由于车速较快,其安全行驶距离要大,具体数值可以由用户自行设置。当距离检索范围越大,或者车数阈值越小时,监测灵敏度越高,当距离检索范围越小,或车数阈值越大时,误报率越低。数值设置可根据现场条件调试获得,一般经验是,由于露天矿范围巨大,车数阈值可设为2-3台,距离检索范围为车辆安全行驶距离即可。
步骤7:检索获得这些车辆的终端编号,并向其发送提醒信息。当获得哪些车此时周围车流密度较高时,系统立即向这些车辆广播发送预警信息,提醒司机注意周边车辆。
传统方法普遍采用计算卡车彼此距离的方法计算车流密度,如露天矿卡车数量为N时,其计算时间复杂度为O(N
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种基于局部密度和聚类中心优化的密度峰聚类方法
- 基于密度的多自适应阈值解决密度不均数据集的聚类方法