提问素材的生成方法、装置、电子设备和存储介质
文献发布时间:2024-04-18 19:58:30
技术领域
本公开涉及人工智能技术领域,尤其涉及自然语言处理和图像处理领域。
背景技术
儿童问答游戏不仅可以给儿童带来欢乐,还可以提高儿童的认知能力和逻辑推理技能。随着儿童素质教育的推进,提供儿童问答游戏的平台或书籍越来越多。但是,目前用于儿童问答游戏的素材一般由人工设计。一般地,由儿童教育专家在大量的图像中选取适用的图像,再针对图像设计题目。人工设计素材的设计周期较长,不能满足儿童对问答的数量需求。并且人工设计的成本也较为高昂。
发明内容
本公开提供了一种提问素材的生成方法、装置、电子设备和存储介质,以解决或缓解现有技术中的一项或更多项技术问题。
第一方面,本公开提供了一种提问素材的生成方法,包括:
获取参考图像;其中,参考图像是基于儿童用户的关注度在多个候选图像中确定的;
采用图文表征模型对参考图像进行处理,得到参考图像的描述文本;
对所述参考图像的描述文本以及预设的第一提示信息进行组合,得到第一输入信息;
将所述第一输入信息输入第一大语言模型,得到用于儿童问答游戏的目标题目;其中,所述第一输入信息中的所述第一提示信息用于指示所述第一大语言模型基于所述第一输入信息中的描述文本扩散得到与预设的题目类型相关的题目;
采用图像生成模型,生成与目标题目匹配的目标图像;
基于目标图像以及目标题目,得到用于儿童问答游戏的提问素材。
第二方面,本公开提供了一种提问素材的生成装置,包括:
图像获取模块,用于获取参考图像;其中,参考图像是基于儿童用户的关注度在多个候选图像中确定的;
文本生成模块,用于采用图文表征模型对参考图像进行处理,得到参考图像的描述文本;
题目生成模块,用于对所述参考图像的描述文本以及预设的第一提示信息进行组合,得到第一输入信息,并将所述第一输入信息输入第一大语言模型,得到用于儿童问答游戏的目标题目;其中,所述第一输入信息中的所述第一提示信息用于指示所述第一大语言模型基于所述第一输入信息中的描述文本扩散得到与预设的题目类型相关的题目;
图像生成模块,用于采用图像生成模型,生成与目标题目匹配的目标图像;
素材生成模块,用于基于目标图像以及目标题目,得到用于儿童问答游戏的提问素材。
第三方面,提供了一种电子设备,包括:
至少一个处理器;以及
与该至少一个处理器通信连接的存储器;其中,
该存储器存储有可被该至少一个处理器执行的指令,该指令被该至少一个处理器执行,以使该至少一个处理器能够执行本公开实施例中任一的方法。
第四方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,该计算机指令用于使该计算机执行根据本公开实施例中任一的方法。
本公开提供的技术方案的有益效果至少包括:利用参考图像得到描述文本,再利用描述文本得到目标题目,生成与目标题目匹配的目标图像,从而得到提问素材,实现了自动生成用于儿童问答游戏的提问素材。通过自动生成代替人工设计提问素材,可以降低提问素材的生成成本,并且可以实现批量生成,提升生成效率以及数量。
应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
附图说明
在附图中,除非另外规定,否则贯穿多个附图相同的附图标记表示相同或相似的部件或元素。这些附图不一定是按照比例绘制的。应该理解,这些附图仅描绘了根据本公开提供的一些实施方式,而不应将其视为是对本公开范围的限制。
图1是本公开一实施例提供的提问素材的生成方法的流程示意图;
图2是本公开实施例中提问素材的一个示例的示意图;
图3是本公开实施例中提问素材的另一个示例的示意图;
图4是本公开实施例中提问素材的另一个示例的示意图;
图5是本公开实施例中提问素材的生成方法的一个应用示例的示意图;
图6是本公开一实施例提供的提问素材的生成装置的示意性框图;
图7是本公开另一实施例提供的提问素材的生成装置的示意性框图;
图8是本公开另一实施例提供的提问素材的生成装置的示意性框图;
图9是用来实现本公开实施例的提问素材的生成方法的电子设备的框图。
具体实施方式
下面将参考附图对本公开作进一步地详细描述。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
另外,为了更好的说明本公开,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本公开同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路等未作详细描述,以便于凸显本公开的主旨。
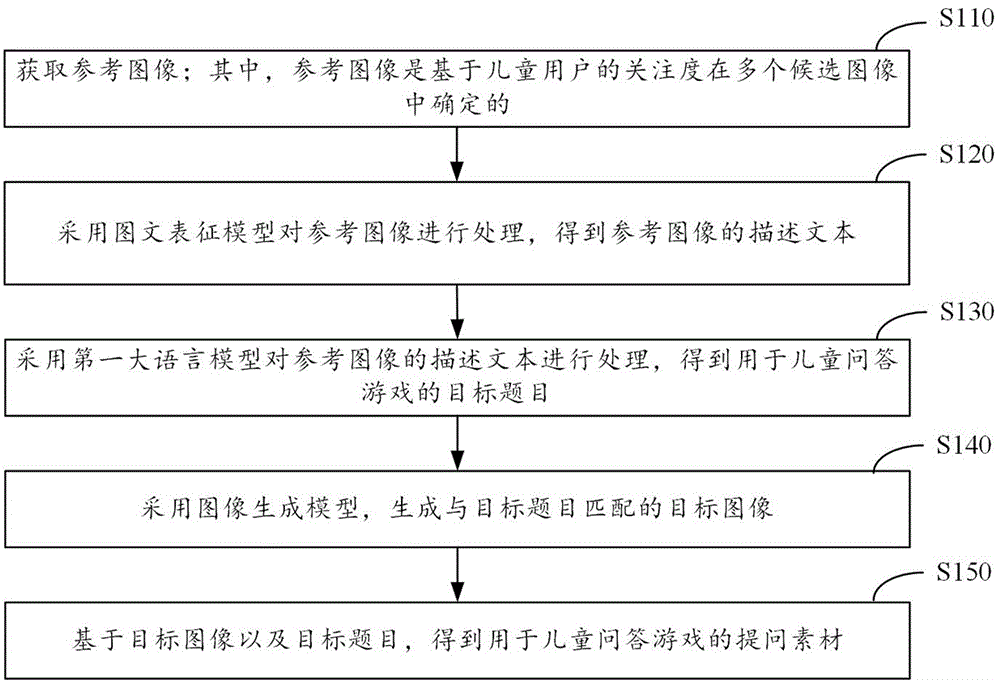
图1示出了本公开一实施例提供的提问素材的生成方法的示意图。该方法可以应用于提问素材的生成装置,该装置可以部署于电子设备中。电子设备例如是单机或多机的终端、服务器或其他处理设备。其中,终端可以为移动设备、个人数字助理(PersonalDigital Assistant,PDA)、手持设备、计算设备、车载设备、可穿戴设备等用户设备(UserEquipment,UE)。在一些可能的实现方式中,该方法还可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。如图1所示,该方法可以包括以下步骤S110至S150。
步骤S110、获取参考图像;其中,参考图像是基于儿童用户的关注度在多个候选图像中确定的。
在本公开实施例中,参考图像用于作为提问素材的生成过程中的参考。示例性地,参考图像可以包括真实生活的图像,例如风景图像、人群图像或者物体图像等,也可以包括卡通图像、绘画作品、AIGC(Artificial Intelligence Generated Content,人工智能生成内容)图像等。
在本公开实施例中,参考图像是基于儿童用户的关注度在多个候选图像中确定的。其中,候选图像也可以是真实图像、卡通图像、绘画作品、AIGC图像等。可选地,参考图像可以是多个候选图像中关注度高于预设阈值的图像,或者是关注度最高的图像等。
示例性地,上述多个候选图像可以是特定的数据库中的图像,例如面向儿童用户的网站、应用程序(Application,App)等的资源库中的图像。可选地,上述多个候选图像可以是网站、App中的海报、横幅等图像。
示例性地,儿童用户的关注度可以基于面向儿童用户的网站或App上图像的转化率确定。图像的转化率与互联网中图像的点击次数、收藏次数、点击率或收藏率等信息相关。例如,该转换率可以是对点击次数、收藏次数、点击率和收藏率中的至少一个参数进行加权处理得到的。
如此,通过预先获取各个候选图像的关注度,根据该关注度在多个候选图像中确定出参考图像,则该参考图像为比较受儿童的青睐的图像,使用该参考图像生成提问素材,可以提高儿童对问答游戏的感兴趣程度,即提高了提问素材的质量。
步骤S120、采用图文表征模型对参考图像进行处理,得到参考图像的描述文本。
在本公开实施例中,图文表征模型指用于获得对图像的文本形式的描述信息的模型。例如,图文表征模型可以为CLIP(Contrastive Language-Image Pre-training,对比语言-图像预训练)模型。
在本公开实施例中,描述文本是指文本形式的描述信息。具体地,将参考图像输入图文表征模型,可以使得图文表征模型输出参考图像的描述文本。描述文本例如是:“一排不同颜色的蜡笔,上面有卡通狗,前面有一名消防员”、“一些英文字母的卡通人物在舞台上表演”或“一个孩子正在玩一个彩色塑料数字益智游戏,上面有数字和字母和铅笔”等。
步骤S130、采用第一大语言模型对参考图像的描述文本进行处理,得到用于儿童问答游戏的目标题目。
在本公开实施例中,大语言模型(Large Language Model,LLM)是指使用大量文本数据训练的深度学习模型,可以理解语言文本的含义。
在本公开实施例中,第一大语言模型可以用于对输入的文本进行扩散,得到符合题目的语言范式的文本。
一种实施方式中,第一大语言模型可以从参考图像的描述文本中提取图像特征,并基于图像特征进行扩散,得到目标题目。示例性地,该图像特征可以包括图像中的元素,例如图像中的人物、字母、数字、动物或者背景等,也可以包括参考图像中元素的相关属性,例如颜色、形状、大小、空间位置关系或者数量等。
例如,参考图像的描述文本为“一张木制的桌子,桌上有许多彩色的玩具和形状”,第一大语言模型可以从中提取图像特征“形状”,并进行扩散,得到题目“哪个是圆圈”、“哪个是矩形”、“哪个是正方形”、“哪个是三角形”等。
又例如,参考图像的描述文本为“一群玩具恐龙在白色的背景上一起玩耍”,第一大语言模型可以从中提取图像特征“玩具恐龙”、“一群”,并进行扩散,得到题目“哪个图片有五只恐龙”、“哪个图片有两只恐龙”、“哪个图片有一只恐龙”等。
在本公开实施例中,题目类型可以是预先设定的任意类型。不同的题目类型可以对应不同的语言范式。第一大语言模型可以根据不同的语言范式对描述文本进行扩散,输出的对应的题目。
示例性地,目标题目的题目类型可以包括选择题、填空题、判断题等。例如,目标题目可以为“哪个字母是A”、“小猴子前面的字母是()”、“这是字母A吗”。
或者,目标题目的题目类型可以包括颜色识别、形状识别、大小比较、情绪识别、字母识别、数字识别、动物识别、数量识别和个位数加减运算中的一种或多种。
具体地,在上述步骤S130中,可以对所述参考图像的描述文本以及预设的第一提示信息进行组合,得到第一输入信息,并将所述第一输入信息输入第一大语言模型,得到用于儿童问答游戏的目标题目;其中,所述第一输入信息中的所述第一提示信息用于指示所述第一大语言模型基于所述第一输入信息中的描述文本扩散得到与预设的题目类型相关的题目。
由于一般的大语言模型具有对输入信息进行理解,以及学习语言范式的能力,但其不具备在特定领域下的业务处理能力,即其无法根据输入信息输出定向类型的信息,因此,直接将参考图像的描述文本输入第一大语言模型,第一大语言模型的输出可能是发散性的,例如不是问句,或者虽然是问句但跟儿童问答游戏中的题目类型不相符。基于此,本公开实施例中,预设有第一提示信息,在确定描述文本之后将描述文本和第一提示信息进行组合,将组合得到的第一输入信息输入第一大语言模型,而不是将描述文本输入到第一大语言模型。其中,第一提示信息用于指示模型将描述文本扩散为与预设的题目类型相关的题目。如此,第一大语言模型在接收到第一输入信息后,会通过对第一提示信息的理解,输出定向类型的信息。
举例而言,第一提示信息可以如下:
“你是一个儿童教育专家,在一个儿童问答游戏网站上工作。你的主要工作是根据图像的描述文本生成提供给儿童的问题,以训练儿童的认知和逻辑推理技能。这些问题包括但不限于儿童对颜色、形状、大小、情感、字母、数字和普通动物的识别,以及简单的计数,以及在10岁以内进行加减的能力。
请注意,每一组问题的主题必须保持一致,即,
如果是关于颜色的,那么一组问题都必须是关于颜色识别的问题;如果是关于形状的,那么一组问题都必须是关于形状识别的问题;如果是关于大小的,那么一组问题都必须是关于大小比较的问题;如果是关于情绪的,那么一组问题都必须是关于情绪识别的问题;如果是关于字母的,那么一组问题都必须是关于字母识别的问题;如果是关于数字的,那么一组问题都必须是关于数字识别的问题;如果是关于普通动物的,那么一组问题都必须是关于普通动物识别的问题;如果是关于要进行计数的数字,那么一组问题都必须是关于计数的问题;如果是关于加减法的,那么一组问题都必须是关于加减法的问题;等等。
也就是说,颜色识别、形状识别、大小比较、情绪识别、字母识别、数字识别、普通动物识别、简单计数,以及在10个范围内的加减能力,这些问题类别不能相互混合。每一组问题只能并且只涉及其中一个类别。而且所有的问题都尽可能与封面图片有关。
现在请基于下面的描述文本提供问题吧!”
可以理解,将上述第一提示信息与参考图像的描述文本进行组合得到第一输入信息之后,将第一输入信息输入第一大语言模型,第一大语言模型可以根据对上述第一提示信息的理解,针对其后的描述文本进行预设的题目类型的扩散,从而输出一个或多个题目。
一种实施方式中,目标题目可以是从第一大语言模型针对描述文本输出的多个题目中筛选出的最终用于作为提问素材的题目。可选地,目标题目的数量可以大于或等于2,即利用一个参考图像,可以得到多个目标题目。如此,可以实现自动化生成大量的题目。
步骤S140、采用图像生成模型,生成与目标题目匹配的目标图像。
在本公开实施例中,图像生成模型指根据文本形式的内容生成图像的模型。例如,图像生成模型可以是Diffusion(扩散)作画模型。
可选地,与目标题目匹配的目标图像,可以包括一个或多个图像。实际应用中,目标题目与目标图像的匹配方式可以根据不同的问答模式而不同。
示例性地,如果问答模式为根据题目选择图像,则与目标题目匹配的目标图像,可以包括作为选项的多个图像。示例性地,该多个图像包括作为正确选项的第一图像以及作为错误选项的第二图像,且第一图像与第二图像与目标题目的主题相关。例如,如图2所示,如果目标题目为“哪个是字母A”,则第一图像可以是字母A的图像;第二图像可以是其他字母的图像,例如字母B的图像。
示例性地,如果问答模式为根据图像给出题目的答案,则与目标题目匹配的目标图像中包含可以作为答案的信息。例如,如图3所示,如果目标题目为“图片中的字母是()”,则目标图像可以是任意字母的图像。又例如,如图4所示,如果目标题目为“图片中的字母是A吗”,则第三图像可以是字母A的图像或其他字母的图像。
实际应用中,可以通过采用符合预设的问答模式的训练数据对图像生成模型进行训练,使得图像生成模型可以根据输入的题目,输出与之匹配的图像。具体地,训练数据可以包括多个样本,每个样本包括一个题目以及与该题目匹配的图像。
步骤S150、基于目标图像以及目标题目,得到用于儿童问答游戏的提问素材。
示例性地,可以将目标图像和目标题目进行组合,得到提问素材。
可选地,该提问素材可以应用于任一儿童益智平台、绘本或书籍等。其中,儿童益智平台例如是面向儿童用户的网站、App等。
可以看到,根据本公开实施例的技术方案,可以通过参考图像得到文字形式的题目,并且采用图像生成模型生成与题目匹配的图像,组合图像以及题目得到提问素材,从而可以自动、大量且快速的生成儿童问答游戏的提问素材,降低提问素材的生成成本,提高儿童问答素材的生成效率和数量。
并且,需要说明的是,与相关技术中生成素材的方式不同,相关技术中生成素材的方式一般是给定输入的图像或文本,然后通过不同信息模态的转换,得到与输入的图像或文本紧密结合的素材。然而,本公开实施例用于儿童问答游戏中的提问素材的生成,对生成的提问素材中的题目与图像之间的关联度的要求高于对提问素材与输入的参考图像之间的关联度的要求。而实际情况中,若根据参考图像同时生成题目与图像,则可能造成题目素材与图像素材各自与参考图像保持关联度但题目素材与图像素材关联度不高的问题,并且无法保证题目素材与图像素材与预设的题目类型相关(即无法保证信息的定向输出)。若根据参考图像先生成图像再生成题目,则可能由于图生图、图生文过程是基于图像特征进行的,从而无法实现图像素材的语义定向输出。为了解决上述技术问题,本公开实施例摒弃人工设计中先确定图像素材再设计问题的处理逻辑,先根据参考图像扩散生成目标题目,再根据目标题目生成目标图像。通过先生成题目再生成图像的方式,使得即便进行扩散式生成,也能利用第一提示信息的引导,利用大语言模型对输入信息的理解能力实现题目信息的定向生成,再基于大语言模型生成的题目进行图像生成确保题目和图像之间的匹配度,从而保证了提问素材的质量。
此外,由于提问素材是基于对参考图像的扩散得到的,而参考图像是根据儿童用户的关注度确定的,因此,基于参考图像扩散得到的题目和图像可以符合儿童的喜好,更受儿童的欢迎,增加儿童答题过程中的趣味性,保证提问素材的质量。
在一些实施例中,第一提示信息包括第一引导话语以及多个第一示例,第一引导话语用于指示所述第一大语言模型参考所述多个第一示例,将第一输入信息中的描述文本扩散为与预设的题目类型相关的多个题目;其中,多个第一示例中的每个第一示例包括一个示例图像的描述文本以及该示例图像的描述文本所对应的多个题目。
相应地,将第一输入信息输入第一大语言模型,得到用于儿童问答游戏的目标题目,包括:将所述第一输入信息输入所述第一大语言模型,得到所述第一大语言模型参考所述多个第一示例输出的多个题目;在多个题目中进行筛选,得到目标题目。
其中,第一引导话语可以理解为用于指示第一大语言模型的扩散方向的信息。
可选地,第一引导话语可以用于表征题目类型。示例性地,第一引导话语可以包括颜色、形状、大小比较等题目类型信息。如此,第一大语言模型根据题目类型对应的语言范式对描述文本进行扩散。
示例性地,若需要生成颜色识别题目,则可以设定第一引导话语包括颜色类型信息,第一大语言模型根据该引导话语,针对颜色进行扩散,例如,描述文本为“一排不同颜色的蜡笔,上面有卡通狗,前面有一名消防员”,则第一大语言模型输出的题目可以包括:“卡通狗是绿色的吗”、“卡通狗是蓝色的吗”、“卡通狗是红色的吗”等等。
示例性地,若需要生成形状识别题目,则可以设定第一引导话语为形状类型信息,第一大语言模型根据该引导话语,针对形状进行扩散。例如,描述文本为“一张木制的桌子,表面上有许多彩色的玩具和形状”,则第一大语言模型输出的题目可以包括:“哪个是圆形”、“哪个是矩形”、“哪个是心形”等等。
可选地,第一引导话语可以用于表征一个或多个题目类型,如此,第一大语言模型可以针对每个题目类型分别进行输出,从而输出一组或多组题目。
可选地,第一引导话语还可以包括引导第一大语言模型参考多个第一示例的信息。在本公开实施例中,第一引导话语、多个第一示例是与描述文本一同输入至第一大语言模型的。因此,第一大语言模型可以基于对第一引导话语的理解,参考多个第一示例,进行与预设的题目类型相关的题目输出。
举例而言,第一引导话语可以如下:
“你是一个儿童教育专家,在一个儿童问答游戏网站上工作。你的主要工作是根据图像的描述文本生成提供给儿童的问题,以训练儿童的认知和逻辑推理技能。这些问题包括但不限于儿童对颜色、形状、大小、情感、字母、数字和普通动物的识别,以及简单的计数,以及在10岁以内进行加减的能力。
请注意,每一组问题的主题必须保持一致,即,
如果是关于颜色的,那么一组问题都必须是关于颜色识别的问题;如果是关于形状的,那么一组问题都必须是关于形状识别的问题;如果是关于大小的,那么一组问题都必须是关于大小比较的问题;如果是关于情绪的,那么一组问题都必须是关于情绪识别的问题;如果是关于字母的,那么一组问题都必须是关于字母识别的问题;如果是关于数字的,那么一组问题都必须是关于数字识别的问题;如果是关于普通动物的,那么一组问题都必须是关于普通动物识别的问题;如果是关于要进行计数的数字,那么一组问题都必须是关于计数的问题;如果是关于加减法的,那么一组问题都必须是关于加减法的问题;等等。
也就是说,颜色识别、形状识别、大小比较、情绪识别、字母识别、数字识别、普通动物识别、简单计数,以及在10个范围内的加减能力,这些问题类别不能相互混合。每一组问题只能并且只涉及其中一个类别。而且所有的问题都尽可能与封面图片有关。
下面是10个例子,每个例子都包含一个示例图像的描述文本和由这个示例图像生成的几个题目:
{第一示例集合}
现在请基于下面的描述文本提供问题吧!”
多个第一示例可以如下:
“例1.示例图像的描述文本:一排不同颜色的蜡笔,上面有卡通狗,前面有一名消防员。题目:1)哪个是绿狗;2)哪个是紫色的狗;3)哪个是蓝狗;4)哪个是黄色的狗;5)哪个是黑狗;6)哪个是粉红色的狗。
例2.示例图像的描述文本:一些英文字母的卡通人物在舞台上表演。题目:1) 哪个是大写字母n;2) 哪个是大写字母t;3) 哪个是大写字母b;4) 哪个是大写字母f;5) 哪个是大写字母z;6) 哪个是大写字母d。
……”基于第一引导性话语和第一示例组合成的第一提示信息如下:
“你是一个儿童教育专家,在一个儿童问答游戏网站上工作。你的主要工作是根据图像的描述文本生成提供给儿童的问题,以训练儿童的认知和逻辑推理技能。这些问题包括但不限于儿童对颜色、形状、大小、情感、字母、数字和普通动物的识别,以及简单的计数,以及在10岁以内进行加减的能力。
请注意,每一组问题的主题必须保持一致,即,
如果是关于颜色的,那么一组问题都必须是关于颜色识别的问题;如果是关于形状的,那么一组问题都必须是关于形状识别的问题;如果是关于大小的,那么一组问题都必须是关于大小比较的问题;如果是关于情绪的,那么一组问题都必须是关于情绪识别的问题;如果是关于字母的,那么一组问题都必须是关于字母识别的问题;如果是关于数字的,那么一组问题都必须是关于数字识别的问题;如果是关于普通动物的,那么一组问题都必须是关于普通动物识别的问题;如果是关于要进行计数的数字,那么一组问题都必须是关于计数的问题;如果是关于加减法的,那么一组问题都必须是关于加减法的问题;等等。
也就是说,颜色识别、形状识别、大小比较、情绪识别、字母识别、数字识别、普通动物识别、简单计数,以及在10个范围内的加减能力,这些问题类别不能相互混合。每一组问题只能并且只涉及其中一个类别。而且所有的问题都尽可能与封面图片有关。
下面是10个例子,每个例子都包含一个示例图像的描述文本和由这个示例图像生成的几个题目:
例1.示例图像的描述文本:一排不同颜色的蜡笔,上面有卡通狗,前面有一名消防员。题目:1)哪个是绿狗;2)哪个是紫色的狗;3)哪个是蓝狗;4)哪个是黄色的狗;5)哪个是黑狗;6)哪个是粉红色的狗。
例2.示例图像的描述文本:一些英文字母的卡通人物在舞台上表演。题目:1) 哪个是大写字母n;2) 哪个是大写字母t;3) 哪个是大写字母b;4) 哪个是大写字母f;5) 哪个是大写字母z;6) 哪个是大写字母d。
……
现在请基于下面的描述文本提供问题吧!”
可以理解,在上述第一提示信息的指示下,第一大语言模型能够通过理解第一提示信息,实现参考多个第一示例,输出与预设的题目类型相关的题目。
可选地,在多个题目(如上述一组或多组题目)中进行筛选,可以是人工进行筛选,也可以是自动进行筛选,例如采用预先训练的判别器进行筛选。
根据上述实施例,可以自动生成不同题目类型的提问素材,增加提问素材的知识性与趣味性。
在一些实施例中,上述题目类型可以包括颜色识别、形状识别、大小比较、情绪识别、字母识别、数字识别、动物识别、数量识别以及个位数加减运算中的一种或多种。
在一些实施例中,步骤S140、采用图像生成模型,生成与目标题目匹配的目标图像,包括:
采用第二大语言模型对目标题目进行处理,得到用于生成图像的多个提示词;
采用图像生成模型,根据特征信息生成目标图像。
根据上述实施例,在得到目标题目之后,先采用第二大语言模型将目标题目处理为多个提示词,再基于多个提示词生成目标图像。如此,可以基于第二大语言模型对目标题目进行理解和扩散,获得更丰富的用于提示图像生成的信息,从而提高图像生成质量;同时利用大语言模型对输入的文本信息的理解能力,实现从题目到预设信息类型的提示词的定向生成,相比于直接从题目生成图像,可以保证生成的图像和题目之间的匹配度、关联度。
在一些实施例中,采用第二大语言模型对目标题目进行处理,得到用于生成图像的多个提示词,包括:
对所述目标题目以及预设第二提示信息进行组合,得到第二输入信息;
将所述第二输入信息输入第二大语言模型,得到所述第二大语言模型输出的用于生成图像的多个提示词;其中,所述第二提示信息包括第二引导话语以及多个第二示例,所述第二引导话语用于指示所述第二大语言模型参考所述多个第二示例,将第二输入信息中的题目扩散为与预设的信息类型相关的多个提示词。
可选地,第二引导话语可以用于表征信息类型。示例性地,信息类型可以包括图像类型、艺术风格、艺术灵感、相机相关信息、镜头相关信息和渲染相关信息中的一种或多种。
示例性地,第二引导话语可以用于表征多个提示词的描述结构,该描述结构例如是:
结构1:{目标题目},图像类型,艺术风格,艺术灵感,相机,拍摄,渲染相关信息。
结构2:图像类型,{目标题目},艺术风格,艺术灵感,相机,镜头,渲染相关信息。
其中,图像类型可以包括图像的确切类型,如数字插图、漫画书封面、照片或素描等。艺术风格可以包括超现实主义或抽象表现主义等。艺术灵感可以采用艺术家或工作室的具体名称表示。相机相关信息可以包括相机角度、长镜头、特写、POV(Point of View,视点人物写作手法)、中镜头、极端特写和全景等信息。镜头相关信息可以包括短长焦、超长焦、中长距、微距、广角、鱼眼、散焦和锐对焦等。渲染相关信息可以包括渲染风格、分辨率等,分辨率例如是4K、8K、64K、详细、高度详细、高分辨率、超详细、HDR(High Dynamic RangeImaging,高动态范围成像)、UHD(Ultra High Definition,超高清)、专业和黄金比率等。渲染风格可以包括例如工作室照明、软光、霓虹灯、紫色霓虹灯、环境光、环光、体积光、自然光、太阳光、阳光、通过窗户的太阳光线和怀旧照明等,或者包括生动的颜色、生动的颜色、明亮的颜色、深褐色、深色、柔和的颜色、单色、黑色、白色和颜色飞溅等。通过预设信息类型,可以使第二大语言模型实现特定类型信息的定向输出。而第二大语言模型对特定类型的提示词输出,可以影响生成的图像内容。
示例性地,第二引导话语还可以包括引导第二大语言模型参考多个第二示例的信息。
举例而言,第二引导话语可以如下:
“你现在将作为一个被称为“稳定扩散”的生成式人工智能的提示生成器。稳定扩散根据给定的提示生成图像。我将为你提供制作一个稳定的提示词生成所需的基本信息,你将以下结构进行输出:
针对真实图片输出:{主题描述},图像的类型,艺术风格,艺术灵感,相机,拍摄,渲染相关信息。
针对艺术图像输出:图像类型,{主题描述},艺术风格,艺术灵感,相机,镜头,渲染相关信息。
其中,图像的类型是指……(针对每个信息类型进行逐一讲解);
你正在做一个儿童谜题回答游戏网站。你的工作是根据上述知识为每个题目设计两个图像,其中一个必须是对这个问题的正确答案,另一个必须是错误的答案。这两张图像都被要求与主题相关,这是对儿童认知能力的一种测试。
以下是10个例子。每个例子都包含一个题目和与这个题目对应的两张图像的提示词(可以是单词或句子)。图像描述必须与问题相关,并且只有一张图像作为这个问题的正确答案:
例1.题目:这是一只绿色的狗吗?提示词1:一只玩具小狗,穿着绿色衬衫,头上和腿上戴着帽子;提示词2:一只玩具小狗,穿着绿色衬衫,头上和腿上戴着帽子”。
例2:题目:哪个是字母n?提示词1:一个绿色的字母n,有一个微笑的脸和手臂举起在空中;提示词2:一个红色字母s,脸、眼睛和手臂脸上微笑,手臂脸上微笑。
……
现在给我针对以下题目,生成一些提示词,以便于生成以下题目对应的两个图像。”
可以理解,上述第二提示信息与题目组合得到第二输入信息,输入到第二大语言模型后,第二大语言模型可以通过对第二提示信息的理解,确定第二大语言模型的扩散方向,从而有利于生成符合预期的图像,提高素材生成质量。
可选地,第二提示信息中的各项信息可以对应不同的权重,从而使得生成的多个提示词可以具有不同的权重,进而在图像生成模型的处理过程中对不同提示词进行加权处理,得到目标图像。
在一些实施例中,采用图像生成模型,根据多个提示词生成目标图像,包括:
采用图像生成模型,根据多个提示词生成与预设的问答模式匹配的至少一个图像;
基于至少一个图像,得到目标图像。
可选地,在本公开实施例中,图像生成模型也可以称为文生图模型。图像生成模型例如是Diffusion(扩散)模型。
其中,问答模式例如是根据题目选择图像,或根据图像给出题目的答案等。
根据上述实施例,可以根据不同的问答模式生成相匹配的目标图像,从而可以适应不同的儿童游戏的素材生成需求。
为了便于理解上述技术方案,下面结合图5提供一个具体的应用示例。如图5所示,该应用示例中,提问素材的生成方法包括以下步骤:
S1:将预先选取的受欢迎的海报输入CLIP模型,由CLIP模型读取海报中的信息,输出描述文本。
S2:将描述文本输入第一LLM模型,由第一LLM模型解读描述文本,输出提问素材中需要用到的题目。描述文本和生成的题目的形式可参考如下示例。
例1:描述文本为“一张木制的桌子,表面上有许多彩色的玩具和形状”。题目包括:哪个是圆圈、哪个是矩形、哪个是心形、哪个是正方形、哪个是星形、哪个是三角形。
例2:描述文本为“一群色彩斑斓的海洋动物站在沙滩上,旁边是蓝色的海底和蓝天”。题目包括:哪个是螃蟹、哪个是鲸鱼、哪个是章鱼、哪个是海星、哪个是水母。
例3:描述文本为“一个孩子正在玩一个彩色塑料数字益智游戏,上面有数字和字母和铅笔”。题目包括:找到数字8、找到数字1、找到数字5、找到数字6、找到数字2、找到数字3。
S3:将题目输入第二LLM模型,第二LLM模型扩散生成多个提示词。
S4:将多个提示词输入Diffusion模型,Diffusion模型生成提问素材中需要用到的图像。
以问答模式为根据题目在图像1和图像2中选择为例,提问素材的形式可以参考如下示例。
例4:题目为“哪张照片上有五只恐龙”;图像1为一群五只玩具恐龙站在彼此旁边;图像2为一只张牙舞爪的玩具恐龙。
例5:题目为“哪只猫是快乐的”;图像1为一只快乐的卡通猫,嘴里叼着一把牙刷,眼睛睁大了眼睛;图像2为一只不开心的卡通猫的爪子里拿着一个红苹果,脸上带着流泪的表情。
可以看到,根据本公开实施例,通过不同模态信息的多次转换处理,可以实现自动生成大量的提问素材,从而降低了成本,也提高了素材生成质量。
根据本公开的实施例,本公开还提供了一种提问素材的生成装置,图6示出了本公开一实施例提供的提问素材的生成装置的示意性框图,如图6所示,该提问素材的生成装置包括:
图像获取模块610,用于获取参考图像;其中,所述参考图像是基于儿童用户的关注度在多个候选图像中确定的;
文本生成模块620,用于采用图文表征模型对所述参考图像进行处理,得到所述参考图像的描述文本;
题目生成模块630,用于对所述参考图像的描述文本以及预设的第一提示信息进行组合,得到第一输入信息,并将所述第一输入信息输入第一大语言模型,得到用于儿童问答游戏的目标题目;其中,所述第一输入信息中的所述第一提示信息用于指示所述第一大语言模型基于所述第一输入信息中的描述文本扩散得到与预设的题目类型相关的题目;
图像生成模块640,用于采用图像生成模型,生成与所述目标题目匹配的目标图像;
素材生成模块650,用于基于所述目标图像以及所述目标题目,得到用于儿童问答游戏的提问素材。
在一些实施例中,如图7所示,题目生成模块630可以包括:
第一模型处理单元710,用于将所述第一输入信息输入所述第一大语言模型,得到所述第一大语言模型参考所述多个第一示例输出的多个题目;
题目筛选单元720,用于在所述多个题目中进行筛选,得到所述目标题目。
在一些实施例中,所述题目类型包括颜色识别、形状识别、大小比较、情绪识别、字母识别、数字识别、动物识别、数量识别以及个位数加减运算中的至少一种。
在一些实施例中,如图8所示,图像生成模块640包括:
第二模型处理单元810,用于采用第二大语言模型对所述目标题目进行处理,得到用于生成图像的多个提示词;
第三模型处理单元820,用于采用图像生成模型,根据所述多个提示词生成所述目标图像。
在一些实施例中,第二模型处理单元810具体用于:
对所述目标题目以及预设第二提示信息进行组合,得到第二输入信息;
将所述第二输入信息输入第二大语言模型,得到所述第二大语言模型输出的用于生成图像的多个提示词;其中,所述第二提示信息包括第二引导话语以及多个第二示例,所述第二引导话语用于指示所述第二大语言模型参考所述多个第二示例,将第二输入信息中的题目扩散为与预设的信息类型相关的多个提示词。
在一些实施例中,所述信息类型包括图像类型、艺术风格、艺术灵感、相机相关信息、镜头相关信息和渲染相关信息中的至少一种。
在一些实施例中,第三模型处理单元具体用于:
采用图像生成模型,根据所述多个提示词生成与预设的问答模式匹配的至少一个图像;
基于所述至少一个图像,得到所述目标图像。
图9为根据本公开一实施例的电子设备的结构框图。如图9所示,该电子设备包括:存储器910和处理器920,存储器910内存储有可在处理器920上运行的计算机程序。存储器910和处理器920的数量可以为一个或多个。存储器910可以存储一个或多个计算机程序,当该一个或多个计算机程序被该电子设备执行时,使得该电子设备执行上述方法实施例提供的方法。该电子设备还可以包括:通信接口930,用于与外界设备进行通信,进行数据交互传输。
如果存储器910、处理器920和通信接口930独立实现,则存储器910、处理器920和通信接口930可以通过总线相互连接并完成相互间的通信。该总线可以是工业标准体系结构(Industry Standard Architecture,ISA)总线、外部设备互连(Peripheral ComponentInterconnect,PCI)总线或扩展工业标准体系结构(Extended Industry StandardArchitecture,EISA)总线等。该总线可以分为地址总线、数据总线、控制总线等。为便于表示,图9中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
可选的,在具体实现上,如果存储器910、处理器920及通信接口930集成在一块芯片上,则存储器910、处理器920及通信接口930可以通过内部接口完成相互间的通信。
应理解的是,上述处理器可以是中央处理器(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processing,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(FieldProgrammable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者是任何常规的处理器等。值得说明的是,处理器可以是支持进阶精简指令集机器(Advanced RISC Machines,ARM)架构的处理器。
进一步地,可选的,上述存储器可以包括只读存储器和随机存取存储器,还可以包括非易失性随机存取存储器。该存储器可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以包括只读存储器(Read-OnlyMemory,ROM)、可编程只读存储器(Programmable ROM,PROM)、可擦除可编程只读存储器(Erasable PROM,EPROM)、电可擦除可编程只读存储器(Electrically EPROM,EEPROM)或闪存。易失性存储器可以包括随机存取存储器(Random Access Memory,RAM),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用。例如,静态随机存取存储器(Static RAM,SRAM)、动态随机存取存储器(Dynamic Random Access Memory ,DRAM) 、同步动态随机存取存储器(Synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(Double Data Date SDRAM,DDR SDRAM)、增强型同步动态随机存取存储器(EnhancedSDRAM,ESDRAM)、同步连接动态随机存取存储器(Synchlink DRAM,SLDRAM)和直接内存总线随机存取存储器(Direct RAMBUS RAM,DR RAM)。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意结合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机指令时,全部或部分地产生按照本公开实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络或其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如:同轴电缆、光纤、数据用户线(Digital Subscriber Line,DSL))或无线(例如:红外、蓝牙、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质,或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如:软盘、硬盘、磁带)、光介质(例如:数字通用光盘(Digital Versatile Disc,DVD))或半导体介质(例如:固态硬盘(Solid State Disk,SSD))等。值得注意的是,本公开提到的计算机可读存储介质可以为非易失性存储介质,换句话说,可以是非瞬时性存储介质。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本公开实施例的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包括于本公开的至少一个实施例或示例中。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
在本公开实施例的描述中,除非另有说明,“/”表示或的意思,例如,A/B可以表示A或B。本文中的“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。
在本公开实施例的描述中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本公开实施例的描述中,除非另有说明,“多个”的含义是两个或两个以上。
以上所述仅为本公开的示例性实施例,并不用以限制本公开,凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
- 素材处理方法及装置、存储介质和电子设备
- 类文件生成方法、装置、电子设备及存储介质
- 无人机迁移轨迹生成方法、装置、电子设备和存储介质
- 视频摘要生成方法、装置、存储介质和电子设备
- 网页生成方法、装置、电子设备及计算机可读存储介质
- 提问信息生成方法、装置、电子设备及存储介质
- 提问信息生成方法、装置、电子设备及存储介质