一种基于计算机视觉的结直肠镜图像分类方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及一种结直肠镜图像分类方法,尤其涉及一种基于计算机视觉的结直肠镜图像分类方法,属于计算机视觉技术领域。
背景技术
随着技术飞速发展、医学数据的持续扩增以及硬件设备的不断提升,结直肠癌的诊断也越来越受重视。由于肠道环境复杂、早期癌变或息肉又小又平、检查前洗肠不干净等因素,多数医生很难做到精准化判断,临床漏诊率很高,美国是6%~27%,日本约为20%。
因此,医学界需要一款肠镜辅助诊断结直肠癌的技术以帮助各级医院与医生更好更快的做出诊断。本发明是以计算机视觉为核心的拥有结直肠分类能力的辅助诊疗平台,其主要目标是提供一款帮助内窥镜医师完成结直肠癌症的检测和组织学分类任务的结直肠辅助诊疗平台。
本发明将前沿技术与现代医疗相结合,运用人工智能图像识别技术在保证高准确率的情况下,省去繁琐的人工识别,提高诊断效率。积极响应国家分级诊疗政策,辅助消化科医师进行快速分类。分类速度快,分类的准确率高,能有效帮助医生和患者。
发明内容
本发明的目的是:提供一种基于计算机视觉的结直肠镜图像分类方法。
为解决上述技术问题,本发明采用的技术方案是:
一种基于计算机视觉的结直肠镜图像分类方法,其特征在于:包括以下步骤:
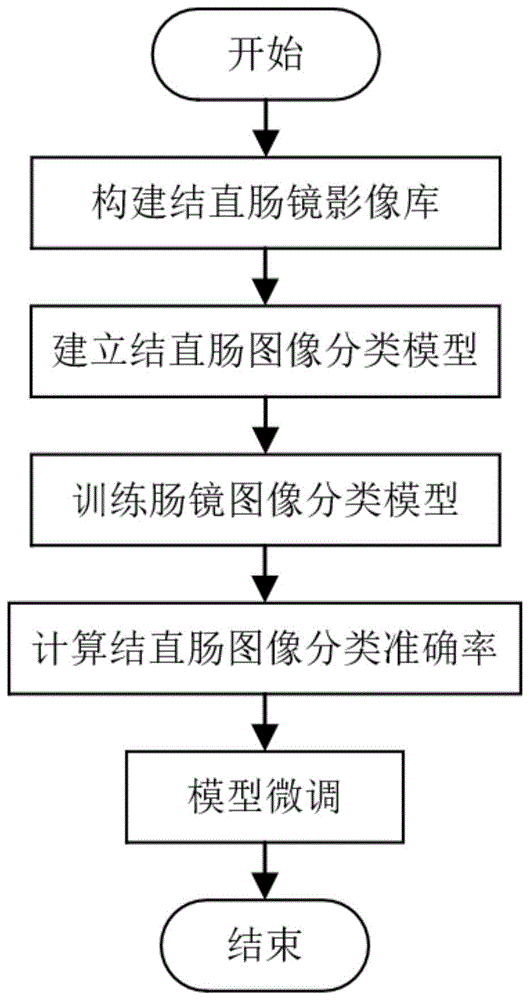
步骤1:构建结直肠镜影像库,由以下具体步骤组成:
步骤1-1:收集网上结直肠镜图像和公开数据集,对数据进行汇总和筛选,作为结直肠镜影像库的图像;
步骤1-2:对结直肠镜影像库的图像进行分类并进行类别标注,包括健康结直肠、肠炎、肠息肉和肠癌;
步骤1-3:将结直肠镜影像库的图像按预设比例划分为训练集、测试集和验证集,将训练集进行图像增强处理;
步骤2:建立结直肠图像分类模型:包括依次级联的位置编码、卷积层1、自注意力机制、多层感知机和全连接层;多层感知机包括依次级联的卷积层2、卷积层3、随机失活层1、卷积层4、归一化、激活函数、随机失活层2组成;
步骤3:训练肠镜图像分类模型由以下具体步骤组成:
步骤3-1:设置训练参数,包括学习率、Epoch和BatchSize;学习率包括初始值和用于调整学习率的优化器;
步骤3-2:预设训练轮次和各训练轮次包括的训练的次数;设置当前轮次为1;
步骤3-3:进行模型训练,实时输出loss曲线作为训练曲线,判断训练曲线和测试曲线是否出现交叉,如果是,转向步骤3-5;否则转向步骤3-4;
步骤3-4:判断是完成训练当前训练轮次;如果是,转向步骤3-5;否则转向步骤3-3;
步骤3-5:保留当前模型参数作为当前轮次模型参数;
步骤3-6:判断是否最后一轮次,如果是,转向步骤,否则,当前轮次数加1,转向步骤3-3;
步骤4:计算结直肠图像分类准确率:选择测试集中预设比例的图像分别输入各轮次模型参数,选择准确率最高的轮次模型参数作为优选模型的参数;再优选模型利用预设比例的验证集图像输入优选模型,判断优选模型的准确率是否存在低于90%的类别,如果有,转向步骤5,否则转向步骤6;
步骤5:模型微调,由以下具体步骤组成:
步骤5-1:将测试集中的图像输入优选模型,选择分类错误的图像,并在训练集中按照预设相似度使用预设相似准则选择图像,组成易混淆数据集;
步骤5-2:将易混淆数据集进行数据增强,数据增强操作包括翻转、平移和裁剪,得到强化学习数据集;
步骤5-3:用强化学习数据集划分轮次,逐轮次微调优选模型,保存各轮次微调模型最佳参数;
步骤5-4:将验证集中的数据分别输入各轮次微调模型和优选模型,选择准确率最高的微调模型作为最优模型。
步骤6:结束训练。
进一步,所述步骤2中的位置编码模块将输入图像进行特征提取后按预设大小进行分割,各分割为作为一个token;在图像各token之后加上一个用于预测分类的classtoken;位置编码信息与各token求和后输入卷积层1。
进一步,步骤3在包含两个以上显存卡得平台上训练肠镜图像分类模型,通过log_Softmax函数生成各Batchsize运行在各显存卡的预测概率:根据预测概率选择其运行的显存卡。
进一步,步骤3还包括剪枝步骤,对最优模型中各卷积层选取预设比例的参数剪枝。
进一步,步骤1还包括数据去重步骤:利用图像感知算法、平均哈希算法或差异哈希算法按照预设得相似准则删除相似度高于预设阈值的图像。
进一步,所述步骤3-1中用于调整学习率的优化器设置为SDG。
进一步,所述步骤3-1中用于调整学习率的优化器设置为Adam。
进一步,所述步骤3-1中Epoch设置为150或200。
进一步,所述步骤3-1中BatchSize设置为64。
采用上述技术方案,本发明的有益效果是:
1、本发明基于计算机视觉技术,通过图像数据的训练获得结直肠镜图像的准确分类;
2、本发明采用算法去除重复数据和跨卡同步Batch Normalization,提高了图像分类模型的效率,实现了图像分类模型高并发、高性能的支持;
3、采用图像位置编码的方式将图像分为多个patch进行学习,减少显存占用,并将位置信息与权重信息相融合,更好的进行分类任务。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是数据流程图;
图2是模型结构图;
图3是loss曲线图;
图4是结肠图像多分类的准确率图。
实施例1:
步骤1:构建结直肠镜影像库,由以下具体步骤组成:
步骤1-1:收集网上结直肠镜图像和公开数据集,对数据进行汇总和筛选,作为结直肠镜影像库的图像;
步骤1-2:对结直肠镜影像库的图像进行分类并进行类别标注,包括健康结直肠、肠炎、肠息肉和肠癌;
步骤1-3:将样本数据集中的数据按7:2:1的比例划分为训练集、测试集和验证集,将训练集中的结直肠镜图像进行图像增强处理;
步骤2:建立结直肠图像分类模型:建立结直肠图像分类模型:分类模型由位置编码、自注意力机制、多层感知机和全连接层组成,首先输入图像并被分为64个局部图像进行训练,减少训练的时间和成本;图像分块后进入位置编码模块记录图像块各自的位置信息,在学习图像时使位置信息与权重相结合,更好的获取特征;位置编码模块输出的图像特征信息和位置编码,经过卷积层1进入自注意力机制模块,获取图像中的关键部分,是提升分类效果的重要模块;自注意力机制连接多层感知机进行训练,多层感知机由卷积层2、卷积层3、随机失活层1、卷积层4、归一化、激活函数和随机失活层2组成,可以应对更加复杂的非线性关系;最后利用全连接层处理多层感知机的输出,这些模块的组合能利用较少的数据达到较高的准确率;
步骤3:训练肠镜图像分类模型,训练过程包括两部分,由以下具体步骤组成:
步骤3-1:设置训练参数,包括学习率、Epoch和BatchSize;学习率包括初始值和用于调整学习率的优化器;
学习率初始值设置为0.01,用于调整学习率的两种优化器分别是SGD和Adam,在进行训练时这两种方式都会对学习率乘一个系数形成每个Epoch的真实学习率,系数由训练过程生成,这两种方式都可以使模型收敛,通过实验对比SGD方式使该模型得到更好的收敛;
Epoch为模型训练的最大次数,在进行训练时,发现在150Epoch左右达到最佳训练效果,因此设置最大Epoch为200,保证可以获取到最佳模型;
BatchSize的大小决定训练的速度和质量,本实施例分别将BatchSize设置为8、16、32、64、128来进行参数设置实验,并设置Epoch为5,当BatchSize为64时,准确率最高,因此确定BatchSize为64;
学习率设为SGD或Adam;进行对比,这两种方式都可以使模型收敛,但是SGD方式使该模型得到更好的收敛;
步骤3-2:进行模型训练,每进行十次训练为一个训练轮次,各训练轮次保留一个优选模型;训练过程中实时输出loss曲线,用测试集数据进行测试,检测训练集的loss曲线和测试集的loss曲线是否交叉,如果交叉则表明出现了过拟合的情况,取过拟合之前的模型为优选模型,如果一直无交点,择取最后一个Epoch的模型作为优选模型;
步骤4:计算结直肠图像分类准确率:利用20%的测试集观察训练时不同阶段模型的准确率,保留最优模型,利用10%的验证集验证模型的分类效果,如果准确率有低于90%的类别,则进行步骤5,如果准确率全部在90%以上,则结束训练;
步骤5:模型微调,由以下步骤组成:
步骤5-1:使用测试集进行测试,把分类错误的图像提取出来,组成易混淆数据集;
步骤5-2:将易混淆数据集进行翻转,平移和裁剪,得到强化学习数据集;
步骤5-3:用强化学习数据集对分类模型进行微调训练;
步骤5-4:微调时每个Epoch保存一次模型,并用验证集进行验证,因为微调的数据单一,不用经过长时间训练,因此3-5个epoch就可以达到较好的效果;最后,与微调前的模型进行对比保证模型有所提升,保存最优模型,结束训练。
所述步骤2中的位置编码模块对图像序列编码,图像大小为224*224,分割为8*8个平铺的图像块,每个图像块的维度为28*28*3=2532,网络学习时每个图像块生成一个token,得到8*8=64个token,维度为2532*64;位置编码信息为各像素在图像中的位置序号,其与token进行求和操作,使得位置编码与图像进行匹配,数据维度不变。
将具有位置编码的token进行卷积后输入自注意力机制中进行学习,得到结肠图像的特征;将图像的特征输入多层感知机中继续进行特征学习,最后输入到全连接层进行分类,全连接层将多层感知机输出的二维特征图转化成一维的一个向量,将特征空间映射样本标记空间,得到最终的分类结果。
所述步骤3还包括跨卡同步批标准化Batch Normalization步骤,图像的训练是一般对GPU的要求较高,对于比较消耗显存的训练任务时,往往单显存卡上可以设置的BatchSize过小,通过多卡同步批标准化Batch Normalization来提升模型的收敛效果,使用RTX2080型号的显存卡无法将BatchSize设置为64,两块并行的显存卡也只能使用一张,一个Batch被分到了好几个进程,无法均衡每个Batch的数据,通过跨卡同步批标准化BatchNormalization来提升模型的收敛效果;在使用跨卡同步前,loss收敛后仅仅能达到0.2~0.3,在使用跨卡同步后,收敛可达到0.1~0.2;
所述步骤3还包括剪枝步骤:对模型中所有的卷积层执行剪枝操作,通过不同的剪枝率的效果决定降低多层感知机中的卷积层维数为原来的60%,,将得到的模型参数作为网络权重。实现在模型压缩和性能之间达到的平衡,网络可以自动识别无关紧要的通道,从而安全地删除这些通道,而不会很大地影响泛化性能。
所述步骤1还包括数据去重步骤:利用图像感知算法、平均哈希算法和差异哈希算法将每个类别中相似复的数据进行删除,在利用以上算法时,可以设置不同的阈值来达到控制删除数据的相似程度,通过数据的去重可以提高数据集的多样性,有助于模型更好地泛化到新的、未见过的数据,防止训练的模型在训练时过早的出现过拟合现象。
本实例中采用健康结直肠、肠炎、肠息肉和肠癌数据进行模型训练。
其中四类数据每类数据各7000张作为训练集,2000张作为测试集,1000张作为验证集。
设置BatchSize为64,Epoch为200,使用两张GPU进行训练,并设置优化器为SGD。使用测试集达到较高的测试准确率,平均准确率达到了96.3%,平均召回率达到了95.58%。验证集的平均准确率达到94.48%。使用验证集进行模型效果验证,肠癌的准确率为96.46%,肠炎的准确率为97.26%,肠息肉的准确率为91.66%,健康结直肠的准确率为92.55%。
- 一种基于互联网可视化结直肠镜检查系统及其装置
- 一种基于互联网可视化结直肠镜检查系统及其装置