一种基于熵聚类和卷积神经网络的舌质舌苔分离方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及深度学习和图像处理技术领域,尤其涉及一种基于熵聚类和卷积神经网络的舌质舌苔分离方法。
背景技术
在中医的诊断上面,舌诊是很重要的一个环节。根据舌象可以判断一个人的身体的健康状态。舌头和人体的很多器官相互连接,舌头的不同区域的状况对应这人体每个器官的状况。舌象主要由舌质和舌苔组成,根据舌质舌苔之间的分布比例以及颜色在很大程度上可以帮助在对舌象上的特征分析。
在目前的舌质舌苔分离方法中主要包括有监督深度学习和传统图像处理方法这两种方式;其中,深度学习的方法,利用深度学习里面的语义分割算法对舌质舌苔进行分离,在很大程度上依赖于像素级别的标签标注和细粒度的分割模型,这会导致该方法需要大量的标注工作和大规模的网络模型参数;而传统的图像处理方法,虽然不需要大量的标注数据,但是其算法的鲁棒性不及深度学习方法,而且对舌质舌苔的分离效果不佳。
综上,目前的舌质舌苔分离方法,存在标注量和计算量大、算法的精度和速度不足等缺陷。
发明内容
鉴于上述的分析,本发明实施例旨在提供一种基于熵聚类和卷积神经网络的舌质舌苔分离方法,用以解决现有舌质舌苔分离方法中存在的标注量和计算量大、算法的鲁棒性不足等问题。
本发明的目的主要是通过以下技术方案实现的:
本发明实施例提供了一种基于熵聚类和卷积神经网络的舌质舌苔分离方法,包括如下步骤:
获取包含舌质舌苔信息的舌象图像集;基于所述舌象图像集的总体图像熵,得到聚类中心个数,聚类后得到舌象子图集;
对聚类后的所述舌象子图集进行类别标注,获得标注后的舌象子图集,形成数据集;所述类别包括舌质和舌苔;
利用所述数据集,对卷积神经网络模型进行训练,获得训练后的卷积神经网络模型;
利用训练后的卷积神经网络模型对待分类的舌象子图进行分类,获得分类结果;所述待分类的舌象子图通过待分类的舌象图像聚类后得到;
对所述分类结果进行验证,对验证通过的分类结果中的同类别的舌象子图进行合并叠加,得到最终的分类结果。
基于上述方法的进一步改进,获取包含舌质舌苔信息的舌象图像集,包括:
对舌象进行图像拍摄,获得原始图像集;
根据拍摄过程中的光线环境,通过CCM对原始图像集进行颜色校正,得到经过颜色校正的图像集;
将经过颜色校正的图像集进行尺寸调整,送入舌图像分割网络进行分割,得到分割好的舌象图像集。
基于上述方法的进一步改进,舌象图像集的总体图像熵,通过以下方式获得:
将舌象图像集的色彩空间从RGB色彩空间转到HSV色彩空间;
对舌象图像集中的舌象图像,分别计算舌象图像在H通道的图像二维熵H
对舌象图像集中的舌象图像,利用H
基于上述方法的进一步改进,基于所述舌象图像集的总体图像熵,得到聚类中心个数,包括:
建立聚类中心数与总体图像熵的非线性关系式;
基于聚类中心数与聚合程度的关系,对所述非线性关系式进行拟合,得到聚合程度最大时,所述非线性关系式的系数;
基于拟合后得到的所述非线性关系式和所述总体图像熵,计算得到聚类中心数;
对聚类中心数进行向上取整,获得聚类中心个数。
基于上述方法的进一步改进,聚类中心数与聚合程度的关系,包括:
其中,S是聚合程度,N
通过使N
基于上述方法的进一步改进,聚类后得到舌象子图集,包括:
基于聚类中心个数N,对RGB色彩空间的舌象图像,进行K均值聚类的初始点,即初始聚类中心位置的计算;
将舌象图像分成预设数目的网格,然后分别计算这些网格中像素的熵,取前N个熵最大的网格,将其中心坐标作为初始聚类中心位置;
基于初始聚类中心,进行K均值聚类的迭代,获得聚类后的舌象子图;
对舌象图像集中的每一舌象图像进行处理,获得聚类后的舌象子图集。
基于上述方法的进一步改进,对聚类后的所述舌象子图集进行类别标注,获得标注后的舌象子图集,形成数据集,包括:
按照舌质、舌苔两种类别,对聚类后的舌象子图进行类别标注,获得标注后的舌象子图;标注后的舌象子图,按照预设的比例划分为训练集和验证集,形成数据集。
基于上述方法的进一步改进,对所述分类结果进行验证,包括:
利用相似度指标,对所述分类结果进行验证,按照如下步骤获得验证通过的分类结果:
步骤1:输入分类结果中的各簇舌象子图的数据以及各相似度指标的阈值D、E和F;其中,D、E和F预先由实验测得;
步骤2:计算总直方图相似度HB;
计算总余弦相似度COS;
计算总结构相似度SSIM;
步骤3:判断是否满足HB>D、COS>E且SSIM>F;
步骤4:若满足,则验证通过;否则不通过;其中,
总直方图相似度通过以下方式获得:
使用分类结果的RGB直方图来进行直方图统计,并把分类结果中的黑色像素排除,把彩色像素个数进行归一化;
分类结果的RGB的R通道归一化直方图、G通道归一化直方图和B通道归一化直方图可以按照如下表示:
其中,N
使用巴氏系数进行相似度计算,按如下方式获得分类结果中两幅舌象子图间的直方图相似度ρ:
其中p、p′分别代表分类结果中源区域与候选区域的舌象子图的直方图数据,p、p′包含对应舌象子图的R通道归一化直方图、G通道归一化直方图和B通道归一化直方图;
获得两个舌象子图间的直方图相似度;
对分类结果中所有的舌象子图,两两进行直方图相似度的计算,并求和,得到总直方图相似度HB。
基于上述方法的进一步改进,总余弦相似度通过以下方式获得:
将舌象子图分为m个区域,每个区域有n个像素,每个像素在舌象子图中以红、绿、蓝三色来表示,则通过以下方式计算获得舌象子图的区域特征码:
其中,n
计算两幅舌象子图间的余弦相似度时,将其中一幅舌象子图的区域特征码记作A,另一幅舌象子图的区域特征码记作B,将A和B代入余弦相似度计算公式来计算两幅舌象子图间指定区域的余弦相似度:
其中,i表示n个像素中的第i个像素;
对m个区域进行余弦相似度的计算,并求和,得到两个舌象子图间的余弦相似度;
对分类结果中所有的舌象子图,两两进行余弦相似度的计算,并求和,得到总余弦相似度COS。
基于上述方法的进一步改进,总结构相似度通过以下方式获得:
按照如下方式计算获得分类结果中两幅舌象子图间的结构相似度:
其中,下标x,y代表两幅舌象子图的标号,μ为亮度对比和σ为对比度对比;
对分类结果中所有的舌象子图,两两进行结构相似度的计算,得到每两个舌象子图间的结构相似度S
与现有技术相比,本发明至少可实现如下有益效果之一:
1、本发明通过计算图像二维熵和K均值聚类,仅需要在训练时手动对聚类的子图类型,即舌质舌苔类型进行标注,相比于现有技术中的细粒度分割标注,本发明的标注工作量大幅减小。
2、本发明在实现中结合聚类等算法和深度学习算法,减少了算法模型的参数,同时提高了算法的速度。
3、本发明通过聚合程度等指标确定最佳聚类中心个数,对图像的相同特征进行综合,在深度学习分类阶段,进行特征分类使得像素分类的结果,相对于传统算法在精度上有很大提升。
本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
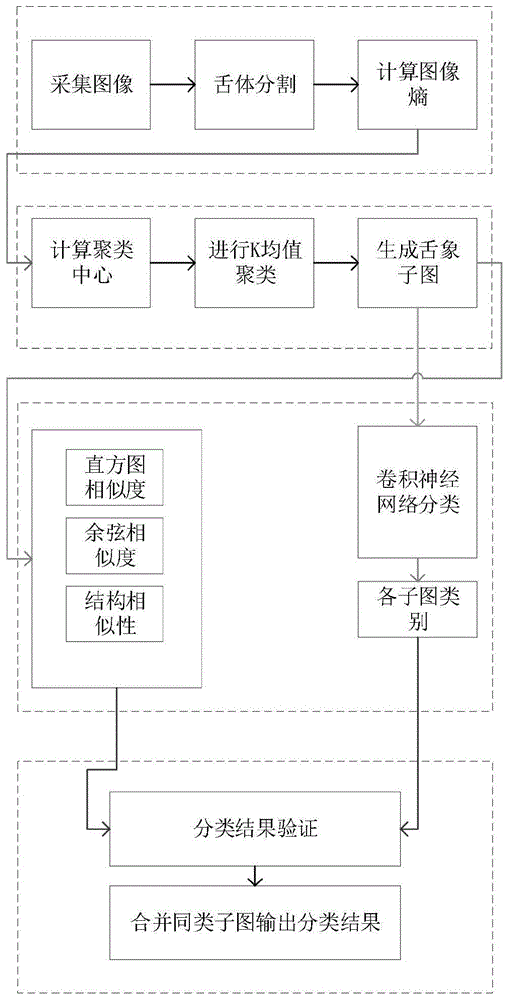
图1为本发明的算法流程图;
图2为本发明的卷积神经网络架构图;
图3为本发明的卷积神经网络架构中第三阶段的SE(压缩和激励网络,squeezeand excitation)模块;
图4(a)为本发明的原始图像;
图4(b)为本发明的最终分类结果。
具体实施方式
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
实施例1
本发明的一个具体实施例,公开了一种基于熵聚类和卷积神经网络的舌质舌苔分离方法,该方法的流程如图1所示,包括如下步骤:
S1.采集包含舌质舌苔信息的原始图像集,并对原始图像集进行处理,获得舌象图像集;计算获得舌象图像集的总体图像熵;基于所述总体图像熵,通过拟合获得聚类中心个数;基于聚类中心个数,对舌象图像集进行K均值聚类,得到聚类后的舌象子图集。
S2.对聚类后的舌象子图集进行类别标注,获得标注后的舌象子图集,形成数据集;
利用所述数据集,对卷积神经网络模型进行训练,获得训练后的卷积神经网络模型;
重新获取新的聚类后的舌象子图作为待分类舌象子图,利用训练后的卷积神经网络模型对所述待分类舌象子图进行分类,获得分类结果。
S3.利用相似度指标,对所述分类结果进行验证,获得验证通过的分类结果;并将验证通过的分类结果中,同一类别的舌象子图合并为同一类别的像素,进行图片叠加,得到最终的分类结果。
实施例2
在实施例1的基础上进行优化,步骤S1可进一步细化为如下步骤:
S11.采集包含舌质舌苔信息的原始图像集,并对原始图像集进行处理,获得舌象图像集。处理过程如下:
首先使用图像采集设备对舌象进行图像拍摄,获得原始图像集;
然后根据采集过程中的光线环境,通过CCM(颜色矫正矩阵,color correctionmatrix)对原始图像进行颜色校正,得到经过颜色校正的图像集;
最后将经过颜色校正的图像集调整到合适大小,然后送入舌图像分割网络进行分割,得到分割好的图像集,即舌象图像集。
具体的,舌图像分割网络采用Unet(U型网络)分割结构,用于将经过颜色校正和尺寸调整的图像集分割得到舌象图像集。
S12.计算获得舌象图像集的总体图像熵。
熵是一种特征统计形式,它反应了一个体系中的信息量的多少,在一张图像中的内容越复杂,那么图像所包含的信息就越多,求得的图像的熵也就越大。因为舌象图像上的舌质和舌苔中包含丰富的信息,并且在颜色和纹理上都比较复杂,所以使用熵来刻画舌图像的特征是准确并且有效的。
在RGB的色彩空间中,由于亮度对图像的影响比较大,因此将舌象图像的色彩空间从RGB色彩空间转到HSV色彩空间,并采用HSV色彩空间进行图像二维熵的计算,则可将亮度这一信息对结果的影响进行忽略。
具体的,在进行图像二维熵计算时,我们只针对我们感兴趣的颜色与色调所决定的图像二维熵、并且只选取HSV色彩空间中的H和S这两个通道进行计算。
基于舌象图像,设置通道像素值在0到255,为表征通道像素信息的空间特征,引入图像的像素点与该点的邻域信息,构成一个新的特征二元组。按照如下方式计算舌象图像在H通道的图像二维熵H
其中,在H通道中,i
按照如下方式计算舌象图像在S通道的图像二维熵H
其中,在S通道中,i
获得H通道的图像二维熵H
H
其中,a’和b’根据实验得到,a’为H
S13.基于所述总体图像熵,通过拟合获得聚类中心个数。
根据总体图像熵,可以建立起一套准确的聚类中心个数的拟合。在图像的聚类分析上的一个难题就是具体的聚类中心个数的确定,为了实现像素分类的目标我们需要在保证分类准确率的情况下用最小的聚类中心个数来进行聚类,即用最少的子图来准确的分离同类特征。具体的实现方式是定义一个与聚类准确率相关的指标。我们使用聚合程度来作为评价指标。而最优的聚类中心个数,则根据聚类后同类别像素的聚合程度来判断。
基于所述总体图像熵,通过拟合获得聚类中心个数,包括:
按照如下方式计算获得聚合程度:
其中,S是聚合程度,N
通过使N
将聚合程度S和总体图像熵H
N
其中,a、b、c和d为待通过拟合得到的系数;
通过拟合,获得当聚合程度S最大时对应的系数a、b、c和d,进而获得当聚合程度S最大时对应的聚类中心数N
S14.基于聚类中心个数N,对舌象图像进行K均值聚类,得到聚类后的舌象子图集。
根据聚类中心个数N,对S11.中RGB色彩空间的舌象图像集,进行K均值聚类的初始点,即初始聚类中心位置的计算。具体的,将舌象图像集中的舌象图像分成s×s的网格,然后分别计算这些网格中像素的熵,取前N个熵最大的网格,将其中心坐标作为初始聚类中心位置。
在K均值聚类过程中,进行聚类的测度是HSV图像上的H和S两个的指标的距离,示例性的,根据求得的初始聚类中心进行K均值聚类的算法迭代,获得聚类后的舌象子图集,算法流程如下:
步骤1:加载初始聚类中心;
步骤2:计算每个样本点到中心点的欧氏距离并分配类别编号;
步骤3:对类别相同的聚类样本重新计算各簇聚类中心;
步骤4:判断是否达到簇中心的平方和,即迭代阈值和:
若没有达到,则返回步骤2继续迭代;若达到,则终止算法得到各簇舌象子图集。
优选地,步骤S2可进一步细化为如下步骤:
S21.对聚类后的舌象子图集进行类别标注,获得标注后的舌象子图集,形成数据集。
具体的,按照舌质、舌苔两种类别,手动对聚类后的舌象子图集进行类别标注,获得标注后的舌象子图;标注后的舌象子图,按照7∶3的比例划分为训练集和验证集,形成数据集。
S22.利用所述数据集,对卷积神经网络模型进行训练,获得训练后的卷积神经网络模型。
具体的,在对卷积神经网络进行搭建的过程中,使用resnet作为提取网络,结合特征金字塔与注意力模块,使得卷积神经网络具备对细粒度信息进行检测的能力。
在对卷积神经网络进行训练的过程中,数据集经过的卷积过程如下:
网络计算分三个阶段,如图2所示:
第一阶段对特征进行采样,即为网络的前馈,前馈网络以ResNet为骨干网络;此阶段使用的网络架构为ResNet50网络,其中,对于ResNet50网络有五个过程卷积阶段通过短路机制加入残差单元,最后再经过平均池化层的处理,可以提取图像不同层次的特征;通过第一阶段是自下而上的路径阶段,主要是为了提取不同层次的特征,将得到不同层次的特征的特征图,即c2,c3,c4,c5,送到第二阶段进行处理;
第二阶段为自上而下路径的阶段,主要从第一阶段得到的特征上面构造出一组新的特征,p2,p3,p4,p5每个特征层都是ResNet50中不同卷积层融合的结果,保证了拥有更多的层次信息。主要将自下而下所得的特征图过一个1×1的卷积层以融合个通道的信息同时降低通道维度,此后在与自上而下的特征图进行融合,然后进行3×3的卷积以消除混叠效应;
第三阶段为特征融合与注意力提取阶段,第二阶段的各层特征在这里首先经过如图3所示的SE(压缩和激励网络,squeeze and excitation)模块提取通道注意力,SE模块对于每个输出通道,预测一个常数权重,对每个通道加权一下,本质上,SE模块是在通道维度上做注意力或者门控操作,这种注意力机制让模型可以更加关注信息量最大的通道特征,而抑制那些不重要的通道特征。以提高网络对细粒度特征识别的性能。通过一次反卷积,将每个特征图的大小同步到相同尺寸,然后进行拼接,之后再将所有拼接得到的特征送入卷积网络进行特征提取,最后展平后送入全连接网络,经过softmax函数得到每个类别的概率值,得到分类结果。
S22.重新获取新的聚类后的舌象子图作为待分类舌象子图,利用训练后的卷积神经网络模型对所述待分类舌象子图进行分类,获得分类结果。
获取新的聚类后的舌象子图。重新采集包含舌质舌苔信息的新的原始图像,并对新的原始图像进行处理,获得新的舌象图像,计算获得该舌象图像的总体图像熵,并基于所述总体图像熵,通过拟合获得聚类中心个数,然后基于聚类中心个数N,对新的舌象图像进行K均值聚类,得到聚类后的舌象子图。
优选地,步骤S3可进一步细化为如下步骤:
S31.利用相似度指标,对所述分类结果进行验证,获得验证通过的分类结果。
在结果验证方面,由于仅依靠人眼验证主要依靠主观判断,在结果的准确性上面存在诸多弊端,因此在获得分类结果之后,为了保证分类结果的准确性,需要使用三种不同的客观量化指标对分类结果进行验证;其中,这三种客观量化指标分别为直方图相似度指标、余弦相似度指标和结构相似度指标,直方图相似度指标,用于在像素统计方面,比较分类结果中的舌象子图之间的相似程度;余弦相似度指标,用于衡量分类结果中的舌象子图之间颜色的余弦相似度;结构相似度指标,用于在粗略的作出舌苔大部分分布在舌中心位置、舌质大部分分布在舌边缘位置,这一判断的基础上,还能考虑到具体的结构信息。结合这几个不同的指标,可以对分类结果进行客观化验证。
总直方图相似度通过以下方式获得:
使用分类结果的RGB直方图来进行直方图统计,并把分类结果中的黑色像素排除,把彩色像素个数进行归一化;
分类结果的RGB的R通道归一化直方图、G通道归一化直方图和B通道归一化直方图可以按照如下表示:
其中,N
使用巴氏系数进行相似度计算,按如下方式获得分类结果中两幅舌象子图间的直方图相似度ρ:
其中p、p′分别代表分类结果中源区域与候选区域的舌象子图的直方图数据,p、p′包含对应舌象子图的R通道归一化直方图、G通道归一化直方图和B通道归一化直方图;
获得两个舌象子图间的直方图相似度;
对分类结果中所有的舌象子图,两两进行直方图相似度的计算,并求和,得到总直方图相似度HB。
余弦相似度指标,通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0°的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而通过两个向量之间的角度的余弦值,可以确定两个向量是否大致指向相同的方向。当两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向相关。余弦相似度通常用于正空间,因此设置余弦相似度的值为0到1之间。把分类结果中的舌象子图表示成一个向量,通过计算向量之间的余弦距离来表征分类结果中的两张舌象子图的相似度。
这里把分类结果中的舌象子图上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。将这些点按区域组成子集,提取子集的特征后,将每个子集的特征作为舌象子图的一个特征项来进行计算。
总余弦相似度通过以下方式获得:
将舌象子图分为m个区域,每个区域有n个像素,每个像素在舌象子图中以红、绿、蓝三色来表示,则通过以下方式计算获得舌象子图的区域特征码:
其中,n
计算两幅舌象子图间的余弦相似度时,将其中一幅舌象子图的区域特征码记作A,另一幅舌象子图的区域特征码记作B,将A和B代入余弦相似度计算公式来计算两幅舌象子图间指定区域的余弦相似度:
其中,i表示n个像素中的第i个像素;
对m个区域进行余弦相似度的计算,并求和,得到两个舌象子图间的余弦相似度;
对分类结果中所有的舌象子图,两两进行余弦相似度的计算,并求和,得到总余弦相似度COS。
总结构相似度通过以下方式获得:
按照如下方式计算获得分类结果中两幅舌象子图间的结构相似度:
其中,下标x,y代表两幅舌象子图的标号,μ为亮度对比和σ为对比度对比;
对分类结果中所有的舌象子图,两两进行结构相似度的计算,并求和,得到总结构相似度SSIM。
利用相似度指标,对所述分类结果进行验证,按照如下步骤获得验证通过的分类结果:
步骤1:输入分类结果中的各簇舌象子图的数据以及各相似度指标的阈值D、E和F;其中,D、E和F预先由实验测得;
步骤2:计算总直方图相似度HB;
计算总余弦相似度COS;
计算总结构相似度SSIM;
步骤3:判断是否满足HB>D、COS>E且SSIM>F;
步骤4:若满足,则验证通过;否则不通过。
S32.将验证通过的分类结果中,同一类别的舌象子图合并为同一类别的像素,进行图片叠加,得到最终的分类结果,如图4所示,图4(a)为原始图像,图4(b)为最终的分类结果。
通过上述方式,计算图像二维熵和K均值聚类,仅需要在训练时手动对聚类的子图类型,即舌质舌苔类型进行标注,相比于现有技术中的细粒度分割标注,本发明的标注工作量大幅减小;结合聚类等算法和深度学习算法,减少了算法模型的参数,同时提高了算法的速度;通过聚合程度等指标确定最佳聚类中心个数,对图像的相同特征进行综合,在深度学习分类阶段,进行特征分类使得像素分类的结果,相对于传统算法在精度上有很大提升。
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 一种增强负压吸附卷带效果的伸缩式负压装置
- 一种基于负压的车床主轴用高效清洁除屑装置
- 一种负压集屑吹风一体式车床