一种基于选择性激活的脉冲神经网络连续学习目标识别系统
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于图像识别领域,尤其是涉及一种基于选择性激活的脉冲神经网络连续学习目标识别系统。
背景技术
生物大脑在整个生命周期中能够不断从与环境的互动中学习,具有面向多任务时的终身学习能力。当前人工神经网络(Artificial neural networks,ANN)的机器智能已经表现出了非凡的能力。然而,新一代的边缘端等应用,如自动驾驶汽车和可穿戴设备,需要新的具有连续学习能力的机器智能,既能获取新知识,又不遗忘旧知识,同时还能在计算资源受限的情况下高效率运行。受到生物系统的启发,脉冲神经网络(Spiking neuralnetworks,SNN)与ANN相比具有更丰富的时空动态性(Maass,1997年;SubbulakshmiRadhakrishnan等,2021年;Yin、Corradi和Bohte,2023年),同时通过与神经形态硬件相结合,更有潜力实现具有低功耗的下一代机器智能。上述持续学习的目的是以一种有序的方式获取知识,同时确保代理只能访问当前任务的数据,而不会影响其回忆之前所学任务的能力。
当前主流的持续学习技术可大致分为三类,即基于正则化的技术、基于重放的技术和基于架构的技术。基于正则化的技术通过在损失函数中添加正则化项来保护突触连接如EWC(Kirkpatrick等人,2017年)、MAS(Aljundi等人,2018年)、SI(Zenke、Poole和Ganguli,2017年),它们通过一定的规则计算每个参数的重要性,并生成惩罚项来限制重要参数的变化。基于重放的技术旨在通过保留每个任务中的几个关键样本(或中间表征),并将它们与当前任务的数据混合后在网络中传播,从而提高知识保留率。这些方法大多面向人工智能网络,例如(Van de Ven、Siegelmann和Tolias 2020;Arani、Sarfraz和Zonooz2022;Rebuffi等人2017)。根据定义,这些方法不可避免地需要额外的存储空间来存储额外的信息和扩展模型。基于架构的方法(Kang等人,2022年;Yoon等人,2017年)通过不断调整架构来增强网络执行不同任务的能力,也会遇到类似的问题。由于对子网络进行了有目的的分割/扩展,这些方法通常在不同任务之间表现出相对稳定的性能。然而,为了区分不同子网络的使用范围,这些方法往往需要事先了解任务信息。
至于其他基于SNNs的持续学习方法,(Antonov、Sviatov和Sukhov2022年)通过局部STDP的随机Langevin动力学确定突触权重的重要性,并通过无监督学习实现持续学习。(Skatchkovsky、Jang和Simeone2022)在贝叶斯方法的基础上引入了在线规则SNN模型。(Hammouamri、Masquelier和Wilson 2022)通过使用进化策略训练外部网络来生成分类器的发射阈值,从而实现SNN的持续学习。(Tadros等人2022年)通过使用转换算法在脉冲频率编码和脉冲时间编码之间切换,实现了局部可塑性,以帮助模型在学习新任务后纠正偏差。
简而言之,尽管上述技术具有明显的性能优势,但它们往往需要复杂的算法、额外的存储空间或特定任务的知识,因此大大偏离了生物制剂与生俱来的顺序学习能力。
发明内容
本发明公开了一种基于选择性激活的脉冲神经网络连续学习目标识别系统,通过增强智能学习网络(SNN)中的神经动态特性来减轻灾难性遗忘,提高连续学习场景下的图像识别的效果,并且扩展了脉冲神经网络的应用场景。
一种基于选择性激活的脉冲神经网络连续学习目标识别系统,包括计算机存储器、计算机处理器以及存储在所述计算机存储器中并可在所述计算机处理器上执行的计算机程序,所述计算机存储器中存有训练好的选择性激活SNNs模型;
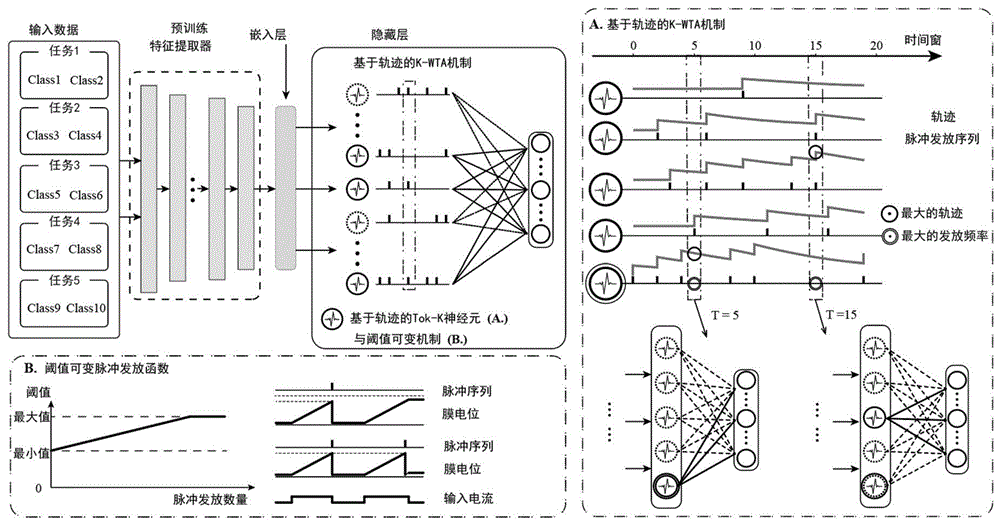
所述的选择性激活SNNs模型包括脉冲神经网络前端的特征提取部分,并在后端采用基于轨迹的K-WTA机制和可变阈值机制进行持续学习;
具体的,在脉冲神经网络隐藏层中的神经元的动态变化中应用基于轨迹的K-WTA机制,以减少不同任务之间的相互干扰,同时,对隐藏层中的神经元使用可变的脉冲发放阈值,以鼓励沉默神经元参与学习,并抑制在旧任务训练过程中已被激活的神经元重新被激活;
所述计算机处理器执行所述计算机程序时实现以下步骤:
将待识别的图像输入训练好的选择性激活SNNs模型,得到图像的分类结果。
本发明保证了脉冲神经元在不同时间步的选择性激活,从而实现在连续学习过程中不同任务选择性地激活特定的脉冲神经元亚群,该系统从脉冲神经网络自身特殊的结构和时空动力学计算的原理出发,实现了基于结构自适应选择的脉冲神经网络连续学习方法,对不同任务具有更强的适应性,克服了原始脉冲神经网络模型在多任务连续学习过程中的灾难性遗忘问题,从而扩展了脉冲神经网络的应用场景。
进一步地,基于轨迹的K-WTA机制,具体为:
在神经元引入了一个名为Trace轨迹的内部变量作为时间维度上的K-WTA的指标,脉冲神经元的轨迹的计算方法如下:
其中,τ是时间常数,它决定了迹线的衰减速度;tr[t]是神经元在时间步长为t时的迹线;S[t+1]表示神经元在步长为t时的脉冲输出。
进一步地,对隐藏层中的神经元使用可变的脉冲发放阈值时,随着激活时间的增加,将脉冲发放阈值设置为缓慢增加的方式,脉冲发放阈值不会衰减,通过不可逆的阈值变化来增强旧任务相关记忆的维持能力。
进一步地,在神经元中加入基于轨迹的K-WTA机制和可变阈值机制后,得到以下神经元动力学模型:
H(t)=f(V[t-1],X[t]),
S[t]=Θ(H(t)-V
Mask[t=TopK(tr[t]),
S
V[t]=H[t]-V
其中,X[t]是神经元在时间步长t上的输入;S[t]表示神经元的原始脉冲输出;V[t]和H(t)分别是神经元发放脉冲前和发放脉冲后的膜电位;Θ(-)是控制膜电压超过阈值就发放脉冲的函数;TopK(-)是基于轨迹的K-WTA组件中使用的函数,用于生成一个掩码,得到前K个最大轨迹对应的掩码;S
神经元模型的可变阈值V
其中,Th
进一步地,所述神经元模型可以为LIF神经元模型、IF神经元模型等不同类型的神经元模型。
进一步地,对选择性激活SNNs模型的输入层及其相关权重矩阵采用了L2正则项方法来控制稀疏性。
进一步地,对选择性激活SNNs模型进行训练时,在每个学习阶段的训练过程中,计算输出与真实标签之间的交叉熵作为损失函数,并使用STBP(spatio-temporalbackpropagation)来训练网络中的可学习参数。
与现有技术相比,本发明具有以下有益效果:
1、本发明从脉冲神经网络自身特殊的结构和时空动力学计算的原理出发,从基于结构自适应选择性激活的角度设计了脉冲神经网络连续学习方法。本发明模型的准确率变化曲线在连续学习过程中各个任务中保持相对平衡的性能。这种不同任务之间的平衡得益于模型对特定亚群神经元及其相关连接的选择性激活,因此本发明的脉冲神经网络模型在多任务连续学习场景中相比其他基线方法更强的稳定性。
2、本发明提出的模型中脉冲神经元面对不同任务的选择性的分布在学习过程中则更加均匀,不会出现某些任务的选择性脉冲神经元过少或过多导致整体连续学习过程收到干扰,因此本发明的方法被证明更加鲁棒。
3、相比基于脉冲发放频率的K-WTA,本发明提出的Trace-based K-WTA对具有相似功能的神经元有一定的容忍度,因此在不同任务之间也具有更好的混合选择性,因此本专利的方法仍能保持相对均匀的选择性分布;本发明将阈值可变组件应用到脉冲神经网络,在一定程度上抑制旧任务学习过程中已经被激活过的神经元被再次激活,促进新任务训练过程中特定神经元集群的激活,从而避免连续学习过程中的灾难性遗忘。
附图说明
图1为本发明一种基于选择性激活的脉冲神经网络连续学习目标识别系统框架图;
图2为本发明系统在Cifar10数据集上的性能示意图;
图3为本发明实施例中分析神经元对不同任务的选择性。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
一种基于选择性激活的脉冲神经网络连续学习目标识别系统,其结构如图1所示,该系统包括脉冲神经网络前端的特征提取部分,用于挖掘复杂任务中的深层特征,以及后端基于Trace-based K-WTA和可变阈值组件的持续学习部分,使网络具备持续学习的能力。
其中在SNN的隐层神经元的动态变化中应用的Trace-based K-WTA机制,以减少不同任务之间的相互干扰。同时,具有可变发射阈值的神经元,以鼓励沉默神经元在一定程度上参与学习,同时抑制在旧任务训练过程中已被激活的神经元重新被激活。本发明适用于类增量(Class-IL)、任务增量(Task-IL)和域增量(Domain-IL)等场景。
本发明实施例以难度系数最高的类增量场景为例,其实现步骤如下:
假设该类增量学习过程中包括N个学习阶段(即总共N个顺序任务)。每个阶段的任务包含了所有c
本发明涉及的基于选择性激活的脉冲神经网络模型的关键技术如下:
(1)基于Trace的K-WTA方法(Trace-based K-WTA)
正如一些研究(Lin et al.2014)(Stevens 2015)所提到的,在动物的神经回路中,存在抑制性神经元,它们收集部分神经元的兴奋,并发出反馈抑制,最终阻止大部分神经元点火。这种机制通常被称为"赢家通吃"机制(WTA),它可能有助于维持网络的鲁棒性(这种机制也被称为K-WTA,其中K代表赢家的数量)。然而,SNNs中神经元在时间窗口内的同质脉冲发放使得神经元之间很难直接进行适当的比较。
如果直接整合整个时间窗口中的脉冲,然后再部署K-WTA机制,可能不够合理。一方面,由于脉冲的离散性,可能会有很多神经元具有相同数量的脉冲发放(尤其是在时间步长相对较小的情况下),因此仍然容易产生混淆。另一方面,用未来的信息来为过去的事件产生门控信号似乎也不合理。在研究过程中,注意到突触时间相关可塑性根据突触前神经元和突触后神经元之间的突触时间间隔来更新权重。为了弥补可塑性理论中时间尺度和动作电位之间的差距,神经元引入了一个名为"Trace(轨迹)"的内部变量。由于该变量可以在线估算出脉冲序列中的平均发射率,因此也可以用它作为时间维度上的K-WTA的指标。上述脉冲神经元的轨迹的计算方法如下:
其中,τ是时间常数,它决定了迹线的衰减速度;tr[t]是神经元在时间步长为t时的迹线;S[t+1]表示神经元在步长为t时的脉冲输出;该迹线可以在每个时间步长上计算出来,而且比较容易比较并获得Top-K值,因此将其应用于逐步部署K-WTA计算。图1中(A)显示了一个可能的轨迹示例及其相应的Top-1选择。这种基于迹线的K-WTA方法的另一个潜在好处是,从整个时间窗的角度来看,它并不严格遵守K的约束条件,这可能会提高Top-K函数下子网络的表达能力。
(2)可变阈值
Top-K激活函数通常会导致大量神经元死亡(Ahmad和Scheinkman,2019年;Fedus、Zoph和Shazeer,2022年)。这是因为随机初始化的权重可能会让一组神经元很容易被激活,其突触权重也会不断更新,而其他神经元则永远不会被激活,因此也就永远不会收到反馈信号。本发明提出对隐藏层中的脉冲神经元使用可变的脉冲发放阈值。如图1中(B)所示,随着激活时间的增加,将脉冲发放阈值设置为缓慢增加的方式。值得注意的是,本发明中的脉冲发放阈值不会衰减,这样就可以通过不可逆的阈值变化来增强旧任务相关记忆的维持能力,同时实现简单,运算效率高。通过上述方式,那些过去最常被激活的神经元被重新激活的概率就会下降,从而使那些激活频率相对较低的神经元更有可能被激活,然后逐渐参与到网络的学习过程中。在基本神经元模型中加入上述两个特征,就可以得到以下神经元动力学模型:
H(t)=f(V[t-1],X[t]),
S[t]=Θ(H(t)-V
Mask[t]=TopK(tr[t]),
S
V[t]=H[t]-V
其中,X[t]是神经元在时间步长t上的输入;S[t]表示神经元的原始脉冲输出;V[t]和H(t)分别是神经元发放脉冲前和发放脉冲后的膜电位;Θ(-)是控制膜电压超过阈值就发放脉冲的函数;TopK(-)是基于轨迹的K-WTA组件中使用的函数,用于生成一个掩码,得到前K个最大轨迹对应的掩码;S
其中,Th
尽管上述两个关键方法可以促进子网络的形成,并引导神经元参与持续学习。但过密的输入仍可能导致性能异常。这是因为反向传播的贪婪内核以及SNN的有限精度和激活可能会导致这些神经元的脉冲发放频率过高,从而损害记忆的保持。因此,本发明对输入层及其相关权重矩阵采用了L2正则项方法来控制稀疏性。此外,本发明还应用了一些已被证明有效的持续学习技术,如戴尔规则和SGD优化器,以避免"陈旧动量"问题。而在每个学习阶段的训练过程中,SNN采用的训练方法与SNN的标准图像分类算法一致。即,本发明计算输出与真实标签之间的交叉熵作为损失函数,并使用STBP(spatio-temporalbackpropagation)来训练网络中的可学习参数。
本发明提出的基于选择性激活的脉冲神经网络持续学习目标识别系统,适用于基于传统相机的图像目标识别和基于动态事件相机的时间流目标识别等。为了验证本发明提出的框架在持续学习问题中的有效性,原始的图像识别数据集CIFAR10数据集被随机分为5个任务,每个任务包含2个类别,下文中称为"splitCIFAR10"数据集。如上述训练过程,每个模型依次在这些任务上进行训练。本发明使用(Bricken et al.2023)中预先训练好的特征提取器,将CIFAR数据集中的每个样本转换成256维的潜在嵌入。此外,本发明还评估了模型在splitMNIST、splitN-MNIST和split-CIFAR100数据集上的性能。模型在每个子数据集上进行训练,其中Batchsize设置为256个样本,训练epoch个数为500。对模型学习到的每个类别进行性能测试。最终的准确率是采用随机种子进行的三组实验结果的平均值。Trace-based K-WTA中的K值设置为10,p的值设置为2*1e6。
如表1所示,在splitMNIST和splitCIFAR10数据集上,所提出的SASNN的准确率分别为60.06%和77.73%,优于其他基线方法。
表1
此外,从图2中可以看出,在整个多任务连续学习过程中,本发明提出的方法始终保持着相对其他方法的准确率优势。此外,SA-SNN模型与两个具有类似持续学习原理的先进ANN模型(即SDMLP(73.27%)和FlyModel(70.09%))相比,也表现出卓越的性能。此外,即使直接利用率掩码(以SA-SNN(rate)表示),本发明提出的模型也表现出了相对较高的性能,准确率比SDMLP算法(76.78%)更高,这证明本发明提出的方法通过考虑脉冲神经网络中不同时间步的神经元动态运算,能够有效提升脉冲神经网络处理多任务连续学习任务的能力,尤其是Trace-based K-WTA机制的引入,能够使得脉冲神经网络模型更好地缓解灾难性遗忘问题。
同时,如图2所示,本发明的模型的准确率变化曲线在连续学习过程中各个任务中保持相对平衡的性能。这种不同任务之间的平衡得益于模型对特定亚群神经元及其相关连接的选择性激活,因此本发明的脉冲神经网络模型在多任务连续学习场景中相比其他基线方法更强的稳定性和鲁棒性。
另外,本发明的脉冲神经网络模型并没有利用权重的重要性比如通过引入权重正则化项来避免遗忘,因此它与基于权重正则化的方法(如EWC、MAS、SI)兼容,这些方法通常是通过在损失函数中添加惩罚项来实现。如表1所示,当本发明的方法与EWC结合使用时,本发明的脉冲神经网络模型在splitCIFAR10和splitMNIST数据集上分别提升了约2.66%和22.12%的准确率。
最后,分析了本发明的脉冲神经网络模型中神经元对不同任务的选择性。
该选择性指的是当一个神经元只对一个类别的输入做出主要反应时,它对这个类别具有选择性。为了对具有不同选择性的神经元进行粗略分类,以splitCIFAR10为例,本发明将隐层活动与10个预期数据集的类别不同选择性(即神经元只对特定类别做出反应)进行回归。活动"指的是神经元的输出(在ReLu之后),而在SNN中指的是脉冲个数。其中一个结果如图3所示。在图3(下)中,可以看出在SDMLP方法中,具有不同选择性的神经元的分布相对有偏差,而在本发明的方法中,神经元面对不同任务的选择性的分布在学习过程中则更加均匀。这种现象也直接反映在图3(上)中模型的最终混淆矩阵中:在SDMLP模型的学习过程中,具有类别2、4和5选择性的神经元所占比例相对较小,因此在后续的学习过程中识别这些类别的能力很容易受到干扰,最终导致几个类别的准确率相对较低。而使用本发明的方法,由于本发明设计的脉冲神经网络方法有更强的鲁棒性,因此本发明的方法基本不受上述干扰的影响。此外,与不同时间步下利用Trace-based K-WTA掩码相比,使用基于脉冲发放频率掩码时具有特定选择性的神经元数量更多,但本发明具有更稳定的均匀分布。这可能是由于多步掩码对具有相似功能的神经元有一定的容忍度,从而鼓励了神经元对不同任务尤其是相近任务的混合选择性。即便如此,本发明仍能保持相对均匀的选择性分布。
在本发明中,探讨了如何通过增强智能学习网络(SNN)中的神经动态特性来减轻灾难性遗忘。本发明提出了选择性激活SNNs(SA-SNN)模型,该模型采用基于轨迹的Trace-based K-Winner-Take-All(Trace-based K-WTA)和可变阈值机制进行持续学习,通过增强SNN中的神经动态特性来缓解灾难性遗忘,它不需要任务标签或记忆重放。在SA-SNN模型中,首先采用了一种生物学上可行的、基于时间轨迹的K-WTA方法来减少不同任务之间的干扰。基于轨迹的K-WTA方法本身与许多使用抑制性中间神经元的脑区的连接性趋同,进一步修改了该方法,以适应多个时间步运算的脉冲神经元。然后,设计了一种简单而有效的可变阈值方法来修改脉冲神经元的阈值,从而鼓励所有神经元参与,进而增强群体神经元在面向不同任务时的门控效果。本发明适用于类增量(Class-IL)、任务增量(Task-IL)和域增量(Domain-IL)等场景。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 一种污泥基除磷材料及其制备方法和含磷污水的处理方法
- 一种生态污水处理系统及污水处理方法
- 一种去除污水中氟化物的药剂、制备方法及污水处理方法
- 一种洗扫车污水循环装置及其污水处理方法
- 一种污水池中污水的处理方法
- 一种超高磷污水的处理方法
- 一种超高浓度含磷污水的处理方法