一种基于重采样的数据公平粒化及分类方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及粒计算信息颗粒生成性能优化技术领域,具体涉及一种基于重采样的数据公平粒化及分类方法。
背景技术
在大数据时代,提高数据的利用价值已成为数据科学研究的热点。从信息处理到数据驱动,知识提取需要一些有效的方法。作为一种新兴的信息处理范式,粒计算(GrC)引起了众多学者的关注。1997年,Zadeh首先提出了GrC的概念。GrC的目标是提取数据的信息,并将数据分成不同的颗粒。颗粒是一些个体通过不明确、相似、相邻或功能关系形成的块。
自颗粒概念提出以来,GrC被广泛应用于自动控制理论、分类、模糊系统等各个领域,颗粒性能的优化也成为热门话题。日前,公认的信息颗粒评价指标是由Pedrycz提出的两个参数:覆盖率coverage和特殊性specific。覆盖率用于评价信息颗粒读取信息的能力,特殊性则用于评价信息颗粒有效提取知识的能力,其重点是寻找颗粒可以代表的最优信息区域。
当今社会,人工智能已在大众生活中得到广泛应用,作为人工智能的重要分支,机器学习能够基于给定数据对计算机系统或算法进行改进。然而,受机器学习执行原理的影响,基于机器学习所得到的决策结果会产生一定程度的不公平现象。算法公平,指机器学习算法所产生的结果不应存在对基于某个群体的敏感特征产生偏见(好或坏),由该偏见所引起的对特定群体的不公平待遇往往会使该群体的利益受到损害。如亚马逊网站因算法偏见问题对顾客的人种产生偏见导致部分顾客的利益受到损害。如今已有大量的研究者聚焦于提高算法的公平性以减少社会的不公平现象。但在GrC领域中,研究者们仍关注于提升颗粒的表达能力,缺少对颗粒公平性的关注。
发明内容
本发明的目的是为了解决现有技术中的上述缺陷,提出一种基于重采样的数据公平粒化及分类方法,改善信息颗粒公平性能缺失的问题,通过对原始数据集进行概率重采样,执行聚类算法FCM生成粗粒,利用差分进化算法优化质心,引入公平性约束调整颗粒区间,提高了颗粒组间和组外的公平性,同时最大程度维持了颗粒在分类问题上的性能。
本发明的目的可以通过采取如下技术方案达到:
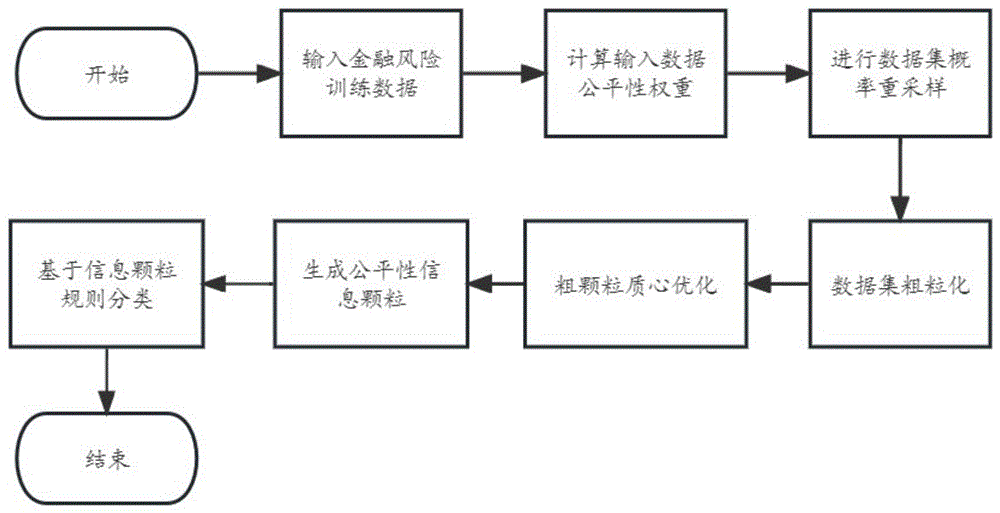
一种基于重采样的数据公平粒化及分类方法,所述数据公平粒化及分类方法包括以下步骤:
S1、输入金融风险训练数据D
S2、计算输入数据集的公平性权重:选定敏感特征fs,计算训练数据X
S3、进行数据集概率重采样:对X
S4、数据集粗粒化:对高公平性输入数据集ND
S5、粗颗粒质心优化:对粗颗粒执行改进质心差分进化算法,以聚类准确率作为优化目标,更新粗颗粒对应质心位置,得到新质心V
S6、生成公平性信息颗粒:对新质心C
S7、基于信息颗粒规则分类:将信息颗粒集合Ω作为分类器的分类规则,构造颗粒区间匹配度公式对同类型金融风险测试数据D
进一步地,所述步骤S1中将训练数据D
进一步地,所述步骤S2中计算输入数据集的公平性权重过程如下:
根据数据集具体值X
其中,k∈{0,1},y∈{0,1},期望概率P
P
期望概率P
观测概率P
其中,N
进一步地,所述步骤S3中进行数据集概率重采样过程如下:
为了对数据集进行公平性处理,调整敏感特征取值对不同标签的平衡性,本步骤将对数据集进行概率重采样。将敏感特征公平性权重w(X|fs=k,label=y)作为重采样过程中数据点的被选择概率,即权重越大的对应条件应在采样中尽可能保留。对X
其中,N
通过寻找最小数据集平衡因子进行迭代,得到高公平性输入数据集ND
进一步地,所述步骤S4中数据集粗粒化的过程如下:
基于高公平性输入数据集ND
进一步地,所述步骤S5中粗颗粒质心优化的过程如下:
改进来自2003年KV Price作者在Springer期刊187-214页发表的文献《Differential evolution》的差分进化算法优化质心V,与原始差分进化算法的不同在于本文所使用的差分进化算法加入了粗颗粒包含数据点的准确率参与目标优化,设置质心的偏移范围在[-1,1],不断随机偏移质心直到达到最优准确率停止迭代,最后更新质心和粗颗粒所包含数据点集合,得到新质心V
进一步地,所述的步骤S6中生成公平性信息颗粒的过程如下:
由于粗颗粒属于无监督聚类得到的结果,因此需要对其进行细粒度公平性优化。输入新质心V
coveage=card(fa∈ψ|fa>left并且fa 其中fa表示属于粗颗粒ψ的数据点,card()表示在粗颗粒ψ覆盖范围区间[left,right]内数据点fa的个数,left表示粗颗粒覆盖范围区间的左边界,right表示粗颗粒覆盖范围区间的右边界; 计算第二个目标优化指标颗粒特殊性specifiv,表示颗粒对数据信息的精确提取能力,由下式计算: specifiv=r 其中e表示指数,β表示特殊性权重因子,当β等于0,specfic=1,特殊性最差,覆盖率最高; 计算第三个目标优化指标颗粒公平值GF,表示颗粒覆盖数据在当前敏感特征取值下是否存在偏见,以及偏见程度高低,由下式计算: 其中,FAG()函数用于计算在当前颗粒区间下,不同敏感特征在label=1的比值,用于衡量同标签内的敏感特征数据公平性,由下式计算: 其中,f为条件函数,P(f|label=1)表示当label=1时,当前粗颗粒覆盖范围区间[left,right]所包含数据点所构成的数据点集合满足函数条件f的概率,P(f)表示当前区间[left,right]所包含数据点所构成的数据集合满足函数条件f的概率,以两者的商作为衡量当前区间所构成的颗粒的公平性,当FAG(f)越接近0.5,表明当前颗粒区间越公平;将敏感特征取值为0和1对应的FAG(f)值进行加和,得到粗颗粒的颗粒公平值GF;由于覆盖率和特殊性的最优值存在矛盾关系,因此需要构造颗粒生成目标函数f f 对粗颗粒的每个特征区间Interval 进一步地,所述步骤S7中基于信息颗粒规则分类过程如下: 为减少对输入数据重复训练,本步骤将最佳公平信息粒作为算法分类规则对测试数据进行分类。输入金融风险测试数据D 其中,[left,rigtht]表示最佳公平信息颗粒Ω所包含数据点的取值范围,通过比较该数据点对不同标签信息颗粒的隶属度,将隶属度最大的信息颗粒对应的标签作为该数据点的分类输出结果,遍历所有金融风险测试数据,输出每个数据点的分类结果。以上分类方法能够基于所得到的最佳公平信息颗粒作为分类规则对相似特征的数据进行分类,减少了对输入数据进行反复训练的过程。 本发明相对于现有技术具有如下的优点及效果: 1、所生成的信息颗粒公平性更高。对于所生成的信息颗粒,由于采用了基于敏感特征的概率重采样方法,数据集本身对于敏感特征数值比例的偏见得到极大改善,同时,在颗粒生成过程中加入了公平性约束调整颗粒大小,相比于其他颗粒生成方法,所生成的颗粒用于分类,回归等应用决策时所产生的偏见也大幅减少,其中,同标签的组内公平性平均提升了46.6%,不同标签的组间公平性平均提升了77.9%,极大减少了由于颗粒算法歧视导致的分类结果偏见。 2、能定义一套同类型数据通用的颗粒规则。通过对同类型金融风险数据中的一部分数据进行训练,能够生成一套统一的判别该类型具有相同特征的金融风险输入数据的分类规则,与其他分类器相比,减少了对于新数据重复训练的计算开销。 附图说明 此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中: 图1是本发明公开的一种基于重采样的数据公平粒化及分类方法的流程图; 图2是本发明实施例中公开的式中基于公平性约束的颗粒生成过程的流程图。 具体实施方式 为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。 实施例1 本实施例公开了一种基于重采样的数据公平粒化及分类方法,具体包括以下步骤: S1、输入金融风险训练数据D S2、计算输入数据集的公平性权重。基于步骤S1所输入的训练数据X 其中,k∈{0,1},y∈{0,1},期望概率P P 期望概率P 观测概率P 其中,N S3、进行数据集概率重采样。利用敏感特征公平性权重集合W,将敏感特征公平性权重w(X|fs=k,label=y)作为重采样过程中数据点的被选择概率,对X 其中,N S4、数据集粗粒化。使用来自1994年2月SL Chiu作者在期刊Journal ofIntelligent and Fuzzy Systems第267-278页发表的文献《Fuzzy model identificationbased on cluster estimation》的模糊聚类算法FCM对高公平性输入数据集ND S5、粗颗粒质心优化。改进使用来自2003年KV Price作者在Springer期刊187-214页发表的文献《Differential evolution》的差分进化算法,对粗颗粒优化质心V,以粗颗粒包含数据点准确率作为优化目标,根据随机生成的候选解进行染色体交叉,更新质心和粗颗粒所包含数据点集合,得到新质心V S6、生成公平性信息颗粒。对步骤S3到S5所得到的质心V S7、基于信息颗粒规则分类。输入测试数据D 本发明与其他算法在评价分类结果的公平性上进行了比较,比较指标包括组内公平性DP,组间公平性EO,其中DP表示所构造的每个颗粒覆盖的数据点在其敏感特征取值不同时在相同颗粒下的平衡度,EO表示所构造的所有颗粒覆盖的数据点在其敏感特征取值不同时在不同颗粒之间的平衡度。DP和EO越小表明颗粒越公平,分类方法准确度指标ACC,ACC表示依据颗粒分类规则所得到的分类结果与实际分类结果是否相符的准确率。ACC越高表明分类效果越好,颗粒单位质量指标Q/S,其中Q表示为最佳目标函数f 表1.本发明公开方法与有方法的相关指标对比结果表(German) 实施例2 本实施例继续公开了一种基于重采样的数据公平粒化及分类方法,具体包括以下步骤: S1、输入金融风险训练数据D S2、计算输入数据集的公平性权重。基于步骤S1所输入的训练数据X 其中,k∈{0,1},y∈{0,1},期望概率P P 期望概率P 观测概率P 其中,N S3、进行数据集概率重采样。用敏感特征公平性权重集合W,将敏感特征公平性权重w(X|fs=k,label=y)作为重采样过程中数据点的被选择概率,对X 其中,N S4、数据集粗粒化。使用来自1994年2月SL Chiu作者在期刊Journal ofIntelligent and Fuzzy Systems第267-278页发表的文献《Fuzzy model identificationbased on cluster estimation》的模糊聚类算法FCM对高公平性输入数据集ND S5、粗颗粒质心优化。改进使用来自2003年KV Price作者在Springer期刊187-214页发表的文献《Differential evolution》的差分进化算法,对粗颗粒优化质心V,以粗颗粒包含数据点准确率作为优化目标,根据随机生成的候选解进行染色体交叉,更新质心和粗颗粒所包含数据点集合,得到新质心V S6、生成公平性信息颗粒。对步骤S3到S5所得到的质心V S7、基于信息颗粒规则分类。输入测试数据D 本发明与其他算法在评价分类结果的公平性上进行了比较,比较指标包括组内公平性DP,组间公平性EO,其中DP表示所构造的每个颗粒覆盖的数据点在其敏感特征取值不同时在相同颗粒下的平衡度,EO表示所构造的所有颗粒覆盖的数据点在其敏感特征取值不同时在不同颗粒之间的平衡度。DP和EO越小表明颗粒越公平,分类方法准确度指标ACC,ACC表示依据颗粒分类规则所得到的分类结果与实际分类结果是否相符的准确率。ACC越高表明分类效果越好,颗粒单位质量指标Q/S,其中Q表示为最佳目标函数f 表2.本发明公开方法与有方法的相关指标对比结果表(Home loan) 目前仍未有研究对颗粒的公平性能进行优化,因此,将发明的方法分别与传统分类算法(KNN,NB,resFCM),基准粒化方法FGC-rule以及普通公平性分类算法AF进行比较。本实施例用3个来自金融贷款领域的数据集(信用放贷,住房贷款,信用卡审批)对以上方法进行测试。测试过程中比较了以上算法所得到的分类结果的公平性指标DP和EO,与粒化算法FGC-rule比较了所生成的颗粒的质量Q。测试结果表明,在以上三个数据集中,本发明的平均DP和平均EO达到最优。在颗粒质量比较中,本发明所生成的颗粒与FGC-rule相比平均提升了38.7%,与AF算法相比,本发明在DP和EO上平均提高了20.87%和40%。在颗粒应用性能损失上,与应用性能表现最好的NB算法相比,本发明ACC性能损失在1%-10%之间,这是可接受的。综上测试,证明本发明的方法是有效的。 综上所述,本实施例提出了一种基于重采样的数据公平粒化及分类方法。该方法的目标是在尽量避免颗粒应用性能损失的前提下提高颗粒的公平性。该方法能有效的提高输入数据集的组间公平性,基于聚类算法并通过差分进化算法减少了颗粒的应用性能损失,最后通过公平性约束提高了生成颗粒的公平性。 上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 层叠体以及使用该层叠体的图像显示装置的前面板、图像显示装置、带图像显示功能的反射镜、电阻膜式触摸面板及静电电容式触摸面板
- 感光性组合物、固化物形成方法、固化物、图像显示装置用面板及图像显示装置
- 一种显示基板的光配向方法、显示基板和液晶显示面板
- 显示基板、包括该显示基板的显示面板和显示设备
- 辅助图像显示装置、辅助图像显示方法和辅助图像显示程序
- 仪表面板图像显示装置、仪表面板图像变更方法、车辆、服务器、仪表面板图像变更系统、仪表面板图像显示程序、存储有仪表面板图像显示程序的计算机可读取的存储介质
- 主机装置、图像显示设备、图像显示系统、图像显示方法、面板属性读出方法以及图像显示控制方法