一种使用检索增强技术强化CTC解码的语音识别方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于语音识别技术领域,更具体地,涉及一种使用检索增强技术强化CTC解码的语音识别方法。
背景技术
近年来,检索增强语言模型通过使用k近邻(kNN)模型线性插值输出词分布来改进预训练语言模型,在自然语言处理(NLP)任务中取得了显著的成功,包括语言模型、问答和机器翻译。kNN语言模型成功的核心是构建高质量的键值数据存储。尽管NLP任务取得了这些进步,但语音任务中的应用,特别是语音识别(ASR),由于构建音频模态的细粒度数据存储相关较为困难,仍然受到限制。有人提出通过加入检索机制来为ASR提供外部文本语料库的信息,增强ASR系统的性能。然而,这种方法仍然属于kNN语言模型的范畴,只是增强了RNN-T(Recurrent neural network transducer)的文本模态。有研究人员采用语音合成技术生成音频,并使用音频嵌入和文本嵌入作为键值对构建数据存储,然后将kNN融合层插入Conformer以增强上下文ASR。然而,这种方法仅限于上下文ASR,并且键值对是粗粒度的,键和值都在短语级别。针对于基于连接时序分类(Connectionist TemporalClassification)解码的语音识别模型,如何构建细粒度帧级别键值数据存储以进一步提升性能,仍然是一个挑战。
发明内容
为了增强基于CTC解码的语音识别系统性能,本发明提出一种基于检索增强的提升CTC解码性能的语音识别方法。给定一个预训练后的CTC解码模型,首先利用数据经过特征编码器得到帧级别向量,然后以帧级别的向量与CTC伪标签形成键值对,构造细粒度键值数据存储。最后,在解码阶段通过检索帧级向量和对应的CTC伪标签得到检索增强预测的概率分布,对CTC解码结果进行线性插值,提升语音识别系统的性能。另外,本发明提出了一种跳过“空”的策略,以减小数据存储,并加速解码。
为实现上述目的,本发明提供了如下技术方案:
一种使用检索增强技术强化CTC解码的语音识别方法,包括以下步骤,
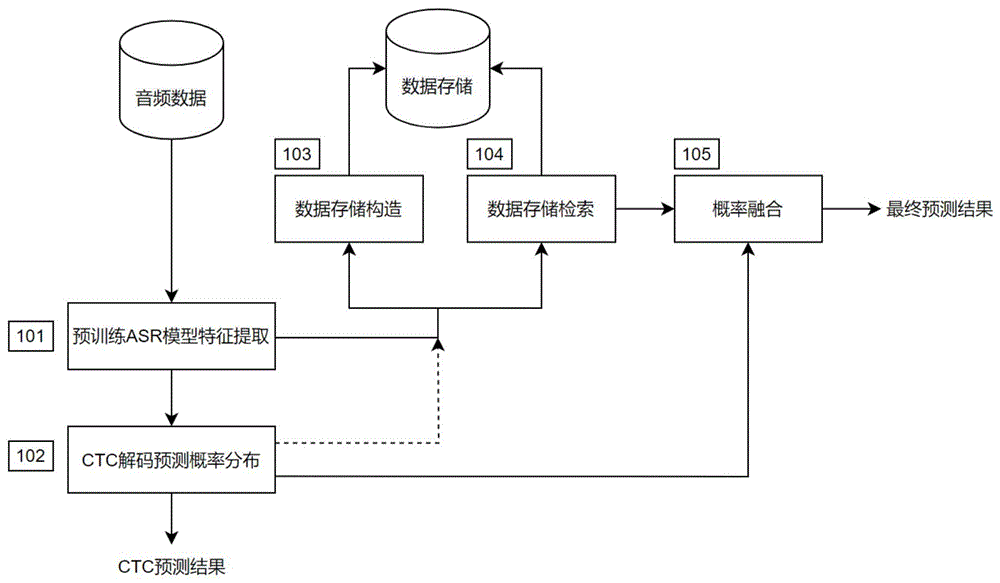
S101、预训练ASR模型特征提取,将音频数据传入该ASR模型特征编码器,提取该数据对应的帧级别中间特征表示;
S102、CTC解码预测概率分布,将步骤S101输出的中间特征表示输入到CTC解码器中,获取CTC解码器预测的帧级别概率分布;
S103、数据存储构造,即使用训练集数据来构建大量的特征向量与标签的键值对,并将其缓存,且在数据存储构建阶段,跳过伪标签为“空”字符的帧;
S104、数据存储检索,即在测试阶段检索最近邻的k个键值对,计算得到数据存储检索概率分布,且在数据存储检索阶段,对于伪标签为“空”的帧,无需进行检索和概率融合,直接以CTC预测的概率分布作为最终结果;
S105、概率融合,利用线性插值将数据存储检索得到的概率分布和预训练ASR模型的CTC解码的概率分布融合,得到最终的概率分布P(y|x):
p(y|x)=λp
其中P
本技术方案进一步的优化,所述步骤S102,根据CTC解码的条件独立假设,利用该分布可以为提取出的每一帧中间特征标记字符伪标签,公式如下:
其中,X
本技术方案进一步的优化,所述步骤S103中使用CTC解码器预测的帧级别伪标签作为value,即值;通过将这一过程扩展到整个训练集,记为S,即可成功构建一个由帧级别键值对组成的数据存储,
其中(K,V)是构造的键值对数据存储,S是整个训练集,f(X
本技术方案进一步的优化,所述步骤104中数据存储检索概率分布P
其中,x为音频,y为预测的文本,N为检索出的最近邻键值对集合,(k
本技术方案进一步的优化,所述ASR模型特征编码器为Transformer编码器或Conformer编码器。
区别于现有技术,上述技术方案有益效果是,应用本发明提出的语音识别方法,无需额外的训练即可进一步提升已完成训练的基于CTC解码的语音识别模型的性能。本发明还提出了一种跳过“空”的策略,以减小数据存储,并加速解码。另外,本发明同样可以用于快速域适应,仅需要构建无标签目标域数据的数据存储,即可提升语音识别系统在目标域上的性能。
附图说明
图1为使用检索增强技术强化CTC解码的语音识别方法的流程示意图。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
如图1所示,为使用检索增强技术强化CTC解码的语音识别方法的流程示意图。该方法具体包括以下步骤。
S101、预训练ASR模型特征提取。给定一个基于CTC(Connectionist TemporalClassification)解码的预训练语音识别(Automatic Speech Recognition,ASR)模型。将音频数据传入该ASR模型特征编码器,如Transformer编码器、Conformer编码器,提取该数据对应的帧级别中间特征表示。
S102、CTC解码预测概率分布。将S101中输出的中间特征表示输入到CTC解码器中,获取CTC解码器预测的帧级别概率分布。根据CTC解码的条件独立假设,利用该分布可以为提取出的每一帧中间特征标记字符伪标签,即字典中的字符如“a”、“b”等,公式如下。
其中,X
S103、数据存储构造。即使用训练集数据以构建大量的特征向量与标签的键值对,并将其缓存。由于音频各帧到转录字符之间缺乏准确的对齐知识,因此为音频模态构建精确的细粒度数据存储较为困难。本发明首先使训练集数据经过步骤S101、S102,提取音频数据X的中间特征表示,记为f(X)。在评估了三个可能的位置之后(包括编码器输出,最后一层前馈网络的输入和输出),本发明使用最后一层编码器层的前馈网络(FFN)的输入作为键(key)。另外,本发明使用CTC解码器预测的帧级别伪标签作为值(value)。通过将这一过程扩展到整个训练集(记为S),即可成功构建一个由帧级别键值对组成的数据存储。
其中(K,V)是构造的键值对数据存储,S是整个训练集,f(X
需要注意的是,在帧级处理音频时,会生成大量的帧级数据。由于CTC解码的尖峰特性,其中大部分帧被赋予为“
S104、数据存储检索。即在测试阶段检索最近邻的k个键值对,计算得到数据存储检索概率分布。首先使测试数据经过步骤S101、S102。接下来利用特征提取器提取的中间特征作为query,即查询。使用KNN(K-Nearest Neighbor)算法,在数据存储中检索k个最近邻键值对。为加速整个检索过程,本发明使用了检索工具如FAISS。进一步使用softmax函数根据检索得到的k个最近邻距离,计算概率分布。最后合并相同值的元素,得到数据存储检索概率分布P
其中,x为音频,y为预测的文本,N为检索出的最近邻键值对集合,(k
此外,在数据存储检索阶段,需要根据CTC解码输出(图中虚线所示)来策略性地跳过与“
S105、概率融合。利用线性插值将数据存储检索得到的概率分布和预训练ASR模型的CTC解码的概率分布融合,得到最终的概率分布P(y|x):
p(y|x)=λp
其中P
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
- 氨法磷酸铁生产废水资源化处理装置及方法
- 一种氨法磷酸铁生产废水资源化利用的装置