基于健康评估的Informer风电功率预测模型的优化方法
文献发布时间:2024-05-31 01:29:11
技术领域
本发明涉及风电功率技术领域,特别是涉及一种基于健康评估的Informer风电功率预测模型的优化方法。
背景技术
风能的波动性,造成风电的间歇性,并网后可能影响电网运行。为了保障电网安全,需要进行风电功率预测,以便及时调控。
早期基于数值天气预报(Numerical Weather Prediction)的预测方法,目前已被神经网络取代。虽然神经网络的预测精度较高,但预测速度慢、结构复杂、后期维护难度大。寻找新的预测模型,成为近年来的研究热点。Informer凭借预测速度快、模型轻量化的特点,可代替传统神经网络,进行功率预测。然而,Informer的预测精度较低,预测速度难以满足实际需求,预测性能不足之处较为明显。
针对Informer预测性能的不足,研究者从多方面进行优化。潘立群,张倩,Gong M
等优化编码流程,强化Informer的序列分析能力,提升预测精度;赵懂宇,冯霞,Yang Z
等引进对抗机制,增强Informer的抗干扰能力,提升预测精度;余琼芳,梁英杰,Zhu Q等改进采样方法,提高Informer的多元采样能力,提升预测速度。目前,大部分优化方法,不能同时提升Informer的预测精度和速度,优化效果不理想,且增加了Informer复杂度,影响其实际应用。
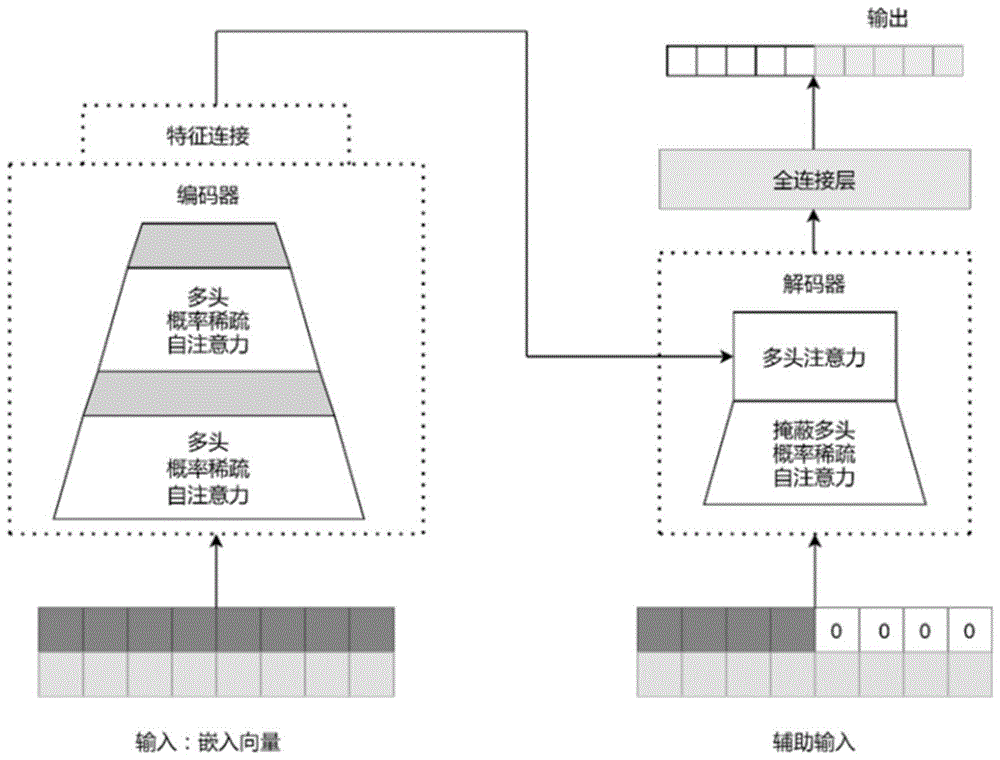
Informer是一种基于概率稀疏自注意力的预测模型,由Zhou Haoyi等人于2021年提出。和传统神经网络不同,Informer采用了Encoder-Decoder分离的结构。预测过程中,编码输出送入解码器处理,得到解码输出,并通过全连接层,输出预测结果。
Informer预测流程如图1所示。在Informer中,存在3个要点:
(1)自注意蒸馏操作(Self-attention Distilling Operation):Encoder模块中,每个编码层的深度递减,输出长度随之递减,从而提取特征,并在模块结尾,将所有特征进行连接,作为Decoder模块的输入。
(2)生成式解码器(Generative Style Decoder):Decoder模块中,使用了一种新的生成式解码器,只需要一个前向推导过程,便可获得指定长度的预测结果,有效避免了累积误差的扩散。
(3)概率稀疏自注意机制(ProbSparse Self-attention Mechanism):基于高得分点积对贡献主要关注的结论,Informer对强相关特征进行额外关注,在自注意过程中,仅计算强相关特征部分,降低预测成本。
现有的Informer预测模型,保证一定精度和速度的同时,仍存在下列不足:
1、计算频繁:Encoder模块中,为了提升强相关特征的关注度,需要频繁进行自注意力计算,降低了预测速度;
2、解码缺陷:Decoder模块中,使用了序列占位符,进行辅助预测,且占位符和特征数据具有相同的权重。权重分配的不合理,导致预测精度下降。
3、计算复杂:Informer需要引进额外模块,或提升特征维度,从而完成自注意机制,增加了计算复杂度,减小了模型轻量化的优势。
健康评估是一种权重优化算法,由Lars Landberg于2011年提出。它依据模型输出统计学概率分布的特点,将二维的概率密度函数,转化为权重健康矩阵。
健康评估的流程如图2所示,具体为:
(1)数据采集:通过传感器和SCADA系统,采集风速、温度、压力、转速、功率等风机数据;
(2)数据清洗:针对数据中的缺失值、异常值、传输噪声,进行清洗工作,提高数据可靠性;
(3)特征筛选:从清洗后的数据中,筛选出特征数据,并基于特征数据的维度,得到健康矩阵的维度;
(4)状态分类:使用特征数据,计算特征权重,并根据权重数值高低,划分正常、轻微故障、严重故障等风机状态;
特征权重的计算如下:
式中,i是特征编号,从1到n,μ是均值向量,Σ是协方差矩阵。
(5)矩阵生成:将相同状态的特征权重,排列成健康矩阵。每个矩阵元素,代表该状态下,对应特征的权重系数。
将式(1)的特征权重,按照顺序排列,得到权重矩阵Q
对特征数据使用因子分析法,得到相关矩阵R
A
式中,n是健康矩阵维度,常取6-12。n大于12时,需要降维。
健康评估的原理如下:
假设预测模型的初始输入z
在预测模型中,第i层输入z
D
将z
式(4)中,A降低了D
因不同模型的预测流程不同,z和D对预测的影响也不同,优化后,可能提升模型的预测精度或速度。
现有健康评估算法,存在两点缺陷:
1、处理成本高:筛选特征时,需要多维度的风机数据,提高了数据采集,处理和分析的成本;
2、复杂度高:为提高评估可靠性,引入复杂的特征选取模块,增加了评估复杂度。
发明内容
针对上述要解决的技术问题,本发明提供一种基于健康评估的Informer风电功率预测模型的优化方法,实时监控,降低救援风险,缩短救援时间,提高救援成功率,确保救援工作有序进行。
为解决上述技术问题,本发明提出的技术方案为:
一种基于健康评估的Informer风电功率预测模型的优化方法,所述优化方法至少包括以下内容中的两种结合:
1)编码器优化:提升第i层的输入x
2)解码器优化:提升第L层的输入c
3)嵌入向量优化:提升模块的初始输入x
4)预测过程优化:根据模块的初始输入x
作为上述技术方案的进一步改进为:
优选地,所述编码器优化,具体为:
假设Encoder模块由多个编码层和卷积层组成,第i层的输入为x
式(5)中,Conv表示卷积层的卷积计算;Attention表示概率稀疏自注意力函数,
式(6)中,softmax表示归一化函数;
提升x
式(7)中以
优选地,所述解码器优化,具体为:
假设Decoder模块由L个解码层构成,每个解码层中,输入c
c
式中,Decoder
提升c
c
式中,h为健康因子,由健康矩阵A
优选地,所述嵌入向量优化,具体为:
Encoder模块的初始输入x
式中,x
优选地,所述预测过程优化,具体为:
嵌入向量x
健康评估对c
其中,
本发明提供的基于健康评估的Informer风电功率预测模型的优化方法,与现有技术相比,有以下优点:
(1)本发明的基于健康评估的Informer风电功率预测模型的优化方法,采用健康评估,优化Informer模型,提升预测精度和速度,首先,基于运行数据,进行健康评估,得到风机健康矩阵;然后,通过健康矩阵,优化编码方式,提升Informer的预测速度;接着,使用健康矩阵,改进解码方式、嵌入向量和预测流程,提高Informer的预测精度。
(2)本发明的基于健康评估的Informer风电功率预测模型的优化方法,基于健康评估而设计的Informer优化模型,可加速Informer收敛,提升模型的预测精度和速度。Encoder结合优化后的Informer模型,是优质的风电功率预测模型。与未优化模型比较,基于健康评估的Informer优化模型,进行风电功率预测时,数据成本更小,优化效果更好。
附图说明
图1为现有技术中Informer预测流程图。
图2为现有技术中健康评估流程图。
图3为本发明应用实施时嵌入向量结构图。
图4为本发明应用实施时优化前后
图5为本发明验证时K-C 5号机组预测效果图。
图6为本发明验证时K-C 33号机组预测效果图。
图7为本发明验证时龙源1号机组预测效果图。
图8为本发明验证时龙源12号机组预测效果图。
图9为本发明验证时5th 1-36号机组预测效果图。
图10为本发明验证时5th 2-30号机组预测效果图。
图11为本发明验证时GEFC 5号机组预测效果图。
图12为本发明验证时GEFC 6号机组预测效果图。
具体实施方式
以下对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
如图1至图4所示,本发明的基于健康评估的Informer风电功率预测模型的优化方法,包括以下内容:
1)编码器优化
假设Encoder模块由多个编码层和卷积层组成,第i层的输入为x
式(5)中,Conv表示卷积层的卷积计算;Attention表示概率稀疏自注意力函数,即
式(6)中,softmax表示归一化函数;
在x
式(7)中以
Encoder模块的优化效果论证:
式(6)中,矩阵
式中,q
p(k
式(6)和式(8)中,使用了稀疏度量为M(q
式中,L
在稀疏自注意力中,查询和键的长度相等,即L
由式(3)和式(4)得知,在式(7)中,优化后的
2)解码器优化
假设Decoder模块由L个解码层构成,每个解码层中,输入c
c
式中,Decoder
由于c
c
式中,h为健康因子,由健康矩阵A
由于提升了Decoder模块的解码精度,优化后,Informer的预测精度上升。
Decoder模块的优化效果论证:
Decoder模块的第1层输入可表示为
式中,
虽然掩蔽多头注意力的应用,防止了
采用式(11)的优化方案,等价于提高
3)嵌入向量优化
嵌入向量是指Encoder模块的初始输入x
式中,x
因嵌入向量中,强相关特征的权重提升,优化后,Informer的预测精度提高。
嵌入向量模块的优化效果论证:
假设第t个序列输入为X
式中,j∈{1,…,[d
式中,i∈{1,…,L
嵌入向量结构如图3所示。因三角函数sin,cos自带采样权重,式(14)和式(15)得到的
式(13)结合了特征分布的偏差,对嵌入向量进行优化。由式(3)和式(4)可知,优化后,由特征分布变化引起的系统误差,在后续的编码-解码过程中会逐渐减小,从而提升Informer的预测精度。
4)预测过程优化
由图2和式(3)-式(12)得知,嵌入向量x
且健康评估改为对c
其中,
因结合了特征分布的变化,优化后,Informer的预测精度上升。
预测过程的优化效果论证:
假设x
1≤e≤g 由式(3)至式(16)可知,预测过程中,不涉及强相关特征的数量增减,因此,存在下列约束条件: f-e=h-g=k,k为正整数(20) 对于嵌入向量x D 类似地,对于解码输出c 和/> 由式(16)和图3得知,x 采用式(17)和式(18)的优化方案,可以针对 k=2时,优化前后的 5)组合优化 因为Encoder模块的优化,以速度提升为主,Decoder模块、嵌入向量和预测过程的优化,以精度提升为主。为了避免过度优化,本发明选择了Encoder-Decoder,Encoder-嵌入向量,Encoder-预测过程,共3种结合优化模型,进行训练、测试。 优化验证: 1)误差指标设置 采用R 式中,y 若优化有效,理想情况下,R 2)仿真测试 本次验证方法使用了百度KDD CUP 2022数据集、“中国软件杯”——龙源风电赛道数据集,第五届全国工业互联网数据创新应用大赛的数据集,和Global EnergyForecasting Competition 2014的Task15数据集等四个数据集。每个数据集,具有17000-21000条数据。选择未优化、Encoder优化、Decoder优化,Encoder-Decoder优化、嵌入向量优化、预测过程优化、Encoder-嵌入向量优化、Encoder-预测过程优化,共8套模型进行仿真测试。每套模型,分别进行3轮训练和6轮训练的仿真测试。数据集的前80%作为训练集,剩余20%为测试集。 为了减少量纲差异的影响,对所有预测结果进行标准化,如下所示: 式中,z Informer模型的组件细节见表1。 表1Informer模型组件细节 采用KDD CUP数据集的预测效果如图5和图6所示。采用龙源风电数据集的预测效果如图7和图8所示。采用第五届大赛数据集的预测效果如图9和图10所示。采用GEFC 2014数据集的预测效果如图11和图12所示。 各数据集的预测结果对比见表2至表9。 表2KDD CUP 5号机组预测指标 /> 表3KDD CUP 33号机组预测指标 表4龙源风电1号机组预测指标 /> 表5龙源风电12号机组预测指标 表6 5th 1号风场36号机组预测指标 表7 5th 2号风场30号机组预测指标 /> 表8GEFC 5号机组预测指标 表9GEFC 6号机组预测指标 /> 图5-图12中,V1代表未优化的预测效果、V2代表Encoder优化的预测效果、V3代表Decoder优化的预测效果、V4代表Encoder-Decoder结合优化的预测效果、V5代表嵌入向量优化的预测效果、V6代表预测过程优化的预测效果、V7代表Encoder-预测过程结合优化的预测效果、V8代表Encoder-嵌入向量结合优化的预测效果。所有预测效果图,均在6轮训练下绘制。 由图5-图12知,除Encoder独立优化外,其余的优化模型,与未优化模型相比,预测精度均有所上升。由表2至表9可知,所提出的7种优化模型,实现了预测精度提升15%,或是预测速度提升100%中,至少一种的优化效果。并且,3种Encoder结合优化模型,均同时实现了预测精度提升15%,预测速度提升100%的优化效果。此外,所选的结合优化模型,只需要一半的训练轮数,其预测精度就已接近,或是超过未优化的模型。这说明基于健康评估进行的Informer优化,是合理且有效的。Encoder结合优化的Informer模型,是优质的风电功率预测模型。 上述实施案例只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 基于SDAE-SVR-BA的风电功率深度学习预测模型优化方法
- 风电功率预测模型的训练方法、风电功率预测方法及设备