一种测试用例优化的softAPFD评价方法
文献发布时间:2024-05-31 01:29:11
技术领域
本发明涉及软件可靠性测试技术领域,具体为一种测试用例优化的softAPFD评价方法。
背景技术
随着现代软件复杂程度的不断提高,软件测试成为保障软件质量的重要工作内容。在当前软件开发中,普遍采用持续集成的技术。即鼓励程序员频繁提交最新的代码,以保证项目的开发库内容为最新。持续集成技术可以有效降低版本集成的代价,避免多人多团队协作时出现版本混乱。为了保证上传代码的质量,任意新的提交都需要经过测试,包括对更新代码本身的测试和系统集成测试。
如此一来,随着新提交代码的积累,将形成大量的测试用例代码。如果测试用例过多,那么对测试用例的执行效率又提出了更高要求。事实上,在现实中常常会出现大量的测试用例累积,以至于在有限时间内无法执行所有测试用例的情况。有研究表明,软件测试复杂度的增加速度会更快于软件本身复杂度的增加速度。这意味着软件项目持续进行,其测试工作复杂到难以完整执行,将是必然的结果。因此,必须对测试用例进行优化。
在此背景下,测试用例的优先级排序(Test Case Prioritization,TCP)是测试用例优化的重要内容,其主要思想是分析给出待执行的测试用例的顺序,以使先执行的测试用例尽量找出更多的软件bug。换句话说,TCP旨在调整测试用例的执行顺序,使软件问题及早被发现。传统的TCP技术通常依赖于多种特征提取,包括覆盖率信息分析、基于需求分析、基于测试执行历史的启发式方法以及特定于领域的启发式规则等。
伴随着机器学习技术的兴起,以数据为驱动、基于神经网络自适应学习方式的测试用例优化技术是当前主流,成为了当前测试用例优化研究的主要方式。在这种模式下,神经网络被用于建立一个预测器,其输入是某测试用例执行历史的统计特征信息,而其输出是该测试用例的优先级指标。模型输入通常是高维矢量,而输出是标量。因此模型的输出,即该测试用例的优先级,可以用于排序算法排序。我们希望,按照该排序结果执行测试用例,能够及早的检测出软件中的全部错误。为评价该顺序是否得当,目前国际上普遍采用的评价指标是APFD(Average Percentage of Faults Detected平均故障检测百分比)。
在此给出APFD指标的定义。令T为包含n个测试用例的测试集T={T
尽管评价测试用例优先级排序有APFD这样的标准指标,但是由于其不可求导,无法计算微分,继而不能用于基于梯度的模型优化算法(例如随机梯度下降、牛顿法等)。因此在当前的研究当中,普遍使用代理损失函数(Surrogate loss function)的方式,即另外设计一个损失函数用于优化模型参数以提升其APFD指标。这些代理损失函数包括以下三类。
第1种方法是基于单个样本点的方法(Point wise)。其将每一个数据点预测的优先级与数据集中给出的优先级真值进行欧式距离的比较,并使这个距离在统计意义上最小。因此第1种方式本质上就是一个回归模型。
第2种方法是基于样本对(Pair wise)相对差异的方法。其思想借鉴了ranknet排序的方法,即分别预测两个样本的优先级,再将其优先级差异输入给逻辑斯提克函数(Logistic function),最后将函数输出作为测试用例前者相对于后者优先的概率。由于两个测试用例属于数据集,其优先级顺序已知,因此可以使用negative log likelihood(NLL)来优化。第2种方法本质上就是样本对的相对分类问题。由于其训练时,只需要知道优先级真值的顺序,而无需知道优先级真值的具体量,因此第2种方法比第1种方法更容易实现和训练。
第3种方法是在第2种方法的基础上,将模型训练的过程扩大个批量数据,从而使其变为基于列表(List wise)的方式。由于第3种方法一次训练动用的数据更多,因此能够获取到更加均衡有效的模型优化趋势,提升数据使用效率。但是以上方法也仍然存在较明显的问题。即,以上损失函数皆为代理损失函数,并不能直接优化APFD本身。因此其优化结果并不能总是确保对APFD指标的提升。另外,第1种方法需要优先级真值,而事实上数据集的优先级真值也是人为给定,其准确性并非毫无差错。
发明内容
针对上述问题,本发明的目的在于提供一种测试用例优化的softAPFD评价方法,改进了APFD的计算方法,使其能够适应梯度计算,继而使其能够应用于当前主流的神经网络框架,能够使用计算图机制自动完成梯度推导。技术方案如下:
一种测试用例优化的softAPFD评价方法,包括以下步骤:
步骤1:根据测试用例的优先级真值,通过神经网络模型,预测得到测试用例优先级的预测值,用softmax函数将各个测试用例优先级的预测值,转化为其检测软件错误的占比,以此计算得到softAPFD损失函数;
步骤2:对应用softAPFD损失函数的测试用例优先级预测模型进行训练;
步骤3:根据训练好的测试用例优先级预测模型的参数,进行待测测试用例优先级的预测,根据预测到的优先级在已有序列中排序。
进一步的,所述步骤1中计算softAPFD损失函数具体为:
步骤1.1:从数据集中获取n个样本
步骤1.2:根据该n个样本的优先级真值,采用快速排序算法对其排序,获取排序后列表元素与未排序时元素序号的对应关系γ=argsort([s
其中,
步骤1.3:将该n个样本的特征向量x
步骤1.4:将优先级预测向量[η
步骤1.5:将优先级预测排序向量η带入softmax函数,得到归一化向量
步骤1.6:将优先级预测值的归一化值
其中,
更进一步的,所述步骤2中,模型训练过程如下:
步骤2.1:读取数据集
步骤2.2:设置:训练次数n
步骤2.3:从数据集
步骤2.4:针对样本集D,计算softAPFD指标;
步骤2.5:计算损失值L=1-softAPFD;
步骤2.6:计算损失值L对各个变量的梯度,用梯度下降法更新模型参数;
步骤2.7:训练次数递增n
步骤2.8:若前次指标softAPFD
步骤2.9:若新指标与前次指标的差异大于设定阈值∈,即|softAPFD
步骤2.10:若训练次数超过最大训练次数,即n
步骤2.11:新前次指标softAPFD
步骤2.12:保存网络模型参数;
步骤2.13:结束。
更进一步的,所述步骤3具体过程如下:
步骤3.1:载入测试用例优先级预测模型,读取模型的权重参数,将其载入模型的权重;
步骤3.2:读取一个待预测测试用例;
步骤3.3:将所述待预测测试用例的统计特征输入给所述测试用例优先级预测模型,并进行前馈计算;
步骤3.4:读取模型的输出及为所述待预测测试用例的优先级;
步骤3.5:若测试用语已经读取完毕,则退出,否则读取下一个。
本发明的有益效果是:
1)本发明优化结果可直接提升APFD的指标,而不是通过代理损失函数间接地进行提升;因此,相比于原有的代理损失函数,本损失函数可更有效的提升模型性能;
2)本发明改进了APFD的计算方法,使其能够适应梯度计算,继而使其能够应用于当前主流的神经网络框架,能够使用计算图机制自动完成梯度推导;
3)本发明损失函数可适配于任意尺寸和长度的有序集合;且运算简单,且易于实现,具有极高的计算效率。
附图说明
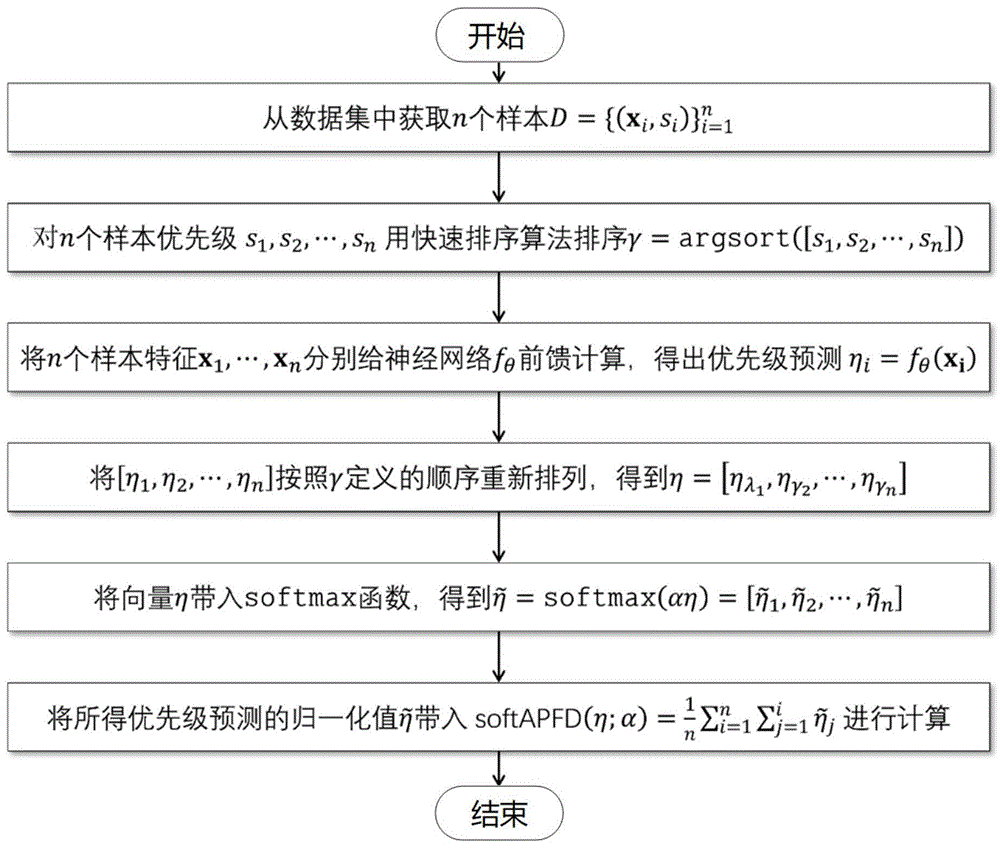
图1为测试用例优先级排序的处理流程示意图。
图2为测试用例优先级排序模型的训练过程流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细说明。
本发明提出一种基于APFD指标改造的近似损失函数,称为softAPFD,其设计思想是:首先应该认识到APFD是测试用例执行过程与缺陷检出率的关系曲线之下的面积,因此只要能近似计算该面积,即可近似APFD指标。其次,某测试用例的优先级量值,与该测试用例即将检测到的软件错误占比呈现正相关关系,即该测试用例检测到的软件错误数量与总错误数量的比例。因此,可用softmax函数将各个测试用例优先级的预测值,转化为其检测软件错误的占比。而该占比已是归一化的结果,所以可直接用于估计APFD。最后,因为某测试用例的优先级是神经网络模型的预测值,因此对此预测结果的改进,随即完成了对模型参数的优化。顺便说明一下,本损失函数的名称softAPFD,即源自本方法涉及的softmax函数和APFD指标两者名称的结合。
步骤1:计算softAPFD损失函数。
softAPFD损失函数的计算过程如图1所示,具体包含以下几个步骤:
步骤1.1:从数据集中获取n个样本
步骤1.2:根据这n个样本的优先级真值,采用快速排序算法对其排序,获取排序后列表元素与未排序时元素序号的对应关系γ=argsort([s
步骤1.3:将n个样本的特征向量x
步骤1.4:将[η
步骤1.5:将向量η带入softmax函数,得到
步骤1.6:将前面步骤所得到的优先级预测值的归一化值
步骤2:在实现softAPFD的计算能力之后,可以将其纳入数据驱动的测试用例优先级预测模型训练。本损失函数可以适配于任何监督学习模型。
为方便描述,本发明中以神经网络模型为例。但不对神经网络模型的深度、宽度等指标做任何具体限制。其原因正是因为,本发明方法是一种普遍使用的技术方法,不需要限制为适配某具体模型。
应用softAPFD的测试用例优先级预测模型训练过程如图2所示,具体过程如下:
步骤2.1:读取数据集
步骤2.2:设置:训练次数n
步骤2.3:从数据集
步骤2.4:针对样本集D,根据步骤1所述方法计算softAPFD指标;
步骤2.5:计算损失值L=1-softAPFD;其中softAPFD指标越大越好,因此取其负加1作为损失值;
步骤2.6:计算损失值L对各个变量的梯度,用梯度下降法更新模型参数;
步骤2.7:训练次数递增n
步骤2.8:若前次指标softAPFD
步骤2.9:若新指标与前次指标的差异大于设定阈值∈,即|softAPFD
步骤2.10:若训练次数超过最大训练次数,即n
步骤2.11:新前次指标softAPFD
步骤2.12:保存网络模型参数;
步骤2.13:结束。
步骤3:在使用训练好测试用例优先级预测模型的参数之后,可以将其应用于预测新测试用例的优先级,以及根据该优先级在已有序列中排序。
其步骤如下:
步骤3.1:载入模型,读取模型的权重参数,将其载入模型的权重。
步骤3.2:读取一个测试用例;
步骤3.3:将该测试用例的统计特征输入给该模型;
步骤3.4:模型进行前馈计算;
步骤3.5:读取模型的输出及为该测试用例的优先级;
步骤3.6:若测试用语已经读取完毕,则退出,否则读取下;
步骤3.7:结束。
本发明的基本思想如下:面向工业软件开发过程积累大量测试用例亟待有先后的执行的需求,应用于工业软件测试用例验证,主要由计算机自动化处理功能组成。测试软件通过读取核计算仿真模块的计算拓扑图和通过KCG转换所得C代码,再将C代码转入定时循环仿真执行环境,进行以下处理步骤:
步骤a:将待测试模块及其包含模块对应的Luster-C代码编译为动态链接库(dll)文件,其中调用接口预先已知。编译器可用但不限于GCC或clang等。
步骤b:在配置文件中设定定时循环仿真的总循环次数。
步骤c:启用预先编制的定时循环仿真程序,其中包含一个定时启动的循环,在循环内将自动调用前文所述的动态链接库(dll)文件中的接口函数。
步骤d:定时循环仿真程序包含有前文所述的软件异常测试功能模块。在每一次循环中,仿真程序将当前“系统状态”和“系统输出”发送给软件异常测试功能模块,后者处理后反馈待测试软件模块的“系统输入”。该系统输入经由定时循环仿真程序传输给动态链接库(dll)文件中的接口函数。如此测试不断循环往复,直至完成中循环次数。
步骤e:预先编制的定时循环仿真程序将软件异常测试功能模块汇总生成的测试报告输出。
步骤f:测试过程结束。
- 一种回归测试用例集的优化方法和自动优化装置
- 一种回归测试用例集的优化方法和自动优化装置