基于编码转写增强词嵌入迁移的老-中神经机器翻译方法
文献发布时间:2024-07-23 01:35:21
技术领域
本发明涉及基于编码转写增强词嵌入迁移的老-中神经机器翻译方法,属于自然语言处理技术领域。
背景技术
神经机器翻译是机器翻译领域的主导框架。现有基于数据驱动的神经机器翻译模型在资源较为丰富的中-英、泰-英等翻译任务上已经取得了良好的性能,但在老挝语这类低资源语言上效果不佳。迁移学习从富资源语言模型中迁移知识到低资源语言模型,是提升低资源神经机器翻译的有效方法。
迁移学习中的词嵌入迁移主要通过提高父子语言间的词表对齐来提升模型迁移效果。然而现有迁移学习方法在泰语到老挝语迁移学习上表现不佳,主要问题在于泰语和老挝语的书写体系不同,难以建立准确的迁移词表映射。泰语和老挝语同属于汉藏语系壮傣语支,具有很大的相似性,其相似性主要体现在发音上。罗马化是一种常见编码转写方法,指将不是罗马字母(或称拉丁字母)形式的拼音文字系统转换成拉丁文字系统的过程。通过罗马化这类编码转写方式可以将泰语和老挝语转化为同一种编码表示,提高泰语和老挝语的文本相似度,可以有效提高泰语和老挝语的词表对齐。现有罗马化方法通常针对单一语言设计,在跨语言联合编码转写上缺少一致性。针对以上问题,本发明提出了基于编码转写增强词嵌入迁移的老-中神经机器翻译方法。
发明内容
为了解决上述问题,本发明提供了基于编码转写增强词嵌入迁移的老-中神经机器翻译方法,以提升老挝到中文的翻译性能。
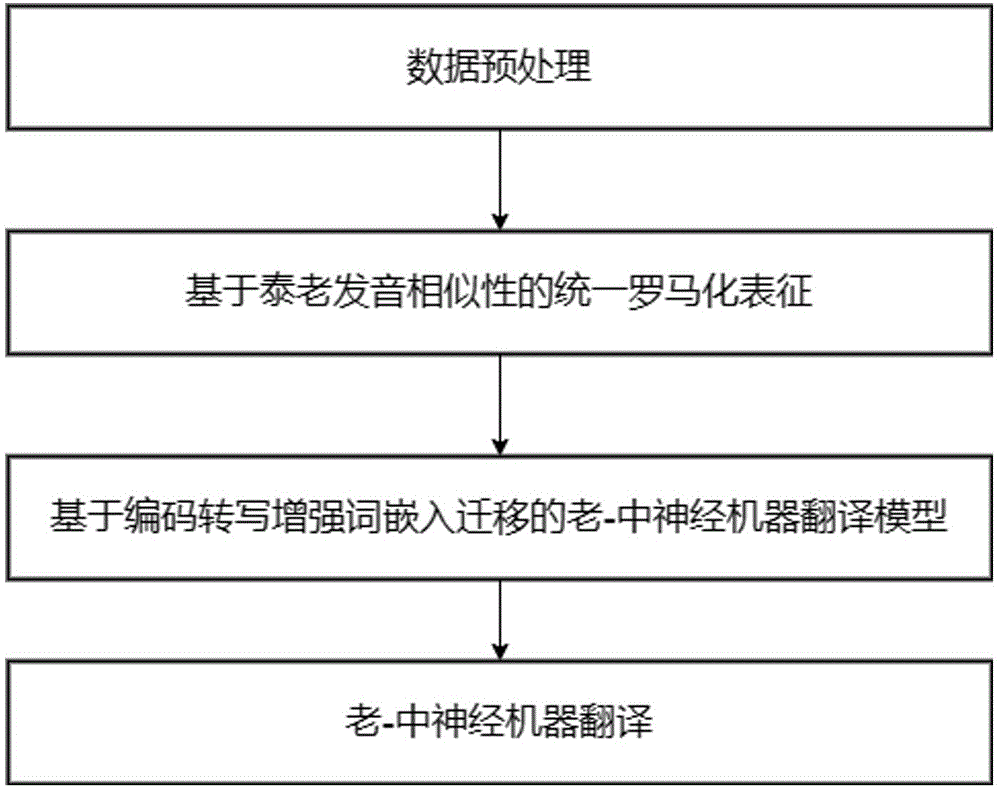
本发明的技术方案是:基于编码转写增强词嵌入迁移的老-中神经机器翻译方法,所述方法的具体步骤如下:
Step1、进行文本数据预处理:本发明需要使用泰语-中文、老挝语-中文平行双语语料和泰语-老挝语双语词典,构建基于罗马化转写迁移的老挝语-中文机器翻译模型,但目前双语平行语料稀缺且缺乏泰语-老挝语双语词典。本发明通过语法特点计算句子相似度和人工筛选的方式对互联网上获取的伪平行语料进行清洗,构建泰语-中文和老挝语-中文双语平行语料。并利用泰语和老挝语的发音相似性构建泰语和老挝语的双语词典;
Step2、基于泰老发音相似性的统一罗马化表征:针对泰语、老挝语书写表示不一致,现有泰语、老挝语罗马化工具跨语言表示一致性不高的问题,本发明利用泰语、老挝语之间的发音相似性和当前的罗马化转写标准,修改罗马化转写规则,根据新的罗马化转写规则对泰语和老挝语进行罗马化转写得到泰语和老挝语的统一罗马化表征;优化模型迁移效果;
Step3、构建基于编码转写增强词嵌入迁移的老-中神经机器翻译模型:针对泰语、老挝语书写体系不一致难以有效构建词表对应关系的问题,使用基于泰老发音相似性的统一罗马化表征对泰语和老挝语进行统一表示;对转化后的泰语和老挝语词表构建映射关系,提高泰语-中文翻译模型到老挝语-中文翻译模型的迁移效果。使用老挝语-中文平行语料对迁移后的老-中神经翻译模型进行微调,并将训练好的模型进行保存,部署到服务器上,实现老挝语文本翻译为中文。
作为本发明的优选方案,所述Step1的具体步骤为:
Step1.1、首先从OPUS和亚洲语言树库上获取了泰语-中文、老挝语-中文和泰语-老挝语平行语料,从泰语-中文双语网站获取泰语-中文可比语料;通过网页标签清除、正则匹配和长度筛查等方式对可比语料进行清洗,然后利用发音相似性,对句子进行相似度计算,筛选出具有较高匹配度的泰语-中文、老挝语-中文伪平行语料,在此基础上进行人工标注得到泰语-中文、老挝语-中文平行语料作为实验数据集,并划分训练集、验证集和测试集;OPUS是一个由多个欧洲语言组成的平行语料库,是一个公知的平行语料库,旨在为机器翻译研究者提供多语言的数据资源;
Step1.2、构建泰语-老挝语双语词典。利用泰语、老挝语分词工具对Step1.1中的泰语-老挝语平行语料进行分词处理,然后使用泰语、老挝语音标转写工具对分词后的语料进行发音转写。根据泰语、老挝语的发音相似性对音标转写后的语料进行相似度计算并结合人工标注的方式构建泰语-老挝语双语词典。
作为本发明的优选方案,所述Step2的具体步骤为:
Step2.1、针对现有泰语、老挝语罗马化工具文本转写后相似度不高的问题,如表1:中文的“万象”对应泰语和老挝语如第2列所示,对它们进行罗马化转写后分别为/weiiyngchantn/和/wyngcan/,可以发现转化后的文本存在较大差异。使用泰语分词工具和老挝语分词工具分别对泰语-老挝语平行语料中的泰语、老挝语进行分词,利用泰语-老挝语双语词典对分词后的平行语料构建互译词对,如:构建互译词对泰语-老挝语分别如第3列所示;
表1
Step2.2、对Step2.1中罗马化后的互译词对进行差异分析,运用现有的罗马化工具对互译词进行初步罗马化转写,筛选出互译词中对应位置罗马化表示不同的字符,并将其对应的原始字符构成差异字符对。如表2,对互译词对如泰语词和老挝语词第1列,进行初步罗马化转写,结果如第2列,构建的差异字符对为第3列。对差异字符对中字符对的种类及出现频率进行统计;
表2
Step2.3、差异字符对分析、修改罗马化转写规则:使用泰老发音词表对Step2.2中的差异字符对进行分析,对其中具有发音相似性的字符对,使用其共同音标作为罗马化转写字符。如表3所示:差异字符对,如表3第1列,现有转写规则为第2列,其对应发音为第3列,统一其罗马化转写规则为第4列。对剩余字符对中出现频率高的字符对,即出现频率在字符对总数一半以上的字符对,比较罗马化转写后字符对的长度,选取罗马化转写后字符对中转写字符少的一方作为字符对统一罗马化表征。如表4:差异字符对如表4第1列,差异字符对的现有转写规则为表4第2列,选取罗马化转写后字符对中转写字符少的“a”作为字符对统一罗马化表征,新的罗马化转写规则(统一罗马化转写规则)即为表4第3列,根据新的罗马化转写规则对泰语和老挝语进行罗马化转写得到泰语和老挝语的统一罗马化表征。
表3
表4
作为本发明的优选方案,所述Step3的具体步骤为:
Step3.1、编码转写:使用Step2中获取的基于泰老发音相似性的统一罗马化表征对泰语-中文和老挝语-中文平行语料中的泰语和老挝语语料进行罗马化转写,得到转写后的泰语-中文和老挝语-中文平行语料;
Step3.2、预训练泰-中神经机器翻译模型:使用Step3.1中罗马化转写后的泰语-中文平行语料训练泰-中神经机器翻译模型;
Step3.3、词表对齐:将Step3.2中训练好的泰-中神经机器翻译模型中的泰语词嵌入词表与罗马化后的老挝语词表进行对齐,使得罗马化后具有相同表示的泰语和老挝语字符的词嵌入对齐,用于提升词嵌入迁移效果;
Step3.4、模型迁移微调:将训练好的泰-中神经机器翻译模型迁移到老-中神经机器翻译模型,使用Step3.1中罗马化的老挝语-中文平行语料对迁移后的老-中神经机器翻译模型进行微调。
Step3.5、将Step3.4训练出的“.pt”格式模型部署到服务器端上,实现通过Web多用户并发请求的功能。将需要翻译的老挝语文本输入Web端并通过API传输到服务器,调用老-中神经机器翻译模型,将老挝语翻译为中文。
本发明的有益效果是:
1、本发明为了使罗马化后的泰语和老挝语文本具有更好的一致性表示,在现有的泰语和老挝语罗马化转写方法上,利用泰语、老挝语的发音相似性对现有罗马化转写规则进行改进;
2、本发明解决的现有方法运用于泰语到老挝语的迁移学习时难以构建准确词表映射问题,以及泰语和老挝语的书写体系不一致的问题;本发明有效提升了老挝语到中文的翻译效果;
3、本发明基于编码转写增强词嵌入迁移的老-中神经机器翻译方法,利用泰语和老挝语的发音相似性构建统一罗马化转写规则,使得罗马化后的泰语和老挝语文本具有高度一致性,并利用这种一致性表示提高泰语和老挝语的词表对齐度,增强泰语到老挝语的模型迁移效果,进而提升老挝语的神经机器翻译模型性能。
附图说明
图1为本发明中基于泰老发音相似性的统一罗马化表征流程图;
图2为本发明中基于编码转写增强词嵌入迁移的老-中神经机器翻译方法网络构架图;
图3为本发明中基于编码转写增强词嵌入迁移的老-中神经机器翻译方法整体流程图。
具体实施方式
实施例1:如图1-图3所示,基于编码转写增强词嵌入迁移的老-中神经机器翻译方法,所述方法的具体步骤如下:
Step1、进行文本数据预处理:本发明需要使用泰语-中文、老挝语-中文平行双语语料和泰语-老挝语双语词典,构建基于罗马化转写迁移的老挝语-中文机器翻译模型,但目前双语平行语料稀缺且缺乏泰语-老挝语双语词典。本发明通过语法特点计算句子相似度和人工筛选的方式对互联网上获取的伪平行语料进行清洗,构建泰语-中文和老挝语-中文双语平行语料。并利用泰语和老挝语的发音相似性构建泰语和老挝语的双语词典;所述Step1的具体步骤为:
Step1.1、首先从OPUS和亚洲语言树库上获取了泰语-中文、老挝语-中文和泰语-老挝语平行语料,从泰语-中文双语网站获取泰语-中文可比语料;通过网页标签清除、正则匹配和长度筛查等方式对可比语料进行清洗,然后利用发音相似性,对句子进行相似度计算,筛选出具有较高匹配度的泰语-中文、老挝语-中文伪平行语料,在此基础上进行人工标注得到泰语-中文、老挝语-中文平行语料作为实验数据集,并划分训练集、验证集和测试集;OPUS是一个由多个欧洲语言组成的平行语料库,是一个公知的平行语料库,旨在为机器翻译研究者提供多语言的数据资源;
Step1.2、构建泰语-老挝语双语词典。利用泰语、老挝语分词工具对Step1.1中的泰语-老挝语平行语料进行分词处理,然后使用泰语、老挝语音标转写工具对分词后的语料进行发音转写。根据泰语、老挝语的发音相似性对音标转写后的语料进行相似度计算并结合人工标注的方式构建泰语-老挝语双语词典。
Step2、基于泰老发音相似性的统一罗马化表征:针对泰语、老挝语书写表示不一致,现有泰语、老挝语罗马化工具跨语言表示一致性不高的问题,本发明利用泰语、老挝语之间的发音相似性和当前的罗马化转写标准,修改罗马化转写规则,根据新的罗马化转写规则对泰语和老挝语进行罗马化转写得到泰语和老挝语的统一罗马化表征;优化模型迁移效果;所述Step2的具体步骤为:
Step2.1、针对现有泰语、老挝语罗马化工具文本转写后相似度不高的问题,如表1:中文的“万象”对应泰语和老挝语如第2列所示,对它们进行罗马化转写后分别为/weiiyngchantn/和/wyngcan/,可以发现转化后的文本存在较大差异。使用泰语分词工具和老挝语分词工具分别对泰语-老挝语平行语料中的泰语、老挝语进行分词,利用泰语-老挝语双语词典对分词后的平行语料构建互译词对,如:构建互译词对泰语-老挝语分别如第3列所示;
表1
Step2.2、对Step2.1中罗马化后的互译词对进行差异分析,运用现有的罗马化工具对互译词进行初步罗马化转写,筛选出互译词中对应位置罗马化表示不同的字符,并将其对应的原始字符构成差异字符对。如表2,对互译词对如泰语词和老挝语词第1列,进行初步罗马化转写,结果如第2列,构建的差异字符对为第3列。对差异字符对中字符对的种类及出现频率进行统计;
表2
Step2.3、差异字符对分析、修改罗马化转写规则:使用泰老发音词表对Step2.2中的差异字符对进行分析,对其中具有发音相似性的字符对,使用其共同音标作为罗马化转写字符。如表3所示:差异字符对,如表3第1列,现有转写规则为第2列,其对应发音为第3列,统一其罗马化转写规则为第4列。对剩余字符对中出现频率高的字符对,即出现频率在字符对总数一半以上的字符对,比较罗马化转写后字符对的长度,选取罗马化转写后字符对中转写字符少的一方作为字符对统一罗马化表征。如表4:差异字符对如表4第1列,差异字符对的现有转写规则为表4第2列,选取罗马化转写后字符对中转写字符少的“a”作为字符对统一罗马化表征,新的罗马化转写规则(统一罗马化转写规则)即为表4第3列,根据新的罗马化转写规则对泰语和老挝语进行罗马化转写得到泰语和老挝语的统一罗马化表征。
表3
表4
Step3、构建基于编码转写增强词嵌入迁移的老-中神经机器翻译模型:针对泰语、老挝语书写体系不一致难以有效构建词表对应关系的问题,使用基于泰老发音相似性的统一罗马化表征对泰语和老挝语进行统一表示;对转化后的泰语和老挝语词表构建映射关系,提高泰语-中文翻译模型到老挝语-中文翻译模型的迁移效果。使用老挝语-中文平行语料对迁移后的老-中神经翻译模型进行微调,并将训练好的模型进行保存,部署到服务器上,实现老挝语文本翻译为中文。所述Step3的具体步骤为:
Step3.1、编码转写:使用Step2中获取的基于泰老发音相似性的统一罗马化表征对泰语-中文和老挝语-中文平行语料中的泰语和老挝语语料进行罗马化转写,得到转写后的泰语-中文和老挝语-中文平行语料;
Step3.2、预训练泰-中神经机器翻译模型:使用Step3.1中罗马化转写后的泰语-中文平行语料训练泰-中神经机器翻译模型;
Step3.3、词表对齐:将Step3.2中训练好的泰-中神经机器翻译模型中的泰语词嵌入词表与罗马化后的老挝语词表进行对齐,使得罗马化后具有相同表示的泰语和老挝语字符的词嵌入对齐,用于提升词嵌入迁移效果;
Step3.4、模型迁移微调:将训练好的泰-中神经机器翻译模型迁移到老-中神经机器翻译模型,使用Step3.1中罗马化的老挝语-中文平行语料对迁移后的老-中神经机器翻译模型进行微调。
Step3.5、将Step3.4训练出的“.pt”格式模型部署到服务器端上,实现通过Web多用户并发请求的功能。将需要翻译的老挝语文本输入Web端并通过API传输到服务器,调用老-中神经机器翻译模型,将老挝语翻译为中文。
为了验证本发明提出的基于编码转写增强词嵌入迁移的老-中神经机器翻译方法的效果,设计了以下实验进行分析。
所采用的实验数据如下,本发明的泰-中语料主要包含从亚洲语言树库等网站中收集的语料、通过互联网的双语网站收集的语料以及人工构建的平行语料共254741条。泰-英语料来自于SCB-MT-EN-TH-2020公开的泰-英语料,选取英文长度在300以内的语料,重新划分数据集。老-中、老-英平行语料直接来自于亚洲语言树库各20106条。具体如表5所示。
表5 数据集
实验的神经网络模型是基于Torch实现的,Torch版本为1.8,编译语言为Python3.8,在单个NVIDIA 3090 GPU上进行实验的。实验使用Jieba分词工具对汉语进行分词处理。应用BPE对源语言和目标语言进行子词切分,词表大小为16k。实验选择Transformer模型作为基础模型,模型的编码器和解码器分别设置为6层。在编码器和解码器中的词向量的维度设置为512维。优化器选择参数设置为β1= 0.9,β2= 0.98的Adam优化器优化模型。实验使用warm steps =4000的warm-up策略来调整学习率,每个批次包含大约4096个词。模型训练直到连续10次验证集的BLEU值没有提升,则认为模型收敛并停止训练。在解码过程中,beam search的值设置为5,为了评估,实验使用标准的BLEU评分标准来检测模型的性能。
实验一、为了检查所提统一罗马化方法与现有罗马化方法对泰语和老挝语文本转写的一致性差异,对泰语-老挝语平行语料进行罗马化转写并计算句子相似度,实验结果如表6所示。
表6泰-老句子相似度比较
从表6可以看出,相较于原始文本两种罗马化方法转写后的泰老句子相似度都有大幅度的提升。与现有的罗马化工具uroman相比,本发明所提的基于泰老发音相似性的统一罗马化方法在泰老句子相似度上提高了4.63%。
实验二、为了验证本发明所提基于泰老发音相似性的统一罗马化方法对泰语到老挝语的迁移性能的提升,分别在泰-中迁移到老-中和泰-英迁移到老-英两个方向上进行迁移效果的测试,实验结果如表7所示。通过对表7的结果进行分析,可以得到以下结果:仅使用Transformer对老-中进行模型训练取得了最低的BLEU值3.33,即仅使用稀缺的老中数据训练模型效果较差,模型得不到充分的训练。与此相比,采用迁移学习方法的模型在BLEU值明显优于仅使用Transformer模型,验证了迁移学习能够有效地将泰语语言知识迁移到老挝语,从而增强模型对老挝语的学习能力。不同的词对齐方式取得了不同程度的翻译效果提升,这表明在迁移学习中父子语言的词对齐方式对迁移效果具有重要影响。特别的,Transformed Vocabulary相较Frequency Assignment方法取得了较好的效果,主要在于其对齐了父子语言的公共子词。Frequency Assignment方法在原始文本的迁移上取得了较好效果,原因是泰语和老挝语在词语上具有相似性,泰语中高频词与其含义相同的词在词表中同样具有较高的频率,因此能够更好的进行词表对齐。在引入罗马化方法的迁移中,对Random Assignment和Frequency Assignment方法并没有明显的性能提升,主要原因是这两种词表对齐方法与文本表示无关,引入罗马化方法并不能有效改进对齐效果。然而,在Token Matching方法中,两种罗马化方法在老-中翻译方向上分别提升了1.86和2.45个BLEU值,这表明在泰老文本转化后,将一些具有相同含义的词转写为相同的拉丁字母,增加了泰老词表中相同子词的数量,从而更有效的对齐词表。值得注意的是,本发明提出的罗马化方法相较于uroman在Token Matching方法上进一步提升了0.59个BLEU值,证明本发明提出的罗马化方法能进一步的拉近泰老文本的相似性,提升老挝语翻译性能。
表7 老挝语翻译效果
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 融合BERT与词嵌入双重表征的汉越神经机器翻译方法
- 一种基于同类词与同义词替换的数据增强机器翻译方法