基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法
文献发布时间:2024-07-23 01:35:21
技术领域
本发明属于机器翻译技术领域,涉及蒙古语与汉语的互译,特别涉及一种基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法。
背景技术
现有基于人工智能的机器翻译多采用神经网络,然而神经机器翻译是一种依靠数据驱动的机器翻译方法,在蒙古语-汉语这类语料不足的翻译任务中翻译性能并不理想。
发明内容
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法,以解决蒙古语-汉语语料不足导致的翻译效果不佳的问题。
为了实现上述目的,本发明采用的技术方案是:
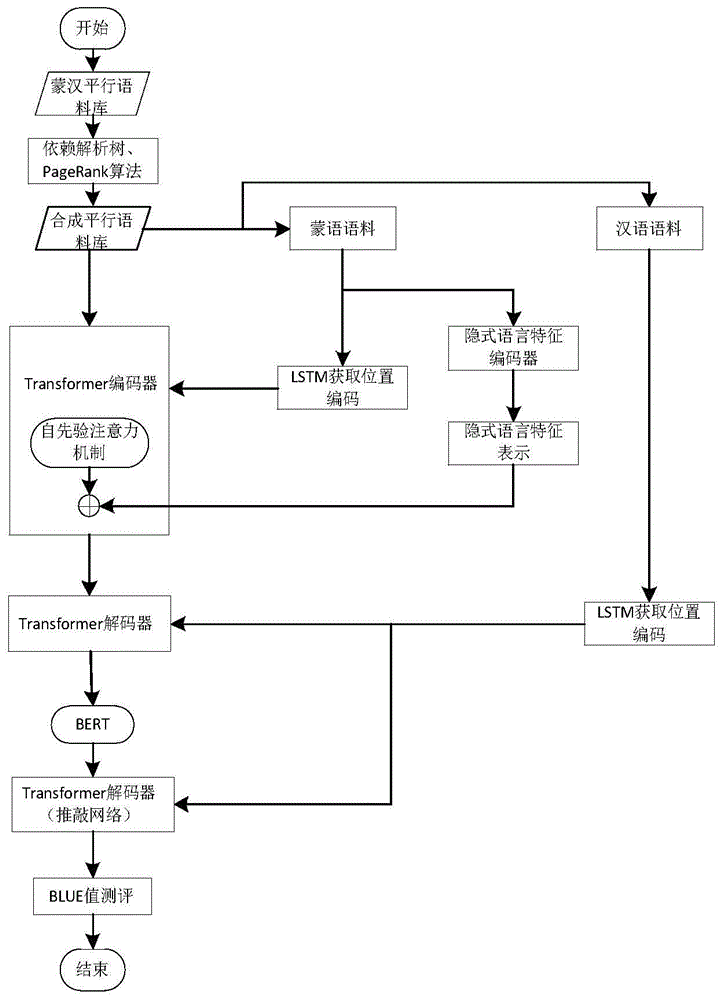
一种基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法,基于由编码器和两阶段解码器组成的推敲网络实现,包括如下步骤:
步骤1,获取蒙古语语料和汉语语料的位置编码以及蒙古语语料的隐式语言特征表示;
步骤2,在编码器,将所述蒙古语语料的位置编码与蒙古语语料源序列进行融合得到源语言向量,在解码器,将所述汉语语料的位置编码与汉语语料源序列进行融合以获取含有更准确的位置信息的词向量;
步骤3,在编码器,基于自先验注意力机制,将所述源语言向量与隐式语言特征表示融合以获取含有深层语言特征的表示向量;
步骤4,将第一阶段解码器输出的文本序列进行预训练,得到包含预训练语言信息的表征向量;
步骤5,在第二阶段解码器,对所述表征向量进行再次解码,以利用预训练中的语言知识对第二段解码过程进行指导。
在一个实施例中,所述步骤1,利用LSTM分别获取蒙古语语料和汉语语料的位置编码。
在一个实施例中,利用LSTM获取位置编码的步骤如下:
首先,分别对蒙古语语料和汉语语料进行词嵌入操作,以获得文本序列的词向量表示;
其次,将获取的词向量表示输入到LSTM模型中进行训练,进而获取具有位置信息的表征向量,即所述位置编码。
在一个实施例中,所述步骤1,利用隐式语言特征编码器获取蒙古语语料的隐式语言特征表示,所述隐式特征编码器包括多层Transformer编码器层,其编码过程如下:
首先,对输入的蒙古语句子进行词嵌入操作得到Input Embedding;
其次,将Input Embedding输入到自注意力机制子层中,使得词向量聚焦更重要的信息,忽略不相关的信息;
最后,将经过注意力操作的词向量输入到前馈全连接层中,得到最后的隐式语言特征表示。
在一个实施例中,所述步骤1,将蒙汉平行语料库通过依赖解析树和PageRank算法进行扩充,得到合成平行语料库,所述蒙古语语料和汉语语料均取自所述合成平行语料库。
在一个实施例中,所述步骤2,采用concat方法,将所述蒙古语语料的位置编码与蒙古语语料源序列进行融合得到源语言向量。
在一个实施例中,所述步骤3,基于自先验注意力机制,将所述源语言向量与隐式语言特征表示融合,方法如下:
首先,将源语言向量输入到自先验注意力模块中,以获得具有先验知识引导的词向量表示;
其次,将所述词向量表示与隐式语言特征进行相加,以此将两者进行融合。
在一个实施例中,所述步骤4,利用BERT预训练模型进行预训练。
在一个实施例中,所述编码器为Transformer编码器,两阶段解码器均为Transformer解码器。
与现有技术相比,本发明的有益效果是:
1、本发明基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法,通过引入LSTM和推敲网络进而缓解因位置信息编码不够灵活及只可利用前序生成序列信息而导致的译文质量差的问题。
2、本发明基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法,通过引入隐式语言特征进而缓解因编码器不能充分理解源语言句子导致词汇级翻译忠实度降低的问题。
附图说明
图1为本发明的流程示意图。
图2为本发明的整体翻译模型图。
图3为隐式特征编码器结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1和图2所示,本发明为一种基于隐式语言特征和推敲网络的蒙汉神经机器翻译方法,基于由编码器和两阶段解码器组成的推敲网络实现,包括如下步骤:
步骤1,对于蒙古语语料和汉语语料,分别获取其位置编码,对于蒙古语语料,还获取其隐式语言特征表示。
本发明蒙古语语料和汉语语料均来自蒙汉平行语料库,由于现有的蒙汉平行语料库资源较为匮乏,为此,本发明实施例中,还对现有的蒙汉平行语料库利用基于语言驱动的数据增强方法进行了扩充,具体地,将蒙汉平行语料库通过依赖解析树和PageRank算法进行扩充,得到合成平行语料库,其实现步骤可描述如下:
首先,利用Stanfod CoreNLP解析器对汉语进行分析并构造依赖解析树。
其次,将构建的依赖解析树转化为强连通图。依赖解析树是一棵有向树,从根节点开始,执行深度优先搜索(Depth First Search,DFS)从而遍历所有的节点。在DFS中,当访问到每个节点时,为每个节点与其父节点之间添加一条反向的有向边,以确保每对节点之间都有一条双向的有向边。继续执行DFS直到遍历完所有的节点。
再次,利用PageRank算法确定句子中每个单词的重要程度,利用激活函数确定每个单词被选中的概率。
最后,对被选中的单词进行标准的词级操作以生成原句子的变体,新生成的句子保持和原句子相同的蒙语对齐,进而得到合成的平行语料库,新生成的平行语料与原平行语料组成伪平行语料库。
本发明实施例中,利用LSTM分别获取蒙古语语料和汉语语料的位置编码与传统的RNN相比,LSTM可应用于更长的序列中,学习长期依赖信息。LSTM引入了三个门结构来实现网络结构中信息的传递,分别是遗忘门、输入门、输出门。通过门控机制来控制信息的丢弃和增加,实现遗忘和记忆功能,本发明基于LSTM的记忆特性,能够获取更准确的位置信息,之后采用concat方法融合位置信息和词向量,并将融合后的表征向量输入到模型中进行训练,其具体步骤如下:
首先,分别对蒙古语语料和汉语语料进行词嵌入操作,以获得文本序列的词向量表示。此处的蒙古语语料和汉语语料可以取自已有平行语料库,也可以取自前述合成的平行语料库。
其次,将获取的词向量表示输入到LSTM模型中进行训练,从而获取具有位置信息的表征向量,即所述位置编码。LSTM的计算公式如下:
遗忘门:决定保留信息还是舍弃信息,即:
f
更新门:决定是否将输入信息更新到cell单元中,即:
c′
i
记忆单元cell节点最新状态为:
c
输出门:决定记忆单元状态值的输出,即:
o
最后的隐层状态的输出,即:
h
其中,f
在本发明的实施例中,利用隐式语言特征编码器获取蒙古语语料的隐式语言特征表示,隐式特征编码器的结构如图3所示,主要包括多层Transformer编码器层,先采用降噪自编码方法对源语言进行自动编码,将训练好的降噪自编码网络的编码器参数作为隐式语言特征编码器的初始化参数,然后通过微调参数得到更好的隐式语言特征表示,具体过程如下:
首先,对输入的蒙古语句子进行词嵌入操作得到Input Embedding。
其次,将Input Embedding输入到自注意力机制子层中,使得词向量聚焦更重要的信息,忽略不相关的信息。
最后,将经过注意力操作的词向量输入到前馈全连接层中,得到最后的隐式语言特征表示。
步骤2,在编码器,将蒙古语语料的位置编码与蒙古语语料源序列进行融合得到源语言向量以获取含有更准确的位置信息的词向量,进而让解码器提取到更重要的特征;同样地,在解码器(包括其第一阶段和第二阶段),将所述汉语语料的位置编码与汉语语料源序列进行融合以获取含有更准确的位置信息的词向量,进而让解码器提取到更重要的特征。
具体地,若直接对位置编码与源序列进行简单的相加操作会模糊词向量的语义表示,不能很好地表征位置信息,因此本步骤采用concat方法,将蒙古语语料的位置编码与蒙古语语料源序列进行融合得到源语言向量。
步骤3,在编码器,基于自先验注意力机制,将源语言向量与隐式语言特征表示融合以获取含有深层语言特征的表示向量,进而可以更好的指导神经机器翻译的编码过程。
传统的自注意力操作用以建模源语言到目标语言的任意两个单词之间的依赖关系。它将输入序列投影到三个矩阵Q,K和V,这三个元素用于计算上下文单词所对应的权重得分,这些权重反映了在编码当前单词的时候对于上下文不同部分所需要的关注程度。其操作可表示为:
Q=XW
其中,
但传统的自注意力机制的每次计算都缺少先验知识的指导,可能会导致模型对一些无关的信息进行过多的关注。为此,本步骤采用自先验注意力模块,具体过程为:当前编码层在进行计算时会用到前层的注意力权重作为参数补充,并传递到下一层。这使得注意力能关注到更相关的信息,同时对模型起到一定的指导作用。其方法主要如下:
首先,自先验注意力模块以源语言向量为输入,获得具有先验知识引导的词向量表示;
其次,利用自适应门控机制,将该词向量表示与前述的隐式语言特征表示进行相加,以此将两者进行融合,进而提高蒙汉神经机器翻译模型的翻译效果。
与传统的自注意力操作相比,自先验注意力机制的操作可表示为:
其中,Prior-Attention(Q,K,V,prior)表示自先验注意力,prior中的Q
步骤4,将第一阶段解码器输出的文本序列进行预训练,得到包含预训练语言信息的表征向量。
步骤5,在第二阶段解码器,对所述的表征向量进行再次解码,以利用预训练中的语言知识对第二段解码过程进行指导。
编码器-解码器框架在许多序列生成任务中都取得了较好的性能,但是在解码器端生成词的时候只能利用已经生成的词汇而不能利用尚未生成的词汇,也就是说缺少推敲的过程。为此,本发明在解码器端引入了推敲网络的思想,并在推敲阶段(第一阶段解码器和第二阶段解码器之间)引入预训练模型对推敲过程进行指导。具体而言,第一阶段解码器用于解码生成原始序列,第二阶段解码器(也叫推敲解码器)通过推敲的过程打磨和润色原始语句。由于第二阶段推敲解码器具有应该生成什么样的语句这一全局信息,因此它能通过从第一阶段的原始语句中观察未来的单词而产生更好的序列。示例地,本步骤采用BERT预训练模型进行预训练。
在本发明中,编码器以及两阶段解码器均可为Transformer解码器。
也即,本发明的蒙汉神经机器翻译模型融合了隐式语言特征编码器和自先验注意力模块,其进行蒙汉翻译的一个例子如下:
以翻译
- 基于源语言句法依赖和量化矩阵的蒙汉神经机器翻译方法
- 基于编码归纳-解码推敲的汉-越低资源神经机器翻译方法