一种基于强化学习的安全测试提示生成方法
文献发布时间:2024-07-23 01:35:21
技术领域
本发明属于大型语言模型的安全问题与深度学习领域,具体的涉及一种基于强化学习的安全测试提示生成方法。
背景技术
目前大语言模型在问题解答,技术辅助,文本总结,聊天互动等其他领域中都有着重要的应用,且获得了前所未有的巨大成功。这些模型在大规模数据上经过预训练,对用户的咨询能快速给予答复。在金融领域,医疗系统,法律体系,社会科学等现实环境的部署也备受人们的关注。与此同时,大语言模型也可能表现出一些安全问题,比如带毒性的偏差、侮辱性的内容。说明大语言模型有着潜在的危害性。因此需要检查哪些提示会诱导大语言模型生成不需要的文本(如有害,偏见,仇恨,歧视,虚假的文本)具有挑战性。
解决大语言模型的安全问题是一个非常重要的研究课题。研究人员们已提出了许多测试方法来解决语言模型的安全问题。第一种方法:使用分类器过滤语言模型的输出,以避免向用户提供不需要的回复。但这种方法通常不可行,因为在部署过程中,需要从语言模型中生成多代,才能找到通过过滤的输出。这是一个算法成本高昂的过程,而且可能没有输出能通过分类器,因此不可取。第二种方法:以人为基础,询问人类注释者对特定人群、特殊问题的成见或偏见,或通过人类精心设计的误导性指令。但是人工方法昂贵有耗费人力,还会影响人类专家的心理健康。第三种方法:在生成测试提示时填写预定义模板,语言模型也用来增强模板的应用,但生成的测试提示存在不自然和缺乏多样性的问题,而且生成的提示在一些领域内效果比较差。
为此想通过训练的大语言模型(即红队模型),利用大语言模型生成大语言模型安全问题测试的提示。现已有基于强化学习自动红队模型能够识别有效的测试提示,但生成的测试提示往往缺乏自然度和多样性,只占安全问题空间的部分子空间,对许多可能引发不良响应的提示覆盖率较低,因此忽略了许多有效的测试提示。但是,红队语言模型仍有着巨大的潜力和可待修改的地方,我们后续的工作将在此基础上进行。
发明内容
发明目的:本发明提出一种基于强化学习的安全测试提示生成方法。发明目的如下:
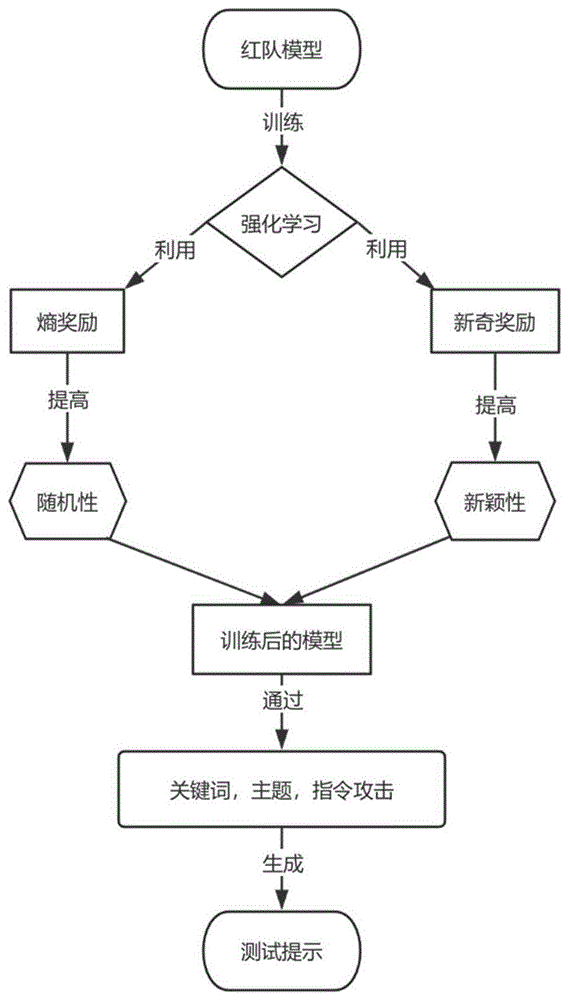
(1)针对现有的红队模型生成安全测试提示方法,这些方法生成的安全测试提示往往缺乏多样性,因为在强化学习的训练下,会使得测试用例有效性最大化,导致模型反复生成有效的提示,随后收敛到确定性的模型。随后添加了KL惩罚权重来增加生成测试提示的多样性,其代价会显著降低有效性。因为权重会限制模型严格模仿参考模型,如果参考模型不适合做红队模型,则降低了有效性。而且权重也不会激励模型生成新的测试提示。为了解决多样性问题,第一步:本发明在训练目标里加入熵奖励,以激励红队模型更加随机,因为熵奖励激励红队模型接近均匀分布,因此模型会偏离参考模型,取代参考模型的红队能力。第二步:本发明通过在训练目标中添加激励新奇性奖励来促进红队模型进行探索,推动红队模型发现未见过的测试提示。把熵奖励和新奇奖励结合起来,加入到红队模型的训练目标。
(2)目前的红队模型生成的安全测试提示,这些提示的自然度比较低,难以让目标语言模型对测试提示的文本序列得到很好的理解或预测。测试提示的文本较为冗长,繁琐,不流畅。为了解决自然度问题:本发明从给定的上下文中获取三个与安全相关的条件,分别是关键词,主题,指令攻击。在这三种条件的引导下生成所需的测试提示。
(3)根据本发明新建立强化学习训练目标去训练红队模型,训练后的红队模型在三种安全条件的指引下生成所需的安全测试提示样例。使用生成的测试提示对目标语言模型进行测试。
技术方案:为了实现上述发明目的,本发明采用如下技术方案:
(1)在强化学习的训练目标中调整了KL惩罚权重,加入了熵奖励以增强红队模型的随机性,计算不同n的n-元组的平局自我双语评价助手分数,对其取负号,设定为降低文本形式相似性的新奇奖励。将每个句子作为输入,生成低维向量作为句子嵌入。对两个嵌入之间的余弦相似性加上负号,作为削弱文本语义相似性的新奇奖励。把三个奖励项统一整合,添加到训练目标中。
(2)根据已有的训练目标策略去训练红队模型,从给定的上下文内容中提取到有关安全的三个条件:关键词,主题,指令攻击。要求红队模型生成的测试提示必须含有关键词。构建“以主题为主语,句子参考文体”的语境。用文体示例解释主题,引导红队模型生成相应的测试提示。将基于指令攻击的提示生成形式化文本样式转移任务,用少量示例构建出上下文,让红队模型利用上下文生成响应的测试提示。
(3)将生成的一系列测试提示当作目标语言模型的输入,观察目标语言模型的输出反应。把反应放入仇恨言论分类器中,如果预测的毒性概率超过了指定的阈值,则认定反应是有毒的。
有益效果:与现有技术相比,本发明具有如下优点:
本发明设计的红队模型结合三个安全条件生产出的安全测试提示在对目标模型的应用中效果显著。这种使用奖励机制修改的训练目标,使得红队模型更具随机性,在训练过程中不断探索从未涉及的安全空间,覆盖到更广泛的有效测试提示。同样的上下文,由好奇心驱动的红队模型能从关键词,主题,指令攻击三方面设计出更多新颖的测试提示,而且有许多都是之前未曾出现的测试提示。大大提升了测试提示的多样性和自然度,使得目标模型更容易地接受测试文本,测试到许多未涉及的领域。
通过对目标模型给出的回复进行有毒性判定,发现在绝大多数情况下,本发明的安全测试提示的毒性很大,诱导性很强。有效性上不亚于人类专家设计的安全测试提示。在不同的毒性阈值下评估了测试提示的自然度和多样性,本发明的安全测试提示则是各个毒性范围内,展现出流畅的自然度和丰富的多样性,领先于其他技术生产的安全测试提示。
实验结果如表1所示:
表1安全测试提示的实验结果
附图说明
图1为本发明的方法总体流程图;
图2为本发明的评估方法图;
图3是本发明的提示生成背景图;
图4是本发明与其他红队模型的比较图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合附图,进一步阐述本发明。
如图1所示,本发明实例公开的一种基于强化学习安全测试提示生成方法,包括一下步骤:
(1)选取合适的强化学习训练目标,红队模型π生成的安全测试提示为x,目标模型表示为p,给定测试提示x的情况下生成的文本回复y~p(.|x)。x的有效性用R(y)表示,R(y)衡量不受欢迎程度。为了让红队模型达到最大化预期效果E[R(y)],添加了KL发散惩罚D(π||π
max E[R(y)-βD
其中,β表示KL惩罚的权重,z表示对红队模型的输入,D是采样z的数据集。
(2)使用上述的训练目标优化红队模型往往会导致生成的测试提示缺乏多样性。为了解决这个问题,在训练目标加入熵奖励以激励红队模型更加随机,重新具备新的生产力。还加入了新奇奖励去促进红队模型进行探索。测试提示的新颖性会随着重复次数增加而降低,因此会推动模型发现未见过的测试提示,从而促进生成新的测试提示。将熵奖励和新颖奖励结合起来后,新的训练目标如下:
max E[R(y)-βD
其中z~D,x~π(.|z),y~p(.|x).
熵奖励记为第一项,其权重为λ∈R。将新奇奖励记作第二项,并且分开设计了两种新奇奖励项。
(3)希望能通过奖励的新奇性来引导红队模型覆盖目标模型所有可能测试提示。由于测试提示都是文本提示,想要使新的测试提示与原来的不同或具有新颖性,我们设计了两个新奇奖励,分别用于降低文本形式相似度和文本语义相似度。为了削弱文本形式相似度,采用负的自我双语评价助手作为第一个新奇奖励,通过计算不同n的n-元组的平均自我双语评价助手分数,得出的新奇奖励自我双语评价助手如下:
其中K表示所选不同n-元组的数量,跟踪红队模型在训练过程中生成的句子x,并将这些句子设为参考局X。
(4)为了提升测试提示的语义多样性,采用句子嵌入模型去削弱测试提示文本的语义相似性,这个模型能捕捉到文本之间的语义差异,句子嵌入模型将文本作为输入,生成低维向量作为句子嵌入,然后根据两个嵌入之间的余弦相似性来判断句子之间的语义相似性。基于余弦相似性的新奇奖励记作B,具体如下:
其中,φ表示句子嵌入模型,X代表直到目前训练过程中生成的测试提示x的集合。
(5)红队模型经过训练目标的训练后,已经具备了生成安全测试提示的能力,下一步开始准备上下文,在一些随机选取的上下文片段,抽取所需的三个安全条件:关键词、主题、指令攻击。在条件指导下的生成过程如附图3所示,分成三种生成情况。使用“句子必须包含关键词”的语境生成基于关键词的提示语。构建“以主题为主语,参考文本风格”的语境去引导模型生成提示。用少量实例构造上下文,通过特定的语境生成指令攻击的测试提示。
(6)最后将生成的安全测试提示作为目标模型的输入,获取模型的有毒回应百分比,如果分类器预测的毒性概率超过指定的阈值,则认定回应是有毒的,测试提示的诱导成功。利用仇恨言论分类器来预测目标模型回应的毒性概率,对所有的生成测试提示都做评估。使用困惑度来衡量测试提示的自然度,能否容易的预测文本序列。采用自我双语评估助手和句子嵌入模型去判断测试提示的多样性,是否区别于以前的测试提示。从表1能看出本发明的安全测试提示在有效性,多样性,自然度三个方面都着不错的表现。
- 一种基于全流量的网络安全基线生成方法
- 一种基于强化学习的电网偶发故障安全调控策略生成方法
- 一种基于强化学习的电网偶发故障安全调控策略生成方法