一种注意力机制计算方法、计算系统及存储介质
文献发布时间:2024-07-23 01:35:21
技术领域
本发明涉及人工智能领域,尤其涉及一种注意力机制计算方法、计算系统及存储介质。
背景技术
大语言模型(LLM)的影响力与日俱增,它有非常好的处理文本的能力,通过训练或微调模型的参数能够适用于各种场景,包括机器翻译、文本生成、智能助手、聊天机器人等。然而一个大语言模型的参数量远大于传统的神经网络,通常达到了数十亿级别,导致其训练和推理的耗时非常长,如何加速大语言模型的计算过程是关键。现有的大语言模型如Llama2,OPT,GPT的计算过程主要分为预填充(prefill)和解码(decode)两个阶段,在prefill阶段或是输入长文本的decode阶段时,注意力计算的占比都非常高,往往会达到整体计算过程的1/3甚至更多。就以LLaMa2-7B为例,整个网络结构由32个TransformerBlock+归一化层+线性层组成,TransformerBlock(变换器块)则主要包括注意力计算和FFN(Feed-Forward Neural Network,前馈神经网络)计算。
现有attention(注意力机制)计算加速优化技术主要为flash attention,他们通过一系优化方案,如使用分段的softmax从而不用全量输入数据,反向传播时不存储中间注意力矩阵从而充分缩短了从HBM(High Bandwidth Memory,高带宽存储器)中读取和写入注意力矩阵。通过加速注意力机制中的单个算子,也能够对整体过程进行加速,比如说GEMM(通用矩阵乘,General Matrix
Multiplication),GEMV(通用矩阵向量乘,General Matrix Vector
Multiplication)等。
现有的大语言模型中的注意力机制加速优化仍然存在以下问题:
现有注意力机制优化技术大多都是部署在计算访存比较低的GPU(例如,NIVIDA的GPU)上,没有针对计算访存比较高的GPU进行优化。例如:NVIDIA A100 GPU fp32峰值算力为19.5TFLOPS(每秒一万亿(=10^12)次的浮点运算),带宽为1935GB/s,计算访存比为10.32,而AMD MI210峰值算力为22.6TFLOPS,带宽却仅为1638GB/s,计算访存比高达14.13。如果将适用于计算访存比较低的GPU的优化技术应用于AMD GPU或其他厂商的计算访存比较高的GPU上将会出现加速效果很小甚至负优化的情况。数据表明flash attention计算在NVIDIA A100 GPU上的利用率约为50%,但在AMD MI210GPU上的利用率只有30%。经过分析,注意力机制前向和反向传播过程访存量较大,访存次数多,需要较大的存储空间来导入各种数据到寄存器和共享内存中用于计算,现有技术没有考虑到对于访存速度较慢的GPU,多次访存导致访存开销增大的问题。
现有技术如flash attention主要优化的过程是Q(查询,query)映射,K(键,Key)映射,V(值,value)映射过后的softmax(Q*K)过程,然而整个注意力计算还有大部分未得到优化,特别是新的LLaMa模型推出后,除了QKV映射,RoPE(旋转位置编码),KV cache(KV缓存)的更新在注意力计算中也不能忽视。
发明内容
有鉴于现有技术的上述缺陷,本发明提供一种注意力机制计算方法、计算系统及存储介质,通过优化注意力机制的前向传播阶段以及反向传播阶段,以提升计算单元的利用率。为实现以上目的,本发明的技术方案包括:
一种注意力机制计算方法,其包括前向传播阶段以及反向传播阶段;
在前向传播阶段,将QKV映射、更新KV缓存以及旋转位置编码的算子进行融合,并调整融合后算子的内部计算流程,以减小访存的时间开销;
在反向传播阶段,调整计算顺序以及访存顺序,以提高反向传播过程的效率。
本发明的进一步改进在于:融合后算子的内部计算流程包括三个阶段:
第一阶段:对输入矩阵X进行K映射以及V映射,得到矩阵K和矩阵V;
第二阶段:对输入矩阵X进行Q映射,得到矩阵Q;并利用矩阵K和矩阵V对KV缓存进行更新;
第三阶段:对矩阵Q以及矩阵K进行旋转位置编码。
本发明的进一步改进在于:在第一阶段和第二阶段中,输入矩阵X暂存在片上;在第二阶段中,矩阵K和矩阵V暂存在片上;在第三阶段中,矩阵Q和矩阵K暂存在片上。
本发明的进一步改进在于:
在第一阶段过程中,读入用于K映射的映射矩阵W
在第二阶段过程中,利用矩阵K和矩阵V对KV缓存进行写入更新,并读入用于Q映射的映射矩阵W
本发明的进一步改进在于:片上的存储空间包括共享内存。
本发明的进一步改进在于:前向传播阶段的输出为的表达式为:
其中,V、Q、K分别为矩阵V、经过旋转位置编码的矩阵Q和矩阵K;d
本发明的进一步改进在于:反向传播过程中的计算包括:
S1:导入lse数据用于softmax计算,并计算S=Q*K
S2:利用S和lse数据进行softmax计算;
S3:计算dP=dY×V
S4:计算dV=P
S5:计算dS=P×(dP-YdY);
S6:计算dQ=dS×K;
S7:计算dK=dS
S8:计算dQ原子加;dQ原子加是指将dQ所得的部分结果累加。
本发明还提供一种计算系统,所述计算系统包括:
存储器,所述存储器用于存储计算机可执行指令;和
处理器,所述处理器用于执行所述计算机可执行指令,以实现上述的注意力机制计算方法。
本发明的进一步改进在于:所述处理器包括图形处理单元(GPU)、神经网络处理单元(NPU)以及现场可编程门阵列(FPGA)芯片。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有可执行指令,计算机执行所述可执行指令时能够实现上述的注意力机制计算方法。
本发明提供的技术方案具有以下技术效果:通过优化注意力计算的前向传播和反向传播过程,分别采用算子融合和计算过程重排的策略,减少了计算中的访存次数和访存量,通过加速大语言模型中的注意力计算过程,提升了大语言模型的训练和推理性能。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
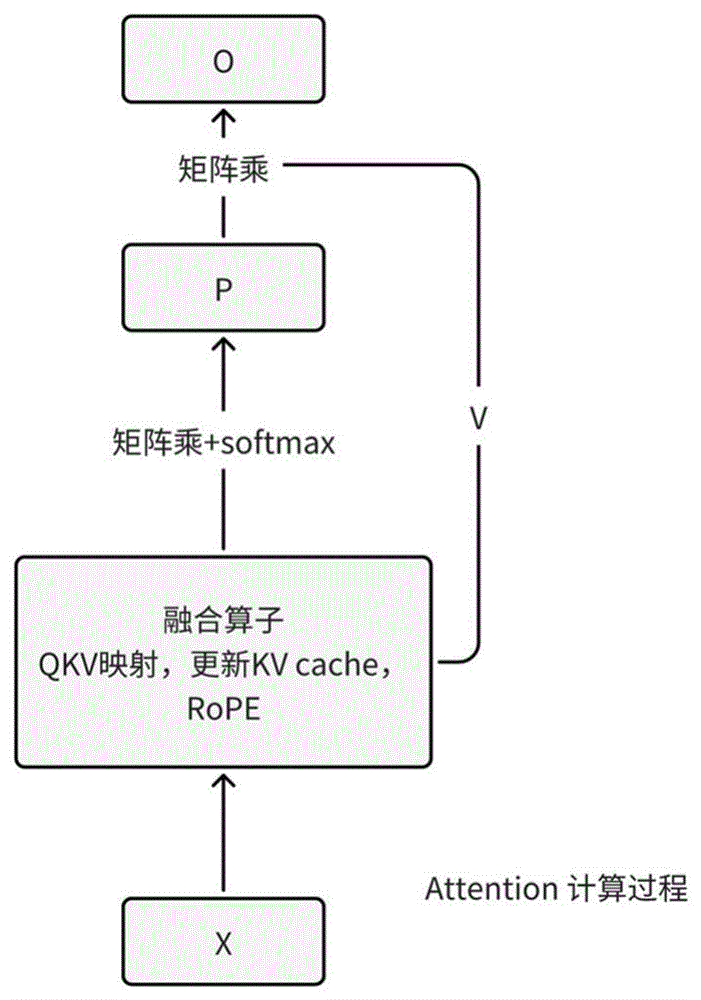
图1所示为现有技术中的注意力机制的前向传播计算过程的示意图;
图2所示为本发明中优化后的注意力机制的前向传播计算过程的示意图;
图3所示为本发明中融合算子内部的计算过程示意图;
图4所示为现有技术以及本发明中反向传播过程的计算顺序示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图示中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
为了阐释的目的而描述了本发明的一些示例性实施例,需要理解的是,本发明可通过附图中没有具体示出的其他方式来实现。
本发明的实施例提供了一种注意力机制计算方法,该方法通过优化attention(注意力机制)的前向传播和反向传播的过程,提升在高计算访存比的计算单元上的利用率。本实施例中,以LLaMa2模型中的attention(注意力机制)为例,进行优化,其计算公式:
其中矩阵Q,K,V都是由输入矩阵X映射而来,即Q=W
如图2所示,本实施例中,前向传播阶段将QKV映射、更新KV缓存以及旋转位置编码的算子进行融合,以减少访存次数和访存大小;并调整融合后算子的内部计算流程,以减小访存的时间开销。
如图1所示,在现有的前向传播阶段矩阵K经过了三次计算,而矩阵Q和V均为两次,主要是由于得到矩阵K既要参与KV cache的更新,又要进行RoPE计算。如果顺序执行映射,更新KV cache,RoPE三个步骤,则更新KV cache的阶段并没有计算步骤,反而是大量的访存操作,导致计算资源浪费。因此在算子内部优化计算流程如图3所示。
融合后算子的内部计算流程包括三个阶段:
第一阶段:对输入矩阵X进行K映射以及V映射,得到矩阵K和矩阵V;
第二阶段:对输入矩阵X进行Q映射,得到矩阵Q;并利用矩阵K和矩阵V对KV缓存进行更新;
第三阶段:对矩阵Q以及矩阵K进行旋转位置编码。
算子融合减少访存次数和访存大小:将矩阵X映射为矩阵Q,K,V的操作为相同大小的矩阵乘(GEMM),两次RoPE和两次更新KV cache的操作均存在相同的计算流程,因此可以通过算子融合的方式融合为一个算子,从而避免多次访存的开销。如果分开计算,总访存量为3×(k
通过优化算子内的计算流程,能够做到计算和访存的负载均衡。通过上述两个优化,能够掩盖掉访存所带来的时间开销,减少计算访存比较小的GPU(例如部分AMD GPU芯片)访存速度慢对前向传播计算速度的影响。
在反向传播阶段,调整了计算顺序以及访存顺序,以提高反向传播过程的效率。反向传播过程中的计算包括:
S1:导入lse数据用于softmax,并计算S=Q*K
S2:利用S和lse数据进行softmax计算,其中P=softmax(QK
S3:计算dP=dY×V
S4:计算dV=P
S5:计算dS=P×(dP-YdY);
S6:计算dQ=dS×K;
S7:计算dK=dS
S8:计算dQ原子加;dQ原子加是指将dQ所得的部分结果累加起来。
反向传播过程在本发明中得到了优化,基于flash attention2的反向传播过程进行了改进。通过详细分析各个步骤之间的依赖关系,dP=V
本发明的实施例还提供一种计算系统,所述计算系统包括:
存储器,所述存储器用于存储计算机可执行指令;和
处理器,所述处理器用于执行所述计算机可执行指令,以实现上述的注意力机制计算方法。
本发明的进一步改进在于:所述处理器包括GPU、NPU以及FPGA芯片。
本发明的实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有可执行指令,计算机执行所述可执行指令时能够实现上述的注意力机制计算方法。
在优化过程中,本实施例采用了以下两个关键策略:
1.解除依赖关系:根据反向传播的各个步骤之间的依赖性,调整了计算的顺序,以降低访存冲突的可能性。这样的优化可以有效地提高计算的效率,避免了由于连续利用同一块空间而导致的性能瓶颈。同时还可以缓解多个线程并行执行时,线程之间互相等待导致的较高的同步开销。
2.计算与访存交替并行:在反向传播的计算过程中引入了错开的机制,即尽量保证仅在进行计算之前提前导入相应的数据。这样的操作可以避免寄存器和共享内存同时存储导致的频繁换出问题,同时也能够巧妙地隐藏计算和访存之间的延迟时间。通过错开计算和访存,从而更有效地利用了GPU的并行计算能力,提高了整体的反向传播过程的性能。
实验表明,本方案在flash attention的基础上进行了改进,前向传播即推理阶段加速了约30%,而反向传播也有10%的加速。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 一种主播相似度的计算方法、装置、设备和存储介质
- 一种文本相似度计算方法、装置、电子设备及存储介质
- 一种文本相似度计算方法、装置、电子设备及存储介质
- 一种功率自适应计算方法、系统及存储介质
- 多水库水量调度方法、终端、存储介质及异构计算系统
- 一种基于自注意力机制与空洞卷积池化的语义分割方法、存储介质和视觉装置
- 一种基于注意力机制以及多尺度特征融合的目标检测方法、设备及存储介质