模型训练方法、装置、计算机设备及存储介质
文献发布时间:2024-07-23 01:35:21
技术领域
本申请实施例涉及机器学习技术领域,特别涉及一种模型训练方法、装置、计算机设备及存储介质。
背景技术
大型语言模型(在本申请中简称大模型)可以用来处理很多常见NLP(NaturalLanguage Processing,自然语言处理)任务,依靠大模型广阔的知识量和强大的语言理解能力,在一些场景中,可以通过调整输入的指令来满足最新需求,更加灵活。
然而大模型的推理速度慢,难以满足大规模数据处理要求,同时线上推理成本很高,是专用NLP模型的十倍或百倍以上。专门训练的NLP模型不仅具有推理速度和成本的优势,通常也可以达到接近大模型或更高的准确率,
但目前训练一个NLP模型需要算法工程师根据业务需求进行数据选择、模型选择、模型训练,需求响应速度慢,人力成本和时间成本都更高,从而使得模型训练效率较低。
发明内容
本申请实施例提供了一种模型训练方法、装置、计算机设备及存储介质,可以实现模型训练过程的自动化,提高模型训练效率。该技术方案如下:
一方面,提供了一种模型训练方法,所述方法包括:
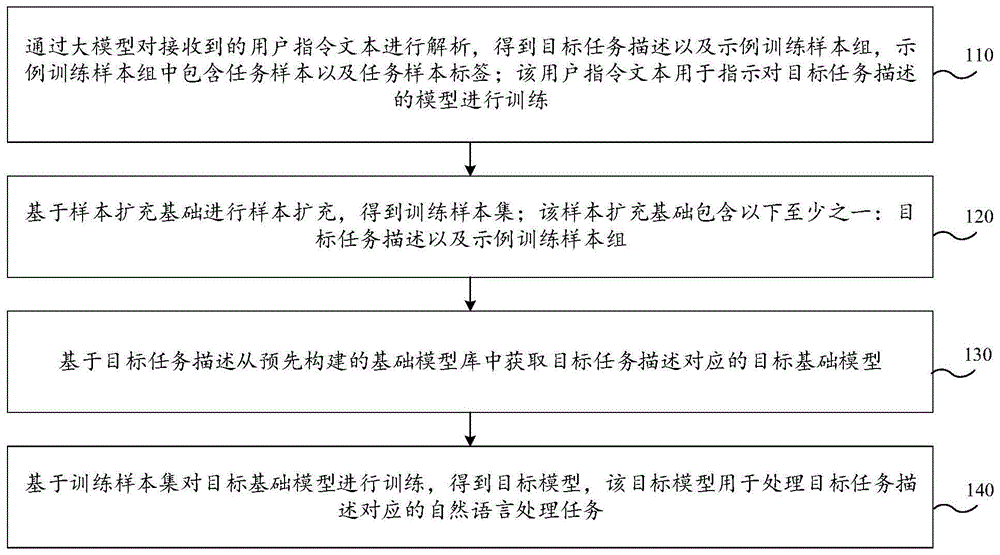
通过大模型对接收到的用户指令文本进行解析,得到目标任务描述以及示例训练样本组,所述示例训练样本组中包含任务样本以及任务样本标签;所述用户指令文本用于指示对所述目标任务描述的模型进行训练;
基于样本扩充基础进行样本扩充,得到训练样本集;所述样本扩充基础包含以下至少之一:所述目标任务描述以及所述示例训练样本组;
基于所述目标任务描述从预先构建的基础模型库中获取所述目标任务描述对应的目标基础模型;
基于所述训练样本集对所述目标基础模型进行训练,得到目标模型,所述目标模型用于处理所述目标任务描述对应的自然语言处理任务。
另一方面,提供了一种模型训练装置,所述装置包括:
文本解析模块,用于通过大模型对接收到的用户指令文本进行解析,得到目标任务描述以及示例训练样本组,所述示例训练样本组中包含任务样本以及任务样本标签;所述用户指令文本用于指示对所述目标任务描述的模型进行训练;
样本扩充模块,用于基于样本扩充基础进行样本扩充,得到训练样本集;所述样本扩充基础包含以下至少之一:所述目标任务描述以及所述示例训练样本组;
模型获取模块,用于基于所述目标任务描述从预先构建的基础模型库中获取所述目标任务描述对应的目标基础模型;
模型训练模块,用于基于所述训练样本集对所述目标基础模型进行训练,得到目标模型,所述目标模型用于处理所述目标任务描述对应的自然语言处理任务。
在一种可能的实现方式中,所述样本扩充模块,包括:
数据集筛选子模块,用于在所述样本扩充基础包含所述目标任务描述的情况下,基于所述目标任务描述从预先构建的数据集库中筛选出至少两个候选数据集;
第一分数获取子模块,用于将至少两个候选数据集的数据集元信息分别与所述目标任务描述输入到数据集推荐模型中,得到至少两个候选数据集分别与所述目标任务描述之间的第一匹配分数;所述数据集推荐模型是通过第一正样本集与第一负样本集训练得到的;所述第一正样本集中包含样本数据集的数据集元信息以及与样本数据集相匹配的任务描述标签;所述第一负样本集中包含样本数据集的数据集元信息以及与样本数据集不匹配的任务描述标签;
第一筛选子模块,用于基于至少两个候选数据集各自对应的所述第一匹配分数筛选得到目标数据集;
数据集构建子模块,用于基于所述目标任务描述对所述目标数据集进行字段筛选得到训练样本组,以构建所述训练样本集。
在一种可能的实现方式中,所述数据集筛选子模块,用于,
基于所述目标任务描述中的关键词对所述数据集库中的数据集进行筛选,得到至少两个候选数据集;
或者,
计算所述目标任务描述与所述数据集库中的各个数据集之间的向量相似度,并基于所述数据集库中的各个数据集各自对应的向量相似度筛选得到至少两个候选数据集。
在一种可能的实现方式中,所述样本扩充模块,包括:
样本组获取子模块,用于在所述样本扩充基础包含所述示例训练样本组的情况下,将所述样本扩充指令输入到所述大模型中,获得所述大模型输出的与所述示例训练样本组类型一致的训练样本组;
所述样本集构建子模块,用于基于所述大模型输出的训练样本组构建所述训练样本集。
在一种可能的实现方式中,所述模型获取模块,包括:
第二分数获取子模块,用于将所述基础模型库包含的各个基础模型的模型元信息分别与所述目标任务描述输入到基础模型推荐模型中,得到各个基础模型分别与所述目标任务描述之间的第二匹配分数;所述基础模型推荐模型是通过第二正样本集与第二负样本集训练得到的;所述第二正样本集中包含样本基础模型的模型元信息以及与样本基础模型相匹配的任务描述标签;所述第二负样本集中包含样本基础模型的模型元信息以及与样本基础模型不匹配的任务描述标签;
第二筛选子模块,用于基于各个基础模型分别与所述目标任务描述之间的第二匹配分数筛选得到所述目标基础模型。
在一种可能的实现方式中,所述装置还包括:
评估指标获取模块,用于将基于所述目标任务描述构建的所述模型评估指标生成指令输入到预先训练好的大模型中,获得所述大模型输出的模型评估指标。
在一种可能的实现方式中,所述装置还包括:
模型评估模块,用于基于所述模型评估指标评价所述目标模型的模型效果。
另一方面,提供了一种计算机设备,所述计算机设备包含处理器和存储器,所述存储器存储有至少一条计算机程序,所述至少一条计算机程序由所述处理器加载并执行以实现上述的模型训练方法。
另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一条计算机程序,所述计算机程序由处理器加载并执行以实现上述的模型训练方法。
另一方面,提供了一种计算机程序产品,所述计算机程序产品包括至少一条计算机程序,所述计算机程序由处理器加载并执行以实现上述各种可选实现方式中提供的模型训练方法。
本申请提供的技术方案可以包括以下有益效果:
本申请实施例提供的模型训练方法,计算机设备通过大模型接收并解析用户指令文本获得目标任务描述以及示例训练样本组,并基于目标任务描述和/或示例训练样本组进行样本扩充,以得到训练样本集;根据目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型;通过训练样本集对目标基础模型进行模型训练,得到用于处理目标任务描述对应的自然语言处理任务的目标模型。通过上述方法,计算机设备可以利用大模型的知识和语言理解能力将样本选择、补充样本生成、模型选择以及模型训练过程自动化,从而减少模型训练过程中所需的人为操作,降低模型开发成本,提高模型训练效率。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
图1示出了本申请一示例性实施例提供的模型训练方法的流程图;
图2示出了本申请一示例性实施例提供的模型训练方法的流程图;
图3示出了本申请一示例性实施例提供的模型训练方法的架构图;
图4示出了本申请一示例性实施例提供的模型训练装置的方框图;
图5示出了本申请一示例性实施例示出的计算机设备的结构框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
在具有为特定NLP任务训练专用小模型需求的场景中,可以通过在已有大模型(即预训练后的大模型或增量预训练后的大模型)的基础上,使用指令样本继续训练,通过指令微调使得大模型掌握理解和执行用户指令的能力,以执行特定的NLP任务;由于在特定NLP模型训练过程中,需要算法工程师根据业务需求进行数据选择、模型选择、模型训练等过程,使得训练特定NLP模型的效率受到人为因素的影响,使得需求响应速度较慢;在此情况下,本申请实施例提供的模型训练方法,可以实现模型训练的自动化,减少模型训练过程中的人为影响,从而提高模型训练效率;图1示出了本申请一示例性实施例提供的模型训练方法的流程图,该方法可以由计算机设备执行,该计算机设备中可以配置有大模型,该计算机设备可以实现为服务器,如图1所示,该模型训练方法可以包括以下步骤:
步骤110,通过大模型对接收到的用户指令文本进行解析,得到目标任务描述以及示例训练样本组,示例训练样本组中包含任务样本以及任务样本标签;该用户指令文本用于指示对目标任务描述的模型进行训练。
该用户指令文本是用户基于当前的模型训练需求输入到大模型中的文本内容,该用户指令文本中包含有目标任务描述以及示例训练样本组对应的信息,计算机设备通过大模型对接收到的用户指令文本进行解析,以得到目标任务描述以及示例训练样本组。
该示例训练样本组中可以包含示例性的少量的任务样本以及任务样本对应的任务样本标签;用以起到样本规范作用。
示意性的,以目标任务描述指示训练文本分类模型为例,该用户指令文本可以为:
“请根据以下示例判断输入的新闻标题属于下列哪个分类:生活、娱乐、房产、财经、体育、旅游、科技、军事。只输出分类名称,不需要解释。
示例:
>标题:一知名公司百余员工吃团餐疑食物中毒:检测出沙门氏菌。
>分类:生活;
>标题:2023年国庆档,电影票房预期?
>分类:娱乐;
>标题:某中介公司下调中介费,暂无对手跟进。
>分类:房产;
>标题:突发利空!股市波动!
>分类:财经;
>标题:混合团体10米气步枪金牌花落谁家?
>分类:体育;
>标题:乡村walk|爬长城,赏古城,游览司马台村。
>分类:旅游;
>标题:手机性能battle,谁才是“体验王者”。
>分类:科技;
>标题:某国将举行大规模阅兵。
>分类:军事”
基于对上述用户指令文本的解析可以确定当前需求为训练一个能够判断输入的新闻标题所属分类的模型。比如,在该模型训练完成后,在将“标题:土豆的多种烹饪方法”输入到该模型中后,该模型可以输出“分类:生活”,达到对新闻标题进行分类的效果。
需要说明的是,上述用户指令文本仅为示意性的,基于实际中所需实现的模型的训练效果不同,用户输入描述的不同,用户指令文本不同,本申请对此不进行限制。
步骤120,基于样本扩充基础进行样本扩充,得到训练样本集;该样本扩充基础包含以下至少之一:目标任务描述以及示例训练样本组。
由于用户指令文本中包含的任务样本的数量较少,为了保证模型训练的全面性,提高训练得到的模型的准确性,计算机设备可以通过大模型基于样本扩充基础进行样本扩充,以得到包含大量任务样本及任务样本标签的训练样本集。
步骤130,基于目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型。
该基础模型库中可以存储有大量已训练好的基础模型的模型元信息,模型元信息可以包含模型名称、描述、预训练使用的数据集信息、支持对哪些下游任务进行微调、参数规模、支持的输入输出长度等等;以便于计算机设备基于目标任务描述进行基础模型的筛选,得到对应于目标任务描述的目标基础模型。
步骤140,基于训练样本集对目标基础模型进行训练,得到目标模型,该目标模型用于处理目标任务描述对应的自然语言处理任务。
该目标模型是用于处理目标任务描述对应的自然语言处理任务的专用模型。
综上所述,本申请实施例提供的模型训练方法,计算机设备通过大模型接收并解析用户指令文本获得目标任务描述以及示例训练样本组,并基于目标任务描述和/或示例训练样本组进行样本扩充,以得到训练样本集;根据目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型;通过训练样本集对目标基础模型进行模型训练,得到用于处理目标任务描述对应的自然语言处理任务的目标模型。通过上述方法,计算机设备可以利用大模型的知识和语言理解能力将样本选择、补充样本生成、模型选择以及模型训练过程自动化,从而减少模型训练过程中所需的人为操作,降低模型开发成本,提高模型训练效率。
在本申请实施例中,样本扩充基础包含以下至少之一:目标任务描述以及示例训练样本组;不同的样本扩充基础可以对应有不同的样本扩充方法;图2示出了本申请一示例性实施例提供的模型训练方法的流程图,该方法可以由计算机设备执行,该计算机设备中可以配置有大模型,该计算机设备可以实现为服务器,如图2所示,该模型训练方法可以包括以下步骤:
步骤202,通过大模型对接收到的用户指令文本进行解析,得到目标任务描述以及示例训练样本组,该示例训练样本组中包含任务样本以及任务样本标签;该用户指令文本用于指示对目标任务描述的模型进行训练。
步骤204,在样本扩充基础包含目标任务描述的情况下,基于目标任务描述从预先构建的数据集库中筛选出至少两个候选数据集。
该数据集库中可以包含大量数据集的数据集元信息,数据集可以包括私有数据集以及网络公开数据集;其中,数据集元信息可以包含以下至少之一:数据集名称、描述、摘要、字段信息、存储路径或者下载链接等等。
基于目标任务描述从预先构建的数据集库中筛选出至少两个候选数据集的过程可以实现为:
基于目标任务描述中的关键词对数据集库中的数据集进行筛选,得到至少两个候选数据集;
或者,
计算目标任务描述与数据集库中的各个数据集之间的向量相似度,并基于数据集库中的各个数据集各自对应的向量相似度筛选得到至少两个候选数据集。
其中,任务描述中的关键词可以是预先设置或指定的,任务描述中可以包含有一个或多个关键词;在通过关键词进行数据集筛选时,计算机设备可以基于数据库中各个数据集的元信息匹配上的关键词的数量筛选得到至少两个候选数据集。
步骤206,将至少两个候选数据集的数据集元信息分别与目标任务描述输入到数据集推荐模型中,得到至少两个候选数据集分别与目标任务描述之间的第一匹配分数。
该数据集推荐模型是通过第一正样本集与第一负样本集训练得到的;该第一正样本集中包含样本数据集的数据集元信息以及与样本数据集相匹配的任务描述标签;该第一负样本集中包含样本数据集的数据集元信息以及与样本数据集不匹配的任务描述标签。
在本申请实施例中,该数据集推荐模型可以是通过正样本集与负样本集训练得到的,其中,计算机设备可以通过大模型得到训练数据集推荐模型的训练样本集:计算机设备在获取到各个数据集的数据集元信息后,基于各个数据集的数据集元信息构建第一模型类型确定指令,将该第一模型类型确定指令输入到大模型中后,得到大模型输出的基于数据集可以训练的模型类型,从而生成数据集对应的任务描述标签,从而构建训练数据集推荐模型的正样本集以及负样本集。
以一个数据集为例,该第一模型类型确定指令可以为输入“以下数据集可以用来训练哪些自然语言处理模型?请根据提供的数据集信息,生成20个可以利用该数据集训练的模型解决相应自然语言处理任务的指令。
数据集名称:中文文本分类数据集
数据来源:xxxx客户端
数据格式:
`6552431613437805063_!_102_!_news_entertainment_!_新闻标题xxxx!_新闻关键词xxxx`
每行为一条数据,以_!_分割的字段,从前往后分别是新闻ID,分类code,分类名称,新闻字符串(仅含标题),新闻关键词;
分类code与名称:
…
100民生故事news_story
101文化文化news_culture
102娱乐娱乐news_entertainment
103体育体育news_sports
104财经财经news_finance
106房产房产news_house
107汽车汽车news_car
108教育教育news_edu
109科技科技news_tech
110军事军事news_military
112旅游旅游news_travel
113国际国际news_world
114证券股票stock
115农业三农news_agriculture
116电竞游戏news_game
…
数据规模:共382688条,分布于15个分类中。
采集时间:2018年05月”;
将上述第一模型类型确定指令输入到大模型中后,可以得到大模型的输出为:
“根据提供的中文文本分类数据集,可以训练以下NLP模型完成相应任务:
1.使用LSTM文本分类器,针对新闻标题进行15分类。
2.使用BERT预训练模型微调,针对新闻标题进行15分类。
3.使用TextCNN文本分类模型,针对新闻标题进行15分类。
4.使用FastText文本分类模型,针对新闻标题进行15分类。
5.使用文本聚类模型如KMeans对新闻标题进行无监督聚类。
6.使用Seq2Seq模型,针对新闻标题生成关键词。
7.使用Seq2Seq模型,针对新闻标题生成文章摘要。
8.使用Transformer模型,针对新闻标题生成文章正文。
9.使用关键词提取模型如TextRank对新闻标题进行关键词提取。
10.使用命名实体识别模型对新闻标题进行实体识别。
11.使用情感分析模型对新闻标题进行正负面情感判断。
12.使用语言模型如GPT-2针对新闻标题进行文本风格转换。
13.使用BERT Next Sentence Prediction任务微调进行新闻推荐/召回。
14.使用推荐系统模型如FM对新闻标题进行个性化推荐。
15.使用知识图谱模型抽取新闻标题中的实体和关系。
16.使用阅读理解模型针对新闻标题生成问答。
17.使用对话模型针对新闻标题进行闲聊。
18.使用文本匹配模型判断新闻标题的相似度。
19.使用文本生成模型如GPT-2根据新闻标题生成评论。
20.使用迁移学习方法,利用新闻分类模型进行其他文本分类任务。”
基于上述结果即可以得到该中文文本分类数据集所能训练的模型类型,从而生成该中文文本分类数据集对应的任务描述标签;其他数据集的任务描述标签的获取过程可以与上述中文文本分类数据集的任务描述标签的获取过程类似,此处不再赘述,之后,即可以根据各个数据集及其对应的任务描述标签构造正样本集;并通过对任务描述标签的替换更改构造负样本集。
通过上述正负样本集对数据集推荐模型进行训练,使得训练好的数据集推荐模型可以根据输入的任务描述以及数据集的数据集元信息计算任务描述与数据集的匹配分数。
步骤208,基于至少两个候选数据集各自对应的第一匹配分数筛选得到目标数据集。
计算机设备可以基于至少两个候选数据集各自对应的第一匹配分数对各个候选数据集进行排序,以将匹配分数最高的前N个候选数据集获取为目标数据集,其中,N为正整数,且N的取值可以基于实际需求进行设置。
进一步的,在获取到匹配分值最高的前N个候选数据集后,计算机设备可以将N个候选数据集通过交互界面进行展示,并基于接收到的数据集选择操作,确定N个候选数据集中的目标数据集。
步骤210,基于目标任务描述对目标数据集进行字段筛选得到训练样本组,以构建训练样本集。
由于数据集中可能包含有多个字段的字段信息,而在不同类型的模型的训练过程中,数据集中的有效字段不同,比如,在上述中文文本分类数据集中,在训练标题分类任务对应的模型时,数据集中的有效字段为“新闻字符串”以及“分类code”,其余字段为无效字段或者干扰字段,因此,在获取到目标数据集后,计算机设备需要进一步基于目标任务描述对数据集中的字段信息进行筛选,以提取出训练样本组,从而构建训练样本集。
由于部分数据集中的字段命名不规范或者没有字段命名,导致计算机设备无法筛选得到对应于目标任务描述的训练样本组,此时,计算机设备可以将目标数据集通过交互界面进行展示,并基于接收到的对目标数据集的任务输入字段和输出字段的选择操作后,提取出训练样本组,以构建训练样本集。
步骤212,在样本扩充基础包含示例训练样本组的情况下,将基于示例训练样本组构建样本扩充指令输入到大模型中,获得大模型输出的与示例训练样本组类型一致的训练样本组。
该样本扩充指令可以是用户基于示例训练样本组构建并输入的,或者,也可以是计算机设备基于示例训练样本组与相应的指令模板构建,本申请对此不进行限制。
示意性的,该样本扩充指令可以为“请根据以下示例进行20个示例扩充。
示例:
>标题:互联网公司百余员工吃团餐疑食物中毒:检测出沙门氏菌。
>分类:生活”
从而得到与该示例训练样本组类型一致的训练样本组,以增加训练样本集中的样本数量。
步骤214,基于大模型输出的训练样本组构建训练样本集。
将示例训练样本组与大模型输出的训练样本组确定为训练样本集中的训练样本组。
可选的,计算机设备还可以基于通过交互界面接收到的样本组选择操作对大模型输出的训练样本组进行筛选,将筛选后的训练样本组与示例训练样本组确定为训练样本集中训练样本组。
在本申请实施例中,计算机设备可以基于示例训练样本组构建训练样本集,也可以基于目标任务描述构建训练样本集,也可以两者结合构建训练样本集,本申请对此不进行限制。
步骤216,基于目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型。
在本申请实施例中,基于目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型的过程可以实现为:
将基础模型库包含的各个基础模型的模型元信息分别与目标任务描述输入到基础模型推荐模型中,得到各个基础模型分别与目标任务描述之间的第二匹配分数;该基础模型推荐模型是通过第二正样本集与第二负样本集训练得到的;该第二正样本集中包含样本基础模型的模型元信息以及与样本基础模型相匹配的任务描述标签;该第二负样本集中包含样本基础模型的模型元信息以及与样本基础模型不匹配的任务描述标签;
基于各个基础模型分别与目标任务描述之间的第二匹配分数筛选得到目标基础模型。
该基础模型推荐模型的训练过程与数据集推荐模型的训练过程类似,即通过正样本集与负样本集训练得到基础模型推荐模型;其中,计算机设备可以通过大模型得到训练基础模型推荐模型的训练样本集:计算机设备在获取到各个基础模型的模型元信息后,基于各个基础模型的模型元信息构建模型第二模型类型确定指令,将该第二模型类型确定指令输入到大模型中后,得到大模型输出的基于基础模型可以训练得到的模型类型,从而生成基础模型对应的任务描述标签,从而构建训练基础模型推荐模型的正样本集以及负样本集。通过上述正负样本集对基础模型推荐模型进行训练,使得训练好的基础模型推荐模型可以根据输入的基础模型的元信息以及任务描述计算任务描述与基础模型的匹配分数。
计算机设备可以基于各个基础模型各自对应的第二匹配分数对各个基础模型进行排序,以将匹配分数最高的前M个基础模型获取为目标基础模型,其中,M为正整数,且M的取值可以基于实际需求进行设置。
进一步的,在获取到匹配分值最高的前M个基础模型后,计算机设备可以将M个基础模型通过交互界面进行展示,并基于接收到的基础模型选择操作,确定M个基础模型中的目标基础模型。
步骤218,基于训练样本集对目标基础模型进行训练,得到目标模型,该目标模型用于处理目标任务描述对应的自然语言处理任务。
计算机设备可以基于训练样本集对目标基础模型进行微调以得到目标模型。
可选的,计算机设备在基于训练样本集对目标基础模型进行训练之前,还可以将训练样本集中的部分样本组划分为测试集,以在目标模型训练完成后,对目标模型的模型效果进行评估,在此情况下,计算机设备可以通过大模型以及目标任务描述来生成模型评估指标,该过程可以实现为:
将基于目标任务描述构建的模型评估指标生成指令输入到预先训练好的大模型中,获得大模型输出的模型评估指标。
模型评估生成指令可以是由用户基于目标模型构建的,或者,也可以是由计算机设备基于目标模型以及对应的指令模板构建的,本申请对此不进行限制。
该模型评估生成指令中可以包含模型功能信息,示意性的,该模型评估生成指令可以是“现有一个NLP模型,功能是“判断输入的新闻标题属于哪个分类:生活、娱乐、房产、财经、体育、旅游、科技、军事。只输出分类名称,不需要解释。”,请问需要计算哪些评估指标来评价模型的效果?请用JSON格式输出”;大模型的输出结果可能是“"metrics":["accuracy","precision","recall","F1 score"]”。
其中,accuracy即准确率是指计算模型分类结果中正确预测的样本占所有样本的比例,反映模型的整体分类性能。
precision即精确率是指计算每个类别中,模型预测为正样本且真实也为正样本的比例,反映模型的准确性。
recall及召回率是指计算每个类别中,模型预测为正样本的比例,反映模型的覆盖面。
F1 score即F1值是指精确率和召回率的调和均值,综合反映准确性和覆盖面。
需要说明的是,上述模型评估指标生成指令的描述方式,以及大模型输出的模型评估指标的内容均为示意性的,本申请对此不进行限制。
在得到模型评估指标后,计算机设备可以基于模型评估指标评价目标模型的模型效果,从而实现了模型评估环节的自动化。
综上所述,本申请实施例提供的模型训练方法,计算机设备通过大模型接收并解析用户指令文本获得目标任务描述以及示例训练样本组,并基于目标任务描述和/或示例训练样本组进行样本扩充,以得到训练样本集;根据目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型;通过训练样本集对目标基础模型进行模型训练,得到用于处理目标任务描述对应的自然语言处理任务的目标模型。通过上述方法,计算机设备可以利用大模型的知识和语言理解能力将样本选择、补充样本生成、模型选择、模型训练以及模型评估过程自动化,从而减少模型训练过程中所需的人为操作,降低模型开发成本,提高模型训练效率。
图3示出了本申请一示例性实施例提供的模型训练方法的架构图,如图3所示,计算机设备在接收到用户指令文本后,对该用户指令文本进行解析,得到目标任务描述以及示例训练样本组,基于目标任务描述进行基础模型选择,以及,基于目标任务描述以及示例训练样本组训练样本集构建,其中,训练样本集构建包含数据集选择以及数据集生成两种方式;将训练样本集中的一部分划分为测试集,另一部分对目标基础模型进行模型训练,以获得目标模型,之后,通过确定好模型评估指标的测试集对目标模型进行评估,以评估目标模型的模型效果。
图4示出了本申请一示例性实施例提供的模型训练装置的方框图,该模型训练装置可以用于执行如图1或图2实施例所示的全部或部分步骤,如图4所示,该模型训练装置可以包括:
文本解析模块410,用于通过大模型对接收到的用户指令文本进行解析,得到目标任务描述以及示例训练样本组,所述示例训练样本组中包含任务样本以及任务样本标签;所述用户指令文本用于指示对所述目标任务描述的模型进行训练;
样本扩充模块420,用于基于样本扩充基础进行样本扩充,得到训练样本集;所述样本扩充基础包含以下至少之一:所述目标任务描述以及所述示例训练样本组;
模型获取模块430,用于基于所述目标任务描述从预先构建的基础模型库中获取所述目标任务描述对应的目标基础模型;
模型训练模块440,用于基于所述训练样本集对所述目标基础模型进行训练,得到目标模型,所述目标模型用于处理所述目标任务描述对应的自然语言处理任务。
在一种可能的实现方式中,所述样本扩充模块420,包括:
数据集筛选子模块,用于在所述样本扩充基础包含所述目标任务描述的情况下,基于所述目标任务描述从预先构建的数据集库中筛选出至少两个候选数据集;
第一分数获取子模块,用于将至少两个候选数据集的数据集元信息分别与所述目标任务描述输入到数据集推荐模型中,得到至少两个候选数据集分别与所述目标任务描述之间的第一匹配分数;所述数据集推荐模型是通过第一正样本集与第一负样本集训练得到的;所述第一正样本集中包含样本数据集的数据集元信息以及与样本数据集相匹配的任务描述标签;所述第一负样本集中包含样本数据集的数据集元信息以及与样本数据集不匹配的任务描述标签;
第一筛选子模块,用于基于至少两个候选数据集各自对应的所述第一匹配分数筛选得到目标数据集;
数据集构建子模块,用于基于所述目标任务描述对所述目标数据集进行字段筛选得到训练样本组,以构建所述训练样本集。
在一种可能的实现方式中,所述数据集筛选子模块,用于,
基于所述目标任务描述中的关键词对所述数据集库中的数据集进行筛选,得到至少两个候选数据集;
或者,
计算所述目标任务描述与所述数据集库中的各个数据集之间的向量相似度,并基于所述数据集库中的各个数据集各自对应的向量相似度筛选得到至少两个候选数据集。
在一种可能的实现方式中,所述样本扩充模块420,包括:
样本组获取子模块,用于在所述样本扩充基础包含所述示例训练样本组的情况下,将所述样本扩充指令输入到所述大模型中,获得所述大模型输出的与所述示例训练样本组类型一致的训练样本组;
所述样本集构建子模块,用于基于所述大模型输出的训练样本组构建所述训练样本集。
在一种可能的实现方式中,所述模型获取模块430,包括:
第二分数获取子模块,用于将所述基础模型库包含的各个基础模型的模型元信息分别与所述目标任务描述输入到基础模型推荐模型中,得到各个基础模型分别与所述目标任务描述之间的第二匹配分数;所述基础模型推荐模型是通过第二正样本集与第二负样本集训练得到的;所述第二正样本集中包含样本基础模型的模型元信息以及与样本基础模型相匹配的任务描述标签;所述第二负样本集中包含样本基础模型的模型元信息以及与样本基础模型不匹配的任务描述标签;
第二筛选子模块,用于基于各个基础模型分别与所述目标任务描述之间的第二匹配分数筛选得到所述目标基础模型。
在一种可能的实现方式中,所述装置还包括:
评估指标获取模块,用于将基于所述目标任务描述构建的所述模型评估指标生成指令输入到预先训练好的大模型中,获得所述大模型输出的模型评估指标。
在一种可能的实现方式中,所述装置还包括:
模型评估模块,用于基于所述模型评估指标评价所述目标模型的模型效果。
综上所述,本申请实施例提供的模型训练装置,通过大模型接收并解析用户指令文本获得目标任务描述以及示例训练样本组,并基于目标任务描述和/或示例训练样本组进行样本扩充,以得到训练样本集;根据目标任务描述从预先构建的基础模型库中获取目标任务描述对应的目标基础模型;通过训练样本集对目标基础模型进行模型训练,得到用于处理目标任务描述对应的自然语言处理任务的目标模型。通过上述方法,计算机设备可以利用大模型的知识和语言理解能力将样本选择、补充样本生成、模型选择以及模型训练过程自动化,从而减少模型训练过程中所需的人为操作,降低模型开发成本,提高模型训练效率。
图5示出了本申请一示例性实施例示出的计算机设备500的结构框图。该计算机设备可以实现为本申请上述方案中的服务器。所述计算机设备500包括中央处理单元(Central Processing Unit,CPU)501、包括随机存取存储器(Random Access Memory,RAM)502和只读存储器(Read-Only Memory,ROM)503的系统存储器504,以及连接系统存储器504和中央处理单元501的系统总线505。所述计算机设备500还包括用于存储操作系统509、应用程序510和其他程序模块511的大容量存储设备506。
不失一般性,所述计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括RAM、ROM、可擦除可编程只读寄存器(Erasable Programmable Read Only Memory,EPROM)、电子抹除式可复写只读存储器(Electrically-Erasable Programmable Read-OnlyMemory,EEPROM)闪存或其他固态存储其技术,CD-ROM、数字多功能光盘(DigitalVersatile Disc,DVD)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机存储介质不局限于上述几种。上述的系统存储器504和大容量存储设备506可以统称为存储器。
根据本申请的各种实施例,所述计算机设备500还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备500可以通过连接在所述系统总线505上的网络接口单元507连接到网络508,或者说,也可以使用网络接口单元507来连接到其他类型的网络或远程计算机系统(未示出)。
所述存储器还包括至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、至少一段程序、代码集或指令集存储于存储器中,中央处理器501通过执行该至少一条指令、至少一段程序、代码集或指令集来实现上述各个实施例所示的模型训练方法中的全部或部分步骤。
在一示例性实施例中,还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有至少一条计算机程序,该计算机程序由处理器加载并执行以实现上述模型训练方法中的全部或部分步骤。例如,该计算机可读存储介质可以是只读存储器(Read-OnlyMemory,ROM)、随机存取存储器(Random Access Memory,RAM)、只读光盘(Compact DiscRead-Only Memory,CD-ROM)、磁带、软盘和光数据存储设备等。
在一示例性实施例中,还提供了一种计算机程序产品,该计算机程序产品包括至少一条计算机程序,该计算机程序由处理器加载并执行上述图1或图2任一实施例所示的模型训练方法的全部或部分步骤。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由下面的权利要求指出。
应当理解的是,本申请并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本申请的范围仅由所附的权利要求来限制。
- 机器学习模型训练方法、装置、存储介质和计算机设备
- 语句输出、模型训练方法、装置、计算机设备及存储介质
- 分类器训练方法、装置、设备和计算机可读存储介质
- 一种神经网络训练方法、装置、计算机设备和存储介质
- 一种模型训练方法、计算机可读存储介质及计算设备
- 模型训练方法、模型训练装置、计算机设备和存储介质
- 模型训练方法、模型训练装置、计算机设备和存储介质