用于监控通过物流网络运输中的包裹的系统、装置和计算机实现的方法
文献发布时间:2024-07-23 01:35:21
相关申请
本申请要求于2021年11月30日提交的、并且标题为“SYSTEMS,APPARATUS,ANDCOMPUTER-IMPLEMENTED METHODS FOR MONITORING PACKAGES IN TRANSIT THROUGH ALOGISTICS NETWORK”的美国临时申请第63/284,615号的优先权,其全部内容通过引用并入本文。
技术领域
本公开总体上涉及装运管理和物流领域中的系统、装置、计算机可读介质和方法,并且更特别地涉及包括用于各种增强和改进的物流监控能力的系统、装置、计算机可读介质和方法的各种方面,以确定有晚于规定承诺时间交付风险的包裹。
背景技术
物流网络将包裹从始发地运送到目的地。大型物流网络可能以庞大规模运营,其中每天都有数百万件包裹贯穿国家运送以及在全球范围内跨国运送。如此大的物流网络可能涉及数百架飞机、数万辆卡车/货车、和数十万名团队成员。此外,这些物流网络在运营上可能非常复杂,例如,包裹有确切日期、确切时间、具有不同的运输日期、数百种服务类型,并通过不同的运送模式(包括公路、航空和铁路)移动。网络运营可能随时间和星期几而变化。附加地,网络可能受季节性影响,其中峰值运量大约是非峰值运量的1.5至2倍。此外,新的设施和新的运送路段和模式可能不断增加,使得网络计划需要持续发展以适应改变的运量和网络配置。
对于由物流网络运送的任何给定包裹,所购买的服务类型可以规定将包裹从始发地运送到目的地的承诺时间。因此,客户可以购买特定包裹所需的服务水平。然而,由于任何数量的原因,通过物流网络运输的包裹可能经历延迟或正常运送时间表的其他异常。天气、交通、设备故障、内部网络运营错误等都影响包裹的运送。因此,一些包裹可能在规定的承诺时间后交付。
虽然在一些状况下晚于预期交付可能无伤大雅,但在其他状况下,晚于预期交付可能具有更严重的后果。因此,尤为重要的是,可知道将交付迟到的包裹。然而,物流网络的传统计算机系统缺乏向物流网络运营商的人员或向客户提供这种包裹级洞察的能力。因此,在任何给定时间对于任何一个大规模客户来说,这种确定可能需要人工调查潜在的数百或甚至数千个运输中的包裹。监控运输中的包裹以确定哪些包裹可能潜在地迟到到达目的地成为一项巨大且繁重的任务,其需要投入大量且昂贵的人员和时间,这可能导致并不能识别所有相关包裹。
为了解决这些问题中的一个或多个,需要更有能力、更智能的设备配置,以从网络的历史运营中学习,并在监控物流网络内的包裹运送时应用那些学习,以识别有晚于预期交付风险的那些包裹。
发明内容
在以下描述中,某些方面和实施例将变得清楚,因为其总体上针对物流运营的技术解决方案,其涉及为处理系统提供训练网络运营的模型的能力,所述模型基于对历史物流网络数据的分析,为包裹在始发地和目的地之间的运输时预期会遇到的事件指定阈值。此外,某些方面和实施例将变得清楚,因为这些方面和实施例总体上针对相对于指定阈值来监控包裹的事件,以确定哪些包裹有晚于规定的承诺时间被交付的风险,使得可以为人员和/或客户识别那些有风险的包裹。应当理解,这些方面和实施例在其最广泛的意义上可以在不具有这些方面和实施例的一个或多个特征的情况下实践。应当理解,这些方面和实施例仅仅是示例性的。
在本公开的一个方面中,描述了一种用于监控物流网络内包裹运送的计算机系统。该计算机系统包括到至少一个物流网络数据源的接口。该计算机系统包括包含历史网络数据的第一数据存储模块,该第一数据存储模块耦合到接口,以根据来自物流网络数据源的数据馈送来构建历史网络数据。该计算机系统包括包含包裹运送模型数据的第二数据存储模块。该计算机系统包括第一处理系统,该第一处理系统访问数据存储设备并将机器学习应用于历史网络数据以训练包裹运送模型数据。第一处理系统捕获数据驱动模式,其包括历史事件的预期位置、历史事件的预期类型和历史事件的预期时间。根据数据驱动模式,第一处理系统为通过物流网络从第一位置运送到最终位置的假设包裹创建一组预测事件,并为每个预测事件确定阈值,以便假设包裹在规定时间前到达最终位置,每个阈值与假设包裹的预测事件发生的预期时间相关,其中预测事件与预期位置和预期类型相关。该计算机系统包括第二处理系统,该第二处理系统耦合到该接口以接收来自物流网络的实况数据,该实况数据包括关于运输中的真实包裹的数据,该第二处理系统从第二数据存储访问运送模型数据以将阈值应用于真实包裹的预测事件,并且该第二处理系统基于阈值的应用与每个预测事件相关地评估真实包裹是否如期交付到最终位置。
在本公开的另一方面中,描述了一种用于找出包裹在规定时间之后交付至最终位置的风险水平的计算机系统。该计算机系统包括第一处理系统,该第一处理系统为包裹在第一位置和最终位置之间的每个预期事件确定阈值。该计算机系统包括第二处理系统,当包裹在运输中时,该第二处理系统针对每个预期事件,通过对应于每个预期事件的阈值来确定事件是否发生。在包裹运输期间的时间点,第二处理系统基于超过最新近预期事件的阈值的延迟量来确定包裹在规定时间之后被交付的风险水平。
本公开的另一方面集中于一种找出包裹在规定时间之后交付至最终位置的风险水平的计算机实现的方法。该方法涉及为包裹在第一位置和最终位置之间的每个预期事件确定阈值。该方法涉及,当包裹在运输中时,对于每个预期事件,通过对应于每个预期事件的阈值来确定事件是否发生。附加地,该方法涉及在包裹运输期间的时间点,基于超过最新近预期事件的阈值的延迟量来确定包裹在规定时间之后被交付的风险水平。
本公开的另一方面集中于一种用于监控物流网络内包裹运送的计算机实现的方法。该方法涉及将机器学习应用于物流网络的历史网络数据,以训练包裹运送模型数据。机器学习通过捕获包括历史事件的预期位置、历史事件的预期类型和历史事件的预期时间的数据驱动模式来训练包裹运送模型数据。机器学习还通过为通过物流网络从第一位置运送到最终位置的假设包裹创建一组预测事件,并且通过为每个预测事件确定阈值以便假设包裹在规定时间前到达最终位置,来从数据驱动模式训练包裹运送模型数据,每个阈值与假设包裹的预测事件发生的预期时间相关,其中预测事件与预期位置和预期类型相关。
这些方面中的每一个分别实现了对物流运营技术的改进,其涉及监控通过物流网络运输中的包裹的事件,以找出有在规定的承诺时间之后交付风险的那些包裹。所公开的实施例和示例的这一方面和其他方面的附加优点将在下面的描述中部分地阐述,并且部分地将从描述中而清楚,或者可以通过本发明的实践来了解。应理解,前面的总体描述和下面的详细描述都仅仅是示例性和解释性的,并且不是对所要求保护的本发明的限制。
附图说明
并入本说明书中并构成本说明书的一部分的所附附图示出了根据本发明的一个或多个原理的若干实施例,并与说明书一起用于解释本发明的一个或多个原理。在附图中,
图1是根据本发明的实施例的示例性物流网络的示意图,该示例性物流网络包括包裹数据收集,该包裹数据收集可以用于训练物流网络运营的模型,并且还用于通过将该模型应用于实况包裹数据来实时监控包裹的目的,以确定物流网络内的包裹在规定时间之后交付的风险。
图2是示例性计算机系统的示意图,该示例性计算机系统可以包括一个或多个处理系统,该一个或多个处理系统实施一个或多个模块以训练网络运营模型,并实施一个或多个模块以通过应用该模型来实时监控包裹以确定风险。
图3是示意图,其展示了监控包裹以检测有在规定时间之后交付风险的包裹的三个示例性方面,这三个示例性方面包括模型训练、模型评分和可配置输出。
图4是流程图,其示出了训练物流网络运营模型的示例性方法,该模型包括预测事件、预测事件的相关联阈值、以及与事件的实时延迟发生相关联的风险。
图5是可以由处理系统(诸如图2中所示的处理系统)执行以训练物流网络运营模型的示例性模块的示意图。
图6是示例性直方图,其示出了如图4和图5中所述的事件宽裕时间的分布,并展示了根据事件宽裕时间的分布确定要包括在模型中的事件阈值。
图7是流程图,其示出了为物流网络内运送的包裹预期发生的预测的当前事件确定事件阈值的示例性方法。
图8A和图8B示出了流程图,其示出了一种确定在对应的当前事件发生后,物流网络内运送的包裹预期将发生的预测的下一事件的位置和类型的示例性方法。
图9A和图9B示出了流程图,其示出了一种确定风险表的值的示例性方法,该风险表提供了与每个预测事件的延迟量相关联的风险。
图10是流程图,其示出了使用模型对与预测事件相关的包裹的风险进行评分的示例性方法,该示例性方法涉及对预测事件的风险进行反应性和前摄性评分两者。
图11是流程图,其示出了使用模型为包裹提供与预测的当前事件的发生相关的风险的反应性评分的示例性方法。
图12是流程图,其示出了使用模型为包裹提供与当前事件发生后预测的下一事件的未发生相关的风险前摄性评分的示例性方法。
图13是流程图,其示出了该模型的风险聚集器方面的示例性方法,用于从预测的下一事件(一旦预测事件已经发生,其就成为当前事件)的角度来建立预测事件的风险水平。
图14是流程图,其示出了响应于由模型确定的风险水平对包裹按新路线发送的示例性方法。
图15是示出由于风险水平而变得按新路线发送的包裹的示例性事件时间线的示意图。
图16是流程图,其示出了根据与如由模型提供的预期运送路径相关的装运前恶劣条件建议找出包裹风险的示例性方法。
图17是示出呈现关于物流网络内运输中的包裹的信息的示例性用户接口的屏幕截图,所述信息包括有晚于规定时间交付风险的包裹。
图18是示出呈现关于物流网络内运输中的包裹的信息的示例性用户接口的屏幕截图,所述信息包括处于有晚于规定时间交付的不同风险水平的包裹。
图19是示出呈现关于物流网络内运输中的包裹的信息的示例性用户接口的屏幕截图,所述信息包括指示包裹有晚于规定时间交付风险的事件正在发生的位置,其包括用于控制所显示信息的性质的过滤器。
具体实施方式
现在将详细参考各种示例性实施例。只要有可能,在附图和描述中使用相同的附图标记来指代相同或相似的部分。然而,本领域技术人员将领会,不同的实施例可以根据相应实施例的预期部署和操作环境的需要,以不同的方式实现特定的部分。
总体而言,下文描述了系统、装置、计算机可读介质和方法的各种实施例,它们从包裹在物流网络内运输时遇到的事件的时序和位置的角度创建物流网络运营的模型。为预期针对包裹发生的事件确定阈值,其中那些阈值提供了一种方式,即与包裹在运输时预测会遇到的每个事件相关地确定该包裹是否有在晚于规定时间(诸如收货人预期被满足的承诺时间)被交付的风险。
本领域技术人员还将领会,本文所述的每个实施例对特定技术(诸如监控包裹装运、物流运营和相关基础设施的系统)进行了改进。每个实施例描述了一种特定的技术应用,该技术应用利用并应用创建物流网络事件的模型并使用该模型来监控通过物流网络的运输中的包裹以识别有在规定的承诺时间之后被交付风险的那些包裹的特定实施例。识别那些有风险的包裹的监控允许在物流网络内以及在客户水平采取相关的动作,其中特定的技术应用改进或者以其他方式增强了这样的技术领域,如下面的公开内容所解释和支持的。
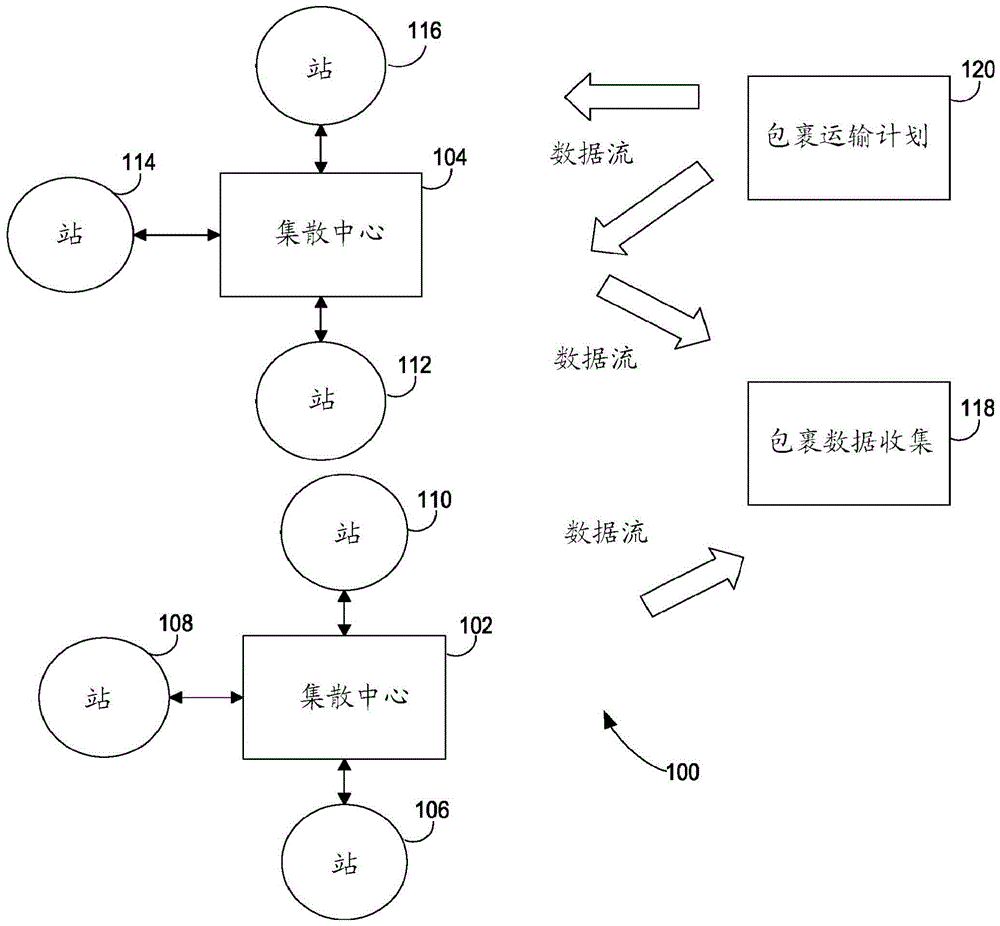
图1示出了示例性物流网络100的一部分,该示例性物流网络100用于在始发地和最终位置(也称为目的地)之间运送包裹。该示例的物流网络100可以包括任意数量的设施。集散中心102、104是包裹到达、被分拣以便向前运送到另一个集散中心或运送到与该集散中心相关联的站106、108、110、112、114或116的设施的示例。包裹可以从集散中心102、104运送到相关联的站,在那里包裹然后可以被按路线发送到目的地。
当包裹正通过物流网络100运送时,包裹遇到各种事件,其中物流网络100收集关于包裹的信息。然后,在计算机系统118处收集该数据,该计算机系统118诸如是维护包裹和事件信息的一个或多个数据库的一个或多个服务器计算机。这些事件可以是扫描事件,诸如其中来自标签或来自电子电路的条形码、QR码或类似的可读码(诸如位于包裹上的射频识别电路(RFID)标签)可以被扫描。这些事件还可以包括由包裹上的发射机发起的通信,诸如有源RFID标签、近场发射机、或向接收设备传输包裹信息的
这些事件可能发生在运输中包裹的每个里程碑处。例如,在远程位置处收取包裹后,一事件可能发生。当包裹到达站时,另一事件可能发生。当包裹经过站内的分拣或装载台时,另一事件可能发生。当包裹从站出发前往集散中心时,另一事件可能发生。当包裹到达集散中心时,另一事件可能发生。当包裹在集散中心处分拣时,另一事件可能发生,等等。每个事件识别包裹以及事件的时间和位置,使得包裹在任何给定时间在物流网络100内的位置是已知的。
当包裹通过物流网络运输时其遵循的特定路径和时序由计划定义。包裹运输计划系统120(诸如一个或多个服务器计算机)可以为每个包裹确定适当的运输计划,并且将数据提供给包括集散中心和站的各种设施,使得在每个事件识别的包裹可以被分拣和装载,以遵循计划中提出的路径。该计划还可以指定应当将包裹交付到最终目的地的规定时间,其中可以选择路径。然而,由于各种因素,该包裹可能经历延迟和其他与初始计划的背离。
图2示出了示例性计算机系统200,其可以用于基于已经在包裹数据收集系统118处捕获的历史数据对物流网络进行建模。然后,示例性计算机系统200还可以将该模型应用于来自物流网络100的实时数据流,以确定任何包裹晚于规定时间被交付的风险水平。计算机系统200可以包括到物流网络100的数据源的接口202,该物流网络100包括数据收集118。经由包裹数据接口202从物流网络100流式传输到计算机系统200的数据可以使用典型的数据清理技术进行准备和清理。例如,数据接口可以过滤掉可能与针对模型的训练活动或评分活动无关的事件。
包裹数据存储模块204收集准备好的历史网络事件数据,供在用于模型的训练活动和评分活动两者的后续过程中使用。出于模型训练的目的,包裹数据存储204可以向第一处理系统210提供物流网络100的历史事件数据。出于模型评分的目的,包裹数据存储204可以在实况数据从物流网络100流式传输到第二处理系统218时提供它。虽然第一处理系统210和第二处理系统218在图2中被示为单独的项目,但是将领会,这些处理系统可以由实现用于模型训练和评分目的的单独功能模块的单个计算机或单个计算机集合来提供。此外,将领会,当在本文中提及计算机、服务器计算机、计算机系统和处理系统时,这些可以包括一个或多个通用可编程处理器、一个或多个专用处理器、硬连线数字逻辑和/或这种设备的各种组合。
第一处理系统210可以执行操作以根据已经在一段时间内从物流网络100捕获的历史事件数据来训练代表物流网络100内发生的事件的模型。此外,第一处理系统210可以重复地执行模型训练,以考虑可能随时间发生的物流网络100的新方面。例如,可以在现有的设施集合内引入新事件,并且在包裹数据存储204内维护的历史数据内捕获这些新事件,使得第一处理系统210可以继续训练模型以并入新事件。此外,新设施的添加可以向包裹数据存储内维护的历史数据中引入新事件,使得第一处理系统210可以继续训练模型以并入对应于新设施的新事件。以这种方式,计算机系统200允许模型与物流网络100一起缩放,并且从而保持网络100的模型是当前的,使得用于评分的模型的实时应用考虑到演进的网络100。
此外,计算机系统200不限于单个物流网络100或物流网络100的运营商。当训练模型时,计算机系统(并且具体是第一处理系统210)可以并入不同的网络,只要来自这些附加网络的历史事件数据是可用的,而不考虑运营商。附加地,只要来自不同网络的实况事件数据的流式传输可用,计算机系统200(并且具体是第二处理系统218)就可以针对不同网络内的包裹对模型进行评分。
关注第一处理系统210,在该示例性计算机系统200中,包括提供机器学习以训练模型的两个子系统。第一子系统212从已经捕获的历史事件数据中实现机器学习,以提供包裹指纹计算来创建定义模型的包裹指纹。包裹指纹描述了当包裹从特定的第一位置(诸如包裹的起始位置)运输到作为包裹目的地的特定最终位置时预期会遇到的事件。从网络捕获的构成历史数据的事件以及包裹指纹中特定的事件被识别为具有几个特性。例如,事件可以被识别为具有以下三个特性:事件发生的位置、事件发生的类型以及事件发生的时间。
包括在为事件指定的模型的包裹指纹中的时间是对于将如期在规定时间前交付到最终位置的假设包裹而言,事件应该发生的最晚时间。因此,模型中事件的这一时间被称为包裹阈值。该包裹阈值是通过从历史数据中进行机器学习来确定的,其中在历史数据内表示的给定位置和给定类型的事件通常在一系列时间内发生。下面参考图4-图8B更详细地描述产生阈值的第一子系统212的机器学习操作的示例。
第一处理系统210将通过机器学习从历史数据确定的所有已知包裹事件的包裹指纹存储在包裹指纹存储模块216中并且作为包裹运送模型数据形成模型,该包裹指纹存储模块216可以是数据库。然后可以使包裹指纹数据从包裹指纹存储216可用于第一处理系统210的其他子系统,其包括用于包裹风险表计算的第二子系统214。第二子系统214使用包裹指纹数据来针对假设包裹找出针对超过假设包裹的包裹指纹中的每个预测事件的包裹阈值的不同延迟量被交付到特定最终位置的风险水平。下面关于图9A和图9B更详细地描述在第二子系统214处确定风险表中的条目。
使第二子系统214的风险表和来自第一子系统212和存储216的包裹指纹可用于第二处理系统218,用于针对实时包裹数据进行模型评分的目的。第二处理系统218在使用模型评分时应用包裹阈值,以通过还接收从物流网络100流式传输的实况数据来实时确定超出真实包裹的包裹阈值的预测事件的延迟量。在确定真实包裹在特定预测事件已经发生的延迟量(如果有的话)后,第二处理系统218然后可以找出包裹在规定时间之后被交付到最终位置的对应风险水平。下面关于图10-图13更详细地描述对运输中的真实包裹的风险水平的确定。
除了基于来自第二子系统214的风险表的风险确定之外,第二处理系统218还可以接收为运送包裹造成恶劣条件的外部因素的风险信息。与这种外部因素相关的外部数据源206可以将数据流式传输到计算机系统200,并且更具体地,流式传输到外部因素/风险存储208和第二处理系统218。例如,外部因素可以包括可能导致延迟的天气、交通、停电等,这些可以提前于包裹从一个位置运送到另一个位置进行预报,而不是仅相对于事件的包裹阈值来确定。第二处理系统218可以通过具有来自包裹指纹的预测路径来进行这种延迟风险的提前预测,从而然后评估包裹预期进行的每段行程的预报延迟风险。下面关于图16更详细地描述了对来自外部源的风险的确定。
一旦已经对物流网络100内运输中的真实包裹的风险水平进行了评估,下游消费者就可获得关于该真实包裹和风险水平的信息。可以从第二处理系统218立即生成警报,以引起对关于包裹丢失事件或具有显著风险水平的特定情形的注意。此外,关于包裹和风险水平的信息可以被提供给另一存储设备220,该另一存储设备220维护当前在物流网络100内运输中的每个真实包裹的最新风险评估。附加地,一个或多个第三处理系统222、224可以访问信息以经由用户应用向一个或多个实体提供信息。例如,一个系统222可以充当web服务器,并且经由到专用应用或者客户经由互联网访问的网站的数据馈送向预期接收包裹的客户提供信息。另一系统224可以向运营物流网络100的装运实体的人员提供信息。
将从系统222或224提供的信息作为设备上的显示进行查看的人可以能够快速看到哪些包裹有在规定时间之后被交付的风险。因此,此人不需要对此人希望监控的每一个包裹的信息进行翻查以得到准时交付状态,因为只有那些有在规定时间之后被交付的风险的包裹才需要注意。此外,可以给予此人进一步的选项,其包括查看有在规定时间之后被交付的风险的任何包裹的特定于包裹的信息。可以给予装运实体的人员附加的特征,其包括诸如由客户过滤物流网络100中的任何包裹的信息的能力,以及识别物流网络100内包裹变得有风险的特定设施、星期几等的能力,以进一步识别网络内的潜在故障点。下面参考图17-19更详细地讨论这种用户接口的示例的屏幕截图。
除了提供关于有晚于规定交付时间风险的包裹的用于显示的信息外,还可以与第四处理系统226共享关于有风险包裹的信息,该第四处理系统226执行物流网络的包裹运输计划。第四处理系统226可以是包裹运输计划系统120的子系统,该子系统确定包裹将被交付到最终位置所遵循的通过物流网络100的实际路径。因此,在沿着针对包裹的预期路径的任何给定设施处,第四处理系统226可以确定有更好的路线可用,用于增加在规定时间前交付包裹的可能性的目的。在包裹采用新路线后,第二处理系统218然后可以使用沿着新路线发生的事件来确定风险水平,使得在用于包裹运输计划的第四处理系统226和用于经由模型评分进行风险确定的第二处理系统218之间提供闭环系统。
例如,在包裹的装运前阶段,外部因素(诸如在包裹预期到达设施或从设施出发时在该设施处的恶劣天气的天气预报)可能示出包裹的风险,其触发第四处理系统226创建新计划以通过不同设施按路线发送包裹。同样地,由于在运输期间违反包裹阈值而确定的风险水平可以触发第四处理系统226创建新的计划来将包裹通过不同的设施按路线发送,以试图减少与包裹将遇到的后续事件相关联的延迟量。在这两种情况下,第二处理系统218评估包裹被交付到最终位置的风险,并且该风险信息作为反馈被提供给第四处理系统226。
图3示出了示意图,其展示了计算机系统200的功能的概览300。这里可以看出,根据来自物流网络100的历史数据捕获事件的模型训练发生在概览步骤302。这涉及第一处理系统210的操作,其中确定了包括预测事件和每个事件的对应包裹阈值的包裹指纹,以及相对于包裹阈值的不同延迟量的相关联风险水平。然后在概览步骤304发生模型评分。这涉及第二处理系统218的操作,一旦当前事件发生,第二处理系统218就反应性地将包裹指纹的包裹阈值与当前事件进行比较,以及在等待预测的下一事件发生时,前摄性地将包裹阈值与它们进行比较。然后,在概览步骤306,已经确定的风险水平以及丢失事件的异常一起可以经由显示的用户接口上的可配置输出提供给下游消费者。
图4是为模型训练目的而执行的、并且可以由第一处理系统210执行的机器学习步骤400的流程图。最初,在步骤402,第一处理系统210提取历史数据,该历史数据包含在特定时间范围内已交付包裹的事件类型、事件时间和事件位置。事件类型可以指定事件是否是收取、到达、出发、交付等。事件时间可以指定一天中的时间和星期几。事件位置可以指定事件发生的位置,包括物流网络100内的任何设施或事件发生的任何其他位置。然后在步骤404,由第一处理系统210实现的第一模块(模块1)计算所有事件的宽裕时间,并将宽裕时间分类到宽裕时间分区中。宽裕时间是在事件时间和规定时间之间的时间量,该规定时间是交付应被视为准时发生的最晚时间。将事件的宽裕时间分类到宽裕时间分区中有效地构建了直方图,并且下面参考图5和图6更详细地讨论一个示例。
一旦对来自历史数据的所有事件的宽裕时间进行了分类,则第二模块的第一部分(模块2.1)就在步骤406为假设包裹的每个预测的当前事件找出阈值。通过为预测的当前事件的位置计算特定于准时包裹的所有宽裕时间的期望百分位数,找出每个预测的当前事件的阈值。对于该假设包裹的预测的当前事件,该假设包裹具有最终目的地,正与特定产品类型一起装运,并且具有在一周中的特定一天交付的规定承诺时间。产品类型与为运送假设包裹所提供的服务(诸如地面服务、次日服务、国际服务等等)的水平相关。因此,在步骤406确定的每个阈值与具有这几个特性的假设包裹的预测的当前事件相关联,这然后允许正确选择预测的当前事件以包括在具有与假设包裹相同特性的真实包裹的包裹指纹中。下面参考图7更详细地描述如在步骤406中确定阈值所采取的子步骤流程的示例。
一旦已经为网络中所有可能的预测的当前事件确定了包裹阈值,则第二模块的第二部分(模块2.2)就在步骤408找出特定当前事件之后的预测的下一事件位置和类型。为了找出特定当前事件之后的预测的下一事件位置和类型,使用特定当前事件之后的潜在预测的下一事件的宽裕时间直方图,并再次使用期望百分位数来确定潜在的下一事件的阈值,来找出特定当前事件之后的所有潜在预测的下一事件的阈值。选择具有最新阈值的潜在的下一事件作为包裹指纹的预测的下一事件位置和类型。下面参考图8A和图8B更详细地描述如在步骤408中确定预测的下一事件位置和类型所采取的子步骤的流程的示例。
一旦已经确定了所有预测的下一事件,则第二模块的第三部分(模块2.3)就在步骤410组合模块2.1和2.2的输出。因此,对于具有确定阈值的给定假设包裹的给定预测的当前事件,模块2.3加入适当的预测的下一事件位置和类型以及已经在模块2.1中确定的预测的下一事件的阈值。与已经由模块2.2选择的预测的下一事件一起使用的阈值不是由模块2.2找出的阈值,而代替地是当该预测的下一事件位置和类型被认为是模块2.1中的预测的当前事件时为该预测的下一事件位置和类型计算的阈值。通过使用模块2.1的输出作为每个预测的下一事件的阈值,这移除了在找出该预测的下一事件的阈值时对预测的下一事件之前的预测的当前事件的任何依赖性。这与当前事件的反应性评分和下一事件的前摄性评分相关,这在下面关于图10-图13进行讨论。模块2.3的输出——其组合了模块2.1的预测的当前事件和模块2.2的预测的下一事件——的示例紧接着在下表1中示出。
表1:
用于假设包裹的该包裹指纹示出每个预测的当前事件具有阈值T_1(在承诺时间之前以分钟为单位指定),该阈值T_1已在步骤406在模块2.1中确定。在预测的当前事件之后的每个预测的下一事件具有阈值T_2(在承诺时间之前以分钟为单位指定)。然而,还可以看到,每个预测的下一事件之后是相同的事件,但现在是预测的当前事件。换句话说,一旦预测的下一事件实际发生,它就是预测的当前事件。因此,在一个预测的当前事件之后的预测的下一事件的T_2等于之后预测的当前事件的T_1。
作为来自上表1中所示的包裹指纹的具体示例,对于承运人实体FX,第一预测的当前事件发生在ABEA设施处,具有类型PU(即收取事件),其中包裹的目的地为与CHIA设施相关联的交付地址。服务描述代码D指示国内交付服务,服务代码3指示2天交付,而星期几(dow)指示星期三交付日。第一预测的当前事件具有为2835的阈值T_1,这意味着预期在所购买的服务类型的规定交付时间之前2835分钟收取。预期在预测的当前事件之后的预测的下一事件作为如由模块2.2确定的到达(AR)发生在设施EWRHB,从而寻找预测的ABEA PU当前事件之后的所有可能的下一事件。该预测的下一事件在模块2.2未找出该T_2值的规定交付时间之前具有1890分钟的阈值T_2。预测的下一事件之后的预测的当前事件是EWRHB到达,其具有1890的阈值T_1,与先前预测的下一事件的T_2值完全相同。当评估EWRHB到达事件为当前事件时,模块2.1找出阈值T_1为1890。然后,模块2.3使用EWRHB预测的当前事件的阈值T_1值1890作为EWRHB预测的下一事件的阈值T_2值,以消除T_2EWRHB阈值对先前ABEAPU事件的任何依赖性。
附加模块部分2.4可以与模块2.3的输出结合使用,以附加目的地时区名称,如上表1中所示。这允许以后基于适用于每个预测事件的位置的时区将时间调整到通用参考系,诸如协调世界时(UTC)。这简化了阈值的应用,因为事件可能从一个时区跨越到下一个时区。
一旦物流网络100内可能发生的所有预测事件的包裹指纹信息完整,就在步骤412为所有预测事件创建风险维度表。这是通过计算事件发生超过事件阈值的每个潜在时间范围的交付延迟风险来完成的。例如,该范围可能是一个小时,因此在从包裹指纹阈值之后事件发生的每个小时都计算风险水平。该风险特定于预测事件和假设包裹的特性,包括事件位置、事件类型、产品或服务类型、承诺时间前的天数、承诺时间是星期几、等等。
图5提供了在图4的流程中用于找出预测的当前事件、预测的下一事件和阈值的组件集合的图示,其分别为事件位置、事件类型、产品或服务类型、承诺时间前的天数、承诺时间是星期几、等等。如上针对图4的步骤404所述的模块1利用输入502,该输入502包括事件类型、国内与国际服务类型、正运送包裹的国家的国家代码、识别任何特定包裹的承运人的承运人代码、以及确定宽裕时间的交付日期范围,使得被分类到分区中的宽裕时间是具有某些特性的特定假设包裹的正确宽裕时间。模块1操作504访问历史包裹事件数据506来计算物流网络100内可能的每个事件的宽裕时间分布。模块1输出508包括分区中的宽裕时间,以建立宽裕时间分布,该宽裕时间分布可以以如图6中所示的直方图形式600表示。在图6的示例中可以看出,直方图600包括被排序到15分钟间隔的分区中的宽裕时间。将领会,可以选择其他间隔,但是已经发现15分钟的间隔为确定有效阈值提供了足够的分辨率。
模块1的该输出随后与模块2的输入512一起提供给模块2,该模块2的输入512包括百分比数、最小流量百分比、和规定交付时间的承诺日期范围。模块2操作确定包裹指纹事件和每个事件的阈值,其包括预测的当前事件和预测的下一事件,如图4的步骤406、408和410中所述。模块2的输出被放置在存储510中,并且包含包裹指纹成分,该包裹指纹成分包括所有预测的事件和对应的阈值,诸如上面表1中所示的用于给定假设包裹的阈值。
回到图6,直方图600进一步展示了模块2.1如何找出给定当前事件的阈值。在此示例中,事件是从集散中心对发往特定最终位置的包裹进行出站扫描。然后,使用宽裕时间的期望百分位数来找出阈值。在该示例中,如606所指示的期望百分位数是第99个百分位数,其已经示出提供了用于确定包裹延迟风险的有效阈值。在此示例中,第99个百分位数的观察到的准时扫描是承诺日的上午12:15进行交付。因此,假定在承诺日上午12:15之后离开该特定集散中心并前往该特定最终位置的任何包裹将处于在承诺日之后被交付的风险水平。因此,区域602的分区中具有宽裕时间的包裹被假定为是准时的而没有风险水平,而区域604的分区中具有宽裕时间的包裹被假定为有延迟交付的风险。
图7是流程图,其示出了在执行模块2.1的功能以找出包裹指纹的预测的当前事件阈值时可以遵循的步骤的示例700。模块2.1在步骤702开始,在步骤702中,模块2.1读取输入参数作为选择事件的指纹阈值处于的百分位数。如上面针对图6中所示的示例所描述,百分位数是第99个。在步骤704,从存储直方图的数据库(诸如当使用Apache Hive时的Hive表)读取直方图中提供的预测的当前事件的宽裕时间分布作为输入。在步骤706,分区代码列被提取为事件位置、装运目的地位置、事件类型、装运服务类型、装运承诺在星期几、和事件宽裕时间的分区号。在步骤708,如果分区时间代码为负,则创建一个标志。然后,在步骤710,计算事件位置、装运目的地位置、事件类型、装运服务类型、装运承诺在星期几、以及其中分区时间代码不为负的事件宽裕时间的分区号各自的总频率。
此时,对事件位置、装运目的地位置、事件类型、装运服务类型、和装运在星期几的每个唯一组合采取步骤集合712。在集合712的第一步骤714,事件按分区时间结束以升序排序。在集合712的步骤716,计算累积频率(CF),而在集合712的步骤718,计算总频率(TF)。然后在集合712的步骤720计算累积百分比(CP)为CP=CF/TF。在集合712的步骤722,选择其中相关联CP至少为1-百分位数(例如99)/100的行。然后在步骤724,以分区时间结束的升序分配行号,并选择行号等于1的行作为预测的当前事件的指纹阈值,其中预测的当前事件被定义为事件位置、装运目的地位置、事件类型、装运服务类型、和装运承诺在星期几的唯一组合。然后,在步骤726,将与针对每个所选指纹阈值相关联的预测的当前事件写入阈值数据帧,以结束模块2.1。
图8A-图8B是流程图,其示出了当执行模块2.2的功能以找出如在模块2.1中确定的给定预测的当前事件的包裹指纹的预测的下一事件位置和类型时可以遵循的步骤示例800。最初,在步骤802,输入参数被读取为观察到的准时扫描的期望百分位数。这可以是与模块2.1中使用的相同的百分位数(诸如第99个),或者它可以是不同的,因为该阈值被用作在给定的当前事件之后找出具有最新预测的下一事件的下一事件的测试,而不是用作包裹指纹中预测的下一事件的阈值。然后在步骤804,另一个输入参数被读取为预测的下一事件相对于所有历史的下一事件成为有效预测的下一事件所需的期望最小百分比。该最小百分比表示潜在预测事件的最小流量,以允许从给定当前事件的潜在的下一事件池中过滤出那些发生率非常低的预测的下一事件。已经发现10%是用于这种过滤的有效最小百分比,但是其他最小百分比也是适用的。
一旦已经读取了输入参数,就在步骤806从存储直方图的数据库(诸如其中使用Apache Hive的Hive表)中读取给定预测的当前事件的每个潜在的下一事件的宽裕直方图数据作为输入。在步骤808,这允许将分区代码列提取为事件位置、装运目的地位置、事件类型、装运服务类型、装运承诺dow、下一事件位置、下一事件类型和下一分区时间代码。在步骤810,如果分区时间代码是负的,则创建标记,否则从下一个分区时间代码中的数字创建分区时间结束。然后在步骤812计算事件位置、装运目的地位置、事件类型、装运服务类型、装运承诺dow、下一事件位置、下一事件类型、以及其中分区时间代码不为负的下一分区时间代码各自的总频率。
此时,对事件位置、装运目的地位置、事件类型、装运服务类型、装运承诺dow、下一事件位置和下一事件类型的每个唯一组合执行步骤集合814。在集合814的第一步骤816,事件按分区时间结束以升序排序。在集合814的步骤818,计算累积频率(CF),而在集合814的步骤820,计算第一总频率(TF1)。然后在集合814的步骤822计算累积百分比(CP)为CP=CF/TF1。在集合814的步骤824选择其中相关联CP至少为1-百分位数(例如99)/100的行。然后在步骤826,以分区时间结束的升序分配行号,并选择行号等于1的行。
一旦已经为每个唯一组合选择了等于1的行,则为事件位置、装运目的地位置、事件类型、装运服务类型和装运承诺dow的每个唯一组合执行步骤集合828。在集合828的第一步骤830,计算第二总频率(TF2)。然后,对于事件位置、装运目的地位置、事件类型、装运服务类型、装运承诺dow、下一事件位置和下一事件类型的每个唯一组合,执行嵌套在集合828内的步骤集合832。在步骤834,分布百分比(DP)被计算为DP=TF1/TF2。在集合832的步骤836,选择其中相关联DP至少为最小百分比(例如,10)/100的行,从而仅保留那些满足该最小流量的潜在的下一事件。然后在步骤838,以分区时间结束的升序分配行号,并选择行号等于1的行作为预测的下一事件类型和位置,其中每个预测的当前事件的预测的下一事件被定义为事件位置、装运目的地位置、事件类型、装运服务类型、和与相关联的前一预测的当前事件对应的装运承诺在星期几的唯一组合。在步骤840,将该预测的下一事件类型和位置作为输出写入下一事件数据帧。如前所讨论的,要用于预测的下一事件的包裹指纹中的包裹阈值由模块2.1单独确定,其中预测的下一事件被认为是预测的当前事件,并且然后模块2.3组合模块2.1和2.2的输出以产生包裹指纹,诸如上面表1中所示的包裹指纹,其中预测的下一事件的阈值T_2与该预测事件之后的预测的当前事件的T_1相同,因为它们是相同的预测事件,其中分别在前摄性评分期间监控预测的下一事件(T_2)以及在反应性评分期间监控随后的当前事件(T_1)。
展示模块2.2如何找出预测的下一事件的位置和类型的具体示例如下。在DENR事件位置发生的具有出发类型的历史当前事件在历史数据中具有三个潜在的下一位置和事件类型。对于三个潜在的下一位置和事件类型中的每一个,确定第99个百分位阈值时间和样本大小。例如,在ORDR事件位置的到达事件类型有5%的时间发生,并且此对的第99个百分位阈值为10/1/195:30。在INDH事件位置的到达事件类型和在MEMH事件位置的到达事件类型分别有45%和50%的时间发生,并且第99个百分位阈值分别为10/1/191:45和10/1/1900:00。给定该信息,在INDH事件位置的到达事件类型被选择为针对从DENR出发的当前事件的预测的下一事件类型和位置,因为该预测的下一事件位置和类型具有大于10%的样本大小,并且其第99个百分位阈值在样本大小大于10%的那些当中是最新的。
图9A和图9B是流程图,其示出了在执行第一处理系统210的包裹风险表计算子系统214的功能时可以遵循的步骤示例900。在第一步骤902,输入参数被读取作为历史数据的包裹的开始和结束装运日期。然后,在步骤904,读取装运日期在开始和结束装运日期内的包裹的历史事件数据作为进一步的输入。在步骤906,从每个包裹的历史数据中提取服务类型、承诺dow和服务结果(准时交付或延迟特定时间长度)。在步骤908,为提取的信息扩展事件数组。然后在步骤910过滤数据以仅保留指纹合格事件。例如,与包裹指纹中使用的物流网络100的预测事件无关的任何事件被移除。
一旦已经过滤了历史事件数据,就准备好基于包裹指纹的每个预测事件的超过阈值的延迟长度,应用该历史事件数据来确定包裹在规定时间之后被交付的风险水平。在步骤912,对于来自历史数据的每个包裹的每个事件,确定事件类型、事件位置、从事件时间到承诺日期的天数,尽管特定于每个服务类型具有最大值。例如,快速服务类型最多可以有三天,而地面服务类型最多可以有七天。在步骤914,为每个历史包裹的每个事件获得对应的包裹指纹阈值。然后,步骤916确定任何包裹的任何历史事件是否会违反包裹指纹阈值。
此时,在步骤916中找出的每个包裹的每个历史事件的延迟量可以在步骤918通过找出实际事件时间和指纹阈值之间的差值直至期望的最大值来计算。例如,最大延迟可以被限制在诸如10小时的水平,在该水平下,预期包裹迟到的风险水平已经非常高。在该示例中,延迟量是以小时为单位计算的,但是将领会,取决于期望的粒度水平,其他时间单位也可以是确定的基础。在步骤920,对于具有指纹阈值违反的每个历史事件,分配给具有阈值违反的事件所属的一组匹配事件的指纹违反计数器递增一。因此,步骤920的结果是每组特定匹配事件的阈值违反的合计。
在步骤922,对于具有指纹阈值违反且由于其发生在规定时间(诸如承诺时间)之后因此交付迟到的每个历史事件,分配给具有阈值违反和迟到交付的事件所属的一组匹配事件的迟到交付计数器递增一。因此,步骤922的结果是每组特定匹配事件的迟到交付的合计。对于这些组匹配事件中的每一个,风险水平可以被计算为迟到计数器的值除以违反计数器的值。因此,步骤924的输出是0和1之间的值,以设置风险水平。如果期望将输出表达为百分比,则该值可以乘以100。然后在步骤926将输出写入风险表。
下表2中示出了在事件位置MEMH的到达(AR)事件类型的风险表的示例。这展示了可能存在没有在历史事件数据中表示的一些延迟量。例如,1小时、2小时、3小时和6小时的延迟没有表示在历史数据中。然而,将来可能发生这些延迟量。因此,进行插值可能是适当的,以找出任何这种缺失延迟量的风险量。包含这种插值的风险表如下表3所示。由于随着历史数据继续被捕获,创建风险表的过程可以由第一处理系统210持续执行,因此来自插值的延迟量最终可以被历史数据中发生的延迟量所取代。
表2(无插值):
表3(插值后):
上文已描述了第一处理系统210创建如由包裹指纹和相关联风险表定义的模型的操作,并且然后第二处理系统218可以对照物流网络100中运输中的真实包裹的实时数据对模型进行评分,以反应性地和前摄性地找出每个预测事件的风险水平。图10是对照运输中的真实包裹的实时事件数据对模型进行评分的示例性方法1000的流程图。在步骤1002,第二处理系统218中接收运输中的真实实况包裹的实况事件数据的实时流。此时,由于对应于刚刚在步骤1002接收的事件数据的预测的当前事件的发生,来自包裹指纹的预测的下一事件的任何前摄性评分被取消。在步骤1006,对于真实包裹刚刚已经发生的新的当前事件,通过将预测的当前事件的阈值与真实包裹已经实际发生的当前事件进行比较,以找出事件的发生超过阈值的延迟量(如果有的话),从而对照模型对新的当前事件评分。然后可以在风险表中找出与当前事件匹配的预测事件的该延迟量,以揭示风险表中指定的对应风险水平。然后可以使这种风险水平可用于下游过程。
一旦已经找出真实包裹的当前事件的风险水平,然后在步骤1008就可以针对包裹指纹中为当前事件定义的预测的下一事件安排前摄性评分。然而,如果当前事件是交付类型,则该过程可以结束,因为交付已经发生。如果当前事件不是交付类型,这意味着包裹仍在运输中,则在步骤1008,安排前摄性评分,并且前摄性评分在由时间表指定的时段开始发生。例如,可以安排每15分钟执行一次前摄性评分。将领会,该时间表可以不是每15分钟一次,其中考虑到物流网络100的潜在大规模以及在任何给定时间对照模型被评分的大量运输中的真实包裹,可以选择时间量来平衡前摄性评分的分辨率对第二处理系统218所需的处理量。一旦已经超过被评分的预测的下一事件的阈值,就分配风险水平。然后,基于延迟增加超过阈值,然后在周期性地更新风险水平的情况下继续进行安排的前摄性评分。一旦发生了用于包裹的新事件发生,示例性方法1000的流程就返回到步骤1002。
前摄性评分寻找尚未经历预测的下一事件的包裹,使得将该事件评分为当前事件尚不可能。由此,步骤1008的前摄性评分允许在预测的下一事件在网络100中实际发生之前为预测的下一事件确定风险,而不是仅在事件一旦确实发生时才经由在步骤1006的反应性评分来找出风险。一旦在安排的时间执行了前摄性风险评估,就可以如图13中所示使用与最新近反应性评分和当前前摄性评分相关的风险聚集来确定是将来自最新近前摄性评分的风险还是来自现有反应性评分的风险用作该时刻该包裹的风险水平。然而,一旦预测的下一事件确实发生并成为正在进行反应性评分的当前事件,来自反应性评分的该风险然后就成为该包裹的风险水平。下面关于图11描述了反应性评分的步骤的具体示例,而下面关于图12描述了前摄性评分的步骤的具体示例。
图11是流程图,其示出了在执行第二处理系统218的反应性评分功能时可以遵循的步骤的示例1100。在步骤1102,流程开始于从物流网络100内的事件位置读取指向第二处理系统218的流式传输的事件。流式传输的事件可以识别包裹、始发地、最终位置、称为服务承诺的规定交付时间、产品/服务类型、和交付dow。在步骤1104,事件可以被模式化成所需的特定数据处理格式,并被净化以过滤掉任何与评分无关的事件或以其他方式超出范围的事件。在步骤1106,由于可以被反应性评分的事件已经发生,因此已经被安排的该包裹的任何前摄性评分活动被停用。
在步骤1108,做出关于事件时间是否已经超过服务承诺的判定。如果是,则包裹已经迟到,并且因此包裹迟到的风险是1或100%,并且反应性评分结束。如果当前事件的时间尚未超过服务承诺,则在步骤1112获得与从物流网络100流式传输的实际当前事件对应的预测的当前事件的指纹阈值,并将其应用于事件的时间。确定真实事件相对于由阈值指示的预测的当前事件的截止时间的延迟量,并且在步骤1114做出关于是否存在相对于阈值截止时间的任何延迟的判定。
如果没有超过阈值的延迟,则包裹正按计划在服务承诺前进行交付。因此,在步骤1116,该风险被分配零分。如果真实当前事件的发生相对于来自包裹指纹的匹配预测的当前事件的阈值之间存在延迟量,则在步骤1118,从风险表中检索风险水平,并将该风险水平分配为该包裹的风险评分。在步骤1116或1118完成风险评分之后,步骤1120然后安排前摄性评分以针对包裹指纹的预测的下一事件而激活。该当前事件的反应性评分过程然后完成,并且反应性评分是空闲的,直到下一事件从物流网络100内的位置流式传输。
反应性评分时可能出现的一种场景是,已经在物流网络100中发生的真实当前事件可能与来自包裹指纹的预测的当前事件不匹配。换句话说,运输计划可能已经将包裹发送到不同于包裹指纹所预期的设施。这可能是由于普通的商业运营(诸如沿着物流网络路线的负载平衡),和/或由于装运前风险分析的应用——其导致选择了通过物流网络的非预期路线——所致。然而,在网络中发生当前事件后,反应性评分可以从可用于物流网络100的包裹指纹信息中获得与真实当前事件相关联的阈值,并且然后从该当前事件继续进行,使得反应性评分和前摄性评分可以基于来自实际当前事件的预测的下一事件和预测的当前事件继续,直到到达最终目的地位置。指纹可能不同于包裹指纹最初预期的向前移动,因为基于实际当前位置的下一预测事件可能不同于基于预测的当前事件位置的下一预测事件,但是该过程基于新的包裹指纹预测事件和阈值继续反应性和前摄性评分。
图12是流程图,其示出了在执行第二处理系统218的前摄性评分功能时可以遵循的步骤的示例1200,该功能已在图11的反应性评分方法期间被安排。该方法根据时间表周期性地开始,并在步骤1202开始,在步骤1202评估包裹指纹的预测的下一事件。该评估将当前时间与服务承诺时间以及由该预测的下一事件的包裹指纹指定的阈值进行比较,并确定超过阈值的延迟量(如果有的话)。判定步骤1204判定当前时间是否超过服务承诺时间。如果是,则该包裹已经迟到,并且该包裹迟到的风险因此被指定为1或100%,并且针对下一预测事件的前摄性评分的这一实例结束。如果当前事件的时间尚未超过服务承诺,则考虑真实事件相对于如由先前确定的阈值指示的预测的下一事件的截止时间的延迟量,并且在步骤1208做出关于是否存在相对于阈值截止时间的任何延迟的判定。
如果不存在延迟,则与执行最新近的反应性评分时相比,该包裹目前在该时间点不存在更多风险。因此,风险评分不改变,并且针对下一预测事件的前摄性评分的这一实例结束。如果相对于阈值的延迟确实存在,则在该示例中,在步骤1210,为该包裹清除所安排的前摄性事件,因为将改为创建新的前摄性安排。然后在步骤1212,在风险表中找出该预测的下一事件在超过阈值的该延迟量下的风险水平,并将其分配给该包裹。用于预测的下一事件的新的前摄性评分动作然后可以被安排在未来的新时间开始。例如,对包裹的前摄性评分的新时间表可以被安排在一小时后开始,这可以对应于风险表中延迟量的增量,例如一小时的增量。直到下一次前摄性评分开始的时间量是前摄性安排所需的处理能力量相对于用于更新前摄性评分的特定粒度水平的值之间的平衡。这种前摄性评分的实例然后结束。
图13是流程图,其示出了在执行第二处理系统218的风险聚集功能时可以遵循的步骤的示例1300。在一些实施例中,可能期望仅出于确定在规定时间之后交付包裹的风险是否比来自最新近反应性评分的风险更差的目的而使用前摄性评分,并针对包裹记录该更差风险。因此,当预测的下一事件的前摄性评分导致比最大反应性评分所分配的风险评分更低的风险评分时,最大反应性评分的较高风险被保留为该包裹的风险水平。因此,在这样的实施例中,只有被反应性地评分的网络中事件的实际发生才可以降低分配给该包裹的风险水平。示例1300展示了这种实现。
示例1300始于步骤1302,在步骤1302,对包裹指纹的下一预测事件的前摄性评分发生,以找出前摄性评分的风险水平。将该前摄性评分的风险水平(即,新风险)对照该包裹的最新近反应性评分的风险水平(即,旧风险)进行比较,并关于新风险是否大于旧风险进行判定。如果新风险不大于旧风险,则在步骤1308,从最新近的反应性评分中找出的旧风险被保留为该包裹的风险水平。如果新风险大于旧风险,则在步骤1306,从最新近的前摄性评分中找出的新风险被保留为该包裹的风险水平。风险聚集器示例1300然后结束,直到对该包裹的下一次前摄性评分发生。
图14是流程图,其示出了第四处理系统226可以遵循的步骤的示例1400,以响应于由第二处理系统218确定的风险水平,经由改变由物流网络100实施的运输计划来使包裹按新路线发送。在步骤1402,第二处理系统218可以将运输中的实况包裹的风险数据输出为被引导至第四处理系统226并由第四处理系统226接收的流。然后,在步骤1404,第四处理系统226可以找出从包裹的当前位置到最终目的地位置的替代运输计划,该替代运输计划具有比当前风险水平更低的假定风险。例如,该步骤可以涉及在步骤1406实施替代运输计划,在步骤1406,包裹被送往非典型的下一事件位置,该非典型的下一事件位置将不同于指纹阈值的预测的下一事件位置,并且然后将导致对包裹的新的风险评估,该新的风险评估将可能不同于先前一个。当与来自外部因素风险分析的装运前风险确定结合使用时,这可能更加有效,诸如预测到选定的非典型下一位置的天气或交通是否比到更典型的下一位置的天气或交通引起的风险更低。下面关于图15和图16讨论运输计划和外部风险因素分析。
图15示出了在包裹处于运输中时发生的真实包裹事件1502和相关联的包裹在规定时间之后交付的风险水平1504的示例1500。包裹到达位置INDH,并且招致零风险评分。然而,在INDH位置的一个站内,由于天气风险,出现了例外,这使包裹置于有73%的机率在规定的承诺时间之后被交付。然而,高风险水平导致对包裹的运输计划的改变,该改变按新路线发送包裹,这导致更新的风险预测为零,因为新路线不遭受天气风险。此外,在从INDH的出发事件时,对于给定的承诺时间和服务水平,应用于从INDH位置出发并前往MICA最终目的地的包裹的包裹指纹阈值没有被违反。
沿着该路线,从MEMH位置的出发事件比该事件的指纹阈值晚9分钟(上午5:09对上午5:00),基于风险表,这导致34%的反应性风险评分。然而,34%的风险评分被认为是低风险,因为包裹仍然更有可能在上午10:30的规定承诺时间前到达最终位置。然后,包裹比该事件的指纹阈值晚56分钟到达下一事件位置MSPA(上午7:41对上午6:45),但是风险表指示风险评分仅为7%,因此落入无风险类别,因为包裹仍然非常有可能在上午10:30的规定承诺时间前到达最终目的地。随着风险持续波动,这继续进行,但绝不超过低风险分类,并在上午10:30的规定承诺时间前交付。
图16是流程图,其示出了第四处理系统226可以遵循的步骤的示例1600,以使用外部因素和相关联风险将装运前分析考虑在内。在步骤1602,获得包裹开始位置或始发地、开始时间、最终目的地位置、和产品/服务类型。然后在步骤1604,使用包裹指纹中的预测事件来计算产品沿着预期路径移动通过网络100的预期路径和时序,以将这样的包裹移动到最终位置。在步骤1606,获得外部因素和相关联的风险信息1608,使得可以基于从包裹指纹计算的预测位置和时间来识别包裹是否将行进通过恶劣条件(诸如天气或交通),从而然后将该信息转换成外围风险评分。
然后,运输计划系统226可以使用该风险评分,以关于运输计划以及不同计划是否将具有较低风险进行装运前确定。上面讨论了一个与图15相关的示例,并且天气导致73%的风险水平。同样,装运前风险确定的该示例1600也可以由第二处理系统218在真实包裹沿着路线访问的每个位置实时应用,以确定运输计划系统226在判定从访问位置按新路线发送包裹时可以考虑的外围风险。
为物流网络100内运输中的每个包裹确定的风险信息对运营物流网络100的实体以及还对预期接收装运物的实体都可以非常有用。对于具有特殊处置要求(如温度控制)的包裹(如某些疫苗和其他医疗相关包裹)和/或具有极端时间敏感性的包裹(还如某些疫苗或医疗相关包裹)来说尤其如此。因此,风险信息可以以显示格式提供给各种感兴趣方,以允许他们监控感兴趣的包裹。此外,这允许装运实体的人员监控网络内导致延迟的故障点,所述延迟影响在规定时间前交付包裹的能力。
图17示出了由图2的应用程序222、224提供的这种用户显示的屏幕截图的一个示例1700。示例1700允许用户应用各种过滤器来控制正在显示的信息,诸如针对付款人对托运人的过滤器1702、选择已在过滤器1702选择的付款人或托运人账户的过滤器1704、以及包裹的服务类型(诸如地面服务或快递服务)。取决于所选择的过滤器,示例1700还在字段1708显示运输中的包裹的总数,在字段1710显示处于足够引起兴趣的风险水平的包裹的总数,以及在字段1712显示已经经历异常(诸如由于天气或其他非典型因素而错过事件)的包裹的数量。示例1700还包括地图1714,该地图1714指示有风险在该规定时间之后被交付到给定地理区域中的位置(诸如美利坚合众国中的每个州内)的包裹的数量。
在1700的示例中提供该信息允许对监控包裹感兴趣的人能够关注处于足够风险水平(诸如大于50%)的需要关注的那些包裹。因此,此人可能选择关注处于足够风险水平的283个包裹,而不是监控运输中的所有446个包裹。那些包裹可以通过用户选择字段1710以查看全部283个包裹或者通过从地图1714中选择地理区域以关注该选定区域的有风险的包裹来识别。此外,用户可以通过选择查看更多信息来关注任何给定的有风险的包裹,并且响应于接收到用户选择,第三处理系统然后显示有风险的包裹的列表,其中感兴趣的包裹可以是用户从列表中选择的。在第三处理系统从列表中接收到对特定包裹的选择后,该第三处理系统然后可以显示特定于包裹的信息。
将领会,对于给定客户(诸如托运人或收货人)的包裹,托运人具有账户。每个包裹可以与该账户关联,使得第三处理系统仅向托运人账户提供与该托运人账户的包裹相关的风险信息以供显示信息。此外,给定托运人账户的包裹可能具有不同的特定于包裹的最终位置,并且在运送期间针对包裹发生的事件可以是特定于包裹的事件。因此,在图17的示例中,托运人账户的446个包裹可能被送往数百个不同的最终位置。此外,这些包裹可能独立地行进,并且因此即使对于遵循相同运输路径具有相同始发地和最终目的地的两个包裹来说,它们也可能处于沿着运输路径的不同点处,并且从而遇到单独的特定于包裹的事件,这些特定于包裹的事件产生单独的延迟和风险确定。示例1700示出了在第一显示时间取得的屏幕截图。然后,用户可以选择在随后的第二显示时间查看显示,并且随着已经对那些包裹进行附加评分,数字可能已经改变。例如,有风险的包裹的数量可能大于或小于图17中所示的第一显示时间的有风险的283个。
图18示出了由图2的应用程序222、224提供的用户显示的屏幕截图的另一示例1800。该示例1800提供信息1802,包括针对给定标准(诸如针对特定客户或特定位置)的包裹/装运物的总数、有延迟风险的那些包裹的数量、没有承诺日期的数量、如期的数量、接近承诺日期的数量、以及超过承诺日期的数量。这允许装运实体的人员快速查看给定客户的快照。
示例1800内的条形图表还提供了快速查看图表1804中装运状态(包括延迟的包裹数量1806)的快照的能力。延迟状态图表1808示出了在超过承诺时间被交付的每个风险类别的包裹数量,包括:处于足够风险水平(诸如至少80%)的包裹数量1810,其中延迟被认为是可能的;处于低风险(诸如低于40%)的包裹数量1812;以及被认为是中等风险(诸如在40%和80%之间)的包裹数量1814。还示出了其他信息,诸如示出包裹的最后已知位置的图表1816。因此,装运实体的人员可以收集信息的快照,该快照为给定客户提供网络运营以及装运状态的洞察。
图19示出了由图2的应用程序222、224提供的用户显示的屏幕截图的另一示例1900。该示例1900特别适合于装运实体的人员留意找出物流网络100的故障点,这些故障点导致延迟,从而导致包裹在规定的承诺时间之后被交付的风险。示例1900包括热图1902,该热图1902表示物流网络100内基于在反应性和前摄性评分期间找出的违反指纹阈值的数量而发生延迟的位置。如图表1904中,延迟可以示出为分布在一周的各天内。
过滤器集合1906也可以可用于由用户选择,以根据期望过滤信息,并允许用户以各种方式深入数据,其考虑到存储的风险数据与包裹的所有其他参数(包括客户、始发地、当前位置、最终位置、服务类型、规定承诺时间等)相关联。过滤器可以单独应用,也可以组合应用。第一字段1908提供了对客户名称(即,托运人)的选择,以过滤被提供用于显示的信息。第二字段1910提供了对EAN代码的选择,以过滤被提供用于显示的信息。第三字段1912提供对设施名称的选择,以过滤被提供用于显示的信息。第四字段1916提供了对设施名称的选择,以过滤用于显示的信息。第五字段1918提供了对交付日期的选择,以过滤用于显示的信息。第六字段1920提供了对服务延迟天数的选择,以过滤用于显示的信息。第七字段1922提供了对扫描类型或如上所指代的事件类型的选择,其产生事件数据以过滤用于显示的信息。第八字段1924提供了对设施类型的选择,以过滤用于显示的信息。第九字段1926提供了对始发地位置的选择,以过滤用于显示的信息,并且第十字段1928提供了对目的地位置的选择,以过滤用于显示的信息,其中使用两个字段1926和1928允许用户指定始发地/目的地配对。
除热图1902和图表1904之外,还显示信息表1930,以向用户提供特定细节。例如,表1930中出现的由应用过滤器而产生的包裹在列1932中示出事件类型,在列1934中示出事件时间戳,并且在列1936中示出对应的指纹阈值时间戳。因此,人们可以看到产生延迟风险的原始数据,并可以按(诸如设施、客户等的)期望过滤那些数据。可以显示诸如环形图表1938、1940和1942的其他图表,以进一步示出对延迟的相对贡献,诸如通过扫描类型、设施类型和始发地/目的地对。通过设施、通过设施类型、通过扫描类型、通过客户、通过始发地/目的地对等等了解故障点允许用户考虑补救措施以改进物流网络100的运营。
上文描述了用于创建和应用以包裹指纹形式的网络模型的各种示例和实施例,以提供确定运输中包裹的延迟交付风险和异常的能力,并允许监控这种有风险的包裹以及监控延迟交付风险和异常的发生。对与物流网络相关联的计算机系统的改进包括从历史数据中创建这些阈值的能力,并且然后实时应用这些阈值以允许实时监控延迟交付的风险。
总之,应强调的是,执行本文实施例中所述的任何方法和方法变型的操作序列仅为示例性的,并且可以遵循各种各样的操作序列而仍成立并且符合如本领域技术人员所理解的本发明的原理。
上述示例性实施例的至少一些部分可以与其他示例性实施例的部分相关联地使用,以增强和改进物流运营和对有延迟交付风险的包裹的相关监控。例如,基于反应性和前摄性评分的风险可以与装运前风险分析一起使用。同样,这些风险评估中的一个或两个可仅用于监控和信息人员,或可以用于创建包裹运输计划的闭环。此外,本文公开的至少一些示例性实施例可以彼此独立地使用和/或彼此组合使用,并且可以应用于本文未公开的设备和方法。然而,本领域技术人员将领会,如上所述的示例性模型训练、模型评分和相关输出对物流和装运管理中使用的技术提供了增强和改进。
本领域技术人员将领会,实施例可以提供一个或多个优点,并且并非所有实施例都一定提供如这里所述的全部或多于一个特定优点。附加地,对于本领域技术人员来说将清楚的是,可以对本文描述的结构和方法进行各种修改和变型。因此,应该理解,本发明不限于说明书中讨论的主题。而是,如以下权利要求中所记载的,本发明旨在覆盖修改和变型。
- 一种物流智能盒子、运输装置、运输系统及工作方法
- 用于在区块链网络上对能源设备进行监控的方法和装置
- 用于集中物流监控的计算机实现的系统和方法
- 物流运输用包裹信息实时监控登记系统