一种分布式SQL数据库的虹膜特征生成排序方法
文献发布时间:2023-06-19 10:11:51
技术领域
本发明属于计算机语言技术领域,涉及一种分布式SQL数据库的虹膜特征生成排序方法。
背景技术
随着技术的发展,数据库所包含的数据量越来越庞大。相应的,服务器在响应用户针对数据库的查询请求,对数据库中的数据进行排序处理(或操作)所需要的耗时也变得越来越长,导致用户往往需要等待较长的时间,才能得到服务器反馈的排序后的数据序列。因此,亟需一种能够达到针对数据库中的数据高效地进行排序处理的方法。
在分布式SQL数据库中包含两类节点:控制节点和计算节点,计算节点用于与控制节点交互,保存分片数据,完成局部查询和局部查询优化;控制节点用于对外提供查询接口,全局优化,结果合并。对于客户端来说,客户端不关心分布式SQL数据库的数据分布情况和数据合并过程,只要拿到正确的查询结果即可,但是由于查询是在多个计算节点上同时展开的,控制节点需要合并所有的查询结果,对于非排序的用于XML数据查询的语言(XQuery)来说,控制节点只要把各个计算节点得到的数据简单合并起来即可;对于需要排序的XQuery来说,由于数据分布在不同的计算节点上,简单合并各个计算节点并不能得到全局的排序结果,需要在控制节点对数据进行排序操作。想要得到排序后的结果,控制节点需要对多个计算节点合并得到的结果进行排序。时间序列是重要的时序数据,广泛存在于日常生活、金融和科学应用中,挖掘有用的时间序列模式是十分重要的,数值性和连续性是时间序列数据的重要特点,这使得相似性的研究成为时间序列的一个最基本的问题。随着互联网的迅猛发展,每天由网络产生的互联网数据量越来越庞大,如何进行海量数据的分析和挖掘一直是互联网分析领域一个非常重要的研究课题,而面对海量数据,相似度值的获取变得更加复杂、耗时。因为结果集可能会超过内容的容量,所以控制节点需要采用外部排序。外部排序指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存,需要在内存和外部存储器之间进行多次数据交换,以达到排序整个文件的目的。外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装人内存的部分,分别把每一部分调入内存完成排序。然后,对已经排序的子文件进行归并排序。根据有限的内存资源将大文件分为L个段,然后依次将这L个段读入内存并利用高效的内部排序算法对每个段进行排序,排序后的结果即为初始有序归并段直接写入外存文件。内部排序时要选择合适的排序算法,并且要考虑到内部排序需要的辅助空间以及有限的内存空间来决定究竟要把大文件分为几个段。接下来选择合适的路数k对这L个归并段进行多路归并排序,每一趟归并使k个归并段变为1个较大归并段写入文件,反复几趟归并后得到整个有序的文件。上述算法中,根据内存限制,L和K的不同选择可能会涉及到多次IO操作。
发明内容
本发明的目的是提供一种分布式SQL数据库的虹膜特征生成排序方法,解决传统传统虹膜数据排序速度慢的问题。
本发明所采用的技术方案是,
一种分布式SQL数据库的虹膜特征生成排序方法,包括以下步骤:
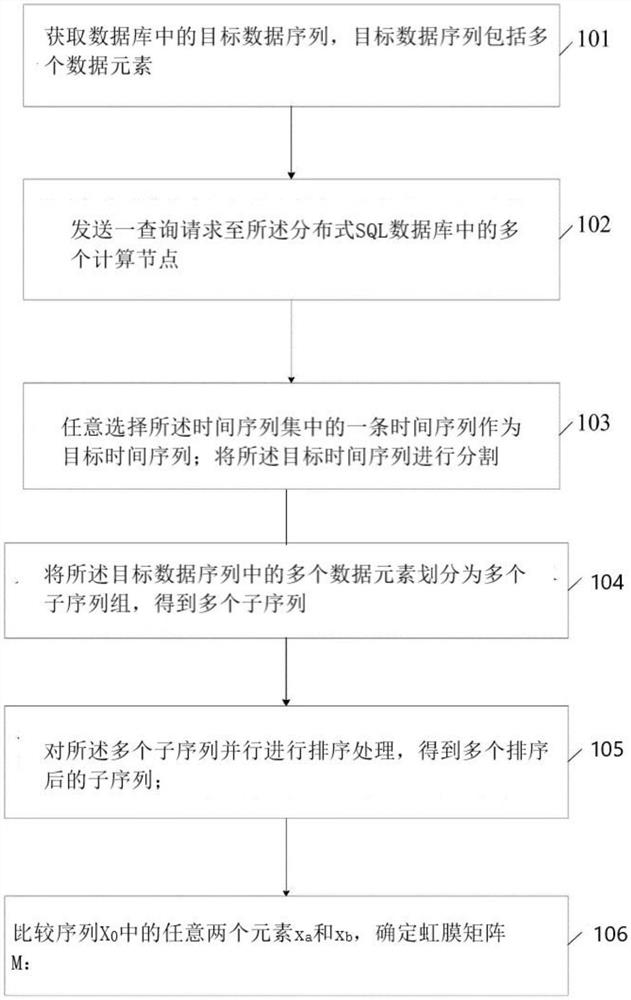
步骤1:获取数据库中的目标数据序列,其中,所述目标数据序列包括多个数据元素;
步骤2:发送一查询请求至所述分布式SQL数据库中的多个计算节点,所述查询请求携带有查询项、排序项和排序规则;
步骤3:任意选择所述时间序列集中的一条时间序列作为目标时间序列;将所述目标时间序列进行分割,得到至少两个时间子序列;
步骤4:将所述目标数据序列中的多个数据元素划分为多个子序列组,得到多个子序列;
步骤5:将n个含有时间序的数值,分别以幅值、排序位置为属性表示,构成时间序列X
步骤6:对接收到的各个计算节点返回的所述有序序列进行归并操作。
步骤7:对所述多个子序列并行进行排序处理,得到多个排序后的子序列;按照预设规则,合并所述多个排序后的子序列,得到排序后的目标数据序列。
步骤8:比较序列X
发送所述有序序列至所述控制节点包括:分别将所述多个子序列依次发送至所述控制节点。。
分割模块用于,将所述目标时间序列进行分割,得到至少两个时间子序列。
获取模块用于,分别获取所述每个时间子序列与所述时间序列集中的其余每个时间序列的弯曲路径;。
确定模块用于,依据所述弯曲路径,确定所述目标时间序列与所述时间序列集中的其余每个时间序列的相似度值。
排序模块用于,将所述目标时间序列与所述时间序列集中的其余每个时间序列的相似度值按照相似度值的大小进行排序,得到排序后的相似度值。
本发明有益效果为:
在本发明每个计算节点根据查询项对本节点处的数据进行查询,并对查询果根据排序项和排序规则进行排序,利用时间序列包含的信息生成其独一无二的特征虹膜矩阵,能作为虹膜图为深度学习算法提供输入数据,为结合深度学习算法进行数据挖掘提供保障;可进一步服务于特征比对、机器学习等数据分析、数据挖掘方法,且基于本发明的方法,可拓展应用至其他具有排序关系的数值的特征虹膜的生成及读取,具有很强的实用性和广泛的适用性。控制节点只需要归并各个计算节点已经排序好的有序序列,即可完成大量数据的排序,从而大大减少了IO时间,提高了排序效率,增强了用户体验。
附图说明
图1是本发明一种分布式SQL数据库的虹膜特征生成排序方法的方法流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种分布式SQL数据库的虹膜特征生成排序方法,如图1所示,包括以下步骤:
步骤1:获取数据库中的目标数据序列,其中,所述目标数据序列包括多个数据元素;
步骤2:发送一查询请求至所述分布式SQL数据库中的多个计算节点,所述查询请求携带有查询项、排序项和排序规则;
步骤3:任意选择所述时间序列集中的一条时间序列作为目标时间序列;将所述目标时间序列进行分割,得到至少两个时间子序列;
步骤4:将所述目标数据序列中的多个数据元素划分为多个子序列组,得到多个子序列;
步骤5:将n个含有时间序的数值,分别以幅值、排序位置为属性表示,构成时间序列X
步骤6:对接收到的各个计算节点返回的所述有序序列进行归并操作。
步骤7:对所述多个子序列并行进行排序处理,得到多个排序后的子序列;按照预设规则,合并所述多个排序后的子序列,得到排序后的目标数据序列。
步骤8:比较序列X
发送所述有序序列至所述控制节点包括:分别将所述多个子序列依次发送至所述控制节点。。
分割模块用于,将所述目标时间序列进行分割,得到至少两个时间子序列。
获取模块用于,分别获取所述每个时间子序列与所述时间序列集中的其余每个时间序列的弯曲路径;。
确定模块用于,依据所述弯曲路径,确定所述目标时间序列与所述时间序列集中的其余每个时间序列的相似度值。
排序模块用于,将所述目标时间序列与所述时间序列集中的其余每个时间序列的相似度值按照相似度值的大小进行排序,得到排序后的相似度值。
在本发明实施例的方法中,每个计算节点根据查询项对本节点处的数据进行查询,并对查询结果根据排序项和排序规则进行排序,利用时间序列包含的信息生成其独一无二的特征虹膜矩阵,能作为虹膜图为深度学习算法提供输入数据,为结合深度学习算法进行数据挖掘提供保障;可进一步服务于特征比对、机器学习等数据分析、数据挖掘方法,且基于本发明的方法,可拓展应用至其他具有排序关系的数值的特征虹膜的生成及读取,具有很强的实用性和广泛的适用性。控制节点只需要归并各个计算节点已经排序好的有序序列,即可完成大量数据的排序,从而大大减少了IO时间,提高了排序效率,增强了用户体验。
- 一种分布式SQL数据库的虹膜特征生成排序方法
- 一种全文检索建立的方法和分布式NewSQL数据库系统