基于余弦相似性的软件可靠性增长模型优化选择方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于软件可靠性增长模型技术领域,具体涉及一种优化选择可靠性增长模型的方法。
背景技术
随着现代社会的发展,软件已被应用于人类社会的各种业务,极大地促进了人类的学习和生活,提高了工作效率,降低了劳动工作量。然而,如果在操作过程中出现软件故障或问题,将极大地影响人类的工作和生活。软件可以被认为是现代人类生活和商业中的重要工具。
为了防止或减轻软件发布后的故障,在软件发布前分析软件可靠性至关重要。然而,准确有效地测量软件可靠性是一个困难的事情。为了评估软件的可靠性水平,研究人员开发了许多软件可靠性增长模型。不幸的是,没有哪一个软件可靠性增长模型可以用于评估所有软件测试场景中的可靠性。因为软件可靠性增长模型的开发是基于与实际软件测试过程中故障检测或故障引进服从的分布,但经常不匹配的它的建模假设,或者因为检测或引入故障的规律不一致。因此,在实际软件可靠性评估中使用特定的软件可靠性增长模型将大大降低评估的准确性和有效性。
鉴于上述情况,研究人员调查了使用最优选择模型来选择最适合当前软件开发和软件可靠性评估测试环境的软件可靠性增长模型。例如,Knaf和Sacks采用最大似然估计来确定最佳软件可靠性增长模型。KHOSHGOFTAR和WOODCOCK使用Akaike信息准则(AIC)来选择最优软件可靠性增长模型。Ullah等人根据模型标准R2和阈值选择了自适应软件可靠性增长模型。此外,Sharma等人和Yaghoobi等人分别采用欧几里得复合距离(ECD)和香农熵来确定最佳软件可靠性增长模型。考虑到ECD和Shannon熵的优点,Garg等人将ECD和香农熵合并以选择最优软件可靠性增长模型。
上述优化选择模型方法可以有效地选择在一定条件下评估软件可靠性的最优模型。然而,由于软件测试和开发环境的不确定性和复杂性,以及故障检测的主观性,故障检测和故障引进的过程会发生复杂的变化。换句话说,在软件测试过程中,故障检测可能在软件测试的不同阶段表现出不同的变化。例如,在软件测试的早期、中期和后期,故障检测和故障引进表现出完全不同的变化,并遵循不同的阶段分布。因此,考虑单一最优模型方法来选择最优软件可靠性增长模型具有显著的误差和不确定性。选择的最优模型的建模假设可能不一定符合实际软件测试过程中故障检测或引入模式的规律变化。
为了应对上述挑战,本发明提出使用余弦相似性来划分和选择理想的软件可靠性增长模型。这种优化选择模型方法主要考察余弦相似性对类别进行有效分类的能力,以及软件可靠性增长模型在当前软件测试环境中的适应性。利用余弦相似度的分类方法,可以成功地选择相同类型的软件可靠性增长模型进行软件可靠性评估。通过避免单一分类的最佳方法选择的软件可靠性增长模型的建模假设与软件测试过程中故障检测和故障引进的实际测试环境与场景不符。
本发明的贡献如下:
(1)本发明提出了一种选择最优软件可靠性增长模型的分类和划分方法。
(2)本发明提出使用余弦相似性来划分、分类和选择最优软件可靠性增长模型。
发明内容
为解决上述现有技术中存在的技术问题,本发明提供了一种基于余弦相似性的软件可靠性增长模型优化选择方法,其特征在于,具体包括以下步骤:
步骤1,软件可靠性增长模型的属性:
假设软件可靠性增长模型的属性为[A1,A2,…,An],其值为[v1,v2,…,vn],各种软件可靠性增长模型表示为[M1,M2,…,Mm],使用矩阵来表示软件可靠性增长模型与其属性之间的关系,如下所示:
其中Mi表示第i个软件可靠性增长模型,i取1~m,A
步骤2,使用余弦相似性来选择最优模型:
步骤2.1,利用两个软件可靠性增长模型的属性向量之间的角度的余弦值,来测量两个软件可靠性增长模型的相似性,其公式表示如下:
其中M1和M2分别表示两个软件可靠性增长模型;
步骤2.2,考虑到在标准化模型属性值时有两种情况,第一种情况是模型性能越好,模型属性值越小;第二种情况是模型属性值越大,模型的性能越好,归一化由以下公式表示:
第一种情况:
第二种情况:
步骤2.3,对矩阵Mij进行标准化,表示为:
步骤2.4,对矩阵Mij进行标准化之后,用公式(2)计算余弦相似性;伪代码如下:
第一种情况的伪代码:
第二种情况的伪代码:
步骤2.5,将具有最优模型属性值的最优模型添加到公式(5)中,表示如下:
然后,计算每个软件可靠性增长模型标准化后与优化的软件可靠性增长模型之间的余弦相似度;
步骤3,综合考虑步骤2.4和步骤2.5的结果,给出一类最优软件可靠性增长模型。
进一步地,软件可靠性增长模型的属性使用模型比较标准。
进一步地,模型比较标准为MSE、Bias和R
与现有技术相比,本发明的有益效果如下:
本发明提出了使用余弦相似性分类方法。与现有的选择单个优化软件可靠性增长模型的方法相比,所提出的方法使用余弦相似性来划分一类软件可靠性增长模型。采用多个优化软件可靠性增长模型进行软件项目可靠性评估更适合于实际软件项目开发和测试的复杂环境。在实际软件开发项目中通过选择最佳软件可靠性增长模型为有效地评估软件可靠性做出了重大贡献。
附图说明
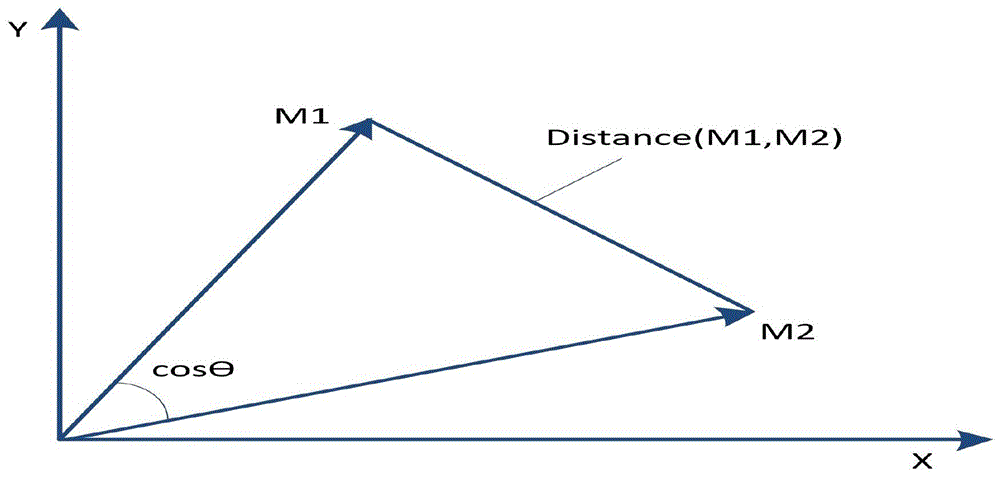
图1为本发明中软件可靠性增长模型的余弦相似性和距离测量图;
图2为本发明中DS1的80%的故障数据集进行实验时,十二个软件可靠性增长模型估计检测到的累计故障数比较;
图3为本发明中DS1的100%的故障数据集进行实验时,十二个软件可靠性增长模型估计检测到的故障的累积数量比较;
图4为本发明中DS2的70%的故障数据集进行实验时,十二个软件可靠性增长模型估计检测到的故障的累计数量比较;
图5为本发明中DS2的95%的故障数据集进行实验时,十二个软件可靠性增长模型估计检测到的故障的累计数量比较;
图6为本发明中使用DS1和DS2故障数据集进行实验时,十二个软件可靠性增长模型的余弦相似性比较。
具体实施方式
为了便于理解本发明,下面将对本发明进行更全面的描述。本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
实施例1
本发明提供了一种基于余弦相似性的软件可靠性增长模型优化选择方法,其特征在于,具体包括以下步骤:
步骤1,软件可靠性增长模型的属性:
假设软件可靠性增长模型的属性为[A1,A2,…,An],其值为[v1,v2,…,vn],各种软件可靠性增长模型表示为[M1,M2,…,Mm],使用矩阵来表示软件可靠性增长模型与其属性之间的关系,如下所示:
其中Mi表示第i个软件可靠性增长模型,i取1~m,A
步骤2,使用余弦相似性来选择最优模型:
步骤2.1,利用两个软件可靠性增长模型的属性向量之间的角度的余弦值,来测量两个软件可靠性增长模型的相似性,其公式表示如下:
其中M1和M2分别表示两个软件可靠性增长模型;
步骤2.2,考虑到在标准化模型属性值时有两种情况,第一种情况是模型性能越好,模型属性值越小;第二种情况是模型属性值越大,模型的性能越好,归一化由以下公式表示:
第一种情况:
第二种情况:
步骤2.3,对矩阵Mij进行标准化,表示为:
步骤2.4,对矩阵Mij进行标准化之后,用公式(2)计算余弦相似性;
伪代码如下:
第一种情况的伪代码:
第二种情况的伪代码:
步骤2.5,将具有最优模型属性值的最优模型添加到公式(5)中,表示如下:
然后,计算每个软件可靠性增长模型标准化后与优化的软件可靠性增长模型之间的余弦相似度;
步骤3,综合考虑步骤2.4和步骤2.5的结果,给出一类最优软件可靠性增长模型。
实施例2
实验
(1)故障数据集
使用文献中的故障数据集作为第一个故障数据集(DS1),DS1在36周内里检测到181个故障。使用另外文献中的故障数据集视为第二个故障数据集(DS2),DS2在81周内检测到461个故障。
为了充分利用故障数据集来验证所提出的优化方法的有效性,将DS1分为80%和100%来估计软件可靠性增长模型的参数值,并分别使用70%和95%的DS2来估计软件可靠性增长模型的参数值。然后,计算软件可靠性增长模型的属性值。故障数据集划分比例是随机的,目的是检查和验证给定优化方法的有效性。
(2)多种软件可靠性增长模型
为了验证给定优化方法的有效性,选择多种软件可靠性增长模型进行实验。例如,有完美调试软件可靠性增长模型(即G-O、DSS和ISS等)和不完美调试软件可靠性增长模型(即YID1、P-Z和P-N-Z等)。考虑故障检测服从多个分布,如指数分布(即G-0)、威布尔分布(即GGO)和S形分布(即ISS)。考虑故障引进服从指数分布(即YID1)和随时间的线性变化(即YIDA2)。此外,考虑故障检测的去除效率(即Z-T-P)和学习现象(即P-Z)。表1提供了各种软件可靠性增长模型的详细列表。
表1.多种软件可靠性增长模型
(3)软件可靠性增长模型属性
使用模型度量作为软件可靠性增长模型的属性,同时,模型比较标准可以衡量软件可靠性增长模型建立的质量。各种模型比较标准从不同方面全面考察了软件可靠性增长模型的拟合和预测性能。使用了多种模型比较标准,如MSE、R
表2.软件可靠性增长模型的属性(模型比较标准)
(4)软件可靠性增长模型参数估计方法
最小二乘估计(LSE)方法用于估计模型的参数。主要考虑的是,故障数据集是一个小样本,每个软件可靠性增长模型都可以用最小二乘法估计出确定的参数值。如表3所示,软件可靠性增长模型的参数值分别使用DS1的80%和100%、DS2的70%和95%进行估计。
表3软件可靠性增长模型的参数估计值
(5)用故障数据集1进行实验
使用12个软件可靠性增长模型、10个模型比较标准(模型属性)和两个故障数据集进行了优化模型选择实验。通过估计模型参数,计算模型属性值,然后对其进行标准化,最后计算余弦相似度。如表4所示,可以看到每两个模型之间的余弦相似性。例如,在使用DS1的80%的故障数据集进行实验后,结果为模型-1、模型-6和模型-10分为一类;模型-2型和模型-12划分为同一类;模型-3和模型-4属于同一类;模型-5与模型-4相似;模型-6、模型-1、模型-7、模型-10和模型-11分为一类;模型-7类似于模型-6、模型-10和模型-11;模型-8、模型-10和模型-11分为一类;模型-10与模型-1、模型-6、模型-7和模型-11相似;模型-11与模型-6、模型-7和模型-10相似;此外,模型-12和模型-2之间还有许多相似之处。但模型-2与其它软件可靠性增长模型并不相似。
接下来,使用DS1的100%故障数据集进行软件可靠性增长模型的余弦相似性研究的情况。如5所示,每两个软件可靠性增长模型之间的余弦相似性。模型-1、模型-6和模型-10分为一类。模型-3与模型-1相似。模型-5与模型-4相似。模型-6、模型-1、模型-7和模型-11属于同一类。模型-7、模型-6、模型-9和模型-11分为一类。模型-8与模型-10相似。模型-9、模型-7和模型-11分为一类。模型-10与模型-1相似。模型-11、模型-6、模型-7和模型-9分为一类。模型-12与模型-1和模型-6相似。但模型-2与其它软件可靠性增长模型并不相似。
从表4和表5分析可以得出以下结论:
1)使用相同故障数据集的不同百分比,相同的软件可靠性增长模型可能具有不同的相似类型。例如,如表4所示,模型-6与模型-10相似,而模型-6与模型-11相似。
2)在不同的测试阶段,同一类型软件可靠性增长模型的性能差异很大。
3)故障检测在不同测试阶段的模式和规律可能不同,它们服从的分布也可能不同。
4)在整个测试过程中,相同类型的软件可靠性增长模型的性能将完全不同。
表4.使用DS1的80%故障数据集进行每两个模型之间的余弦相似性实验结果
表5.使用DS1的100%故障数据集进行每两个模型之间的余弦相似性实验结果
(6)用故障数据集2进行实验
对表6和表7分析。例如,在表6和表7中模型-1都模型-10相似,如表7所示,模型-1还和模型-2、模型-4、模型-6、模型-7、模型-8、模型-11和模型-12类似。这表明在同一测试的不同测试阶段存在不同的适用软件可靠性增长模型类型。相同类型的软件可靠性增长模型在不同的测试阶段可能表现出不同的性能。
基于表4~7的综合比较,发现同一类型软件可靠性增长模型的适用性在不同的测试环境和阶段有所不同。例如,如表4所示,在相同的测试环境下,模型-12和模型-2可以分为一种类型的软件可靠性增长模型。如表5所示,在相同的测试环境下,模型-12、模型-1和模型-6可以归类为一种软件可靠性增长模型。表6显示,模型-12和模型-4都适用于相同的测试条件。如表7所示,在相同的测试环境下,模型-12、模型-1、模型-2、模型-4、模型-6、模型-7、模型-8、模型-10和模型-11可分为一种类型的软件可靠性增长模型。
表6.使用DS2的70%故障数据集进行每两个模型之间的余弦相似性实验结果
表7.使用DS2的95%故障数据集进行每两个模型之间的余弦相似性实验结果
(7)选择最优软件可靠性增长模型的余弦相似性的结果与讨论
如表8所示,在用DS1的80%的故障数据集的情况下,模型-8和模型-10是可以预测软件故障剩余数量和评估软件可靠性的最佳软件可靠性增长模型。此外,在用DS1的100%故障数据集的情况下,模型-12是最佳软件可靠性增长模型。此外,使用DS2的70%的故障数据集情况下,模型-6是所有软件可靠性增长模型中最好的。此外,用DS2的95%的故障数据集情况下,模型-2和模型-4是最佳软件可靠性增长模型。
假设最优模型(Mopt)的属性为SSE=1,MSE=1,R2=1,RMSE=1,KD=1,TS=1,MAE=1,Variance=1,RMSPE=1和MEOP=1。这个结果与表4~7中余弦相似性的比较结果并不矛盾。如表4~7所示,每两个软件可靠性增长模型之间的相似性,即在当前测试环境中是否可以将它们分类为一个类别。如表8所示,在当前的测试环境中,哪些模型和最优模型属于同一类型。如图2~5所示,选出的最优软件可靠性增长模型具有良好的性能。
为了检验软件可靠性增长模型的总体余弦相似性,如图6所示。
如图2~5所示,使用DS1和DS2的故障数据集,模型-1、模型-3、模型-6、模型-7、模型-8、模型-10、模型-11和模型-12具有相对稳定的性能。在使用DS1和DS2的故障数据集情况下,选择的最佳软件可靠性增长模型中,除模型-2和模型-4外,模型-6、模型-8、模型-10和模型-12的性能非常稳定。
综上所述:
1)没有一个软件可靠性增长模型能够适应所有的软件测试环境。
2)在某个软件测试环境中,可以有多个软件可靠性增长模型适应当前的软件测试环境。
3)在确定软件测试环境时,选择的最优软件可靠性增长模型只能适应软件测试的某个阶段。
4)由于软件测试的复杂性、不确定性和主观性,选择最优软件可靠性增长模型需要考虑软件测试的环境和阶段性变化,并考虑多个软件可靠性增长模型适合当前的软件测试情况。
表8.基于余弦相似性的最优软件可靠性增长模型的选择结果
(8)结论
使用余弦相似性来选择最优软件可靠性增长模型。与以前只考虑单个最优模型的优化选择方法不同,提出的优化方法考虑一类相似的模型作为最优模型。事实上,在软件的开发和测试过程中,故障检测和故障引进在不同的阶段表现出不同的模式和特性,服从不同的分布。没有一个模型能够适应所有的软件测试环境和过程。由于软件测试的复杂性和不确定性,多个模型也有可能适应当前的软件测试环境。为了验证所提出的优化模型选择方法的有效性,使用12个模型、10个模型比较标准(模型属性)和两个不同的故障数据集进行了相应的实验。实验结果表明,在同一软件测试阶段,存在多个适用于当前软件测试环境的软件可靠性增长模型。可以利用余弦相似性有效地选择一类最优软件可靠性增长模型。此外,考虑到选择优化软件可靠性增长模型的复杂性,在未来研究其他分类方法将选择最优软件可靠性增长模型。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
- 一种优化选择软件可靠性增长模型的方法
- 一种优化选择软件可靠性增长模型的方法