一种基于人工智能的自然语言处理系统
文献发布时间:2023-06-19 09:24:30
技术领域
本发明属于自然语言处理技术领域,具体涉及一种基于人工智能的自然语言处理系统。
背景技术
自然语言处理(Natural Language Processing,NLP)是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理基本包括认知、理解、生成等部分。自然语言认知和理解是让电脑把获取的自然语言变成有意义的符号并建立相应的关系,然后再根据使用目的进行处理。近年来自然语言处理成为热门研究方向,其中机器翻译是自然语言处理最早的研究工作。
目前,自然语言处理大多是基于规则的方法,在这种方法中,仅限于一个孤立句子的分析,难以配合上下文之间的关联以及谈话语境,因此存在语言处理局限性较大、准确性较低、智能程度较低的问题。
发明内容
鉴于此,为解决现有技术中的不足,本发明的目的在于提供一种基于人工智能的自然语言处理系统。
为实现上述目的,本发明提供如下技术方案:一种基于人工智能的自然语言处理系统,包括:
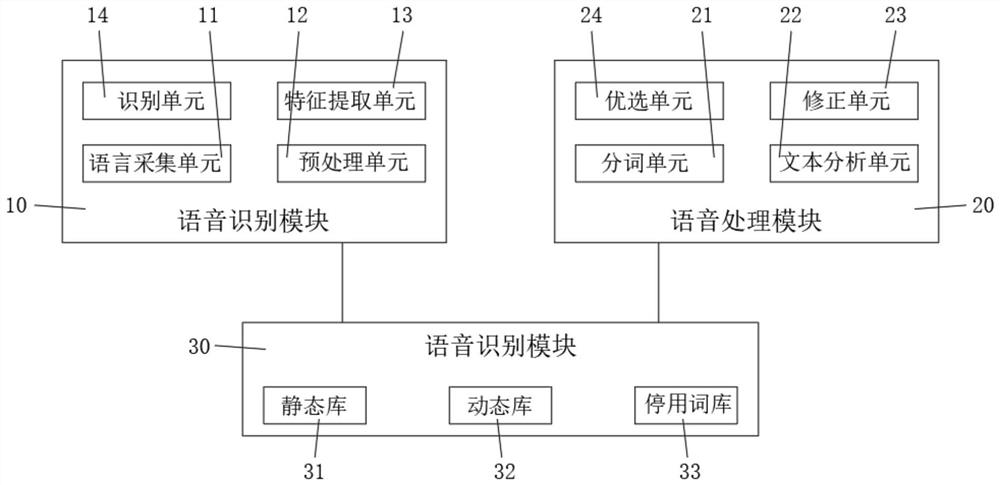
语音识别模块,用于采集、识别语音资料,并将所述语音资料转换为拼音字符所组成的目标文本;
语音处理模块,用于对所述目标文本进行纠错及修正处理,并以处理后的目标修正方案作为输出结果进行输出;
其中,所述语音处理模块包括:
分词单元,用于对所述目标文本进行拼音分词,获得拼音序列;
文本分析单元,识别所述拼音序列的错误,并分析所述错误的类型,且错误类型包括语法错误、语义错误和语用错误;
修正单元,根据所述文本分析单元的分析结果给出至少一个修正方案;
优选单元,对至少一个修正方案进行优化筛选,并以优化筛选后的目标修正方案作为输出结果进行输出。
优选的,所述语音识别模块包括:
语言采集单元,用于在线采集语音资料,并将所述语音资料转换为TXT格式文本进行保存;
预处理单元,根据预设的分词程序对所述格式文本进行分词,并滤除格式文本中已停用的词或词组,获得目标特征集合;
特征提取单元,对所述目标特征集合进行特征提取,获得语音特征序列,并将所述语音特征序列转换为拼音特征序列;
识别单元,将所述拼音特征序列与声学模型进行识别配合与比较,获得目标识别结果,且目标识别结果为拼音字符所组成的目标文本。
优选的,所述预处理单元中所采用的分词程序为中文汉字分词程序。
优选的,所述预处理单元进行分词处理时,相邻词或词组之间通过空格进行分隔。
优选的,在所述特征提取单元中,将所述语音特征序列转换为拼音特征序列包括:
根据汉字的ASCII码将所述语音特征序列转换为拼音特征序列;或
根据汉字的Unicode值将所述语音特征序列转换为拼音特征序列。
优选的,所述的处理系统还包括知识库,且所述知识库包括静态库和动态库,所述修正单元结合错误类型以及所述静态库和动态库中存储的应用文本给出至少一个修正方案。
优选的,所述静态库用于储存标准文本和历史识别的语音文本,并可进行自动更新;所述动态库基于当前采集的语音资料自动构建,且从所述静态库中筛选与当前采集的语音资料语境相同的标准文本或语音文本。
优选的,在所述识别单元中,所述声学模型为通过静态库中的标准文本进行预训练后的声学模型;且每更新一次静态库,对应执行一次声学模型的预训练。
优选的,所述优选单元根据每个修正方案所修正的错误数量进行目标修正方案的优选,且所述目标修正方案所修正的错误数量最多。
优选的,所述知识库还包括停用词库,且所述预处理单元依据停用词库滤除已停用的词或词组。
本发明与现有技术相比,具有以下有益效果:
在本发明中,结合语法分析、语义分析和语用分析对传统识别的自然语言进行进一步的纠错处理,由此使得最终输出的结果能更准确的适应于实际的谈话环境,进而有效提高整体处理系统对语音识别的准确率。
另外,在整体系统中设置包含静态库和动态库的知识库,其中静态库可基于历史识别记录进行自动更新,动态库则基于当前所采集的语音资料自动进行文本信息的筛选,由此进一步提高整体系统对特定问题的适应能力和处理效率。
附图说明
图1为本发明所提供的自然语言处理系统的结构框图;
图2为本发明所提供的自然语言处理系统执行处理时的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明实施例中,公开了一种基于人工智能的自然语言处理系统,具体请参阅图1所示,该处理系统包括如下结构:
语音识别模块10,用于采集、识别语音资料,并将语音资料转换为拼音字符所组成的目标文本;
具体的,语音识别模块10包括如下:
语言采集单元11,用于在线采集语音资料,并将语音资料转换为TXT格式文本进行保存;
预处理单元12,根据预设的分词程序对(TXT)格式文本进行分词,并滤除(TXT)格式文本中已停用的词或词组,获得目标特征集合;其中,关于分词程序,采用的是中文汉字分词程序,且在进行进行分词处理时,相邻词或词组之间通过空格进行分隔;
特征提取单元13,对目标特征集合进行特征提取,获得语音特征序列,并将语音特征序列转换为拼音特征序列;具体表现为,将目标特征集合按照其语音波形随时间的变化分成多个离散的片段,并对多个片段依次进行标号,对应的,每一个片段中均包括至少一个词或词组,由此根据标号能形成语音特征序列;
识别单元14,将拼音特征序列与声学模型进行识别配合与比较,获得目标识别结果,且目标识别结果为拼音字符所组成的目标文本。
语音处理模块20,用于对目标文本进行纠错及修正处理,并以处理后的目标修正方案作为输出结果进行输出;
具体的,语音处理模块20包括如下:
分词单元21,用于对目标文本进行拼音分词,获得拼音序列;
文本分析单元22,识别拼音序列的错误,并分析错误的类型,且错误类型包括语法错误、语义错误和语用错误;
修正单元23,根据文本分析单元22的分析结果给出至少一个修正方案;
优选单元24,对至少一个修正方案进行优化筛选,并以优化筛选后的目标修正方案作为输出结果进行输出。
知识库30,包括静态库31、动态库32和停用词库33。其中,静态库31用于储存标准文本和历史识别的语音文本,并可进行自动更新;动态库32基于当前采集的语音资料自动构建,且从静态库31中筛选与当前采集的语音资料语境相同的标准文本或语音文本。
另外:
上述修正单元23修正处理时,结合错误类型以及静态库31和动态库32中存储的应用文本给出至少一个修正方案。
在识别单元14中,声学模型为通过静态库31中的标准文本进行预训练后的声学模型;且每更新一次静态库31,对应执行一次声学模型的预训练。
具体,关于静态库31中所储存的标准文本信息可从书籍、新闻、网页(例如百度百科、维基百科等)等数据源中收集;例如,可以对书籍中的文字进行文字识别,特别是标准性书籍(如词典等),对应均可储存于静态库31中作为标准文本。
综上,关于上述公开的一种基于人工智能的自然语言处理系统在其进行语音识别处理时,具体包括如下步骤:
S1.在线采集语音资料,并将语音资料转换为TXT格式文本进行保存;
例如,通过语言采集单元11采集的语音资料为“什么时候会下鱼”,对应的其应用语境设为天气查询;
S2.根据预设的中文汉字分词程序对格式文本进行分词,并滤除格式文本中已停用的词或词组,获得目标特征集合;
具体,将“什么时候会下雨”分词形成“什么”-“时候”-“会”-“下鱼”的词及词组序列;并且根据知识库30中的停用词库33,该序列中不包含已停用的词或词组。
S3.对目标特征集合进行特征提取,获得语音特征序列,并将语音特征序列转换为拼音特征序列;
具体,根据汉字的ASCII码将语音特征序列转换为拼音特征序列;由于汉字在计算机系统中以ASCII码表示,只需要利用计算机系统中已有的或用户建立的每个拼音与每个ASCII码对应关系,即可实现将句子转换成拼音序列。若句子含有多音字,则可以根据所采集的语音资料读音进行确定。例如“会”包含有“hui”和“kuai”两个读音,则以语音资料的读音为准,以获得对应的语音特征序列:“shenme”-“shihou”-“hui”-“xiayu”。
另外,还可根据汉字的Unicode值将语音特征序列转换为拼音特征序列。
S4.将拼音特征序列与声学模型进行识别配合与比较,获得目标识别结果,且目标识别结果为拼音字符所组成的目标文本;
S5.用于对目标文本进行拼音分词,获得拼音序列;
S6.识别拼音序列的错误,并分析错误的类型;
在“shenme”-“shihou”-“hui”-“xiayu”中,包括:语义错误“xiayu”,如下雨/下鱼/夏禹/下狱等均有各不相同的语义;语法错误,缺少限定;
S7.结合错误类型以及静态库31和动态库32中存储的应用文本给出至少一个修正方案;
关于上述语义错误,给出方案1:“什么时候会下雨”;给出方案2:“什么时候回夏禹”;
针对语法错误,结合上述方案1,根据静态库31和动态库32中存储的应用文本可知,语法缺少时间限定,进而根据天气查询语境所建立的动态库32给出修正方案可为:“这个星期什么时候会下雨”;结合上述方案2,根据静态库31和动态库32中存储的应用文本可知,语法缺少时间限定和目的限定,进而根据天气查询语境所建立的动态库32给出修正方案可为:“什么时候回夏禹”;
S8.对至少一个修正方案进行优化筛选,并以优化筛选后的目标修正方案作为输出结果进行输出;
由上述给出的两个修正方案可知,“这个星期什么时候会下雨”所修正的错误数量最多最多,因此以“这个星期什么时候会下雨”作为输出结果进行输出。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。