一种基于语音控制的多端联动大屏控制系统及方法
文献发布时间:2024-04-18 19:53:33
技术领域
本发明涉及一种基于语音控制的多端联动大屏控制系统及方法。
背景技术
目前,在煤矿领域,信息中心或者展厅需要通过大屏来进行煤矿安全监控信息的展示。传统的大屏显示是通过监控电脑连接,通过监控电脑来控制大屏显示界面的切换和跳转。
但是,随着信息技术的发展,以及手机和平板等移动终端的普及,传统的大屏显示控制已无法满足企业多样化的需求。因此,如何通过移动终端来实现对大屏的显示控制,从而给观展人员带来更好的观展体验,是煤矿企业用户关注的问题。
发明内容
本发明所要解决的技术问题是,克服现有技术的不足,提供一种基于语音控制的多端联动大屏控制系统及方法,实现大屏显示的移动化控制,通过用户语音远程控制大屏的界面切换和跳转。
为了解决上述技术问题,本发明的技术方案是:
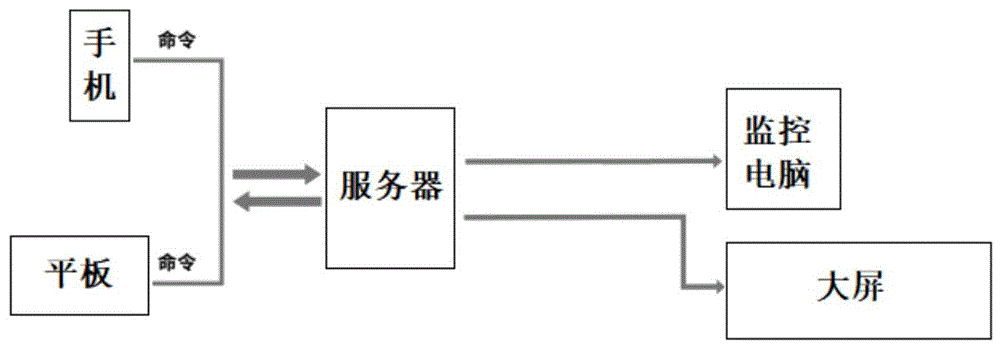
本发明一方面提供一种基于语音控制的多端联动大屏控制系统,它包括移动端、服务器和显示端,所述移动端通过服务器与显示端相连;
所述移动端内设置有联动控制APP,所述联动控制APP将操作指令,通过接口的方式发送至服务器;
所述服务器接收移动端发送的指令,进行指令解析,并将需要的操作结果,发送至显示端,控制显示端根据操作结果进行显示。
进一步,所述移动端包括手机和平板,所述联动控制APP分别安装在手机和平板内。
进一步,所述显示端包括监控电脑和大屏。
本发明另一方面提供一种基于语音控制的多端联动大屏控制系统的控制方法,它包括如下步骤:
步骤S1、在移动端的联动控制APP上进行用户登录;
步骤S2、用户向移动端发送语音命令,由联动控制APP将语音命令信号转换为文字命令信号,调用服务器接口将文字命令信号发送至服务器后台;
步骤S3、由服务器后台配置文字命令信号和显示端菜单的映射关系;
步骤S4、文字命令信号和显示端菜单的映射关系配置完成后,显示端根据映射关系进行语音命令对应的显示界面切换和跳转。
进一步,所述步骤S2中,由联动控制APP将语音命令信号转换为文字命令信号,具体包括如下步骤:
通过AudioRecord采集移动端的麦克风输入的语音命令信号,对语音命令信号进行降噪处理;
将采集到的语音命令信号送入DFSMN语音识别模型进行处理,DFSMN语音识别模型将语音命令信号转换为文字命令信号。
进一步,所述语音命令信号的降噪处理,具体包括如下步骤:
建立语音训练数据集,所述语音训练数据集包括环境噪声和纯净人声;
将语音训练数据集输入至深度神经网络,由深度神经网络训练出语音增强回归算法;
通过语音增强回归算法从环境噪声中分离出纯净人声。
进一步,所述步骤S3中,由服务器后台配置文字命令信号和显示端菜单的映射关系,具体包括如下步骤:
首先建立网页,将网页打开到显示端菜单;
将网页和服务器后台的数据处理服务进行websocket连接,然后将文字命令信号中的关键词与网页链接进行一对一绑定;
当服务器接收到某一关键词时,则对绑定的网页进行操作,显示端进行相应的显示界面跳转和切换。
采用了上述技术方案,本发明可以实现大屏显示的移动化控制,联动控制APP可以方便的安装在智能手机或平板电脑上,实现用户语音远程控制大屏的界面切换和跳转,可以完全替代PC电脑端控制。具有集中管控、同步显示、远程操作等多项功能。将用户从被动地、静态接受的展示状态中解放出来,能够帮助用户更好地融入展览环境,获得双向互动的交流体验。
附图说明
图1为本发明的基于语音控制的多端联动大屏控制系统的原理框图;
图2为本发明的基于语音控制的多端联动大屏控制系统的控制方法的流程图。
具体实施方式
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明。
实施例一
如图1所示,本实施例提供一种基于语音控制的多端联动大屏控制系统,它包括移动端、服务器和显示端,移动端通过服务器与显示端相连。移动端包括手机和平板,联动控制APP分别安装在手机和平板内,显示端包括监控电脑和大屏。
移动端内设置有联动控制APP,用户可以向手机和平板发送语音命令,联动控制APP将操作指令,例如大屏显示页面的切换和跳转等指令通过接口的方式,发送至服务器。
服务器接收移动端发送的指令,进行相关的指令解析,并将需要的操作结果,发送至显示端,控制显示端根据操作结果进行语音命令中对应的操作,例如大屏显示页面的切换和跳转。
实施例二
如图2所示,本实施例提供一种基于语音控制的多端联动大屏控制系统的控制方法,它包括如下步骤:
步骤S1、在移动端的联动控制APP上进行用户登录。
步骤S2、用户向移动端发送语音命令,由联动控制APP将语音命令信号转换为文字命令信号,调用服务器接口将文字命令信号发送至服务器后台。其中,由联动控制APP将语音命令信号转换为文字命令信号,具体包括如下步骤:
首先,通过AudioRecord采集移动端的麦克风输入的语音命令信号,对语音命令信号进行降噪处理,降低环境噪声的干扰,从而提高语音识别的准确率。其中,语音命令信号的降噪处理,具体包括如下步骤:
建立语音训练数据集,语音训练数据集包括环境噪声和纯净人声;
将语音训练数据集输入至深度神经网络,由深度神经网络训练出语音增强回归算法;
通过语音增强回归算法从环境噪声中分离出纯净人声。具有更好的鲁棒性,可以覆盖更广的噪声场景,能够实时分离人声和环境噪声,在任何噪声环境下都能提取出清晰的人声,不受声源方向的限制。
然后,将采集到的语音命令信号送入DFSMN(深度分离卷积递归短时记忆网络)语音识别模型进行处理,DFSMN语音识别模型将语音命令信号转换为文字命令信号。
步骤S3、由服务器后台配置文字命令信号和显示端菜单的映射关系,具体包括如下步骤:
首先建立网页,将网页打开到显示端菜单;
将网页和服务器后台的数据处理服务进行websocket连接,然后将文字命令信号中的关键词与网页链接进行一对一绑定;
当服务器接收到某一关键词时,则对绑定的网页进行操作,显示端进行相应的显示界面跳转和切换。
步骤S4、文字命令信号和显示端菜单的映射关系配置完成后,显示端根据映射关系进行语音命令对应的显示界面切换和跳转。
例如:将“首页”与“/home”的路径做了绑定,当服务器收到移动端的“显示首页”语音命令时,服务器会发出映射好的路径“/home”给大屏,大屏进行响应的跳转,在大屏上显示首页界面。
例如:用户手持移动终端,向移动终端发送“打开瓦斯泵房监测界面”语音命令,识别到已绑定的“瓦斯泵房”关键词,则大屏跳转到瓦斯泵房监测界面。
例如:用户手持移动终端,向移动终端发送“打开水泵房监测界面”语音命令,识别到已绑定的“水泵房”关键词,则大屏跳转到水泵房监测界面。
例如:用户手持移动终端,向移动终端发送“打开皮带机头机尾监测界面”语音命令,识别到已绑定的“皮带机头机尾”关键词,则大屏跳转到皮带监测界面。
此外,如果用户A在监控电脑A上有打开到大屏,服务器会将大屏地址传输至监控电脑A做相应显示跳转,用户B在监控电脑B上打开的大屏显示界面则不受影响。
以上所述的具体实施例,对本发明解决的技术问题、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。