估计用于处理所获取的声音数据的优化掩模
文献发布时间:2024-04-18 19:58:21
技术领域
本说明书涉及声音数据的处理,特别是在远场声音捕获的上下文中。
例如,当说话人远离声音捕获设备时,发生远场声音捕获。然而,它提供了用户与用户当前正在使用的服务“免提(hands-free)”交互的真正的人体工程学舒适性所证明的优点:进行电话呼叫、经由智能扬声器设备(谷歌家居(Google Home)
另一方面,远场声音捕获引入某些伪像:混响和周围噪声由于与用户的距离而显得放大。这些伪像降低了说话者语音的可懂度,并因此削弱了服务的操作。显然,无论是与人还是与语音识别引擎的通信都更加困难。
此外,免提终端(诸如智能扬声器或会议电话)通常配备有麦克风天线,该麦克风天线通过减少这些中断来增强期望的信号。基于天线的增强利用在多通道记录期间编码的并且特定于每个源的空间信息,将感兴趣信号与其他噪声源区分开。
存在许多天线处理技术,诸如“延迟和求和(Delay and Sum)”滤波器,其通过仅知道来自感兴趣源或来自其他源的到达方向来执行纯空间滤波,或者“MVDR”滤波器(代表“最小方差无失真响应”),其由于除了知道来自感兴趣源的到达方向之外,还知道噪声的空间分布而被示出为稍微更有效。其他甚至更有效的滤波器(诸如多通道维纳滤波器)也要求感兴趣源的空间分布是可用的。
实际上,这些空间分布的知识来自时间-频率图的知识,该时间-频率图指示该图中由语音主导的点和由噪声主导的点。该图的估计(也称为掩模)通常由先前训练的神经网络推断。
此后,包含语音和噪声的混合的信号在时频域中被表示为x(t,f)=s(t,f)+n(t,f),其中s(t,f)是语音并且n(t,f)是噪声。
掩模(表示为
因此,我们寻求掩模
背景技术
深度神经网络的使用(在利用人工智能的方法中)已经用于源分离。这种实施方式的描述例如在文献[@umbachChallenge]中给出,其参考文献在下面的附录中给出。已经研究了诸如最简单的“前馈”(FF)类型的架构,并且与通常基于模型(如参考文献[@heymannNNmask]中所述)的信号处理方法相比,已经显示出它们的有效性。被称为“LSTM”(如[@laurelineLSTM]中所描述的长短期记忆)或“Bi-LSTM”(如[@heymannNNmask]中所描述)的类型的“循环”架构(其使得可能更好地利用信号的时间依赖性)显示出更好的性能,但计算成本非常高。为了降低这种计算成本,无论是用于训练还是推理,已经成功地提出了称为“CNN”(卷积神经网络)的卷积架构([@amelie Unet],[@janssonUnetSinger]),除了并行执行计算的可能性之外,还改善了性能并降低了计算成本。虽然用于分离的人工智能方法通常利用时频域中的特性,但是也已经成功地采用了纯时间架构([@stollerWaveUnet])。
所有这些用于增强和分离的人工智能方法为噪声是问题的任务(转录、识别、检测)提供了真正的附加值。然而,这些架构在存储和计算能力方面都具有共同的高成本。深度神经网络模型由数十个层和数十万或甚至数百万个参数组成。此外,它们的学习需要在现实条件下注释和记录的大型详尽数据库,以确保它们泛化到所有使用条件。
发明内容
本说明书改善了这种情况。
提出了一种用于处理由多个麦克风获取的声音数据的方法,其中:
-基于由多个麦克风获取的声音数据,确定源自至少一个感兴趣声源的声音的到达方向,
-根据声音的到达方向对声音数据应用空间滤波,
-在时频域中估计一方面的经滤波的声音数据与另一方面的所获取的声音数据之间的表示信号幅度的幅度的比率,
-根据所估计的比率,产生权重掩模以在时频域中应用于所获取的声音数据,以便构造表示源自感兴趣源的声音并相对于环境噪声增强的声学信号。
这里,术语“表示信号幅度的量”意为信号的幅度,但也意为其能量或其功率等。因此,可以通过将由经滤波的声音数据表示的信号的幅度(或能量或功率等)除以由获取的(因此原始的)声音数据表示的信号的幅度(或能量或功率等)来估计上述比率。
由此获得的权重掩模然后在时频域的每个时频点处表示感兴趣声源相对于环境噪声的主导程度。
可以估计权重掩模,以便直接构造表示源自感兴趣源的声音并且相对于环境噪声增强的声学信号,或者计算第二空间滤波器,该第二空间滤波器可以比上述直接构造的情况更有效地更强烈地减少噪声。
通常,然后可以在不使用神经网络的情况下获得时频掩模,唯一的先验知识是来自相关源的到达方向。然后,该掩模使得可能实现有效的分离滤波器,诸如MVDR滤波器(“最小方差无失真响应”)或来自多通道维纳滤波器族的滤波器。该掩模的实时估计使得可能导出低等待时间滤波器。此外,即使在感兴趣信号淹没在周围噪声中的不利条件下,其估计也保持有效。
在一个实施例中,上述第一空间滤波(应用于在估计比率之前获取的数据)可以是“延迟和求和”类型。
实际上,在这种情况下,例如,连续延迟可以应用于由沿着天线布置的麦克风捕获的信号。由于麦克风之间的距离以及因此这些捕获信号之间的这些距离固有的相移是已知的,因此可以对所有这些信号进行定相,然后可以进行求和。
在立体混响声(ambisonic)域中获取的信号的变换的情况下,信号的幅度表示麦克风之间的距离固有的这些相移。这里再次,可以对这些幅度进行加权,以便实现可以被描述为“延迟和求和”的处理。
在一个变型中,该第一空间滤波可以属于MPDR类型(代表“最小功率无失真响应”)。这具有在保持相关信号完整的同时更好地减少周围噪声的优点,并且除了到达方向之外不需要任何信息。这种类型的过程例如在文献[@gannotResume]中被描述,其内容在下面详细描述,并且在附录中给出完整引用。
然而,这里,MPDR类型的空间滤波(表示为w
其中a
其中:
-Ω(t,f)是时频点(t,f)的邻域,
-card是“基数(cardinal)”算子,
-x(t
此外,如上所述,该方法可以可选地包括细化权重掩模以便对其估计进行降噪的后续步骤。
为了执行该后续步骤,可以通过平滑(例如通过应用启发式定义的局部均值)来对估计进行降噪。
替代地,可以通过定义初始掩模分布模型来对该估计进行降噪。
第一方法保持低复杂度,而基于模型的第二方法以增加的复杂度为代价获得更好的性能。
因此,在第一实施例中,可以通过应用在所考虑的时频点(t,f)的时间-频率邻域上计算的局部统计算子,通过在每个时频点处进行平滑来进一步细化所产生的权重掩模。该算子可以采用平均值、高斯滤波器、中值滤波器或其他的形式。
在第二实施例中,为了执行上述第二方法,可以通过应用概率方法在每个时频点处进行平滑来进一步细化所产生的权重掩模,该概率方法包括:
-将权重掩模视为随机变量,
-定义随机变量的模型的概率估计量,
-搜索概率估计量的最优,以便改善权重掩模。
通常,掩模可以被视为区间[0,1]内的均匀随机变量。
掩模Ms(t,f)的概率估计量可以例如表示在变量对的多个观测
-声学信号
-所获取的声音数据x
所述观测在所考虑的时频点(t,f)的邻域内选择。
因此,这两个实施例旨在在掩模估计之后细化掩模。如上所述,所获得的(可选地细化的)掩模可以直接应用于所获取的数据(原始的、由麦克风捕获的),或者可以用于构建要应用于这些获取的数据的第二空间滤波器。
因此,在该第二情况下,表示源自感兴趣源的声音并且相对于环境噪声增强的声学信号的构造可以涉及应用从权重掩模获得的第二空间滤波。
该第二空间滤波可以属于MVDR类型(代表“最小方差无失真响应”),并且在这种情况下,针对环境噪声估计至少一个空间协方差矩阵R
其中:
-Ω(t,f)是时频点(t,f)的邻域,
-card是“基数”算子,
-x(t
-M
替代地,第二空间滤波可以属于MWF类型(代表“多通道维纳滤波器”),并且在这种情况下,空间协方差矩阵R
MWF类型的空间滤波由下式给出:
w
其中:
其中:
-Ω(t,f)是时频点(t,f)的邻域,
-card是“基数”算子,
-x(t
-M
上述空间协方差R
应当理解,在该实施例中,可以如何根据针对最有利的时频点估计的掩模来导出所执行的空间滤波,例如MWF,因为感兴趣声源在这些时频点主导。还应当注意,可以执行两个联合优化:一个是声学信号的协方差R
因此,上述解决方案通常使得可能仅基于关于来自感兴趣源的到达方向的信息,而没有来自神经网络的贡献(用于将掩模直接应用于所获取的数据,或者用于构造要应用于所获取的数据的第二空间滤波),在感兴趣源主导的时频点处在时间-频率域中估计最佳掩模。
本说明书还提出了一种计算机程序,该计算机程序包括用于在程序由处理器执行时实现如本文所定义的方法的全部或部分的指令。根据另一方面,提供了一种其上存储有这样的程序的非暂时性计算机可读存储介质。
本说明书还提出了一种设备,包括(如图3所示)用于接收由多个麦克风(MIC)获取的声音数据的至少一个接口(IN)和处理电路(PROC,MEM),该处理电路(PROC,MEM)被配置用于:
-基于由多个麦克风获取的声音数据,确定源自至少一个感兴趣声源的声音的到达方向,
-根据声音的到达方向对声音数据应用空间滤波,
-在时频域中估计一方面的经滤波的声音数据与另一方面的所获取的声音数据之间的表示信号幅度的幅度的比率,
-根据所估计的比率,产生权重掩模以在时频域中应用于所获取的声音数据,以便构造表示源自感兴趣源的声音并相对于环境噪声增强的声学信号。
因此,设备还可以包括用于传递该声学信号的输出接口(在图3中表示为OUT)。该接口OUT可以连接到语音识别模块,例如以便不管环境噪声如何都正确地解释来自用户的命令,因此已经根据上述方法处理了所传递的声学信号。
附图说明
通过阅读下面的详细描述并通过分析附图,其他特征、细节和优点将变得显而易见,其中:
图1
[图1]示意性地示出了利用上述方法的可能上下文。
图2
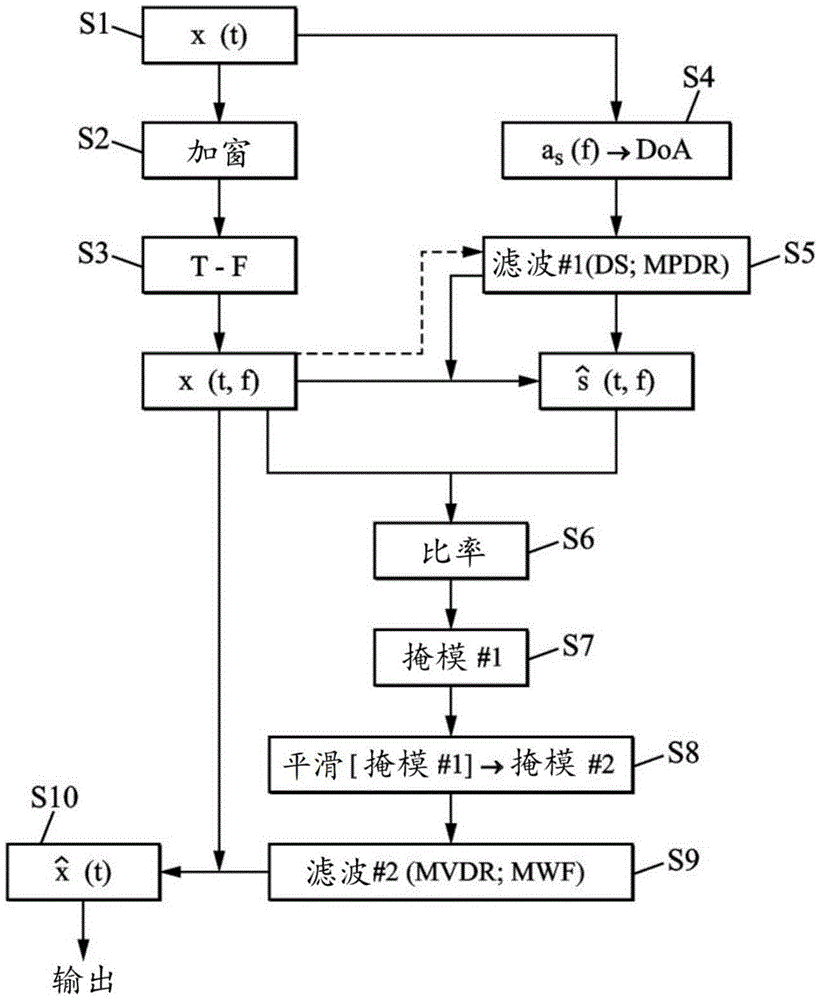
[图2]图示了根据一个特定实施例的可以包括在本说明书含义内的方法中的一系列步骤。
图3
[图3]示意性地示出了根据一个实施例的用于处理声音数据的设备的示例。
具体实施方式
这里再次参考图3,上面呈现的设备DIS的处理电路通常可以包括能够存储上述计算机程序的指令的存储器MEM、以及能够与存储器MEM协作以便执行计算机程序的处理器PROC。
通常,输出接口OUT可以提供个人助理的语音识别模块MOD,其能够在上述声学信号中标识来自用户UT的语音命令,如图1所示,用户UT可以说出由麦克风天线MIC捕获的语音命令,特别是在存在由例如用户UT所在的房间的墙壁和/或隔断生成的环境噪声和/或声音混响REV的情况下这样做。然而,在本说明书和下面详述的含义内,处理所获取的声音数据使得可能克服这些困难。
图2中示出了本说明书含义内的一般方法的一个示例。该方法开始于获取由麦克风捕获的声音数据的第一步骤S1。接下来,在步骤S2中执行加窗之后,在步骤S3中执行所获取的信号的时间-频率变换。然后可以在步骤S4中估计源自感兴趣源的声音的到达方向(DoA),特别是给出该到达方向的向量a
由N个信道组成的天线信号在下面被表示为x(t),在步骤S1中以列向量的形式组织:
该向量被称为“观测”或“混合”向量。
信号x
在下文中,在步骤S3中,各种量(信号、协方差矩阵、掩模、滤波器)在时频域中表示如下:
其中,
在上述关系式中,
其中M≤L,并且其中w(k)是汉宁窗(Hann)或其他类型的加窗窗口。
可以根据可用信息定义几个增强滤波器。然后,它们可以用于推导时频域中的掩模。
对于给定位置的源s,指向该源的方向(声音的到达方向)的列向量被标记a
其中c是声音在空气中的速度。
第一通道在此对应于声波遇到的最后一个传感器。然后,该导向向量给出声音的到达方向或“DOA”。
在通常按照SID/N3D格式的一阶3D立体混响天线的情况下,导向向量也可以由以下关系式给出:
其中(θ,φ)对对应于源相对于天线的方位角和俯仰角。
仅知道来自声源的到达方向(或DOA),在步骤S5中,可以定义延迟和求和(DS)类型的滤波器,其指向该源的方向,如下:
w
还可以使用稍微更复杂但也更强大的滤波器,诸如MPDR滤波器(代表“最小功率无失真响应”)。除了由源发出的声音的到达方向之外,该滤波器还需要通过其空间协方差矩阵R
其中由天线捕获的多维信号x的空间协方差由以下关系式给出:
这种实施方式的细节特别地在附录中指定的参考文献[@gannotResume]中描述。
最后,如果用于感兴趣信号s和噪声n的空间协方差矩阵R
w
以及调用空间协方差矩阵,该空间协方差矩阵表示由感兴趣源R
估计混合x的空间协方差的一种方式是执行局部时频积分:
其中Ω(t,f)是时频点(t,f)周围的或多或少宽的邻域,并且card是“基数”算子。
由此,已经可以估计可以在步骤S5中应用的第一滤波w
对于矩阵R
噪声掩模M
这里的目的是估计这些时频掩模M
在时间t处源自相关源s的声音的到达方向(或“DOA”,在步骤S4中获得)(表示为doa
因此,仅知道相关源s的DOA,我们寻求在步骤S7中估计这些掩模。时频域中的相关信号的增强版本是可用的。通过在步骤S5中应用指向相关源的方向的空间滤波器w
根据该滤波器,通过在步骤S5中应用滤波器来增强感兴趣信号s:
该增强的信号使得可能在步骤S7中计算由来自步骤S6的比率给出的初步掩模
其中x
例如,对于立体混响天线,可以使用作为全向信道的第一信道。在线性天线的情况下,它可以是对应于任何传感器的信号。
在信号被滤波器w
下面描述掩模细化步骤S8。尽管该步骤是有利的,但是它决不是必要的,并且可以可选地执行,例如如果在步骤S7中为滤波估计的掩模被证明是超过所选阈值的噪声。
为了限制掩模中的噪声,在步骤S8中应用平滑函数soft(.)。该平滑函数的应用可以相当于估计每个时频点处的局部平均值,例如如下:
其中Ω
替代地,可以选择例如由高斯核加权的平均值,或者对于异常值更鲁棒的中值算子。
该平滑函数可以应用于观测
为了改进估计,可以应用第一饱和步骤,这确保掩模确实在区间[0,1]内:
实际上,上述方法有时导致低估掩模。可能感兴趣的是通过应用以下类型的饱和函数sat(.)来“校正”先前的估计:
其中u
基于原始观测估计掩模的另一方式包括,不是执行平均运算,而是通过设置R为由以下定义的随机变量来采用概率方法:
其中:
-
-x对应于混合的特定通道,以及
-M
这些变量可以被视为时间和频率相关的。
变量R|M
其中V(.)是方差算子。
还可以假设M
在一个变型中,可以定义有利于掩模简约性的另一分布,例如指数定律。
基于对所描述的变量施加的模型,可以使用概率估计量来计算掩模。这里,我们在最大似然的意义上描述掩模M
假设我们对于变量对具有一定数量I的观测
掩模的似然函数写作:
最大似然估计量直接由表达式
其中/>
再次,为了避免区间[0,1]之外的值,我们可以应用以下类型的饱和运算:
概率方法过程比使用局部平均的过程噪声小。它呈现较低的方差,其代价是由于需要计算局部统计量而导致较高的复杂度。这使得例如可以在没有有用信号的情况下正确地估计掩模。
该方法可以在步骤S9中继续,通过基于权重掩模产生第二空间滤波,特别是产生矩阵M
其中:
-Ω(t,f)是时频点(t,f)的邻域,
-card是“基数”算子,
-x(t
-M
然后,MWF类型的空间滤波由下式给出:
w
作为变型,应当注意,如果保留的第二滤波是MVDR类型,则第二滤波由下式
其中Ω(t,f)和card如上所定义。
一旦将该第二空间滤波应用于所获取的数据x(t,f),就可以应用逆变换(从时间-频率空间到直接空间)并且在步骤S10中获得表示源自感兴趣源的声音并且相对于环境噪声增强的声学信号
工业应用
这些技术解决方案特别适用于经由复杂滤波器的语音增强,例如MWF类型滤波器([@laurelineLSTM],[@amelieUnet]),这确保了良好的收听质量和高速率的自动语音识别,而不需要神经网络。该方法可以用于检测关键字或“唤醒词”,或者甚至用于语音信号的转录。
引用文献列表
为方便起见,引用了以下非专利参考文献:
[@amelieUnet]:Amélie Bosca等人,“Dilated U-net based approach formultichannel speech enhancement from First-Order Ambisonics recordings”,Computer Speech&Language(2020),第37-51页
[@laurelineLSTM]:L.Perotin等人,“Multichannel speech separation withrecurrent neural networks from high-order Ambisonics recordings”,Proc.ofICASSP.ICASSP 2018-IEEE International Conference on Acoustics,Speech andSignal Processing,2018年,第36-40页。
[@umbachChallenge]:Reinhold Heab-Umbach等人,“Far-Field AutomaticSpeech Recognition”,arXiv:2009.09395v1。
[@heymannNNmask]:J.Heymann、L.Drude和R.Haeb-Umbach,“Neural networkbased spectral mask estimation for acoustic beamforming”,Proc.of ICASSP,2016年,第196-200页。
[@janssonUnetSinger]:A.Jansson、E.Humphrey、N.Montecchio、R.Bittner、A.Kumar和T.Weyde,“Singing voice separation with deep U-net convolutionalnetworks”,Proc.of Int.Soc.for Music Inf.Retrieval,2017年,第745-751页。
[@stollerWaveUnet]:D.Stoller、S.Ewert和S.Dixon,“Wave-U-Net a multi-scale neural network for end-to-end audio source separation”,Proc.ofInt.Soc.for Music Inf.Retrieval,2018年,第334-340页。
[@gannotResume]:Sharon Gannot等人,“A Consolidated Perspective onMultimicrophone Speech Enhancement and Source Separation”,IEEE/ACM Transac-tions on Audio,Speech,and Language Processing 25.4(2017年4月),第692-70页,issn:2329-9304.doi:10.1109/TASLP.2016.2647702。
[@diBiaseSRPPhat]:J.Dibiase、H.Silverman和M.Brandstein,“Robustlocalization in reverberant rooms”,Microphone Arrays:Signal ProcessingTechniques and Applications.Springer,2001年,第157-180页。
- 处理音频数据的方法和实行这个方法的声音获取设备
- 处理音频数据的方法和实行这个方法的声音获取设备