使用大型语言模型生成自动化助理响应
文献发布时间:2024-04-18 19:58:21
背景技术
人类可以与本文中称为“自动化助理”(也称为“聊天机器人”、“交互式个人助理”、“智能个人助理”、“个人话音助理”、“谈话代理”等)的交互式软件应用进行人机对话。自动化助理通常依赖一系列组件来解释和响应于口述话语。例如,自动语音辨识(ASR)引擎可以处理与用户的口述话语相对应的音频数据以生成ASR输出,诸如口述话语的ASR假设(即词项和/或其他标记的序列)。此外,自然语言理解(NLU)引擎可以处理ASR输出(或触摸/键入输入)以生成NLU输出,诸如由用户在提供口述话语(或触摸/键入输入)时表达的请求(例如,意图)以及可选地与意图相关联的参数的槽值。最终,NLU输出可以由各种履行组件处理以生成履行输出,诸如响应于口述话语的响应性内容和/或可以响应于口述话语而执行的一个或多个动作。
一般而言,通过用户提供口述话语发起与自动化助理的对话会话,并且自动化助理可以使用前述一系列组件来响应于口述话语。用户可以通过提供附加口述话语来继续对话会话,并且自动化助理可以使用前述一系列组件再次响应于附加口述话语。换句话说,这些对话会话通常是基于轮次(turn-based)的,因为用户在对话会话中的轮次中提供口述话语,自动化助理在对话会话中的轮次中响应于口述话语,用户在对话会话中的附加轮次中提供附加口述话语,自动化助理在对话会话中的附加轮次中响应于附加口述话语,等等。然而,从用户的角度来看,这些基于轮次的对话会话可能不自然,因为它们没有反映人类实际如何彼此交谈。
例如,如果第一人在对话会话期间提供口述话语以向第二人传达初始想法(例如,“I’m going to the beach today(我今天要去海滩)”),则第二人可以在对话会话的上下文下考虑该口述话语来制定对第一人的响应(例如,“sounds fun,what are you going todo at the beach?(听起来很有趣,你要在海滩做什么?)”,“nice,have you looked atthe weather?(很好,你看过天气吗?)”等等)。值得注意的是,第二人在响应于第一人时可以提供口述话语,其使第一人以自然的方式继续进行对话会话。换句话说,在对话会话期间,第一人和第二人都可以提供口述话语以促进自然对话,并且无需这些人之一驱动对话会话。
然而,如果在上述示例中第二人被自动化助理替换,则自动化助理可能无法提供使第一人继续进行对话会话的响应。例如,响应于第一人提供“I’m going to the beachtoday”的口述话语,自动化助理可能只是简单地响应“sounds fun”或“nice”,而不提供任何附加响应来促进对话会话,并且尽管自动化助理能够执行某个动作和/或提供某个响应来促进对话会话,诸如主动询问第一人他们打算在海滩做什么、主动查找第一人经常访问的海滩的天气预报并在响应中包括天气预报、主动基于天气预报做出一些推断等。因此,由自动化助理响应于第一人的口述话语提供的响应可能不会与第一人产生共鸣,因为响应可能无法反映多人之间的自然谈话。此外,第一个人可能必须提供附加口述话语来明确请求自动化助理可以主动提供的某些信息(例如,海滩的天气预报),从而增加指向自动化助理的口述话语的数量并浪费用于处理这些口述话语的客户端设备的计算资源。
发明内容
本文描述的实施方式涉及使得自动化助理能够在对话会话期间执行与用户的自然谈话。一些实施方式可以接收捕获用户的口述话语的音频数据流。音频数据流可以由客户端设备的一个或多个麦克风生成,并且口述话语可以包括助理查询。一些实施方式可以进一步基于处理音频数据流来确定助理输出集合,并且处理助理输出集合和对话会话的上下文以使用利用大型语言模型(LLM)生成的一个或多个LLM输出生成修改的助理输出集合。可以基于对话会话的上下文的至少一部分以及包括在助理输出集合中的助理输出中的一个或多个来确定一个或多个LLM输出中的每一个。一些实施方式还可以使得来自修改的助理输出集合当中的给定的修改的助理输出被提供以呈现给用户。此外,一个或多个LLM输出中的每一个可以包括例如跨一个或多个词汇的一个或多个词和/或短语的序列的概率分布,以及可以基于概率分布将该序列中的一个或多个词和/或短语选择作为一个或多个LLM输出。此外,可以基于一个或多个上下文信号来确定对话会话的上下文,该上下文信号包括例如一天中的时间、一周中的一天、客户端设备的位置、在客户端设备的环境中检测到的环境噪声、用户简档数据、软件应用数据、关于客户端设备的用户的已知环境的环境数据、用户和自动化助理之间的对话会话的对话历史和/或其他上下文信号。
在一些实施方式中,可以基于使用流式自动语音辨识(ASR)模型处理音频数据流来确定助理输出集合,以生成ASR输出流,诸如被预测为对应于口述话语的一个或多个辨识的词项或短语、被预测为对应于口述话语的一个或多个音素、与一个或多个辨识的词项或短语和/或一个或多个预测的音素中的每个相关联的一个或多个预测度量、和/或其他ASR输出。此外,可以使用自然语言理解(NLU)模型来处理ASR输出,以生成NLU输出流,诸如用户在提供口述话语时的一个或多个预测意图以及与一个或多个预测意图中的每个相关联的一个或多个参数的一个或多个对应的槽值。此外,NLU数据流可以由一个或多个第一方(1P)和/或第三方(3P)系统处理以生成助理输出集合。如本文所使用的,一个或多个1P系统包括由开发和/或维护本文描述的自动化助理的同一实体(例如,共同的发布者)开发和/或维护的系统,而一个或多个3P系统包括由与开发和/或维护本文描述的自动化助理的实体不同的实体开发和/或维护的系统。值得注意的是,本文描述的助理输出集合包括通常被考虑用于响应于口述话语的助理输出。然而,通过使用要求保护的技术,以上述方式生成的助理输出集合可以被进一步处理以生成修改的助理输出集合。具体地,可以使用一个或多个LLM输出来修改助理输出集合,并且可以从修改的助理输出集合中选择给定的修改的助理输出,以响应于接收到口述话语而被提供以呈现给用户。
例如,假设客户端设备的用户提供“Hey Assistant,I’m thinking about goingsurfing today(嘿助理,我今天正在考虑去冲浪)”的口述话语。在该示例中,自动化助理可以以上述方式处理口述话语以生成助理输出集合和修改的助理输出集合。在该示例中,包括在助理输出集合中的助理输出可以包括例如“That sounds like fun!(那听起来很有趣!)”、“Sounds fun!(听起来很有趣!)”等。此外,在该示例中,包括在修改的助理输出集合中的助理输出可以包括例如“That sounds like fun,how long have you been surfing?(这听起来很有趣,你冲浪多久了?)”、“Enjoy it,but if you’re going to ExampleBeach again,be prepared for some light showers(享受它,但是如果你要再次去示例海滩,做好迎接小阵雨的准备)”等等。值得注意的是,包括在助理输出集合中的助理输出不包括以进一步使客户端设备的用户进行对话会话的方式驱动对话会话的任何助理输出,但是包括在修改的助理输出集合中的助理输出包括以通过询问上下文相关的问题(例如,“how long have you been surfing?”)进一步使客户端设备的用户进行对话会话的方式驱动对话会话、提供上下文相关的信息(例如,“but if you’re going to Example Beachagain,be prepared for some light showers”)、和/或以其他方式在对话会话的上下文中与客户端设备的用户产生共鸣的助理输出。
在一些实施方式中,可以使用以在线方式生成的一个或多个LLM输出来生成修改的助理响应集合。例如,响应于接收到口述话语,自动化助理可以使得以上述方式生成助理输出集合。此外,并且还响应于接收到口述话语,自动化助理可以使得使用一个或多个LLM处理助理输出集合、对话会话的上下文和/或包括在口述话语中的助理查询,以基于使用一个或多个LLM生成的一个或多个LLM输出来生成修改的助理输出集合。
在附加或替选实施方式中,可以使用以离线方式生成的一个或多个LLM输出来生成修改的助理响应集合。例如,在接收到口述话语之前,自动化助理可以从助理活动数据库(其可以是客户端设备的用户的有限的助理活动)获得多个助理查询以及针对多个助理查询中的每个的对应先前对话会话的对应上下文。此外,自动化助理可以使得对于多个助理查询中的给定助理查询,以上述方式并且针对给定助理查询生成助理输出集合。此外,自动化助理可以使得使用一个或多个LLM来处理助理输出集合、对话会话的对应上下文和/或给定助理查询,以基于使用一个或多个LLM生成的一个或多个LLM输出来生成修改的助理输出集合。可以针对多个查询中的每个以及由自动化助理获得的先前对话会话的对应上下文来重复该过程。
另外,自动化助理可以在由用户的客户端设备能够访问的存储器中对一个或多个LLM输出进行索引。在一些实施方式中,自动化助理可以使得一个或多个LLM基于多个助理查询中包括的一个或多个词项而在存储器中被索引。在附加或替选实施方式中,自动化助理可以为多个助理查询中的每个生成对应嵌入(例如,word2vec嵌入或另一低维表示),并且将对应嵌入中的每个映射到助理查询嵌入空间以对一个或多个LLM输出进行索引。在附加或替选实施方式中,自动化助理可以使得一个或多个LLM基于对应先前上下文中包括的一个或多个上下文信号而在存储器中被索引。在附加或替选实施方式中,自动化助理可以为对应上下文中的每个生成对应嵌入,并且将对应嵌入中的每个映射到上下文嵌入空间以对一个或多个LLM输出进行索引。在附加或替选实施方式中,自动化助理可以使得一个或多个LLM基于包括在针对多个助理查询中的每个的助理输出集合中的助理输出的一个或多个词项或短语而在存储器中被索引。在附加或替选实施方式中,自动化助理可以为包括在助理输出集合中的每个助理输出生成对应嵌入(例如,word2vec嵌入,或另一个低维表示),并且将每个对应嵌入映射到助理输出嵌入空间以对一个或多个LLM输出进行索引。
因此,当随后在用户的客户端设备处接收到口述话语时,自动化助理可以识别基于对应于包括在多个查询中的一个或多个助理查询的当前助理查询、对应于一个或多个对应先前上下文的当前上下文和/或对应于一个或多个先前助理输出的一个或多个当前助理输出而在先生成的一个或多个LLM输出。例如,在基于先前助理查询的对应嵌入对一个或多个LLM输出进行索引的实施方式中,自动化助理可以使得生成当前助理查询的嵌入并将其映射到助理查询嵌入空间。此外,自动化助理可以基于查询嵌入空间中当前助理查询的嵌入与先前助理查询的对应嵌入之间的距离满足阈值来确定当前助理查询对应于先前助理查询。自动化助理可以从存储器获得基于处理先前助理查询而生成的一个或多个LLM输出,并且利用该一个或多个LLM输出来生成修改的助理输出集合。此外,例如,在一个或多个LLM基于包括在多个助理查询中的一个或多个词项被索引的实施方式中,自动化助理可以确定例如当前助理查询与多个先前助理之间的编辑距离,以识别对应于当前助理查询的先前助理查询。类似地,自动化助理可以从存储器获得基于处理先前助理查询而生成的一个或多个LLM输出,并且利用该一个或多个LLM输出来生成修改的助理输出集合。
在一些实施方式中,并且除了一个或多个LLM输出之外,可以基于处理助理查询和/或对话会话的上下文来生成附加助理查询。例如,在处理助理查询和/或对话会话的上下文时,自动化助理可以基于NLU数据流来确定与给定助理查询相关联的意图。此外,自动化助理可以基于与给定助理查询相关联的意图来识别与与助理查询相关联的意图相关的至少一个相关意图(例如,基于该意图到客户端设备可访问的数据库或存储器中的至少一个相关意图的映射和/或基于使用一个或多个机器学习(ML)模型或启发式定义的规则处理与给定助理查询相关联的意图)。此外,自动化助理可以基于至少一个相关意图来生成附加助理查询。例如,假设助理查询指示用户要去海滩(例如,“Hey assistant,I’m going tothe beach today(嘿助理,我今天要去海滩)”)。在该示例中,附加助理查询可以对应于例如“what’s the weather at Example Beach?(示例海滩的天气怎么样?)”(例如,以主动确定用户通常访问的名为Example Beach(示例海滩)的海滩的天气信息)。值得注意的是,可以不提供附加助理查询以呈现给客户端设备的用户。
相反,在这些实施方式中,可以基于处理附加助理查询来确定附加助理输出。例如,自动化助理可以将结构化请求传输到一个或多个1P和/或3P系统以获得天气信息作为附加助理输出。进一步假设天气信息指示示例海滩预计会下雨。在这些实施方式的一些版本中,自动化助理可以进一步使得使用一个或多个LLM输出和/或一个或多个附加LLM输出来处理附加助理以生成附加的修改的助理输出集合。因此,在上面提供的初始示例中,响应于接收到“Hey Assistant,I’m thinking about going surfing today”的口述话语而被提供给用户的来自初始的修改的助理输出集合的给定的修改的助理输出可能是“Enjoyit”,并且来自附加的修改的助理输出集合的给定的附加的修改的助理输出可能是“but ifyou’re going to Example Beach again,be prepared for some light showers”。换句话说,自动化助理
在各种实施方式中,在生成修改的助理输出集合时,可以使用多个相异的参数集合中的对应参数集合来生成所利用的一个或多个LLM输出中的每个。多个相异的参数集合中的每个参数可以与自动化助理的相异个性相关联。在那些实施方式的一些版本中,可以利用单个LLM以使用每个相异个性的对应参数集合来生成一个或多个对应LLM输出,而在那些实施方式的其他版本中,可以利用多个LLM以使用每个相异个性的对应参数集合来生成一个或多个对应LLM输出。因此,当来自修改的助理输出集合的给定的修改的助理输出被提供以呈现给用户时,其可以经由不同个性的韵律属性(例如,这些不同个性的语调、抑扬顿挫、音高、停顿、语速、重音、节律等)反映各种动态上下文个性。
值得注意的是,本文描述的这些个性回复不仅反映了不同个性的韵律属性,而且还可以反映不同个性的相异词汇和/或不同个性的相异说话风格(例如,冗长的说话风格、简洁的说话风格等)。例如,可以使用第一参数集合来生成提供以呈现给用户的给定的修改的助理输出,该第一参数集合在由自动化助理使用的第一词汇和/或用于提供修改的助理输出以向用户进行可听呈现的第一韵律属性集合方面反映自动化助理的第一个性。替选地,可以使用第二参数集合来生成提供以呈现给用户的修改的助理输出,该第二参数集合在由自动化助理使用的第二词汇和/或用于提供修改的助理输出以向用户进行可听呈现的第二韵律属性集合方面反映自动化助理的第二个性。
因此,自动化助理可以基于在渲染用于向用户可听呈现的修改的助理输出时由自动化助理所使用的词汇和所使用的韵律属性两者来动态地调整在提供用于向用户呈现的修改的助理输出时所使用的个性。值得注意的是,自动化助理可以基于对话会话的上下文——包括从用户接收到的先前口述话语和由自动化助理提供的先前助理输出和/或本文描述的任何其他上下文信号——来动态地调整在提供修改的助理输出时使用的这些个性。结果,由自动化助理提供的修改的助理输出可以更好地与客户端设备的用户产生共鸣。此外,应当注意,可以随着给定对话会话的上下文的更新而动态地调整在给定对话会话中使用的个性。
在一些实施方式中,自动化助理可以根据一个或多个排名准则对包括在助理输出集合中的助理输出(即,不是使用一个或多个LLM输出生成的)和修改的助理输出(即,使用一个或多个LLM输出生成的)进行排名。因此,在选择要提供以呈现给用户的给定助理输出时,自动化助理可以从助理输出集合和修改的助理输出集合两者当中进行选择。一个或多个排名准则可以包括例如:一个或多个预测度量(例如,在生成ASR输出流时生成的ASR度量、在生成NLU输出流时生成的NLU度、在生成助理输出集合时生成的履行度量)——其指示包括在助理输出集合和修改的助理输出集合中的每个助理输出被预测来对口述话语中包括的助理查询的响应性如何;NLU输出流中包括的一个或多个意图;和/或其他排名准则。例如,如果客户端设备的用户的意图指示用户想要事实答案(例如,基于提供包括“why isthe sky blue?(为什么天是蓝色的?)”的助理查询的口述话语),则自动化助理可以促进包括在一个或多个助理输出的集合中的一个或多个助理输出,因为用户可能想要对助理查询的直接回答。然而,如果客户端设备的用户的意图指示用户提供了更多开放式输入(例如,基于提供包括“what time is it?(现在是什么时间?)”的助理查询的口述话语),则自动化助理可以促进包括在修改的助理输出集合中的一个或多个助理输出,因为用户可能更喜欢更多谈话方面。
在一些实施方式中,并且在生成修改的助理输出集合之前,自动化助理可以确定甚至是否生成修改的助理输出集合。在那些实施方式的一些版本中,自动化助理可以基于用户在提供如由NLU数据流所指示的口述话语时的一个或多个预测意图来确定甚至是否生成修改的助理输出集合。例如,在自动化助理确定口述话语请求自动化助理执行搜索(例如,助理查询“Why is the sky blue?”)的实施方式中,自动化助理可以确定不生成修改的助理输出集合,因为用户正在寻求事实回答。在那些实施方式的附加或替选版本中,自动化助理可以基于与修改一个或多个助理输出相关联的一个或多个计算成本来确定甚至是否生成修改的助理输出集合。与修改一个或多个助理输出相关联的一个或多个计算成本可以包括例如以下中的一个或多个:与修改一个或多个助理输出相关联的电池消耗、处理器消耗或者与修改一个或多个助理输出相关联的等待时间。例如,如果客户端设备处于低功率模式,则自动化助理可以确定不生成修改的助理输出集合以减少客户端设备的电池消耗。
通过使用本文描述的技术,可以实现一个或多个技术优点。作为一个非限制性示例,本文描述的技术使得自动化助理能够在对话会话期间与用户进行自然谈话。例如,自动化助理可以使用一个或多个本质上更具谈话性的LLM输出来生成修改的助理输出。因此,自动化助理可以主动提供用户未直接请求的与对话会话相关联的上下文信息(例如,通过生成如本文所述的附加助理查询并通过提供基于附加助理查询确定的附加助理输出),从而使得修改的助理输出与用户产生共鸣。此外,可以根据在整个对话会话中在上下文上调整的词汇并且根据用于可听地渲染修改的助理输出的韵律属性来生成具有各种个性的修改的助理输出,从而使得修改的助理输出更进一步与用户产生共鸣。这带来了节省客户端设备处的计算资源的各种技术优势,并且可以使得对话会话以更快且更有效率的方式结束和/或减少对话会话的数量。例如,可以减少在客户端设备处接收到的用户输入的数量,因为可以减少用户必须请求与对话会话上下文相关的信息的发生的数量,因为其可以由自动化助理主动提供以呈现给用户。此外,例如,在以离线方式生成一个或多个LLM输出并随后以在线方式使用其的实施方式中,可以在运行时减少等待时间。
如本文所使用的,“对话会话”可以包括用户和自动化助理(以及在一些情况下,其他人类参与者)之间的逻辑上独立(logically-self-contained)的交换。自动化助理可以基于各种信号来区分与用户的多个对话会话,该各种信号诸如是会话之间的时间流逝、会话之间用户上下文(例如,位置、预定会面之前/期间/之后等)的变化、除了用户和自动化助理之间的对话之外在用户和客户端设备之间的一个或多个干预交互的检测(例如,用户切换应用一段时间,用户离开然后返回到独立式(standalone)的话音激活产品)、会话之间客户端设备的锁定/休眠、用于与自动化助理对接的客户端设备的改变等等。值得注意的是,在给定的对话会话期间,用户可以使用各种输入模态与自动化助理交互,包括但不限于口述输入、键入输入和/或触摸输入。
提供以上描述作为仅本文公开的一些实施方式的概述。本文更详细地描述了那些实施方式以及其他实施方式。
应当理解,本文公开的技术可以在客户端设备上本地实现、由经由一个或多个网络连接到客户端设备的服务器远程实现、和/或两者。
附图说明
图1描绘了示例环境的框图,该示例环境示范了本公开的各个方面,并且可以在其中实现本文所公开的实施方式。
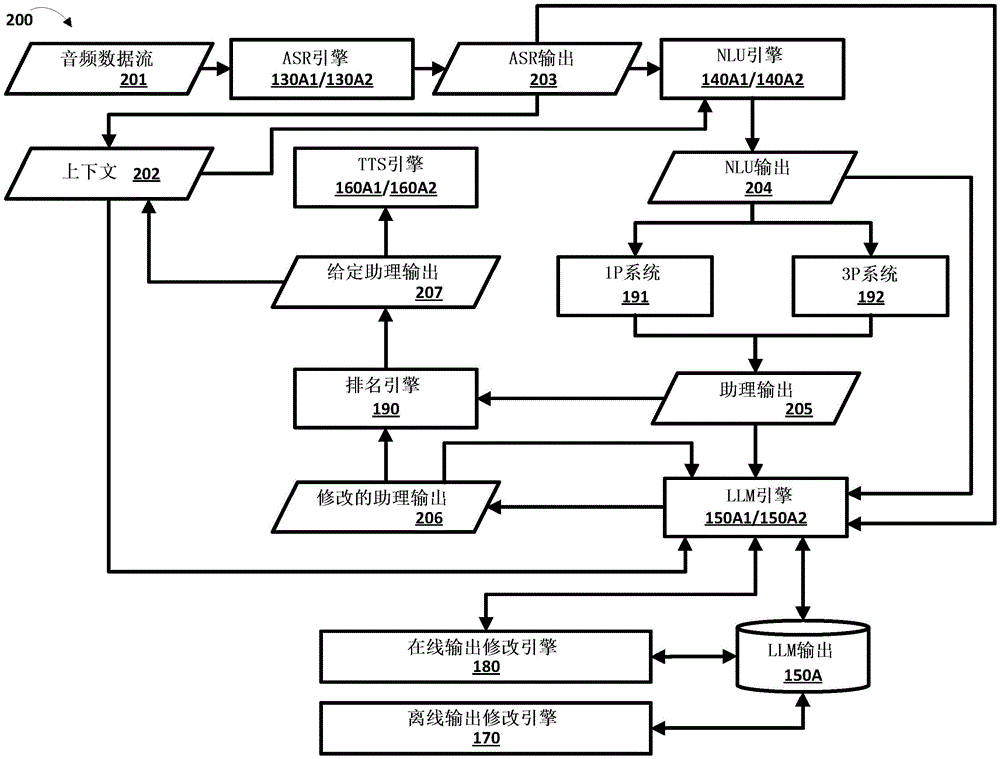
图2描绘了根据各种实施方式的利用大型语言模型来生成助理输出的示例处理流程。
图3描绘了示出根据各种实施方式的利用大语言模型以离线方式生成助理输出以便以在线方式后续使用的示例方法的流程图。
图4描绘了示出根据各种实施方式的利用大型语言模型基于生成助理查询来生成助理输出的示例方法的流程图。
图5描绘了图示根据各种实施方式的、利用大语言模型来基于生成助理个性回复来生成助理输出的示例方法的流程图。
图6描绘了根据各种实施方式的用户和自动化助理之间的对话会话的非限制性示例,其中,自动化助理利用大语言模型生成助理输出。
图7描绘了根据各种实施方式的计算设备的示例架构。
具体实施方式
现在转向图1,描绘了示例环境100的框图,该示例环境100演示了本公开的各个方面,并且可以在其中实现本文所公开的实施方式。示例环境100包括客户端设备110和自然谈话系统120。在一些实施方式中,自然谈话系统120可以在客户端设备110处本地实现。在附加或替选实施方式中,自然谈话系统120可以在如图1中描绘的客户端设备110远程实现(例如,在远程服务器处)。在这些实施方式中,客户端设备110和自然谈话系统120可以经由一个或多个网络199彼此通信地耦合,一个或多个网络199诸如是一个或多个有线或无线局域网(“LAN”,包括Wi-Fi LAN、网状网络、蓝牙、近场通信等)或广域网(“WAN”,包括互联网)。
客户端设备110可以是例如以下中的一个或多个:台式计算机、膝上型计算机、平板计算机、移动电话、车辆的计算设备(例如,车载通信系统、车载娱乐系统、车载导航系统)、独立式的交互式扬声器(可选地具有显示器)、诸如智能电视的智能电器、和/或包括计算设备的用户的可穿戴装置(例如,具有计算设备的用户的手表、具有计算设备的用户的眼镜、虚拟或增强现实计算设备)。可以提供附加的和/或替选的客户端设备。
客户端设备110可以执行自动化助理客户端114。自动化助理客户端114的实例可以是与客户端设备110的操作系统分离的应用(例如,安装在操作系统的“顶部”)——或者可以替代地由客户端设备110的操作系统直接实现。自动化助理客户端114可以与在客户端设备110处本地实现或远程地实现并经由一个或多个网络199调用的自然谈话系统120交互,如图1中所描绘的。自动化助理客户端114(并且可选地通过其与其他远程系统(例如,服务器)的交互)可以形成从用户的角度来看似乎是自动化助理115的逻辑实例,通过该逻辑实例,用户可以进行人机对话。自动化助理115的实例在图1中描绘,并且由包括客户端设备110的自动化助理客户端114和自然谈话系统120的虚线包围。因此应当理解,与在客户端设备110上执行的自动化助理客户端114接洽的用户实际上可以与他或她自己的自动化助理115的逻辑实例(或者在家庭或其他用户组之间共享的自动化助理115的逻辑实例)接洽。为了简洁和简单起见,如本文所使用的自动化助理115将是指在客户端设备110上本地执行和/或在可以实现自然谈话系统120的一个或多个远程服务器处远程执行的自动化助理客户端114。
在各种实施方式中,客户端设备110可以包括用户输入引擎111,其被配置为检测由客户端设备110的用户使用一个或多个用户接口输入设备提供的用户输入。例如,客户端设备110可以配备有一个或多个麦克风,其捕获音频数据,诸如与用户的口述话语或客户端设备110的环境中的其他声音相对应的音频数据。附加地或替选地,客户端设备110可以配备有一个或多个视觉组件,其被配置为捕获与在一个或多个视觉组件的视场中检测到的图像和/或移动(例如,手势)相对应的视觉数据。附加地或替选地,客户端设备110可以配备有一个或多个触摸敏感组件(例如,键盘和鼠标、触笔、触摸屏、触摸面板、一个或多个硬件按钮等),其被配置为捕获与指向客户端设备110的触摸输入相对应的信号。
在各种实施方式中,客户端设备110可以包括渲染引擎112,其被配置为使用一个或多个用户接口输出设备向客户端设备110的用户提供用于可听和/或视觉呈现的内容。例如,客户端设备110可以配备有一个或多个扬声器,其使得内容能够经由客户端设备110被提供以向用户进行可听呈现。附加地或替选地,客户端设备110可以配备有显示器或投影仪,其使得内容能够经由客户端设备110被提供以向用户进行视觉呈现。
在各种实施方式中,客户端设备110可以包括一个或多个存在传感器113,其被配置为在来自对应用户的批准下提供指示检测到的存在、特别是人类存在的信号。在那些实施方式中的一些中,自动化助理115可以至少部分地基于用户在客户端设备110处(或在与客户端设备110的用户相关联的另一计算设备处)的存在来识别客户端设备110(或与客户端设备110的用户相关联的另一计算设备),以满足口述话语。可以通过在客户端设备110和/或与客户端设备110的用户相关联的其他计算设备处渲染响应内容(例如,经由渲染引擎112)、通过使得客户端设备110和/或与客户端设备110的用户相关联的其他计算设备被控制和/或通过使得客户端设备110和/或与客户端设备110的用户相关联的其他计算设备执行任何其他满足口述话语的动作,可以满足口述话语。如本文所描述的,自动化助理115可以利用基于存在传感器113确定的数据以基于用户在附近哪里或最近在附近哪里来确定客户端设备110(或其他计算设备),并且仅向客户端设备110(或那些其他计算设备)提供对应的命令。在一些附加或替选实施方式中,自动化助理115可以利用基于存在传感器113确定的数据来确定任何用户(任何用户或特定用户)当前是否接近客户端设备110(或其他计算设备),并且可以可选地基于接近客户端设备110(或其他计算设备)的用户来抑制向客户端设备110(或其他计算设备)提供数据和/或从客户端设备110(或其他计算设备)提供数据。
存在传感器113可以采用各种形式。例如,客户端设备110可以利用上面关于用户输入引擎111描述的一个或多个用户接口输入组件来检测用户的存在。附加地或替选地,客户端设备110可以配备有其他类型的基于光的存在传感器113,诸如测量从其视野内的对象辐射的红外(“IR”)光的被动红外(“PIR”)传感器。
附加地或替选地,在一些实施方式中,存在传感器113可以被配置为检测与人类存在或设备存在相关联的其他现象。例如,在一些实施例中,客户端设备110可以配备有存在传感器113,其检测由例如由用户携带/操作的其他计算设备(例如,移动设备、可穿戴计算设备等)和/或其他计算设备发射的各种类型的无线信号(例如,诸如无线电、超声、电磁等的波)。例如,客户端设备110可以被配置为发射人类无法察觉的波,诸如超声波或红外波,其可以由其他计算设备检测到(例如,经由诸如有超声能力的麦克风的超声/红外接收器)。
附加地或替选地,客户端设备110可以发射其他类型的人类不可察觉的波,诸如可以由由用户携带/操作的其他计算设备(例如,移动设备、可穿戴计算设备等)检测到并用于确定用户的特定位置的无线电波(例如,Wi-Fi、蓝牙、蜂窝等)。在一些实施方式中,GPS和/或Wi-Fi三角测量可以用于例如基于去往/来自客户端设备110的GPS和/或Wi-Fi信号来检测人的位置。在其他实施方式中,诸如飞行时间、信号强度等的其他无线信号特性可以由客户端设备110单独或共同使用,以基于通过由用户携带/操作的其他计算设备发射的信号来确定特定人的位置。附加地或替选地,在一些实施方式中,客户端设备110可以执行说话者识别(SID)以根据用户的话音辨识用户和/或执行面部识别(FID)以根据捕获用户面部的视觉数据辨识用户。
在一些实施方式中,然后可以例如通过客户端设备110的存在传感器113(以及可选的客户端设备110的GPS传感器、Soli芯片和/或加速度计)来确定扬声器的移动。在一些实施方式中,基于这种检测到的移动,可以预测用户的位置,并且当使得任何内容至少部分地基于客户端设备110和/或其他计算设备与用户位置的接近度在客户端设备110和/或其他计算设备处渲染时,可以假设该位置是用户的位置。在一些实施方式中,可以简单地假设用户处于他或她与自动化助理115接洽的最后位置中,尤其是如果自上次接洽以来没有过去太多时间的话。
此外,客户端设备110和/或自然谈话系统120可以包括用于存储数据和/或软件应用的一个或多个存储器、用于访问数据和执行软件应用的一个或多个处理器、和/或促进通过网络199中的一个或多个进行通信的其他组件。在一些实施方式中,软件应用中的一个或多个可以本地安装在客户端设备110处,而在其他实施方式中,软件应用中的一个或多个可以被远程托管(例如,通过一台或多台服务器)并且可由客户端设备110通过网络199中的一个或多个来访问。
在一些实施方式中,由自动化助理115执行的操作可以经由自动化助理客户端114在客户端设备110处本地实现。如图1中所示,自动化助理客户端114可以包括自动语音辨识(ASR)引擎130A1、自然语言理解(NLU)引擎140A1、大型语言模型(LLM)引擎150A1和文本转语音(TTS)引擎160A1。在一些实施方式中,诸如当如图1中所描绘的在客户端设备110远程实现自然谈话系统120时,由自动化助理115执行的操作可以跨多个计算机系统分布。在这些实施方式中,自动化助理115可以附加地或替选地利用自然谈话系统120的ASR引擎130A2、NLU引擎140A2、LLM引擎150A2和TTS引擎160A2。
这些引擎中的每个都可以被配置为执行一个或多个功能。例如,ASR引擎130A1和/或130A2可以使用存储在机器学习(ML)模型数据库115A中的流式ASR模型(例如,循环神经网络(RNN)模型、变换器(transformer)模型、和/或能够执行ASR的任何其他类型的ML模型)处理捕获口述话语并且由客户端设备110的麦克风生成的音频数据流以生成ASR输出流。值得注意的是,流式ASR模型可以用于在生成音频数据流时生成ASR输出流。此外,NLU引擎140A1和/或140A2可以使用存储在ML模型数据库115A中的NLU模型(例如,长短期存储器(LSTM)、门控循环单元(GRU)和/或能够执行NLU的任何其他类型的RNN或其他ML模型)和/或基于语法的规则来处理ASR输出流以生成NLU输出流。此外,自动化助理115可以使得NLU输出被处理以生成履行数据流。例如,自动化助理115可以通过一个或多个网络199(或一个或多个应用编程接口(API))向一个或多个第一方(1P)系统191和/或通过一个或多个网络向一个或多个第三方(3P)系统192发送一个或多个结构化请求,并从一个或多个1P系统191和/或3P系统192接收履行数据以生成履行数据流。一个或多个结构化请求可以包括例如包括在履行数据流中的NLU数据。履行数据流可以对应于例如被预测为响应于由ASR引擎130A1和/或130A2处理的音频数据流中捕获的口述话语中包括的助理查询的助理输出集合。
此外,LLM引擎150A1和/或150A2可以处理被预测为响应于包括在由ASR引擎130A1和/或130A2处理的音频数据流中捕获的口述话语中的助理查询的助理输出集合。如本文所述(例如,参考图2至图6),在一些实施方式中,LLM引擎150A1和/或150A2可以使用一个或多个LLM输出来使得助理输出集合被修改,以生成修改的助理输出集合。在那些实施方式的一些版本中(例如,并且如关于图3所描述的),自动化助理115可以使得一个或多个LLM输出以离线方式生成(例如,不响应于在对话会话期间接收到的口述话语),并随后以在线方式使用(例如,当在对话会话期间接收到口述话语时)以生成修改的助理输出集合。在那些实施方式的附加或替选版本中(例如,并且如关于图4和图5所描述的),自动化助理115可以使得以在线方式生成一个或多个LLM输出(例如,当在对话会话期间接收到口述话语时)。在这些实施方式中,可以基于使用存储在模型数据库115A中的一个或多个LLM(例如,一个或多个变换器模型,诸如Meena、RNN和/或任何其他LLM)处理助理输出集合(例如,履行数据流)、其中接收到口述话语的对话会话的上下文(例如,基于存储在上下文数据库110A中的一个或多个上下文信号)、对应于包括在口述话语中的助理查询的辨识文本和/或自动化助理115可以在生成一个或多个LLM输出时利用的其他信息而生成一个或多个LLM输出。一个或多个LLM输出中的每个可以包括例如跨一个或多个词汇的一个或多个词和/或短语的序列上的概率分布,并且该序列中的一个或多个词和/或短语可以基于概率分布被选择为一个或多个LLM输出。在各种实施方式中,LLM输出中的一个或多个可以被存储在LLM输出数据库150A中,以供随后用于修改包括在助理输出集合中的一个或多个助理输出。
此外,在一些实施方式中,TTS引擎160A1和/或160A2可以使用存储在ML模型数据库115A中的TTS模型来处理文本数据(例如,由自动化助理115制定的文本)以生成包括计算机生成的合成语音的合成语音音频数据。文本数据可以对应于例如来自履行数据流中所包括的助理输出集合中的一个或多个助理输出、来自修改的助理输出集合中的一个或多个修改的助理输出、和/或本文描述的任何其他文本数据。值得注意的是,存储在ML模型数据库115A中的ML模型可以是本地存储在客户端设备110处的设备上ML模型,或者是当自然谈话系统120不在客户端设备110处本地实现时客户端设备110和/或远程系统两者都可访问的共享ML模型。在附加或替选实施方式中,与来自包括在履行数据流中的助理输出集合中的一个或多个助理输出相对应的音频数据、来自修改的助理输出集合中的一个或多个修改的助理输出和/或本文描述的任何其他文本数据可以被存储在存储器或由客户端设备110可访问的一个或多个数据库中,使得自动化助理不需要在使得音频数据被提供以向用户可听呈现时使用TTS引擎160A1和/或160A2生成任何合成语音音频数据。
在各种实施方式中,ASR输出流可以包括例如:ASR假设流(例如,词项假设和/或转录假设),其被预测为对应于在音频数据流中捕获的用户的口述话语;针对每个ASR假设的一个或多个对应的预测值(例如,概率、对数似然和/或其他值);被预测为对应于在音频数据流中捕获的用户的口述话语的多个音素;和/或其他ASR输出。在那些实施方式的一些版本中,ASR引擎130A1和/或130A2可以选择一个或多个ASR假设作为对应于口述话语的辨识文本(例如,基于对应的预测值)。
在各种实施方式中,NLU输出流可以包括例如带注释的辨识文本流,其包括针对辨识文本的一个或多个(例如,所有)词项的辨识文本的一个或多个注释。例如,NLU引擎140A1和/或140A2可以包括被配置成用词项的语法角色来注释词项的词性标注器(未描绘)的一部分。附加地或替选地,NLU引擎140A1和/或140A2可以包括实体标记器(未描绘),其被配置为注释在辨识文本的一个或多个片段中的实体引用,诸如对人(包括例如文学人物、名人、公众人物等)、组织、地点(真实的和虚构的)等等的引用。在一些实施方式中,关于实体的数据可以被存储在一个或多个数据库中,诸如存储在知识图(未描绘)中。在一些实施方式中,知识图可以包括表示已知实体(以及在一些情况下,实体属性)的节点,以及连接节点并表示实体之间的关系的边。实体标记器可以以高粒度级别(例如,以使得能够识别对诸如人的实体类的所有引用)和/或较低粒度级别(例如,以使得能够识别对诸如特定人的特定实体的所有引用)来注释对实体的引用。实体标记器可以依赖于自然语言输入的内容来消解特定实体和/或可以可选地与知识图或其他实体数据库通信来消解特定实体。
附加地或替选地,NLU引擎140A1和/或140A2可以包括共指消解器(未描绘),其被配置为基于一个或多个上下文线索将对同一实体的引用进行分组或“聚类”。例如,基于紧接在接收输入“buy them(购买它们)”之前渲染的客户端设备通知中提及的“theatretickets(剧院门票)”,共指消解器可以用于将词项“them”消解为自然语言输入“buy them”中的“buy theatre tickets(购买剧院门票)”。在一些实施方式中,NLU引擎140A1和/或140A2的一个或多个组件可以依赖于来自NLU引擎140A1和/或140A2的一个或多个其他组件的注释。例如,在一些实施方式中,实体标注器可以依赖于来自共指消解器的注释来注释对特定实体的所有提及。另外,例如,在一些实施方式中,共指消解器可以依赖于来自实体标记器的注释来将对同一实体的引用进行聚类。
虽然图1是关于具有单个用户的单个客户端设备进行描述的,但是应当理解,这是为了示例的目的并且并不意味着限制。例如,用户的一个或多个附加客户端设备也可以实现本文描述的技术。例如,客户端设备110、一个或多个附加客户端设备和/或用户的任何其他计算设备可以形成可以采用本文描述的技术的设备的生态系统。这些附加客户端设备和/或计算设备可以(例如,通过网络199)与客户端设备110通信。作为另一个示例,给定的客户端设备可以由共享设置(例如,一组用户、家庭)中的多个用户使用。
如本文所述,自动化助理115可以确定是否使用一个或多个LLM输出来修改助理响应集合和/或基于一个或多个LLM输出来确定一个或多个修改的助理输出集合。自动化助理115可以利用自然谈话系统120来做出这些确定。在各种实施方式中并且如图1中所描绘的,自然谈话系统120可以附加地或替选地包括离线输出修改引擎170、在线输出修改引擎180和/或排名引擎190。离线输出修改引擎170可以包括例如助理活动引擎171和索引引擎172。此外,在线输出修改引擎180可以包括例如助理查询引擎181和助理个性引擎182。将参考图2至图5更详细地描述自然谈话系统120的这些各种引擎。
现在转向图2,描绘了利用LLM生成助理输出的示例处理流程200。由图1的客户端设备110的一个或多个麦克风生成的音频数据流201可以由ASR引擎130A1和/或130A2处理以生成ASR输出203的流。此外,ASR输出203可以由NLU引擎140A1和/或140A2处理以生成NLU输出204的流。在一些实施方式中,NLU引擎140A1和/或140A2可以处理客户端设备110的用户与至少部分地在用户的客户端设备110处执行的自动化助理115之间的对话会话的上下文202。在那些实施方式的一些版本中,可以基于由客户端设备110生成的一个或多个上下文信号(例如,一天中的时间、一周中的一天、客户端设备110的位置、在客户端设备110的环境中检测到的环境噪声和/或由客户端设备110生成的其他上下文信号)来确定对话会话的上下文202。在那些实施方式的附加或替选版本中,可以基于存储在客户端设备110处可访问的上下文数据库110A中的一个或多个上下文信号(例如,用户简档数据、软件应用数据、关于客户端设备110的用户的已知环境的环境数据、用户和自动化助理115之间正在进行的对话会话的对话历史和/或用户和自动化助理115之间的一个或多个先前对话会话的历史对话历史、和/或存储在上下文数据库110A中的其他上下文数据)来确定对话会话的上下文202。此外,NLU输出204的流可以由一个或多个1P系统191和/或3P系统处理以生成包括一个或多个助理输出205集合的履行数据流,其中,包括在一个或多个助理输出205集合中的一个或多个助理输出中的每个助理输出被预测为响应于在音频数据流201中捕获的口述话语。
通常,在不利用LLM的基于轮次的对话会话中,排名引擎190可以处理一个或多个助理输出205集合以根据一个或多个排名准则对包括在一个或多个助理输出205集合中的一个或多个助理输出中的每个进行排名,并且自动化助理115可以响应于接收到口述话语而从一个或多个助理输出205集合中选择一个或多个给定助理输出207来提供以呈现给客户端设备110的用户。在一些实施方式中,所选择的一个或多个给定助理输出207可以由TTS引擎160A1和/或160A2处理以生成合成语音音频数据,该合成语音音频数据包括与所选择的一个或多个给定助理输出207相对应的合成语音,并且渲染引擎112可以使得合成语音音频数据由客户端设备110的扬声器可听地渲染,以可听地呈现给客户端设备110的用户。在附加或替选实施方式中,渲染引擎112可以使得对应于所选择的一个或多个给定助理输出207的文本数据由客户端设备110的显示器视觉地渲染,以视觉呈现给客户端设备110的用户。
然而,在使用要求保护的技术时,自动化助理115还可以使得一个或多个助理输出205集合由LLM引擎150A1和/或150A2处理以生成一个或多个修改的助理输出206集合。在一些实施方式中,可以使用离线输出修改引擎170(例如,在接收由客户端设备110的一个或多个麦克风生成的音频数据流201之前)以离线方式在先生成一个或多个LLM输出,并且一个或多个LLM输出可以被存储在LLM输出数据库150A中。如关于图3所描述的,可以基于对应助理查询和/或其中接收到对应助理查询的对应对话会话的对应上下文,在LLM输出数据库150A中对一个或多个LLM输出在先进行索引。此外,LLM引擎150A1和/或150A2可以确定在音频数据流201中捕获的口述话语中包括的助理查询与对应助理查询相匹配,和/或其中接收到助理查询的对话会话的上下文202与其中接收到对应助理查询的对应对话会话的对应上下文相匹配。LLM引擎150A1和/或150A2可以获得由对应助理查询和/或与助理查询匹配的对应上下文索引的一个或多个LLM输出,以修改一个或多个助理输出205集合。此外,可以基于一个或多个LLM输出来修改一个或多个助理输出205集合,从而产生一个或多个修改的助理输出206集合。
在附加或替选实施方式中,可以使用在线输出修改引擎180以在线方式生成一个或多个LLM输出(例如,响应于接收由客户端设备110的一个或多个麦克风生成的音频数据流201)。如参考图4和图5所述,可以基于使用存储在ML模型数据库115A中的一个或多个LLM处理一个或多个助理输出205集合、对应于包括在音频数据流201中捕获的口述话语中的助理查询的辨识文本(例如,包括在ASR输出203的流中)和/或客户端设备110的用户与自动化助理115之间的对话会话的上下文202而生成一个或多个LLM输出,以生成一个或多个LLM输出。此外,可以基于一个或多个LLM输出来修改一个或多个助理输出205集合,从而产生一个或多个修改的助理输出206集合。换言之,在这些实施方式中,LLM引擎150A1和/或150A2可以使用存储在ML模型数据库115A中的一个或多个LLM直接生成一个或多个修改的助理输出206集合。
在这些实施方式中,并且与上述不利用LLM的典型的基于轮次的对话会话相比,排名引擎190可以处理一个或多个助理输出205集合以及一个或多个修改的助理输出206集合以根据一个或多个排名准则对包括在一个或多个助理输出205集合和一个或多个修改的助理输出206集合两者中的一个或多个助理输出中的每个进行排名。因此,在选择一个或多个给定助理输出207时,自动化助理207可以从一个或多个助理输出205集合和一个或多个修改的助理输出206集合当中进行选择。值得注意的是,一个或多个修改的助理输出206集合中包括的助理输出可以基于一个或多个助理输出205集合来生成,并且传达相同或相似的信息,而且还连同与对话的上下文202(例如,如关于图4所描述的)相关和/或更自然、流畅和/或更符合自动化助理的特征的附加信息一起传达相同或相似的信息,使得一个或多个给定助理输出207更好地与客户端设备110的用户产生共鸣。
一个或多个排名准则可以包括例如:一个或多个预测度量(例如,由ASR引擎130A1和/或130A2在生成ASR输出203的流时生成的ASR度量、由NLU引擎140A1和/或140A2在生成NLU输出204的流时生成的NLU度量、由1P系统191和/或3P系统192中的一个或多个生成的履行度量)——其指示预测包括在一个或多个助理输出205集合和一个或多个修改的助理输出206集合中的每个助理输出对在音频数据流201中捕获的口述话语中包括的助理查询的响应性如何;NLU输出204的流中包括的一个或多个意图;从分类器导出的度量,该分类器处理包括在一个或多个助理输出205集合和一个或多个修改的助理输出206集合中的每个助理输出以确定每个助理输出在被提供以呈现给用户时的自然性、流畅性和/或与自动化助理的特性符合程度如何;和/或其他排名准则。例如,如果客户端设备110的用户的意图指示用户想要事实回答(例如,基于提供包括“Why is the sky blue?”的助理查询的口述话语),则排名引擎190可以促进包括在一个或多个助理输出205集合中的一个或多个助理输出,因为用户可能想要对助理查询的简单回答。然而,如果客户端设备110的用户的意图指示用户提供了更多开放式输入(例如,基于提供包括“what time is it?”的助理查询的口述话语),则排名引擎190可以促进包括在一个或多个修改的助理输出206集合中的一个或多个助理输出,因为用户可能更喜欢更多谈话方面。
虽然在本文中关于基于话音的对话会话描述了图1和图2,但是应当理解,这是为了示例的目的并且并不意味着限制。相反,应当理解,无论用户的输入模态如何,都可以利用本文描述的技术。例如,在用户提供键入输入和/或触摸输入作为助理查询的一些实施方式中,自动化助理115可以使用NLU引擎140A1和/或140A2处理键入输入以生成NLU输出204的流(例如,跳过音频数据流201的处理),并且LLM引擎150A1和/或150A2可以利用与助理查询相对应的文本输入(例如,从键入输入和/或触摸输入导出)来以与上述相同或类似的方式生成一个或多个修改的助理输出206集合。
现在转向图3,描绘了图示利用大型语言模型以离线方式生成助理输出以便以在线方式后续使用的示例方法300的流程图。为了方便起见,参考执行来自图2的处理流程200的操作的系统来描述方法300的操作。方法300的该系统包括计算设备(例如,图1的客户端设备110、图6的客户端设备610和/或图7的计算设备710、一个或多个服务器和/或其他计算设备)的一个或多个处理器、存储器和/或其他组件。此外,虽然以特定顺序示出了方法300的操作,但这并不意味着限制。一个或多个操作可以被重新排序、省略和/或添加。
在框352处,系统获得指向自动化助理的多个助理查询以及针对多个助理查询中的每个助理查询的对应先前对话会话的对应上下文。例如,系统可以使得图1和图2的离线输出修改引擎的助理活动引擎171获得多个助理查询和先前对话会话的对应上下文,其中从例如图1中描绘的助理活动数据库170A接收多个助理查询。在一些实施方式中,多个助理查询和其中接收到多个助理查询的先前对话会话的对应上下文可以限于与客户端设备的用户(例如,图1的客户端设备110的用户)相关联的那些。在其他实施方式中,多个助理查询和其中接收到多个助理查询的先前对话会话的对应上下文可以限于与相应客户端设备的多个用户相关联的那些(例如,其可以包括或可以不包括图1的客户端设备110的用户)。
在框354处,系统使用一个或多个LLM处理多个助理查询中的给定助理查询来生成一个或多个对应LLM输出,其中,一个或多个对应LLM输出中的每个被预测为响应于给定助理查询。一个或多个对应LLM输出中的每个可以包括例如跨一个或多个词汇的一个或多个词和/或短语的序列上的概率分布,并且,该序列中的一个或多个词和/或短语可以基于概率分布被选择为一个或多个对应LLM输出。在各种实施方式中,在生成给定助理查询的一个或多个对应LLM输出时,系统可以使用一个或多个LLM连同助理查询一起处理其中接收到给定助理查询的对应先前对话会话的对应上下文,和/或被预测为响应于给定助理查询的助理输出集合(例如,基于使用如参考图2所描述的ASR引擎130A1和/或130A2、NLU引擎140A1和/或140A2以及1P系统191和/或3P系统192中的一个或多个处理对应于给定助理查询的音频数据而生成的助理输出集合)。在一些实施方式中,系统可以处理对应于给定助理查询的辨识文本,而在附加或替选实施方式中,系统可以处理捕获包括给定助理查询的口述话语的音频数据。在一些实施方式中,系统可以使得LLM引擎150A1使用在用户(例如,图1的客户端设备110的用户)的客户端设备处本地的一个或多个LLM来处理给定助理查询,而在其他实施方式中,系统可以使得LLM引擎150A2使用在用户的客户端设备远程(例如,在远程服务器处)的一个或多个LLM来处理给定助理查询。如本文所述,一个或多个对应LLM输出可以反映比自动化助理可以提供的典型助理输出更自然的谈话输出,这使得自动化助理能够以更流畅的方式驱动对话会话,使得基于一个或多个对应LLM输出修改的助理输出更有可能与感知修改的助理输出的用户产生共鸣。
在一些实施方式中,除了一个或多个对应LLM输出之外,可以基于处理给定助理查询和/或其中接收到给定助理查询的对应先前对话会话的对应上下文,使用一个或多个LLM模型来生成附加助理查询。例如,在处理给定助理查询和/或其中接收到给定助理查询的对应先前对话会话的对应上下文时,一个或多个LLM可以确定与给定助理查询相关联的意图(例如,基于在使用图2中的NLU引擎140A1和/或140A2生成的NLU输出204的流)。此外,一个或多个LLM可以基于与给定助理查询相关联的意图来识别与与给定助理查询相关联的意图相关的至少一个相关意图(例如,基于意图到客户端设备110可访问的数据库或存储器中的至少一个相关意图的映射和/或基于使用一个或多个机器学习(ML)模型或启发式定义的规则来处理与给定助理查询相关联的意图)。此外,一个或多个LLM可以基于至少一个相关意图来生成附加助理查询。例如,假设助理查询指示用户还没有吃晚饭(例如,晚上在用户的实际住所接收到的给定助理查询“I’m feeling pretty hungry(我感觉很饿)”,如由与指示他/她想要吃饭的用户意图相关联的对应先前对话会话的对应上下文所指示的)。在该示例中,附加助理查询可以对应于例如“what types of cuisine has the user indicatedhe/she prefers?(用户已经指示了他/她喜欢什么类型的美食?)”(例如,反映与用户指示他/她想吃饭的意图相关联的相关美食类型意图)、“what restaurants nearby are open?(附近有哪些餐馆营业?)”(例如,反映与指示他/她想要吃饭的用户意图相关联的相关餐馆查找意图)和/或其他附加助理查询。
在这些实施方式中,可以基于处理附加助理查询来确定附加助理输出。在附加助理查询是“what types of cuisine has the user indicated he/she prefers?”的上述示例中,可以利用来自本地存储在客户端设备110处的一个或多个1P系统191的用户简档数据来确定用户指示他/她更喜欢地中海美食和印度美食。基于指示用户更喜欢地中海美食和印度美食的用户简档数据,可以修改一个或多个对应LLM输出以询问用户地中海美食和/或印度美食用户听起来是否有胃口(例如,“how does Mediterranean cuisine or Indiancuisine sound for dinner(晚餐吃地中海美食或印度美食听起来怎么样)”)。
在附加助理查询是“what restaurants nearby are open?”的上述示例中,来自1P系统191和/或3P系统192中的一个或多个的餐馆数据可以用来确定用户的主要住所附近有哪些餐馆营业(并且可选地基于用户简档数据仅限于提供地中海美食和印度美食的餐馆)。基于结果,可以修改一个或多个对应LLM输出,以向用户提供在用户的主要住所附近营业的一个或多个餐馆的列表(例如,“Example Mediterranean Restaurant is open until9:00PM and Example Indian Restaurant is open until 10:00PM(示例地中海餐馆营业至晚上9:00并且示例印度餐馆营业至晚上10:00)”)。值得注意的是,最初使用LLM生成的附加助理查询(例如,在上面的示例中“what types of cuisine has the user indicatedhe/she prefers?”和“what types of cuisine has the user indicated he/sheprefers?”)可能不会被包括在一个或多个对应LLM输出中,因此可能不会被提供以呈现给用户。相反,基于附加助理查询确定的附加助理输出(例如,“how does Mediterraneancuisine or Indian cuisine sound for dinner”和“Example MediterraneanRestaurant is open until 9:00PM and Example Indian Restaurant is open until10:00PM”)可以被包括在一个或多个对应LLM输出中,并且因此可以被提供以呈现给用户。
在附加或替选实施方式中,可以使用一个或多个LLM的多个相异参数集合中的对应参数集合来生成一个或多个对应LLM输出(以及可选的基于附加助理查询确定的附加助理输出)中的每个。多个相异参数集合中的每个参数可以与自动化助理的相异个性相关联。在那些实施方式的一些版本中,可以利用单个LLM以使用每个相异个性的对应参数集合来生成一个或多个对应LLM输出,而在那些实施方式的其他版本中,可以利用多个LLM以使用每个相异个性的对应参数集合来生成一个或多个对应LLM输出。例如,可以利用单个LLM以:使用反映第一个性(例如,在上面示例中的厨师个性,其中,给定助理查询对应于“I’mfeeling pretty hungry”)的第一参数集合来生成第一LLM输出;使用反映第二个性(例如,在上面示例中的管家个性,其中,给定助理查询对应于“I’m feeling pretty hungry”)的第二参数集合来生成第二LLM输出;对于多个其他的相异个性,依此类推。此外,例如,第一LLM可以用于使用反映第一个性(例如,在上面示例中的厨师个性,其中,给定助理查询对应于“I’m feeling pretty hungry”)的第一参数集合来生成第一LLM输出;第二LLM可以用于使用反映第二个性(例如,在上面示例中的管家个性,其中,给定助理查询对应于“I’mfeeling pretty hungry”)的第二参数集合来生成第二LLM输出;对于多个其他的相异个性,依此类推。因此,当提供对应LLM输出以呈现给用户时,其可以经由不同个性的韵律属性(例如,这些不同个性的语调、抑扬顿挫、音高、停顿、语速、重音、节律等)来反映各种动态上下文个性。附加地或替选地,用户可以以持续的方式(例如,始终使用管家个性)和/或以上下文方式(例如,在早上和晚上使用管家个性,但在下午使用不同的个性)定义要由自动化助理使用的一个或多个个性(例如,经由与本文描述的自动化助理相关联的自动化助理应用的设置)。
值得注意的是,本文描述的这些个性回复不仅反映了不同个性的韵律属性,而且还可以反映不同个性和/或不同个性的相异说话风格(例如,冗长的说话风格、简洁的说话风格、友好的个性、讽刺的个性等)的词汇。例如,上述厨师个性可以具有特定厨师词汇,使得使用针对厨师个性的参数集生成的一个或多个对应LLM输出的一个或多个词和/或短语序列上的概率分布可以促进由厨师使用的词和/或短语的序列超过其他个性(例如,科学家个性、图书管理员个性等)的其他词和/或短语序列。因此,当提供一个或多个对应LLM输出以呈现给用户时,其不仅可以在不同个性的韵律属性方面反映各种动态上下文个性,而且可以在不同个性的准确且现实的词汇方面反映各种动态上下文个性,使得一个或多个对应LLM输出在不同的上下文场景中更好地与用户产生共鸣。此外,应当理解,可以以不同程度的粒度来定义不同个性的词汇和/或说话风格。继续以上示例,上述厨师个性可以具有当基于与地中海美食相关联的附加助理查询询问地中海美食时的特定地中海厨师词汇、当基于附加助理查询与印度美食相关联询问印度美食时的特定印度厨师词汇等等。
在框356处,系统基于给定助理查询和/或针对给定助理查询的对应先前对话会话的对应上下文,在客户端设备处能够访问的存储器(例如,图1的LLM输出数据库150A)中对一个或多个对应LLM输出进行索引。例如,系统可以使得图1和图2的离线输出修改引擎的索引引擎172在LLM输出数据库150A中对一个或多个对应LLM输出进行索引。在一些实施方式中,索引引擎172可以基于给定助理查询中包括的一个或多个词项和/或其中接收到给定助理查询的对应先前对话会话的对应上下文中包括的一个或多个上下文信号来对一个或多个对应LLM输出进行索引。在附加或替选实施方式中,索引引擎172可以使得生成给定助理查询的嵌入(例如,word2vec嵌入或任何其他更低维表示)和/或包括在其中接收到给定助理查询的对应先前对话会话的对应上下文中的一个或多个上下文信号的嵌入,并且这些嵌入中的一个或多个可以被映射到嵌入空间(例如,更低维空间)。在这些实施方式中,在LLM输出数据库150A中索引的一个或多个对应LLM输出可以随后由在线输出修改引擎180用来修改助理输出集合(例如,如下文关于图3的方法300的框362、364和366所述)。在各种实施方式中,系统可以附加地或替选地生成一个或多个助理输出(例如,如关于图2所描述的一个或多个助理输出205),其被预测为响应于给定助理查询(但不是使用LLM引擎150A1和/或150A2生成的),并且一个或多个对应LLM输出可以附加地或替选地由一个或多个助理输出来索引。
在一些实施方式中,并且如在框358处所指示的,系统可以可选地接收用户输入以审阅和/或修改一个或多个对应LLM输出。例如,人类审阅者可以分析使用一个或多个LLM模型生成的一个或多个对应LLM输出,并通过改变一个或多个对应LLM输出中包括的一个或多个词项和/或短语来修改一个或多个对应LLM输出。另外,例如,人类审阅者可以重新索引、丢弃和/或以其他方式修改一个或多个对应LLM输出的索引。因此,在这些实施方式中,使用一个或多个LLM生成的一个或多个对应LLM输出可以由人类审阅者策划(curate)以确保一个或多个对应LLM输出的质量。此外,任何未丢弃的、重新索引的和/或策划的LLM输出都可以用于以离线方式修改或重新训练LLM。
在框360处,系统确定是否存在在框352处获得的多个助理查询中所包括的尚未使用一个或多个LLM处理的附加助理查询。如果在框360的迭代处,系统确定存在在框352处获得的多个助理查询中所包括的尚未使用一个或多个LLM处理的附加助理查询,则系统返回到框354并且执行框354和356的附加迭代,但是是关于附加助理而不是给定助理查询。可以针对在框352处获得的多个助理查询中包括的每个助理查询重复这些操作。换句话讲,系统可以在使得利用一个或多个对应LLM输出之前为每个助理查询和/或其中接收到多个助理查询中的对应一个的对应先前对话会话的对应上下文索引一个或多个对应LLM输出。
如果在框360的迭代处,系统确定不存在在框352处获得的多个助理查询中所包括的尚未使用一个或多个LLM处理的附加助理查询,则系统可以前进到框362。在框362处,系统可以监视由客户端设备的一个或多个麦克风生成的音频数据流,以确定音频数据流是否捕获客户端设备的用户的指向自动化助理的口述话语。例如,系统可以监视音频数据流中包括的一个或多个特定词或短语(例如,监视使用热词检测模型调用自动化助理的一个或多个特定词或短语)。此外,例如,可选地除了一个或多个其他信号(例如,由客户端设备的视觉传感器捕获的一个或多个手势、指向客户端设备的眼睛凝视等)之外,系统还可以监视指向客户端设备的语音。如果在框362的迭代处,系统确定音频数据流没有捕获客户端设备的用户的指向自动化助理的口述话语,则系统可以在框362处继续监视音频数据流。如果在框362的迭代处,系统确定音频数据流捕获客户端设备的用户的指向自动化助理的口述话语,则系统可以前进到框364。
在框364处,系统基于对音频数据流进行处理来确定口述话语包括与多个助理查询之一相对应的当前助理查询和/或口述话语是在与针对多个助理查询之一的对应先前对话会话的对应上下文相对应的当前对话会话的当前上下文中接收的。例如,系统可以使用ASR引擎130A1和/或130A2来处理音频数据流(例如,图2的音频数据流201)以生成ASR输出流(例如,图2的ASR输出203的流)。此外,系统可以使用NLU引擎140A1和/或140A2处理ASR输出流以生成NLU输出流(例如,图2的NLU输出204的流)。此外,基于ASR输出流和/或NLU输出流,系统可以识别当前助理查询。在一些实施方式中,系统还可以通过使得1P系统191和/或3P系统中的一个或多个处理ASR输出流和/或NLU输出流来确定一个或多个助理输出(例如,图2的一个或多个助理输出205)集合。
在图3的方法300的一些实施方式中,系统可以利用在线输出修改引擎180来确定当前助理查询的一个或多个词项或短语对应于多个助理查询之一的一个或多个词项或短语,对于其而言,一个或多个对应LLM输出被索引(例如,使用任何已知的技术来确定词项或短语是否对应于一个或另一个,诸如精确匹配技术、软匹配技术、编辑距离技术、发音相似性技术、嵌入技术等)。响应于确定当前助理查询的一个或多个词项或短语对应于多个助理查询之一的一个或多个词项或短语,系统可以(例如,从LLM输出数据库150A)获得在框356的迭代处被索引并且与多个助理查询之一相关联的一个或多个对应LLM输出。例如,如果当前查询包括短语“I’m hungry(我饿了)”,则系统可以获得在关于给定助理查询描述的上述示例中生成的一个或多个对应LLM输出。例如,系统可以基于比较当前查询的词项和给定助理查询的词项之间的编辑距离来确定上述当前查询和给定助理查询两者都包括短语“我饿了”。另外,例如,系统可以生成当前助理查询的嵌入,并将当前查询的嵌入映射到上面关于框356描述的嵌入空间。此外,系统可以基于嵌入空间中的当前查询的生成的嵌入与给定助理查询的在先生成的嵌入之间的距离满足距离阈值来确定当前助理查询对应于给定助理查询。
在图3的方法300的附加或替选实施方式中,系统可以利用在线输出修改引擎180来确定当接收到当前助理查询时检测到的一个或多个上下文信号对应于当接收到多个助理查询之一时的一个或多个对应上下文信号(例如,接收到的一周中的同一天、一天中的同一时间、同一地点、相同的环境噪声存在于客户端设备的环境中、在对话会话期间以口述话语的特定序列接收等)。响应于确定与当前助理查询相关联的一个或多个上下文信号对应于多个助理查询之一的一个或多个上下文信号,系统可以(例如,从LLM输出数据库150A)获得在框356的迭代处索引的并且与多个助理查询之一相关联的一个或多个对应LLM输出。例如,如果当前查询是在晚上在用户的主要住所处接收到的,则系统可以获得在关于给定助理查询描述的上述示例中生成的一个或多个对应LLM输出。例如,系统可以确定所描述的当前查询和给定助理查询两者都与“晚上”的时间上下文信号和“主要住所”的位置上下文信号相关联。另外,例如,系统可以生成与当前助理查询相关联的一个或多个上下文信号的嵌入,并将与当前查询相关联的一个或多个上下文信号的嵌入映射到上面关于框356描述的嵌入空间。此外,系统可以基于嵌入空间中的与当前查询相关联的一个或多个上下文信号的所生成的嵌入和与给定助理查询相关联的一个或多个上下文信号的在先生成的嵌入之间的距离满足距离阈值来确定与当前助理查询相关联的一个或多个上下文信号对应于与给定助理查询相关联的一个或多个上下文信号。
值得注意的是,系统可以利用当前助理查询和其中接收到当前助理查询的对话会话的上下文(例如,检测到的一个或多个上下文信号)中的一个或两者来确定一个或多个对应LLM输出将被用于生成要响应于当前助理查询而被提供以呈现给用户的一个或多个当前助理输出。在各种实施方式中,系统可以附加地或替选地利用针对当前助理查询生成的一个或多个助理输出来确定要在生成要响应于当前助理查询而被提供以呈现给用户的一个或多个当前助理输出时使用的一个或多个对应LLM输出。例如,系统可以附加地或替选地生成一个或多个助理输出(例如,如关于图2所描述的一个或多个助理输出205),其被预测为响应于当前助理查询(但不是使用LLM引擎150A1和/或150A2生成的),并且使用上述各种技术确定被预测为响应于当前助理查询的一个或多个助理输出对应于针对多个助理查询之一的一个或多个在先生成的助理输出。
在框366处,系统使得自动化助理利用一个或多个对应LLM输出来生成要提供以呈现给客户端设备的用户的一个或多个当前助理输出。例如,系统可以根据一个或多个排名准则对一个或多个助理输出(例如,如关于图2所描述的一个或多个助理输出205)以及一个或多个对应LLM输出(例如,如关于图2所描述的一个或多个修改的助理输出206)进行排名。此外,系统可从一个或多个助理输出以及一个或多个对应LLM输出当中选择一或多个当前助理输出。此外,系统可以使得一个或多个当前助理输出被视觉和/或可听地渲染以呈现给客户端设备的用户。
尽管利用以离线方式生成一个或多个对应LLM输出(例如,通过利用离线输出修改引擎170以使用一个或多个LLM来生成对应LLM输出,并且在LLM输出数据库150A中对一个或多个对应LLM输出进行索引),并且随后以在线方式利用一个或多个对应LLM输出(例如,通过利用在线输出修改引擎180以基于当前助理查询来确定从LLM输出数据库150A利用)描述图3的方法300的实施方式,但是应当理解,这是为了示例的目的并且并不意味着限制。例如,如下文关于图4和图5所描述的,在优选实施方式中,在线输出修改引擎180可以附加地或替选地以在线方式利用LLM引擎150A1和/或150A2。
现在转向图4,描绘了图示利用大语言模型基于生成助理查询来生成助理输出的示例方法400的流程图。为了方便起见,参考执行来自图2的处理流程200的操作的系统来描述方法400的操作。方法400的该系统包括计算设备(例如,图1的客户端设备110、图6的客户端设备610和/或图7的计算设备710、一个或多个服务器和/或其他计算设备)的一个或多个处理器、存储器和/或其他组件。此外,虽然以特定顺序示出方法400的操作,但这并不意味着限制。一个或多个操作可以被重新排序、省略和/或添加。
在框452处,系统接收捕获用户的口述话语的音频数据流,该口述话语包括指向自动化助理的助理查询,并且该口述话语是在用户和自动化助理之间的对话会话期间接收的。在一些实施方式中,系统可以仅响应于确定满足一个或多个条件而处理音频数据流以确定其捕获助理查询。例如,系统可以监视音频数据流中包括的一个或多个特定词或短语(例如,监视使用热词检测模型调用自动化助理的一个或多个特定词或短语)。此外,例如,可选地除了一个或多个其他信号(例如,由客户端设备的视觉传感器捕获的一个或多个手势、指向客户端设备的眼睛凝视等)之外,系统还可以监视指向客户端设备的语音。
在框454处,系统基于处理音频数据流来确定助理输出集合,该集合中包括的助理输出中的每一个是响应于口述话语中包括的助理查询。例如,系统可以使用ASR引擎130A1和/或130A2来处理音频数据流(例如,音频数据流201)以生成ASR输出流(例如,ASR输出203)。此外,系统可以使用NLU引擎140A1和/或140A2处理ASR输出流(例如,音频数据流201)以生成NLU输出流(例如,NLU输出204的流)。此外,系统可以使得一个或多个1P系统191和/或3P系统192处理NLU输出流(例如,NLU输出204的流)以生成助理输出205集合(例如,助理输出集合)。值得注意的是,助理输出集合可以对应于这样的一个或多个候选助理输出:自动化助理可以在没有本文描述的技术(即,在如本文所述的修改助理输出中不利用LLM引擎150A1和/或150A2的技术)的情况下考虑这些一个或多个候选助理输出以用于响应于口述话语时。
在框456处,系统处理助理输出集合和对话会话的上下文以:(1)使用一个或多个LLM输出生成修改的助理输出集合,该一个或多个LLM输出中的每一个是至少基于对话会话的上下文和/或包括在助理输出集合中的一个或多个助理输出来确定的;以及(2)基于对话会话的上下文的至少一部分和口述话语中所包括的助理查询的至少一部分来生成与口述话语相关的附加助理查询。在各种实施方式中,可以进一步基于音频数据流中捕获的口述话语中包括的助理查询来确定每个LLM输出。在一些实施方式中,在生成修改的助理输出集合时,一个或多个LLM输出可能已经以离线方式在先生成(例如,在接收到口述话语并使用离线输出修改引擎170之前,如上面参考图3所述)。在这些实施方式中,系统可以确定音频数据流中捕获的口述话语中包括的助理查询对应于已经为其在先生成一个或多个LLM输出的先前助理查询,该对话会话的上下文对应于其中接收到先前助理查询的先前对话会话的先前上下文,和/或包括在框454处确定的助理输出集合中的一个或多个助理输出对应于基于先前查询确定的一个或多个先前助理输出。此外,系统可以获得基于如关于图3的方法300所描述的分别对应于助理查询、上下文和/或包括在助理输出集合中的一个或多个助理输出的先前助理查询、先前上下文和/或一个或多个先前助理输出而索引的一个或多个LLM输出(例如,使用在线输出修改引擎180),并利用一个或多个LLM输出作为修改的助理输出集合。
在附加或替选实施方式中,在生成修改的助理输出集合时,系统可以以在线方式至少处理对话会话的上下文和/或包括在助理输出集合中的一个或多个助理输出(例如,响应于接收到口述话语并使用在线输出修改引擎180)以生成一个或多个LLM输出。例如,系统可以使得LLM引擎150A1和/或150A2使用一个或多个LLM来处理对话会话的上下文、助理查询和/或包括在助理输出集合中的一个或多个助理输出,以生成修改的助理输出集合。可以以与上面关于以离线方式生成一个或多个LLM输出参考图3的方法300的框354描述的相同或相似的方式但是响应于在客户端设备处接收到口述话语以在线方式生成一个或多个LLM输出。例如,系统可以使用一个或多个LLM来处理包括在助理输出集合中的一个或多个助理输出,以针对包括在助理输出集合中的一个或多个助理输出中的每个生成一个或多个个性答复,如上文关于图3的方法300的框354所述。换言之,包括在助理输出集合中的每个助理输出在与每个助理输出相关联的韵律属性方面可以具有有限的词汇和一致的个性。然而,在处理包括在助理输出集合中的每个助理输出以生成修改的助理输出集合中,每个修改的助理输出可以根据使用一个或多个LLM以生成一个或多个修改的助理输出而具有大得多且在与每个修改的助理输出相关联的韵律属性方面具有更大的差异的词汇。结果,每个修改的助理输出可以对应于上下文相关的助理输出,其与同自动化助理进行对话会话的用户更好地产生共鸣。
类似地,在一些实施方式中,在生成附加助理查询时,可能已经以离线方式在先生成了附加助理(例如,在接收到口述话语并使用离线输出修改引擎170之前,如上文关于图3所述)。在这些实施方式中,并且类似于上面关于获得以离线方式在先生成的一个或多个LLM输出所描述的,系统可以获得基于如关于方法300所描述的分别对应于助理查询、上下文和/或包括在助理输出集合中的一个或多个助理输出的先前助理查询、先前上下文和/或一个或多个先前助理输出而索引的附加助理查询,并且利用在先生成的附加助理查询作为附加助理查询。
而且,类似地,在附加或替选实施方式中,在生成附加助理查询时,系统可以以在线方式(例如,响应于接收到口述话语并使用在线输出修改引擎180)至少处理对话会话的上下文和/或包括在助理输出集合中的一个或多个助理输出,以生成附加助理查询。例如,系统可以使得LLM引擎150A1和/或150A2使用一个或多个LLM来处理对话会话的上下文、助理查询和/或包括在助理输出集合中的一个或多个助理输出,以生成附加助理查询。可以以与上面关于以离线方式生成附加助理查询参考图3的方法300的框354描述的相同或相似的方式但是响应于在客户端设备处接收到口述话语以在线方式生成附加助理查询。在一些实施方式中,本文描述的一个或多个LLM可以具有专用于执行某些功能的多个相异的层。例如,一个或多个LLM的一个或多个第一层可以用于生成本文描述的个性答复,并且一个或多个LLM的一个或多个第二层可以用于生成本文描述的附加助理查询。在附加或替选实施方式中,一个或多个LLM可以在生成本文描述的附加助理查询时与未包括在一个或多个LLM中的一个或多个附加层进行通信。例如,一个或多个LLM的一个或多个层可以用于生成本文描述的个性回复,并且与一个或多个LLM通信的另一ML模型的一个或多个附加层可以用于生成本文描述的附加助理查询。下面将参考图6更详细地描述个性回复和附加助理查询的非限制性示例。
在框458处,系统基于附加助理查询来确定响应于附加助理查询的附加助理输出。在一些实施方式中,系统可以使得附加助理查询由1P系统191和/或3P系统192中的一个或多个以关于图2中的处理助理查询所描述的相同或相似的方式来处理,以生成附加助理输出。在一些实施方式中,附加助理输出可以是单个附加助理输出,而在其他实施方式中,附加助理输出可以被包括在附加助理输出集合中(例如,类似于图2的附加助理输出205集合)。在附加或替选实施方式中,附加助理查询可以基于例如提供口述话语的用户的用户简档数据和/或自动化助理可访问的任何其他数据而被直接映射到附加助理输出。
在框460处,系统基于响应于附加助理查询的附加助理输出来处理修改的助理输出集合以生成附加的修改的助理输出集合。在一些实施方式中,系统可以将对一个或多个修改的助理输出的附加助理输出在前附加(prepend)或在后附加(append)到包括在框456处生成的修改的助理输出集合中的一个或多个助理输出中的每个。在附加或替选实施方式中并且如框460A处所指示的,系统可以处理附加助理输出和对话会话的上下文,以使用在框456处使用的一个或多个LLM输出和/或基于对话会话的上下文的至少一部分和附加助理输出的至少一部分而生成的除了在框456处使用的一个或多个LLM输出之外的一个或多个附加LLM输出来生成附加的修改的助理输出集合。附加的修改的助理输出集合可以以与上面关于生成修改的助理输出集合描述的相同或类似的方式但是基于附加助理输出而不是助理输出集合(例如,使用以离线方式和/或以在线方式使用LLM引擎150A1和/或150A2生成的一个或多个LLM输出)来生成。
在框462处,系统使得来自修改的助理输出集合的给定的修改的助理输出和/或来自附加的修改的助理输出集合的给定的附加的修改的助理输出被提供以呈现给用户。在一些实施方式中,系统可以使得排名引擎190根据一个或多个排名准则对包括在修改的助理输出集合中的一个或多个修改的助理输出中的每个(以及可选地,包括在助理输出集合中的一个或多个助理输出中的每个)进行排名,并且从修改的助理输出集合中选择给定的修改的助理输出(或者从助理输出集合中选择给定助理输出)。此外,系统还可以使得排名引擎190根据一个或多个排名准则对包括在附加的修改的助理输出集合中的一个或多个附加的修改助理输出中的每个(以及可选地附加助理输出)进行排名,并且从附加的修改的助理输出集合中选择给定的附加的修改助理输出(或者选择附加助理输出作为给定附加助理输出)。在这些实施方式中,系统可以组合给定的修改的助理输出和给定的附加助理输出,并且使得给定的修改的助理输出和给定的附加助理输出被提供以向与自动化助理进行对话会话的客户端设备的用户进行视觉和/或可听呈现。
现在转向图5,描绘了图示利用大语言模型基于生成助理个性回复来生成助理输出的示例方法500的流程图。为了方便起见,参考执行来自图2的处理流程200的操作的系统来描述方法500的操作。方法500的该系统包括计算设备(例如,图1的客户端设备110、图6的客户端设备610和/或图7的计算设备710、一个或多个服务器和/或其他计算设备)的一个或多个处理器、存储器和/或其他组件。此外,虽然以特定顺序示出方法500的操作,但这并不意味着限制。一个或多个操作可以被重新排序、省略和/或添加。
在框552处,系统接收捕获用户的口述话语的音频数据流,该口述话语包括指向自动化助理的助理查询,并且该口述话语是在用户和自动化助理之间的对话会话期间接收的。在框554处,系统基于处理音频数据流来确定助理输出集合,包括在该集合中的每个助理输出响应于包括在口述话语中的助理查询。可以以与分别关于图4的方法400的框452和454描述的相同或相似的方式来执行图5的方法500的框552和554的操作。
在框556处,系统确定是否修改包括在助理输出集合中的一个或多个助理输出。系统可以基于例如用户提供口述话语(例如,包括在NLU输出204的流中)的意图、包括在助理输出集合(例如,助理输出205集合)中的一个或多个助理输出、与修改包括在助理输出集合中的一个或多个助理输出相关联的一个或多个计算成本(例如,电池消耗、处理器消耗、等待时间等)、与自动化助理交互的持续时间和/或其他考虑因素来确定是否修改一个或多个助理输出。例如,如果用户的意图指示提供口述话语的用户期望快速和/或事实回答(例如,“Why is the sky blue?”、“what’s the weather?(天气怎么样?)”、“what time is it?”等),在一些情况下,系统可以确定不修改一个或多个助理输出,以减少在提供响应于口述话语的内容时的等待时间和计算资源的消耗。另外,例如,如果用户的客户端设备处于省电模式,则系统可以确定不修改助理输出中的一个或多个以节省电池电量。另外,例如,如果用户已经进行对话会话的持续时间超过阈值持续时间(例如,30秒、1分钟等),则系统可以确定不修改一个或多个助理输出,以尝试以更快速且高效的方式结束对话会话。
如果在框556的迭代处,系统确定不修改包括在助理输出集合中的一个或多个助理输出,则系统可以前进到框558。在框558处,系统使得来自助理输出集合的给定助理输出被提供以呈现给用户。例如,系统可以使得排名引擎190根据一个或多个排名准则对包括在助理输出集合中的每个助理输出进行排名,并且基于排名来选择要提供以向用户进行视觉和/或可听呈现的给定助理输出。
如果在框556的迭代处,系统确定修改包括在助理输出集合中的一个或多个助理输出,则系统可以前进到框560。在框560处,系统处理助理输出集合和对话会话的上下文,以使用一个或多个LLM输出生成修改的助理输出集合,一个或多个LLM输出中的每一个是基于对话会话的上下文和/或包括在助理输出集合中的一个或多个助理输出来确定的,并且一个或多个LLM输出中的每一个反映自动化助理的来自多个相异的个性当中的对应个性。如关于图3的方法300的框354所描述的,可以使用各种相异的参数来生成一个或多个LLM输出,以反映自动化助理的不同个性。在各种实施方式中,可以进一步基于音频数据流中捕获的口述话语中包括的助理查询来确定每个LLM输出。在一些实施方式中,系统可以处理助理输出集合和对话会话的上下文(以及可选地助理查询),以使用如本文所述的以离线方式在先生成的LLM输出中的一个或多个来生成修改的助理输出集合,而在附加或替选实施方式中,系统可以处理助理输出集合和对话会话的上下文(以及可选地助理查询),以如本文描述的以在线方式生成修改的助理输出集合。如上面关于图4的方法400所指出的,下面关于图6更详细地描述个性答复和附加助理查询的非限制性示例。
在框562处,系统使得来自助理输出集合的给定助理输出被提供以呈现给用户。在一些实施方式中,系统可以使得排名引擎190根据一个或多个排名准则对包括在修改的助理输出集合中的一个或多个修改的助理输出中的每个(以及可选地,包括在助理输出集合中的一个或多个助理输出中的每个)进行排名,并且从修改的助理输出集合中选择给定的修改的助理输出(或者从助理输出集合中选择给定助理输出)。此外,系统可以使得给定的修改的助理输出被提供以向用户进行视觉和/或可听呈现。
尽管没有关于生成任何附加助理查询描述图5,但是应当理解,这是为了示例的目的并且并不意味着限制。相反,应当理解,在图4的方法400中生成附加助理查询是基于确定存在上下文相关的附加助理输出,其可以是为了促进对话会话并且关于提供用户的更自然的谈话体验而提供的,使得提供用于呈现给用户的任何助理输出更好地反映人类之间的对话会话,并且使得用户和自动化助理之间的对话会话更好地与用户产生共鸣。此外,虽然没有关于确定是否修改助理输出集合描述图3和图4,但还应该理解的是,这是为了示例的目的并且并不意味着限制。相反,应当理解,可以在图3、图4和图5的示例方法中的任一个中执行确定是否使用一个或多个LLM来触发对助理响应集合的修改。
现在转向图6,描绘了用户和自动化助理之间的对话会话的非限制性示例,其中,自动化助理利用一个或多个LLM来生成助理输出。如本文所述,在一些实施方式中,自动化助理可以利用以离线方式在先生成的一个或多个LLM输出来生成修改的助理输出集合(例如,如上文关于图3的方法300所述)。例如,自动化助理可以确定已经为其在先生成一个或多个LLM输出的先前助理查询对应于口述话语中包括的助理查询,先前对话会话的先前上下文对应于其中接收到口述话语的在用户和自动化助理之间的对话会话的上下文,和/或一个或多个先前助理输出对应于针对包括在口述话语中的助理查询的助理输出集合中包括的一个或多个助理输出。此外,自动化助理可以获得根据先前助理查询、先前上下文和/或包括在先前助理输出集合中的一个或多个先前助理输出来索引的一个或多个LLM输出(例如,在LLM输出数据库150A中),并利用一个或多个LLM输出作为修改的助理输出集合。在附加或替选实施方式中,自动化助理可以使用一个或多个LLM来处理助理查询、对话会话的上下文和/或包括在助理输出集合中的一个或多个助理输出,以生成要以在线方式用作修改的助理输出集合的一个或多个LLM输出(例如,如上文关于图4的方法400和图5的方法500所述)。因此,提供图6的非限制性示例来说明根据本文描述的技术的LLM的利用如何导致在用户和自动化助理之间的改进的自然谈话。
客户端设备610(例如,图1的客户端设备110的实例)可以包括各种用户接口组件,包括例如:麦克风,用于基于口述话语和/或其他可听输入生成音频数据;扬声器680,用于可听地渲染合成语音和/或其他可听输出;和/或显示器680,用于可视地渲染视觉输出。此外,客户端设备610的显示器680可以包括可以由客户端设备610的用户与之交互以使得客户端设备610执行一个或多个动作的各种系统接口元件681、682和683(例如,硬件和或软件接口元件)。客户端设备610的显示器680使得用户能够通过触摸输入(例如,通过将用户输入引导到显示器680或其部分(例如,到文本输入框(未描绘)、到键盘(未描绘)或到显示器680的其他部分))和/或通过口述输入(例如,通过在客户端设备610处选择麦克风接口元件684——或仅通过说话而不必选择麦克风接口元件684(即,自动化助理可以监视一个或多个词项或短语、手势、凝视、嘴部移动、嘴唇运动和/或激活口述输入的其他条件))与显示器680上渲染的内容交互。尽管图6中描绘的客户端设备610是移动电话,但是应当理解,这只是为了示例而不意味着限制。例如,客户端设备610可以是具有显示器的独立式扬声器、不具有显示器的独立式扬声器、家庭自动化设备、车载系统、膝上型计算机、台式计算机和/或能够执行自动化助理以与客户端设备610的用户进行人机对话会话的任何其他设备。
例如,假设客户端设备610的用户提供“Hey Assistant,what time is it?(嘿助理,现在几点了?)”的口述话语652。在该示例中,自动化助理可以使得使用ASR引擎130A1和/或130A2来处理捕获口述话语652的音频数据,以生成ASR输出流。此外,自动化助理可以使得使用NLU引擎140A1和/或140A2来处理ASR输出流,以生成NLU输出流。此外,自动化助理可以使得由1P系统191和/或3P系统192中的一个或多个处理NLU输出流以生成一个或多个助理输出的集合。该助理输出集合可以包括例如“8:30AM(上午8:30)”、“Good morning,it’s 8:30AM(早上好,现在是上午8:30)”和/或向客户端设备610的用户传达当前时间的任何其他输出。
在图6的示例中,进一步假设自动化助理确定修改包括在助理输出集合中的一个或多个助理输出以生成修改的助理输出集合。例如,自动化助理可以确定包括在口述话语652中的助理查询请求自动化助理提供当前时间以呈现给用户。自动化助理可以确定请求自动化助理提供当前时间以呈现给用户的已经为其在先生成了一个或多个LLM输出的先前助理查询的实例对应于包括在图6的口述话语652中的助理查询,先前对话会话的先前上下文对应于图6中的用户和自动化助理之间的对话会话的上下文(例如,用户请求自动化助理提供早上的当前时间(并且可选地通过发起对话会话来做出请求)、客户端设备610位于特定位置处、和/或其他上下文信号),和/或一个或多个先前助理输出对应于针对包括在图6的口述话语652中的助理查询的助理输出集合中包括的一个或多个助理输出。此外,自动化助理可以获得根据先前助理查询、先前上下文和/或包括在先前助理输出集合中的一个或多个先前助理输出(例如,在LLM输出数据库150A中)索引的一个或多个LLM输出,并且利用一个或多个LLM输出作为修改的助理输出集合。另外,例如,自动化助理可以使得使用一个或多个LLM来处理助理查询、对话会话的上下文和/或包括在助理输出集合中的一个或多个助理输出,从而以在线方式生成一个或多个LLM输出以用作修改的助理输出集合。
在图6的示例中,进一步假设自动化助理确定提供修改的助理输出654“Goodmorning[User]!It’s 8:30AM.Any fun plans today?(早上好[用户]!现在是上午8:30。今天有什么有趣的计划吗?)”以用于呈现给用户,其中,修改的助理输出654是基于一个或多个LLM输出来确定的。提供以呈现给用户的修改的助理输出654是针对客户端设备610的用户和对话会话的上下文而个性化或定制的,因为修改的助理输出654用上下文适当的问候语(例如,“Good Morning(早上好)”)向用户打招呼,并通过姓名(例如,“[User]([用户])”)称呼客户端设备610的用户。值得注意的是,一个或多个LLM输出可以包括一个或多个对应的占位符(例如,如修改的助理输出654中的“[User]([用户])!”所指示的),其可以填充有自动化助理可访问的用户简档数据。虽然图6的示例包括客户端设备610的用户的姓名的对应占位符,但是应当理解,这是为了示例的目的并且并不意味着限制。例如,一个或多个对应占位符可以填充有自动化助理可访问的任何数据,诸如智能联网设备标识符(例如,智能灯、智能TV、智能电器、智能扬声器、智能门锁等)、与客户端设备610的用户相关联的已知位置(例如,城市、州、县、地区、省、国家、工作地点的物理地址、用户的业务、或客户端设备610的用户的主要住所等)、实体引用(例如,引用人、地点、事等)、在用户的客户端设备610处可访问的软件应用、和/或自动化助理可访问的任何其他数据。
此外,修改的助理输出654在响应于口述话语652中包括的助理查询(例如,“It’s8:30AM(现在是上午8:30)”)方面起作用。然而,修改的助理输出654不仅是针对用户个性化或定制的并且在对助理查询进行响应方面起作用,而且修改的助理输出654还通过进一步使用户进行对话会话来帮助驱动用户和自动化助理之间的对话会话(例如,“Any funplans today?(今天有什么有趣的计划吗?)”)。如果不使用本文关于使用一个或多个LLM输出以基于处理口述话语652来修改最初生成的助理输出集合描述的技术,则自动化助理可以简单地回复“It’s 8:30AM(现在是上午8:30)”而不向客户端设备610的用户提供任何问候语(例如,“Good morning(早上好)”),不用姓名(例如,“[User]([用户])”)称呼客户端设备610的用户,并且不进一步使客户端设备610的用户进行对话会话(例如,“Any fun planstoday?(今天有什么有趣的计划吗?)”)。因此,与不利用一个或多个LLM输出的原始生成的助理输出集合中包括的任何助理输出相比,修改的助理输出654可以更好地与客户端设备610的用户产生共鸣。
在图6的示例中,进一步假设客户端设备610的用户提供“Yes,I’mthinking aboutgoing to the beach(是的,我正在考虑去海滩)”的口述话语656。在该示例中,自动化助理可以使得处理捕获口述话语656的音频数据以生成在不使用一个或多个LLM输出的情况下生成的助理输出集合。此外,自动化助理可以使得处理包括在口述话语656中的助理查询、助理输出集合和/或对话会话的上下文以生成使用一个或多个LLM输出确定的修改的助理输出集合(例如,以离线和/或在线方式),并且可选地基于助理查询来生成附加助理查询。
在该示例中,包括在(在不使用一个或多个LLM输出的情况下生成的)助理输出集合中的助理输出可以是有限的,因为包括在口述话语656中的助理查询不请求自动化助理执行任何动作。例如,包括在助理输出集合中的助理输出可以包括“Sounds fun!(听起来很有趣!)”、“Surf’s up!(冲浪了!)”、“That sounds like fun!(那听起来很有趣!)”和/或响应于口述话语656的其他助理输出,但不进一步使客户端设备610的用户进行对话会话。换句话说,包括在助理输出集合中的助理输出可能在词汇变化方面受到限制,因为助理输出不是使用如本文所述的一个或多个LLM输出来生成的。尽管如此,自动化助理可以利用包括在助理输出集合中的助理输出来确定如何使用一个或多个LLM输出来修改一个或多个助理输出。
此外,并且如关于图3和图4所描述的,自动化助理可以基于助理查询并使用一个或多个LLM或与一个或多个LLM通信的不同ML模型来生成附加助理查询。例如,在图6的示例中,由客户端设备610的用户提供的口述话语656指示用户要去海滩。基于识别到与口述话语656相关联的意图指示用户打算去海滩,自动化助理可以确定与查找客户端设备610的用户经常访问的海滩(例如,名为“Half Moon Bay(半月湾)”的示例海滩)的天气相关联的相关意图。基于识别到相关意图,自动化助理可以生成具有位置参数“Half Moon Bay(半月湾)”的““What’s the weather?(天气怎么样?)”的附加助理查询,将查询提交给一个或多个1P系统191和/或3P系统192以获得附加助理输出,其包括“Half Moon Bay(半月湾)”的“weather(天气)”,其指示例如“Half Moon Bay(半月湾)”会下雨,并且全天气温阴冷。在一些实施方式中,自动化助理可以使得处理附加助理输出和/或对话会话的上下文以生成使用一个或多个LLM输出和/或一个或多个附加LLM输出来确定的附加的修改的助理输出集合。
在图6的示例中,自动化助理可以使得包括在助理输出集合和修改的助理输出集合中的助理输出根据一个或多个排名准则来排名,并且可以基于排名来选择一个或多个助理输出(例如,选择给定助理输出“Sounds fun!(听起来很有趣!)”)。此外,自动化助理可以使得包括在附加的修改的助理输出集合中的助理输出和附加助理输出根据一个或多个排名准则来排名,并且可以基于排名来选择一个或多个助理输出(例如,选择给定的附加助理输出“But if you’re going to Half Moon Bay again,expect rain and chilly temps.(但是如果你再次前往半月湾,预计会下雨且气温阴冷。)”)。此外,自动化助理可以组合所选择的给定助理输出和所选择的给定附加助理输出,从而产生“Sounds fun!But if you’re going to Half Moon Bay again,expect rain and chilly temps(听起来很有趣!但是,如果你再次前往半月湾,预计会下雨且气温阴冷)”的修改的助理输出658,并且可以使得修改的助理输出658被提供以向客户端设备610的用户进行视觉和/或可听呈现。因此,在该示例中,自动化助理可以处理口述话语656,并提供与口述话语相关联的附加上下文信息(例如,客户端设备610的用户可能访问的海滩处的天气)以进一步使客户端设备610的用户进行对话会话。在没有本文描述的技术的情况下,尽管自动化助理能够确定并提供天气信息,但可能需要客户端设备610的用户主动从自动化助理请求天气信息,从而增加用户输入的数量并浪费客户端设备610处处理增加的数量的用户输入的计算资源,并且还增加客户端设备610的用户的认知负荷。
在图6的示例中,进一步假设客户端设备610的用户提供口述话语660“Oh no…thanks for the heads up,can you remind me to check the weather again in twohours?(哦不……谢谢提醒,你能提醒我在两小时后再次查看天气吗?)”。在该示例中,自动化助理可以使得处理捕获口述话语660的音频数据以生成在不使用一个或多个LLM输出的情况下生成的助理输出集合。此外,自动化助理可以使得处理包括在口述话语660中的助理查询、助理输出集合和/或对话会话的上下文以生成使用一个或多个LLM输出确定的修改的助理输出集合(例如,以离线和/或在线方式)。基于处理口述话语660,自动化助理可以确定设置上午10:30(例如,对话会话后两个小时)的提醒,其提醒客户端设备610的用户检查“Half Moon Bay(半月湾)”处的天气,或者在上午10:30主动向客户端设备610的用户提供“Half Moon Bay”处的天气。此外,自动化助理可以使得来自(即,使用一个或多个LLM输出生成的)修改的助理输出集合的修改的助理输出662“Sure thing,I set the reminderand hope the weather clears up for you(没问题,我设置提醒并希望天气为你放晴)”将被提供以向客户端设备610的用户进行视觉和/或可听呈现。值得注意的是,图6的示例中的修改的助理输出662相对于对话会话而上下文相关,因为其向用户指示天气放晴的愿望。相反,包括在助理输出集合中的助理输出(即,在不使用一个或多个LLM输出的情况下生成的)可能仅提供设置提醒的指示,而不考虑对话会话的上下文。
虽然关于使用一个或多个LLM输出并基于对话会话的特定口述话语和上下文生成特定的修改的助理输出以及选择要提供以呈现给用户的特定的修改的助理输出来描述图6,但是应当理解,这是为了示例的目的而不意味着限制。相反,应当理解,本文描述的技术可以用于任何用户与自动化助理的对应实例之间的任何对话会话。此外,虽然在客户端设备610的显示器680处描绘了与用户和自动化助理之间的对话会话相对应的转录,但是还应当理解,这是为了示例的目的并且并不意味着限制。例如,应当理解,对话会话可以在能够执行自动化助理的任何设备处执行,而不管客户端设备是否包括显示器。
此外,还应当理解的是,在图6的对话会话中提供用于呈现给用户的助理输出可以包括本文描述的各种个性回复。例如,可以使用第一参数集合来生成修改的助理输出654,该第一参数集合在要由自动化助理使用的第一词汇和/或要用于提供修改的助理输出654以向用户进行可听呈现的第一韵律属性集合方面反映自动化助理的第一个性。此外,可以使用第二参数集合来生成修改的助理输出658,该第二参数集合在要由自动化助理使用的第二词汇和/或要用于提供修改的助理输出658以向用户进行可听呈现的第二韵律属性集合方面反映自动化助理的第二个性。在此示例中,第一个性可以反映例如用于提供早晨问候的管家或女仆的个性,响应于请求当前时间的用户,并询问用户他/她是否对当天有任何计划。此外,第二个性可以反映例如天气预报员、冲浪者或救生员(或其组合)的个性,其用于指示去海滩听起来很有趣,但天气可能不适合在海滩度过一天。例如,可以利用冲浪者个性来提供修改的助理输出658的“Sounds fun!(听起来很有趣!)”部分,因为用户指示他/她计划去海滩,并且天气预报员个性可以被用来提供“But if you’re going to Half MoonBay again,expect rain and chilly temps(但是如果你再次去半月湾,预计会下雨且气温寒冷)”,因为自动化助理正在向用户提供天气信息。
因此,自动化助理可以基于由自动化助理所使用的词汇和在渲染用于向用户可听呈现的修改的助理输出时使用的韵律属性两者来动态地调整用于提供修改的助理输出以呈现给用户的个性。值得注意的是,自动化助理可以基于对话会话的上下文——包括从用户接收到的先前口述话语和由自动化助理提供的先前助理输出和/或本文描述的任何其他上下文信号——动态地调整在提供修改的助理输出时使用的这些个性。结果,由自动化助理提供的修改的助理输出可以更好地与客户端设备的用户产生共鸣。
此外,虽然本文关于用户在整个对话会话中提供口述话语来描述图6,但是应当理解,这是为了示例的目的并且并不意味着限制。例如,用户可以附加地或替选地在整个对话会话中提供键入输入和/或触摸输入。在这些实施方式中,自动化助理可以处理键入输入(例如,使用NLU引擎140A1和/或140A2)以生成NLU输出流(例如,并且可选地跳过使用ASR引擎130A1和/或130A2的任何处理),并且可以处理与从键入输入和/或触摸输入(例如,使用LLM引擎150A1和/或150A2)导出的助理查询相对应的NLU数据流和文本输入,以便以与上述相同或相似的方式生成一个或多个修改助理输出的集合。
现在转向图7,描绘了可以可选地用来执行本文描述的技术的一个或多个方面的示例计算设备710的框图。在一些实施方式中,客户端设备、基于云的自动化助理组件和/或其他组件中的一个或多个可以包括示例计算设备710的一个或多个组件。
计算设备710通常包括至少一个处理器714,其经由总线子系统712与多个外围设备通信。这些外围设备可以包括存储子系统724(包括例如存储器子系统725和文件存储子系统726)、用户接口输出设备720、用户接口输入设备722和网络接口子系统716。输入和输出设备允许用户与计算设备710交互。网络接口子系统716提供到外部网络的接口并且耦合到其他计算设备中的对应的接口设备。
用户接口输入设备722可以包括键盘、诸如鼠标、轨迹球、触摸板或图形输入板的指示设备、扫描仪、并入显示器中的触摸屏、诸如话音辨识系统、麦克风的音频输入设备、和/或其他类型的输入设备。一般而言,术语“输入设备”的使用旨在包括将信息输入到计算设备710中或通信网络上的所有可能类型的设备和方式。
用户接口输出设备720可以包括显示子系统、打印机、传真机或非视觉显示器,诸如音频输出设备。显示子系统可以包括阴极射线管(CRT)、诸如液晶显示器(LCD)的平板设备、投影设备或用于创建可见图像的某种其他机构。显示子系统还可以诸如经由音频输出设备提供非视觉显示。一般而言,术语“输出设备”的使用旨在包括将信息从计算设备710输出到用户或另一机器或计算设备的所有可能类型的设备和方式。
存储子系统724存储提供本文描述的一些或所有模块的功能的编程和数据结构。例如,存储子系统724可以包括用于执行本文所公开的方法的选定方面以及用于实现图1和图2中描绘的各种组件的逻辑。
这些软件模块通常由处理器714单独执行或与其他处理器组合执行。存储子系统724中使用的存储器725可以包括多个存储器,包括用于在程序执行期间存储指令和数据的主随机存取存储器(RAM)730和其中存储固定指令的只读存储器(ROM)732。文件存储子系统726可以为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移除介质、CD-ROM驱动器、光盘驱动器或可移除介质盒。实现某些实施方式的功能的模块可以由文件存储子系统726存储在存储子系统724中,或者存储在处理器714可访问的其他机器中。
总线子系统712提供用于使计算设备710的各种组件和子系统按预期彼此通信的机制。尽管总线子系统712被示意性地示出为单个总线,但是总线子系统712的替代实施方式可以使用多个总线。
计算设备710可以是不同的类型,包括工作站、服务器、计算集群、刀片服务器、服务器场、或任何其他数据处理系统或计算设备。由于计算机和网络的不断变化的性质,对图7中描绘的计算设备710的描述仅旨在作为用于说明一些实施方式的目的的具体示例。计算设备710的许多其他配置可能具有比图7中描绘的计算设备更多或更少的组件。
在本文描述的系统收集或以其他方式监视关于用户的个人信息或者可以利用个人和/或监视的信息的情况下,可以向用户提供机会以控制程序或特征是否收集用户信息(例如,关于用户的社交网络、社交行为或活动、职业、用户偏好或用户当前地理位置的信息),或者控制是否和/或如何从内容服务器接收可能与用户更相关的内容。此外,某些数据在存储或使用之前可能会以一种或多种方式进行处理,使得删除个人身份信息。例如,可以处理用户的身份,使得无法确定该用户的个人身份信息,或者可以在获得地理位置信息的情况下一般化用户的地理位置(诸如到城市、邮政编码或州级别),使得无法确定用户的特定地理位置。因此,用户可以控制如何收集和/或使用关于用户的信息。
在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:作为客户端设备的用户和由客户端设备实现的自动化助理之间的对话会话的一部分:接收捕获用户的口述话语的音频数据流,该音频数据流由客户端设备的一个或多个麦克风生成,并且口述话语包括助理查询;基于处理音频数据流来确定助理输出集合,助理输出集合中的每个助理输出响应于包括在口述话语中的助理查询;处理助理输出集合和对话会话的上下文以:使用利用大型语言模型(LLM)生成的一个或多个LLM输出来生成修改的助理输出集合,一个或多个LLM输出中的每个是基于对话会话的上下文的至少一部分以及包括在助理输出集合中的助理输出中的一个或多个来确定的,以及基于对话会话的上下文的至少一部分和助理查询的至少一部分来生成与口述话语相关的附加助理查询;基于附加助理查询来确定响应于附加助理查询的附加助理输出;处理附加助理输出和对话会话的上下文,以使用利用LLM生成的LLM输出或者一个或多个附加LLM输出中的一个或多个来生成附加的修改的助理输出集合,附加LLM输出中的每个是基于对话会话的上下文的至少一部分和附加助理输出来确定的;以及使得来自修改的助理输出集合的给定的修改的助理输出以及来自附加的修改的助理输出集合的给定的附加的修改的助理输出被提供以呈现给用户。
本文公开的技术的这些和其他实施方式可以可选地包括以下特征中的一个或多个。
在一些实施方式中,基于处理音频数据流来确定响应于包括在口述话语中的助理查询的助理输出可以包括:使用自动语音辨识(ASR)模型处理音频数据流以生成ASR输出流;使用自然语言理解(NLU)模型处理ASR输出流以生成NLU数据流;以及使得基于NLU流来确定助理输出集合。
在那些实施方式的一些版本中,处理助理输出集合和对话会话的上下文以使用利用LLM生成的LLM输出中的一个或多个来生成修改的助理输出集合可以包括:使用LLM处理助理输出集合和对话会话的上下文,以生成LLM输出中的一个或多个;以及基于LLM输出中的一个或多个来确定修改的助理输出集合。在那些实施方式的一些进一步版本中,使用LLM处理助理输出集合和对话会话的上下文以生成LLM输出中的一个或多个可以包括:使用多个相异的LLM参数集合中的第一LLM参数集合来处理助理输出集合和对话会话的上下文,以确定LLM输出中的具有多个相异的个性中的第一个性的一个或多个。修改的助理输出集合可以包括反映第一个性的一个或多个第一个性助理输出。在那些实施方式的又一版本中,使用LLM处理助理输出集合和对话会话的上下文以生成LLM输出中的一个或多个可以包括:使用多个相异的LLM参数集合中的第二LLM参数集合来处理助理输出集合和对话会话的上下文,以确定LLM输出中的具有多个相异的个性中的第二个性的一个或多个。修改的助理输出集合可以包括反映第二个性的一个或多个第二个性助理输出,并且第二个性可以不同于(unique from)第一个性。在那些实施方式的又进一步的版本中,可以使用与第一个性相关联的第一词汇来确定包括在修改的助理输出集合中并且反映第一个性的一个或多个第一个性助理输出,并且,可以使用与第二个性相关联的第二词汇来确定包括在修改的助理输出集合中并且反映第二个性的一个或多个第二个性助理输出,并且其中基于第二词汇不同于第一词汇,第二个性不同于第一个性。在那些实施方式的进一步附加或替选版本中,包括在修改的助理输出集合中并且反映第一个性的一个或多个第一个性助理输出可以与在提供给定的修改的助理输出以用于向用户进行可听呈现时使用的第一韵律属性集合相关联,包括在修改的助理输出集合中并且反映第二个性的一个或多个第二个性助理输出可以与在提供给定的修改的助理输出以用于向用户进行可听呈现时使用的第二韵律属性集合相关联,并且基于第二韵律属性集合不同于第一韵律属性集合,第二个性可以不同于第一个性。
在那些实施方式的一些版本中,处理助理输出集合和对话会话的上下文以使用利用LLM生成的LLM输出中的一个或多个来生成修改的助理输出集合可以包括:基于LLM输出中的一个或多个是基于对应于对话会话的助理查询的先前对话会话的先前助理查询在先生成的,并且/或者基于LLM输出中的一个或多个是针对对应于对话会话的上下文的先前对话会话的先前上下文在先生成的,识别使用LLM模型在先生成的LLM输出中的一个或多个;以及使得利用LLM输出中的一个或多个来修改助理输出集合以确定修改的助理输出集合。在那些实施方式的一些另外的版本中,识别使用LLM模型在先生成的LLM输出中的一个或多个可以包括:识别一个或多个LLM输出中的反映多个相异个性中的第一个性的一个或多个第一LLM输出。修改的助理输出集合包括反映第一个性的一个或多个第一个性助理输出。在那些实施方式的进一步版本中,识别使用LLM模型在先生成的LLM输出中的一个或多个可以包括:识别一个或多个LLM输出中的反映多个相异个性中的第二个性的一个或多个第二LLM输出。修改的助理输出集合可以包括反映第二个性的一个或多个第二个性助理输出,并且第二个性可以不同于第一个性。在那些实施方式的另外的附加或替选版本中,该方法还可以包括:基于ASR输出包括与先前对话会话的先前助理查询的一个或多个词项相对应的助理查询的一个或多个词项,确定先前对话会话的先前助理查询对应于对话会话的助理查询。在这些实施方式的另外的附加或替选版本中,该方法还可以包括:基于ASR输出中对应于助理查询的一个或多个词项,生成助理查询的嵌入;以及基于将助理查询的嵌入与先前对话会话的先前助理查询的在先生成的嵌入相比较,确定先前对话会话的先前助理查询对应于对话会话的助理查询。在这些实施方式的另外的附加或替选版本中,该方法还可以包括:基于对话会话的一个或多个上下文信号对应于先前对话会话的一个或多个上下文信号,确定先前对话会话的先前上下文对应于对话会话的上下文。在那些实施方式的另外的其他版本中,一个或多个上下文信号可以包括以下中的一个或多个:一天中的时间、一周中的一天、客户端设备的位置、客户端设备的环境中的环境噪声。在这些实施方式的另外的附加或替选版本中,该方法还可以包括:基于对话会话的上下文信号来生成对话会话的上下文的嵌入;以及基于将一个或多个上下文信号的嵌入与先前对话会话的先前上下文的在先生成的嵌入相比较,确定先前对话会话的先前上下文对应于对话会话的上下文。
在那些实施方式的一些版本中,处理助理输出集合和对话会话的上下文以基于对话会话的上下文的至少一部分和助理查询的至少一部分来生成与口述话语相关的附加助理查询可以包括:基于NLU输出来确定与口述话语中包括的助理查询相关联的意图;基于与口述话语中包括的助理查询相关联的意图,识别与与口述话语中包括的助理查询相关联的意图相关的至少一个相关意图;以及基于至少一个相关意图来生成与口述话语相关的附加助理查询。在那些实施方式的一些另外的版本中,基于附加助理查询来确定响应于附加助理查询的附加助理输出可以包括:使得附加助理查询经由应用编程接口(API)被传输到一个或多个第一方系统,以生成响应于附加助理查询的附加助理输出。在那些实施方式的一些附加或替选的进一步版本中,基于附加助理查询来确定响应于附加助理查询的附加助理输出可以包括:使得附加助理查询通过一个或多个网络被传输到一个或多个第三方系统;以及响应于附加助理查询被传输到第三方系统中的一个或多个,接收响应于附加助理查询的附加助理输出。在那些实施方式的一些附加或替选的进一步版本中,使用利用LLM确定的LLM输出中的一个或多个或者附加LLM输出中的一个或多个来处理附加助理输出和对话会话的上下文以生成附加的修改的助理输出集合可以包括:使用LLM处理附加助理输出集合和对话会话的上下文,以确定附加LLM输出中的一个或多个;以及基于附加LLM输出中的一个或多个来确定附加的修改的助理输出集合。在那些实施方式的一些附加或替选的进一步版本中,使用利用LLM确定的LLM输出中的一个或多个或者附加LLM输出中的一个或多个来处理附加助理输出和对话会话的上下文以生成附加的修改的助理输出集合可以包括:基于附加LLM输出中的一个或多个是基于对应于对话会话的附加助理查询的先前对话会话的先前助理查询在先生成的,并且/或者基于附加LLM输出中的一个或多个是针对对应于对话会话的上下文的先前对话会话的先前上下文在先生成的,识别使用LLM模型在先生成的附加LLM输出中的一个或多个;以及使得利用附加LLM输出中的一个或多个来修改附加助理输出集合以生成附加的修改的助理输出集合。
在一些实施方式中,该方法还可以包括:基于一个或多个排名准则对助理输出的超集进行排名,助理输出的超集至少包括助理输出集合和修改的助理输出集合;以及基于排名,从修改的助理输出集合中选择给定的修改的助理输出。在那些实施方式的一些版本中,该方法还可以包括:基于排名准则的一个或多个对附加助理输出的超集进行排名,助理输出的超集至少包括附加助理输出和附加的修改的助理输出集合;以及基于排名,从附加的修改的助理输出集合中选择给定的附加的修改的助理输出。在那些实施方式的一些另外的版本中,使得给定的修改的助理输出和给定的附加的修改的助理输出被提供以呈现给用户可以包括:将给定的修改的助理输出和给定的附加的修改的助理输出进行组合;使用文本转语音(TTS)模型处理给定的修改的助理输出和给定的附加的修改的助理输出以生成合成语音音频数据,合成语音音频数据包括捕获给定的修改的助理输出和给定的附加的修改的助理输出的合成语音;以及使得合成语音音频数据被可听地渲染以经由客户端设备的扬声器呈现给用户。
在一些实施方式中,该方法还可以包括:基于一个或多个排名准则对助理输出的超集进行排名,助理输出的超集包括助理输出集合、修改的助理输出集合、附加助理输出集合以及附加的修改的助理输出集合;以及基于排名,从修改的助理输出集合中选择给定的修改的助理输出,并且从附加的修改的助理输出集合中选择给定的附加的修改的助理输出。在那些实施方式的一些另外的版本中,使得给定的修改的助理输出和给定的附加的修改的助理输出被提供以呈现给用户可以包括:使用文本转语音(TTS)模型处理给定的修改的助理输出和给定的附加的修改的助理输出以生成合成语音音频数据,合成语音音频数据包括捕获给定的修改的助理输出和给定的附加的修改的助理输出的合成语音;以及使得合成语音音频数据被可听地渲染以经由客户端设备的扬声器呈现给用户。
在一些实施方式中,使用LLM输出中的一个或多个生成修改的助理输出集合可以还基于处理包括在口述话语中的助理查询的至少一部分。
在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:作为客户端设备的用户和由客户端设备实现的自动化助理之间的对话会话的一部分:接收捕获用户的口述话语的音频数据流,音频数据流由客户端设备的一个或多个麦克风生成,并且口述话语包括助理查询;基于处理音频数据流来确定助理输出集合,该助理输出集合中的每个助理输出响应于包括在口述话语中的助理查询;处理助理输出集合和对话会话的上下文以:使用使用大型语言模型(LLM)生成的一个或多个LLM输出来生成修改的助理输出集合,一个或多个LLM输出中的每个是基于对话会话的上下文的至少一部分以及包括在助理输出集合中的助理输出中的一个或多个来确定的,以及基于对话会话的上下文的至少一部分和助理查询的至少一部分来生成与口述话语相关的附加助理查询;基于附加助理查询来确定响应于附加助理查询的附加助理输出;基于响应于附加助理查询的附加助理输出,处理修改的助理输出集合以生成附加的修改的助理输出集合;以及使得来自附加的修改的助理输出集合当中的给定的附加的修改的助理输出被提供以呈现给用户。
在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:作为客户端设备的用户和由客户端设备实现的自动化助理之间的对话会话的一部分:接收捕获用户的口述话语的音频数据流,音频数据流由客户端设备的一个或多个麦克风生成,并且口述话语包括助理查询;基于处理音频数据流来确定助理输出集合,该助理输出集合中的每个助理输出响应于包括在口述话语中的助理查询;使用利用大型语言模型(LLM)生成的一个或多个LLM输出来处理助理输出集合和对话会话的上下文以生成修改的助理输出集合,一个或多个LLM输出中的每个是基于对话会话的上下文的至少一部分以及包括在助理输出集合中的助理输出中的一个或多个来确定的。使用LLM输出中的一个或多个生成修改的助理输出集合包括:基于(i)助理输出集合,(ii)对话会话的上下文,以及(iii)一个或多个LLM输出中的反映多个相异的个性中的第一个性的一个或多个第一LLM输出,生成第一个性回复集合。该方法还包括使得来自修改的助理输出集合当中的给定的修改的助理输出被提供以呈现给用户。
在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:作为客户端设备的用户和由客户端设备实现的自动化助理之间的对话会话的一部分:接收捕获用户的口述话语的音频数据流,音频数据流由客户端设备的一个或多个麦克风生成,并且口述话语包括助理查询;基于处理音频数据流来确定助理输出集合,该助理输出集合中的每个助理输出响应于包括在口述话语中的助理查询;使用利用大型语言模型(LLM)生成的一个或多个LLM输出来处理助理输出集合和对话会话的上下文以生成修改的助理输出集合,一个或多个LLM输出中的每个是基于对话会话的上下文的至少一部分以及包括在助理输出集合中的助理输出中的一个或多个来确定的;以及使得来自修改的助理输出集合当中的给定的修改的助理输出被提供以呈现给用户。
在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:作为客户端设备的用户和由客户端设备实现的自动化助理之间的对话会话的一部分:接收捕获用户的口述话语的音频数据流,音频数据流由客户端设备的一个或多个麦克风生成,并且口述话语包括助理查询;基于处理音频数据流来确定助理输出集合,该助理输出集合中的每个助理输出响应于包括在口述话语中的助理查询;基于对口述话语的处理来确定是否修改包括在助理输出集合中的助理输出中的一个或多个;响应于确定修改包括在助理输出集合中的助理输出中的一个或多个:使用利用大型语言模型(LLM)生成的一个或多个LLM输出来处理助理输出集合和对话会话的上下文以生成修改的助理输出集合,一个或多个LLM输出中的每个是基于对话会话的上下文的至少一部分以及包括在助理输出集合中的助理输出中的一个或多个来确定的;以及使得来自修改的助理输出集合当中的给定的修改的助理输出被提供以呈现给用户。
本文公开的技术的这些和其他实施方式可以可选地包括以下特征中的一个或多个。
在一些实施方式中,基于对口述话语的处理来确定是否修改包括在助理输出集合中的助理输出中的一个或多个可以包括:使用自动语音辨识(ASR)模型处理音频数据流以生成ASR输出流;使用自然语言理解(NLU)模型处理ASR输出流以生成NLU数据流;基于NLU数据流来识别用户提供口述话语的意图;以及基于用户提供口述话语的意图来确定是否修改助理输出。
在一些实施方式中,确定是否修改包括在助理输出集合中的助理输出中的一个或多个可以还基于与修改助理输出中的一个或多个相关联的一个或多个计算成本。在那些实施方式的一些版本中,与修改助理输出中的一个或多个相关联的一个或多个计算成本可以包括以下中的一个或多个:与修改助理输出中的一个或多个相关联的电池消耗、处理器消耗、或与修改助理输出中的一个或多个相关联的等待时间。
在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:获得指向自动化助理的多个助理查询以及针对多个助理查询中的每个的对应先前对话会话的对应上下文;对于多个助理查询中的每个:使用一个或多个大型语言模型(LLM)处理多个助理查询中的给定助理查询,以生成响应于给定助理查询的对应LLM输出;以及基于给定助理查询和/或针对给定助理查询的对应先前对话会话的对应上下文,在客户端设备处能够访问的存储器中对对应LLM输出进行索引;以及在客户端设备处能够访问的存储器中对对应LLM输出进行索引之后,并且作为客户端设备的用户与由客户端设备实现的自动化助理之间的当前对话会话的一部分:接收捕获用户的口述话语的音频数据流,音频数据流由客户端设备的一个或多个麦克风生成;基于处理音频数据流,确定口述话语包括对应于给定助理查询的当前助理查询和/或口述话语是在对应于给定助理查询的对应先前对话会话的对应上下文的当前对话会话的当前上下文中接收的;以及使得自动化助理利用对应LLM输出来响应于口述话语而生成要提供以呈现给用户的助理输出。
本文公开的技术的这些和其他实施方式可以可选地包括以下特征中的一个或多个。
在一些实施方式中,指向自动化助理的多个助理查询可以已经由用户经由客户端设备在先提交。在一些实施方式中,指向自动化助理的多个助理查询可以已经由除客户端设备的用户之外的多个附加用户经由相应客户端设备在先提交。
在一些实施方式中,在客户端设备处能够访问的存储器中对对应LLM输出进行索引可以基于在处理给定助理查询时生成的给定助理查询的嵌入。在一些实施方式中,在客户端设备处能够访问的存储器中对对应LLM输出进行索引可以基于在处理给定助理查询时生成的给定助理查询中包括的一个或多个词项或短语。在一些实施方式中,在客户端设备处能够访问的存储器中对对应LLM输出进行索引可以基于针对给定助理查询的对应先前对话会话的对应上下文的嵌入。在一些实施方式中,在客户端设备处能够访问的存储器中对对应LLM输出进行索引可以基于包括在针对给定助理查询的对应先前对话会话的对应上下文中的一个或多个上下文信号。
另外,一些实施方式包括一个或多个计算设备的一个或多个处理器(例如,中央处理单元(CPU)、图形处理单元(GPU)和/或张量处理单元(TPU)),其中,一个或多个处理器可操作以执行存储在相关联的存储器中的指令,并且其中,该指令被配置为使得执行前述方法中的任一个。一些实施方式还包括一个或多个非暂时性计算机可读存储介质,其存储可由一个或多个处理器执行以执行前述方法中的任一个的计算机指令。一些实施方式还包括一种计算机程序产品,该计算机程序产品包括可由一个或多个处理器执行以执行前述方法中的任一个的指令。
- 用于响应于来自用户的请求而使用来自其它源的应用数据生成应用输入内容的自动化助理
- 直接从对话历史和资源中生成自动化助理响应和/或动作