一种复杂环境下生猪连续咳嗽声音识别方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及语音信号处理技术领域,特别是涉及一种复杂环境下生猪连续咳嗽声音识别方法。
背景技术
生猪呼吸道疾病是制约生猪养殖行业发展的主要原因之一。近年来研究表明,生猪咳嗽声音监测是实现呼吸道疾病预警的一种有效手段,且对于单咳和连咳的监测对生猪疾病预警与诊断具有重要的意义。已有研究主要集中在孤立词识别方法上,主要方法包括特征选择、特征融合、分类器优化和分类器融合等,以此来提升分类性能。但这些方法无法实现连续声音中咳嗽的检测,且已有研究缺乏对连咳的识别。同时,已有研究对实际猪舍环境的复杂性考虑较少。
专利ZL202211128776.2公开了一种基于改进DS证据理论多分类器融合的猪咳嗽声识别方法,包括:收集猪舍内生猪的声音片段,获得语料库;基于语料库,得到训练集和测试集,提取训练集和测试集中的多个声学特征;将训练集中的多个声学特征输入至若干基分类器中,输出得到若干基分类器性能评价指标;根据基分类器性能评价指标,筛选基分类器,得到优选基分类器;利用训练集训练优选基分类器,完成目标训练模型;将测试集输入目标训练模型,并采用改进的DS证据理论对优选基分类器的输出结果进行融合,完成猪咳嗽声音识别。该发明只是对单个咳嗽声进行识别,缺少对连咳的识别。
专利ZL202210938605.X公开了一种基于分类器融合的生猪咳嗽声音识别方法,包括:收集猪舍内生猪的声音片段,获得语料库;对语料库进行标注,获得咳嗽声音片段与非咳嗽声音片段;基于咳嗽声音片段与非咳嗽声音片段按照一定比例划分为训练集和测试集,提取训练集中声音信号的声学特征和图像特征;构建支持向量机训练模型,将声学特征和图像特征输入支持向量机训练模型进行模型训练,获得目标训练模型;将测试集的数据输入目标训练模型进行分类,获得分类结果,完成猪咳嗽声音的识别。该发明对单个咳嗽声进行识别,缺少对连咳的识别,同时缺少对基分类器的优化筛选。
此外,现有的猪咳嗽声识别方法例如专利CN202210004800.5,CN202210004775.0和CN201811402994.4,均对单个咳嗽声进行识别,缺少对连咳的识别,同时未充分考虑猪舍的复杂情况,导致在复杂环境下识别精度下降。因此,亟需一种复杂环境下生猪连续咳嗽声音识别方法。
发明内容
本发明的目的是针对上述技术问题,提供一种复杂环境下生猪连续咳嗽声音识别方法,实现连咳的识别,并提高复杂环境下生猪咳嗽声的识别精度。
为实现上述目的,本发明提供了如下方案:
一种复杂环境下生猪连续咳嗽声音识别方法,包括:
采集猪舍内的连续声音,基于所述连续声音构建语料库;
对所述语料库进行多重端点检测,获取单个声音段以及所述单个声音段的开始时间和结束时间;
对所述单个声音段进行分类识别,判断所述单个声音段是否为咳嗽,若为咳嗽,则基于所述单个声音段的开始时间和结束时间计算相邻咳嗽之间的时间间隔,根据所述时间间隔判断是否为连续咳嗽。
进一步地,对所述语料库进行多重端点检测之前,还包括对所述语料库进行处理的步骤,所述对所述语料库进行处理包括:
对所述语料库进行标记,然后将所述语料库划分为训练集和测试集,并对所述训练集和测试集中的连续声音进行预加重、滤波、分帧和加窗处理,以及计算所述连续声音每一帧的短时能量。
进一步地,对所述语料库进行多重端点检测,获取单个声音段以及所述单个声音段的开始时间和结束时间包括:
将所述训练集和测试集输入预设的多重端点检测模型,获取所述训练集和测试集中单个声音段以及所述单个声音段的开始时间和结束时间,其中,所述多重端点检测模型基于能量的双门限端点检测法设置动态门限构建,所述动态门限分别为:
T
T
式中,T
P
式中,P
P
P
式中,N
所述多重端点检测模型的工作过程包括:
预设所述单个声音段的最大持续时间T秒、最大检测次数M;
设置第一门限参数a
判断所述第一次端点检测结果中是否存在持续时间大于T秒的单个声音段,若不存在,则结束检测,若存在,则计算所述第一次端点检测的目标函数,并设置第二门限参数a
进一步地,对所述单个声音段进行分类识别包括:
提取所述训练集和测试集中单个声音段的声学特征和深度特征,将所述测试集中单个声音段的声学特征和深度特征输入预设的分类模型中,获取所述测试集中单个声音段的咳嗽识别结果,其中,所述分类模型通过将所述训练集中单个声音段的声学特征和深度特征输入分类器进行训练得到。
进一步地,所述声学特征包括梅尔频率倒谱系数和功率谱密度,所述深度特征为通过卷积神经网络从图像特征中提取的特征,所述图像特征包括语谱图、梅尔语谱图、常数Q变换图和梅尔频率倒谱系数矩阵图。
进一步地,将所述训练集中单个声音段的声学特征和深度特征输入分类器进行训练包括:
将所述训练集中单个声音段的声学特征和深度特征分别输入分类器,获取若干基分类器;
计算所述基分类器之间的融合评价指标,基于所述融合评价指标对所述基分类器进行优化筛选,获取优选基分类器;
对所述优选基分类器进行融合,并利用所述训练集训练所述优选基分类器,获取所述分类模型。
进一步地,计算所述基分类器之间的融合评价指标的方法为:
AD
式中,AD
进一步地,所述整体识别准确率的计算方法为:
OA=(TP+TN)/(TP+TN+FP+FN)
式中,OA为整体识别准确率,TP为咳嗽被正确识别为咳嗽的数量,TN表为非咳嗽被正确识别为非咳嗽的数量,FN为咳嗽被错误识别为非咳嗽的数量,FP为非咳嗽被错误识别为咳嗽的数量;
所述Q统计量的计算方法为:
Q_statistics
式中,Q_statistics
进一步地,基于所述融合评价指标对所述基分类器进行优化筛选,获取优选基分类器包括:
基于所述整体识别准确率对所述基分类器进行排序,根据排序结果和所述Q统计量对所述基分类器进行初步筛选,获取基分类器C
以基分类器C
分别以基分类器C
进一步地,根据所述时间间隔判断是否为连续咳嗽包括:
根据所述测试集中识别为咳嗽的单个声音段的开始时间和结束时间,计算识别为咳嗽的相邻单个声音段之间的时间间隔,若所述时间间隔小于t秒,且所述时间间隔小于t秒的连续单个声音段数量不小于s个,则判定所述连续单个声音段为连续咳嗽,否则判定为单个咳嗽。
本发明的有益效果为:
本发明提供了一种复杂环境下生猪连续咳嗽声音识别方法,首先通过多重端点检测方法对由猪舍内采集到的连续声音构成的语料库进行检测,能够解决复杂猪舍环境下活动语音检测概率低的问题;其次对由多重端点检测获取的单个声音段进行分类识别,确定为咳嗽的单个声音段,最后基于确定为咳嗽的单个声音段的开始时间和结束时间计算相邻咳嗽之间的时间间隔,根据所述时间间隔判断是否为连续咳嗽。与已有方法相比,本发明可实现连咳的识别,且明显提高了在复杂环境下生猪咳嗽声的识别精度,本申请具有更高的实际工程应用价值。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
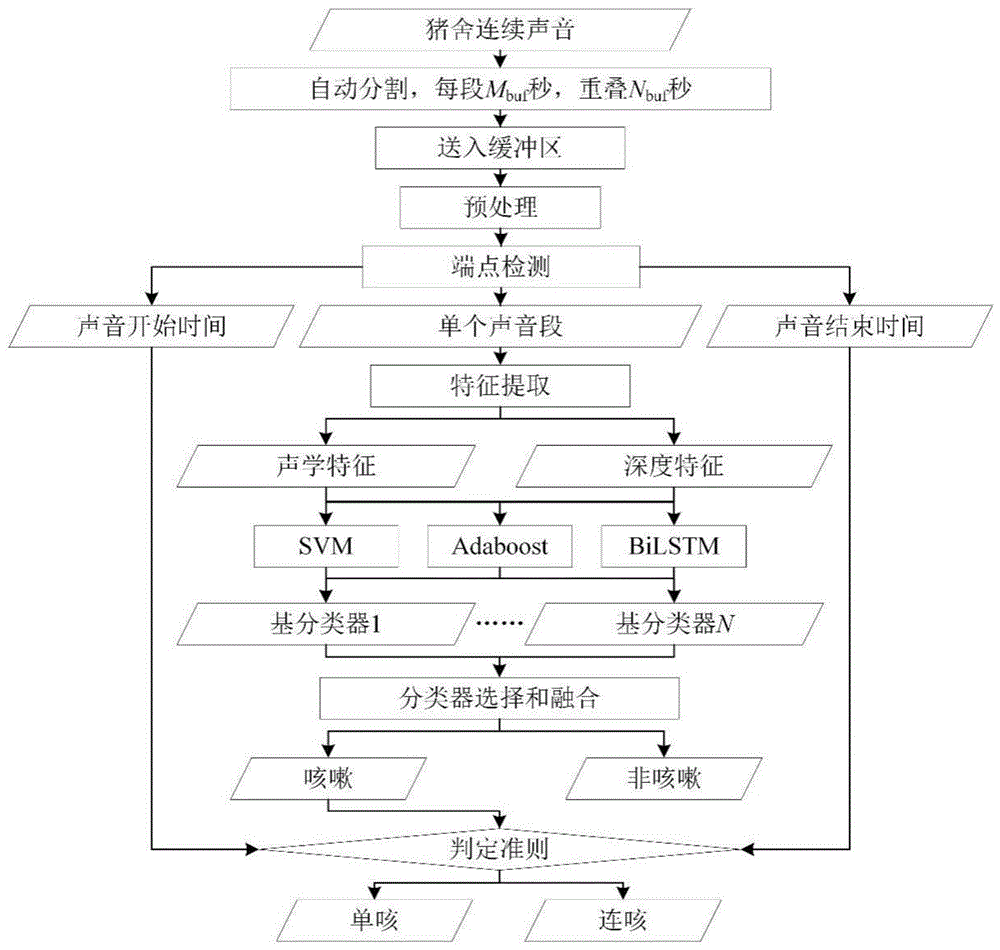
图1为本发明实施例的一种复杂环境下生猪连续咳嗽声音识别方法流程图;
图2为本发明实施例的多重端点检测算法流程图;
图3为本发明实施例的咳嗽声识别流程图;
图4为本发明实施例的分类器选择算法流程图;
图5为本发明实施例的连咳判定方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本实施例提供了一种复杂环境下生猪连续咳嗽声音识别方法,如图1所示,包括:
S1.收集实际猪舍内的连续声音,构建语料库
语料库可以反映实际猪舍的复杂性,包括两部分,第一部分是连咳片段,每段7-40秒不等,共316段,包含大量的咳嗽声和少量非咳嗽声;第二部分是在上午、下午、傍晚、夜间随机挑选的连续声音片段,每段10分钟,共25段,包含大量的非咳嗽声和少量的咳嗽声。
S2.对语料库进行处理
对语料库进行标记,然后将语料库划分为训练集和测试集。对训练集和测试集中的连续声音进行预处理,先对声音进行预加重和滤波,预加重系数为0.9375,带通滤波器频率为100Hz~16kHz,然后进行分帧,帧长为20ms,重叠长度为10ms。计算连续声音信号每一帧的短时能量。
S3.基于处理后的语料库进行多重端点检测
多重端点检测算法流程如图2所示,多重端点检测算法思想是在传统基于能量的双门限端点检测法的基础上,对实际猪舍的背景噪声和复杂情况进行分析,设置多个动态门限来分别适应复杂环境,并根据声音段的持续时间来确定是否需要进一步检测。
基于能量的双门限法需要设置两个门限:较大的门限T
T
T
式中,a和b为门限参数,通过训练集训练端点检测模型获得,训练方式为线性搜索,线性搜索时使目标函数达到最小值时即为门限参数,目标函数为:
P
式中,P
P
P
式中,N
本实施例中计算前50帧噪声帧的能量值E
由于实际猪场中的噪声环境是多变的,本实施例对E
E
式中,α表示更新速率,一般取[0.9,0.98],α越小表示更新速率越快,本实施例中α取值为0.95,端点检测得到单个声音段,以及每个声音段的开始时间和结束时间。
S4.对单个声音段进行分类,识别结果为咳嗽声或者非咳嗽声
咳嗽声识别算法流程如图3所示,首先对端点检测后的声音段进行预处理,包括预加重、滤波、分帧和加窗等,然后分别提取声学特征和深度特征。声学特征包括梅尔频率倒谱系数(MFCC)和功率谱密度(PSD);深度特征为使用微调的卷积神经网络SqueezeNet从图像特征中提取的特征,其中图像特征包括语谱图、梅尔语谱图、常数Q变换(CQT)图和MFCC矩阵图。微调的SqueezeNet采用迁移学习方法固定卷积层的参数,将输出分类数量修改为2,并用训练集中的数据训练可训练层,将训练好的SqueezeNet作为深度特征提取器提取深度特征。将不同特征分别输入SVM,Adaboost和BiLSTM分类器,得到18个基分类器,对所有基分类器按整体识别准确率从高到低排序,并根据排序结果和基于特征的多样性选择出前八个基分类器进行进一步的优化筛选,分别为:MFCC-SVM,PSD-Adaboost,MFCC-LSTM,PSD-LSTM,语谱图-SVM,梅尔语谱图-SVM,CQT图-SVM,MFCC矩阵图-SVM,将这八个分类器分别命名为C
本实施例使用整体识别准确率OA来评价基分类器的准确性,使用Q统计量Q_statistics来评价基分类器之间的多样性。整体识别准确率OA定义为:
OA=(TP+TN)/(TP+TN+FP+FN)
式中,TP表示咳嗽被正确识别为咳嗽的数量,TN表示非咳嗽被正确识别为非咳嗽的数量,FN表示咳嗽被错误识别为非咳嗽的数量,FP表示非咳嗽被错误识别为咳嗽的数量;
第i个基分类器C
Q_statistics
第i个基分类器C
AD
式中,OA
式中,OA
AD指标融合了两个基分类器的准确性和差异性,可以很好的评价基分类器融合效果,进而对基分类器融合方案进行选择。对于八个基分类器C
本实施例采用数据样本扰动的方式对选出的基分类器组合进行多样性增强,分别使用不同的数据训练多个基分类器,然后进行软投票,得到咳嗽声的识别结果。
S5.得到咳嗽与非咳嗽的判定结果后,判断咳嗽为单咳还是连咳
连咳的判定流程如图5所示,根据测试集中识别为咳嗽的单个声音段的开始时间和结束时间,计算相邻两个咳嗽之间的时间间隔,若时间间隔小于t秒,且咳嗽数量不小于s个,则判定为连咳,否则判定为单咳。本实施例中具体设置若相邻两个咳嗽之间的时间间隔小于1.5秒,且咳嗽数量不小于3,则判定这几个咳嗽组成一段连咳,否则判定为单咳。
以上所述的实施例仅是对本发明优选方式进行的描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。