由电子设备执行的方法、电子设备及存储介质
文献发布时间:2024-04-18 19:59:31
技术领域
本申请涉及人工智能技术领域,本申请涉及一种由电子设备执行的方法、电子设备及存储介质。
背景技术
随着科技的发展和人们生活水平的提高,音频检测已经被广泛应用到各种应用场景中。比如,可以用户可以通过语音方式发出指令,电子设备可以通过对用户的语音进行识别进行相应的操作。
为了更好的满足应用需求,音频信号的分类检测(如语音信号和非语音信号的检测区分)已成为音频检测领域的重要研究课题之一,虽然目前已经有不少技术可以实现音频信号的分类检测,但检测效果都不够理想,仍需改进。
发明内容
本申请实施例的目的在于提供一种能够提升音频信号检测效果的由电子设备执行的方法及电子设备。为了实现该目的,本申请实施例提供的技术方案如下:
一方面,本申请实施例提供了一种由电子设备执行的方法,该方法包括:
获取待处理的第一音频信号对应的指导特征,所述指导特征与至少一类信号的信号类型之间的可区分特征对应;
根据所述指导特征,提取所述第一音频信号对应的目标音频特征;
根据所述目标音频特征,确定所述第一音频信号所属的目标信号类型。
另一方面,本申请实施例提供了一种由电子设备执行的方法,该方法包括:
获取待处理的第一音频信号;
基于所述第一音频信号和/或第二音频信号,确定所述第一音频信号的信号检测结果,所述信号检测结果表征第一音频信号在各候选信号类型中所属的目标信号类型;
其中,所述第二音频信号是基于所述第一音频信号进行信号处理得到的,所述信号处理包括信号扩频或信号增强中的至少一项。
另一方面,本申请实施例提供了一种由电子设备执行的方法,该方法包括:获取音频采集设备采集的待处理音频信号;
基于待处理音频信号,确定待处理音频信号的信号检测结果,其中,所述待处理音频信号包括至少一帧音频信号,所述信号检测结果包括各帧音频信号的目标信号类型,一帧音频信号的目标信号类型是采用本申请实施例提供的方法确定的;
根据所述信号检测结果进行相应处理。
另一方面,本申请实施例提供了一种电子设备,该电子设备包括:
音频采集设备,用于采集音频信号;
处理器,被配置为通过执行本申请实施例提供的方法,得到所述音频采集设备采集的音频信号的信号检测结果。
可选的,所述处理器还被配置为:根据所述信号检测结果进行相应处理。
另一方面,本申请实施例还提供了一种电子设备,该电子设备包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被配置为在运行所述计算机程序时执行本申请实施例提供的方法。
另一方面,本申请实施例还提供了一种计算机可读存储介质,该存储介质中存储有计算机程序,所述计算机程序被处理器执行时执行本申请实施例提供的方法。
另一方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器运行时执行本申请实施例提供的方法,或者执行本申请实施例提供的电子设备的控制方法。
本申请实施例提供的技术方案带来的有益效果,将在下文中结合具体实施例进行介绍。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对本申请实施例描述中所需要使用的附图作简单地介绍。
图1为本申请实施例提供的一种由电子设备执行的方法的流程示意图;
图2为本申请实施例提供的多种不同类别的音频信号的示意图;
图3为本申请实施例提供的一种非语音信号的聚类结果示意图;
图4为本申请一个实施例中提供的一种由电子设备执行的方法的实现原理及流程示意图;
图5a为本申请另一个实施例提供的一种由电子设备执行的方法的实现原理及流程示意图;
图5b为本申请另一个实施例提供的一种由电子设备执行的方法的设计思路示意图;
图6为本申请实施例提供的一种信号增强网络的结构示意图;
图7为本申请实施例提供的两种音频信号的波形对比示意图;
图8为本申请实施例提供的一种信号增强网络的神经元结构示意图;
图9为本申请实施例提供的多项音频信号的频谱示意图;
图10为本申请实施例提供的一种音频信号检测效果的比对示意图;
图11为本申请实施例提供的一种由电子设备执行的方法的流程示意图;
图12为本申请实施例提供的一种由电子设备执行的方法的流程示意图;
图13为本申请实施例提供的一种由电子设备执行的方法的实现原理示意图;
图14为本申请实施例提供的一种粗粒度编码器的结构示意图;
图15为本申请实施例提供的粗分类的多种类别的音频信号的对比示意图;
图16为本申请实施例提供的两种不同类别的音频信号的特征的比对示意图;
图17为本申请实施例提供的一种细粒度编码器的结构示意图;
图18为本申请实施例提供的一种多尺度卷积网络的结构示意图;
图19为本申请实施例提供的一种注意力网络的结构示意图;
图20和图21为本申请实施例提供的一种特征提取方案的原理示意图;
图22为本申请实施例提供的一种粗粒度检测和细粒度检测相结合的信号处理方式的原理示意图;
图23为本申请实施例提供的一种由电子设备执行的方法的原理示意图;
图24为本申请实施例提供的一种电子设备的结构示意图。
具体实施方式
下面结合本申请中的附图描述本申请的实施例。应理解,下面结合附图所阐述的实施方式,是用于解释本申请实施例的技术方案的示例性描述,对本申请实施例的技术方案不构成限制。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本申请实施例所使用的术语“包括”以及“包含”是指相应特征可以实现为所呈现的特征、信息、数据、步骤、操作、元件和/或组件,但不排除实现为本技术领域所支持其他特征、信息、数据、步骤、操作、元件、组件和/或它们的组合等。应该理解,当我们称一个元件被“连接”或“耦接”到另一元件时,该一个元件可以直接连接或耦接到另一元件,也可以指该一个元件和另一元件通过中间元件建立连接关系。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的术语“和/或”指示该术语所限定的项目中的至少一个,例如“A和/或B”可以实现为“A”,或者实现为“B”,或者实现为“A和B”。在描述多个(两个或两个以上)项目时,如果没有明确限定多个项目之间的关系,这多个项目之间可以是指多个项目中的一个、多个或者全部,例如,对于“参数A包括A1、A2、A3”的描述,可以实现为参数A包括A1或A2或A3,还可以实现为参数A包括参数A1、A2、A3这三项中的至少两项。
本申请实施例提供了一种能够更好的满足实际应用需求的音频信号处理方法,基于该方法在检测音频信号的信号类型(如检测音频信号是否是语音信号)时,可以取得更好的检测效果。通过该方法,可以更加准确地检测出音频信号到底是属于哪种信号类型,如音频信号是“语音”(人说话发出的声音)还是“人体声音”即非语音(非语音类的人体声音,比如咳嗽、哼歌、震动等产生的声音)。
人体声音的检测可被广泛应用于各类场景。比如,可以应用在可穿戴设备(如蓝牙耳机)上,人体声音检测技术可以自动检测到佩戴者所处的状态以及佩戴者所处的环境,从而可以对设备进行智能控制,令用户得到极舒适的使用体验,比如,可以根据检测结果控制耳机模式的切换,例如由通透模式切换至降噪模式,或者由降噪模式切换成通透模式;再比如,还可以利用人体声音检测进行健康监测。另一方面,可穿戴设备上的人体声音可以反馈人的健康状态,如可以记录运动状态或者睡眠状态的人体数据用于给出分析报告,并且侦测到用户的生理异常并给予反馈,人体声音检测在智能健康领域也有着极富前景的应用价值。
目前的音频信号检测技术中,检测结果的准确性都有待改进,尤其是对检测精度要求较高、或信号类型的划分粒度较细时,目前的检测效果都不够准确,比如,在需要检测音信信号是“人声”还是“人体声音”的应用场景中,目前的技术中能够进一步判别“人声”到底是“语音”还是“人体声音”的方案很少,即使有些方案可以实现,但方案实现的复杂度要不过高,要不检测结果的准确度较低,仍需改进,都因为这种将人声细分的检测技术,对输入信号和检测方式的开发要求会更高,相应的对用户状态的判断也会更加准确。
本申请实施例正是为了改善现有技术所存在的问题中的至少一项,而提供了一种由电子设备执行的方法,以更好的满足实际应用需求。
下面通过对几个示例性实施方式的描述,对本申请实施例的技术方案以及本申请的技术方案产生的技术效果进行说明。需要指出的是,下述实施方式之间可以相互参考、借鉴或结合,对于不同实施方式中相同的术语、相似的特征以及相似的实施步骤等,不再重复描述。
图1示出了本申请实施例提供的一种由电子设备执行的方法的流程示意图,该方法可以由任意电子设备执行,如可以是带有音频采集设备的电子设备,也可以其他电子设备,如与音频采集设备通信连接的电子设备,如图1所示,该方法可以包括步骤S110和步骤S120。
步骤S110:获取待处理的第一音频信号;
步骤S120:基于第一音频信号和/或第二音频信号,确定第一音频信号的信号检测结果,信号检测结果表征第一音频信号在各候选信号类型中所属的目标信号类型;其中,第二音频信号是基于第一音频信号进行信号处理得到的,信号处理包括信号扩频或信号增强中的至少一项。
其中,各候选信号类型包括至少两种信号类型,对于信号类型的具体划分方式本申请实施例不做限定,可以根据实际应用需求确定。例如,在需要检测音频信号是否属于语音信号的应用场景中,候选信号类型可以包括语音信号和非语言信号两种信号类型。
本申请实施例中,第一音频信号是待处理信号,对于第一音频信号的获取方式本申请实施例不做限定,可选的,第一音频信号可以是通过体传导音频采集设备采集的音频信号,其中,体传导音频采集设备可以包括但不限于骨传导音频采集设备,如骨传导拾音器即骨传导音频采集器,相应的,第一音频信号可以是骨传导音频信号(后文可简称为骨传导信号),可选的,第一音频信号也可以是其他类型的音频采集识别采集的信号,如麦克风采集的音频信号(可称为麦克风信号)。
本申请实施例中,第二音频信号是通过对第一音频信号进行处理得到的,该处理可以是对第一音频信号进行信号增强处理或信号扩频处理中的至少一项,相对于第二音频信号,第一音频信号可以称为原始音频信号,第二音频信号是对原始音频信号对应的处理后的信号。对于实现信号增强处理或信号扩频处理的具体实现方式,本申请实施例不做限定,可选的,可以基于常用的信号增强或带宽扩频方式实现。
本申请的可选实施例中,上述第二音频信号可以包括至少一项音频信号,第二音频信号中的每项音频信号可以各自对应一种信号处理方式,其中,一种信号处理方式可以包括上述信号增强和信号扩频中的至少一项处理,比如,第二音频信号包括两项音频信号,可选的,其中一项是基于第一音频信号进行信号增强处理得到的,另一项是基于第一音频信号进行信号扩频处理得到的,或者,其中一项是基于第一音频信号进行信号增强和信号扩频处理得到的,另一项是基于第一音频信号进行信号增强处理得到的。在采用多项处理方式时,多项处理方式之间的执行顺序不同结果也可能不同,因此,采用同样的多项处理方式但多种方式执行顺序不同所得到的第二音频信号可以分别作为一项第二音频信号。
作为一可选方案,第二音频信号可以包括第四音频信号、第五音频信号、第六音频信号、第七音频信号、第八音频信号或第九音频信号中的至少一项;其中,第八音频信号是基于第一音频信号进行信号扩频处理得到的;第四音频信号是基于第一音频信号进行信号增强处理得到的;第五音频信号基于第一音频信号进行信号扩频处理,并对扩频后的音频信号进行信号增强得到的;第六音频信号基于第一音频信号进行信号增强处理,并对增强处理的音频信号进行信号扩频得到的;第七音频信号是基于所述第一音频信号进行信号扩频和信号增强处理,并滤除处理后的音频信号中的高频信息后得到的,第九音频信号是基于第一音频信号进行信号扩频和信号增强处理,并滤除处理后的音频信号中的低频信息后得到的。
通过信号扩频处理,可以实现信号频域的扩展即带宽扩展,比如,对于骨传导信号,骨传导信号的高频部分缺失严重,能量微弱,普通的外麦克信号的带宽最高频率通常可以达到8kHz,而骨传导信号通常只有1kHz以下的信号,通过带宽扩展,可以实现对骨传导信号高频部分的补充。对于语音信号和非语音信号的区分场景中,由于有些非语音信号在低频部分能够很好的与语音信号区分,有些非语音信号是在高频部分能够很好的与语音信号区分,因此,通过信号扩频处理得到的音频信号,可以有利于将低频部分与语音信号相似,但高频部分与语音信号具有区分性的非语音信号检测出来。
经过信号增强处理,可以使得信号的能量被增强,可以避免信号能量过于微弱导致无法被检测出的情况。例如,对于音频信号的低频部分(原始的骨传导信号通常只有低频部分),低频部分有效信息的能量有时会比较微弱,如果不经过增强的话,有时会很难被检出,可以会影响检测结果的准确性。
因此,通过对第一音频信号进行信号扩频或信号增强处理中的至少一项,可以更好的保证最终的检测效果。其中,对于上述第五音频信号,是基于第一音频信号先进行带宽扩展,再对带宽扩展后的信号进行信号增强,通过该方式,可以使得扩展后的信号的低频部分和高频部分都能够被增强,可以称为全频域增强信号,第七音频信号则是通过将全频域增强信号的高频部分进行去除,可以得到低频部分被有效增强后的信号。第六音频信号则是先基于原始音频信号进行信号增强,再进行信号扩展,也可以得到带宽扩展及能量增强后的信号。可选的,第一音频信号可以是体传导音频采集设备采集的音频信号,如骨传导信号,作为一可选方式,第二音频信号可以至少包括上述第五音频信号和第七音频信号。
为了更好的满足需求,本申请实施例还提供一种信号增强处理方案,其中,该方案可以包括:
将待增强的音频信号输入到信号增强网络中,得到增强后的音频信号;
其中,上述信号增强网络包括一层或多层级联的一维卷积层。
可以理解的是,信号增强网络是基于训练样本训练好的神经网络,基于本申请实施例提供的该增强网络,可以有效的实现对输入信号的增强。对于骨传导信号而言,可选的,可以先通过带宽扩展来补充骨传导信号的高频部分,然后通过信号增强网络对带宽扩展后的骨传导信号进行信号增强处理,通过该方案,可以使得增强后的信号与外麦克录入的信号尽可能相似,更有利于提升后续的检测结果。
对于增强网络的具体网络结构,本申请实施例也不做唯一限定,可以根据实际需求配置,上述卷积层可以是一层,也可以是多层。可选的,为了提高增强网络的模型性能,该增强网络可以包括至少两层级联的卷积层,至少两层卷积层中的至少两个相邻的卷积层之间可以连接有激活函数层,以增加卷积层之间的非线性关系。
对于增强网络的训练方式本申请实施例不做限定。可选的,可以基于大量的音频样本对初始的神经网络进行不断训练,直至训练次数设定次数或者是模型的训练损失收敛等,得到训练好的增强网络,其中,每个音频样本可以包括两个音频信号,可称为第一样本信号和第二样本信号,第一样本信号是需要进行增强处理的样本信号,第二样本信号是第一样本信号对应的增强处理后的信号,在训练时,可以将每个样本中的第一样本信号输入到神经网络中,通过网络处理得到增强后的信号,可以根据网络输出的该增强后的信号和第一样本信号对应的第二样本信号之间的差异,计算训练损失,并基于训练损失对神经网络的模型参数进行调整,通过不断执行上述训练过程,直至满足预先设置的训练结束条件,得到满足应用需求的增强网络,通过不断训练,可以使得网络输出的第一样本信号对应的增强后的信号,与该第一样本信号对应的第二样本信号越来越接近。
本申请实施例提供的音频信号处理方法,可以实现对音频信号的信号类型的准确判断,能够很好的满足在各种不同场景下的音频信号的检测需求。可选的,该方案可以应用于对音频信号是否是语音信号的判定场景中,其中,语音信号是指人说话产生的信号,非语音信号指的是不是人说话产生的信号,比如,“非人声”可能是由环境或者音频采集设备本身产生的声音,也可能是由于人咳嗽、哼歌或震动等产生的非语音类的人体声音。
可选的,该方法还可以包括:
滤除第一音频信号中的直流偏置,得到第三音频信号;
其中,第二音频信号是基于第三音频信号进行信号处理得到的;和/或,信号检测结果是基于第三音频信号和/或第二音频信号确定的。
也就是说,在基于第一音频信号进行信号类型检测之前,可以先对第一音频信号进行预处理,该预处理包括对第一音频信号中的直流偏置进行滤除。在对音频信号进行检测时,由于音频信号中的直流偏置会产生干扰,且很可能会在多个环节产生,比如,在基于第一音频信号得到第二音频信号时,如果进行了信号扩频即带宽扩展,在通过带宽扩展来补充信号中的高频信息、增强信号能量时,直流偏置的存在会对高频信息的恢复产生不利的影响,再比如,在通过信号增强处理对第一音频信号进行增强,并基于增强后的信号进行检测时,采用对滤除了直流偏置的第一音频信号进行信号增强得到的信号,相比于采用滤除第一音频信号中的直流偏置之前进行信号增强得到的增强信号,可以产生更加准确的检测结果,这也就是说,直流偏置也会在信号增强过程中产生干扰。
在基于音频信号通过分类模型来得到类别检测结果时,分类模型会先通过其特征提取层对输入的音频信号(信号的音频特征,如频谱特征)进行特征提取,再基于提取得到的特征来确定信号的分类结果(如语音信号或非语音信号),而直流偏置的存在还很有可能会对分类模型所提取的特征的表达能力造成不利干扰,导致所提取的特征的区分度下降,影响检测结果。
因此,为了更好的保证第一音频信号最终的信号检测结果的准确性,可以对音频信号中的直流偏置进行滤除。可选的,在基于第一音频信号得到第二音频信号时,可以是对滤除了直流偏置的第一音频信号即上述第三音频信号进行信号处理,得到第二音频信号,在基于第一音频信号确定第一检测结果时,可以是根据第三音频信号确定第一检测结果。如前文中的第四音频信号、第五音频信号、第六音频信号、第七音频信号、第八音频信号或第九音频信号中的至少一项,可以是在第三音频信号的基础上进行相应的信号处理得到的,如第四音频信号可以是对第三音频信号进行增强处理得到的。
本申请的可选实施例中,第二音频信号可以包括至少一项音频信号,每项音频信号对应一种信号处理方式;各候选信号类型包括至少两种信号类型,每种信号类型包括至少一个子类型;基于第一音频信号和/或第二音频信号,确定第一音频信号在各候选信号类型中所属的信号类型,可以包括:
基于第一音频信号确定第一检测结果,和/或,基于第二音频信号中的至少一项音频信号,确定该项音频信号对应的第二检测结果;
根据第一检测结果和/或各个第二检测结果,确定信号检测结果;
其中,一个检测结果对应一个子类型,一个检测结果表征第一音频信号是否属于对应的子类型。
本申请实施例中,每种信号类型可以包括一个或多个信号子类型,也就是说,一种信号类型可以包括一个子类型,此时的该信号类型即为一个子类型,一种信号类型也可以包括多个子类型,一种信号类型的各子类型的划分方式本申请实施例也不做限定。可选的,对于一种信号类型,可以基于属于该类型的大量样本音频信号进行聚类分析,根据音频信号的频谱特征将这些样本信号聚类为一个或多个类别,每个类别可以作为该种信号类型的一个子类型。
在实际实施时,可以基于原始音频信号及其对应的处理后的第二音频信号中至少一个音频信号的检测结果,来得到最终的信号检测结果。其中,第二检测结果可以有多个,每个第二检测结果可以是基于第二音频信号所包括的一项音频信号确定的。第一检测结果和各个第二检测结果中的每个检测结果可以对应一个子类型,根据一个检测结果可以知晓第一音频信号是否属于相对应的子类型。
在实际的很多应用场景中,由于不同类型的一些音频信号的音频特征是比较类似的,比如,某种类型的有些子类型的音频信号和其他类型(或者其他类型下的子类型)的音频信号的频谱特性是很相似的,信号检测的复杂度较高。为了降低信号检测的复杂度,并达到检测的高准确率,本申请实施例提供的该方法,通过将复杂的大问题分解为多个小问题,可以将信号类型进行进一步细分,每种信号类型细分为包括一种或多种子类型,在对第一音频信号进行检测时,可以基于第一音频信号和第二音频信号中的至少一项分别得到对应的检测结果,根据每个检测结果能够在一个子类型取得高准确率,即根据一个检测结果可以确定第一音频信号是否属于对应的子类型,从而能够提高最终的检测结果。
可选的,上述第一检测结果、第二检测结果可以是采用分类模型得到的,每个子类型可以对应各自的分类模型。
其中,上述分类模型可以是二分类模型,一个二分类模型对应一个子类型,二分类模型的检测结果表征了第一音频信号是否属于该模型对应的子类型。可选的,分类模型的数量为可以为子类型的总数量减去1。一个分类模型对应的输入信号入信号可以是第一音频信号,也可以是第二音频信号中的一项音频信号。
本申请实施例的该可选方案,通过将复杂的大问题(信号类型)分解为多个小问题(子类型),一个子类型对应一个分类模型,可使每个分类模型都能够在某一个子类型取得高准确率,保证该音频信号的最终的信号检测结果的准确性。
其中,每个分类模型可以采用各自对应的训练集对初始的二分类模型进行训练得到,一个分类模型对应的训练集中可以包括多个正样本和多个负样本,正样本是该模型对应的子类型的样本音频信号,负样本是不属于该模型对应的子类型的样本音频信号,可选的,负样本可以包括除该模型对应的子类型之外的其他各个子类型的样本音频信号,通过不断的训练,使得训练后的分类模型可以很好的区分出待检测的音频信号的信号类型是否是该模型对应的子类型,即该音频信号的信号类型是否是该子类型所属的信号类型。比如,如果一个分类模型对应的输入信号是第一音频信号,在通过训练得到该模型时,要训练的初始分类模型所对应的输入信号(即样本音频信号)也应该是原始的样本音频信号,如果一个分类模型对应的输入信号是第二音频信号,该模型对应的样本音频信号也应该对原始的样本音频信号进行过同样信号处理的信号。
上述基于第一音频信号和/或第二音频信号,确定第一音频信号的信号检测结果,可以包括以下任一项:
方式一:分别基于各项待检测音频信号,确定各项待检测音频信号的对应的检测结果,各项待检测信号包括第一音频信号和第二音频信号;
方式二:按照设定顺序,依次对各项待检测音频信号进行以下处理,直至当前待检测音频信号的检测结果表征第一音频信号的信号类型为一种候选信号类型:
基于当前待检测音频信号,确定当前待检测音频信号的检测结果。
对于上述方式一,可以对各项待检测信号都会被检测,得到对应的检测结果。比如,各个子类型对应的分类模型都会执行信号的检测,得到对应的检测结果,分类模型的输入可以是第一音频信号,也可以是第二音频信号中的任一项音频信号,在得到各个模型对应的检测结果之后,可以通过汇总多个类别检测结果确定出第一音频信号的目标信号类型。采用该方式时,可以通过多个分类模型进行信号的并行检测,即使在至少两个分类模型中的部分模型的检测结果无法确定第一音频信号的目标信号类型时,也能够并行获取到出该部分模型之外的其他分类模型的类别检测结果,加快了最终的信号检测结果的获取效率。
对于上述方式二,可以按照设定顺序确定各项待检测信号的检测结果,采用该方式时,如果某项音频信号的检测结果表明第一音频信号属于该项信号对应的子类型,那么则可以确定第一音频信号的目标信号类型是该子类型所属的信号类型,此时可以结束信号的检测。其中,上述设定顺序的具体设置方式本申请实施例不做限定,可以根据实际应用需求配置。可选的,可以按照设定顺序,依次通过各个子类型对应的分类模型确定第一音频信号的类别检测结果,直至一个分类模型的类别检测结果表征第一音频信号的信号类型为该模型对应的子类型,或者各分类模型类别检测结果都已获得。在根据某个分类模型的检测结果确定出第一音频信号是属于该模型对应的子类型时,那么则可以确定出第一音频信号所属的目标信号类型就是该子类型所属的信号类型,如果各分类模型的检测结果均表明第一音频信号不属于任一模型对应的子类型,那么可以确定第一音频信号属于除各模型对应的各个子类型之外的子类型。
以候选信号类型包括语音信号和非语音信号这两种类型为例,假设非语音信号根据信号的频谱特性可以被分为3类,那么非语音信号这种信号类型则包括3个子类型,这3个子类型都是归属于非语音这一种信号类型。在需要判别第一音频信号是否是语音信号的应用场景中,信号子类型则包括了非语音的3个子类型和1个语音的1个子类型(语音类型可以作为一个子类型,可以未进行进一步的细粒度划分)。该示例中,可选的,每个非语音子类型可以对应一个分类模型,如果通过3个分类模型的检测结果确定出第一音频信号不属于任一非语音类型,则可确定第一音频信号的目标信号类型属于语音类型。
本申请提供的上述各实施例中方案,可以应用于任何有信号类型检测的应用场景中。为了更好的理解和说明本申请的方案,下面结合一具体的检测场景,对本申请的可选实施例进行说明,该场景中信号类型可以包括语音信号和非语音信号两种。作为一个示例,图2中示出了一种细分的多种常见的非语音信号和语音信号的产生来源的示意图,如图2中所示,该示意图共展示出了音频信号的27种可能的来源,其中包括23类非语音信号的产生源和4类语音信号的产生源。图2中所示的是一种相对细粒度的划分方式,非语音的种类就有23种,但根据对这23种非语音的大量样本信号的频谱特征进行聚类发现,可以将它们聚类成如图3所示的三类,统计这三类样本信号的原始类别,可以将上述23种细粒度划分的非语音数据归纳为震动类、类咳嗽、类哼唱三大类,这三大类是相对粗粒度的划分方式,该示例中,非语音被划分为了3个子类型,每个大类为一个子类型。
在实际应用的很多场景中,都有检测音频信号是语音信号还是非语音信号的需求,本申请实施例提供的音频信号处理方法,在获取到待检测的第一音频信号之后,可以基于该音频信号和/或对其进行信号增强或扩频处理中的至少一项处理得到第二音频信号,来实现音频信号是语音信号还是非语音信号的判别。
对于检测音频信号是否是语音信号的场景中,上述第一音频信号的信号检测结果则表征第一音频信号的目标信号类型是否是语音信号。
其中,语音信号可以包括一个或多个子类型,非语音信号可以包括一个或多个子类型,两种信号中的至少一种类型包括至少两个子类型。
可选的,可以基于第一音频信号和/或第二音频信号,确定至少一个检测结果,根据该至少一个检测结果确定第一音频信号的信号检测结果。其中,一个类别检测结果对应语音信号和非语音信号这两种信号类型所包括的多个子类型中的一个子类型(不同的类别检测结果对应不同的子类型),具体可以表征第一音频信号是否属于该对应的子类型,如图3中所示的非语音信号可以分为震动类非语音、类咳嗽非语音、类哼唱非语音3个子类型,语音信号可以作为1个子类型,在该示例中,一个类别检测结果可以表征第一音频信号是否属于震动类的非语音。
可选的,上述至少一个检测结果中的各项检测结果,都可以是根据第一音频信号确定的,或者,各项检测结果也都可以是根据第二音频信号确定的,各项检测结果可以对应同一第二音频信号,也可以对应不同的第二音频信号,例如,一个检测结果是根据第三音频信号确定的,一个检测结果是根据第四音频信号确定的,再或者,上述各项检测结果中部分检测结果是根据第一音频信号确定的,部分检测结果是根据第二音频信号确定的。
为了描述方便,下面将基于第一音频信号确定的检测结果称为第一检测结果,将基于第二音频信号确定的检测结果称为第二检测结果,第一音频信号的信号检测结果可以是根据第一检测结果和/或第二检测结果确定的。
作为一可选方式,可以先基于第一音频信号和第二音频信号中的一个音频信号进行检测,得到该音频信号的检测结果a,如果该检测结果a表明原始音频信号是非语音信号(如震动类非语音),可以将该检测结果a作为最终的信号检测结果,即原始语音信号的目标信号类型是非语音信号,如果该检测结果a表征原始音频信号是不是非语音信号(如不是震动类非语音),由于非语音信号可能是各种各样的原因产生的,为了避免将某个或某些与语音信号类似的非语音信号识别为语音信号,可以再对第一音频信号或第二音频信号进行进一步检测,得到另一个检测结果b,根据检测结果b进一步确定原始音频信号是否真的是非语音信号,如果检测结果b说明原始音频信号是语音信号,则最终的信号检测结果表明原始音频信号是语音信号,如果检测结果b说明原始音频信号是非语音信号,则最终的信号检测结果表明原始音频信号是非语音信号。
在采用上述该可选方式时,可选的,可以先对第一音频信号进行检测,得到第一音频信号的第一检测结果,如果第一检测结果说明第一音频信号是非语音信号,可以无需执行对第一音频信号进行信号处理得到第二音频信号的操作,因为此时已经可以确定最终的信号检测结果是非语音信号,如果第一检测结果说明第一音频信号不是非语音信号,可以再对第一音频信号进行信号处理得到第二音频信号,对第二音频信号进行检测,根据第二检测结果进一步确定最终的信号检测结果。
当然,也可以是在获取到第一音频信号之后,既对第一音频信号进行是否是语音信号的检测,也执行获取第二音频信号的操作,采用该方式,可以在第一检测结果表明是语音信号时,能够尽快执行对第二音频信号的检测,加快最终的信号检测结果的获取效率。
由前文可知,第二音频信号可以包括一项或多项音频信号,确定第一音频信号的信号检测结果可以包括:
对于第一音频信号和/或第二音频信号中的各项音频信号,按照第二设定顺序依次对各项音频信号进行以下操作,直至当前处理的音频信号的检测结果表征第一音频信号为非语音信号或各项音频信号都已检测:
基于当前处理的音频信号,确定当前处理的音频信号的检测结果。
其中,第二设定顺序的具体设置依据本申请实施例不做限定,可以根据实验值或经验值设置。假设第二音频信号包括两项音频信号,如上述第四音频信号和第五音频信号,可以预先设置第一音频信号、第四音频信号和第五音频信号这三个新号之间的检测顺序,按照该顺序从第一个信号开始检测,如果该信号的检测结果表明第一音频信号是非语音信号,则可以无需再对后面的两个信号进行检测,如果第一个信号的检测结果表明第一音频信号是语音信号,则继续对第二个信号进行检测,直至当前被检测的信号的检测结果表明是非语音信号或者是三个信号均检测完成。
作为另一个可选实施方式,可以基于第一音频信号,确定第一检测结果,基于第二音频信号,确定第二检测结果;根据第一检测结果和第二检测结果,确定第一音频信号的检测结果。
该可选方案中,第一音频和第二音频信号检测可以没有先后顺序限定,可选的,可以并行执行,采用该方案,可以加快语音信号的检测效率。该方案中,在第一检测结果和第二检测结果都表明第一音频信号是语音信号(也就是都表明第一音频信号不是非语音信号)时,确定第一音频信号的最终检测结果是语音信号,在第一检测结果和第二检测结果中存在表征第一音频信号是非语音信号的检测结果时,确定第一音频信号的最终检测结果是非语音信号。
经本申请的发明人研究发现,语音信号和不同类型的非语音信号之间的信号差异通常是不同的,有些非语音信号和语音信号在低频上相似,而有些非语音信号和语音信号在高频上相似,从该点出发,本申请实施例提供的上述音频信号处理方法,可以基于原始音频信号和对该原始音频信号进行处理后得到的第二音频信号这两种不同的音频信号,有效避免将非语音信号判别为语音信号,可以从多种不同的维度实现对音频信号是否为语音信号的判别,提高音频信号检测的准确性,可以更好的满足实际应用需求。
需要说明的是,在基于第一音频信号和第二音频信号,确定第一音频信号的最终信号检测结果时,除了可以采用上述分别确定第一检测结果和/或第二检测结果的方式外,也可以是结合第一音频信号和第二音频信号,来确定最终的信号检测结果,比如,可以是提取第一音频信号的音频特征(如频谱特征)和第二音频信号的音频特征,并融合(如拼接)这两部分音频特征,基于融合后的特征来确定信号检测结果。由于两部分音频特征可以覆盖不同维度的信号特征,因此,基于融合后的特征也可以提高最终检测结果的准确性。
对于上述各项检测结果的确定,可以基于人工智能技术实现,因为本申请的上述场景实施例中音频信号检测是为了确定第一音频信号是否是语音信号,因此,可以将音频信号检测问题看成是分类问题,其中一个类别(信号类型)对应语音信号,另一个类别(信号类型)对应非语音信号,可以基于训练样本训练得到满足需求的二分类模型,通过二分类模型来得到音频信号的检测结果,如分类模型的预测结果可以是1或0,1表明检测结果是语音信号,0表明检测结果是非语音信号,当然,也可以是0表示非语音信号,1表示语音信号,或者模型的预测结果也可以是表明第一音频信号是语音信号的概率值和表明第一音频信号是非语音信号的概率值,两个概率值之和为0,可以将较大概率值对应的结果认为是模型预测出的检测结果。
可选的,上述基于第一音频信号和/或第二音频信号所确定的至少一个检测结果中的任一检测结果,可以是通过以下方式确定的:
基于输入信号,通过一个分类模型确定检测结果,其中,该检测结果表征第一音频信号是否是该分类模型对应的子类型。
其中,可以基于第一音频信号,通过第一分类模型,确定第一检测结果,该检测结果可以表征第一音频信号是否属于第一类型(子类型)的非语音信号;可以基于第二音频信号,通过第二分类模型,确定第二检测结果,该检测结果可以表征第一音频信号是否属于第二类型(子类型)的非语音信号。
该实施例中,至少两个分类模型则是第一分类模型和第二分类模型,可以理解的是,第一分类模型和第二分类模型是已经训练好的满足需求的分类模型。对于第一分类模型和第二分类模型的具体模型结构,本申请实施例不做限定,可以是目前常用基于任意神经网络结构的分类模型,比如,可以是基于卷积神经网络的二分类模型。第一分类模型和第二分类模型对应的初始神经网络模型(待训练的初始分类模型)的结构可以相同,也可以不同。但可以理解的是,第一分类模型的输入数据是对应第一音频信号的,第二分类模型的输入数据是对应第二音频信号的。
其中,分类模型的输入为音频信号的音频特征,第一分类模型的输入可以是第一音频信号的初始特征(如频谱特征),也可以是对第一音频信号进行预处理后的信号的初始特征,同样的,第二分类模型的输入可以是第二音频信号的初始特征,也可以是对第二音频信号进行预处理后的信号的初始特征。
作为另一可选方式,第一分类模型的输入可以是第三音频信号的初始特征,第二分类模型的输入是对第三音频信号进行信号处理后得到的第二音频信号的初始特征。
由前文的描述可知,本申请实施例中,第二音频信号可以包括一项或多项音频信号,第二音频信号的第二检测结果可以包括至少一个检测结果,其中,第二检测结果中包含的结果的数量可以与第二音频信号中所包含的音信信号的项数相等,也可以不等。可选的,可以对第二音频信号中的每一项音频信号分别进行检测,得到每一项音频信号对应的检测结果,可以基于多项音频信号来得到一个检测结果。
作为一可选方案,第二音频信号的第二检测结果可以是通过以下任一方式得到的:
方式一:分别基于第二音频信号中的各项音频信号,确定各项音频信号对应的检测结果,第二检测结果包括第二音频信号中的各项音频信号对应的检测结果;
方式二:按照第一设定顺序,依次对第二音频信号中的各项音频信号进行以下处理,直至当前处理的音频信号的检测结果表征第一音频信号为非语音信号或各项音频信号都已检测:
基于当前处理的音频信号,确定当前处理的音频信号的检测结果。
对于上述方式一,第二音频信号的检测结果的数量等于其包含的音频信号的项数。比如,第二音频信号包括上述第五音频信号(基于第一音频信号进行信号扩频处理,并对扩频后的音频信号进行信号增强得到的信号)和第七音频信号(基于第一音频信号进行信号扩频和信号增强处理,并滤除处理后的音频信号中的高频信息后得到的信号)这两项信号,对应的,第二检测结果包括第五音频信号的检测结果和第七音频信号的检测结果。
在基于多个检测结果(如第一检测结果和第二检测结果,或者多个第二检测结果),确定最终的信号检测结果时,在多个检测结果都表征第一音频信号不是非语音信号时,最终的信号检测结果确定为语音信号,如果多个检测结果的任一检测结果表明第一音频信号是非语音信号,最终的检测结果确定为非语音信号。
对于上述方式二,可以按照预先设定好的顺序,依次对第二音频信号中的各项音频信号进行检测,如果任一被检测的信号的检测结果表明第一音频信号是非语音信号,则可以结束检测过程,也就是说,只有在当前被检测的音频信号的检测结果表明第一音频信号不是非语音信号时,才需要第二音频信号的下一项音频信号继续进行检测。采用该方案,最终获取的第二检测结果包含的检测结果的数量可能等于,也可能小于第二音频信号包含的信号的项数,在第一音频信号是非语音信号时,可以有效减少要处理的信号数量。而采用上述方式一,可以在第一音频信号是语音信号时,更快的获知最终的信号检测结果。
由前文的描述可知,本申请实施例中的不同分类模型是用于区分不同的子类型的,如上述第一分类模型和第二分类模型是用于区分语音信号和不同类型的非语音信号的,不同类型的非语音信号的信号特性和语音信号的差异是不同的,因此,采用对应于不同子类型的非语音信号的多个不同的分类模型,可以更加全面的关注到各种不同类型的非语音信号和语音信号之间的信号差异性,提高最终的信号检测结果,避免将非语音识别为语音。对于非语音信号的类型的具体划分方式,本申请实施例不做限定。可选的,可以通过对大量的非语音信号样本进行聚类,将这些样本划分为多个子类型,如图3中所示的3个子类型。
本申请的可选实施例中,非语音信号可以包括多个不同的子类型的非语音信号,语音信号为一个子类型(即语音信号可以不划分不同的子类型),分类模型的数量可以等于非语音所包含的子类型的数量,多个分类模型和非语音的多个子类型一一对应。可选的,不同分类模型的输入可以不同。
作为一可选方案,最终的信号检测结果可以是根据第一检测结果和第二检测结果确定的,上述第一类型是多个子类型中的一个类型,第二类型可以包括至少一个子类型,相应的,第二分类模型可以包括与第二类型所包含的每个子类型分别对应的分类模型,可选的,第二音频信号中的每项音频信号对应一个子类型,即各第二分类模型的输入可以是各自对应的第二音频信号的特征。
本申请实施例提供的音频信号处理方法可以适用于任何需要判别信号类型的应用场景中,可以包括但不限于上述判别音频信号是否是语音信号的场景。本申请实施例提供的方案,充分利用了不同类型的信号的物理特性,和/或,同一信号类型下的不同子类型的信号与其他信号类型(或其他信号类型的子类型)的信号进行区分检测时需要关注不同频带的这种差异性,基于待处理音频信号对应的各项音频信号实现了更有针对性的检测,不同的音频信号可以关注到不同的频段信息,从而提升了检测结果的准确性。基于此,还可以将复杂的音频信号检测任务拆分为多个子任务,降低了方案实现的复杂度,也减小了模型的复杂度,可以更好的满足实际应用。
为了更好的理解和说明本申请提供的上述可选方案,下面再结合本申请的一种具体的可选实施方式对该方法进行详细说明。
本实施例中,第一音频信号是采用骨传导音频采集设备(如骨传导耳机)采集的音频信号,下面称为骨传导信号,本实施例中音频信号处理方法所依据的原始信号可以只使用骨传导信号,可以通过对骨传导信号进行带宽扩展和/或增强处理,得到增强信号(第二音频信号中的一项音频信号),下面对该实施例中的音频处理过程进行说明。
图4示出了本实施例中提供的一种音频信号处理方法的流程示意图,如图4所示,该信号处理流程通过图中所示的三子路检测器实现信号类型的检测,其中,模型1、模型2和模型3为3个二分类模型,非语音信号包括3个子类型,3个模型各自对应一个子类型,每个模型可以检测音频信号是否属于该模型对应的子类型。
图4所示的实施例中,3个分类模型对应的输入信号都是原始音频信号即骨传导信号,可选的,在进行检测时,3个分类模型可以采用级联检测流程,也就是可以按照一定顺序依次使用3个模型进行检测,直至能够确定出骨传导音频信号的信号检测结果。
如图4所示,可以先提取骨传导信号的特征,提取的特征分别作为三支路级联检测流程的输入,可以先将提取的特征输入到模型1中,如果模型1的检测结果能够确定出骨传导信号是非语音信号,也就是检测结果表征第一音频信号是模型1对应的非语音的一个子类型,则可结束检测流程,第一音频信号的目标信号类型为非语音信号。如果模型1的检测结果表征骨传导信号不是非语音信号即不是该模型对应的子类型,此时骨传导信号的信号类型不能确定,进入到下一步的检测,将提取的特征输入到模型2,根据模型的检测结果确定骨传导信号是否是非语音信号(模型2对应的子类型),如果是则结束检测流程,如果检测结果不确定,则进入下一步的检测,将提取的特征输入到模型3,如果该模型的检测结果表明表征骨传导信号是非语音信号(即检测出的信号类型是模型3对应的子类型),则确定骨传导信号的目标信号类型是非语音,如果模型3的检测结果表明骨传导信号不是非语音信号,则此时可以确定骨传导信号是语音信号。
图5a示出了本实施例中提供的另一种音频信号处理方法的流程示意图,如图5a中所示,该信号处理流程可以包括信号的带宽扩展(即扩频)和增强处理、以及基于骨传导信号和处理后的增强信号通过图中所示的三子路检测器实现信号检测两大部分。
对比图4和图5a可以看出,在图5a的实施方案的基础上,可以选择去掉带宽扩展+增强网络模块得到图4的实施方案,图4的方案可以直接使用骨传导信号进行信号检测,骨传导信号可未经过信号增强、带宽扩展等处理,检测的准确率可能会略低于图5a的方案,但图4的方案可以有效降低方案实施的复杂度,可以更好的保证方案能够在嵌入式芯片上顺利运行。在实际应用中,可以根据实际需求选择图4或图5a的方案。可选的,图4中三支路的输入特征也可以是第三音频信号的特征,即滤除了骨传导信号中的直流偏置之后的信号特征。
如图5a所示,带宽扩展是扩展骨传导信号的高频特征,增强网络是增强扩展后的骨传导信号的全频域,对信号的低频和高频均有增强作用,通过带宽扩展和信号增强可以使处理后的信号更像是正常外部麦克录制的音频信号。
可选的,图5a中的三支路检测器采用了三个不同的分类模型来覆盖不同类型的非语音信号的检测。同样的,三支路检测器也可以采用三支路级联的检测方式,即可以先通过图5a中的模型1进行检测,如果模型1的检测结果表征骨传导信号是非语音信号,即可结束检测流程,如果模型1的检测结果表征骨传导信号不是非语音信号(图中所示的不确定),则继续采用模型2进行进一步的检测,如果模型2的检测结果表征骨传导信号是非语音信号,则结束检测流程,否则继续采用模型3进行检测,得到最终的检测结果,从图中看出,如果模型1至模型3的检测结果都表明骨传导信号不是非语音信号,则确定最终的检测结果是语音信号,否则确定原始的骨传导信号是非语音信号。
本申请实施例图5a中提供的上述三支路级联检测方式,针对检测任务的目标差异性(不同类型的非语音信号和语音信号的差异不同),设计了三种特征(三个分支的输入信号不同),并分别使用三个模型进行判断,采用本申请实施例提供的该方案,可以使得多种语音和多种非语音的人体声音区分这个复杂问题被分解成三个小问题,可以使用轻量级模型在每个小问题上都取得高准确度,最后综合三个模型的分类结果,在低复杂度的框架内,得到高准确率的人体声音检测结果。下面结合图a5对整个检测流程以及该检测方式的实用价值进行详细说明。
第一部分:骨传导信号的带宽扩展和信号增强(图5a中的带宽扩展+增强网络)
相比于采用外部麦克采集到的外麦克信号,骨传导信号的特征全部来自于佩戴者本身,不受外界环境的干扰,抗噪能力强。但是骨传导和一般的声音传导方式不同,因为它是人类在说话或者做其他动作时,震动通过头骨传递到可穿戴设备并被采集到的信号,而不是通过空气传播被外部麦克采集到的音频信号,根据这种传播特性,骨传导信号中没有高频信息,音频信号能量小,听起来比较沉闷。另外,和外部麦克信号相比,骨传导信号有很强的直流偏置,使用目前经典的带宽扩展方法对骨传导信号进行处理时,直流偏置会被保留下来,在通过带宽扩展补充高频信息时会产生干扰。
为了提高检测的准确性,本申请实施例中,设计了一种专门针对骨传导信号的特点进行带宽扩展和增强的方法,该方法的设计框架包括两个部分:第一步是在经典带宽扩展方法上,添加了去除直流的模块,解决骨传导信号有直流偏置的问题;第二步是训练了一个骨传导信号增强网络,把带宽扩展后的波形再通过神经网络进行增强,得到低频信息和高频信息都被增强的波形信号,即图5a中的增强信号。其中,增强网络的输入是对骨传导信号进行第一步处理后得到的带宽扩展后的信号。
可以理解的是,在实际实施时,增强网络和带宽扩展这两步处理也可以只包含其中一步,例如,可以只包括带宽扩展步骤,将通过该步骤处理得到的信号作为第二音频信号中的一项音频信号,或者,增强网络也可以是训练好的用于对骨传导信号或者滤除直流偏置后的骨传导信号进行信号增强的网络,采用增强网络直接对骨传导信号进行增强,将增强后的信号作为第二音频信号中的一项音频信号。本实施例中,以先对骨传导信号进行带宽扩展,在对带宽扩展后的信号进行增强处理的实施方式进行说明。
作为一可选方案,图6示出了本申请实施例提供的一种实现音频信号带宽扩展和增强的结构的示意图,采用该结构对骨传导信号进行处理的流程可以包括如下几个处理过程:
(1)信号的前处理
原始信号即骨传导信号在带宽扩展之前要进行前处理,然后再进行扩展和增强。可选的,前处理模块可以包括高频噪声抑制模块和去直流模块两个部分。
高频噪声抑制模块的作用是滤除原始骨传导信号中的高频噪声。对于高频噪声抑制模块的具体实现方式本申请实施例不做限定。可选的,如图6所示,可以使用一个低通滤波器作为该模块,过滤掉原始骨传导信号中的高频噪声。
相比于外麦克信号,骨传导信号中有很强的直流偏置,如图7中所示,图7中的a图和b图示出了外麦克信号的骨传导信号的波形对比示意图,从图中可以的看出,骨传导信号中有强的直流成分,会对后续的信号检测结果造成干扰,针对该问题,本申请实施例的方案中设计了去直流处理,图6中去直流模块的作用就是滤除音频信号中的直流偏置,同样的,对于去直流模块的具体实现方式本申请实施例也不做限定。
可选的,可以使用一个高通滤波器作为该模块,去除掉骨传导信号中的直流,避免干扰到后面的带宽扩展部分。通过上述前处理,原始骨传导信号中的高频噪声和直流偏置问题得到解决,得到了干净的低频骨传导信号,该信号作为带宽扩展的输入信号。
本申请实施例还提供了另一种可选的去直流方案,该方案可以采用滑动平均方法去除原始信号即骨传导信号(可以是经过高频噪声抑制模块处理后的骨传导信号)中的直流偏置,具体方式可以是:对骨传导信号的波形信号进行采样处理,对于每个采样点x,可以先通过下述表达式(1)求其滑动平均值x_avg,然后该采样点减去其对应的滑动平均值即得到该采样点对应的去除直流后的幅值即x=x-x_avg。
x_avg=a1* x_avg + a2* x(1)
其中,表达式(1)中的x表示一个采样点的原始幅值,等式左侧的x_avg表示采样点x对应的滑动平均值,该平均值是该采样点x的幅值和时域上位于该采样点之前的各采样点的幅值的均值,等式右侧的x_avg是该采样点x的前一个采样点对应的滑动平均值,a1和a2为调节系数,可以根据需求配置,可选的,a1=0.95,a2=0.05。
(2)带宽扩展
带宽扩展的主要作用,是利用低频来填补骨传导信号缺失的高频信息其中,带宽扩展的具体实现可以是在上述前处理步骤的基础上,采用目前常用的任一实现带宽扩展的方案实现。
可选的,本申请该实施例中提供了如下的一种实现方案:
该步骤的输入信号是上述步骤(1)得到的干净的低频骨传导信号,如图6中所示,可以对该信号进行以下几步处理:
①可以使用全波整流器来扩展干净的低频骨传导信号的带宽,增加高频信息,具体方法可以是对波形信号取绝对值,即x=abs(x),其中,x表示输入信号,abs(x)表示对x取绝对值。
②可以使用一个高通滤波器移除掉扩展带宽后的信号的低频部分,只保留扩展出的高频部分。可选的,该步骤还可以将过经过高通滤波器处理后的信号进行放大(图6中的增益处理,可以将信号放到至原来的5倍),得到放大后的信号。
③将扩展出的高频部分(或者增益处理后的信号)与前处理后的骨传导信号原本的低频部分相加,生成了最终的带宽扩展信号。
作为另一可选方案,对于去除直流后的信号,还可以通过抽点复制的方式实现带宽扩展,扩展出骨传导信号缺失的高频信号,具体的,可以对去除直流后的骨传导信号进行时域采样,对于采样出的各个采样点,可以按照预设间隔(例如每隔一个采样点)选择一个采样点,然后使用所选择出的采样点替换掉与之相邻的未被选择到的采样点,例如,对骨传导信号进行采样得到的原始序列可以表示成1,2,3,4,5,6,假设每个一个采样点选择一个采样点,如被选择的采样点为1,3,5,通过抽点复制之后,原始序列就变成了1,1,3,3,5,5。
通过上述两种带宽扩展方式中的任一方式或者其他带宽扩展方式得到的带宽扩展后的骨传导信号,将被作为骨传导信号增强网络的输入。
(3)增强网络
增强网络使用骨传导信号进行数据增强,用于增强带宽扩展后的信号,可以使得得到的增强信号和外麦克录入的正常信号尽可能相似。
图6中示出了本申请实施例提供的一种增强网络的结构示意图,图8示出了该网络的各层的神经网元之间的连接关系示意图,如图6和图8所示,该增强网络包括两层1D(1维)的CNN层即卷积层,两个卷积层之间连接有一个激活函数层(图6中的激活函数Relu层),增强网络的输入是经过带宽扩展的骨传导信号,输出是增强过后与正常信号相似的信号,增强信号将被用于下一步中的人体声音检测。
第二部分:三支路级联检测器
本申请实施例提供的上述带宽扩展+增强网络和该部分的三支路级联检测流程的设计是相互配合的,目的是覆盖到不同的非语音类人体声音所关注的不同频段。本申请实施例中,针对目标所关注频段的不同,结合骨传导信号的扩展和增强方法,设计了三组特征,每组特征可以训练得到一个低复杂度的分类模型,本实施例中,将非语音类别的信号分成了三类即3个子类型,每一个模型都可以在某一类上取得高准确率。在实际实施时,可以使用级联结构将三个模型的输出融合,得到最终的检测结果。
图5b中示出了本申请的上述图5a所示的音频信号处理方法的设计思路设计图,如图中所示,通过对多种不同来源的人体声音的样本音频信号的频谱特征进行聚类分析,这些样本信号可以被划分为四类,即图中所示的人体声音的空间分布可以包括粗分的A、B、C、D这4类信号,A类的样本全是用户在非交谈状态下发出的人体声音,是典型的无谐波的非语音信号,B类的样本全是想要检测到的用户在交谈过程中说话的人声,是典型的语音类样本,而C类和D类都是语音和非语音样本的混合,具体可参见后文图15中对于这四类的具体说明。下面结合图5b和图6对图5a中的三个分支的工作原理进行说明。
·特征1和模型1对应的分支1,使用原始骨传导信号或滤除了直流偏置的骨传导信号,该分支主要关注低频部分的信息,覆盖了如触碰、摇头、运动撞击等类别的非语音类人体声音的检测。特征1是模型1的输入,该特征1是该分支的输入信号即原始骨传导信号或滤除了直流偏置的骨传导信号的音频特征,该音频特征可以包括但不限于信号的频谱特征,如可以包括输入信号的梅尔倒谱系数(MFCC,Mel-scale Frequency CepstralCoefficients)、Mel谱(即梅尔谱)或线性谱等特征中的一项或多项。
如图5b中所示,分支1可以从待处理的原始骨传导信号中提取频谱特征,该特征基本只包含1kHz下的低频特征,能够检测出骨传导信号是否是无谐波的典型非语音信号即A类(一个子类型),即通过分支1可以将典型的非语音信号区分出。
·特征2和模型2对应的分支2,使用的是带宽扩展和增强之后的骨传导信号,但是将是将该信号降采样到设定频率(如1kHz)的信号(第七音频信号),该处理删除掉了增强信号中的高频部分,只关注被增强后的低频信息,该分支可以覆盖咳嗽声和与其类似的非语音类人体声音的检测。
其中,对于删除增强信号中高频部分的具体实现方式,本申请实施例不做限定,可选的,可以通过降采样的方式将增强信号降采样到1kHz,或者也可以采用低通滤波器来过滤掉增强信号中的高频部分。
同样的,在得到滤除了高频部分的增强信号之后,可以获取该信号的音频特征即上述特征2,将音频特征输入到分类模型2中,检测出骨传导信号是否是语音信号。
如图5b中所示,如果分支1的检测结果表明骨传导信号不是典型的非语音信号,可以进入分支2继续进行检测,分支2基于低频部分被增强后的特征,可以判别出骨传导信号是否为谐波和清音混合的非语音,即是否是图15中所示的D类中的D1类型的非语音,如类咳嗽非语音,通过分支2,该类型的非语音可以被区分出。
·特征3和模型3对应的分支3,使用的是带宽扩展和增强之后的骨传导信号即图6中得到的增强信号,该分支使用的增强信号不进行降采样,高频和低频的信息同时得到关注,该分支可以覆盖和哼歌类似的非语音类人体声音的检测。通过将全频域的增强信号的音频特征即特征3输入到模型3中,可以得到分支的检测结果。
如图5b中所示,如果分支1和分支2的检测结果都表明骨传导信号不是典型的非语音信号,可以进入分支3继续进行检测,分支3可以基于包含低频和高频部分的特征,判别出骨传导信号是否横纹谐波类的非语音,即是否是图15中所示的C类中的C1类型的非语音,通过分支3,该类型的非语音可以被区分出。如果3个分支的检测结果均说明不是非语音,那么则可以确定骨传导信号是语音信号。
具体的,在采用上述3个分支进行检测时,可以先使用分支1进行检测,即获取原始(或滤除直流偏置后)的骨传导信号的音频特征,如上述一种或多种频谱特征,将该特征输入到训练好的模型1中,得到检测结果,如果该检测结果表明骨传导信号是非语音信号,检测流程可以结束,,最终的信号检测结果为非语音信号。如果分支1的检测结果不确定即表明是语音信号,进入分支2的检测流程,获取删除了高频部分的增强信号的音频特征,输入到模型2中,得到该分支的检测结果,同样,如果该检测结果表明骨传导信号是非语音信号,检测流程可以结束,最终的信号检测结果为非语音信号。如果分支2的检测结果不确定即表明是语音信号,进入分支3的检测流程,获取全频域的增强信号的音频特征并输入到模型3中,得到分支3的检测结果,此时分支3的检测结果可以作为骨传导信号最终的信号检测结果。
本申请实施例提供的上述检测方式,可以在保持高准确率的同时降低检测的复杂度,原因如下:
(1)采用上述三支路的检测方式,可以将复杂的大问题分解为三个小问题,小问题达到高准确率所需要的数据处理复杂度会大大降低。
由前文的描述可知,通过对20多种不同来源的非语音的样本信号的频谱特性进行聚类发现,这些非语音的音频信号可以被聚为三类,通过统计这三类样本信号的原始类别,可以这些非语音数据归纳为震动类、类咳嗽、类哼唱三类,通过对非语音数据的粗分类,可使得一个大问题被划分为了三个小问题,每个粗分的小问题的类别内,非语音信号的频谱有相似性,而类间有差异性。利用粗分的类别的类内相似性,可以相对容易将某一小类的非语音和语音区分开,针对这一小类问题,所需的分类模型小,可以达到的准确率就高,且模型的训练复杂度也可以有效降低。
(2)充分利用三个小问题关注的频段(频谱特征不同)不同这个信息,可以针对性的设计三组特征,可以进一步减少模型的复杂度。
由前文可知,震动类非语音、类咳嗽非语音、类哼唱非语音在检测时关注的频段不同,利用这个特点,本申请实施例的方案设计了对应三类非语音各自对应频段的特征(下面称为特征A、特征B和特征C),采用对应频段的特征训练对应的分类模型,可以减小模型的复杂度。
对于分支1的特征A:对应的是原始骨传导信号,有效频率通常只在1kHz以下,特点是几乎没有高频信息,而且低频部分的能量也较低。即使如此,低频部分的信号也足以用来区分比较常见的震动类非语音,比如身体触碰到了设备、指甲敲击在设备上、摘口罩造成的摩擦等等。震动类的非语音和语音的区分度较高,震动类非语音在低频范围内没有明显的谐波,这一点和语音信号有明显区别,因此,基于原始骨传导信号的低频特征可以实现语音信号和该类非语音信号的有效区分。
对于分支2的特征B:该特征对应的是将对原始骨传导信号进行带宽扩展和增强后,再降采样到1kHz的增强信号,该信号的特点是没高频信息,但是低频部分是被增强过,对于咳嗽或者清嗓子这类非语音来说,虽然在低频区存在和震动相似的送气音成分,但低频部分被增强之后,是可以在低频区域和语音信号区分开的。
对于分支3的特征C:该分支对应的是全频域的增强信号,既包含低频信息又包含高频信息,比如,可以通过对原始骨传导信号进行带宽扩展和增强,将信号的频域扩展到8kHz,再提取梅尔谱,将该特征作为模型3的输入特征。虽然这个过程比前两组特征要花费相对更多的计算代价,但是像哼唱和类似哼唱这种需要持续一段时间才能够被捕捉到平稳特性的非语音,通过高频区的扩展,可以更好地强调这个平稳特性,增大这类非语音信号与语音信号的区分度。
作为了示例,图9中示出了上述三种不同的特征对应的信号的对比示意图,该示例中共展示了3个样本信号,每个样本对应的横向的三个示意图由由左到右依次为原始骨传导信号、低频部分被增强的骨传导信号、以及带宽扩展及信号增强后的全频域增强信号的频谱的示意图,即每个样本的上述特征A、特征B和特征C对应的频谱示意图,由图中可以看出,原始骨传导信号只有低频部分,通过低频部分进行增强,可以使得低频部分的能量被增强,全频域增强信号的频域被扩展、且低频和高频部分都被增强。
此外,为了验证本申请实施例提供的方案的有效性,我们对上述三个分子对应的三个检测任务对三组特征的选择倾向性进行了验证,具体的,将非语音和语音的区分任务,分解成了三大类的非语音分别与语音的区分任务,将一个复杂的任务拆解成了三个子任务,经测试,每个子任务对应在三组特征的表现上都是不一样的,图10示出了测试得到的对比结果示意图,从图10中可以看出,在区分语音与震动类非语音的子任务中,特征A使用原始骨传导信号表现最佳,准确率达到94%;在区分语音与类咳嗽非语音的子任务中,特征B使用增强低频后的骨传导信号表现最佳,准确率可以达到99%;在区分语音与类哼唱非语音的子任务中,特征C使用增强全域后带高频信息的骨传导信号表现最佳,准确率达到94%。
可见,本申请实施例提供的信号检测方案,可以更加准确、有效的实现对不同类型非语音和语音的区分,避免将非语音识别为语音。再者,在基于分类模型实现信号检测时,通过复杂的检测任务拆分成多个子任务,采用多个对应不同类型的非语音信号的模型分别实现各自对应的子任务,在保证最终检测结果准确性的基础上,可以大大减少模型的模型参数。
经测试,使用上述三组特征训练出来的三个分类模型,例如,三个分类模型可以是用于分类的卷积网络CNN,三个模型的总共可以只需有6.7k个模型参数。而如果不进行任务拆分,训练得到实现语音和非语音区分的大模型,在只使用骨传导信号的情况下,达到91.1%准确率的大模型需要2427k个模型参数。如果只使用外麦克信号,达到96.3%准确率的模型,需要558k个模型参数。从模型参数上看,本申请实施例提供的上述通过设计三组特征然后将大问题拆解成三个小任务的方法,在保持准确率的情况下,大大降低了模型的复杂度,减少了计算量。
可见,本申请实施例提供的方法,可以实现低计算、低复杂度、低存储的人体声音检测架构,在应用于骨传导信号的检测时,该架构可以只使用骨传导信号作为输入,就可以实现该准确度的信号检测。
对于本申请实施例提供的各种可选实施方式中所涉及的分类模型的具体训练方式,本申请实施例不做不限定。可选的,可以基于每个分类模型对应的带有标注标签的样本信号进行训练。以图5a中所示的模型1、模型2和模型3(模型1对应于前文实施例中的第一分类模型,模型2和模型3对应前文中的第二分类模型)为例,对模型的可选训练方式进行说明。可选的,模型1、模型2和模型3对应的初始神经网络可以是同一神经网络,如用于分类的CNN。
模型1对应的训练样本集可以包括大量的第一样本,这些样本包括大量的语音信号和震动类的非语音信号,其中,哪些信号是语音信号、哪些是非语音信号都是已知的,即样本是有标签的样本,标签代表了样本的真是类别是语音信号或非语音信号。可以直接基于这些第一样本(或者是对这些样本进行前文中的前处理之后的信号)对初始的CNN进行迭代训练,即将这些样本的音频特征作为CNN的输入,通过CNN预测得到这些样本的预测结果,通过不断重复训练直至满足预设条件,得到训练好的模型1,模型1对应的训练损失可以表征这些样本的标签和模型的预测结果(即根据模型的输出确定出的信号类别是语音信号还是非语音信号)之间的差异。
模型2对应的训练样本集可以包括大量的第二样本,这些样本包括大量的语音信号和大量的类咳嗽类的非语音信号,同样的,这些样本也可是带有标注标签的。对于这些第二样本,可以通过前文中描述的前处理、带宽扩展和信号增强处理,得到各个第二样本对应的增强信号,再对每个样本对应的增强信号进行高频部分的去除,得到低频增强信号,将第二样本对应的低频增强信号作为初始的CNN的训练样本,即将这些低频增强信号的音频特征作为CNN的输入,通过CNN得到第二样本的预测结果。同样的,通过不断的训练、模型参数更新,可以得到训练好的模型2。
模型3对应的训练样本集可以包括大量的第三样本,这些样本包括大量的语音信号和大量的类哼唱类的非语音信号,可以通过前处理、带宽扩展和信号增强得到这些第三样本对应的增强信号,将这些增强信号的音频特征作为CNN的输入,对CNN不断进行训练,得到训练好的模型3。
在得到训练好的模型1、模型2和模型3之后,则可以采用图5a中所示的音频信号处理流程对待处理的音频信号进行检测。
作为一个示例,图11示出了采用训练好的三个分类模型进行多个不同的样本音频信号实现检测的原理示意图,其中,图中的模型A为模型1、模型B为模型2、模型C为模型3。该示例中有四个样本,S是语音样本即语音信号,N1是震动类样本即震动类的非语音信号,N2是咳嗽类样本即咳嗽类的非语音信号,N3是哼唱类样本。
对样本N1进行检测时,可以提取样本N1的特征A,即该样本信号的音频特征,将特征A输入到模型A中,被模型A的检测为非语音信号,可以结束对样本的检测,得到该样本最终的信号检测结果为非语音信号。如图11中所示,经过模型A的检测,样本N1就已经检测完毕。
对样本N2进行检测时,可以提取样本N2的特征A,将该特征输入到模型A中,被模型A检测为不是非语音信号,进入下一环节,对样本N2进行带宽扩展和信号增强处理,得到对应的增强信号,在去除增强信号中的高频部分,得到低频部分被增强的音频信号,提取该音频信号的音频特征B,输入到模型B中,模型B的检测结果表明是非语音信号,样本N2检测完成,最终的检测结果即为非语音信号。
对样本N3进行检测时,先提取样本N3的音频特征A输入到模型A中,被模型A检测为不是非语音,进入下一环节,对样本N3进行信号处理得到低频部分被增强后的音频信号,将该信号的音频特征B输入到模型B中,被模型B检测为不是非语音,进入下一环节,将样本N3的全频域增强信号的音频特征C输入到模型C中,被模型C检测为非语音,最后融合三个模型的检测结果,得到样本N3的最终检测结果为非语音信号。
对语音样本S进行检测时,先提取该样本的特征A输入到模型A中,被模型A检测为不是非语音,进入下一环节,获取样本S对应的低频部分被增强的信号,并提取该信号的特征B输入到模型B,被模型B检测为不是非语音,进入下一环节,获取样本S对应的全频域增强信号,提取该信号的特征C并输入到模型C中,模型C的检测结果表明样本S不是非语音信号,即三个模型的检测结果均为不是非语音信号,因此,样本S的最终检测结果为语音信号。
从该示例可以看出,基于待处理的原始音频信号,通过模型A,可以避免将震动类的非语音检测成语音,如果原始音频信号是咳嗽类或哼唱类的非语音信号,即使该信号被模型A检测为语音信号,通过模型B可以进一步判别该信号是否是咳嗽类的非语音信号,可以进一步避免将咳嗽类的非语音信号检测成语音信号,如果原始音频信号既不是震动类非语音,也不是咳嗽类非语音,即使模型A和模型B都将该信号检测成语音信号,通过模型C也可以进一步避免该误判的出现,保证了最终检测结果的准确性。
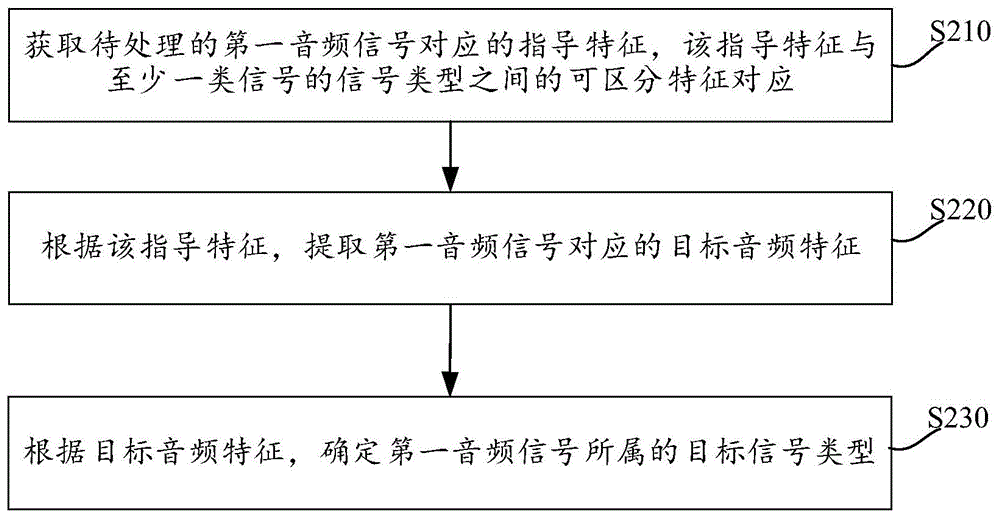
图12示出了本申请另一实施例提供的一种由电子设备执行的方法的流程示意图,如图12所示,该方法可以包括:
步骤S210:获取待处理的第一音频信号对应的指导特征,该指导特征与至少一类信号的信号类型之间的可区分特征对应;
步骤S220:根据该指导特征,提取第一音频信号对应的目标音频特征;
步骤S230:根据目标音频特征,确定第一音频信号所属的目标信号类型。
其中,每类信号可以对应至少一种信号类型,可选的,上述至少一类信号中的每类信号可以对应至少两种信号类型,即一类信号中可以包括一种或多种类型的信号。
在实际应用中,对于不同类型的音频信号,有不少情况下会存在多个音频信号虽然属于不同类型的音频信号,但是这些信号之间的频谱特性却非常相似,会被归属为一类信号,导致在进行信号类型检测时,无法高准确率的判别出这些信号真正所属的哪种类型。比如,电动牙刷产生的非语音信号和人发出“啊”的语音信号的频谱特性就比较难区分,他们都是在频谱上有平稳横向条纹谐波的音频信号,通过聚类可以发现这种类似的信号虽然属于不同的信号类型,但很可能会被聚为一类。针对上述问题,目前的音频信号检测问题无法达到较好的检测效果。
而本申请实施例提供的上述方法,在对音频信号的类型进行检测时,可以通过获取与至少一类信号的信号类型之间的可区分特征对应的指导特征,基于该指导特征包含的指导信息,能够从待处理的第一音频信号中提取得到能够具有更好的特征区分性的目标音频特征,从而可有效提高信号检测的准确性。例如,对于上述电动牙刷产生的非语音信号和人发出“啊”的语音信号,这两种类型的音频信号的频谱特征很类似,可以被归属为一类信号,上述指导特征可以与该类信号的上述两种类似的信号之前的可区分特征相对应,该指导特征中包含指导新,可以用于指导如何提取得到更加具有区分度的目标音频特征。
对于指导特征的具体获取方式,本申请实施例不做限定,可选的,指导特征可以是第一音频信号的频谱特征,也可以是通过训练好的神经网络提取得到的音频特征。
可选的,可以采用第一编码器提取第一音频信号对应的指导特征。
可选的,根据指导特征,提取第一音频信号对应的目标音频特征,可以包括:根据指导特征,采用基于第二编码器提取第一音频信号对应的目标音频特征。
其中,第一编码器和第二编码器可以是基于样本音频信号对神经网络进行训练得到的。对于编码器的网络结构本申请实施例不做限定。
作为一可选方案,上述根据指导特征,提取第一音频信号对应的目标音频特征,可以包括:
提取第一音频信号对应的初始音频特征,初始音频特征包括对应于至少一个通道的特征图;
基于指导特征,确定初始音频特征对应的权重信息,权重信息包括第一权重和第二权重中的至少一项,其中,第一权重为通道权重,第二权重为空间权重;
基于权重信息对初始音频特征进行加权修正,得到目标音频特征。
其中,初始音频特征的提取方式本申请实施例不做限定,比如,可以采用任意的特征提取网络实现,如可以采用深度神经网络。
作为本申请的一可选方案,可以通过以下方式提取得到第一音频信号的初始音频特征:
采用具有不同卷积核尺寸的至少两种特征提取网络,提取得到第一音频信号对应于各特征提取网络的音频特征;
将对应于各特征提取网络的音频特征进行融合,得到初始音频特征。
其中,上述特征提取网络的具体网络架构本申请实施例不做限定,可以根据实际需求配置,可选的,特征提取网络可以选择轻量级的特征提取网络,也就是模型参数规模较小的特征提取网络,如浅层神经网络。多种特征提取网络的卷积参数是不同的,具有不同卷积核尺寸的特征提取网络的感受野是不同的,可以关注到第一音频信号的多种不同维度(如不同频谱范围)的特征,通过融合多种不同网络提取得到的多个音频特征,可以得到具有更好的特征表达能力、隐含多样化信息的初始音频特征,其中,对多种特征提取网络的音频特征进行融合的方式可以包括但不限于特征拼接。
本申请实施例提供的上述初始音频特征的提取方式,可以使用轻量级神经网络来获取浅层特征即可实现高准确率的信号检测。可以理解的是,在实际应用中,如果不考虑神经网络的模型参数的规模,也可以采用深层神经网络提取初始音频特征。
在得到初始音频特征之后,可以基于指导特征和初始音频特征得到第一音频信号的目标音频特征。本申请的上述可选方案,提出了一种基于注意力机制的特征获取方案,采用该方案,可以基于指导特征,从通道维度和/或空间维度实现对第一音频信号对应的初始音频特征的修正,由于指导特征中包含与不同信号类型之间的区分度特征对应的特征提取指导信息,因此,修正后的目标音频特征包含对分类更有用的信息。
其中,上述第一权重为通道权重,每个通道的特征图可以对应各自的权重,各个通道的特征图中,对分类更有用的通道的特征图可以被分配到更大的权重。第二权重为空间权重,所有特征图中相同位置点的特征值对应相同的权重,也就是说第二权重可以是一张权重图,权重图的尺寸可以等于特征图的尺寸,采用第二权重对第二音频特征进行修正,可以使得特征图中对分类更有用的位置点的特征值更被关注到。因此,基于权重信息对初始音频特征进行加权修正后得到的目标音频特征,是具有了更好的信号类型区分性的特征。
可选的,根据指导特征得到初始音频特征的权重信息、以及根据权重信息得到目标音频特征的过程可以采用神经网络实现,如可以通过以下方式实现:
提取第一音频信号对应的初始音频特征;
基于指导特征和初始音频特征,采用注意力网络,得到目标音频特征;其中,注意力网络包括通道注意力网络和/或空间注意力网络。
采用通道注意力网络可以确定初始音频特征对应的通道权重,得到通道加权的音频特征,采用空间注意力网络可以确定初始音频特征对应的空间权重,得到空间加权的音频特征。
可选的,上述权重信息可以包括第一权重和第二权重,比如可以先根据初始音频特征和指导特征,采用通道注意力网络确定通道权重,并采用通道权重对初始音频特征进行通道维度的加权修正,得到修正后的特征,再基于该修正后的特征和指导特征,采用空间注意力网络确定空间权重,采用空间对该修正后的特征再次进行空间维度的加权修正,得到目标音频特征。
其中,在确定权重信息时,指导特征可以用于得到注意力机制中的查询向量(query),初始音频特征可以用于确定注意力机制中的键向量(key)和值向量(value)。可选的,可以对指导特征进行特征提取得到查询向量,可以采用两种不同或者相同的特征提取层对初始音频特征分别进行特征的提取,得到键向量和值向量,之后可以根据查询向量和键向量之间的相关性,确定权重信息,采用权重信息对值向量进行加权,基于加权后的特征得到修正后的特征。
比如,对于通道权重,可以根据查询向量和键向量,确定值向量中各个通道的特征图的权重,采用各个通道的权重对值向量中相应通道的特征图进行加权得到修正后的特征,之后可以基于该修正后的特征得到新的键向量和值向量,基于指导向量得到查询向量,再根据新的键向量和该查询向量确定新的值向量对应的权重图(即空间权重),采用该权重图分别对新的值向量中的各个特征图进行加权,得到目标音频特征。
可选的,在基于指导特征得到第一音频信号的目标音频特征之后,可以将得到的目标音频特征作为分类器的输入,根据分类器的输出可以得到第一音频信号的信号检测结果,即第一音频信号所属的目标信号类型。
本申请的可选实施例中,该方法还可以包括:
根据指导特征,确定第一音频信号的类别检测结果,该类别检测结果表征第一音频信号属于各类信号的可能性,该各类信号包括至少一个第一类信号和至少一个第二类信号,其中,上述至少一类信号为至少一个第二类信号,一个第一类信号对应一种信号类型,一个第二类信号对应至少两种信号类型;
若类别检测结果表征第一音频信号属于一个第一类信号,则将该第一类信号对应的信号类型确定为第一音频信号的目标信号类型;
上述根据所述指导特征,提取第一音频信号对应的目标音频特征,包括:
若类别检测结果表征第一音频信号不属于第一类信号,则根据指导特征,提取所述第一音频信号对应的目标音频特征。
本申请的该可选方案,提出了一种粗粒度检测和细粒度检测相结合的检测方式,粗粒度检测可以判别信号所属的类别即丧失农户类别检测结果,细粒度检测可以在粗粒度检测无法确定出信号是哪种信号类型时,再从相对第二类别对应的多个信号类型进行进一步判别,这种采用两步式不同粒度的划分方式,可使得音频信号的检测变得低复杂度且高效率。
在粗粒度检测中,第一音频信号对应的指导特征可以作为类别区分特征,可以用于确定第一音频信号属于多个信号类中各个类的可能性,也就是第一音频信号属于各类信号的可能性,这里的各类信号至少有两类,包括至少一个第一类信号和至少一个第二类信号,第一类可以理解为比较容易识别的信号类型,一个第一类只对应一种信号类型,比如可以是某种信号类型中的一个子类,第二类可以理解为比较难识别的信号类,一个第二类对应至少两种信号类型,也就是说,第二类是包含多种不同类型的信号的混合类。
由于第一类信号相对比较容易识别,与其他类的信号具有很好的区分特征,可以先根据指导特征对第一音频信号进行粗分类,如果粗分类的类别检测结果表明该第一音频信号属于一个第一类信号,而第一类信号对应一种信号类型,因此,此时即可以确定出第一音频信号所属的目标信号类型。如果粗分类的类别检测结果表明该第一音频信号不属于任一第一类信号,此时无法确定出第一音频信号的目标信号类型,需要进行进一步的细粒度检测,基于指导特征提取第一音频信号对应的更加具有区分度的目标音频特征,根据目标音频特征进一步确定出第一音频信号在至少一个第二类信号对应的各信号类型(不容易区分的信号类型)中所属的信号类型。
可选的,在根据指导特征提取第一音频信号对应的目标音频特征时,还可以使用上述类别检测结果,即可以根据指导特征和类别检测结果,提取第一音频信号对应的目标音频特征。
此时,可以将指导特征和类别检测结果作为指导特征,指导编码器提取得到更加有区分性的目标音频特征。基于粗粒度的类别检测结果即便是无法确定出第一音频信号的信号类型,该类别检测结果也是能够表征第一音频信号大致是属于各类信号中的哪一类信号的,因此,该类别检测结果也是包含了与后续的信号类型的判别有关的信息的,是可以作为细粒度检测的辅助信息的。采用该方案,指导特征和粗分类的类别检测结果可以共同作为辅助信息,用于指导编码器提取出更有利于分类的目标音频特征,进一步提高最终的检测结果。
本申请实施例中,上述各类信号中包括的第二类信号可以是一个,也可以是多个,可选的,每个第二类信号可以对应有各自的分类器(也可称为分类层),上述根据所述目标音频特征,确定所述第一音频信号所属的目标信号类型,可以包括:
根据类别检测结果,从各个第二类信号对应的分类器中确定出目标分类器;
根据目标音频特征,通过目标分类器,确定第一音频信号所属的目标信号类型。
由于粗粒度检测得到的类别检测结果是能够反映第一音频信号属于各类信号的可能性的,比如,类别检测结果可以是多个概率值,每个概率值对应各类信号中的一类信号,也就是第一音频信号是该类信号的概率,可选的,类别检测结果也可以是包含1和0两种数值的分类结果,1对应的一类信号为粗粒度检测判别出的第一音频信号所属的类。
可见,即便根据粗粒度检测得到的类别检测结果无法直接确定第一音频信号的信号类型,也可以根据该类别检测结果知晓第一音频信号应该是属于哪个第二类信号的。考虑到上述因素,本申请的该可选方案中,可以为每个第二类别分别配置相应的分类器(分类层),在基于目标音频特征进行细粒度检测时,可以根据该类别检测结果确定使用哪个第二类信号所对应的分类器,并采用该目标分类器确定第一音频信号的信号类型是第二类信号对应的多个信号类型中的哪一种。
可选的,本申请提供的该方法还可以包括:
对第一音频信号进行信号处理,得到第二音频信号,其中,信号处理包括以下至少一项:
信号扩频;信号增强;滤除信号中的直流偏置;
其中,第一音频信号对应的指导特征是基于第二音频信号得到的;和/或,目标音频特征是根据指导特征从第二音频信号中提取得到的。
关于基于第一音频信号得到第二音频信号处理的方式,可以参照前文实施例中的描述,在此不再重复。
可以理解的是,本申请上述图1中所提供的方法的各可选实施例,与图12中所示的方法的各可选实施例之间在冲突的前提下,是可以相互结合的。同样的,待处理的第一音频信号可以是骨传导信号,也可以是其他音频信号。
同样的,本申请的图12中所提供的方法的各种可选实施例,可以适用于两种或者更多种的信号类型的分类应用中,可以包括,但不限于前文中描述的语音信号和非语音信号的分类检测。
目前常用的音频信号检测多是使用空气传导信号进行检测,但是用空气传导信号检测佩戴者本人的状态会存在受到外界噪声和设备回声干扰的问题,虽然使用骨传导信号可以有效降低这种干扰的影响,但相比于空气传导信号,现有技术中使用骨传导信号进行信号检测的方案很少,这是因为骨传导信号的传播特性会使得信号丧失高频信息,降低了分类任务的区分度,会造成检测难度的上升,骨传导的原理决定了骨传导设备采集到的信号具有很大的相似性,变得难以区分和检测,现有技术无法达到高准确度的检测。
而本申请实施例提供的方法,即便只使用骨传导信号作为输入,也能够实现低复杂度、高效率、高准确率的人体声音检测。该方法可以应用于可穿戴设备上的用户状态检测,可以根据检测出的状态对设备进行自动控制或者为用户生成状态报告。下面仍以语音信号和非语音信号的分类检测为例,对本申请提供的方法的各种可选实施例进行更加详细的说明。下面的实施例描述中第一音频信号将以骨传导信号为例。
图13示出了本申请实施例提供的一种音频信号处理方案的框架结构示意图,如图13所示,该方案中可以包括粗粒度编码器、细粒度编码器和分类器几大部分,其中,粗粒度编码器可以实现粗粒度检测,细粒度编码器和分类器可以实现细粒度检测。具体的,粗粒度编码器使用骨传导信号来生成指导向量(指导特征)和粗粒度标签(类别检测结果),细粒度编码器可以根据指导向量中的指导信息从骨传导信号中提取出紧致的特征(也可以称为紧凑的特征,或者称为目标音频特征),分类器则可以预测出信号属于哪个类别,比如,是对应于用户状态是“正在说话”即交谈状态的语音,还是用户状态是“没有在说话”即非交谈状态的非语音。之后,则可以基于信号检测结果确定如何控制可穿戴设备。
可选的,图13中所示的检测方案可以完全由神经网络来实现,即实现可以完全依赖网络学习实现音频信号的处理,而无需依赖人工设定的规则。其中,粗粒度编码器、细粒度编码器和分类器三个模块可以组成一个整体,可以在训练时以端到端的形式一同被训练,也可以分模块进行训练。下面对上述各个部分的工作原理分别进行说明。
①粗粒度的编码器
粗粒度编码器可以使用可穿戴设备采集到的骨传导信号作为输入,提取出一个指导向量和一个粗粒度的分类结果(即类别检测结果,也可称为粗粒度标签)。比如,粗粒度分出四类(即前文中的信号类别有4个),如A、B、C、D。其中,B类的样本全是想要检测到的用户在交谈过程中说话,而且因为骨传导信号只保留低频部分,所以这类音频喜好的频谱特征都是谐波,是典型的语音类样本,而A类的样本全是用户在非交谈状态下发出的人体声音,C类和D类并非单一的语音和或者非语音样本,即C类和D类都对应两种信号类型,C类和D类在频谱上因为有明显的差异性所以能够被粗分成不同的类别,如果输入信号被粗粒度编码器输出到这两个类别中,是不能直接通过这个标签的结果来判断用户的状态是正在交谈还是没有交谈的,就必须进一步地进行分类,也就是进行细粒度检测。
在上述的例子里,可以把分到A类和B类的样本看成是比较容易检测出来的样本,A类和B类则是该实施例中的2个第一类信号,而C类和D类相比来说有一定难度,C类和D类则是该实施例中的2个第二类信号。
信号检测的目标是区分语音和非语音。粗粒度编码器(也可称为粗粒度模型)可以是个轻量级的模型,对于区分难度比较大的样本,由于这类样本中包含彼此非常相似的语音和非语音样本,语音和非语音不那么容易直接被粗粒度模型给区分开,需要在细粒度分区中进行进一步处理。
其中,粗粒度编码器提取出的指导向量描述了输入信号中的哪些信息有助于语音和非语音的分类,粗粒度标签包含了当前输入信号所属粗粒度类别的信息,这个类别和最终需要检测的目标不同,不受它的约束,这里的类别可以是根据骨传导信号本身频谱之间相似度进行聚类而成,例如可以对多个不同来源的样本骨传导信号的频谱进行聚类分析,得到多个粗粒度的类别,如上述A、B、C、D四类,粗粒度标签表征的则是输入信号与这四类的关系,是属于哪个类别。
图14示出了本申请实施例提供的一种粗粒度编码器的结构示意图,如图中所示,粗粒度编码器可以包括提取层和分类层两部分。其中,提取层将输入的骨传导信号转换成了指导向量,基于这一指导向量,分类层会生成一个粗粒度标签,对应于上述A、B、C、D四类的示例中,如图14所示,该粗粒度标签表征了输入的骨传导信号是这4类中的哪一类,可选的,该粗粒度标签可以是包括4个概率值的概率向量,每个概率值代表骨传导信号属于一个类别的概率。
可以理解的是,粗粒度标签一共对应多少类别,可以是根据样本信号频谱的相似度和区分度而确定的,跟实际应用需求和应用场景有关的,上述该粗粒度标签可以一共包含A、B、C、D四类的例子,只是一种可能的方案。
仍以上述将语音和非语音粗分为四类为例,图15示出了四种粗分类的语音和非语音类别的样本信号的频谱特征的对比示意图,其中,文字部分是各类别的信号的特点说明,文字下方是对应类别的样本信号的频谱特征示意图,如图15所示,A类是典型的非语音类,全部由非语音样本组成,没有语音样本,这一类样本的频谱特征是易于与语音样本区分开,没有周期性的谐波,能量在全频带分布得相对均匀;B是典型的语音类,在骨传导信号的频谱中,可以观察到典型的因为声带振动产生的周期性谐波(因为示意图的显示原因,图中该特点显示不明显,但实际是存在该特点的),该特点可以作为A区分开的典型特征;C类是类机械震动声音的样本,其频谱中包含衡条纹,谐波在时间轴上有平稳特性,这类声音既有语音类又有非语音类,比如语音中的“啊”声(图15中C2语音即C2类型的语音)和电动牙刷造成的振动声(图15中C1类型的非语音);D类是谐波和类似白噪声的清音混合在一起的样本,频谱中既能观察到类似语音特征的谐波,也能观察到能量在频带上分布均匀的类似白噪声的频谱,这类声音也是既有语音类又有非语音类,比如咳嗽声和背景中包含风噪的语音。
由图15给出的示例可以看出,粗粒度标签是可以代表输入到粗粒度编码器的音频信号的频谱特征是归属于哪一类的,包含了粗粒度类别的信息。
本申请实施例中,粗粒度的分类可以是依赖信号的频谱本身的分布特征,而不是检测任务中的标签(信号类型标签),所以即使不能从这个粗粒度的分类结果中得知输入信号到底是不是检测目标,它也可以告诉细粒度编码器这个样本(在训练时样本是用于神经网络训练的样本音频信号,在使用训练好的网络进行信号检测时,样本也就是待检测的音频信号)根据频谱特征来说大概是属于哪一类的,而指导向量则是包含着指导信息,可以用来指导细粒度编码器如何提取高层次的信息,或者说指导信息包含着细粒度编码器应该关注和提取出什么样的特征,以便这个细粒度的特征能够更有利于后面的分类器给这类难度比较高的样本进行分类。
因此,基于粗粒度编码器提取出的指导向量,在粗粒度编码器的分类结果并不能明确给出该样本是否为想要的检测目标时,例如,粗粒度的检测结果表明待检测信号是上面提到的C类或者D类时,此时是无法确定信号到底是语音还是非语音的,可以将指导向量和粗粒度的分类结果一起作为检测指导信息输入到细粒度编码器中,进一步进行特征提取和分类工作,该指导向量可以指导细粒度编码器该关注输入信号中的频谱的什么特征,可被用于引导细粒度编码器生成更加紧致的特征。
仍基于上述将语音和非语音粗分为A、B、C、D四类例子,图16中可视化的示出了指导向量对于细粒度检测的意义。如图16中所示,对于C类信号,属于该类的音频信号既有可能是语音信号,也有可能是非语音信号,比如,电动牙刷振动产生的非语音信号和人说话发出“啊”声产生的语音信号都属于该类,对比信号的第一共振峰的轨迹发现:电动牙刷振动造成的样本比“啊”样本在时间轴上更加平稳,电动牙刷振动造成的样本在时间轴上基本保持平坦,而发出“啊”产生的语音信号在时间轴上会有细微波动。对于C类信号而言,指导向量可以指导细粒度编码器关注信号的频谱中的第一共振峰的轨迹。对于D类信号,属于该类信号的音频信号同样既可能是语音信号,也有可能是非语音信号,如咳嗽声造成的音频信号和人在风中讲话产生的音频信号都属于分类,通过对比D类中的语音信号和非语音信号的频谱上方的谐波发现:咳嗽样本有一个短的弧形而在风噪中讲话的样本没有,因此可以以此区分语音和非语音,在该类中,指导向量可以指导细粒度编码器关注信号的频谱上方部分的谐波中是否存在短的弧形波峰。
本申请实施例提供的方案中,粗粒度编码器的可以采用复杂性很低的网络实现,因为它对于信号类别划分依赖于声音频谱的最原始相似性,由于这种相似性基于浅层的特征,因此可以不需要深度神经网络,经由粗粒度编码器之后,简单但常见的情况(如A类和B类信号)可以直接被解决,这样可以节省更多的计算资源来解决像C类和D类这样的难题。
②细粒度的编码器
有了粗粒度编码器提供的粗分类结果和指导向量作为辅助信息,细粒度的编码器可以也用一个轻量的模型,就可以从输入的骨传信号中提取出紧致的特征(第三音频特征)。这个紧致的特征去除了原始信号中冗余的部分,只保留对区分检测目标最有用的信息,可以和粗分类结果一起输入到后面的分类器中,粗分类结果还可以用于确定目标分类器。
作为一可选方案,图17示出来本申请实施例提供的一种细粒度编码器的结构示意图,细粒度编码器可以采用基于注意力机制的特征提取网络,可以基于粗粒度的编码器提供的指导向量,将注意力集中在骨传导信号中包含的对分类更有用的信息上,从而提取出一种尺寸更小的、包含更有助于分类的紧致的特征,即目标音频特征。
如图17所示,该细粒度编码器可以包括一个多尺度卷积网络(对应前文中的至少两种特征提取网络)和一个基于通道注意力和空间注意力的特征提取网络(通道与空间交叉注意力网络),下面对两部分特征提取网络进行介绍。
图18示出了本申请实施例提供的一种多尺度卷积网络的结构示意图,该卷积网络可以是一个轻量级的神经网络模型,可以使用多个不同尺寸的卷积核将原始骨传导信号转换成一个浅层特征(初始音频特征),可选的,该浅层特征可以是将多个采用不同尺寸的卷积核的卷积网络提取到的特征进行拼接得到的特征。细粒度编码器可以采用带有样本标签(检测标签和粗粒度标签)的样本音频信号训练得到,样本音频信号包括语音样本信号和非语音样本信号,如图18中所示的人说话发出“啊”的语音样本,检测标签是该样本的真实信号类型即语音类型,粗粒度标签代表了该样本的多个类别中属于哪一类,如“啊”的语音样本的粗粒度标签是C类。
图19示出了一种可选的通道与空间交叉注意力网络的结构示意图,该网络可以基于指导向量和粗粒度类别(即粗粒度标签)组成的特征(拼接而成的特征),以及多尺度卷积网络输出的浅层特征,使用注意力机制计算出注意力权重,并将该权重与多尺度卷积网络输出的浅层特征相乘,浅层特征中对分类更有用的部分将会被分配更大的权重,与权重相乘之后的浅层特征,作为紧致特征输出。
如图17和图19所示,粗粒度标签和指导向量的拼接特征可以作为注意力网络的查询向量即query,浅层特征可以作为注意力网络的值向量(value)和键向量(key),可选的,query可以是对拼接特征进行特征提取得到的,key和value是分别采用不同的特征提取模块浅层特征分别进行特征提取得到的。
如图19所示,通道与空间交叉注意力网络可以包括通道注意力机制和空间注意力机制,其中,通道注意力机制可以获取到浅层特征中各个通道的特征图的权重,空间注意力机制可以获取到浅层特征中各个位置点的特征值的权重。可选的,可以将浅层特征和拼接特征输入到通道注意力网络中,通道注意力网络可以分别对拼接特征和浅层特征进行特征提取,得到query、key和value,基于query和key可以得到1*1*c的权重,其中,c为浅层特征的通道数量,可以将c个通道的权重分别与value的c个通道的特征图分别进行加权,基于加权结果得到空间注意力网络的一个输入,空间注意力网络的另一个输入是拼接特征,空间注意力网络可以分别对拼接特征和通道注意力网络输出的加权后的特征进行特征提取,得到query、key和value,之后,可以对key进行通道维度的池化处理,得到H*W*1的一张特征图,其中,H和W为浅层特征中特征图的高和宽,1为通道数,根据该特征图和query可以得到H*W*1的权重图,采用该权重图可以对value中的每个通道的特征图中的各个对应位置点的特征值进行加权,得到紧致特征,也就是采用检测指导信息对初始音频特征进行通道维度和空间维度的修正后得到的目标音频特征。
本申请实施例中,在特征通道和空间上做交叉注意力的好处是:能够挑选出特征通道中对区分不同类的信号最重要的特征种类,同时关注到这个特征在空间上的分布是否存在细微的差异。作为一个示例,对于前文示例中粗分类的C类信号中的电动牙刷对应的非语音信号和“啊”声对应的语音信号,对于该类的信号,如图20和图21所示,通过多尺度卷积网络可以提取得到对应的浅层特征,该浅层特征可以包括多个通道的特征图,基于指导向量,通道注意力网络可以筛选出第一共振峰特征所在的通道,可以为该通道的特征图赋予较大的权重,基于指导向量,通过空间注意力网络,可以进一步关注到第一共振峰通道上的特征在时间轴上的平稳度,为特征图中能够用于区分C1类型和C2类型的位置点的特征值赋予更大的权重。如图21所示,如果最终得到的紧致特征表明音频信号的第一共振峰轨迹不平稳、有细微波动,那么根据该特征可以准确判别出音频信号是C1类的非语音。
基于指导向量,可以去除初始音频特征中的冗余信息,并能够增强与分类任务有关的特征,采用上述方式得到的紧致特征可以降低模型的复杂性并提高其性能。对于细粒度检测过程,语音和非语音之间的差异通常非常细微,仅与特征图上的几个特征或部分区域有关,考虑到已经从粗粒度检测步骤中获得了一些指导信息,因此在细粒度检测结果可以设计一个带有引导的紧致特征提取器,该提取器会重点关注指导信息中所强调的信息。使用引导向量来指出浅层特征中需要关注的特征,冗余信息可以被快速删除,这样,经过轻量级的特征提取网络(如几层卷积网络),就可以提取出通常只存在于深度特征中的高级信息。
综上,本申请实施例提供的上述细粒度编码器的特征提取方案,可以无需使用计算复杂度很高的深层网络的,使用轻量级网络即可获取到具有很好的区分度的紧致特征,这是因为浅层特征和指导信息会一起输入到细粒度编码器中,会编码出直接关注指导信息所需要关注到的特征,去除了冗余信息,在少量的网络参数和计算量下,就能够得到深层网络才能够提取出的特征的区分度效果,所以可以把细粒度编码器在指导信息的辅助下所生成的特征可以叫做紧致的特征。
其中,这里的紧致可以有两个解释:第一,从信号的频谱中去掉对分类无关的冗余信息,只提取出能够区分不同类型样本的特征,使得分类变得容易,紧致可以指提取出的特征只包含对分类任务最有用的信息,没有冗余;第二,这个特征提取的实现可以通过两个轻量级模型进行,其中,轻量级的粗粒度编码器可以对一些容易区分的样本直接分类,同时生成指导向量,来指导细粒度编码器在提取特征的过程中,有目的性地关注能够提升样本区分度地特征,以较小的计算成本和复杂度,挖掘出深层次的有效信息,解决难以区分开的困难样本的问题(比如在低频区域很难区分开的非语音样本和语音样本),在这里紧致指的是模型的复杂度低,只使用少量的参数和计算量就能达到深层神经网络的效果。
在通过细粒度编码器提取得到具有区分度的紧致特征之后,将该特征输入到分类器中,可以根据分类器的输出得到最终的信号检测结果。
③分类器
分类器的输入有两个,一个是从粗粒度的编码器输出的粗分类结果,另一个是从细粒度的编码器输出的紧致特征。粗分类结果会提示分类器进入到不同分支(确定目标分类器)中,比如上述示例中的C类和D类对应的分支。分类器根据不同的分支(一个分支对应一个第二类别的分类器),将紧致的特征分类成样本所属的检测目标,也就是最终的分类结果,待处理的音频信号的目标信号类型。
仍以前文中将语音和非语音粗分为A、B、C、D四类的例子进行说明,图22可视化的展示出了本申请实施例提供的采用粗粒度和细粒度结合的音频信号处理方法的原理示意图,如图22中所示,在实际应用中,根据应用场景中各种来源的人体声音样本的原始频谱特征,大量样本可以被聚类为上述4个粗分的类别,即A、B、C、D四类,在对待检测音频信号进行检测时,可以采用粗粒度编码器进行粗粒度检测,比如可以将待检测音频信号的频谱特征或者是对该频谱特征进行进一步特征提取后的特征作为指导特征,基于该指导特征可以通过粗粒度编码器的分类层(图中的粗粒度分类器)进行粗粒度检测,生成信号的粗粒度标签,也就是说,粗粒度编码器可以按照频谱特征将输入信号粗分类,打上A、B、C、D 4个标签中的一个或者是输出信号是四个标签的概率,如果粗分类的结果是A类或B类,则可以直接给出待检测音频信号是语音还是非语音的分类结果,即当粗粒度编码器的分类层确定输入信号属于A和B中的某一类时,可以直接判断出待检测音频信号属于语音或者非语音。
当粗粒度编码器的分类层判断出输入信号属于C类或者D类时,那么将会使用细分类器进行进一步分类,可以将指导向量和粗粒度标签提供给细粒度编码器,用于指导细粒度编码器将C类和D类内的语音和非语音样本的区分特征变得明显,具体的,粗粒度标签和指导向量一是可以告诉细粒度编码器这个样本频谱特征大致是什么,比如C类的是平稳的横纹谐波,D类是谐波和清音混合,还以是告诉细粒度编码器应该在骨传导信号的频谱中提取哪些信息,能够输出更紧致、有区分度的特征,增大C类或者D类之内语音样本和非语音样本的区分度,以使得后续的分类器能够更容易将它们区分开。因为有了粗粒度标签和指导向量作为提示信息进行输入指导,细粒度的编码器在区分比较困难的C类或者D类样本的时候,则可以做到轻量级模型,降低模型本身的复杂度。如图22所示,细粒度检测可以进一步区分输入信号是C类的C1类型非语音还是C2类型的语音,或者输入信号是D类中的D1类型非语音还是D2类型的语音。
如图23所示的示例中有四个样本,样本A是非人声的经典非语音类,样本B是典型的语音类,样本C是刷牙声,样本D是包含风噪的语音。
对于样本A,这一类别易于区分,故而进入粗粒度编码器后被直接判成非语音。样本B是典型的语音类,同样是易于区分的类别,进入粗颗粒度编码器后被直接判为语音。
样本C是刷牙声,属于类机械震动声音类,其频谱中包含横条纹,对于这一类别粗颗粒度编码器不能判断出其属于语音还是非语音,需要送往细颗粒度编码器,细颗粒度编码器提取出样本C的紧致特征,分类器基于该特征判断出C是非语音。样本D是包含风噪的语音,该样本属于人声与非人声混合类,对于这一类别,粗颗粒度编码器也无法判断其属于语音还是非语音,也需要送往细颗粒度编码器,细颗粒度编码器提取出D的紧致特征,经由分类器基于该特征判断出样本D是语音。
其中,不论是直接从粗粒度编码器分类出的检测目标结果,还是进一步通过细粒度编码器和分类器得到的检测目标结果,都可以根据应用需求,将检测结果应用到具体的下游任务中。可选的,在下游任务中,可以根据检测结果用于用户状态的判断,从而进行智能设备控制或者报告生成。
如图13中所示的智能控制设备的下游应用场景中,可以根据音频信号的检测结果来控制电子设备的状态,可以是根据检测结果确定用户状态再进一步根据用户状态对设备进行相应的控制。比如,信号检测需求是区分蓝牙耳机佩戴者是否在与人交谈,那么对人体声音就可以做二分类,一个是语音,一个是非语音,对应的佩戴者状态分别是交谈和非交谈,如图13中所示,在用户张嘴说“啊”、快速讲话或者低声讲话等场景下,基于采集的骨传导信号确定信号检测结果是语音信号,则可以确定佩戴者状态是交谈,对耳机的控制就是停止播放音乐或者关闭主动降噪模式,让佩戴者能够不摘耳机就和外界进行交谈;再比如,在用户在咳嗽、刷牙、哼歌或吃东西时,基于采集的骨传导信号得到的信号检测结果是非语音信号,那么佩戴者是非交谈状态,对耳机的控制就是保持音乐播放或者主动降噪功能的打开模式,让佩戴者能够自由享受个人世界。
本申请实施例提供的方法,提出了完整的音频信号解决方案,其中可以包括对输入信号进行分类,以及对分类结果进行后处理的检测工作的全流程,可选的,在实际应用中,对待检测音频信号进行实时处理时,音频信号是包括多帧信号的,可以先对待检测音信号进行分帧,对各帧信号分别进行类别检测,得到各帧的分类结果(信号检测结果),通过对各帧的分类结果进行汇总、平滑处理后,可以得到音频信号的最终处理结果,以满足下游检测任务。
需要说明的是,在本申请前文的一些实施例中,针对的检测任务都区分语音和非语音这两种信号类型,进一步,可以根据分类结果而判断设备佩戴者的状态是否与人交谈,从而对设备进行下游任务的控制,但本申请提出的解决方案同样可以区分大于两个的多种类型,应对各种以人体声音分类结果为依据而检测和追踪佩戴者状态的下游任务。本申请实施例提供的方案,可以在满足可穿戴设备对解决方案的复杂度有限制,往往不能使用这复杂度高的分类模型的需求下,解决骨传导信号样本区分度降低的问题,即便是在计算资源受限的情况下,也能够高效率、高准确度的,实现信号的分类。
其中,在使用原始骨传导信号进行信号处理的一些实施例中,可以先滤除信号中的直流偏置,使用信号增强或信号频带扩展等方式对骨传导信号进行前处理,信号增强方式可以包括传统信号增强的方法和神经网络增强中至少一项。
经测试,采用本申请实施例提供的方案,可以更加准确地实现对多种非语音信号和语音信号(包括但不限于图2中所示的语音和非语音类型)的检测,且方案的实现复杂度低,能够满足于多种场景中的音频信号检测需求,实现不同场景中可能产生的不同非语音信号和语音信号的准确识别。本申请实施例提供的方案,可以在低复杂度且不适用外麦克数据的情况下,达到高准确率的语音信号和非语音信号的检测,而且可以达到较好的泛化性能。为了证明本方案的有效性,我们从两个维度对本申请实施例提供的方案和一些其他方案进行了对比,一个维度是检测所使用的信号,包括使用了外麦克信号和不使用外麦克信号只使用骨传导信号的两种方式,另一个维度是检测方式,包括传统信号处理方式、CNN小模型检测方法、CNN大模型检测方法和本申请实施例的检测方法。评估标准对比了两个数据,一个是准确率,另一个是检测方式的复杂度,基于神经网络的检测方式的复杂度由模型参数个数描述,传统信号处理方法复杂度较低。测试结果表明,相比于其他多种方式,传统信号处理方法的准确度过低,在只使用骨传导信号作为输入进行检测时,在模型的模型参数的数据量相差不大的情况下,本申请实施例提供的方案的检测准确性明显高于其他方案,在准确性相差不大的情况下,本申请实施例提供的方案的复杂度可明显降低,模型参数的数据量要小很多。
基于本申请实施例提供的上述方案,本申请实施例还提供了一种由电子设备执行的方法,该方法可以包括:
获取音频采集设备采集的待处理音频信号;
基于待处理音频信号,确定待处理音频信号的信号检测结果,其中,待处理音频信号包括至少一帧音频信号,信号检测结果包括各帧音频信号的目标信号类型,一帧音频信号的目标信号类型是采用本申请实施例提供的方法确定的;
根据信号检测结果进行相应处理。
在实际应用中,待处理音频信号通过都是包括多帧信号的,在获取到待处理音频信号之后,可以进行分帧处理,得到该待处理音频信号包括的各帧信号,可以采用本申请实施例提供的方法对各帧信号或者各帧信号中的部分帧(如可以分帧后得到的各帧信号进行抽帧处理,只对抽出部分帧进行检测)分别进行检测,得到各帧信号的检测结果(目标信号类型),基于这些帧的检测结果,可以得到待处理音频信号的信号检测结果,比如,可以是对各帧的检测结果进行汇总,得到该信号检测结果。
可选的,该电子设备可以包括音频采集设备。该电子设备可以是可穿戴式电子设备。
可选的,上述根据信号检测结果进行相应处理,可以包括下述至少一项:
根据信号检测结果确定用户状态;
根据信号检测结果确定用户当前所处的环境;
根据信号检测结果控制电子设备。
可以理解的是,对于不同的应用需求,根据信号检测结果可以进行不同的处理,可选的,可以根据信号检测结果确定用户状态,用户状态可以包括但不限于是否是在交谈、是否在睡觉、用户的健康状态(还可以生成健康报告)或者用户的活动状态(如检测到按摩椅的声音,可以确定用户在使用按摩椅,检测到信号类型是用户刷牙的声音,可以确定用户在刷牙等)。根据信号检测结果还可以判断出用户所处的环境,如用户是否是处在噪音很大的环境中,还可以根据检测结果对用户的电子设备进行自动化控制,例如,用户在听音乐时,检测到用户在说话,可以调低音乐的播放音量或暂停播放。
在基于信号检测结果对电子设备进行自动化控制时,本公开的该方案可以由被控制额电子设备执行,也可以由与该电子设备连接的其他设备执行。其中,音频采集设备的具体类型本申请实施例不做限定,可选的,音频采集设备可以是体传导音频采集,如骨传导音频采集设备(也就是骨传音频采集器)。基于本申请提供的该控制方法,可以实现对电子设备更加精确的控制。对于该方案的应用场景本申请不做限定,理论上可以适用于任何需要基于音频检测结果对电子设备进行控制的场景中。
本申请实施例还提供了一种电子设备,该电子设备包括音处理器,处理器可以被配置为通过执行本申请实施例提供的方法,得到待处理的音频信号的信号检测结果。
可选的,该电子设备还可以包括音频采集设备,用于采集音频信号。上述待处理的音频信号可以是该电子设备的音频采集设备采集的信号。
可选的,处理器还可以用于根据该信号检测结果进行相应的操作。
本申请实施例还提供了一种电子设备,包括存储器、处理器及存储在存储器上的计算机程序,该处理器执行存储器中存储的计算机程序时可实现本申请任一可选实施例中的方法。
图24示出了本发明实施例所适用的一种电子设备的结构示意图,如图24所示,该电子设备可以为服务器或者用户终端,该电子设备可以用于实施本发明任一实施例中提供的方法。
作为一个示例,图24中示出了本申请实施例的方案所适用的一种电子设备4000的结构示意图,如图24中所示,该电子设备4000可以包括处理器4001和存储器4003。其中,处理器4001和存储器4003相连,如通过总线4002相连。可选地,电子设备4000还可以包括收发器4004。需要说明的是,实际应用中收发器4004不限于一个,该电子设备4000的结构并不构成对本申请实施例的限定。
处理器4001可以是CPU(Central Processing Unit,中央处理器),通用处理器,DSP(Digital Signal Processor,数据信号处理器),ASIC(Application SpecificIntegrated Circuit,专用集成电路),FPGA(Field Programmable Gate Array,现场可编程门阵列)或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本申请公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器4001也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,DSP和微处理器的组合等。
总线4002可包括一通路,在上述组件之间传送信息。总线4002可以是PCI(Peripheral Component Interconnect,外设部件互连标准)总线或EISA(ExtendedIndustry Standard Architecture,扩展工业标准结构)总线等。总线4002可以分为地址总线、数据总线、控制总线等。为便于表示,图24中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
存储器4003可以是ROM(Read Only Memory,只读存储器)或可存储静态信息和指令的其他类型的静态存储设备,RAM(Random Access Memory,随机存取存储器)或者可存储信息和指令的其他类型的动态存储设备,也可以是EEPROM(Electrically ErasableProgrammable Read Only Memory,电可擦可编程只读存储器)、CD-ROM(Compact DiscRead Only Memory,只读光盘)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。
存储器4003用于存储执行本申请方案的应用程序代码,并由处理器4001来控制执行。处理器4001用于执行存储器4003中存储的应用程序代码,以实现前述任一方法实施例所示的方案。
本申请实施例还提供了一种计算机可读存储介质,该存储介质上存储有计算机指令,计算机指令被处理器执行时实现本申请任一实施例所示的方法。
本申请所提供的实施例中,由电子设备执行的上述方法可以使用人工智能模型来执行。
根据本申请的实施例,在电子设备中执行的该方法可以通过使用音频信号作为人工智能模型的输入数据来获得音频信号的信号特征,可以基于人工智能模型来获取音频信号的检测结果,如分类结果。人工智能模型可以由在为人工智能模型处理指定的硬件结构中设计的人工智能专用处理器来处理。人工智能模型可以通过训练获得。这里,“通过训练获得”意味着通过训练算法用多条训练数据训练基本人工智能模型来获得被配置成执行期望特征(或目的)的预定义操作规则或人工智能模型。人工智能模型可以包括多个神经网络层。多个神经网络层中的每一层包括多个权重值,并且通过在前一层的计算结果与多个权重值之间的计算来执行神经网络计算。
本申请所提供的实施例中,可以通过AI模型来实现多个模块中的至少一个模块。可以通过非易失性存储器、易失性存储器和处理器来执行与AI相关联的功能。
该处理器可以包括一个或多个处理器。此时,该一个或多个处理器可以是通用处理器,(例如中央处理单元(CPU)、应用处理器(AP)等)、或者是纯图形处理单元(,例如,图形处理单元(GPU)、视觉处理单元(VPU)、和/或AI专用处理器(,例如,神经处理单元(NPU))。
该一个或多个处理器根据存储在非易失性存储器和易失性存储器中的预定义的操作规则或人工智能(AI)模型来控制对输入数据的处理。通过训练或学习来提供预定义的操作规则或人工智能模型。
这里,通过学习来提供指的是通过将学习算法应用于多个学习数据来得到预定义的操作规则或具有期望特性的AI模型。该学习可以在其中执行根据实施例的AI的装置本身中执行,和/或可以通过单独的服务器/系统来实现。
该AI模型可以由包含多个神经网络层组成。每一层具有多个权重值,一个层的计算是通过前一层的计算结果和当前层的多个权重来执行的。神经网络的示例包括但不限于卷积神经网络(CNN)、深度神经网络(DNN)、循环神经网络(RNN)、受限玻尔兹曼机(RBM)、深度信念网络(DBN)、双向循环深度神经网络(BRDNN)、生成对抗网络(GAN)、以及深度Q网络。
学习算法是一种使用多个学习数据训练预定目标装置(例如,机器人)以使得、允许或控制目标装置进行确定或预测的方法。该学习算法的示例包括但不限于监督学习、无监督学习、半监督学习、或强化学习。
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”、“1”、“2”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例能够以除图示或文字描述以外的顺序实施。
应该理解的是,虽然本申请实施例的流程图中通过箭头指示各个操作步骤,但是这些步骤的实施顺序并不受限于箭头所指示的顺序。除非本文中有明确的说明,否则在本申请实施例的一些实施场景中,各流程图中的实施步骤可以按照需求以其他的顺序执行。此外,各流程图中的部分或全部步骤基于实际的实施场景,可以包括多个子步骤或者多个阶段。这些子步骤或者阶段中的部分或全部可以在同一时刻被执行,这些子步骤或者阶段中的每个子步骤或者阶段也可以分别在不同的时刻被执行。在执行时刻不同的场景下,这些子步骤或者阶段的执行顺序可以根据需求灵活配置,本申请实施例对此不限制。
以上所述仅是本申请部分实施场景的可选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请的方案技术构思的前提下,采用基于本申请技术思想的其他类似实施手段,同样属于本申请实施例的保护范畴。
- 一种减少含镍低铬铁素体不锈钢铸坯横裂的方法
- 一种S32168高品质不锈钢连铸坯的生产工艺
- 一种适用于不锈钢连铸坯生产过程的连铸坯分级判定方法