一种基于变分自编码器和谱图变换的音乐生成方法
文献发布时间:2024-07-23 01:35:12
技术领域
本发明属于人工智能和自动生成的技术领域,具体涉及一种基于变分自编码器和谱图变换的音乐生成方法。
背景技术
我国音乐产业呈现稳健增长态势,其发展在推动国家整体发展中发挥着积极作用。总体而言,音乐在当代社会扮演着独特而重要的角色,已成为日常生活中不可或缺的要素之一。当代社会对音乐的需求不断增长。然而,由于多方面原因,传统的人工音乐创作方法逐渐难以满足社会对音乐不断增加的需求。在这一背景下,计算机辅助音乐生成或许将成为未来主流的作曲趋势。
为了实现音乐的自动生成,需要借助于计算机技术和人工智能技术,构建音乐生成模型。音乐生成模型是一种能够根据一定的输入条件,输出音乐作品的计算机程序。音乐生成模型需要考虑到音乐的结构、风格、语法、逻辑和美学等多个方面,以及人们的心理状态、音乐期待和偏好等多个因素。音乐生成模型的目标是生成能够满足人们心理状态和音乐期待的高质量和高效果的音乐作品。
发明内容
为解决上述问题,本发明公开了一种基于变分自编码器和谱图变换的音乐生成方法,构建了一种基于变分自编码的MelVAE模型进行音乐创作。并且提出了基于梯度的频谱反演模型,极大地提高了频谱到音频的重构质量。
为达到上述目的,本发明的技术方案如下:
一种基于变分自编码器和谱图变换的音乐生成方法,具体步骤如下:
步骤1:对音乐数据集进行预处理,计算梅尔频谱图,
预加重,通过减小这些低频成分的振幅,使得高频成分相对更为突出。
分帧,通过将信号分成小的帧,可以假设在每个帧内信号是平稳的,从而简化信号处理过程。按照标准,通常选择帧长度为25毫秒,适用于8kHz的信号,对应于200个采样点。
加窗,将帧信号乘以一个衰减的窗口,使得帧的两端逐渐减小振幅。这里窗函数选择Hamming窗。
傅里叶变换,将信号从时域转换到频域。
计算Mel滤波器组,将功率谱通过一组Mel刻度的三角滤波器来提取频带。
步骤2:对数组进行最小-最大归一化操作,将数组中的每个元素映射到[0,1]范围内;
步骤3:记录每个特征的最小和最大值,以便在需要进行反归一化时能够使用这些信息,将其保存为pkl格式文件;
步骤4:MelVAE网络训练过程具体表示为:
加载预处理得到的频谱图数据的文件路径;
创建一个空列表,用于存储加载的频谱图数据;
加载.npy文件,得到频谱图数据;
将频谱图数据添加到列表,进行格式转换,列表转换为数组;
设置轮数epochs为150,学习率为0.001以外,还要设置超参数α为100000;
编码器将频谱数据映射到潜在空间,解码器将低维表示重构回频谱数据;
计算重构误差Loss=α·RMSE+KL,其中,Loss是损失函数,RMSE是重构误差,KL是KL散度(Kullback-Leibler Divergence),α是重建损失函数的权重。KL散度可以用下列公式表示:
上式中,N(μ,σ)为当前的正态分布,N(0,1)为标准整体分布,通过计算当前的正态分布和标准正态分布之间的距离,使得当前的正态分布,不断向标准正态分布进行靠拢。
步骤5:通过反馈神经网络调整模型参数;
步骤6:存储模型参数的pkl格式文件以及权重的h5格式文件。
步骤7:加载MelVAE模型,从潜在空间中随机采样一组音乐表示编码,使用解码器将潜在空间中的采样点映射回音频频谱,调用频谱反演模型进行谱图变换,得到最后的音乐。
作为本发明进一步的改进是,所述步骤7中的频谱反演模型采用的不是经典的Griffin-Lim算法,而是基于梯度的反演算法,极大提高音频重构质量。
本发明的有益效果为:
1、本发明所使用的作曲模型采用的是基于频谱的音乐表示形式,相比于直接使用WAV格式的音乐,这种方法既减少了数据量,又更全面地捕获了音频的特征,优化了音乐创作的数据处理流程;
2、本发明所设计了基于变分自编码器的MelVAE模型,专门用于学习音乐的潜在表示并生成新颖的音乐作品;
3、本发明所提出的从相位梯度角度更精确地重建相位的方法,通过维护相位的水平和垂直一致性,显著提高了重建音频信号的质量。
附图说明
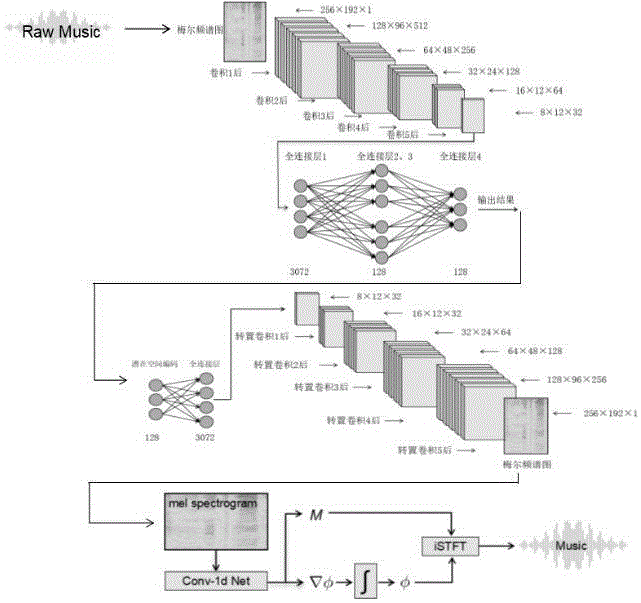
图1是表示本发明提出的作曲模型设计图;
图2是表示本发明提出的基于梯度的反演模型结构示意图;
图3、图4是表示本发明提出模型的重构实验结果;
图5是表示本发明提出模型的插值实验结果。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
作为本发明的一种具体实施实例,本发明提供了一种基于变分自编码器和谱图变换的音乐生成方法,其中作曲模型设计图如图1所示,具体步骤如下:
步骤1:对音乐数据集进行预处理,计算梅尔频谱图,
预加重,通过减小这些低频成分的振幅,使得高频成分相对更为突出,
分帧,通过将信号分成小的帧,假设在每个帧内信号是平稳的,从而简化信号处理过程,
加窗,将帧信号乘以一个衰减的窗口,使得帧的两端逐渐减小振幅,这里窗函数选择Hamming窗,
傅里叶变换,将信号从时域转换到频域,
计算Mel滤波器组,将功率谱通过一组Mel刻度的三角滤波器来提取频带,
步骤2:对数组进行最小-最大归一化操作,将数组中的每个元素映射到[0,1]范围内;
步骤3:记录每个特征的最小和最大值,以便在需要进行反归一化时能够使用这些信息,将其保存为pkl格式文件;
步骤4:MelVAE网络训练过程具体表示为:
加载预处理得到的频谱图数据的文件路径;
创建一个空列表,用于存储加载的频谱图数据;
加载.npy文件,得到频谱图数据;
将频谱图数据添加到列表,进行格式转换,列表转换为数组;
设置轮数epochs为150,学习率为0.001以外,还要设置超参数α为100000;
编码器将频谱数据映射到潜在空间,解码器将低维表示重构回频谱数据;
计算重构误差Loss=α·RMSE+KL,其中,Loss是损失函数,RMSE是重构误差,KL是KL散度(Kullback-Leibler Divergence),α是重建损失函数的权重,KL散度用下列公式表示:
上式中,N(μ,σ)为当前的正态分布,N(0,1)为标准整体分布,通过计算当前的正态分布和标准正态分布之间的距离,使得当前的正态分布,不断向标准正态分布进行靠拢。
步骤5:通过反馈神经网络调整模型参数;
步骤6:存储模型参数的pkl格式文件以及权重的h5格式文件,
步骤7:加载MelVAE模型,从潜在空间中随机采样一组音乐表示编码,使用解码器将潜在空间中的采样点映射回音频频谱,调用频谱反演模型进行谱图变换,得到最后的音乐。
步骤4中编码器,总共使用了5层卷积层,卷积核的数量初始设为512,每层依次减半,大小设为(3×3),步长为(2×2),使得输出特征图尺寸减半。使用“same”填充来保持特征图尺寸与输入相同。每层卷积层使用卷积操作提取输入数据的特征,通过ReLU激活函数引入非线性,最后利用批归一化层提高训练的稳定性。由于卷积层5输出的通道为32,因此全连接层的第一层设定了3072(8×12×32)个神经元,再通过两个全连接层,分别计算潜在空间中的均值(mu)和对数方差(log_variance),这两个参数用于构造高斯分布,最终输出即为潜在空间的采样点。
步骤4中解码器,基本上是与编码器镜像的。输入为潜藏空间的特征表示,再进行卷积重构前,通过Reshape层将一维的数据转换为三维数组,再通过5层转置卷积层,将潜在空间的编码生成与输入音频相似的新样本。特别地,最后一层转置卷积层只使用了一个滤波器(Filter),因为输出的频谱图中的每个像素表示在特定频率和时间点上的信号能量,而不需要多个通道来表示不同的颜色信息。最后,通过Sigmoid激活函数保证输出图像的像素值在[0,1]范围内。
图2为步骤7中反演模型的内部结构,首先利用一维卷积神经网络从梅尔频谱中估计出幅度和相位梯度。接着,通过相位积分算法依据相位梯度来估计相位谱,最终利用幅度谱和相位谱通过逆短时傅里叶变换(逆STFT)重建时域音频。具体的一维卷积网络输入为梅尔频谱图,该网络是一个标准的卷积神经网络,包含五层卷积层,每层的卷积核大小均为3,通道数达到1536,采用RELU作为非线性激活函数。卷积输出层产生三个通道的输出,分别对应幅度以及与时间和频率相关的两个相位梯度分量。此外,网络在输入的幅度谱与输出幅度之间实现了残差连接,通过一个简单的线性插值过程,实现从梅尔尺度到线性尺度的频率转换。
如图3和4所示,为本发明验证作曲模型重构能力所进行的实验结果。实验过程是,首先,加载经过预处理的频谱数据集,并在其中随机选择一定数量的样本,进而获取这些样本的文件路径以及相应的Min-Max值。接着,加载经过训练的MelVAE模型,对其进行初始化以构建音乐生成器。通过该音乐生成器,对选定的样本进行音频频谱的重构生成,随后将其转换为原始音频信号,并将结果保存至指定目录。同时,原始频谱样本也经过相应的转换,得到对应的原始音频信号并进行保存。图3是原音乐和生成音乐的波形对比,可以看出波形的波峰和波谷基本是一致的,但是振幅上生成的音乐要比原音乐较小。为了更直观并且详细地对比两种信号,本发明还使用Librosa库将信号频谱图的振幅转换为对数刻度,并使用Matplotlib库进行可视化。该对数梅尔频谱图颜色表示对应频率和时间上的振幅值,图4从颜色分布来看,音乐信号前后基本一致,说明了MelVAE对音乐信号信息编码解码的能力较好。
如图5所示,为本发明验证作曲模型插值能力所进行的实验结果。
插值实验过程如下:
1)从音乐数据集中随机选择两个音乐序列A和B;
2)将这两个序列分别输入到编码器中,以获得一对对应的潜在向量;
3)在这对潜在向量之间执行线性插值操作,生成一系列中间的潜在向量;
4)通过解码器将这些潜在向量转换为相应的音乐序列;
5)计算每个生成的插值序列与原始序列之间的汉明距离。
从图5可以看出基线插值不考虑潜在空间的结构,而是直接在音乐序列的音符表示上进行操作,在不考虑音乐理论约束的情况下可能会产生更接近原始序列的插值。而两种生成模型随着插值增加,生成的序列平滑地从序列A过渡到序列B,并且MelVAE相较于MusicVAE的变化较小,说明它在潜在空间上分布更密集,从而使得它的生成效果更好。
需要说明的是,以上内容仅仅说明了本发明的技术思想,不能以此限定本发明的保护范围,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰均落入本发明权利要求书的保护范围之内。
- 一种基于图变分自编码器的匿名社交图恢复方法及系统
- 一种基于匹配追踪的音乐速度谱图生成方法