基于音乐基因表达编程的特定作曲风格音乐生成方法
文献发布时间:2024-07-23 01:35:12
技术领域
本申请涉及音乐生成技术领域,特别是涉及一种基于音乐基因表达编程的特定作曲风格音乐生成方法。
背景技术
声音是最早被人类理解的一种能量形式。音乐能够以物理能量的方式直接影响人体内部的气机运动。作为一种跨越时空的艺术形式,音乐对人类的发展尤为重要。适合自己当前时期的特定风格的音乐能够触动人们的内心深处,让人们在不同的情感和情境中得到共鸣和感动。近年来随着人工智能技术的发展,关于音乐创作的研究逐步展开。人工智能生成音乐,作为现代数字多媒体技术重要的组成部分,顾名思义,就是用计算机软件配合MIDI键盘制作的音乐,是科技与艺术的结合。而计算机音乐生成,指的是计算机作为辅助,生成特定的音符序列,其包含音高、节奏、和弦等音乐元素,且可以通过软件对生成的音乐序列进行演奏,进而辅助作曲者进行音乐创作,实现在音乐创作过程中,作曲者的介入程度达到最小。20世纪50年代中期就开始使用计算机进行音乐作曲。1957年,Lejaren Hiller和Leonard Isaaeson采用马卡洛夫过程模型,创作出世界历史上第一首完全由计算机“作曲”的音乐作品——《Illiac Suite for String Quartet》[9],即著名的“Illiac组曲”,从而开创了计算机音乐生成的先河。
然而,目前从技术角度来看,利用深度学习技术自动生成音乐成为音乐生成领域的研究热点。从任务角度来看,目前音乐生成任务中已经衍生出很多个子任务,如旋律生成、和弦生成、风格迁移、音频合成歌声合成等。虽然目前音乐生成领域研究具有一定的音乐自动生成能力,但是目前对于特定作曲家特定作曲风格的音乐自动生成的研究少。
发明内容
基于此,有必要针对上述技术问题,提供一种能够自动生成特定作曲风格音乐的基于音乐基因表达编程的特定作曲风格音乐生成方法。
一种基于音乐基因表达编程的特定作曲风格音乐生成方法,所述方法包括:
获取特定音乐家的音乐数据库;音乐数据库包括多首音乐;将音乐的乐谱映射成由八进制数作为基因组成的基因型并根据音乐基因表达式编程技术进化基因型,得到多个新的基因型;
通过增设记忆细胞及门控机制的方式改进LSTM网络构建音乐评估网络,根据预先设置的损失函数和训练集对音乐评估网络进行训练,得到训练好的音乐评估网络;
根据训练好的音乐评估网络对多个新的基因型的音乐特征进行学习,将多个新的基因型的音频进行快速傅里叶变换后得到的频谱,采用相似度矩阵计算频谱与预先构建的训练集中其他音乐的相似度平均值作为适应度值;将适应度最高的新的基因型进行解码输出,得到特定作曲风格的音乐。
在其中一个实施例中,将音乐的乐谱映射成由八进制数作为基因组成的基因型,包括:
以1-7、11-17、21-27、31-37、41-47表示音高,其中1-7表示低16度区域、11-17表示低八度区域,21-27表示中八度区域,31-37表示高八度区域,41-47表示高16度区域;其中,数字的个位表示音级,即1、2、3、4、5、6、7对应do、ri、mi、fa、so、la、si,也写作C、D、E、F、G、A、B;
利用数字出现的数量来记录音高时长,以十六分音符为最小单位,每一小节由十六个数字编码组成,根据不同音的时间不同,确定音符的数字个数。
在其中一个实施例中,音乐基因表达式编程技术包括乐符节拍重组、乐符节拍复制、乐符对称、乐符倒位、乐符替换和乐符升降;其中,乐符对称表示3到8音以中间某个音为中心移位,乐符倒位表示互换操作对象前后两个乐符位,乐符替换表示在目标乐符总时长不变的情况下,从原料库当中随机选择相同时长的音乐乐符替换,乐符升降表示对2到3个连续的音的音阶进行升或降,高或低一到三度。
在其中一个实施例中,通过增设记忆细胞及门控机制的方式改进LSTM网络构建音乐评估网络,包括:
在LSTM网络的LSTM神经元中增设记忆细胞及门控机制,利用遗忘门过滤LSTM神经元中没用的信息,根据输入门和候选记忆产生LSTM神经元中新的记忆信息,再利用输出门更新新的记忆信息,再将更新后的记忆送给下一个神经元,根据更新后的神经元构建更新后的LSTM层;
利用输入层、更新后的LSTM层、Dropout层、全连接层和输出层构建音乐评估网络。
在其中一个实施例中,遗忘门表示为
其中,Wxf表示输入xt传递到ft对应的权重矩阵,
在其中一个实施例中,输入门表示为
其中,Wxi表示输入x
在其中一个实施例中,候选记忆表示为
其中,C
在其中一个实施例中,输出门表示为
其中,Wxo表示输入xt传递到O
在其中一个实施例中,利用输入层、更新后的LSTM层、Dropout层、全连接层和输出层构建音乐评估网络,包括:
根据三个LSTM层设置更新后的LSTM层,其中两个LSTM层包括128个LSTM神经元,一个LSTM层包括64个神经单元,用于捕捉序列数据中的时间依赖关系和模式;
在LSTM层后添加Dropout层,用于以预先设定的概率随机丢弃LSTM神经元的输出;
在更新后的LSTM层之后包含两个全连接层,第一个全连接层有64个神经元,激活函数为ReLU,第二个全连接层有32个神经元,激活函数也为ReLU,用于进一步处理LSTM层的输出;输出层是一个具有1个神经元的全连接层,没有激活函数。
在其中一个实施例中,根据预先设置的损失函数和训练集对音乐评估网络进行训练,得到训练好的音乐评估网络,包括:
在设置输入训练样本、目标值、迭代次数、批量大小、控制训练过程中日志输出的详细程度以及验证数据后,根据model.fit方法对音乐评估网络进行训练,通过Adam算法调整音乐评估网络权重以最小化均方误差损失函数,直至达到迭代次数时,得到训练好的音乐评估网络。
上述基于音乐基因表达编程的特定作曲风格音乐生成方法,本申请在音乐生成阶段,将作曲家作曲时的一些对乐谱的修改操作与基因表达式编程的进化操作进行融合,形成音乐基因表达式编程操作,实现以小节为单位的乐谱进化,能够更好的生成与特定音乐家的相似音乐。在音乐评估阶段,通过增设记忆细胞及门控机制的方式进行改进,减轻了LSTM神经网络记忆负担从而提升LSTM神经网络整体准确率,利用增设记忆细胞及门控机制的方式改进的LSTM网络构建音乐评估网络能够提高音乐评估准确率,根据预先设置的损失函数和训练集对音乐评估网络进行训练,根据训练好的音乐评估网络对多个新的基因型的音乐特征进行评估,通过音乐频谱特征相似度量化分析生成音乐风格是否与特定作曲家作曲风格相似实现特定作曲风格音乐的最终判定进行生成特定作曲风格音乐。
附图说明
图1为一个实施例中一种基于音乐基因表达编程的特定作曲风格音乐生成方法的流程示意图;
图2为一个实施例中音乐基因表达式编程音乐进化生成的流程示意图;
图3为一个实施例中乐谱音符与音乐基因表达式之间进行映射示意图;
图4为另一个实施例中音乐基因表达式编程的进化操作示意图;
图5为一个实施例中LSTM神经单元结构图;
图6为一个实施例中音乐评估网络结构图;
图7为一个实施例中本申请方法中所生成的音乐与其他方法所生成的音乐的得分示意图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
在一个实施例中,如图1所示,提供了一种基于音乐基因表达编程的特定作曲风格音乐生成方法,包括以下步骤:
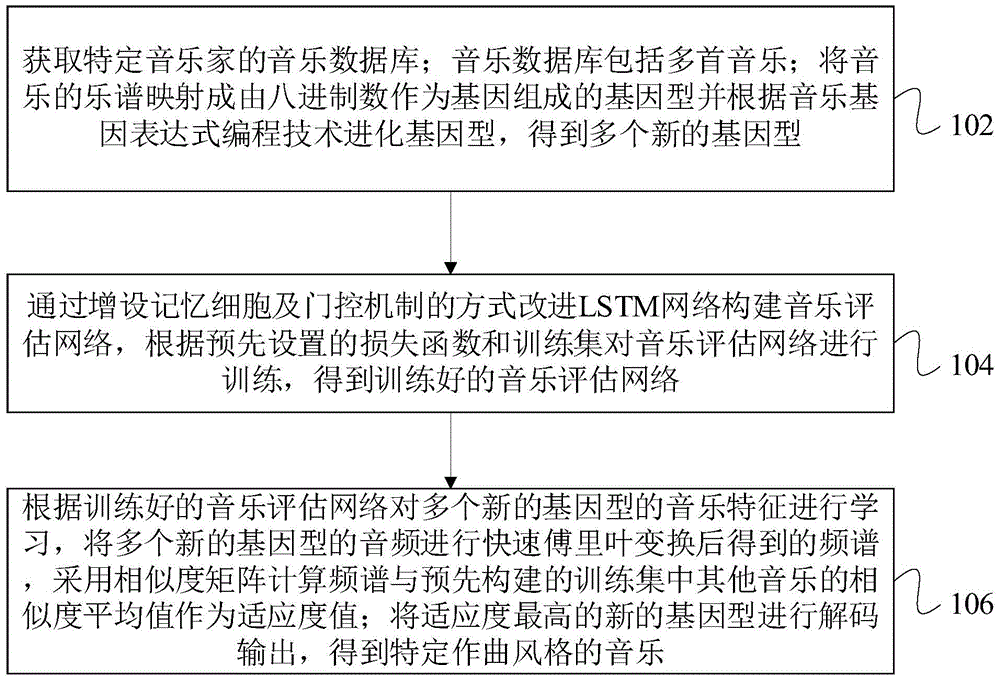
步骤102,获取特定音乐家的音乐数据库;音乐数据库包括多首音乐;将音乐的乐谱映射成由八进制数作为基因组成的基因型并根据音乐基因表达式编程技术进化基因型,得到多个新的基因型。
在音乐生成部分当中,本申请支持用户自定义生成特定曲式结构的音乐。一般流行音乐乐曲由主歌和副歌两部分组成。在生成乐曲前可以选择歌曲中主歌和副歌的曲式结构,例如主歌为A,A,B的形式,而副歌为C,C,D,E的形式。主歌和副歌的A,B,C,D,E部分的模板是使用特定歌曲的节奏模板形式。如图3所示,将音乐的乐谱映射成由八进制数作为基因组成的基因型,根据音乐基因表达式编程技术进化主歌或者副歌的基本节,如图2所示,为音乐基因表达式编程的流程,通过音乐基因表达式编程技术进化产生新的基因型。固定歌曲模板主歌和副歌中休止符0的位置,而其余位置则将由音乐库的片段执行音乐基因表达式编程操作生成,可以得到多个新的乐谱,即新的基因型,实现了以小节为单位的乐谱进化,能够更好的生成与特定音乐家的相似音乐。
步骤104,通过增设记忆细胞及门控机制的方式改进LSTM网络构建音乐评估网络,根据预先设置的损失函数和训练集对音乐评估网络进行训练,得到训练好的音乐评估网络。
如图5所示,为LSTM神经单元结构图,其中ct代表第t个时刻输出的记忆细胞状态,ht代表第t个时刻输出的隐藏状态,xt则代表第t个时刻的输入向量。门控机制包括遗忘门、输入门、输出门三个门单元。其中遗忘门用来从当前单元状态中决定丢弃信息;输入门根据当前时刻的输入向量和输入隐藏状态对该单元状态及输入的记忆细胞状态进行更新;输出门则用来确定LSTM当前单元的输出隐藏状态。遗忘门忘掉没用的信息,输入门和候选记忆产生新的记忆信息,输出门负责更新记忆,再将新的记忆送给下一个神经元,通过将每个功能模块组合起来,就构成了完整的LSTM层。通过增设记忆细胞及门控机制的方式进行改进,减轻了LSTM神经网络记忆负担从而提升LSTM神经网络整体准确率,利用增设记忆细胞及门控机制的方式改进的LSTM网络构建音乐评估网络能够提高音乐评估准确率,在利用训练集进行模型训练时,通过计算生成的新的歌曲与训练集中特定音乐家的音乐的相似度是为了获取一些标签值(也就是歌曲频谱数据的得分),根据得分得到评估结果,在训练好的音乐评估网络中输入生成歌曲的频谱数据自动生成得分,将得分最高的歌曲作为输出。
步骤106,根据训练好的音乐评估网络对多个新的基因型的音乐特征进行学习,将多个新的基因型的音频进行快速傅里叶变换后得到的频谱,采用相似度矩阵计算频谱与预先构建的训练集中其他音乐的相似度平均值作为适应度值;将适应度最高的新的基因型进行解码输出,得到特定作曲风格的音乐。
根据训练好的音乐评估网络对多个新的基因型的音乐特征进行学习,将多个新的基因型进行快速傅里叶变换后得到的矩阵作为频谱,比如,初代生成100个新的基因型,即100首歌曲,每首歌的数据格式为(1,1000)频谱数据。该频谱数据是由wav格式的歌曲经快速傅里叶变换后得到的频谱组成的。为了刻画作曲家的作曲风格,采用相似度矩阵计算音乐作品的频谱与训练集中其他歌曲的相似度平均值作为适应度值,同时使用LSTM神经网络评估后取100首歌适应度值最高的20首作为父本进行同步并行进行串行进化。第一代的父本是歌曲家的曲子的乐谱,后面在20代分别串行进化的时候,每一代的父本是上一代得分的适应度值最高的乐谱,这20首歌曲分别进化50代,得到20首音乐的最终适应度值,最后取得分值高的5首歌曲作为生成结果。
上述基于音乐基因表达编程的特定作曲风格音乐生成方法中,本申请在音乐生成阶段,将作曲家作曲时的一些对乐谱的修改操作与基因表达式编程的进化操作进行融合,形成音乐基因表达式编程操作,实现以小节为单位的乐谱进化,能够更好的生成与特定音乐家的相似音乐。在音乐评估阶段,通过增设记忆细胞及门控机制的方式进行改进,减轻了LSTM神经网络记忆负担从而提升LSTM神经网络整体准确率,利用增设记忆细胞及门控机制的方式改进的LSTM网络构建音乐评估网络能够提高音乐评估准确率,根据预先设置的损失函数和训练集对音乐评估网络进行训练,根据训练好的音乐评估网络对多个新的基因型的音乐特征进行评估,通过音乐频谱特征相似度量化分析生成音乐风格是否与特定作曲家作曲风格相似实现特定作曲风格音乐的最终判定进行生成特定作曲风格音乐。
在其中一个实施例中,将音乐的乐谱映射成由八进制数作为基因组成的基因型,包括:
以1-7、11-17、21-27、31-37、41-47表示音高,其中1-7表示低16度区域、11-17表示低八度区域,21-27表示中八度区域,31-37表示高八度区域,41-47表示高16度区域;其中,数字的个位表示音级,即1、2、3、4、5、6、7对应do、ri、mi、fa、so、la、si,也写作C、D、E、F、G、A、B;
利用数字出现的数量来记录音高时长,以十六分音符为最小单位,每一小节由十六个数字编码组成,根据不同音的时间不同,确定音符的数字个数。
在具体实施例中,将音乐的乐谱映射成由八进制数作为基因组成的基因型,新的基因型中例如33表示高八度的E音,例如[22,22]表示一个8分音符的中音D音,[45]表示一个16分音符的高16度G音。
在其中一个实施例中,音乐基因表达式编程技术包括乐符节拍重组、乐符节拍复制、乐符对称、乐符倒位、乐符替换和乐符升降;其中,乐符对称表示3到8音以中间某个音为中心移位,乐符倒位表示互换操作对象前后两个乐符位,乐符替换表示在目标乐符总时长不变的情况下,从原料库当中随机选择相同时长的音乐乐符替换,乐符升降表示对2到3个连续的音的音阶进行升或降,高或低一到三度。
在具体实施例中,由于音乐乐谱的主歌和副歌要求的歌曲曲式结构(用户定义模板),利用基因表达式编程技术对主歌或者副歌的基本节复制后做出微调。如用户定义“AABB”音乐结构,生成旋律“A”之后(A按照模板由很多小节组成),复制旋律“A”,再次基础上通过音乐基因表达式编程技术对“A”进行微调,得到“AA”这样的组合旋律。再重复该流程生成“BB”组合旋律,通过组合“AABB”形成主歌,执行相同的操作生成副歌,可以极大程度上模仿了人类作曲家的作曲方式。
通过音乐基因表达式编程技术在音乐乐谱生成阶段,依据轮盘赌规则,以一定概率值对乐谱以节为单位执行进化修改操作以生成新的音乐;音乐基因表达式编程技术包括乐符节拍重组、乐符节拍复制、乐符对称、乐符倒位、乐符替换和乐符升降;其中,如图4所示,第一种:乐符节拍重组,例2233变为2223或2333。第二种:乐符节拍复制,例2233变为22223333,其总时长翻倍,该操作导致覆盖紧接着的音。第三种:乐符对称。3到8音以中间某个音为中心移位,例224433变为334422,以44为中心。第四种:乐符倒位。互换操作对象前后两个乐符位,例223344变为442233。第五种:乐符替换,在目标乐符总时长不变的情况下,从原料库当中随机选择相同时长的音乐乐符替换。第六种:乐符升降针对2到3个连续的音的音阶进行升或降,高或低一到三度。
在其中一个实施例中,通过增设记忆细胞及门控机制的方式改进LSTM网络构建音乐评估网络,包括:
在LSTM网络的LSTM神经元中增设记忆细胞及门控机制,利用遗忘门过滤LSTM神经元中没用的信息,根据输入门和候选记忆产生LSTM神经元中新的记忆信息,再利用输出门更新新的记忆信息,再将更新后的记忆送给下一个神经元,根据更新后的神经元构建更新后的LSTM层;
利用输入层、更新后的LSTM层、Dropout层、全连接层和输出层构建音乐评估网络。
在其中一个实施例中,遗忘门表示为
其中,Wxf表示输入xt传递到ft对应的权重矩阵,
在其中一个实施例中,输入门表示为
其中,Wxi表示输入x
在其中一个实施例中,候选记忆表示为
其中,C
在具体实施例中,f
在其中一个实施例中,输出门表示为
其中,Wxo表示输入xt传递到O
在其中一个实施例中,利用输入层、更新后的LSTM层、Dropout层、全连接层和输出层构建音乐评估网络,包括:
根据三个LSTM层设置更新后的LSTM层,其中两个LSTM层包括128个LSTM神经元,一个LSTM层包括64个神经单元,用于捕捉序列数据中的时间依赖关系和模式;
在LSTM层后添加Dropout层,用于以预先设定的概率随机丢弃LSTM神经元的输出;
在更新后的LSTM层之后包含两个全连接层,第一个全连接层有64个神经元,激活函数为ReLU,第二个全连接层有32个神经元,激活函数也为ReLU,用于进一步处理LSTM层的输出;输出层是一个具有1个神经元的全连接层,没有激活函数。
在具体实施例中,如图6所示,利用输入层、更新后的LSTM层、Dropout层、全连接层和输出层构建音乐评估网络,其中,输入层:输入数据为大小为(1,1000)的音乐频谱。隐藏层(LSTM层):该模型包含三个LSTM层,每一层都包含128个LSTM神经元。这些LSTM层是用来捕捉序列数据中的时间依赖关系和模式。指定每个LSTM层都返回完整的输出序列,而不仅仅是最后一个时间步的输出。Dropout层:在每个LSTM层后面添加Dropout层,本申请中Dropout层以20%的概率随机丢弃神经元的输出。这有助于减少过拟合,提高模型的泛化能力。全连接层(Dense层):模型在LSTM层之后包含两个全连接层。第一个全连接层有64个神经元,激活函数为ReLU,第二个全连接层有32个神经元,激活函数也为ReLU。这些全连接层用于进一步处理LSTM层的输出。输出层:输出层是一个具有1个神经元的全连接层,没有激活函数。
在其中一个实施例中,根据预先设置的损失函数和训练集对音乐评估网络进行训练,得到训练好的音乐评估网络,包括:
在设置输入训练样本、目标值、迭代次数、批量大小、控制训练过程中日志输出的详细程度以及验证数据后,根据model.fit方法对音乐评估网络进行训练,通过Adam算法调整音乐评估网络权重以最小化均方误差损失函数,直至达到迭代次数时,得到训练好的音乐评估网络。
在一个实施例,对生成的歌曲进行记录与表达,音级指的是相同字母命名的音高,是划分各音之间距离的单位,同一音级上的音的声音非常相近,因此记为同一音级,从频率上来说,同一音级的音高频率为倍数关系,C4频率为261.63Hz,C5频率为523.25Hz,C6为1046.5Hz,可以看出,每上升一个八度(octave,相隔八度),对应音级的频率就增加一倍。在一个八度里有7个音级。以C大调为例,从C音开始上行,C-D-E-F-G-A-B分别对应第一至第七音级。音乐的调式从本质上讲是一个音阶,每个调式都有自己独特的音阶。建立在E音级所构成的音阶上(E为主音),它就是E调作品,根据不同的音程组合,如E-#F-#G-A-B-#C-#D,称为E大调,在钢琴白键(从C音开始),组成的C-D-E-F-G-A-B称为C大调,C大调里的每个音分别对应着自己的级数,分别用罗马数字Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ、Ⅵ、Ⅶ来表达。一个大调音阶是由七个不同的音级按“全-全-半-全-全-全-半”的音程排列构成,如C上行到B中的白键。一个小调音阶由“全-半-全-全-半-全-全”的音程排列构成,如A-B-C-D-E-F-G,大调和小调指的就是这部作品的调式。大调式在情感色彩比小调式显得更明亮,更稳定,小调通常显得更加忧伤和暗淡。调式不仅有自然大小调之分,常见的调式还有和声小调、旋律小调、和声大调。中国风的五声调式(宫、商、角、徵、羽五种调式),在传统的中国曲风中,音乐多采用“宫调式”的主旋律,编曲上大量运用中国乐器,通曲音调婉转、回环,有一种传统东方的美感。调式的选择对正在创作的作品情感会产生重大影响,不同的调式给人们带来不同的感觉,D大调大部分表现庄严、荣耀,F大调比较清新青春,f小调有象征死亡的意义等等。在使用调式创作音乐的时候,先确定音乐的基调,熟练运用调式中各个音的作用和音程关系,再创作一段旋律围绕着主音有规律的变化,相对来说比较简单,对于自动音乐生成的研究有指导意义。本申请中音乐基因表达式编程的数据库选取了C大调的音乐,理论上生成的音乐也应该按照C大调进行演奏,但是这里并不对音乐调式加以限制,本申请所提出方法生成乐谱按照任意合适的调式进行演奏。作为乐器与计算机之间的通信标准,乐器数字接口(MIDI)被提出来后一直被广泛使用。它是一种记录乐器和计算机连接方式和信息的协议。与其它文本格式相比,MIDI所包含的信息量更多,可以用于辅助音乐创作,被作曲界冠名“计算机能理解的乐谱”。因此,作为规范的音乐格式,MIDI被广泛应用于音乐作曲界。MIDI可以通过与音色库中各种音色组合来制作音乐,而当今大部分的音乐是通过这种方式制作而成。MIDI的基本思想是:在MIDI文件中存储一首音乐中的全部音符Event,在这些音符事件中,记录存储相应的音乐要素信息,如:音量、音高、音符演奏开始结束时间以及持续时间等,通过记录所有音符的信息来记录这首音乐。并且,若一首音乐中包含多个音轨(乐器),那么MIDI为每一条音轨提供专门的通道(channel),在该通道中记录该音轨的音符信息,通过这种分音轨的方式记录音乐的演奏方式。在本申请中,音乐基因表达式编程生成MIDI文件的乐谱,将该乐谱输入软件可以进行音乐播放和音频文件导出。
在一个实施例中,利用本申请提出来的方法生成的歌曲与其他方法所生成的音乐的频谱数据输入音乐评估神经网络中,得到几种方法生成的音乐风格评估结果如图7所示,本申请生成的特定作曲风格的得分最高。
应该理解的是,虽然图1的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 一种基于生成对抗网络的音乐生成方法及装置
- 基于特定风格的音乐生成方法、装置、设备及存储介质
- 一种基于云基因表达式编程的音乐情感识别方法