语音识别方法、装置、设备及介质
文献发布时间:2024-07-23 01:35:12
技术领域
本申请涉及信息识别技术领域,尤其涉及一种语音识别方法、装置、设备及介质。
背景技术
在一些互联网交互场景,例如车载、电视、移动终端等应用场景中,通常仅通过语音输入来生成用户文本以识别用户的指令或问题,选用单一的信息识别易导致识别结果的准确率较低。
发明内容
本申请实施例提供一种语音识别方法、装置、设备及介质,旨在提高语音识别的准确性。
本申请实施例提供了一种语音识别方法,包括:
获取语音信息和手势图像,
识别语音信息,得到语音信息的准文本信息,并识别手势图像中的手势,得到手势图像对应的手势信息;
在语音信息的发声对象和手势的操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息。
根据本申请第一方面的实施方式,在对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息之前,方法还包括:
获取发声对象的第一位置信息以及操作对象的第二位置信息;
计算第一位置信息和第二位置信息的距离;
当第一位置信息和第二位置信息的距离小于距离阈值时,确定语音信息的发声对象和手势的操作对象为同一对象。
根据本申请第一方面前述任一实施方式,方法还包括:
获取发声对象的第一位置信息以及操作对象的第二位置信息;
计算第一位置信息和第二位置信息的距离;
当第一位置信息和第二位置信息的距离差值大于或等于距离阈值时,确定发声对象和操作对象不为同一对象,并根据准文本信息确定目标文本信息。
根据本申请第一方面前述任一实施方式,根据手势信息,对准文本信息进行处理,得到语音信息对应的目标文本信息之前,方法还包括:
确定手势信息为预设手势信息。
根据本申请第一方面前述任一实施方式,识别手势图像中的手势,得到手势图像对应的手势信息,包括:
识别手势图像中的手势,得到手势的位置和手势类型;
确定与手势图像关联的交互空间实体模型;
在手势类型为指向性的手势时,根据所手势的位置,确定手势的指向与交互空间实体模型的拓扑表面的交点坐标;
根据在交互空间实体模型的拓扑表面标注的实体标签,确定交点坐标对应的实体关键词信息;
手势信息包括手势的位置、手势类型以及实体关键词信息。
根据本申请第一方面前述任一实施方式,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息之前,方法还包括:
输出提示信息,提示信息用于提示用户是否指向实体关键词信息对应的实体;
接收用户对提示信息的第一操作;
对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息,包括:
在第一操作为确认操作时,根据实体关键词信息,对准文本信息进行处理,得到语音信息对应的目标文本信息。
根据本申请第一方面前述任一实施方式,接收用户对提示信息的第一操作之后,方法还包括:
在第一操作为拒绝操作时,显示交互空间实体模型中与交点坐标相邻的相邻表面的候选标注标签;
接收用户从候选标注标签中选取目标标注标签的选中操作;
对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息,包括:
根据目标标注标签,对准文本信息进行处理,得到语音信息对应的目标文本信息。
根据本申请第一方面前述任一实施方式,识别手势图像中的手势,得到手势图像对应的手势信息的步骤之前,方法还包括:
获取空间交互信号,空间交互信号包括对车座、天窗、车窗、方向盘、车载显示器、控制键中的至少一个的位置调整信息;
根据空间交互信号更新位于拓扑表面的标注标签的位置信息。
根据本申请第一方面前述任一实施方式,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息,包括:
从准文本信息中提取实体关键词信息;
在提取到实体关键词信息,且提取到的实体关键词信息与指向的实体关键词信息不一致的情况下,将指向的实体关键词信息替换准文本中的实体关键词信息,得到目标文本信息;
在未提取到实体关键词信息时,根据准文本信息的语义信息,将指向的实体关键词信息添加到准文本信息中,得到目标文本信息。
根据本申请第一方面前述任一实施方式,还包括:
确定目标文本信息在第一检索库中对应的多个候选文本,将目标文本信息和多个候选文本中的每一个候选文本分别进行拼接,形成多个输入文本;
对多个输入文本进行分词后输入深度学习模型以得到多个输出词组;
根据映射词典将多个输出词组映射为多个标签信息,映射词典包括输出词组和标签信息的映射关系;
将多个标签信息输入深度学习模型得到多个向量;
通过逻辑回归分类器将多个向量映射归一化为分类概率向量;
根据多个分类概率向量确定各候选文本与目标文本信息的语义相似度;
当多个输出词组中的最大语义相似度大于或等于相似阈值时,将与目标文本信息语义相似度最大候选文本作为最终文本;当多个输出词组的语义相似度均小于相似阈值时,拒绝语音识别。
根据本申请第一方面前述任一实施方式,还包括:根据最终文本和问答映射关系确定最终文本的应答信息,问答映射关系包括多个文本及其对应的应答信息。
本申请第二方面的实施例还提供一种语音识别装置,包括:获取单元,用于获取语音信息和手势图像;
识别单元,用于识别语音信息,得到语音信息的准文本信息,并识别手势图像中的手势,得到手势图像对应的手势信息;
处理单元,用于在语音信息的发声对象和手势的操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息。
本申请第三方面的实施例还提供一种语音识别设备,包括处理器、存储器及存储在存储器上并可在处理器上运行的计算机程序,计算机程序被处理器执行时实现上述的语音识别方法的步骤。
本申请第四方面的实施例还提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述的语音识别方法的步骤。
在本申请实施例提供的语音识别方法中,首先获取语音信息和手势图像,然后分别识别语音信息和图像信息,得到准文本信息和手势信息。最后在语音信息的发声对象和手势的操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息。本申请实施例的目标文本信息根据语音信息和手势图像两种信息类型获得,能够有效提高语音识别的准确性。
附图说明
通过阅读以下参照附图对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显,其中,相同或相似的附图标记表示相同或相似的特征。
图1是本申请实施例提供的一种语音识别方法的流程示意图;
图2是本申请另一实施例提供的一种语音识别方法的流程示意图;
图3是本申请又一实施例提供的一种语音识别方法的流程示意图;
图4是本申请再一实施例提供的一种语音识别方法的流程示意图;
图5是本申请还一实施例提供的一种语音识别方法的流程示意图;
图6是本申请还一实施例提供的一种语音识别方法的流程示意图;
图7是本申请还一实施例提供的一种语音识别方法的过程图;
图8是本申请还一实施例提供的一种语音识别方法的流程示意图;
图9是图8所示语音识别方法的过程图;
图10是本申请还一实施例提供的一种语音识别方法的流程示意图;
图11是图10所示语音识别方法的过程图;
图12是本申请实施例提供的一种语音识别装置的模块结构示意图。
具体实施方式
下面将详细描述本申请的各个方面的特征和示例性实施例。在下面的详细描述中,提出了许多具体细节,以便提供对本申请的全面理解。但是,对于本领域技术人员来说很明显的是,本申请可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本申请的示例来提供对本申请的更好的理解。在附图和下面的描述中,至少部分的公知结构和技术没有被示出,以便避免对本申请造成不必要的模糊;并且,为了清晰,可能夸大了部分结构的尺寸。此外,下文中所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施例中。
在本申请的描述中,需要说明的是,除非另有说明,“多个”的含义是两个以上;术语“上”、“下”、“左”、“右”、“内”、“外”等指示的方位或位置关系仅是为了便于描述本申请和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本申请的限制。此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。
下述描述中出现的方位词均为图中示出的方向,并不是对本申请的实施例的具体结构进行限定。在本申请的描述中,还需要说明的是,除非另有明确的规定和限定,术语“安装”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接相连,也可以间接相连。对于本领域的普通技术人员而言,可视具体情况理解上述术语在本申请中的具体含义。
为了更好地理解本申请,下面结合图1至图12对本申请实施例的语音识别方法、装置、设备及介质进行详细描述。
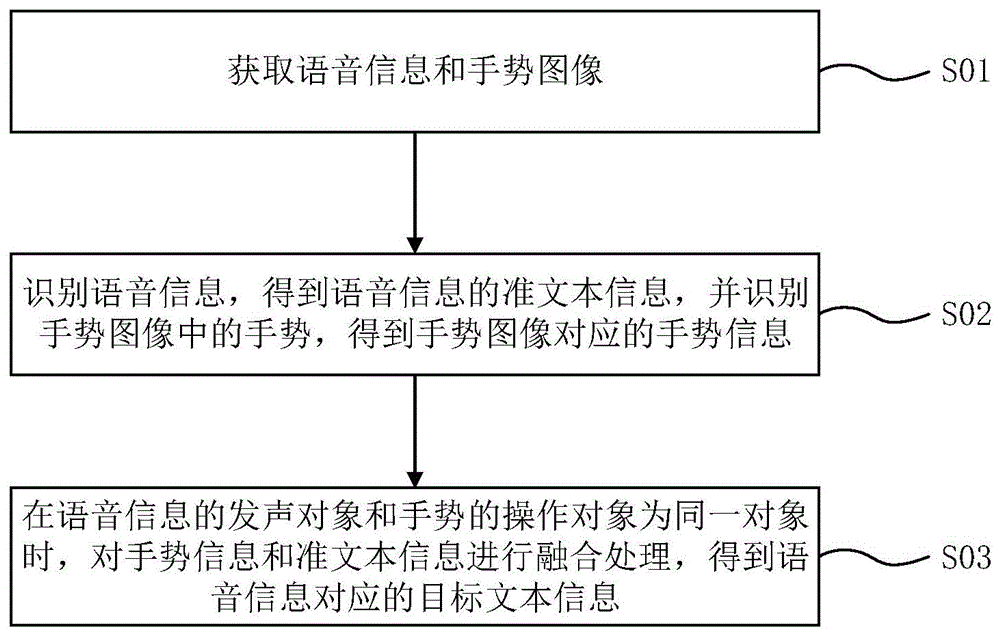
如图1所示,本申请实施例提供了一种语音识别方法,包括:
步骤S01:获取语音信息和手势图像。
可选的,可以通过麦克风、语音传感器获取语音信息。可选的,可以通过多视觉传感器、图像传感器、摄像头等装置获取手势图像。
步骤S02:识别语音信息,得到语音信息的准文本信息,并识别手势图像中的手势,得到手势图像对应的手势信息。
步骤S03:在语音信息的发声对象和手势的操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息。
在本申请实施例提供的语音识别方法中,首先获取语音信息和手势图像,然后分别识别语音信息和图像信息,得到准文本信息和手势信息。最后在语音信息的发声对象和手势的操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息。本申请实施例的目标文本信息根据语音信息和手势图像两种信息类型获得,能够有效提高语音识别的准确性。
本申请实施例的语音识别方法的适用场景有多种,例如语音识别方法可以适用于车辆、显示器、虚拟现实装置等等。作为一种可选的实施例,本申请实施例提供的语音识别方法可以用于车辆,语音识别方法用于识别车辆内用户的指示。
如图2所示,在一些可选的实施例中,在步骤S03之前,语音识别方法还包括:
步骤301:获取发声对象的第一位置信息以及操作对象的第二位置信息。
步骤302:计算第一位置信息和第二位置信息的距离。
步骤303:当第一位置信息和第二位置信息的距离小于距离阈值时,确定语音信息的发声对象和手势的操作对象为同一对象。
在本申请实施例提供的语音识别信息中,首先根据步骤S301和步骤S302获取发声对象的第一位置信息和操作对象的第二位置信息,例如可以通过位置传感器获取第一位置信息和第二位置信息。然后通过步骤S302计算第一位置信息和第二位置信息的距离,例如计算第一位置信息和第二位置信息的空间距离。最后在步骤S303中,当第一位置信息和第二位置信息之间的距离小于距离阈值时,证明第一位置信息和第二位置信息之间的距离较小,第一位置信息和第二位置信息来自于同一用户,确定语音信息的发声对象和手势的操作对象为同一对象。最后在步骤S03中,对手势信息和准文本信息进行融合,得到目标文本信息。
在上述实施例中,距离阈值的取值可以根据用户的实际需求进行确定,例如距离阈值为0.5m、0.6m、0.7m、0.8m等。只要根据距离阈值,能够确定操作对象和发声对象是否为同一对象即可。
在一些可选的实施例中,在上述步骤S302之后,语音识别方法还包括:当第一位置信息和第二位置信息的距离差值大于或等于距离阈值时,确定发声对象和操作对象不为同一对象,根据准文本信息确定目标文本信息。
在本申请实施例中,当第一位置信息和第二位置信息的距离差值大于或等于距离阈值时,表示发声对象和操作对象的距离较远,两者不为同一对象,在步骤S304中直接根据准文本信息确定目标文本信息。一方面能够提高识别准确率,避免将错误的手势信息和准文本信息融合得到目标文本信息;另一方面,能够提高语音识别效率,即使发声对象和操作对象不为同一对象,也能够根据准文本信息得到目标文本信息。
在一些可选的实施例中,步骤S03之前,语音识别方法还包括:确定手势信息为预设手势信息。预设手势信息可以根据用户的实际使用情况进行设定,例如如果手势的目的视为了指示某部件,手势信息中的手势具有指向性,则手势信息为预设手势信息。在手势信息具有指向性时,在步骤S03中对手势信息和准文本信息进行融合处理得到目标文本信息,能够进一步提高识别结果的准确性。
可选的,当手势图像中的手势为单指指向不变或多指指向一致时确定手势具有指向性,手势信息为预设手势信息。
如图3所示,在一些可选的实施例中,识别手势图像中的手势,得到手势图像对应的手势信息,包括:
步骤S200:确定与手势图像关联的交互空间实体模型。
步骤S201:识别手势图像中的手势,得到手势的位置和手势类型。
步骤S202:在手势类型为指向性的手势时,根据所手势的位置,确定手势的指向与交互空间实体模型的拓扑表面的交点坐标。
步骤S203:根据在交互空间实体模型的拓扑表面标注的实体标签,确定交点坐标对应的实体关键词信息。
其中,手势信息包括手势的位置、手势类型以及实体关键词信息。
在本申请实施例中,手势图像包括交互空间实体模型,交互空间实体模型可以包括拓扑表面及分布于拓扑表面的多个实体标签及其位置信息。例如,当语音识别方法用于车辆时,实体标签可以为车内的各部件,实体标签包括但不限于天窗、前排车座、后排车座、顶灯、方向盘、转向灯等等车内的部件。在步骤S201中可以得到手势的位置和手势类型,在步骤S202中当手势类型为指向性的手势时,即当手势是指向某部件时,根据手势位置,可以确定手势的指向与交互空间实体模型的拓扑表面的交点坐标。最后在步骤S203中,根据交互空间实体模型的拓扑表面标注的实体标签,可以确定交点坐标对应的实体关键词信息,即确定手势指向的实体关键词信息。
例如,当用户在后排车座上使用手势指向天窗时,首先根据步骤S201可以确定手势的位置和手势类型。在步骤S202中,当手势为指向性手势,根据手势的位置可以确定手势的指向与交互空间模型的拓扑表面的交点坐标。最后通过步骤S203根据交点坐标匹配交互空间模型的拓扑表面的实体标签,可以得知用户是在后排车座指向天窗,可以确定手势指向的实体关键词信息包括天窗。且最终得到的手势信息包括手势的位置、手势的类型及关键词信息。
如图4和图7所示,在一些可选的实施例中,步骤S03之前,语音识别方法还包括:
步骤S204:输出提示信息,提示信息用于提示用户是否指向实体关键词信息对应的实体。
步骤S205:接收用户对提示信息的第一操作。
步骤S03包括:在第一操作为确认操作时,根据实体关键词信息,对准文本信息进行处理,得到语音信息对应的目标文本信息。
在步骤S203中确定了实体关键词信息时,可能由于用户指示不准确或者车座移动等原因导致实体关键词信息不准确。在本申请实施例中,首先通过步骤S204输出提示信息,以提示用户其指向的实体关键词信息的实体。可以令用户确定其指示的实体是否准确。然后通过步骤S205接收用户收到的提示信息后的第一操作。在步骤S203中,当第一操作为确认操作,即当实体确实为用户想要指示的实体时,根据实体关键词信息,对准文本信息进行处理,得到语音信息对应的目标文本信息。能够提高语音识别方法识别结果的准确性。
如图5和图7所示,在一些可选的实施例中,在步骤S205之后,语音识别方法还包括:
步骤S206:在第一操作为拒绝操作时,显示交互空间实体模型中与交点坐标相邻的相邻表面的候选标注标签。
步骤S207:接收用户从候选标注标签中选取目标标注标签的选中操作。
步骤S03包括:根据目标标注标签,对准文本信息进行处理,得到语音信息对应的目标文本信息。
在这些可选的实施例中,在步骤S206中,当第一操作为拒绝操作时,即当根据交点坐标确定的实体标签并非为用户实际要指示的标签时,显示交互空间模型中与交点坐标相邻表面的多个候选标注标签。然后在步骤S207中获取用户从多个候选标注标签中选取的目标标注标签的选中操作,即获取用户选取的目标标注标签。在步骤S03中,根据目标标注标签,对准文本信息进行处理,得到语音信息对应的目标文本信息,能够提高语音识别方法的准确性和效率。当根据交点坐标确定的实体标签不为用户实际要指示的标签时,无需再次重新进行语音识别,可以直接提供多个候选的标注标签,并获取用户选中的目标标注标签,能够有效提高语音识别的效率。
在上述实施例中,例如当用户目的是想指示天窗,当通过步骤S203得到的实体关键词信息包括天窗,通过步骤S205得到用户对于提示信息的第一操作信息为确认操作时,在步骤S03中,根据包含天窗的关键词信息,对对准文本信息进行处理,得到语音信息对应的目标文本信息。而当通过步骤S203得到的关键词信息为车顶灯,通过步骤S206确定第一操作为拒绝操作时,显示交互空间实体模型中与交点坐标相邻的相邻表面的候选标注标签,即显示交互空间实体模型中与车顶灯相邻的候选标注标签,例如天窗、车顶等。在步骤S207中接收用户从候选标注标签中选取目标标注标签的选中操作,接收到用户从候选标注标签中选取的目标标注标签为天窗,那么在步骤S03中,根据包含天窗的目标标注标签对对准文本信息进行处理,得到语音信息对应的目标文本信息。
如图7所示,在进行语音识别之前,可以根据交互空间实体进行交互空间实体模型的建模。对交互空间实体模型的拓扑表面进行标签标注。以汽车座舱空间为例,在交互空间实体模型的拓扑表面根据座椅、天窗、二排阅读灯开关等位置进行标签标注。
如图6和图7所示,在一些实施例中,在步骤S02之前,语音识别方法还包括:
步骤S101:获取空间交互信号,所述空间交互信号包括对车座、天窗、车窗、方向盘、车载显示器、控制键中的至少一个的位置调整信息。
步骤S102:根据所述空间交互信号更新位于所述拓扑表面的所述标注标签的位置信息。
在用户使用车辆的过程中,可能会对车辆内的一些部件的位置进行调整,这些可以调整的部件例如包括车座、天窗玻璃、车窗玻璃、方向盘、车载显示器和控制键等,控制键例如可以为车辆中控系统的音量控制键、空调控制键等等。在用户调整了这些部件的位置时,通过本申请实施例的步骤S101首先获取这些空间交互信号,然后通过步骤S102根据空间交互信号更新位于拓扑表面的标注标签的位置信息,使得拓扑表面的标注标签的位置信息能够准确反应实体的位置信息,进而提高语音识别的准确率。
如图8和图9所示,在一些可选的实施例中,步骤S03包括:
步骤S031:从准文本信息中提取实体关键词信息。
步骤S032:在提取到实体关键词信息,且提取到的实体关键词信息与指向的实体关键词信息不一致的情况下,将指向的实体关键词信息替换准文本中的实体关键词信息,得到目标文本信息。
步骤S033:在未提取到实体关键词信息时,根据准文本信息的语义信息,将指向的实体关键词信息添加到准文本信息中,得到目标文本信息。
在这些可选的实施例中,首先在步骤S031中从准文本信息中提取实体关键词信息,即从语音信息中也获取关键词信息。在步骤S032中,当能够从准文本中提取到实体关键词信息时,可以判断准文本的实体关键词信息和手势图像得到的实体关键词信息是否一致,当在未提取到所述实体关键词信息时,根据所述准文本信息的语义信息,将指向的实体关键词信息添加到所述准文本信息中,得到目标文本信息。在步骤S033中,当从准文本中无法提取关键词信息时,可以根据准文本信息的语义信息,将指向的实体关键词信息添加到准文本信息中,得到目标文本信息。
例如,当根据语音信息得到的准文本信息为“车窗是什么”时,通过步骤S031获得准文本信息中的实体关键词为“车窗”。当通过步骤S207或步骤S205的殴打的实体关键词为“车顶灯”时,在步骤S032中将“车顶灯”替换为“车窗”得到的目标文本信息为“车顶灯是什么”。
例如,当根据语音信息得到的准文本信息为“这是什么”时,通过步骤S031无法获得准文本信息中的实体关键词。当通过步骤S207或步骤S205的殴打的实体关键词为“车顶灯”时,在步骤S033中将“车顶灯”添加到和“这是什么”中得到的目标文本信息为“车顶灯是什么”。
可选的,上述的目标文本信息可以用于问答系统或者控制系统。本申请以问答系统进行举例说明。
如图10和图11所示,在一些可选的实施例中,在通过步骤S03得到目标文本信息后,语音识别方法还包括:
步骤S04:确定目标文本信息在第一检索库中对应的多个候选文本,将目标文本信息和多个候选文本中的每一个候选文本分别进行拼接,形成多个输入文本。
可选的,各目标文本信息和各候选文本均构成一输入文本。即输入文本为目标文本信息和候选文本的统称。通过步骤S04可以对目标文本信息在第一检索库中进行粗筛得到多个候选文本。
步骤S05:对多个输入文本进行分词后输入深度学习模型以得到多个输出词组。
步骤S06:根据映射词典将多个输出词组映射为多个标签信息,映射词典包括输出词组与标签信息的映射关系。
基于深度数据集以及本地业务数据集,深度和微调深度学习模型,得到一个训练好的可用于文本匹配业务的深度学习模型。该深度学习模型包括但不限于基于RNN、Transformer的模型。
可选的,深度模型包括分词器和分词地址映射词典,该分词器包括但不限于jieba、基于BPE(Byte Pair Encoding)、Word Piece的分词器。通过分词器对多个输入文本进行分词后,继续通过映射词典映射为多个标签信息,将多个标签信息列表输入到深度模型中可以得到多个向量。各向量与各输入文本一一对应,即各向量与各候选文本一一对应。
步骤S07:将多个标签信息输入深度学习模型得到多个向量,深度学习模型包括候选文本和目标文本信息的匹配关系。
步骤S08:通过逻辑回归分类器将多个向量映射归一化为分类概率向量。
步骤S09:根据多个分类概率向量确定各候选文本与目标文本信息的语义相似度。
可选的,在步骤S07中获得的向量有多种,通过步骤S08可以将其映射并归一化为对应标签的分类概率向量。分类概率向量例如包括[X,Y],其中X+Y=1,X表示输出结果与输入文本的语义不匹配的概率,Y表示输出结果与输入文本的语义匹配概率。例如,当分类概率向量为[0.2,0.8]时,表示输出结果与输入文本的20%概率语义不匹配,输出结果与输入文本的80%概率语义匹配。
步骤S10:当多个输出词组中的最大语义相似度大于或等于相似阈值时,将与目标文本信息语义相似度最大候选文本作为最终文本;当多个输出词组的语义相似度均小于相似阈值时,拒绝语音识别。
在这些可选的实施例中,首先通过步骤S04确定多个候选文本,能够扩大语音识别结果的范围,不仅能够将目标文本信息输入深度模型得到输出结果,而且能够将与目标文本信息相关的候选文本也输入深度模型得到输出结果,最后通过步骤S09得到各输出结果与目标文本信息语义相似度,当多个输出结果中的最大语义相似度大于或等于相似阈值时,确定最大语义相似度对应的目标文本信息或候选文本为最终文本;当多个输出结果的语义相似度均小于相似阈值时,拒绝语音识别。
在一些可选的实施例中,语音识别方法还包括:根据最终文本和问答映射关系确定最终文本的应答信息,问答映射关系包括多个文本及其对应的应答信息。在这些可选的实施例中,根据问答映射关系可以得到最终文本的应答信息,即目标文本信息的应答信息。
在一些实施例中,当语音识别方法用于控制系统时,还可以根据最终文本或目标文本信息与控制映射关系输出控制信号,以达到控制的目的,控制映射关系包括文本与控制指令的映射关系。
如图12所示,本申请第二方面的实施例还提供一种语音识别装置,包括获取单元100、识别单元200和处理单元300,获取单元100用于获取语音信息和手势图像,识别单元200用于识别语音信息,得到语音信息的准文本信息,并识别手势图像中的手势,得到手势图像对应的手势信息,处理单元300用于在语音信息的发声对象和手势的操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到语音信息对应的目标文本信息。
可选的,处理单元300可以包括仲裁模块,仲裁模块用于判断发声对象和操作对象是否为同一对象,并在发声对象和操作对象为同一对象时,对手势信息和准文本信息进行融合处理,得到多模态的目标文本信息。在发声对象和操作对象不为同一对象时,令处理单元300直接将语音文本的准文本信息作为目标文本信息。
获取单元100例如包括多个麦克风的语音识别模块,仲裁模块可以根据多麦克风的语音识别模块获取语音信息的第一位置信息,即声源位置信息。获取单元100还可以包括多视觉传感器的手势识别模块,仲裁模块可以根据多视觉传感器的手势识别模块获取手势信息的第二位置信息,即手势位置信息。仲裁模块用于判断第一位置信息和第二位置信息是否来自同一对象,并判断手势信息中的手势方向。如果第一位置信息和第二位置信息之间的距离小于距离阈值,且手势信息中的手势方向有效,则处理单元300对手势信息和准文本信息进行融合处理,得到多模态的目标文本信息。否则,处理单元300直接将语音文本的准文本信息作为目标文本信息。
可选的,识别单元200还用于确定手势信息为预设手势信息。
可选的,识别单元200还用于识别手势图像中的手势,得到手势的位置和手势类型,并在手势类型为至少手势具有指向性的手势时,根据所手势的位置,确定手势的指向与交互空间实体模型的拓扑表面的交点坐标,并根据在交互空间实体模型的拓扑表面标注的实体标签,确定交点坐标对应的实体关键词信息。识别单元200获取的手势信息包括势的位置、手势类型以及实体关键词信息。
可选的,处理单元300还用于输出提示信息,提示信息用于提示用户是否指向实体关键词信息对应的实体;接收用户对提示信息的第一操作,并在第一操作为确认操作时,根据实体关键词信息,对准文本信息进行处理,得到语音信息对应的目标文本信息。
可选的,处理单元300还用于在第一操作为拒绝操作时,显示交互空间实体模型中与交点坐标相邻的相邻表面的候选标注标签;处理单元300还用于接收用户从候选标注标签中选取目标标注标签的选中操作;并根据目标标注标签,对准文本信息进行处理,得到语音信息对应的目标文本信息。
可选的,语音识别装置还包括建模单元,建模单元用于获取空间交互信号,空间交互信号包括对车座、天窗、车窗、方向盘、车载显示器、控制键中的至少一者的位置调整信息;并根据空间交互信号更新位于拓扑表面的标注标签的位置信息。
可选的,处理单元300还包括提取模块,提取模块用于从准文本信息中提取实体关键词信息,处理单元300还用于在提取到实体关键词信息,且提取到的实体关键词信息与指向的实体关键词信息不一致的情况下,将指向的实体关键词信息替换准文本中的实体关键词信息,得到目标文本信息;在未提取到实体关键词信息时,根据准文本信息的语义信息,将指向的实体关键词信息添加到准文本信息中,得到目标文本信息。
可选的,语音识别装置还包括初筛模块、计算模块和输出模块,初筛模块用于确定目标文本信息在第一检索库中对应的多个候选文本,目标文本信息和多个候选文本构成多个输入文本。计算模块用于对多个输入文本进行分词、并通过映射词典映射为多个标签信息后,将标签信息输入深度学习模型以得到多个向量;并通过逻辑回归分类器将多个向量映射归一化为分类概率向量,最后根据多个分类概率向量确定各候选文本与目标文本信息的语义相似度;当多个输出词组中的最大语义相似度大于或等于相似阈值时,将与目标文本信息语义相似度最大候选文本作为最终文本;当多个输出词组的语义相似度均小于相似阈值时,拒绝语音识别。
可选的,输出模块还用于根据最终文本和问答映射关系确定最终文本的应答信息,问答映射关系包括多个文本及其对应的应答信息。
本申请第三方面的实施例还提供一种语音识别设备,包括处理器、存储器及存储在存储器上并可在处理器上运行的计算机程序,计算机程序被处理器执行时实现上述任一第一方面实施例的语音识别方法的步骤。
本申请第四方面的实施例还提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述任一第一方面实施例的语音识别方法的步骤。
虽然已经参考优选实施例对本申请进行了描述,但在不脱离本申请的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,各个实施例中所提到的各项技术特征均可以任意方式组合起来。本申请并不局限于文中公开的特定实施例,而是包括落入权利要求的范围内的所有技术方案。
- 一种语音识别方法、装置、设备及介质
- 语音类别的识别方法、装置、计算机设备和存储介质
- 实时语音识别方法、装置、设备及存储介质
- 一种语音识别方法及装置、设备、介质
- 语音识别方法、装置、计算机设备及存储介质
- 语音设备的语音识别方法、语音设备及可读存储介质
- 语音设备的语音识别方法、语音设备及可读存储介质