边缘智能语音识别方法及系统装置
文献发布时间:2024-07-23 01:35:12
技术领域
本发明涉及语音信号处理技术领域,具体涉及边缘智能语音识别方法及系统装置。
背景技术
边缘智能语音识别是一种将语音识别技术应用于边缘设备的方法,传统的语音识别通常需要将音频数据上传到云端进行处理,而边缘智能语音识别则将语音识别模型和算法部署到本地设备上,实现在设备本身上进行实时的语音识别和命令执行,边缘智能语音识别能够在设备上实现实时的语音转文字功能,不依赖于云端的计算资源和网络连接。这样一来,用户可以在无网络环境下使用智能语音识别技术,提高了语音识别的实时性和可靠性,同时,边缘智能语音识别也减少了对云端的依赖,保护了用户的隐私和数据安全。
目前边缘智能语音识别方法及系统装置可能存在以下问题:1、大多边缘智能语音识别装置未在语音识别前对周围环境进行分析,不同的环境影响因素会对语音信号的采集和传输产生影响,如果未对这些因素进行分析,会导致语音识别的准确性下降,环境因素对语音输入过程产生负面影响会导致用户体验不佳。
2、设备性能分析可以帮助确定边缘智能语音识别设备的性能指标,包括识别错误率、识别响应时长,以及音频处理过程中对应的采样率和位深度,如果未进行设备性能分析,可能无法匹配适当的设备,导致使用性能不佳的设备进行语音识别,从而影响系统的准确性和效率,音频综合分析的目的是综合考虑用户音频质量评估系数和环境影响因子进行综合评价,如果未进行音频综合分析,无法全面了解音频质量和环境对语音识别的影响,导致无法准确判断音频是否符合要求,从而无法及时采取预处理措施。
发明内容
本发明的目的在于提供的边缘智能语音识别方法及系统装置,解决了背景技术中存在的问题。
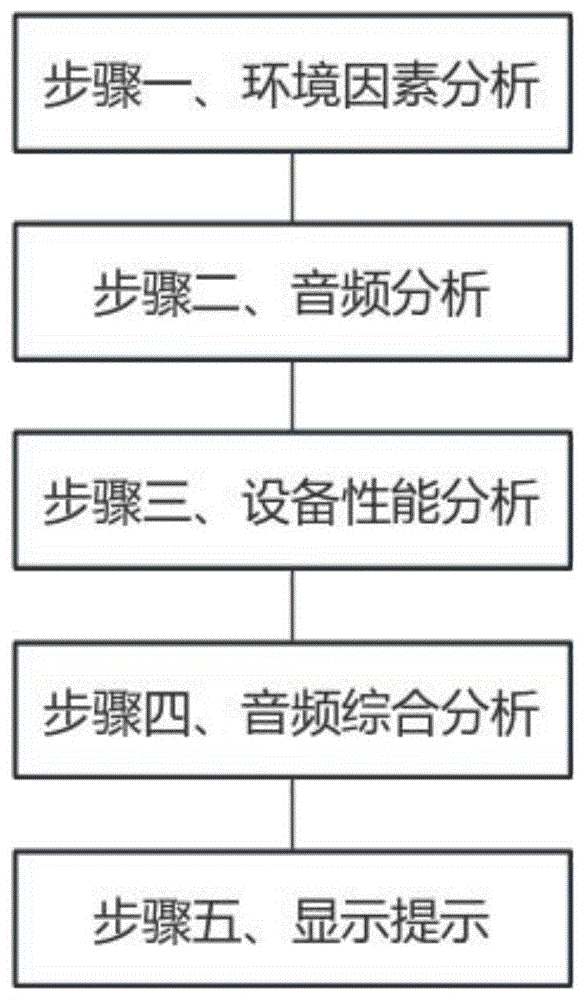
为解决上述技术问题,本发明采用如下技术方案:本发明提供边缘智能语音识别方法,包括:步骤一、环境因素分析:在指定场景下,在用户通过麦克风开始说话前,获取指定场景下对应的环境影响参数,环境影响参数包括噪音水平、回声时长,进而分析得到指定场景对应的环境影响因子,由此分析指定场景下的环境因素对智能语音识别过程的影响。
步骤二、音频分析:当指定场景下的环境因素对智能语音识别过程的影响较大时,通过边缘智能语音识别系统分析得到用户在通过麦克风说话时需要调整的音频响度和与麦克风的距离,并从指定边缘设备管理手册中获取的信号通路数量,进而计算得到用户对应的音频质量评估系数。
步骤三、设备性能分析:从边缘智能语音识别设备管理手册中获取对应的性能信息,性能信息包括语音识别错误率、识别响应时长、采样率、位深度,进而分析得到边缘智能语音识别设备对应的性能评估系数。
步骤四、音频综合分析:根据用户对应的音频质量评估系数、指定场景对应的环境影响因子,进而分析得到指定场景下用户对应的音频综合评估系数,根据边缘智能语音识别设备对应的性能评估系数,由此分析指定场景下用户对应的音频是否符合要求,当指定场景下用户对应的音频不符合要求时,进而将指定场景下用户对应的音频进行预处理。
步骤五、显示提示:当指定场景下的环境因素对智能语音识别过程的影响较大、当指定场景下用户对应的音频不符合要求时,进行显示提示。
优选地,所述获取指定场景下对应的环境影响因素,具体获取过程如下:S1、使用指定的麦克风设备进行声音信号采集,对采集到的声音信号进行滤波,采用频谱分析算法的噪音估计算法,从而得到噪音水平;
S2、选择设定能量强度的声音信号作为发送源,在发出声音信号的同时,通过指定软件工具记录下发出声音的时间点,在录制的音频中,找到回声信号的波形,在检测到回声信号的波形后,记录下回声信号到达麦克风的时间点,通过计算发出声音和回声信号之间的时间差,从而得到回声时长。
优选地,所述分析得到指定场景对应的环境影响因子,具体分析过程如下:根据指定场景下对应的噪音水平、回声时长,通过计算公式
优选地,所述分析指定场景下的环境因素对智能语音识别过程的影响,具体分析过程如下:将指定场景对应的环境影响因子与设定的环境影响因子阈值进行比较,若指定场景对应的环境影响因子大于或者等于设定的环境影响因子阈值,则判定指定场景下的环境因素对智能语音识别过程影响较大,若指定场景对应的环境影响因子小于设定的环境影响因子阈值,则判定指定场景下的环境因素对智能语音识别过程影响较小。
优选地,所述计算得到用户对应的音频质量评估系数,具体计算过程如下:将用户说话时对应的音频响度、与麦克风的距离,以及指定边缘设备对应的信号通路数量代入计算公式
得到用户对应的音频质量评估系数β,其中B、C分别表示户说话时对应的音频响度、与麦克风的距离,E表示指定边缘设备对应的信号通路数量,B′、C′、E′分别为设定的标准音频响度、与麦克风的标准距离、标准信号通路数量,ΔB、ΔC、ΔE分别为设定的许可音频响度差、许可与麦克风的距离差、许可信号通路数量差,η
优选地,所述分析得到边缘智能语音识别设备对应的性能评估系数,具体分析过程如下:将边缘智能语音识别设备对应的语音识别错误率、识别响应时长,以及采样率和位深度代入计算公式
优选地,所述分析得到指定场景下用户对应的音频综合评估系数,具体计算过程如下:根据指定场景对应的环境影响因子、用户对应的音频质量评估系数,通过计算公式ψ=α*λ
优选地,所述分析指定场景下用户对应的音频是否符合要求,具体分析过程如下:根据边缘智能语音识别设备对应的性能评估系数、指定场景下用户对应的音频综合评估系数,将用户对应的音频综合评估系数与边缘智能语音识别设备对应的性能评估系数区间进行比较,若某用户对应的音频综合评估系数属于边缘智能语音识别设备对应的性能评估系数区间内,则判定该用户对应的音频符合要求,若某用户对应的音频综合评估系数不属于边缘智能语音识别设备对应的性能评估系数区间内,则判定该用户对应的音频不符合要求,由此分析指定场景下用户对应的音频是否符合要求。
本发明在第二方面提供了边缘智能语音识别系统装置,包括:环境因素分析模块,用于在指定场景下,在用户通过麦克风开始说话前,获取指定场景下对应的环境影响参数,环境影响参数包括噪音水平、回声时长,进而分析得到指定场景对应的环境影响因子,由此分析指定场景下的环境因素对智能语音识别过程的影响。
音频分析模块,当指定场景下的环境因素对智能语音识别过程的影响较大时,通过边缘智能语音识别系统分析得到用户在通过麦克风说话时需要调整的音频响度和与麦克风的距离,并从指定边缘设备管理手册中获取的信号通路数量,进而计算得到用户对应的音频质量评估系数。
设备性能分析模块,从边缘智能语音识别设备管理手册中获取对应的性能信息,性能信息包括语音识别错误率、识别响应时长、采样率、位深度,进而分析得到边缘智能语音识别设备对应的性能评估系数。
音频综合分析模块,用于根据用户对应的音频质量评估系数、指定场景对应的环境影响因子,进而分析得到指定场景下用户对应的音频综合评估系数,根据边缘智能语音识别设备对应的性能评估系数,由此分析指定场景下用户对应的音频是否符合要求,当指定场景下用户对应的音频不符合要求时,进而将指定场景下用户对应的音频进行预处理。
显示终端,当指定场景下的环境因素对智能语音识别过程的影响较大、当指定场景下用户对应的音频不符合要求时,进行显示提示。
本发明的有益效果在于:1、本发明提供的边缘智能语音识别方法及系统装置,通过分析当前指定场景下的噪音水平和回声时长,得到指定场景下的环境因素对智能语音识别过程的影响程度,从而边缘智能语音识别系统在屏幕中显示用户说话时需要的音频响度和与麦克风的距离,音频综合分析模块结合了用户的音频质量评估系数和指定场景的环境影响因子,从而得到更全面的音频综合评估系数,在噪音较高的环境中,系统可以建议用户调整说话声音的音量和与麦克风的距离,以提高识别准确性,使得系统可以更准确地评估每个用户在特定场景下的音频质量。
2、本发明实施例通过设备性能分析模块的评估结果,边缘智能语音识别系统根据用户和设备的匹配程度,对音频识别过程进行自适应调整,从而提高识别准确性和减少误识别的风险,有助于提高整体的识别效果,通过将用户的音频综合评估系数与边缘智能语音识别设备的性能评估系数进行比较,系统可以实现对用户音频是否符合设备性能要求的实时匹配,有助于确保音频的语音识别效果和设备性能匹配度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施步骤流程示意图。
图2为本发明系统结构连接示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1所示,本发明提供了边缘智能语音识别方法,该方法包括:
步骤一、环境因素分析:在指定场景下,在用户通过麦克风开始说话前,获取指定场景下对应的环境影响参数,环境影响参数包括噪音水平、回声时长,进而分析得到指定场景对应的环境影响因子,由此分析指定场景下的环境因素对智能语音识别过程的影响。
在一个具体的实施例中,所述获取指定场景下对应的环境影响因素,具体获取过程如下:S1、使用指定的麦克风设备进行声音信号采集,对采集到的声音信号进行滤波,采用频谱分析算法的噪音估计算法,从而得到噪音水平;
S2、选择设定能量强度的声音信号作为发送源,在发出声音信号的同时,通过指定软件工具记录下发出声音的时间点,在录制的音频中,找到回声信号的波形,在检测到回声信号的波形后,记录下回声信号到达麦克风的时间点,通过计算发出声音和回声信号之间的时间差,从而得到回声时长。
在一个具体的实施例中,所述分析得到指定场景对应的环境影响因子,具体分析过程如下:根据指定场景下对应的噪音水平、回声时长,通过计算公式
需要说明的是,κ
在一个具体的实施例中,所述分析指定场景下的环境因素对智能语音识别过程的影响,具体分析过程如下:将指定场景对应的环境影响因子与设定的环境影响因子阈值进行比较,若指定场景对应的环境影响因子大于或者等于设定的环境影响因子阈值,则判定指定场景下的环境因素对智能语音识别过程影响较大,若指定场景对应的环境影响因子小于设定的环境影响因子阈值,则判定指定场景下的环境因素对智能语音识别过程影响较小。
步骤二、音频分析:当指定场景下的环境因素对智能语音识别过程的影响较大时,通过边缘智能语音识别系统分析得到用户在通过麦克风说话时需要调整的音频响度和与麦克风的距离,并从指定边缘设备管理手册中获取的信号通路数量,进而计算得到用户对应的音频质量评估系数。
需要说明的是,信号通路数量指的是音频信号中的独立声道数量,每个声道可以传输独立的音频信息,信号通路数量决定了音频的立体声效果和声场表现能力。
在一个具体的实施例中,所述计算得到用户对应的音频质量评估系数,具体计算过程如下:将用户说话时对应的音频响度、与麦克风的距离,以及指定边缘设备对应的信号通路数量代入计算公式
需要说明的是,η
步骤三、设备性能分析:从边缘智能语音识别设备管理手册中获取对应的性能信息,性能信息包括语音识别错误率、识别响应时长、采样率、位深度,进而分析得到边缘智能语音识别设备对应的性能评估系数。
需要说明的是,采样率是指在一定时间内对模拟信号进行采样的次数,采样率越高,采集到的数据越多,能够更准确地还原原始声音,位深度是指用于表示每个样本值的比特数,较低的位深度表示音频信号被精确度较低地量化,较高的位深度可以得到更精确的音频表示。
还需要说明的是,通过对语音识别系统进行测试,使用一系列已知文本录制的语音样本进行输入,然后对比系统输出的文字识别结果与真实文本进行对比,从而得到语音识别错误率,通过记录语音输入的开始时间和结束时间,同时记录系统输出结果的时间,从而得到识别响应时长。
在一个具体的实施例中,所述分析得到边缘智能语音识别设备对应的性能评估系数,具体分析过程如下:将边缘智能语音识别设备对应的语音识别错误率、识别响应时长,以及采样率和位深度代入计算公式
需要说明的是,ι
步骤四、音频综合分析:根据用户对应的音频质量评估系数、指定场景对应的环境影响因子,进而分析得到指定场景下用户对应的音频综合评估系数,根据边缘智能语音识别设备对应的性能评估系数,由此分析指定场景下用户对应的音频是否符合要求,当指定场景下用户对应的音频不符合要求时,进而将指定场景下用户对应的音频进行预处理。
需要说明的是,当指定场景下用户对应的音频不符合要求时,用户再次通过麦克风说话进行语音识别,并通过边缘智能语音识别设备进行预处理,预处理包括降噪、声音增强,达到提升音频质量、降低噪音影响的目的。
在一个具体的实施例中,所述分析得到指定场景下用户对应的音频综合评估系数,具体计算过程如下:根据指定场景对应的环境影响因子、用户对应的音频质量评估系数,通过计算公式ψ=α*λ
需要说明的是,λ
在一个具体的实施例中,所述分析指定场景下用户对应的音频是否符合要求,具体分析过程如下:根据边缘智能语音识别设备对应的性能评估系数、指定场景下用户对应的音频综合评估系数,将用户对应的音频综合评估系数与边缘智能语音识别设备对应的性能评估系数区间进行比较,若某用户对应的音频综合评估系数属于边缘智能语音识别设备对应的性能评估系数区间内,则判定该用户对应的音频符合要求,若某用户对应的音频综合评估系数不属于边缘智能语音识别设备对应的性能评估系数区间内,则判定该用户对应的音频不符合要求,由此分析指定场景下用户对应的音频是否符合要求。
本发明实施例通过设备性能分析模块的评估结果,边缘智能语音识别系统根据用户和设备的匹配程度,对音频识别过程进行自适应调整,从而提高识别准确性和减少误识别的风险,有助于提高整体的识别效果,通过将用户的音频综合评估系数与边缘智能语音识别设备的性能评估系数进行比较,系统可以实现对用户音频是否符合设备性能要求的实时匹配,有助于确保音频的语音识别效果和设备性能匹配度。
步骤五、显示提示:当指定场景下的环境因素对智能语音识别过程的影响较大、当指定场景下用户对应的音频不符合要求时,进行显示提示。
需要说明的是,当指定场景下的环境因素对智能语音识别过程的影响较大时,边缘智能语音识别系统通过在屏幕上显示由于指定场景下的环境因素对智能语音识别过程的影响较大,进而用户说话时需要的音频响度和与麦克风的距离,以及在用户说话结束后,当指定场景下用户对应的音频不符合要求时,在屏幕上显示用户对应的语音识别不成功,从而达到显示提示的目的。
请参阅图2所示边缘智能语音识别系统装置,包括:环境因素分析模块、音频分析模块、设备性能分析模块、音频综合分析模块、显示终端。
所述环境因素分析模块与音频分析模块,音频分析模块与设备性能分析模块连接,设备性能分析模块与音频综合分析模块连接,音频综合分析模块与显示终端连接。
环境因素分析模块,用于在指定场景下,在用户通过麦克风开始说话前,获取指定场景下对应的环境影响参数,环境影响参数包括噪音水平、回声时长,进而分析得到指定场景对应的环境影响因子,由此分析指定场景下的环境因素对智能语音识别过程的影响。
音频分析模块,当指定场景下的环境因素对智能语音识别过程的影响较大时,通过边缘智能语音识别系统分析得到用户在通过麦克风说话时需要调整的音频响度和与麦克风的距离,并从指定边缘设备管理手册中获取的信号通路数量,进而计算得到用户对应的音频质量评估系数。
设备性能分析模块,从边缘智能语音识别设备管理手册中获取对应的性能信息,性能信息包括语音识别错误率、识别响应时长、采样率、位深度,进而分析得到边缘智能语音识别设备对应的性能评估系数。
音频综合分析模块,用于根据用户对应的音频质量评估系数、指定场景对应的环境影响因子,进而分析得到指定场景下用户对应的音频综合评估系数,根据边缘智能语音识别设备对应的性能评估系数,由此分析指定场景下用户对应的音频是否符合要求,当指定场景下用户对应的音频不符合要求时,进而将指定场景下用户对应的音频进行预处理。
显示终端,当指定场景下的环境因素对智能语音识别过程的影响较大、当指定场景下用户对应的音频不符合要求时,进行显示提示。
本发明提供的边缘智能语音识别方法及系统装置,通过分析当前指定场景下的噪音水平和回声时长,得到指定场景下的环境因素对智能语音识别过程的影响程度,从而边缘智能语音识别系统在屏幕中显示用户说话时需要的音频响度和与麦克风的距离,音频综合分析模块结合了用户的音频质量评估系数和指定场景的环境影响因子,从而得到更全面的音频综合评估系数,在噪音较高的环境中,系统可以建议用户调整说话声音的音量和与麦克风的距离,以提高识别准确性,使得系统可以更准确地评估每个用户在特定场景下的音频质量。
以上内容仅仅是对本发明的构思所作的举例和说明,所属本技术领域的技术人员对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离发明的构思或者超越本说明书所定义的范围,均应属于本发明的保护范围。
- 智能语音系统及其语音唤醒方法及智能语音设备
- 应用于智能语音鼠标的文字识别方法、装置、系统和存储介质
- 机器视觉缺陷识别方法和系统、边缘侧装置及存储介质