语音识别前端设备、系统和方法
文献发布时间:2024-07-23 01:35:12
技术领域
本发明涉及语音识别和声信号处理技术领域,尤其涉及一种语音识别前端设备、系统和方法。
背景技术
接收声音信号是语音识别或声信号处理的第一个步骤。在声信号被接收时,声波最先接触到的是声学结构,然后是声电转换器。良好的声学结构设计可以为后续语音识别或声信号处理提供更大的可能性。例如,人的外耳在汇聚信号能量的同时,其独特的声学结构可以使信号在空间上具有稀疏性和可辨识性。人的中耳的声学结构通过谐振放大可将感知灵敏度提高约15dB~20dB。耳蜗中大量毛细胞所构成的分频感知结构保证了整个语音频段内的机电转换可靠性。
人耳结构精妙复杂,直接仿生极其困难。但即使从利用基础原理的方面看,对于当前接收声信号的麦克风而言,其在声学设计和谐振原理利用方面仍存在明显的不足。表现为缺乏外耳这样的声学波导、麦克风谐振腔结构简单。这意味着信号接收完全决定于麦克风自身的指向性,会导致无法汇聚能量、抑制干扰和编码方向的问题,也不能从物理上充分放大远场信号。
当前已有方案的总结和缺陷分析如下:
1)CN104127912B:耳蜗及耳蜗毛细胞仿生声学超材料设计方法。结构过于复杂,过分关注于耳蜗的每个细节,忽略了结构,电,算法的协同配合。用性质和人耳差距明显的已知材料可以模仿耳蜗的所有细节,显然难以达到理想的效果,成本也会大大增加。如用金属或纤维材料代替软骨,这两种材料本身就难以达到软骨的性能水平。用合成纤维代替纤毛,而纤毛本身的复杂结构就和纤维差别巨大。因此,在把握耳蜗的机理前提下,充分考虑已有的技术水平和实现难度,设计简约的人耳将有更大的价值。
可以看出,已有方案存在如下问题:
1)部分方案过渡追求直接复刻人耳,难度大,成本高,已有材料和工艺难以支撑。
2)缺乏高效的阻抗变换,能量接收过程中损失大。
3)对不同方向的声音信号缺乏物理编码。
4)缺乏通过物理手段对人声频段进行放大和抑制噪声的手段。
5)硬件、算法、声学结构未能实现很好地配合。
综上所述,当前的语音识别前端对物理规律利用不足,结构过于复杂,性能严重落后于人耳。
发明内容
本发明的目的是提供一种语音识别前端设备、系统和方法,以解决现有技术中的语音识别前端设备对物理规律利用不足或者结构过于复杂或者结构、硬件、算法配合不充分的问题。
为了实现上述目的,根据本发明的第一方面,提供了一种语音识别前端设备,蜗管结构和声音传感器,蜗管结构具有螺旋腔体,螺旋腔体的横截面的面积由外向内逐渐减小,蜗管结构设有至少一个与螺旋腔体连通的声音输出孔;螺旋腔体的位于外侧的腔体入口用于声音输入;声音输出孔处均安装有声音传感器,并且通过声音传感器的安装使声音输出孔对外密闭。
进一步地,当蜗管结构具有1个声音输出孔时,该声音输出孔与螺旋腔体的内侧末端连通;当蜗管结构具有多于1个的声音输出孔时,声音输出孔的部署位置是目标频率在螺旋腔体中产生驻波的波峰的位置。
进一步地,蜗管结构的声音输出孔的末端与声音传感器的声音接收部分的拾音孔结构平滑连接。
进一步地,在至少一个目标频率所对应的驻波的波峰的位置部署至少2个声音输出孔。
进一步地,语音识别前端设备还包括声学波导结构,声学波导的内壁由多个曲面平滑连接而成,声学波导结构具有声波出口;多个曲面用于对入射声波进行反射和/或衍射,以聚焦入射声波并使入射声波进入声波出口;声波出口与螺旋腔体的位于外侧的腔体入口连通;多个曲面的总面积的50%以上为二次曲面和/或三次曲面和/或四次曲面。
这里的二次曲面指的是三维空间中满足三元二次方程的曲面,如柱面、锥面、双曲面等。这里的三次曲面指的是三维空间中满足三元三次方程的曲面,如贝塞尔曲面、劈锥曲面等。这里的四次曲面指的是三维空间中满足三元四次方程的曲面。这里通过限定曲面的次数,约束曲面的复杂度,进而控制声学波导结构的复杂度。
进一步地,语音识别前端设备还包括谐振管结构和声学波导结构,语音识别前端设备还包括声学波导结构,声学波导结构的内壁由多个曲面平滑连接而成,声学波导结构具有声波出口;多个曲面用于对入射声波进行反射和/或衍射,以聚焦入射声波并使入射声波进入声波出口;多个曲面的总面积的50%以上为二次曲面和/或三次曲面和/或四次曲面;谐振管结构设置在声学导波结构和蜗管结构之间,谐振管结构的入口与声学波导结构的声波出口连通,谐振管结构的出口与螺旋腔体的位于外侧的腔体入口连通。
进一步地,语音识别前端设备还包括与声音传感器连接的可编程增益放大器和/或带通滤波器,可编程增益放大器的增益可以被控制,带通滤波器的中心频率可以被控制。
根据本发明的第二方面,本发明还提供了一种语音识别系统,语音识别系统包括:语音识别前端设备,语音识别前端设备为上述的语音识别前端设备;语音识别模块,语音识别模块与语音识别前端设备信号连接,语音识别前端设备向语音识别模块发送声音信号,语音识别模块向语音识别前端设备发送反馈信号;语音识别模块利用特征提取单元和识别单元依次对声音信号进行处理,形成文本输出;识别单元的反馈连接特征提取单元,特征提取单元的反馈连接语音识别前端设备的可编程放大器和/或带通滤波器。
根据本发明的第三方面,本发明还提供了一种语音识别方法,利用上述的语音识别系统执行语音识别方法,语音识别方法包括如下步骤:步骤1:根据语音识别系统的识别单元的识别结果的回溯找到对应的目标特征,从而引出反馈;步骤2:将反馈输入到特征提取部分,调节候选特征数量,并跟踪目标特征;步骤3:从特征提取中继续回溯,找到目标特征对应的频率,引出反馈;步骤4:根据反馈信号调节可编程增益放大器的增益和/或带通滤波器的中心频率,从硬件层面实现对目标特征的聚焦和/或对干扰的抑制。
进一步地,语音识别方法还包括如下步骤:在识别初始阶段,通过增加候选特征的数量,增加目标特征进入识别算法的概率;在识别初始阶段之外的阶段,通过反馈调节,抑制非目标特征的输入,提高计算效率和/或识别准确率。
应用本发明的技术方案,蜗管结构避免了完全复刻耳蜗的复杂形状和功能,以声音传播的物理规律为依据,通过结构和硬件的联合设计,实现了高效的阻抗变换和信号接收质量的提升,为后续的语音识别或声信号处理提供了更有力的支撑。
声学导波结构采用由多个曲面平滑连接而成的简化结构,避免了完全复刻外耳的复杂几何形状,同时能够保证声音信号的更好接收,此外,多个曲面结构可以使不同方向到来的声波的传播距离产生差异,进而产生声时间差,从而在物理上实现对不同方向声音信号的编码。
本申请在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
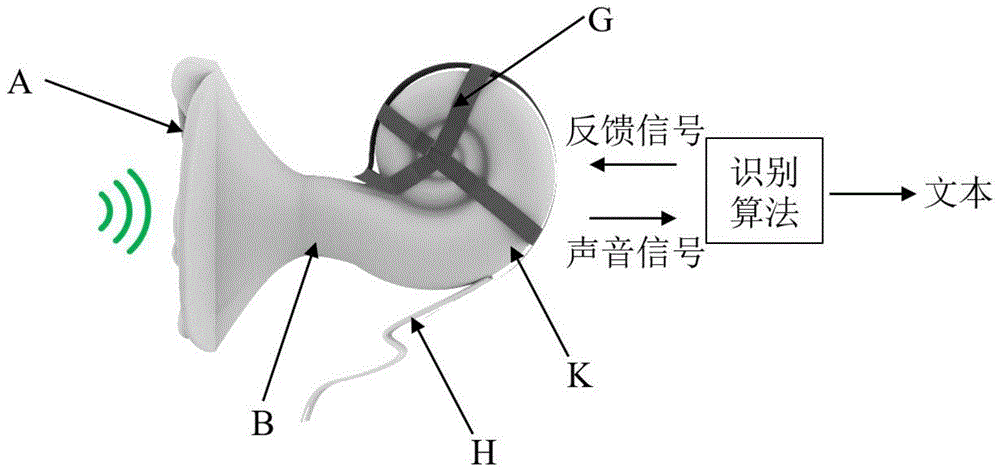
图1示出了本发明可选实施例中的语音识别前端系统的整体架构;
图2示出了本发明可选实施例中的语音识别前端设备中部分结构的剖视图;
图3示出了本发明可选实施例中的声学波导结构对声信号的处理的示意图,其中,声学导波结构采用简化的仿生人耳设计,利用多个曲面使不同角度的声波经过至多三次的反射和/或衍射后,即可进入声波出口;
图4和图5示出了本发明可选实施例中的蜗管结构和多个声音传感器的装配关系,其中,在蜗管结构的内侧末端安装一个声音传感器,在蜗管结构的侧面部署多个声音传感器;
图6示出了本发明可选实施例中的语音识别前端设备的声音传感器、柔性PCB结构和线缆之间的电气连接关系;
图7示出了本发明可选实施例中的蜗管结构和多个声音传感器的装配关系,其中,在蜗管结构上选取多个剖面布置多个声音传感器,每个剖面上均成对部署两个声音传感器;
图8示出了语音识别前端设备的硬件架构;
图9示出了一个可选实施例中蜗管结构的声音输出孔的末端与MEMS声音传感器的拾音孔结构在几何上的平滑关系;
图10示出了在一个优选实施例的蜗管结构中,对于某个频率信号具有相同驻波的波峰的截面,在该截面前后两侧部署两个声音输出孔的方法,以及声音输出孔与MEMS声音传感器的拾音孔在几何上的平滑关系。
附图标号说明:
A、声学波导结构;B、谐振管;C、螺旋腔体;D、声音输出孔;E、声波出口;F、声音传感器;G、柔性PCB结构;H、线缆;K、蜗管结构。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。
如图1至图8所示,本发明提供了一种语音识别前端设备,包括声学波导结构A,声学波导结构A由多个曲面平滑连接而成,声学波导结构具有声波出口E;多个曲面用于对非正对声波出口E方向的声波进行反射和/或衍射,以使声波进入声波出口E。
在本发明中,声学波导结构是由多个曲面平滑连接,且带有声波出口的简化仿生结构;声学波导结构中不同区域的曲面,是所有曲面中主要用于将指定入射角度范围内的声波反射和/或衍射进声学波导结构的声波出口E的曲面。直接仿生生物外耳结构的问题是,外耳结构形貌复杂,这不仅对声波的反射、衍射建模分析提出了巨大挑战,也不利于实际加工。本发明采用由多个曲面平滑连接而成的简化结构,避免了完全复刻外耳的复杂几何形状。通过反射曲面的分区设计,在不同区域处理不同方向的声波信号,在有限的结构复杂度下实现对外耳方向敏感性的模拟。因为非正对声波出口方向的声波需要经过至少一个曲面的至少一次反射和/或衍射才能进入声波出口。这样曲面可以使不同方向到来的声波的传播距离产生差异,进而产生声时间差。而且还可以通过成对配合使用实现对双耳效应的模拟,即进一步在声波传播过程中引入声波到达双耳的时间差和强度差,由此实现对生物外耳声源定位功能的仿生。
可选地,如图3所示,声波经过1个或2个或3个曲面的大于等于1次且小于等于3次的反射和/或衍射后,进入声波出口E。这样,在保证声音信号能够被更好接收的基础上,降低声学波导结构的成本。
由于人外耳结构不规则、非常复杂,本申请采用简化版的外耳设计,而对于多个曲面的具体方案,在实际设计时,变化性非常大,因为反射、衍射次数直接反映了结构的复杂程度,为了对曲面的设计进行进一步地限定,本发明对反射和/或衍射的次数进行了限制,从而避免声学波导结构的结构过于复杂,成本过高。
只要满足本申请要求的多个曲面设计的方案都属于本申请的保护范围,而对于具体曲面的设计采用本领域的常规技术手段可以获得,在此不再赘述。
可选地,语音识别前端设备还包括谐振管B,谐振管B的入口与声学波导结构A的声波出口E连通。
当前的声信号接收直接进入麦克风或者经过非常简单的结构就进入麦克风。问题是:麦克风的谐振腔体很小,难以放大低频信号。本发明引入谐振管B,该谐振管B的尺寸远大于麦克风的谐振腔体,可以通过谐振管B产生的声筒效应从物理上放大声信号,提升信号接收灵敏度。此外,谐振管还可以配合声学波导结构实现对不同入射角声波路径差的放大,这有助于声源定位精度的提升。因为,即使刚进入谐振管入口处的声波具有很小的角度差异,声波在谐振管中经历的多次反射也会逐渐放大该差异,并使谐振管的声波输出时间具有更明显的不同。
可选地,语音识别前端设备还包括蜗管结构K,蜗管结构K具有螺旋腔体C,螺旋腔体C的横截面积由外向内逐渐减小,蜗管结构K设有至少一个与螺旋腔体C连通的声音输出孔D;螺旋腔体C的位于外侧的腔体入口与声波出口E连通。
当前的声信号普遍直接进入MEMS声音传感器,或者经过简单的开孔结构进入MEMS声音传感器。问题是:声信号接收过程缺乏高效的阻抗变换,信号能量损失大,对声信号的物理放大严重不足。本发明通过螺旋腔体C从外向内截面积的减少,可以实现声信号接收过程中的阻抗变换,有利于信号能量的收集。同时,螺旋腔体在一定程度上也形成了封闭结构,这有利于通过物理谐振放大声音信号。
可选地,如图2所示,语音识别前端设备还包括谐振管B和蜗管结构K,蜗管结构K具有螺旋腔体C,螺旋腔体C的横截面积由外向内逐渐减小,蜗管结构K设有至少一个与螺旋腔体C连通的声音输出孔D,谐振管B设置在声学导波结构A和蜗管结构C之间,谐振管B的入口与声学波导结构A的声波出口E连通,谐振管B的出口与螺旋腔体C的位于外侧的腔体入口连通。这样,利用谐振管B产生的声筒效应从物理上放大声信号,提升信号接收灵敏度,谐振管还可以配合声学波导结构实现对不同入射角声波路径差的放大,这有助于声源定位精度的提升,同时通过螺旋腔体C实现声信号接收过程中的阻抗变换,有利于信号能量的收集,螺旋腔体C在一定程度上也形成了封闭结构,这有利于通过物理谐振放大声音信号。
可选地,如图4至图7所示,语音识别前端设备还包括声音传感器F,声音传感器F安装在声音输出孔D处,并且通过声音传感器F的安装使声音输出孔D对外密闭。这样,先利用声学导波结构A和螺旋腔体C对声音信号进行处理,再利用声音传感器F对声音信号进行收集,更有利于声音信号的收集。
可选地,每个声音输出孔D上安装有至少一个声音传感器F。
可选地,螺旋腔体C的至少一个截面位置包括至少两个声信号输出孔D。每个截面位置的声音传感器通过信号求和的方式提升信噪比。
可选地,当蜗管结构上安装一个声音传感器时,在蜗管结构K的内侧末端设置一个声音输出孔D,该声音输出孔的角度可以改变,以适应声学影响和装配影响,将该声音传感器F安装在该声音输出孔D处。
可选地,当蜗管结构上安装有多个声音传感器F时,在蜗管结构K的内侧末端设置一个声音输出孔D,该声音输出孔的角度可以改变,在蜗管结构K的侧面设置多个声音输出孔D,各声音输出孔D处均安装有一个声音传感器F。
可选地,如图7所示,声音传感器F采用MEMS声音传感器,成对部署在每个螺旋腔体C的剖面上。在考虑成本,实际加工可行性的前提下,本发明提出了通过部署多个MEMS声音传感器提升信号接收灵敏度的方案。
本发明的优选实施例为在蜗管结构K的内侧末端部署一个声音传感器,然后从螺旋腔体选出几个剖面,每个剖面处对应部署两个或者多个声音传感器,这样可以通过并联声音传感器提升该位置处的信号质量。结合图7可以看到每个剖面部署两个声音传感器的状态。
可选地,声音传感器F采用特别小的硅麦。
当前麦克风接收信号仅依靠MEMS声音传感器,但MEMS声音传感器面积非常小。相比之下,人耳蜗内感知声音的毛细胞数量上万,无论是在数量和感知面积上都远远超过单一的MEMS声音传感器,更多的数量和面积有利于更充分的感知震动,提升灵敏度。所以,在本发明的优选实施例中,设置了多个声音传感器,有利于提升灵敏度。
可选地,各声音传感器F的安装位置是目标频率在螺旋腔体C的内部产生驻波波峰的位置。这样,利用驻波效应提升声音传感器F处的声压强度,提高声音信号质量。
螺旋腔体内会产生驻波,驻波的位置和声音信号的频率有关,驻波波峰的位置可以通过仿真或者物理声学计算或者几何计算得到。驻波的计算方式可采用本领域的常规技术手段,本发明的重点在于保护声音传感器F的安装位置选择,即目标频率产生驻波的波峰的位置。
更多的声音传感器排布理论上更优于单一的声音传感器,但充分利用物理规律是实现这一优势的关键。本发明通过设置声音传感器的排布方式,提升声音信号的接收灵敏度。具体是将声音传感器的部署位置设置为螺旋腔体产生驻波频率的波峰位置与目标频率相符合,这意味着可以充分利用物理结构的信号放大作用。此外,由于实际中不同声音传感器对于不同频率的灵敏度可能是有差异的,而不同的声信号接收孔对声音传感器的频率需求也不同。因此,实际可以通过适配与不同驻波频率相匹配的声音传感器的方法进一步提升声音信号接收质量。
如图1和图6所示,语音识别前端设备还包括:柔性PCB结构G,多个声音传感器均与柔性PCB结构G与连接;线缆H,线缆H的一端与柔性PCB结构G连接,线缆H的另一端用于声音电信号的输出。
可选地,如图8所示,语音识别前端设备还包括与声音传感器F连接的可编程增益放大器(PGA)和/或带通滤波器(BP),可编程增益放大器的增益可以被控制,带通滤波器的中心频率可以被控制。
已有方案的声音传感器输出通常直接进入后端处理算法,后端处理算法的反馈也都局限在算法内,很少触及硬件。这并未发挥硬件部分的优势,也限制了整个系统对微弱信号的处理能力。本发明增加了可编程增益放大器和/或带通滤波器,并提供了反馈调节接口。这种硬件上的调节相比于已有方案从软件上的调节更靠近信号接收端,调节作用将更为明显、有效,可以实现对目标信号更有效地聚焦。
如图1所示,本发明还提供了一种语音识别系统,语音识别系统包括:语音识别前端设备,语音识别前端设备为上述或下述的语音识别前端设备;语音识别模块,语音识别模块与语音识别前端设备信号连接,语音识别前端设备用于向语音识别模块发送声音信号,语音识别模块用于向语音识别前端设备发送反馈信号;语音识别模块利用特征提取单元和识别单元依次对声音信号进行处理,形成文本输出;识别单元的反馈连接特征提取单元,特征提取单元的反馈连接语音识别前端设备的可编程放大器和/或带通滤波器。这样,本申请将语音识别前端设备和后端的特征提取单元和识别单元结合在一起,形成语音识别系统,特征提取单元采用特征提取算法对声音信号进行特征提取,识别单元利用识别算法对提取到的特征进行处理,形成文本输出,本发明的语音识别前端设备能够在接收声音信号时实现声波的能量汇聚,不同方向声波的物理编码,以及对非目标方向信号物理抑制的功能,从而有利于语音识别模块后续的处理,提升精度和/或效率。
可选地,本发明还提供了一种语音识别方法,利用上述的语音识别系统执行语音识别方法,语音识别方法包括如下步骤:步骤1:根据语音识别系统的识别单元的识别结果的回溯找到对应的目标特征,从而引出反馈;步骤2:将反馈输入到特征提取部分,调节候选特征数量,并跟踪目标特征;步骤3:从特征提取中继续回溯,找到目标特征对应的频率,引出反馈;步骤4:用反馈调节可编程增益放大器的增益和/或带通滤波器的中心频率,从硬件层面实现对目标特征的聚焦和/或对干扰的抑制。本发明具体给出了反馈调节的实现方法,步骤简单,有效。本发明提供的语音识别方法能够从更靠近信号输入的位置对信号进行处理,从而提高语音识别的精度和/或效率。
已有识别方案对于特征的处理流程是固定的,好处是逻辑简单清晰。缺点是不能自动根据声信号的实际情况动态调节音频信号的特征数量、特征选择方法,以及子带增益,而本申请通过反馈调节的方法能够动态调节音频信号的特征数量、特征选择方法,以及子带增益。
可选地,语音识别方法还包括如下步骤:在识别初始阶段,通过增加候选特征的数量,增加目标特征进入识别算法的概率;在识别初始阶段之外的跟踪阶段,通过反馈调节,抑制非目标特征的输入,提高计算效率和/或准确率。这样,本发明通过将特征处理方式分为起始阶段和跟踪阶段,并进一步匹配反馈调节,可以有效提升计算效率,提升语音识别精度。
本发明提供的语音识别方法重点所要保护的是反馈机制,识别算法可采用本领域的常规技术手段,例如隐马尔可夫模型、神经网络、机器学习等。
下面结合附图对本申请的具体实施例进行进一步地描述:
如图1所示,语音识别前端系统包括语音识别前端设备的结构和硬件,以及语音识别模块中的算法。
根据图1可以看出,声波首先被声学结构处理,然后经过硬件电路,最后进入识别算法,形成文本输出。硬件和识别算法之间既有正向的声音信号,也有反向的反馈信号。
语音识别前端设备的结构部分如图2所示,包括声学波导结构A、谐振管B和具有螺旋腔体C的蜗管结构K。根据图2可以看出,声学结构包括:声学波导结构A、谐振管B、螺旋腔体C和声音输出孔D。
声学波导结构A由多个曲面平滑连接而成,如图3所示,不同区域的反射曲面负责处理不同方向的声波信号。声波经过反射和/或衍射后进入谐振管B,多个曲面使不同方向声波的传播距离产生差异,为声源定位提供声时间差信息。声学波导结构A成对部署在声学头模两侧,位置差异产生声时间差和声级差定位信息。根据图3可以看出,声学波导结构A由多个曲面平滑连接而成,不同区域的曲面主要用于将不同方向的声波信号向外反射和/或向声波出口引导E。在引导的过程中,声波的传输路径会产生差异,进而通过引起声波到达时间差实现编码方向信息。谐振管B利用声筒效应对人声频段进行谐振放大。
螺旋腔体C横截面积逐步变窄,实现高效阻抗变换,利用驻波效应提升声音传感器位置处的声压强度。螺旋腔体C两侧开孔,嵌入多个硅麦,即MEMS声音传感器,开孔对准MEMS声音传感器的拾音孔,如图4和图5所示。根据图4和图5可以看出,螺旋腔体前后开孔,声音传感器F嵌入安装在螺旋腔体上。
考虑到MEMS声音传感器的三维排布,通过柔性PCB结构实现电气连接,如图6和图7所示。根据图6和图7可以看出,硬件包括:声音传感器F、柔性PCB结构G和线缆H。特别地,所示的两个声音传感器F成对部署在谐振腔体C的同一个截面上。
硬件部分如图6和图8所示,根据螺旋腔体不同位置的谐振频率,安装频响特性相匹配的硅麦,构成三维体形式的MEMS声音传感器阵列。同一截面处部署2个硅麦,通过信号求和提升信噪比。
如图8所示,通过分频感知和多通道可编程增益调节,在硬件上调节指定频带的音频信号。根据图8可以看出,同一截面处的MEMS声音传感器通过信号求和以提升信噪比,可编程增益放大器可以受控于反馈输入,以实现增益的调节。MEMS声音传感器连接低噪声放大器(LNA),实现模拟声音信号的低噪声放大;LNA连接PGA,实现增益调节;PGA连接带通滤波器,实现子带的频率选择;由于MEMS声音传感器部署在螺旋腔体的不同位置,而不同位置会对不同频率的声波产生驻波的波峰。所以多个麦克风可以充分利用不同位置的驻波波峰,实现对应频率的更灵敏的信号拾取。这样,通过多个MEMS声音传感器的组合,可以实现优于一个麦克风的效果。分频感知是指将不同驻波波峰处信号进行融合,然后再通过依次低通滤波器LP和数模转换器ADC对信号进行处理后,输入至语音识别模块中利用算法进行处理。
如图9所示,蜗管结构的声音输出孔D的末端与MEMS声音传感器的拾音孔结构平滑过渡连接。这样做的好处是,可以更有效地实现信号接收过程中的阻抗变换,让声音信号的能量尽可能地进入声音传感器,提升信号接收质量。
如图10所示,在蜗管结构的声音输出孔大于1个时,将声音输出孔部署在同一频率的驻波的波峰的位置上。这样做的好处是,可以通过增加MEMS声音传感器的个数,并对输出信号求和,提升信号接收灵敏度。优选地,在蜗管结构的前后两侧部署两个MEMS声音传感器,这样做的好处是,相比于部署一个MEMS声音传感器提升了信号质量,同时考虑了实际中的安装问题,因为前后两侧正好可以通过部署柔性PCB实现连接。如果环绕部署多个MEMS声音传感器,则电气连接会麻烦很多。
本发明的算法原理部分基于双耳效应,提出信息融合的声源定位算法。首先,根据曲面和声学头模左右声学波导结构之间的距离参数,建立不同方向声音信号的差异化声时间差、声级差响应数学模型。然后,以声时间差、声级差为主要信息,波前到达时间、持续相位差、包络持续时间为过渡段信息,构建声源定位算法。针对正前方、正后方声源引发的定位歧义,通过模仿人耳小幅度改变自身方位的策略加以解决。声源跟随功能将定位结果作为输入,并通过扩展卡尔曼滤波器平滑跟踪轨迹。
本发明的有益技术效果至少包括;
本发明在有限复杂度的前提下,通过简化的声学仿生结构实现对声波信号的方向编码、物理放大和能量汇聚,充分融合声学结构和硬件架构的优势,实现信号接收灵敏度和质量的提升,通过识别算法对特征提取和硬件的反馈,实现对语音识别精度和/或效率的提升。
在本申请中的编码指的是:对不同方向的声波进行处理,使其传播距离产生差异,进而引起到达时间差和强度差。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
除非另外定义,本公开使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本公开中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,“一个”、“一”或者“该”等类似词语也不表示数量限制,而是表示存在至少一个。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
- 通过语音识别键盘功能的方法、系统、设备及存储介质
- 电子计算机断层扫描前端设备、系统、方法及存储介质
- 基于变电站三维模型的前端设备的自动布置方法及系统
- web前端横向广告展示方法、存储介质、设备及系统
- 日志打印控制方法、装置、系统、后端服务器及前端设备
- 语音识别设备、语音识别设备的协作系统和语音识别设备的协作方法
- 一种语音识别的前端处理方法、装置及终端设备