基于特征增强注意力机制的语音欺骗检测方法
文献发布时间:2024-07-23 01:35:12
技术领域
本申请涉及语音欺骗检测技术领域,特别涉及一种基于特征增强注意力机制的语音欺骗检测方法。
背景技术
随着语音合成系统性能的不断完善,合成的语音质量逐渐难以被人耳区分,这对人们日常生活中的安全问题带来了很大的困扰。人们发现通过使用合成的语音或者对语音进行回放可以很容易地欺骗ASV(Automatic Speaker Verification,自动说话人验证)系统,使其做出错误的判断,于是对伪造语音及合成语音进行欺骗检测,成为成为ASV中的一个热点问题。
为了构建高效的语音欺骗检测系统,现有的方法分别集中在特征工程和模型设计两个方面。特征工程方面,1、提取语音的CQCC(Constant Q Cepstral Coefficients,常数Q倒谱系数)特征在捕获表明欺骗攻击的操纵伪影的迹象方面更有效;2、使用前端特征的分数级融合检测合成语音,通过关注与幅度、相位和音调变化相关的三种伪影提高特征所包含的伪造信息,在基于GMM(Gaussian Mixture Model,高斯混合模型)分类器的模型中取得了最佳性能;3、从CQT(Constant Q Transform,常数Q变换)的倍频程功率谱中提取信息,使用MLT(Multilevel Transform,多级变换)的框架从CQT以多级方式逐级捕获倍频程功率谱的相关信息。模型设计方面,1、把SENet(Squeeze-Excitation Network,挤压-激励网络)和ResNet(Residual Network,残差网络)引入到深度神经网络中,实现高质量的重放语音检测;2、通过设计单类Softmax(One-Class Softmax,OC-Softmax)使真实语音具有一个紧凑的边界,而与伪造语音保持一定的距离;3、使用GAT(Graph Attention Networks,图注意力网络)结构,学习不同子带和时间间隔的线索之间的关系,使用频谱和时间子图的模型级图融合以及图池化策略来提高伪造语音和真实语音之间的区分度;4、基于具有VIB(Variational Information Bottleneck,变分信息瓶颈)的wav2vec 2.0预训练模型的迁移学习方案,提高了模型区分看不见的欺骗和真实语音的性能,在低资源和跨数据集的测试中取得了较好的结果。
上述提到的各种语音欺骗检测方法已经从闭集情况下的检测发展到了开集情形下的检测,即可以对任意合成算法的合成语音进行检测。大多数的方法是基于CNN(Convolutional Neural Network,卷积神经网络)实现的,CNN利用卷积的操作来提取局部感知,能够有效捕捉到输入特征中的局部特征,但是缺乏对全局特征提取的能力,例如CNN无法在语音的起始与结束两端建立联系,所以会产生“长程依赖”的问题,导致特征提取不充分。
发明内容
本发明所要解决的问题是:提供一种基于特征增强注意力机制的语音欺骗检测方法,使用局部编码模块提取并保留特征的局部信息,使用全局感知模块提取特征的全局信息,并进行拼接得到增强的特征,实现特征的充分提取及高质量的开集情形下的合成语音欺骗检测。
本发明采用如下技术方案:一种基于特征增强注意力机制的语音欺骗检测方法,包括训练阶段和测试阶段,在训练阶段得到语音欺骗检测所需的检测网络及参数,在测试阶段实现对真实语音和合成语音真伪的检测;
训练阶段,包括以下步骤:
步骤1、获取训练语料,训练语料包括真实语音和合成语音;
步骤2、将获取的训练语料进行预处理,得到固定帧长的线性频率倒谱系数片段,表示为声学特征X;
步骤3、构建检测模型,将声学特征输入到检测模型中进行模型训练,所述检测模型包括特征提取和分类,对检测的语音进行特征提取获得增强的特征;并对增强的特征进行检测分类,得到语音预测的分类标签;
步骤4、在检测模型训练过程中,设置检测模型的超参数,使目标函数最小化,直到设置的训练轮数,得到训练好的检测模型;
转换阶段包括以下步骤:
步骤5、获取待验证语料,待验证语料包括真实语音和合成的语音,提取验证语料的线性频率倒谱系数,表示为声学特征Y;
步骤6、将提取的声学特征Y输入到训练好的检测模型中,进行语音欺骗检测。
进一步的,步骤2中,将获取训练语料进行预处理,其具体步骤为:训练语音的采样率设置为16kHz,帧长大小为20ms,帧重叠为10ms,然后将帧数固定为750,表示为声学特征X。
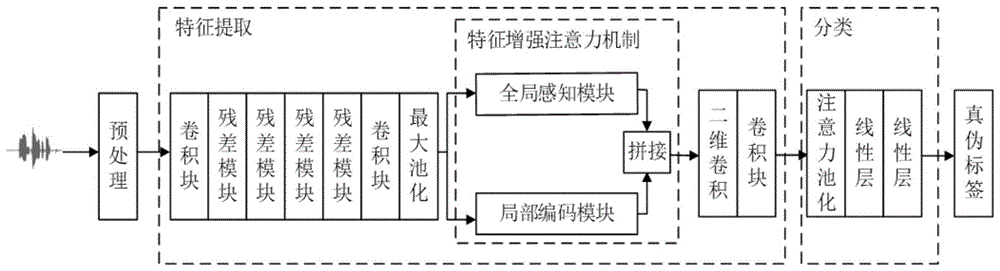
进一步的,步骤3中,特征提取包括:4个二维卷积层、4个残差卷积模块、3个批归一化层、3个ReLU激活函数、1个二维最大池化层和1个特征增强注意力机制。
其中,残差卷积模块由5个卷积层、4个批归一化层和4个ReLU激活函数组成;特征增强注意力机制由1个局部编码模块和1个全局感知模块组成,其局部编码模块由5个卷积层、6个批归一化层、5个ReLU激活函数、1个编码层、1个平均层、1个线性层和1个Sigmoid激活函数组成;全局感知模块由2个组归一化层、1个深度卷积层、1个感知机层和2个通道缩放层组成。
进一步的,局部编码模块中的编码层由1个固有码本和1组缩放因子组成,固有码本表示为B={b
其中,K表示声学特征X经过卷积层和残差模块之后的特征向量
在计算得到所有e
其中,φ(·)表示批归一化层、ReLU层和平均层的组合,e表示整个码字的完整信息。
进一步的,全局感知模块中的深度卷积层和感知机层,深度卷积层由2个二维卷积层、2个批归一化层和2个SiLU激活函数组成,SiLU激活函数的公式为:
其中,x表示激活函数的输入。
进一步的,全局感知模块中,感知机层由2个二维卷积层、1个GELU激活函数和2个Dropout层组成,GELU激活函数的公式为:
GELU(x)=x*Φ(x)
其中,x表示激活函数的输入,Φ(x)表示正态分布的累积分布函数,具体公式为:
其中,erf(·)表示高斯误差函数。
进一步的,步骤3中,分类包括1个注意力池化层和2个线性层,注意力池化将增强特征
进一步的,步骤4中,检测网络的目标函数表示为:
其中,θ
具体的,交叉熵损失函数表示为:
其中,y表示分类器输出的预测标签向量,label表示输入语音的真实真伪标签,y
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1、本发明的检测模型在特征提取中提出了局部编码模块,该模块从经过卷积层和残差模块之后的特征向量中提取了该特征的局部信息,并将其保留了下来,具体而言,用1个固有码本和1组缩放因子对输入特征进行编码操作,计算出整个特征关于每个通道码字的完整信息,然后将这些码字输入到后续的线性层和卷积层中就可以得到关键类的特征。
2、本发明的检测模型还提出了全局感知模块,该模块从经过卷积层和残差模块之后的特征向量中提取了该特征的全局信息,由深度卷积模块和通道多层感知机模块组成,这两个模块的输出都经过通道缩放操作,可以提高特征的泛化能力和鲁棒性,同时相比于传统的卷积操作,深度卷积可以提高特征表示能力和降低计算成本。
3、本发明语音欺骗检测方法,将经过局部编码模块和全局感知模块的特征进行拼接,得到增强特征向量,同时具有语音的局部信息和全局信息,分类器可以更好地从中学习语音的真实特征和伪造特征,从而提高分类检测的准确率。
4、由于本发明检测模型在训练阶段使用了大量的真实语音和多种算法的合成语音,因此在测试阶段可以测试在训练中未使用的合成算法合成的语音的真伪,大大扩展了该模型的适用范围并提高了检测语音欺骗检测的性能。
附图说明
图1是本发明语音欺骗检测方法的流程框图;
图2是本发明语音欺骗检测方法检测模型结构图;
图3是本发明检测模型特征提取中残差模块的网络结构图;
图4是本发明检测模型特征提取中局部编码模块的网络结构图;
图5是本发明检测模型特征提取中全局感知模块的网络结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的阐述,显然,所描述的实施例仅是本发明的一部分实施例,并不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。同时对于本发明实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
在本发明的一个实施例中,基于特征增强注意力机制的语音欺骗检测方法,包括训练阶段和测试阶段。训练阶段用于得到语音欺骗检测所需的检测网络及其参数,而测试阶段用于实现对真实语音和合成语音检测其真伪。
如图1所示,训练阶段包括以下步骤:
步骤1、获取训练语料。
本实施例中,训练语料为ASVspoof 2019比赛中的逻辑访问赛道,即由真实语音和各种语音合成算法合成的语音组成;将获取的语料库中的训练语料和验证语料全部取出,训练语料共有25380条,验证语料共有24986条,每句时长2-8s不等。
将选取的训练语料作为模型训练的输入,每训练完一轮,将验证语料输入至模型中进行验证,这可以使得每轮模型的训练结果更为直观地展现,从而方便调整模型的训练参数。
步骤2、将获取的训练语料进行预处理。
本实施例中,训练语音的采样率设置为16kHz,帧长大小为20ms,帧重叠为10ms,然后将帧数固定为750,表示为声学特征X。
步骤3、将步骤2得到的声学特征X输入到检测网络中进行训练。
本实例中,网络采用卷积神经网络的结构,声学特征X首先通过特征提取中的卷积层和残差模块得到高维特征向量
接着,将全局特征向量和局部特征向量进行拼接获得增强之后的特征
该检测模型主要包括特征提取和分类两个部分:
(1)在特征提取中,声学特征X首先通过卷积层和残差模块提取捕获信息的高维特征向量
特征提取包括4个二维卷积层、4个残差卷积模块、3个批归一化层、3个ReLU激活函数、1个二维最大池化层和1个特征增强注意力机制,所述的残差卷积模块,如图3所示,由5个卷积层、4个批归一化层和4个ReLU激活函数组成,所述的特征增强注意力机制由1个局部编码模块和1个全局感知模块组成。
局部编码模块,如图4所示,由5个卷积层、6个批归一化层、5个ReLU激活函数、1个编码层、1个平均层、1个线性层和1个Sigmoid激活函数组成。
全局感知模块,如图5所示,由2个组归一化层、1个深度卷积层、1个感知机层和2个通道缩放层组成。
局部编码模块中的编码层由1个固有码本和1组缩放因子组成,固有码本表示为B={b
编码层的公式为:
其中,K表示声学特征X经过卷积层和残差模块之后的特征向量
本实例中,特别地,K为512,N为64。
在计算得到所有e
其中,φ(·)表示批归一化层、ReLU层和平均层的组合,e表示整个码字的完整信息。
全局感知模块中的深度卷积层和感知机层,深度卷积层由2个二维卷积层、2个批归一化层和2个SiLU激活函数组成,SiLU激活函数的公式为:
其中,x表示激活函数的输入。
感知机层由2个二维卷积层、1个GELU激活函数和2个Dropout层组成,GELU激活函数的公式为:
GELU(x)=x*Φ(x)
其中,x表示激活函数的输入,Φ(x)表示正态分布的累积分布函数,具体公式为:
其中,erf(·)表示高斯误差函数。
(2)在分类中,注意力池化将增强特征
整个检测网络的目标函数表示为:
其中,θ
上述的交叉熵损失函数表示为:
其中,y表示分类器输出的分类标签向量,label表示输入语音的真实真伪标签,y
步骤3-1、将步骤2中提取的声学特征X输入到特征提取中,经过特征提取网络生成增强特征
步骤3-2、将上述得到的增强特征
步骤4、重复步骤3-1至步骤3-2,直至达到设置的迭代轮数,从而得到训练好的网络。由于神经网络具体设置不同以及实验设备性能不同,设置的迭代轮数也各不相同。
本实施例中,特别的,设置的迭代轮数为150轮。
测试阶段包括以下步骤:
步骤5、待测试语料包含真实语音和由合成算法合成的语音,选取测试语句,提取线性频率倒谱系数,并将其帧数固定为750,表示为声学特征Y。
步骤6、将所述声学特征Y输入到训练好的检测网络中,得到其分类标签。
实验结果如下表所示:
综上,本发明基于特征增强注意力机制的语音欺骗检测方法,在特征提取中提出了特征增强注意力机制,该注意力机制由局部编码模块和全局感知模块组成,局部编码模块用于提取并保留特征的局部信息,全局感知模块用于提取特征的全局信息,将两者进行拼接,得到增强的特征,用于实现高质量的开集情形下的合成语音欺骗检测。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 一种基于特征增强位置注意力机制的图像语义分割模型
- 一种基于特征增强位置注意力机制的图像语义分割模型