乐器、声学
-
一种针对语音关键词分类网络的对抗样本攻击方法
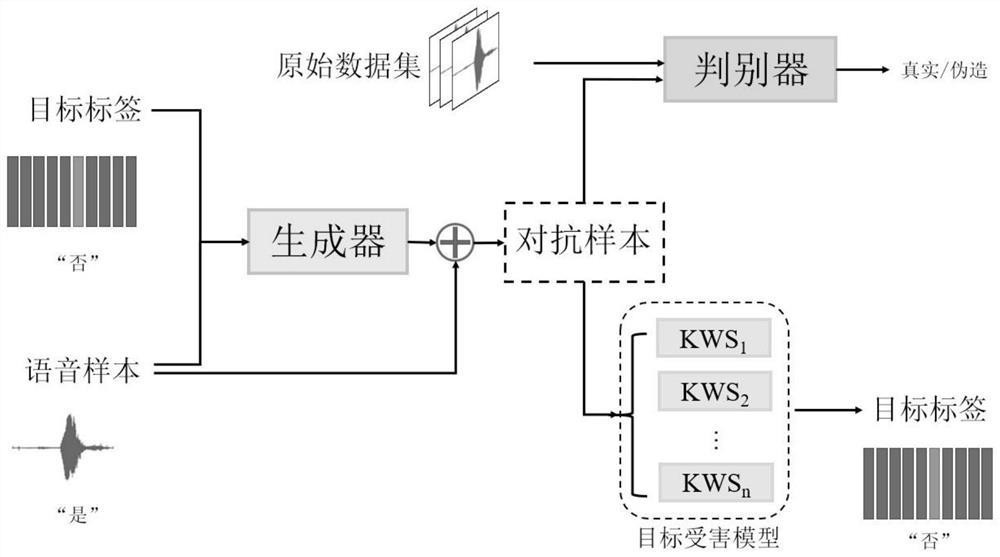
本发明公开了一种针对语音关键词分类网络的对抗样本攻击方法,包括以下步骤:(1)按照训练策略选择训练数据以及训练的批大小的目标标签;(2)将数据以及标签输入到生成器G中,生成对抗扰动,并且构建相应的对抗样本;(3)将生成的对抗样本分别输入到判别器D和目标受害模型,得到相应的损失,并且计算相应的损失,更新网络的参数;(4)重复步骤(1)至步骤(4),直到满足训练的停止条件,最终得到训练好的模型;(5)模型使用,加载模型参数,输入语音样本以及目标标签,即可快速的生成对抗样本。使用本发明提出的方法,能够实现实时场景下基于语音关键词分类网络应用的对抗样本攻击。
2023-08-21 -
声音或声场的压缩HOA声音表示的解码方法和装置
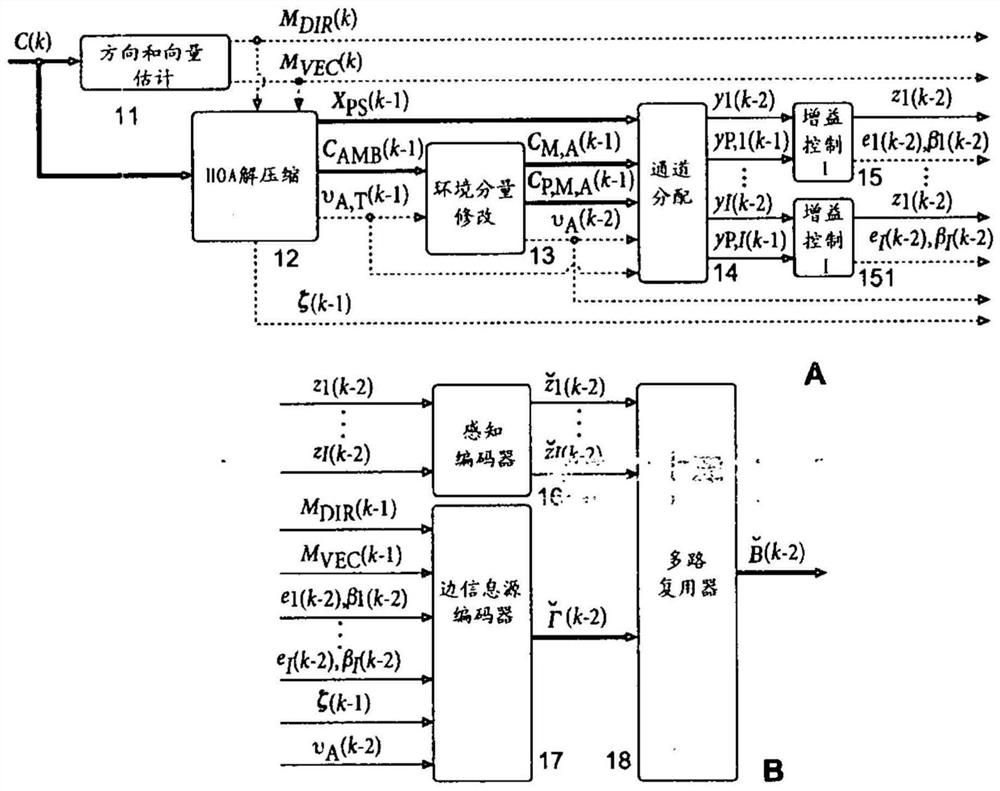
本公开涉及声音或声场的压缩HOA声音表示的解码方法和装置。当对HOA数据帧表示进行压缩时,在每个通道信号被感知地编码(16)之前对其实施增益控制(15,151)。增益值作为边信息以差分的方式被传输。然而,为了开始对这样的流式压缩HOA数据帧表示进行解码,需要绝对增益值,应当以最小数量的比特对该绝对增益值进行编码。为了确定这样的最小整数比特量{βe),在空间域中将HOA数据帧表示(C(k))渲染为位于单位球体上的虚拟扬声器信号,随后对HOA数据帧表示(C(k))进行归一化。然后,将最小整数比特数设置为(AA)。
2023-08-21 -
声音或声场的压缩HOA声音表示的解码方法和装置
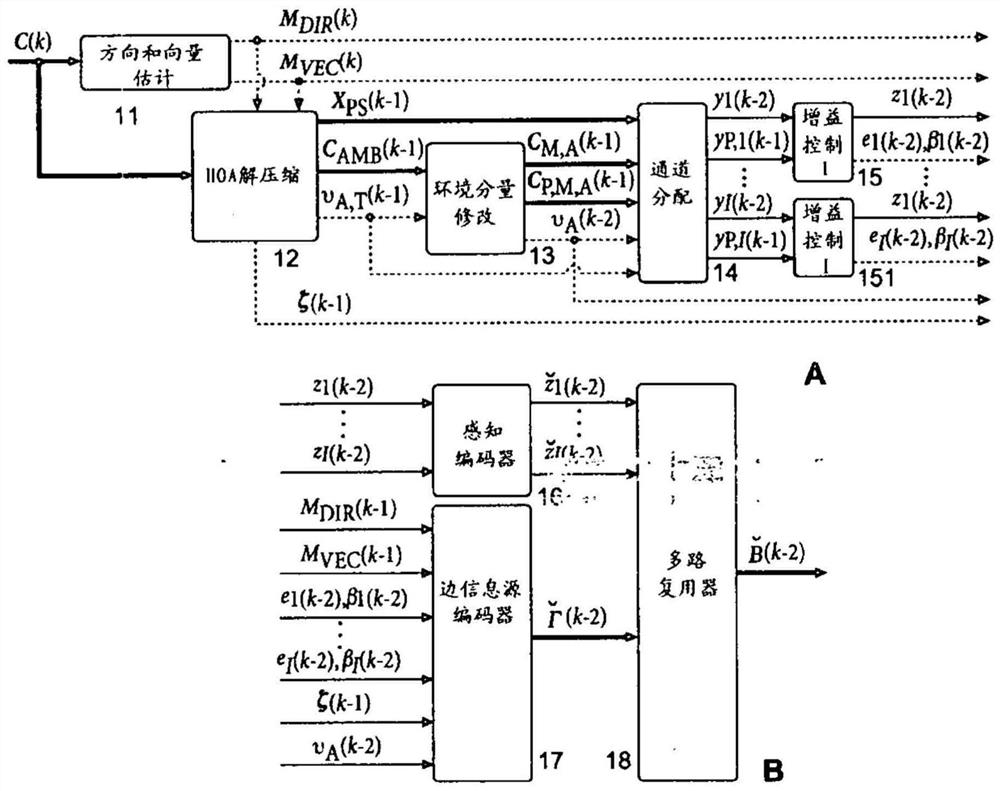
本公开涉及声音或声场的压缩HOA声音表示的解码方法和装置。当对HOA数据帧表示进行压缩时,在每个通道信号被感知地编码(16)之前对其实施增益控制(15,151)。增益值作为边信息以差分的方式被传输。然而,为了开始对这样的流式压缩HOA数据帧表示进行解码,需要绝对增益值,应当以最小数量的比特对该绝对增益值进行编码。为了确定这样的最小整数比特量{βe),在空间域中将HOA数据帧表示(C(k))渲染为位于单位球体上的虚拟扬声器信号,随后对HOA数据帧表示(C(k))进行归一化。然后,将最小整数比特数设置为(AA)。
2023-08-21 -
通用性吉他防脱背带扣
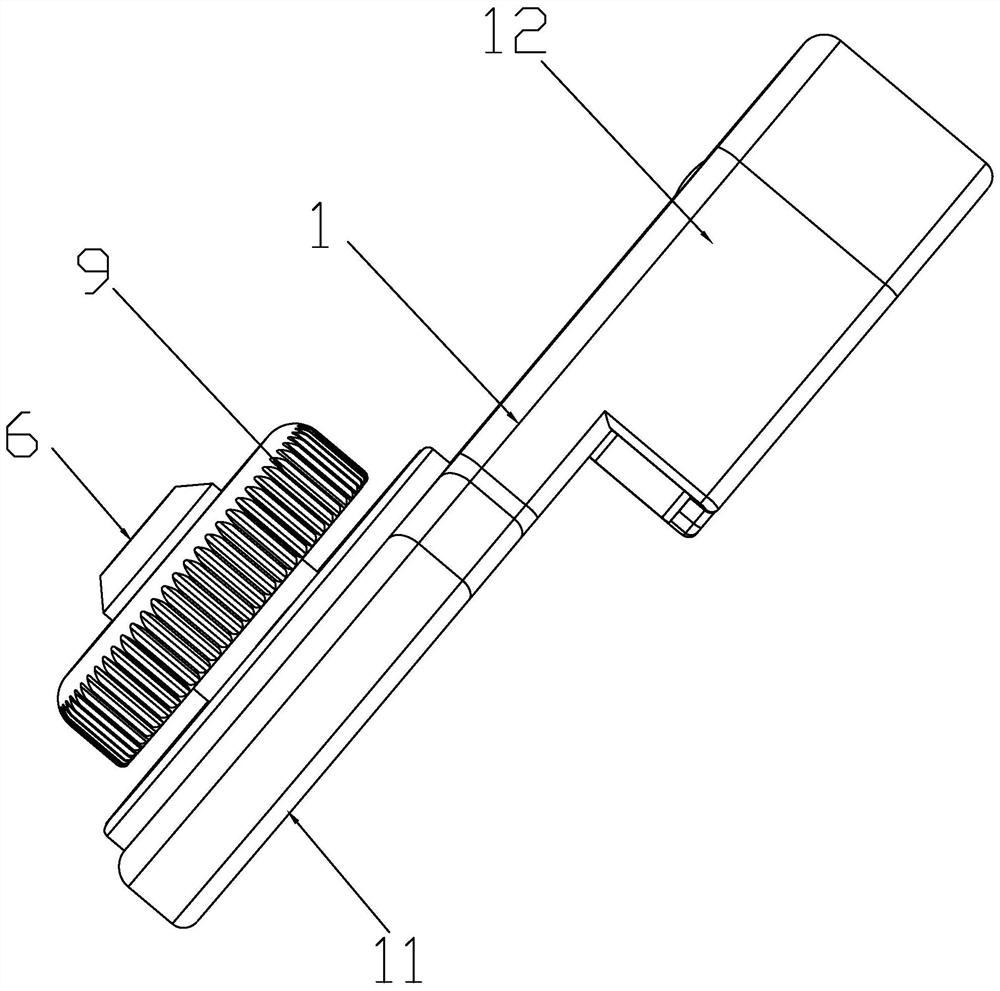
本发明涉及通用型吉他防脱背带扣,包括有背带扣本体,其特征在于:所述背带扣本体一端设有背带连接端另一端设有背带尾钉连接端,所述背带连接端设有用将背带的背带孔锁紧的第一锁紧装置,所述背带尾钉连接端设有卡槽,卡槽一端设有供背带尾钉进入的开口,背带尾钉连接端在卡槽中设有将背带尾钉锁紧的第二锁紧装置,本发明的有益效果为:适应于各种背带尾钉,壳体强度高,产品轻巧玲珑,外观设计简洁大方,卡口采用U型开口,外八角导向,能够轻巧自如滑扣,防脱件采用高强度钢珠材质,耐磨顺滑不卡顿,回弹卡片采用H59黄铜,回弹性能稳定可靠。
2023-08-21 -
用于音频信号的时域数据包丢失隐藏的方法
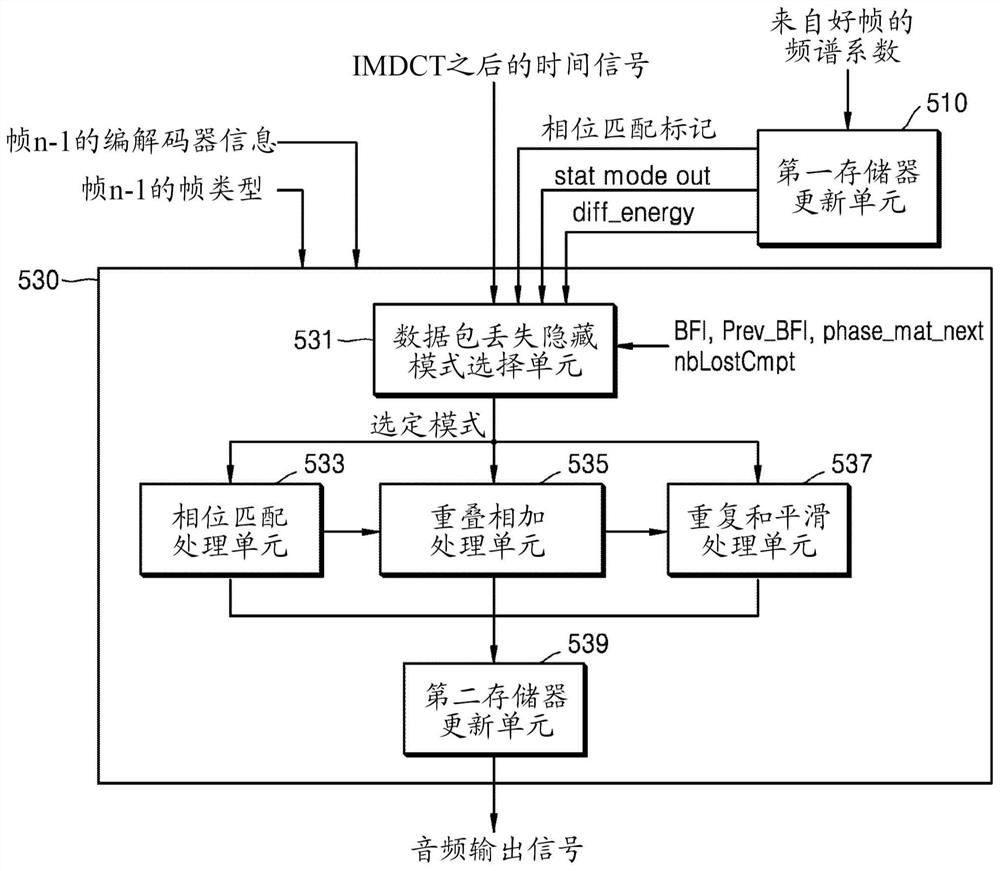
一种用于音频信号的时域数据包丢失隐藏的方法包括:将频域信号时频逆变换为与当前帧对应的时域信号;检查当前帧是否对应于至少一个擦失帧之后的好帧;如果当前帧对应于至少一个擦失帧之后的好帧,则基于包括信号特性的多个参数,从包括相位匹配工具和平滑工具的多个工具中选择一个工具;和基于所选择的工具对当前帧执行数据包丢失隐藏处理;其中,如果所选择的工具是所述平滑工具,则基于所述至少一个擦失帧的数目对当前帧执行一个平滑处理或两个平滑处理。
2023-08-21 -
用于音频信号的时域数据包丢失隐藏的方法
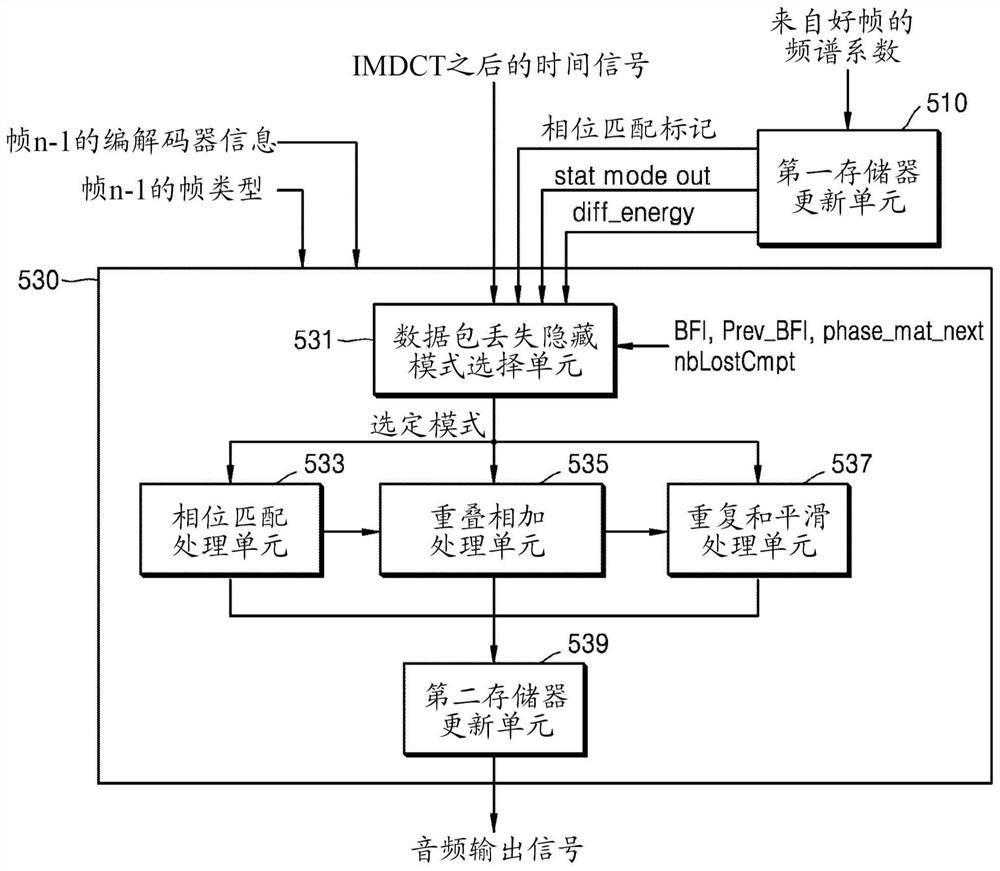
一种用于音频信号的时域数据包丢失隐藏的方法包括:将频域信号时频逆变换为与当前帧对应的时域信号;检查当前帧是否对应于擦失帧和至少一个擦失帧之后的好帧中的一者;如果当前帧对应于擦失帧和至少一个擦失帧之后的好帧中的一者,则获取信号特性;基于包括信号特性的多个参数,从包括相位匹配工具和平滑工具的多个工具中选择一个工具;和基于所选择的工具对当前帧执行数据包丢失隐藏处理;如果所选择的工具是平滑工具,当前帧对应于好帧并且至少一个擦失帧的数目是1,则执行第一平滑处理作为数据包丢失隐藏处理;如果所选择的工具是平滑工具,当前帧对应于好帧并且至少一个擦失帧的数目大于1,则执行第二平滑处理作为数据包丢失隐藏处理。
2023-08-21 -
一种相控多声道声波定向发射方法及系统
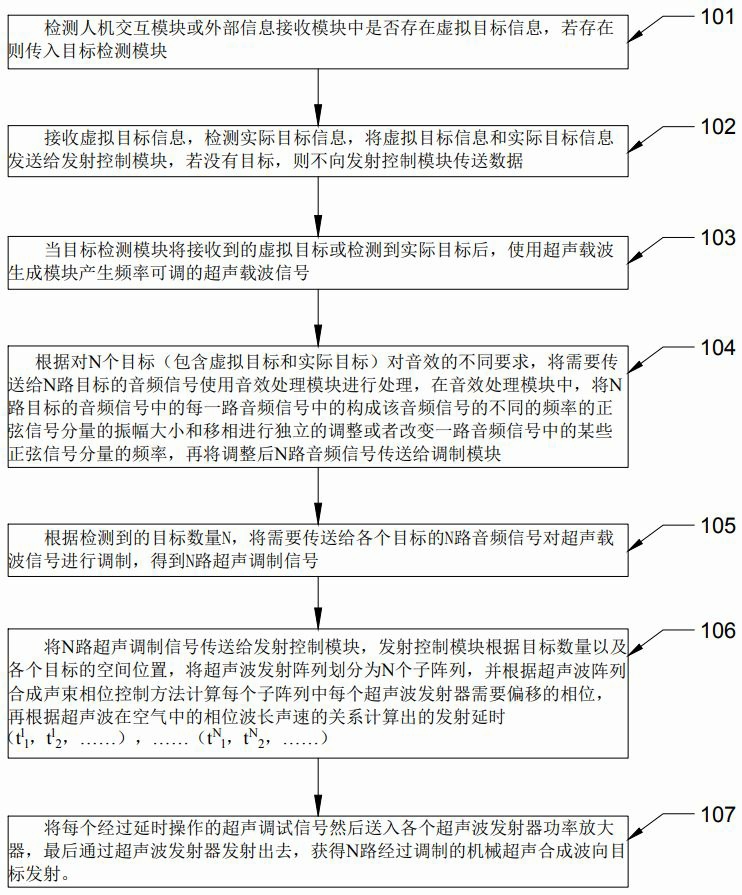
一种相控多声道声波定向发射方法及系统,通过人机交互模块或外部信息接收模块接收虚拟目标信息,并传送给目标检测模块,目标检测模块检测环境中是否存在实际目标,并进一步检测目标类型、目标数量以及各个目标的空间位置,将需要发射的音频信号经过音效变换传送给调制模块,调制模块使用经过音效换号的音频信号对超声载波信号进行调制再传送给发射控制模块,发射控制模块根据目标数量以及各个目标的空间位置将发射阵列划分为对应各个目标的子阵列,并根据相位控制方法计算子阵列中每个超声波发射器需要的发射延时,经过发射延时后,调制好的超声载波信号通过发射子阵列中的各个超声波发射器发射。
2023-08-21 -
用于登记用户命令的显示装置和方法
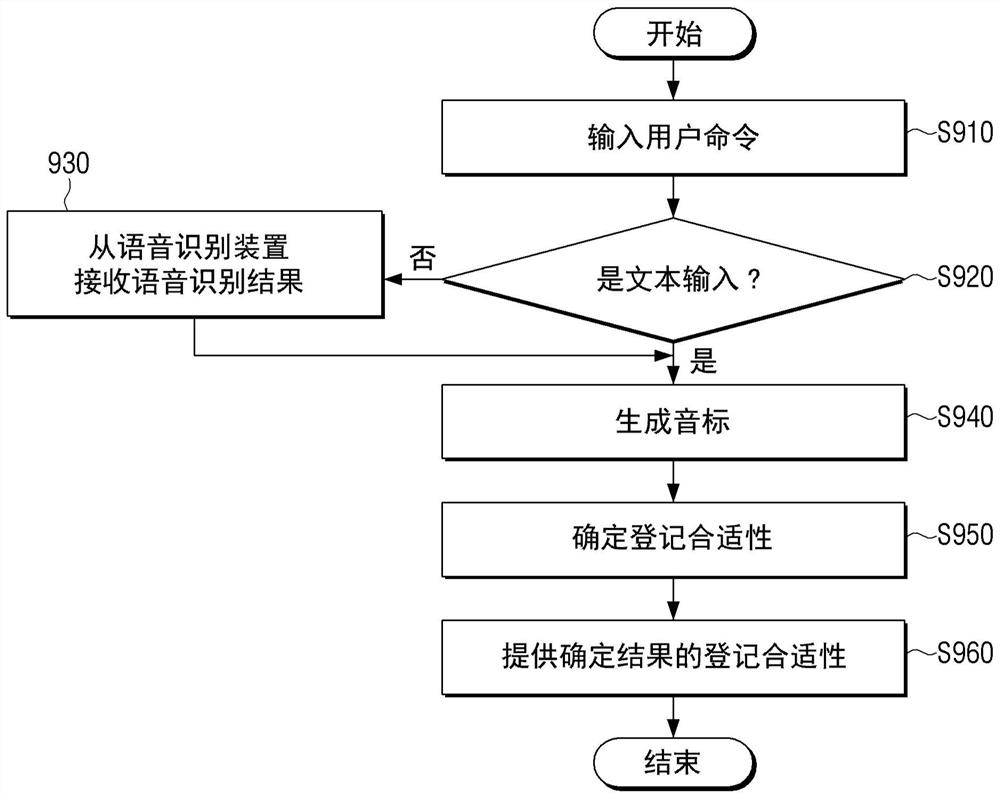
一种显示装置,包括:输入单元,被配置为接收用户命令;输出单元,被配置为输出针对用户命令的登记合适性确定结果;以及处理器,被配置为生成用户命令的音标,分析生成的音标以确定用户命令的登记合适性,并控制输出单元输出针对用户命令的登记合适性确定结果。因此,显示装置可以登记抗误识别并保证用户定义的用户命令中的高识别率的用户命令。
2023-08-21 -
一种超结构水声发射换能器
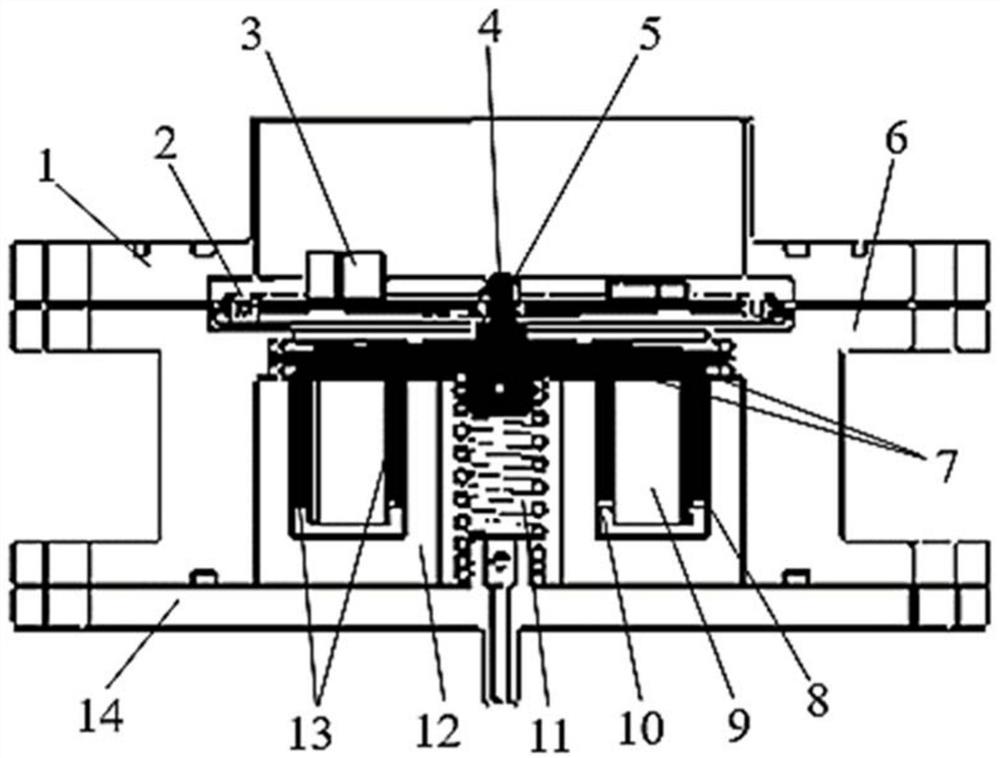
一种超结构水声发射换能器,包括外壳以及设置在外壳内部密封空间的电动式驱动元件以及超结构辐射盖板,超结构辐射盖板由基板以及固定在基板上的多个附加质量单元组成,电动式驱动元件包括软磁材料底座,软磁材料底座上开设有环形凹槽,环形凹槽当中放置有永磁材料芯体,由软磁材料底座顶部至永磁材料芯体与软磁材料底座之间的缝隙插入安装线圈骨架,线圈骨架上缠绕线圈,软磁材料底座的中心掏空并设置有螺旋弹簧,螺旋弹簧通过连接件与基板相连,所述的连接件具有能够与线圈骨架固定的平板面。本发明水声发射换能器的尺寸小,能够在中低频范围形成连续的声发射宽带。
2023-08-21 -
一种电子二胡系统
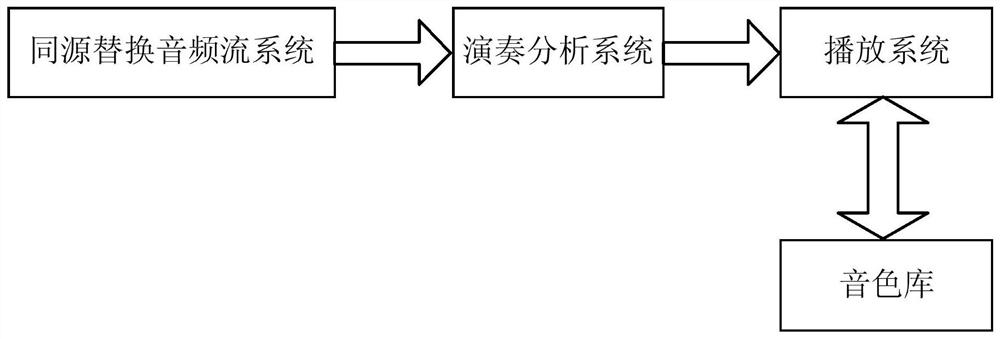
本发明公开了一种电子二胡系统,属于音乐器械技术领域。该系统包括:同源替换音频流系统、演奏分析系统、播放系统和音色库;同源替换音频流系统,用于建立二胡不同技法对应的模型,并将模型发送给演奏分析系统;演奏分析系统,用于检测二胡琴码的振动信号,根据检测到的振动信号和模型,确定二胡当前的演奏信息,并将演奏信息发送给播放系统;播放系统,用于根据演奏信息,调用音色库中的波表,采用波表合成的方式合成并播放对应的音乐。本发明中通过使用音色库中的声音来替代二胡本身发出的声音,使得其发声方式和材料无关,仅仅和音色库的质量有关,彻底摆脱了二胡对材料的依赖,大大降低了电子二胡的制作成本。
2023-08-21 -
一种基于卷积块注意机制的视听双模态语音识别方法
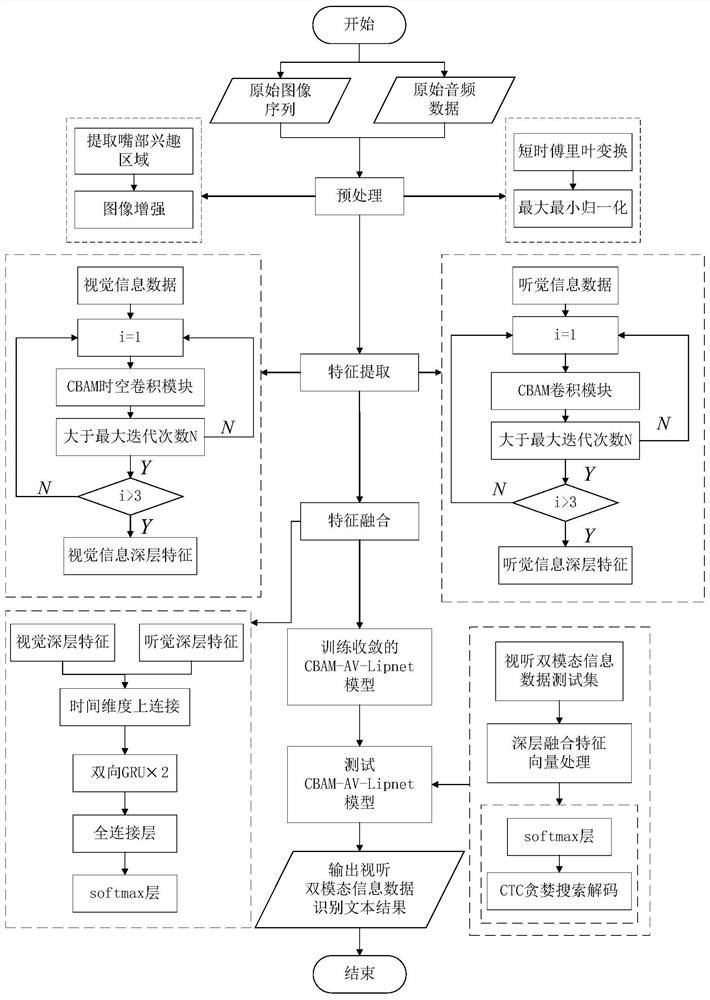
本发明提供一种基于卷积块注意机制的视听双模态语音识别方法,包括如下步骤:(1)对视听双模态信息数据集进行预处理;(2)提出构建CBAM‑AV‑LipNet模型;(3)完成基于卷积块注意机制的视听双模态语音识别任务,实现视听双模态语音识别任务。本发明利用提出构建的CBAM‑AV‑LipNet模型对测试集进行特征提取得到深层融合特征向量,对其进行CTC贪婪搜索解码,获得识别文本信息,完成视听双模态语音识别任务。本发明提出的基于卷积块注意机制的视听双模态语音识别方法较传统的语音识别方法和视觉语音识别模型LipNet具有良好的识别性能和收敛速度,同时具有一定的抗噪能力和有效性。
2023-08-21 -
一种智能语音识别辅助电力巡检设备拍摄方法
本发明公开了一种智能语音识别辅助电力巡检设备拍摄方法,所述电力巡检设备拍摄方法包括以下几个步骤:步骤一:制作生成带语音关键字的设备台账数据库S20;步骤二:将设备台账数据库文件导入红外热像装置S21;步骤三:在日常常规检测和例行巡检任务时,点击选择开启任务巡检模式S22,红外热像装置进行任务巡检模式,巡检模式初始默认按顺序进行巡检。该智能语音识别辅助电力巡检设备拍摄方法,能在时间保存的基础上增加根据拍摄者按照设备信息顺序拍摄命名保存的要求,又同时能根据拍摄者随机拍摄通过语音关键字自动匹配正确设备信息进行保存,避免翻找数据库增加工作量,同时根据时间也可以避免同物体多次拍摄引起存储错误和混淆等问题。
2023-08-21 -
训练数据更新方法及系统、语音识别方法及系统、设备
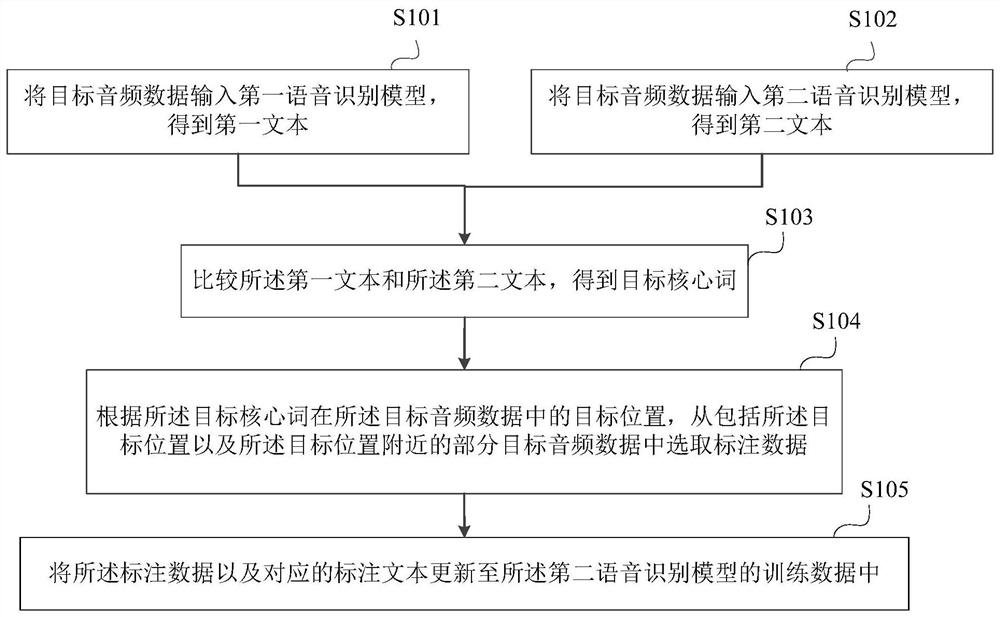
本发明公开了一种训练数据更新方法及系统、语音识别方法及系统、设备。其中,语音识别模型的训练数据更新方法包括以下步骤:将目标场景下的目标音频数据输入第一语音识别模型,得到第一文本;将所述目标音频数据输入第二语音识别模型,得到第二文本;比较所述第一文本和所述第二文本,得到目标核心词;根据所述目标核心词在所述目标音频数据中的目标位置,从包括所述目标位置以及所述目标位置附近的部分目标音频数据中选取标注数据;将所述标注数据以及对应的标注文本更新至所述第二语音识别模型的训练数据中。本发明能够实现自动补充核心词,从而提高第二语音识别模型的更新效率,进而提高语音识别的准确率。
2023-08-21 -
语音音素的识别方法及系统、电子设备及存储介质
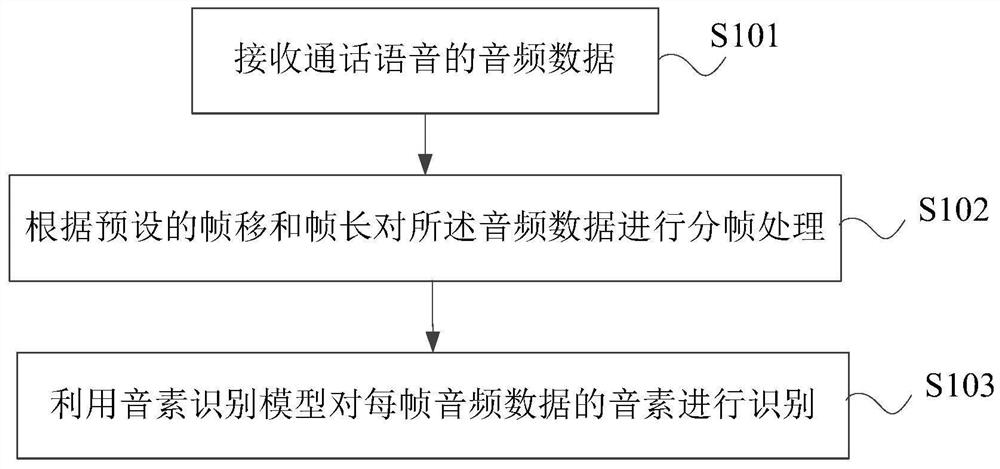
本发明公开了一种语音音素的识别方法及系统、电子设备及存储介质。语音音素的识别方法包括以下步骤:接收通话语音的音频数据;其中,所述音频数据对应的语言为英文;根据预设的帧移和帧长对所述音频数据进行分帧处理;利用音素识别模型对每帧音频数据的音素进行识别,其中,所述音素识别模型是基于音素对齐的英文训练样本训练得到的。本发明根据预设的帧移对所述音频数据进行分帧处理,充分考虑到英文语音信号的短时平稳性以及上下文特征,提高了后续英文音素识别的准确率。同时,利用基于音素对齐的英文训练样本训练得到的音素识别模型对每帧音频数据的音素进行识别,进一步提高了英文音素识别的准确率。
2023-08-21 -
一种办公区用声掩蔽系统
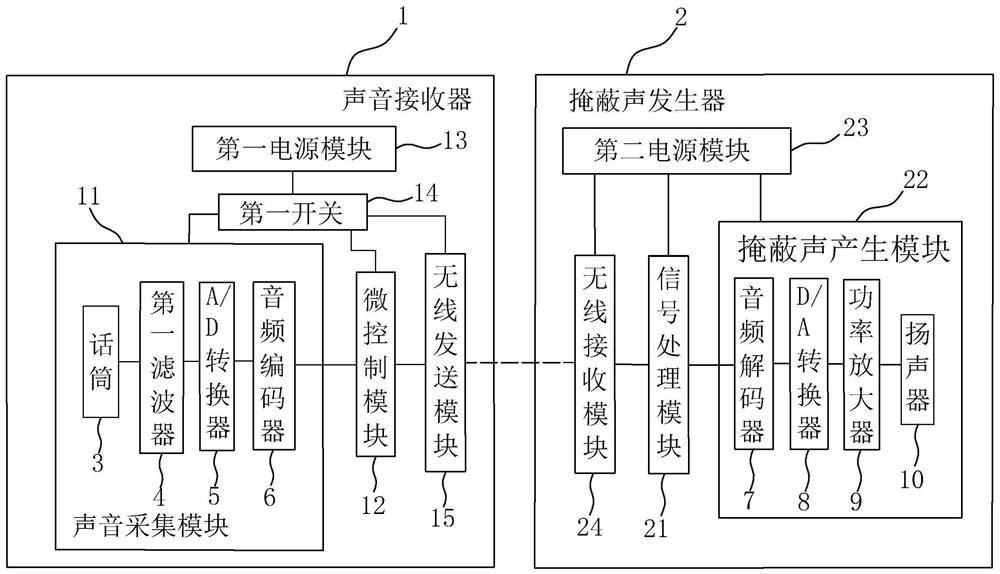
本申请涉及一种办公区用声掩蔽系统,属于声音处理系统的领域,包括设置在工位的隔板外侧的声音接收器以及可与声音接收器电连接的掩蔽声发生器;声音接收器包括相连接的声音采集模块和微控制模块;所述声音采集模块用于采集并处理外部环境音,微控制模块接收并存储所述声音采集模块发出的声音电信号并控制该电信号的发送;掩蔽声发生器包括信号处理模块和掩蔽声产生模块,信号处理模块与掩蔽声产生模块电连接,信号处理模块用于接收所述微控制模块发送的声音电信号;信号处理模块根据环境声电信号,信号处理模块使掩蔽声产生模块产生掩蔽声。本申请具有减小工位附近的噪音对工作人员的影响的效果。
2023-08-21 -
一种金属弦吉他的发光装置
本发明公开了一种金属弦吉他的发光装置,包括有塑料外部壳体,塑料外部壳体内部开设有空腔,空腔水平方向设置有缓冲层,缓冲层将空腔分割为上层空腔与下层空腔,缓冲层靠近上层空腔的一侧设置有磁条,下层空腔设置有电路板与电池座,放大电路板与电池座电性连接;上层空腔外壁嵌有磁柱与LED射灯,磁柱穿出上层空腔外壁,底端与缓冲层相接,位于上层空腔内的磁柱的侧壁缠绕有线圈;LED射灯电性连接电路板,线圈电性连接电路板。本发明相比较以往较为朴素的装饰,可以有更加炫酷的展示效果,使枯燥的学琴过程中增加乐趣。可以辅助拨动琴弦力度的训练,通俗的讲,拨动琴弦的力度越大,LED射灯越亮。
2023-08-21 -
一种音频相似度识别方法
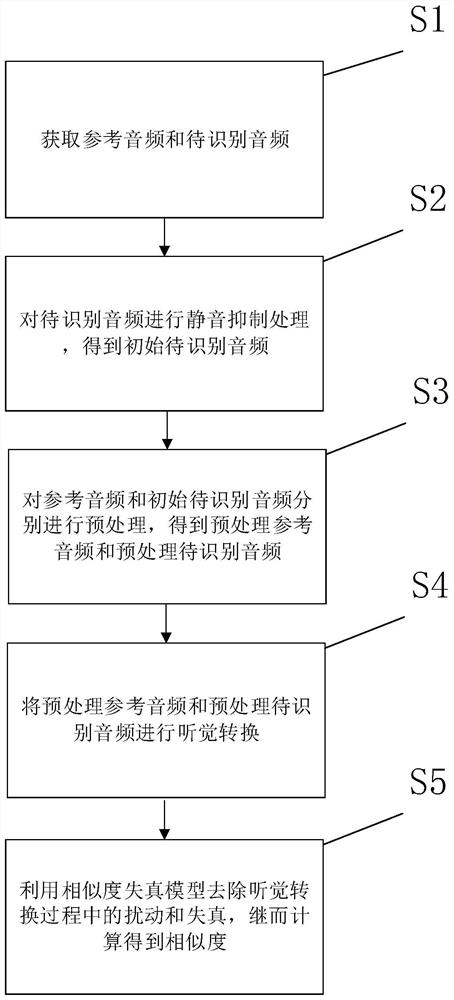
本发明涉及一种音频相似度识别方法,包括以下步骤:获取参考音频和待识别音频;对待识别音频进行静音抑制处理,得到初始待识别音频;对参考音频和初始待识别音频分别进行预处理,得到预处理参考音频和预处理待识别音频;将预处理参考音频和预处理待识别音频进行听觉转换;利用相似度失真模型去除听觉转换过程中的扰动和失真,继而计算得到相似度。与现有技术相比,可以有效提高相似度的精度。
2023-08-21 -
语音传输方法、智能终端及计算机可读存储介质
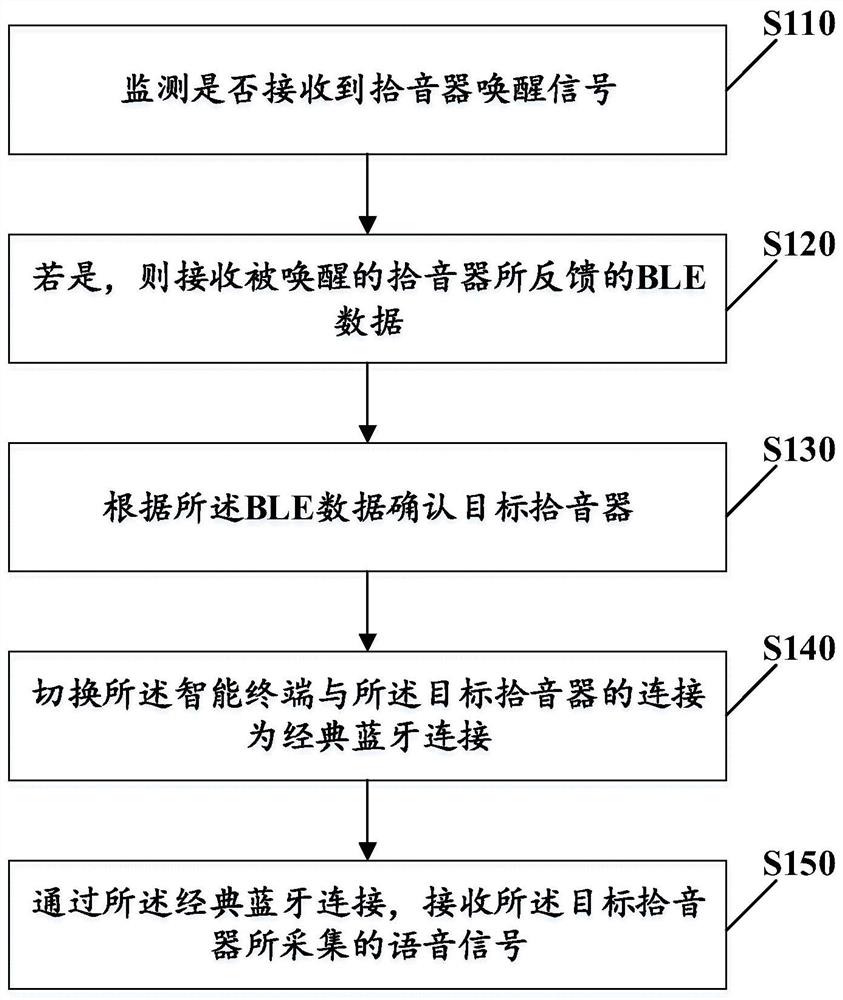
本发明提供一种语音传输方法,应用于智能终端,所述智能终端与至少一拾音设备低功耗蓝牙(BLE)连接,包括:监测是否接收到拾音器唤醒信号;若是,则接收被唤醒的拾音器所反馈的BLE数据;根据所述BLE数据确认目标拾音器;切换所述智能终端与所述目标拾音器的连接为经典蓝牙连接,以及通过所述经典蓝牙连接,接收所述目标拾音器所采集的语音信号。
2023-08-21 -
音乐风格迁移方法、模型训练方法、装置和存储介质
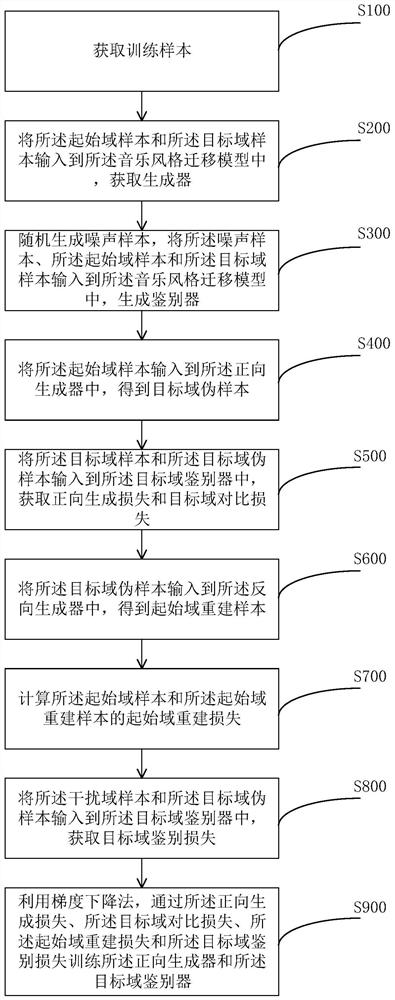
本发明公开了一种音乐风格迁移方法、模型训练方法、装置和存储介质,模型训练方法包括获取训练样本;根据训练样本和噪声样本获取生成器和鉴别器;将训练样本输入到生成器中,得到伪样本;将训练样本和伪样本输入到鉴别器中,获取生成损失和对比损失;将伪样本输入到生成器中,得到重建样本;计算训练样本和重建样本的重建损失;将干扰域样本和伪样本输入到鉴别器中,获取鉴别损失;利用梯度下降法,通过生成损失、对比损失、重建损失和鉴别损失训练生成器和鉴别器。通过将目标域对比损失运用到音频领域以提取并学习目标域的高级特征,实现将音乐风格迁移到不同音乐域的目标,大大降低了音乐风格迁移的训练成本。
2023-08-21 -
一种在线教育功能智能云钢琴系统
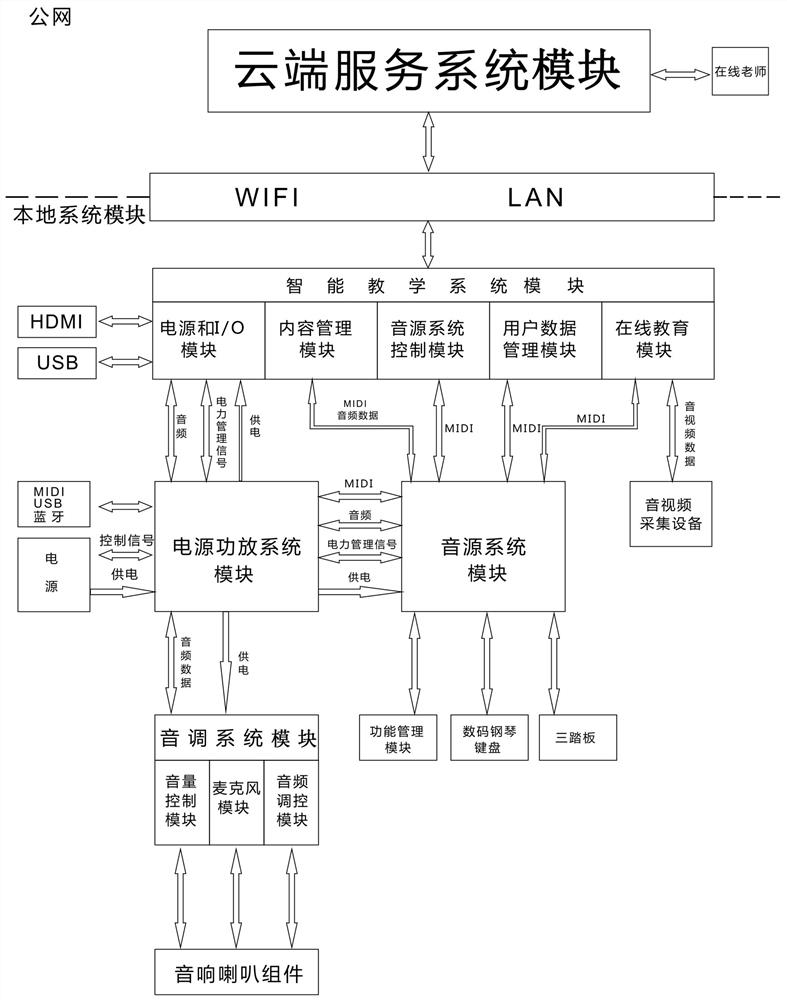
本发明涉及一种具有双向互动功能的在线教育功能智能云钢琴系统。采用的技术方案包括:通过WIFI或有线网络进行数据传输和控制的云端服务系统模块和本地系统模块,其特征在于:所述本地系统模块包括智能教学系统模块、电源功放系统模块、音源系统模块和音调系统模块;所述智能教学系统模块包括电源管理和I/O模、内容管理模块、音源系统控制模块、用户数据管理模块、在线交流教育模块;所述电源管理和I/O模块联合所述电源功放系统模块实现对电源的智能管理。
2023-08-21 -
用于搅拌车驾驶室内声音的降噪方法、装置和搅拌车
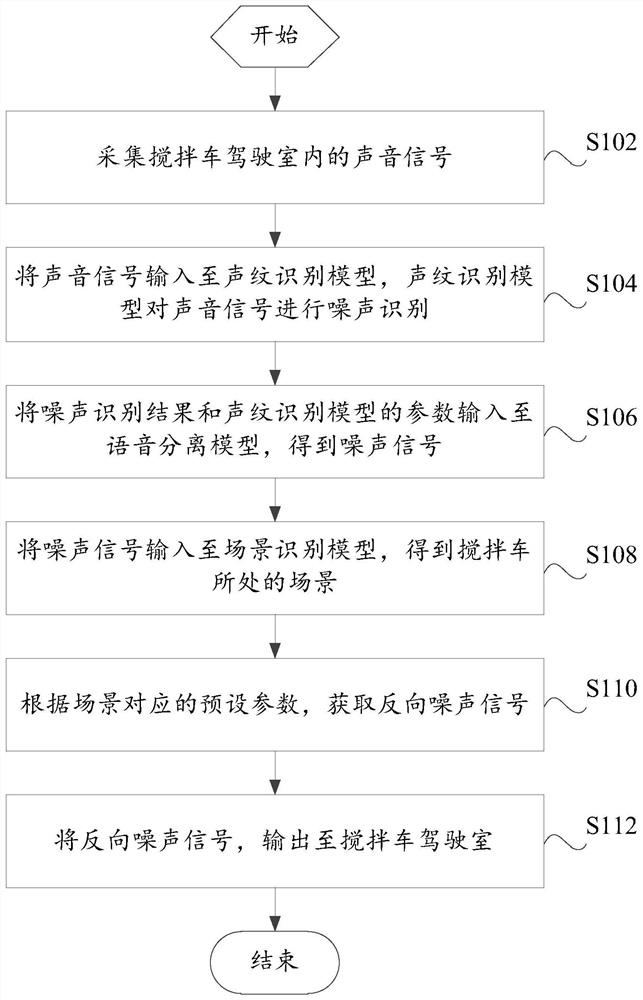
本发明提供了一种用于搅拌车驾驶室内声音的降噪方法、装置和搅拌车。用于搅拌车驾驶室内声音的降噪方法,包括:采集搅拌车驾驶室内的声音信号;将声音信号输入至声纹识别模型,声纹识别模型对声音信号进行噪声识别;将噪声识别结果和声纹识别模型的参数输入至语音分离模型,得到噪声信号;将噪声信号输入至场景识别模型,得到搅拌车所处的场景;根据场景对应的预设参数,获取反向噪声信号;将反向噪声信号,输出至搅拌车驾驶室。本发明通过声纹识别模型进行噪声识别,通过语音分离模型提取噪声信号,有效区分有用的声音和噪声,在去除环境噪声和搅拌机运行噪声的基础上,保留鸣笛声、人声等有用声音,提高驾驶员的驾驶舒适性和安全性。
2023-08-21 -
语音识别系统、指令产生系统及其语音识别方法
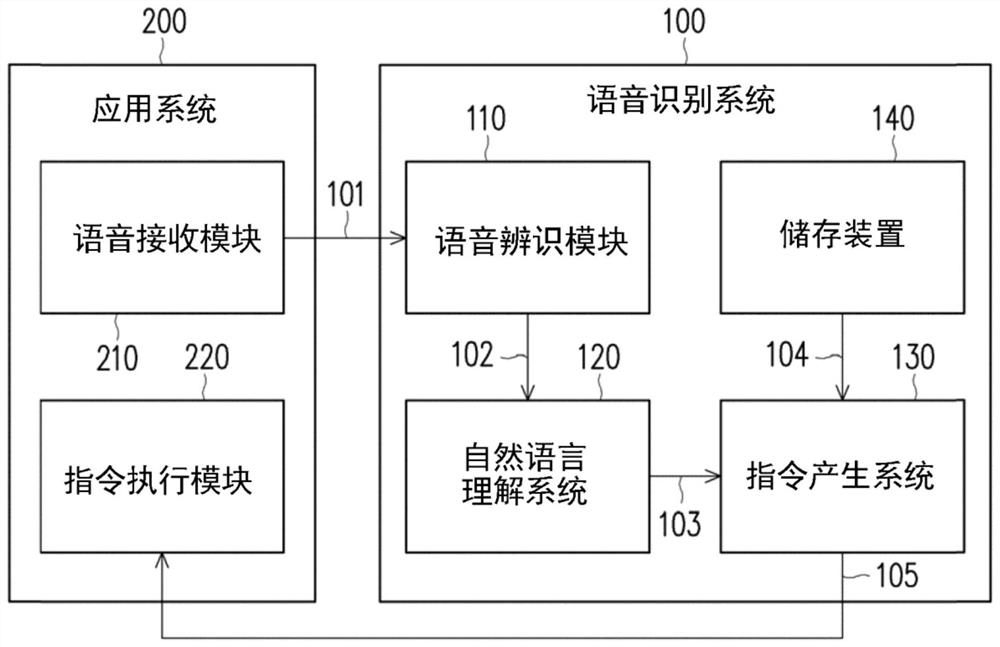
本发明提出一种语音识别系统、指令产生系统及其语音识别方法。语音识别系统适于与应用系统进行通信。应用系统接收语音输入。语音识别系统包括语音辨识模块、自然语音理解系统以及指令产生系统。语音辨识模块接收由应用系统提供的语音输入,并且辨识语音输入,以产生语音信息。自然语音理解系统耦接语音辨识模块。自然语音理解系统理解语音信息,以产生语意分析结果。指令产生系统耦接自然语音理解系统。指令产生系统利用语意分析结果来比较在当前使用者界面的界面内容中的选择项目,并且依据比较结果来输出控制指令至应用系统。由此,除了可提供便捷的语音识别功能,还可降低在应用系统中对于语音识别所需要的系统资源。
2023-08-21 -
基于声纹的通话管理方法、装置、电子设备及存储介质
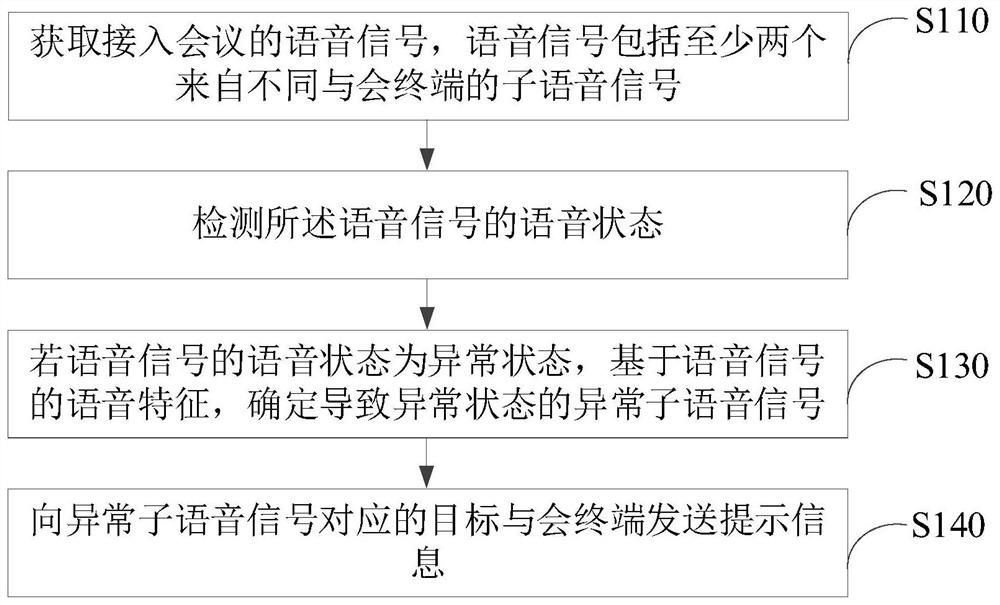
本申请公开了一种基于声纹的通话管理方法、装置、电子设备以及存储介质。该方法包括:获取接入会议的语音信号,所述语音信号包括至少两个来自不同与会终端的子语音信号,检测所述语音信号的语音状态,若所述语音信号的语音状态为异常状态,基于所述语音信号的语音特征,确定导致所述异常状态的异常子语音信号,向所述异常子语音信号对应的目标与会终端发送提示信息。该方法可以提高确定导致异常状态的异常子语音信号的准确性,提高确定异常子语音信号的速度,保证会议正常进行,以及简化会议室现场人员的操作流程。
2023-08-21 -
音频对抗扰动的测试方法、设备及存储介质
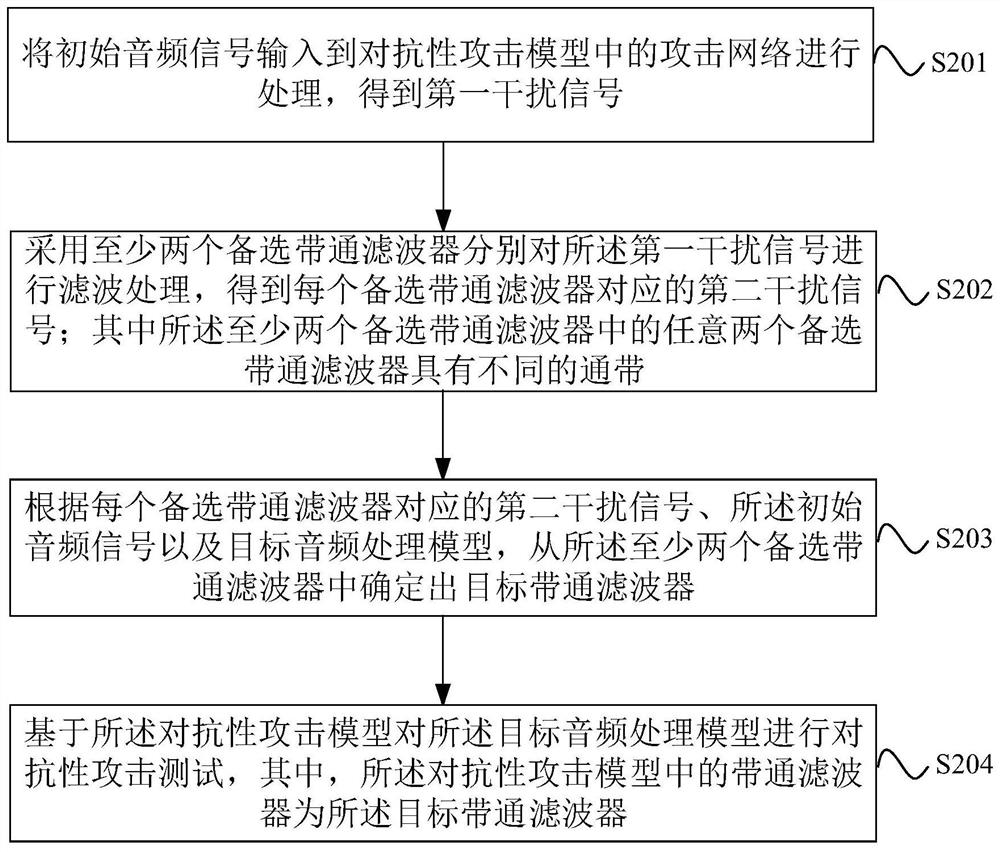
本公开实施例提供一种音频对抗扰动的测试方法、设备及存储介质,通过将初始音频信号输入到对抗性攻击模型的攻击网络获取第一干扰信号;采用具有不同通带的至少两个备选带通滤波器分别对第一干扰信号滤波获取每个备选带通滤波器对应的第二干扰信号;根据各第二干扰信号、初始音频信号及目标音频处理模型确定目标带通滤波器;基于对抗性攻击模型对目标音频处理模型进行对抗性攻击测试,其中对抗性攻击模型中的带通滤波器为目标带通滤波器。本公开实施例从至少两个备选带通滤波器中确定最优的备选带通滤波器作为对抗性攻击模型的目标带通滤波器,使得对抗性攻击模型针对目标音频处理模型生成的对抗音频样本具有最优的对抗性攻击性能。
2023-08-21 -
基于集成学习和卷积神经网络的环境声音识别方法
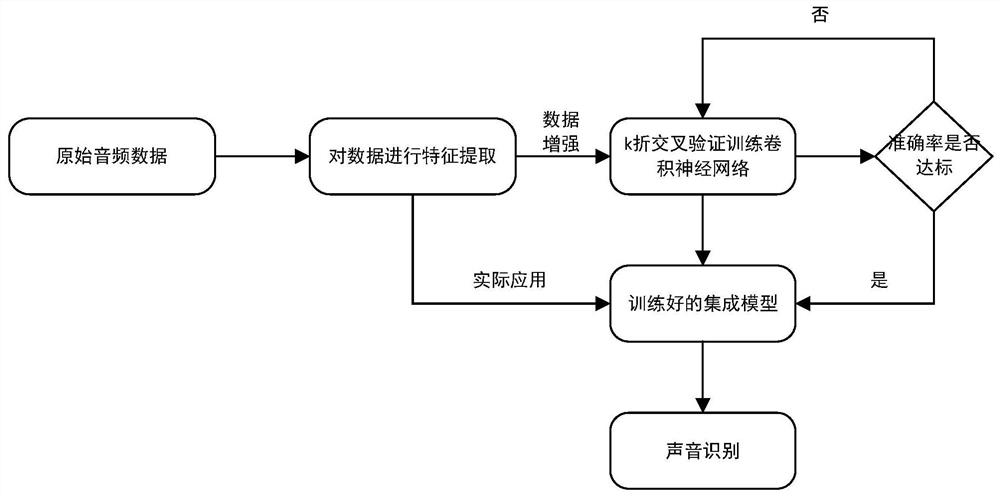
本发明公开了基于集成学习和卷积神经网络的环境声音识别方法,包括:S1、特征提取,对原始音频进行分帧和加窗,利用梅尔滤波器组得到声音的梅尔能量频谱,最终得到最后的梅尔能量频谱特征,作为数据集;S2、模型训练,采用k折交叉验证和使用mixup数据增强方法对于所述数据集进行模型训练,得到K个卷积神经网络模型;S3、声音测试,对待测声音样本通过卷积神经网络模型进行识别。本发明能够利用k折交叉验证训练k个模型并结合k个模型进行声音识别,大大增强了模型的泛化能力,有效缓解了过拟合的现象,此外针对数据量不大的情况,使用mixup数据增强对原始样本进行混合以进一步增强模型的泛化能力。
2023-08-21 -
一种语音识别方法、装置、设备及存储介质
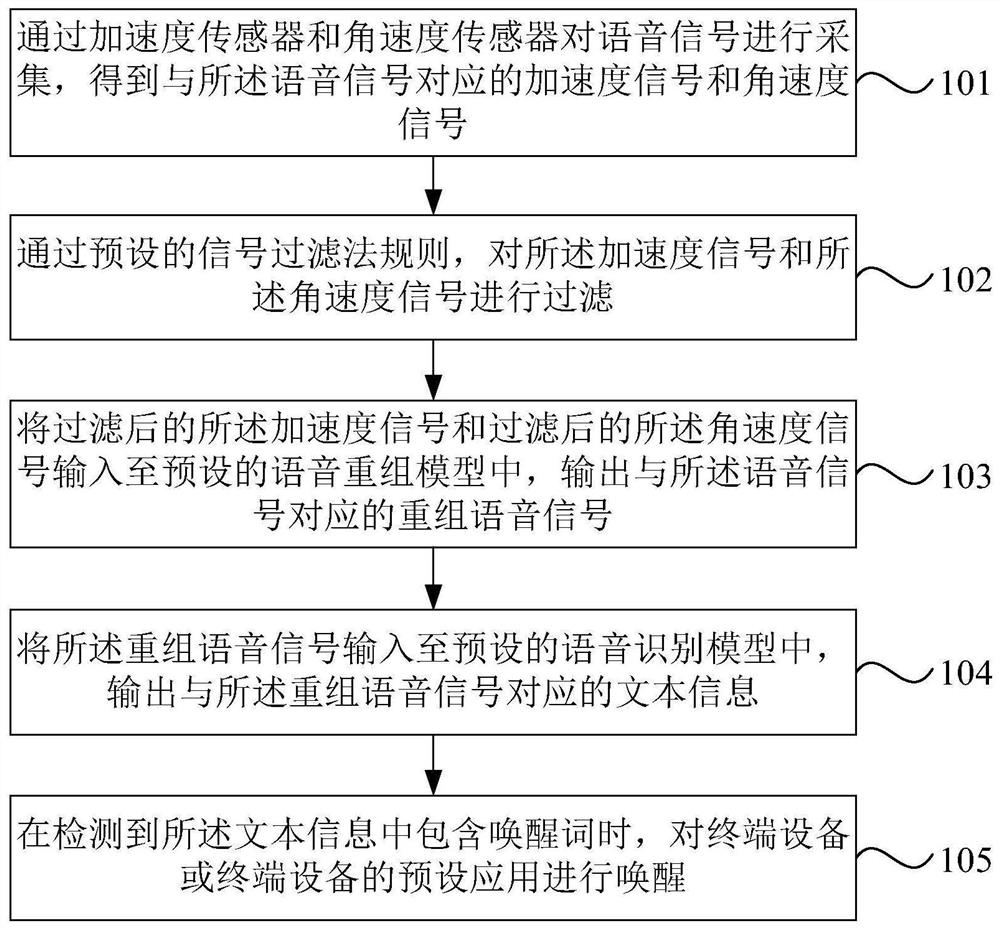
本发明实施例公开了一种语音识别方法、装置、设备及存储介质。方法包括:通过加速度传感器和角速度传感器对语音信号进行采集,得到与语音信号对应的加速度信号和角速度信号;通过预设的信号过滤法规则,对加速度信号和角速度信号进行过滤;将过滤后的加速度信号和过滤后的角速度信号输入至预设的语音重组模型中,输出与语音信号对应的重组语音信号;将重组语音信号输入至预设的语音识别模型中,输出与重组语音信号对应的文本信息;在检测到文本信息中包含唤醒词时,对终端设备或终端设备的预设应用进行唤醒。本发明实施例可以在用户无感知的情况下进行唤醒识别,既能保证唤醒识别效率又做到无干扰,提高用户体验。
2023-08-21 -
一种基于双麦克风系统检测和定位无声语音指令的方法
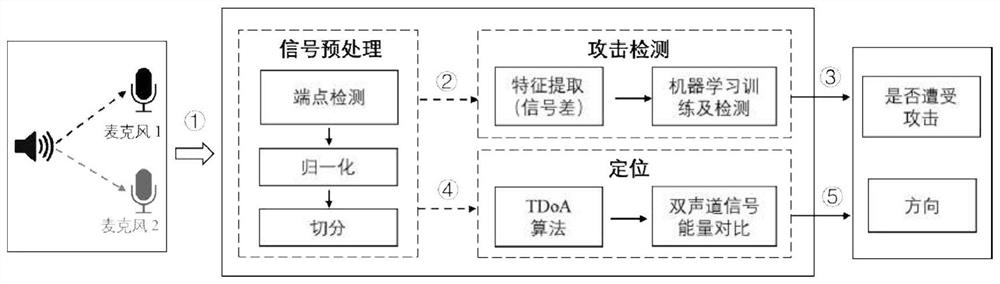
本发明公开了一种基于双麦克风系统检测和定位无声语音指令的方法。所述方法利用智能设备上的双麦克风系统对“海豚音攻击”进行检测和定位。通过对声音信号进行预处理和特征提取,继而训练二分类机器学习模型,利用训练好的模型进行无声语音指令的检测,这种方法可以有效的识别接收到的语音指令是“无声”的还是正常的指令,进而取消无声指令的识别和执行,然后对攻击者进行定位,从而更快的发现攻击者。
2023-08-21 -
一种适用于演出场所的声音反射板
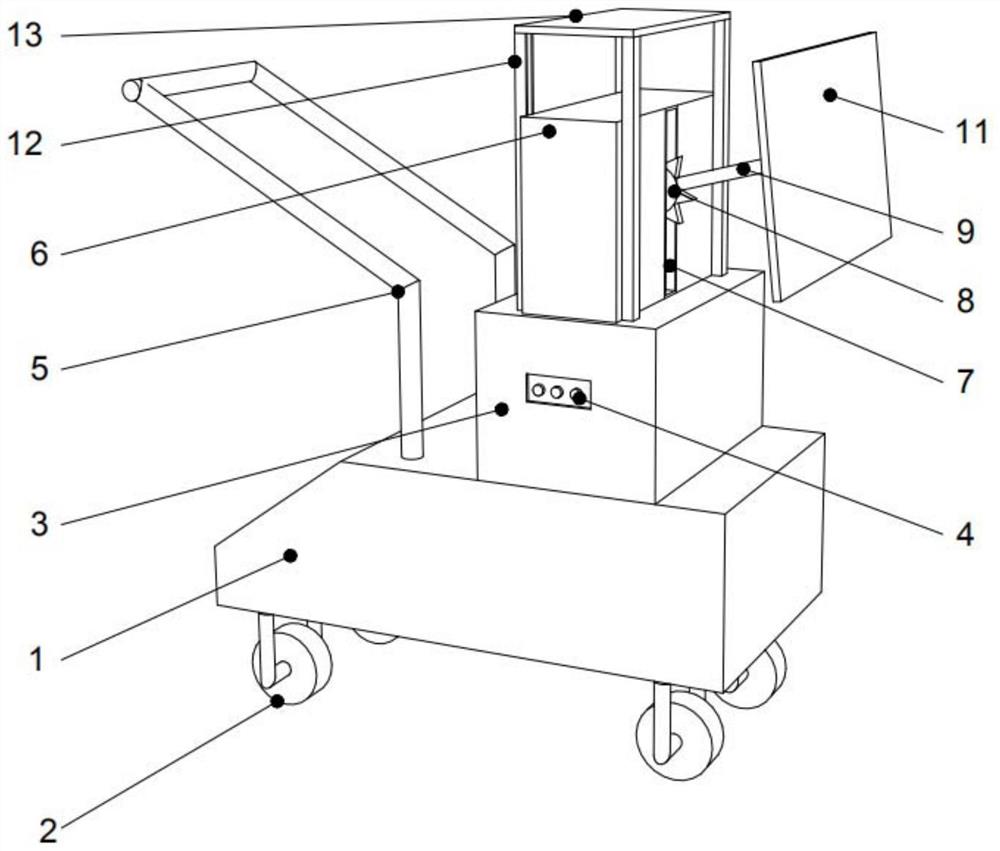
本发明提出了一种适用于演出场所的声音反射板,包括箱体和万向轮,箱体的底部设有万向轮,万向轮通过螺丝与箱体固定连接,箱体的底部设有底座,底座通过螺丝与箱体固定连接,底座的一侧设有控制中心,控制中心通过螺丝与底座固定连接,箱体的一侧设有推手,推手通过焊接与箱体固定连接。该种适用于演出场所的声音反射板,通过设有的万向轮,实现了该设备的移动,且不需要安装,解决了安装费用的问题,通过该设备体型较小,结构简单,解决了高昂的材料费用问题,通过设有的控制中心,实现了该设备的控制功能,提高了便捷性,通过偏转杆的一端设有固定板,实现了声音反射板的固定,提高了稳定性。
2023-08-21 -
一种韵律预测的方法、装置、设备及存储介质
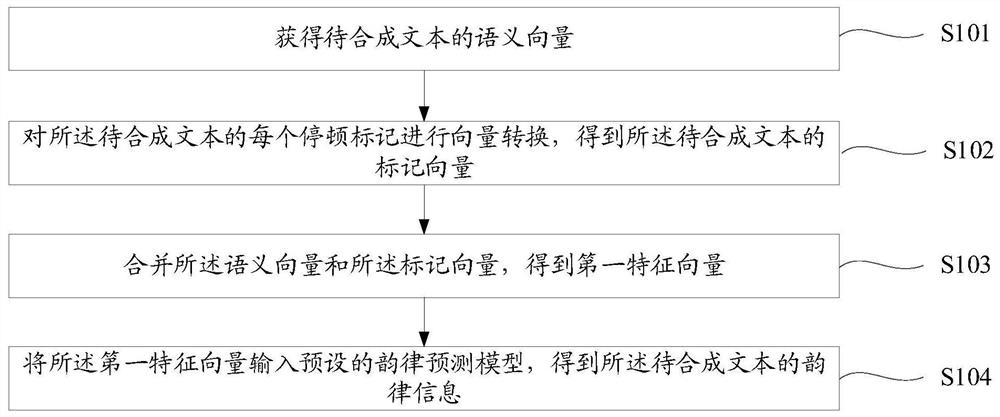
本申请提供了一种韵律预测的方法、装置、设备及存储介质,涉及自然语言理解技术领域。从文本语义和文本标点两方面分析文本语义,再综合文本语义和文本标点对文本语义的影响,预测该文本的韵律信息,保证在文本本身出现歧义的情况下,能够准确地预测文本的韵律信息。所述方法包括:获得待合成文本的语义向量;对所述待合成文本的每个停顿标记进行向量转换,得到所述待合成文本的标记向量;合并所述语义向量和所述标记向量,得到第一特征向量;将所述第一特征向量输入预设的韵律预测模型,得到所述待合成文本的韵律信息。
2023-08-21 -
扫地机降噪方法、装置、扫地机及计算机可读存储介质
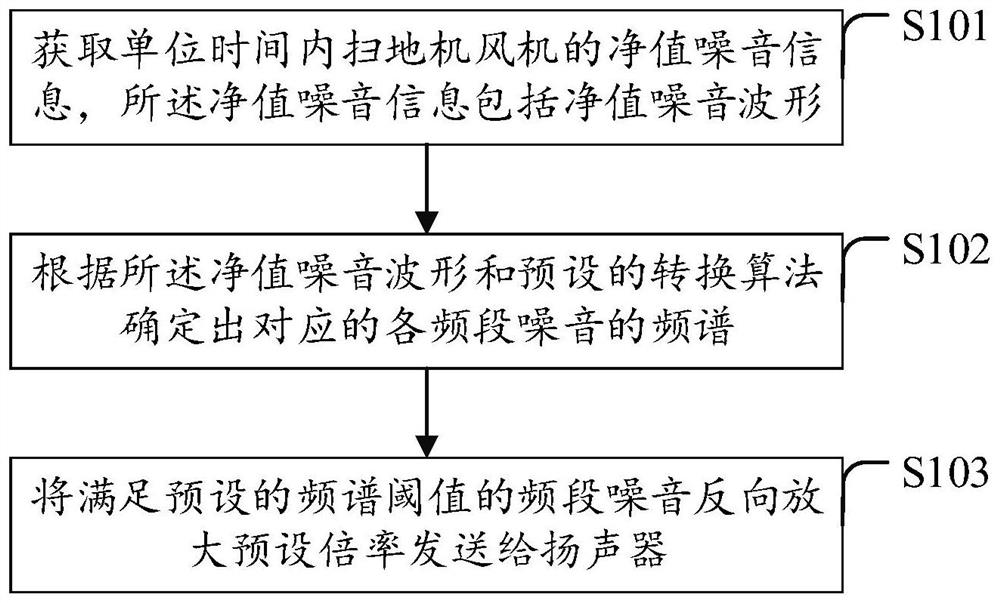
本发明适用于扫地机技术领域,提供一种扫地机降噪方法,该方法包括:获取单位时间内扫地机风机的净值噪音信息,所述净值噪音信息包括净值噪音波形;根据所述净值噪音波形和预设的转换算法确定出对应的各频段噪音的频谱;将满足预设的频谱阈值的频段噪音反向放大预设倍率发送给扬声器。本发明实施例还提供一种扫地机降噪装置、扫地机及计算机可读存储介质。本发明实施例提供的扫地机降噪方法,可以有效降低扫地机工作过程中产生的噪音,减少噪音污染,提高用户使用体验。
2023-08-21 -
音频信号处理方法、装置、电子设备和可读存储介质
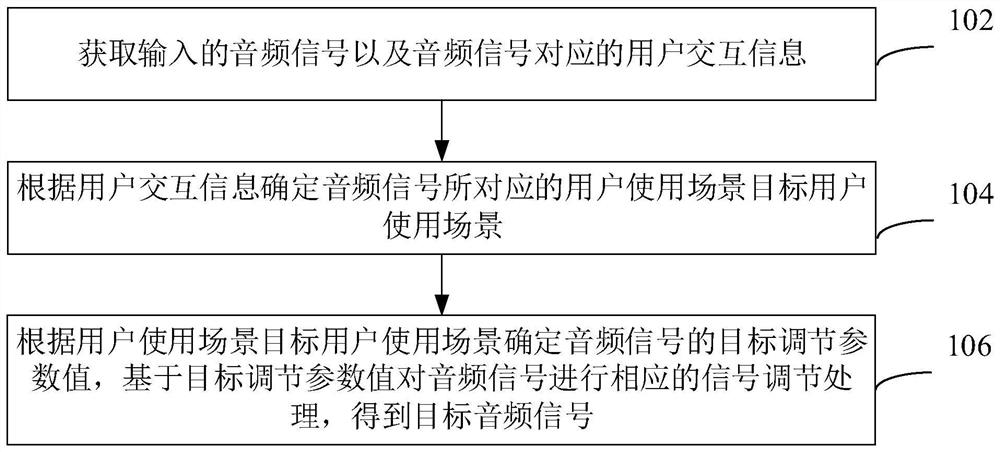
本申请提供了一种音频信号处理方法、装置、电子设备和可读存储介质,所述音频信号处理方法包括:获取输入的音频信号以及所述音频信号对应的用户交互信息;根据所述用户交互信息确定所述音频信号所对应的目标用户使用场景;根据所述目标用户使用场景确定所述音频信号的目标调节参数值,基于所述目标调节参数值对所述音频信号进行相应的信号调节处理,得到目标音频信号。采用本申请的方法能够减少音频信号的误识别情况。
2023-08-21 -
一种英语口语角色扮演题评分方法及系统
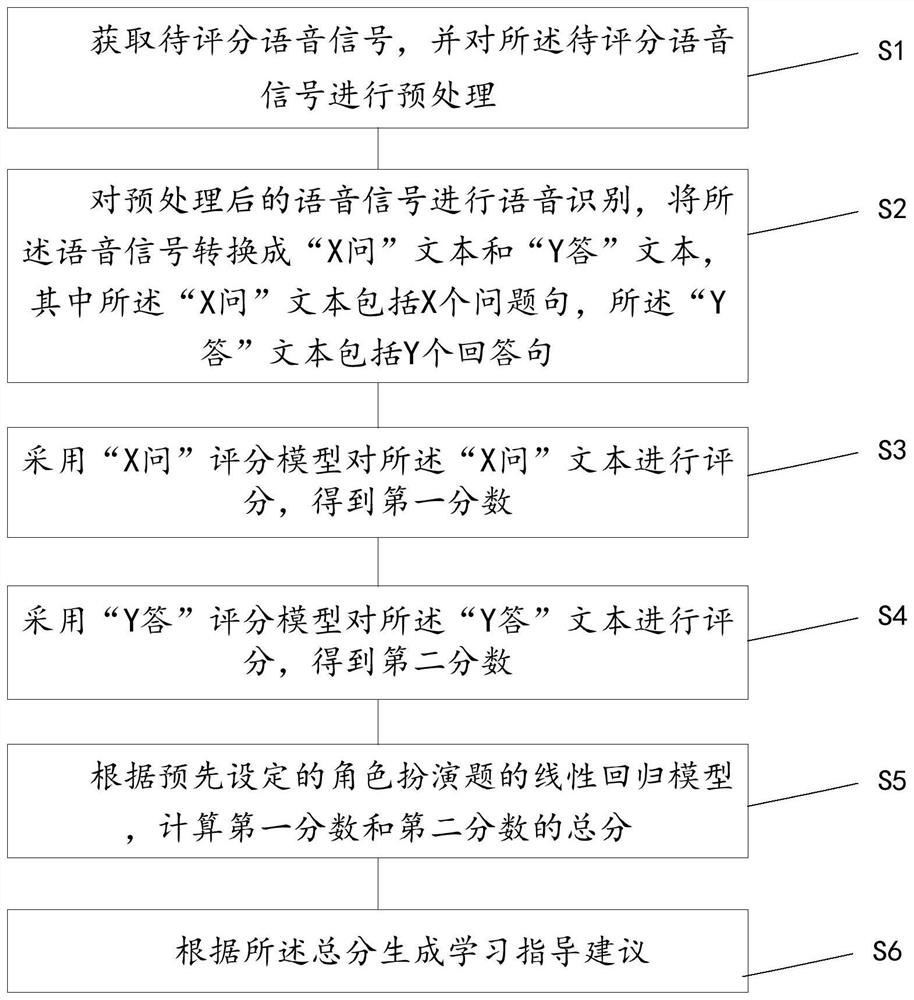
本发明公开了一种英语口语角色扮演题评分方法及系统,所述方法包括:获取待评分语音信号,并对所述待评分语音信号进行预处理;对预处理后的语音信号进行语音识别,将所述语音信号转换成“X问”文本和“Y答”文本,其中所述“X问”文本包括X个问题句,所述“Y答”文本包括Y个回答句;采用“X问”评分模型对所述“X问”文本进行评分,得到第一分数;采用“Y答”评分模型对所述“Y答”文本进行评分,得到第二分数;根据预先设定的角色扮演题的线性回归模型,计算第一分数和第二分数的总分;根据所述总分生成学习指导建议。本发明能有效提高角色扮演题评分的高效性和准确性,实现全自动评分方式,有效节省人力物力,减轻教师的教学负担。
2023-08-21 -
空间音频参数的量化
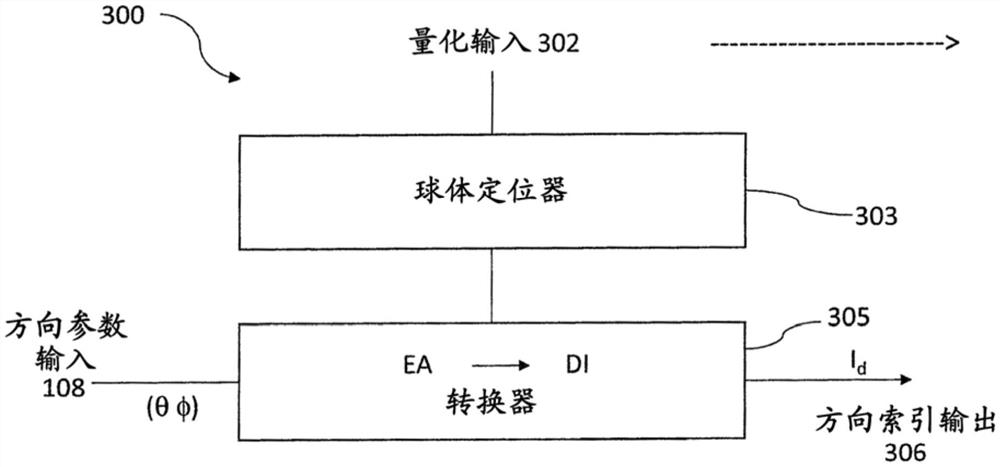
特别公开了一种用于空间音频信号编码的装置,该装置确定至少一个空间音频参数,该空间音频参数包括具有仰角分量和方位角分量的方向参数。进而,该方向参数的仰角分量和方位角分量被转换成索引值。
2023-08-21 -
空间音频参数和相关联的空间音频播放
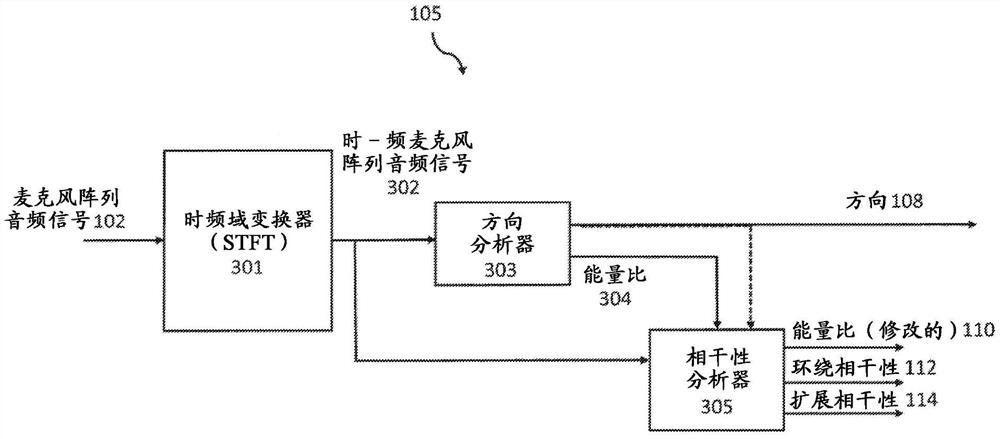
一种装置(105)包括至少一个处理器和至少一个包括计算机程序代码的存储器,该至少一个存储器和该计算机程序代码被配置为与该至少一个处理器一起使该装置(105)至少:对于两个或更多个麦克风音频信号(102),确定用于提供空间音频再现的至少一个空间音频参数(108,304);基于该两个或更多个麦克风音频信号(102),确定与声场相关联的至少一个相干性参数(112,114),使得另一声场被配置为基于该至少一个空间音频参数(108,304)和该至少一个相干性参数(112,114)被再现。
2023-08-21 -
包括处理用户语音的电子设备和控制电子设备上语音识别的
方法的系统
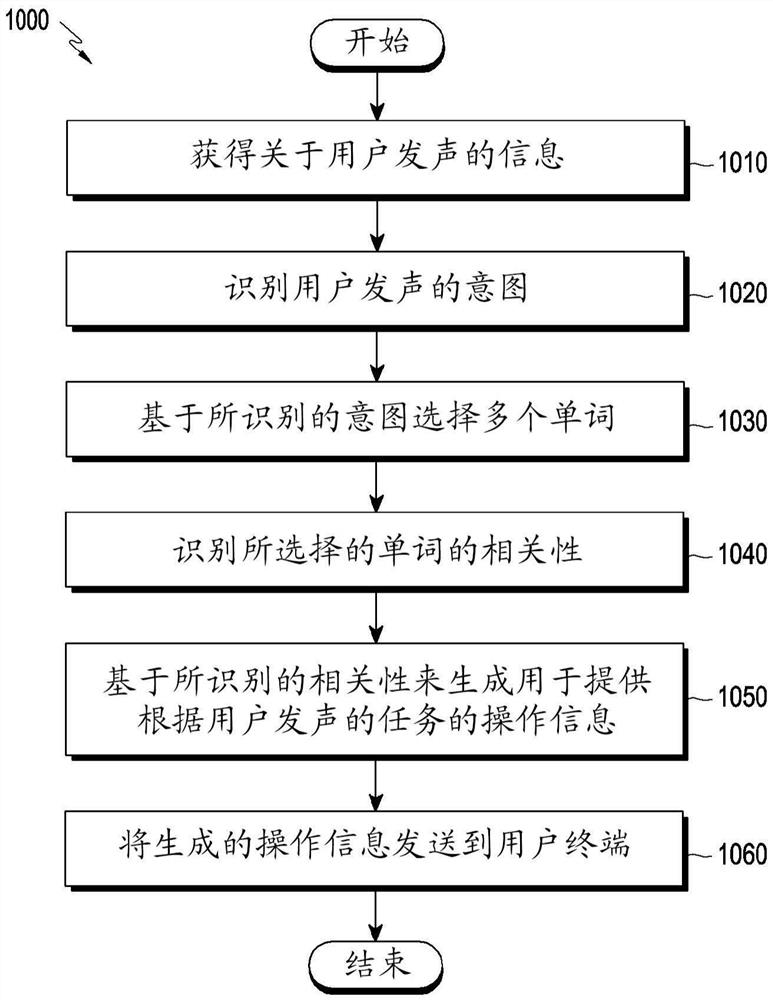
提供了一种包括识别和处理用户语音的电子设备以及一种控制电子设备上的语音识别的方法的系统。根据实施例,电子设备包括通信电路、输入模块、至少一个处理器和存储器,存储器可操作地与至少一个处理器、输入模块和通信电路连接,其中存储器存储指令,指令被配置成使至少一个处理器能够根据用户的用于唤醒的第一发声提供功能,在提供功能的同时通过输入模块接收用户的第二发声,第二发声包括具有预定的相关性的多个单词,经由通信电路将关于用户的第二发声的信息发送到另一电子装置,并根据发送从第二电子设备接收关于用户的第二发声的响应,并提供所接收的响应。
2023-08-21 -
音频处理方法、装置、电子设备及存储介质
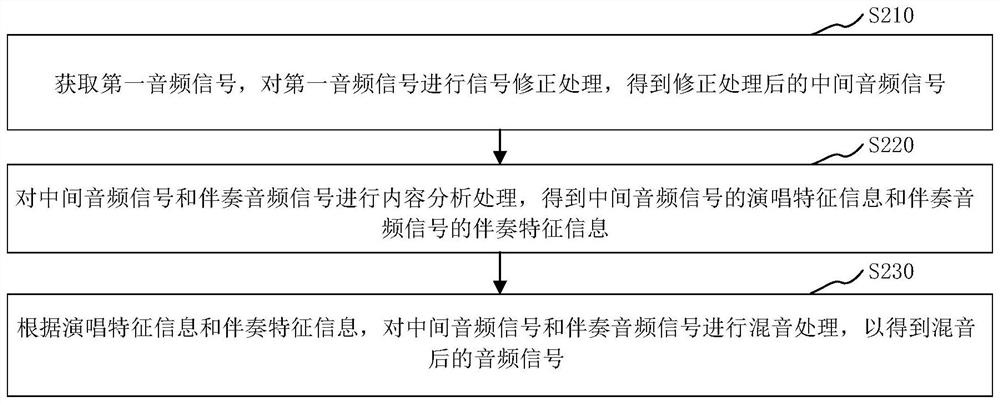
本公开关于一种音频处理方法、装置、电子设备及存储介质,通过获取第一音频信号,对所述第一音频信号进行信号修正处理,得到修正处理后的中间音频信号,并对所述中间音频信号和伴奏音频信号进行内容分析处理,得到所述中间音频信号的演唱特征信息和所述伴奏音频信号的伴奏特征信息,从而根据所述演唱特征信息和所述伴奏特征信息,对所述中间音频信号和所述伴奏音频信号进行混音处理,以得到混音后的音频信号,通过对所述中间音频信号和所述伴奏音频信号进行混音处理能够美化人声,实现良好的混音效果,得到听感质量高的音乐,提高用户的演唱水效果,并逼近专业演唱者的水准。
2023-08-21 -
多人会话检测方法、系统、移动终端及存储介质
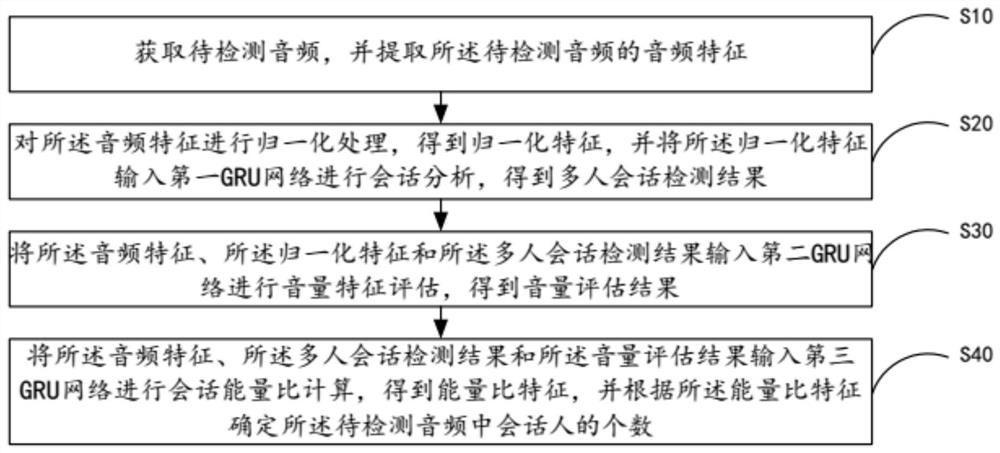
本发明提供了一种多人会话检测方法、系统、移动终端及存储介质,该方法包括:对待检测音频的音频特征进行归一化处理得到归一化特征,将归一化特征输入第一GRU网络进行会话分析得到多人会话检测结果;将音频特征、归一化特征和多人会话检测结果输入第二GRU网络进行音量特征评估得到音量评估结果;将音频特征、多人会话检测结果和音量评估结果输入第三GRU网络进行会话能量比计算,得到能量比特征;根据能量比特征确定待检测音频中会话人的个数。本发明通过该第一GRU网络、第二GRU网络和第三GRU网络的设计,能识别到多人会话对应音频段的位置,且能识别到待检测音频中对应会话人的个数和每个会话人对应的音频数据,提高了多人会话检测的准确率。
2023-08-21 -
一种音色转换方法和装置
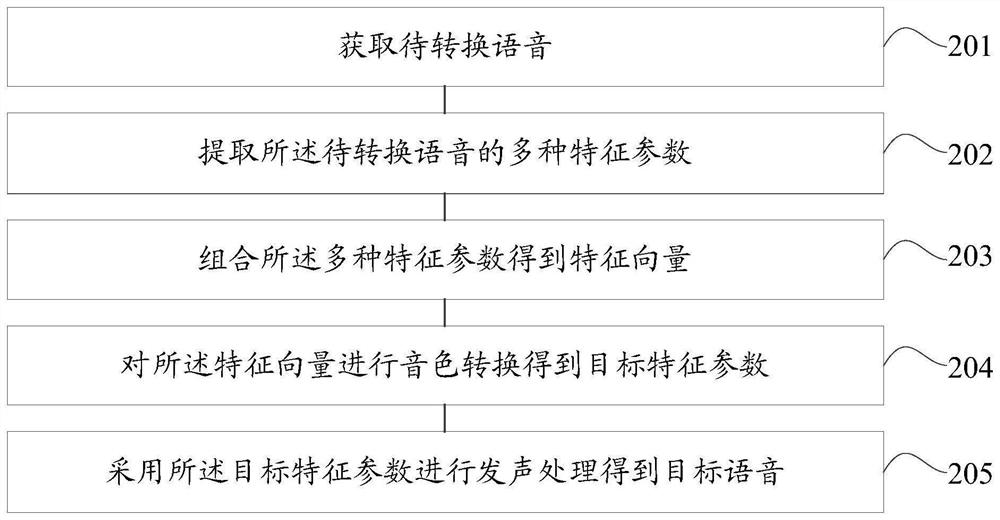
本发明实施例提供了一种音色转换方法和装置,其中,所述方法包括:获取待转换语音;提取所述待转换语音的多种特征参数;组合所述多种特征参数得到特征向量;对所述特征向量进行音色转换得到目标特征参数;采用所述目标特征参数进行发声处理得到目标语音。使得可以对待转换语音的多种特征参数进行音色转换,彻底将待转换语音的多种特征参数转换到目标人的特征参数,改善转换结果的自然度和稳定度,使得转换后的语音能保留原发音人的语气,语调等特征。
2023-08-21 -
语音情感识别方法以及装置
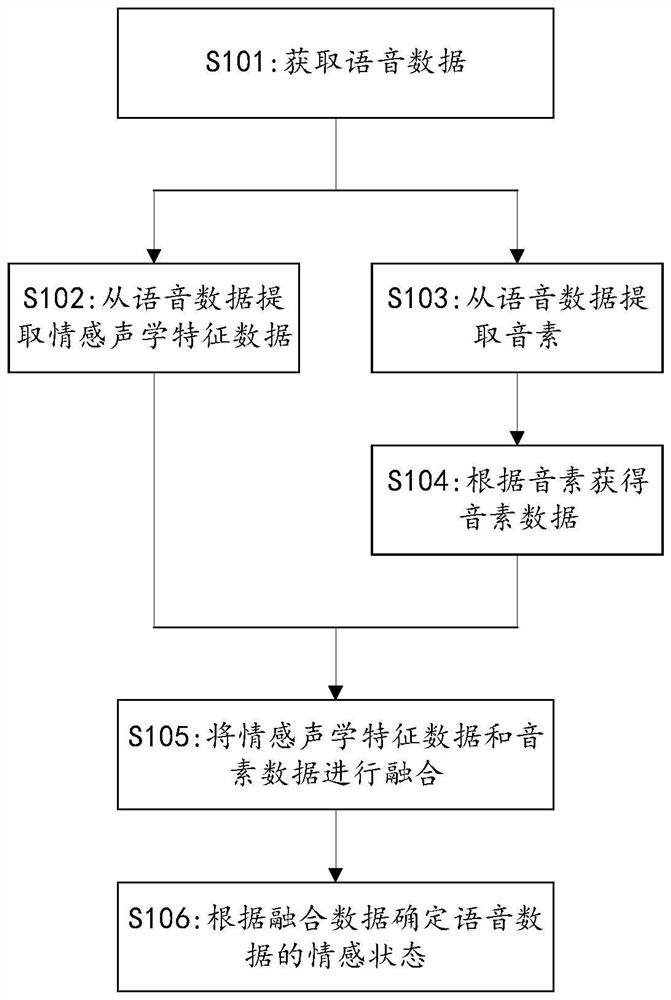
本申请提供了一种语音情感识别方法、装置以及系统,可应用于人工智能领域语音识别场景。所述方法包括:获取语音数据,其中,语音数据包括t个语音帧I,I,…,I;将语音帧I,I,…,I分别输入声学特征识别模型,从而得到语音帧I,I,…,I各自的情感声学特征数据S,S,…,S;将语音帧I,I,…,I分别输入音素识别模型,从而得到语音帧I,I,…,I各自的所属的音素M,M,…,M;根据语音帧I,I,…,I各自的所属的音素M,M,…,M,确定语音帧I,I,…,I各自的音素数据N,N,…,N;将情感声学特征数据S,S,…,S和音素数据N,N,…,N进行融合,从而得到融合数据R,R,…,R;将融合数据R,R,…,R输入情感状态识别模型,从而确定语音数据的情感状态。
2023-08-21 -
双麦克风阵列波束形成方法、装置及设备
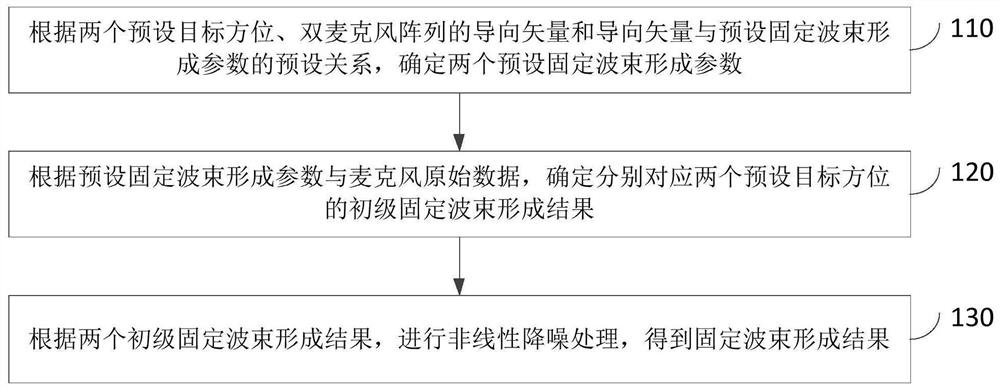
本发明实施例公开了一种双麦克风阵列波束形成方法、装置及设备。该方法包括:根据两个预设目标方位、双麦克风阵列的导向矢量和所述导向矢量与预设固定波束形成参数的预设关系,确定两个所述预设固定波束形成参数;其中,两个所述预设固定波束形成参数与两个所述预设目标方位一一对应;根据所述预设固定波束形成参数与麦克风原始数据,确定分别对应两个所述预设目标方位的初级固定波束形成结果;根据两个所述初级固定波束形成结果,进行非线性降噪处理,得到固定波束形成结果。本发明实施例的技术方案,实现不增加成本和麦克风阵列线路布置难度的情况下,减少目标方向语音失真,获得较为干净的语音信号,提高语音识别率。
2023-08-21 -
通过耳机进行语音识别的方法、耳机、语音识别装置
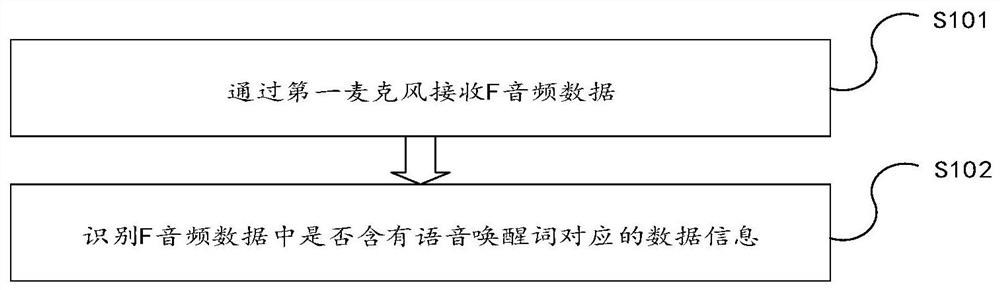
本申请提供了一种通过耳机进行语音识别的方法,包括通过第一麦克风接收F音频数据;识别所述F音频数据中是否含有语音唤醒词对应的数据信息。其中,所述F音频数据包括第一时间段内接收并缓存的第一音频数据和第二时间段内接收的第二音频数据。本申请提供的通过耳机进行语音识别的方法,将第一时间段内接收并缓存的第一音频数据和第二时间段内接收的第二音频数据进行合并识别,确保在进行语音识别唤醒词时不会丢词。
2023-08-21 -
双麦克风阵列声源定向方法、装置及设备

本发明实施例公开了一种双麦克风阵列声源定向方法、装置及设备。该方法包括:根据两个预设目标方位、双麦克风阵列的导向矢量和导向矢量与预设固定波束形成参数的预设关系,确定两个预设固定波束形成参数;根据预设固定波束形成参数与麦克风原始数据,确定分别对应两个预设目标方位的初级固定波束形成结果;根据两个所述初级固定波束形成结果,进行非线性降噪处理,得到固定波束形成结果;根据两个所述固定波束形成结果,确定分别与两个所述预设目标方位对应的信号能量;根据两个所述信号能量和所述信号能量与所述预设目标方位的对应关系,确定声源方位。本发明实施例的技术方案,实现在麦克风距离较近的情况,提高声源定向准确性。
2023-08-21 -
一种能够识别多语言的自动售货设备及自动售货方法
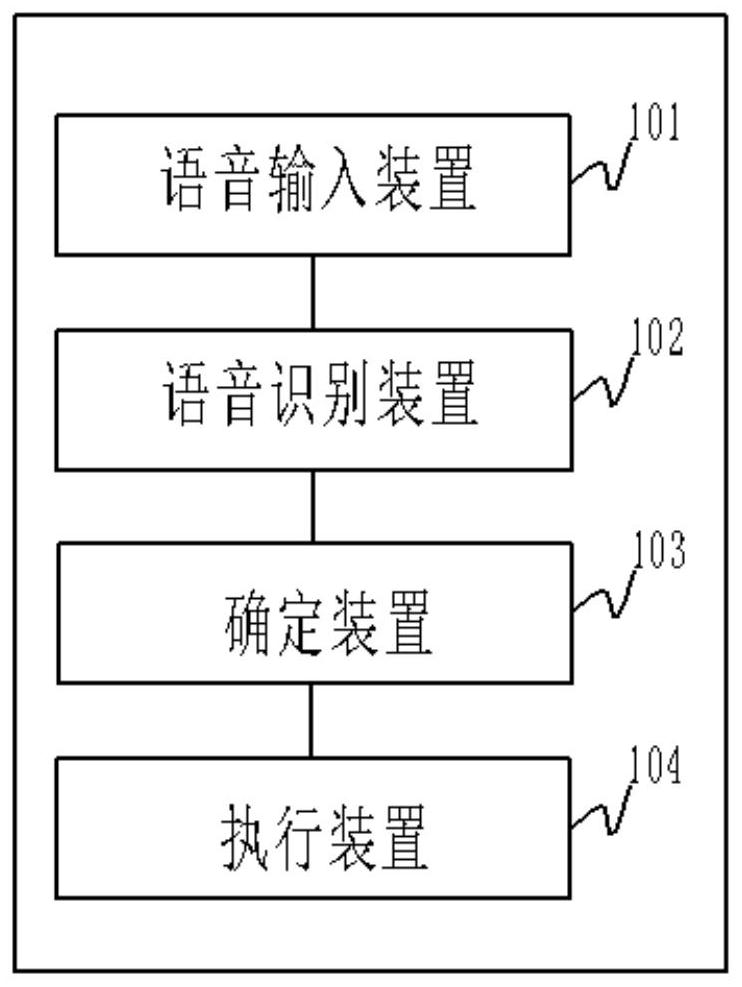
本申请提供了一种能够识别多语言的自动售货设备及自动售货方法,所述自动售货设备包括:用于接收包括用户语音在内的语音信号的语音输入装置;用于基于多国语言或/和多地区语言的统计语言模型对用户语音进行识别,得到与用户语言对应的国别或/和地区和与用户语言对应的文本的语音识别装置;用于确定所述自动售货设备所执行的与所识别的国别或/和地区和所识别的文本对应的命令的确定装置;用于执行确定装置所确定的命令的执行装置。基于本申请提供的自动售货设备及自动售货方法,可以进一步实现商品的促销和提高自动售货设备与用户的互动性,进而提升用户对出货过程的体验。
2023-08-21 -
实时响应方法、计算机可读存储介质及车载终端
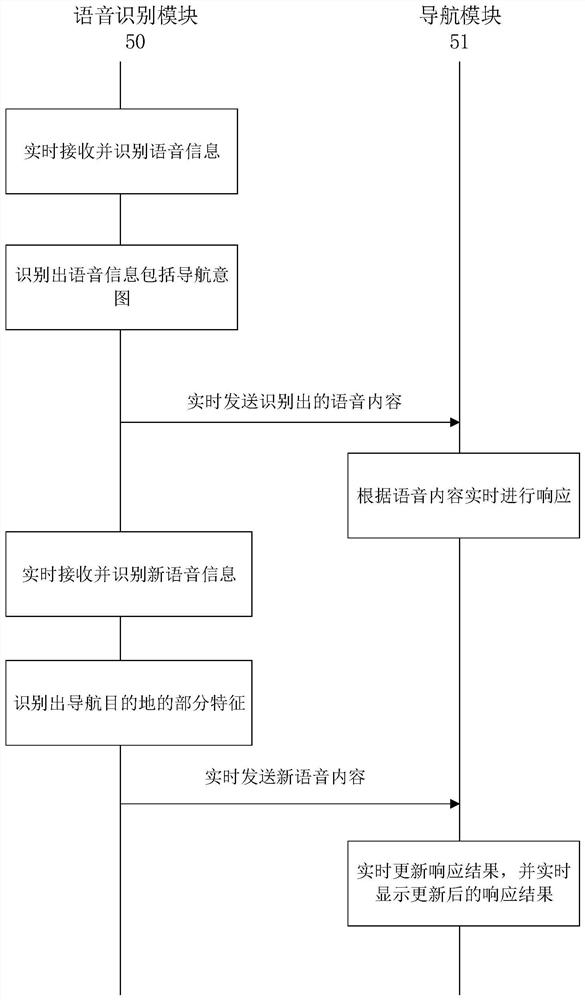
本发明提供一种实时响应方法,应用于终端,包括:实时接收用户的语音信息;实时对所述语音信息进行语音识别;在识别出所述语音信息包括操作意图时,根据所述语音信息实时进行响应。本发明还提供一种计算机可读存储介质及车载终端,本发明的实时响应方法、计算机可读存储介质及车载终端,在识别出所述语音信息包括操作意图时能根据语音信息实时进行响应,缩短了用户的等待时间,提高了响应的实时性。
2023-08-21 -
一种语音处理方法、装置及电子设备
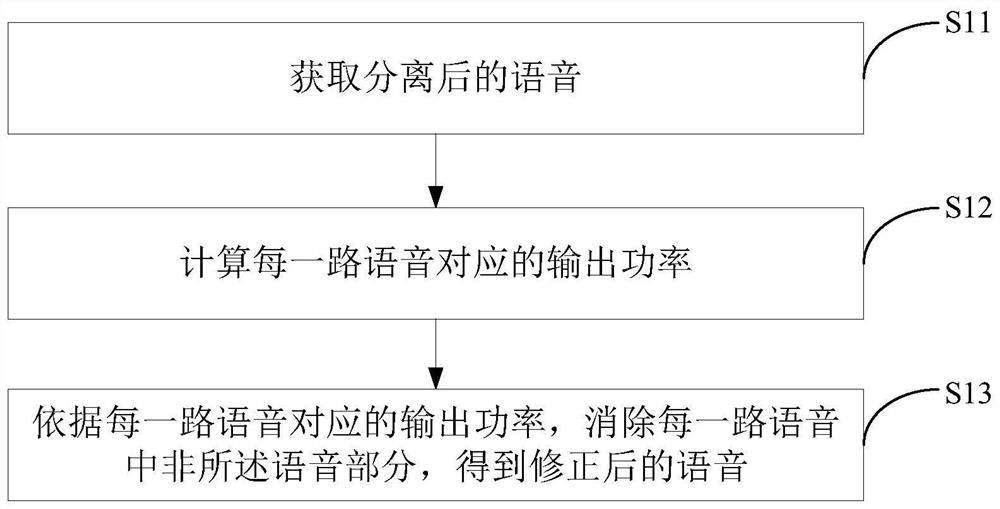
本发明提供了一种语音处理方法、装置及电子设备,获取分离后的语音,计算每一路所述语音对应的输出功率,依据每一路所述语音对应的输出功率,消除每一路所述语音中非所述语音部分,得到修正后的语音。通过本发明,在采用波束成形算法BF进行语音分离得到分离后的语音之后,依据每一语音对应的输出功率来消除语音中的干扰,使得最终得到的修正后的语音中干扰量更小。
2023-08-21 -
一种语音信息的处理方法、装置及电子设备

本发明公开了一种声音信息的处理方法、装置、电子设备及计算机可读存储介质,该处理方法包括:接收用户输入的控制语音;根据控制语音获取待处理的目标语音信息和对应的目标处理指令;根据目标处理指令对目标语音信息进行相应的处理,得到处理后的目标语音信息。
2023-08-21 -
语音唤醒识别方法、装置、电子设备及存储介质
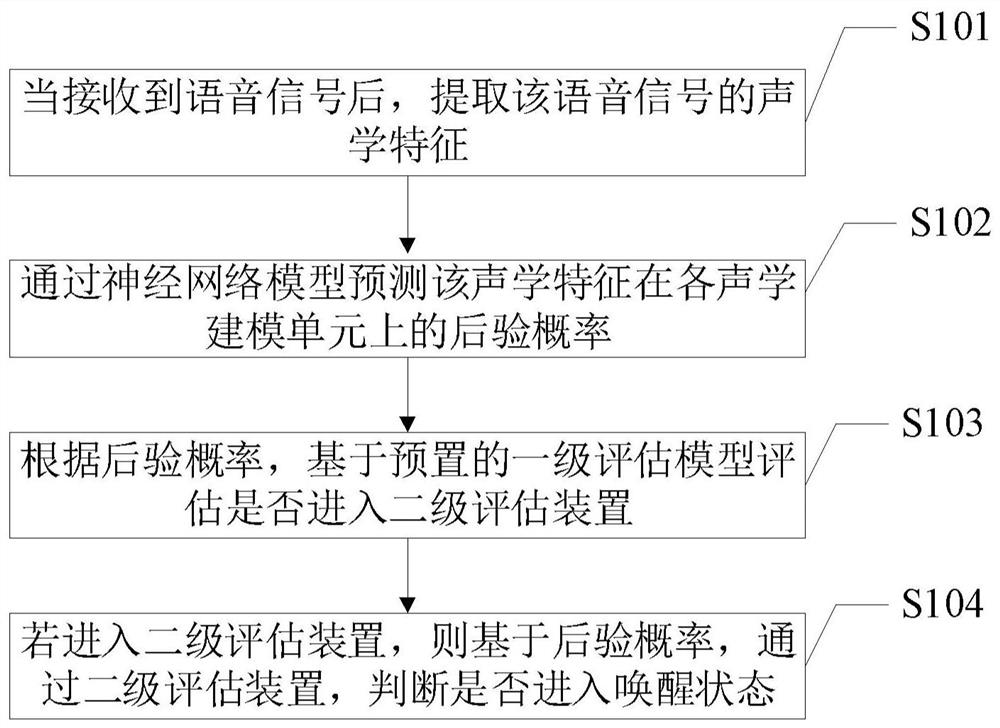
一种语音唤醒识别方法,应用于语音识别领域,包括:当接收到语音信号后,提取语音信号的声学特征,通过神经网络模型预测声学特征在各声学建模单元上的后验概率,根据后验概率,基于预置的一级评估模型评估是否进入二级评估装置,若进入二级评估装置,则基于后验概率,通过二级评估装置,判断是否进入唤醒状态。本发明还公开了一种语音唤醒识别装置、电子设备及存储介质,具有简单易行、功耗低,同时在保证唤醒率的前提下,降低了误唤醒率。
2023-08-21 -
用于家用电器的控制指令自定义方法
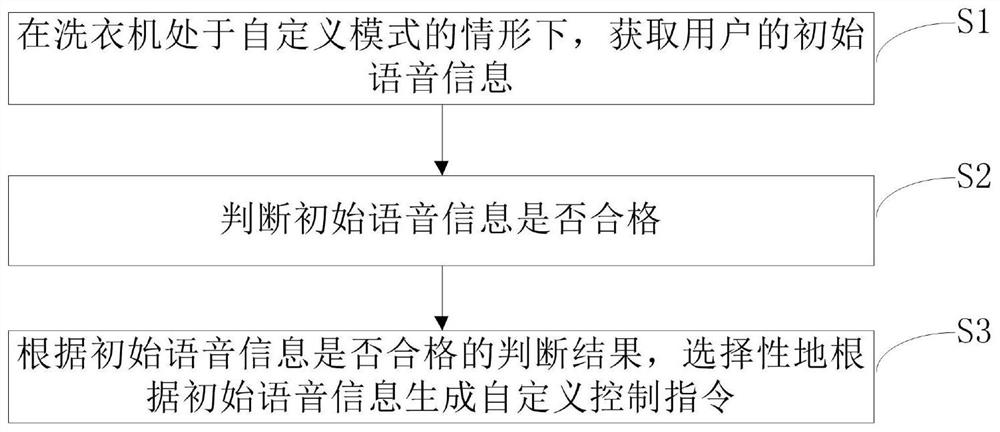
本发明涉及家用电器技术领域,具体提供一种用于家用电器的控制指令自定义方法,旨在解决用户必须准确地输入与预先存储的语音控制信号一模一样的语音控制信号才能够生成控制指令的问题。为此目的,本发明的控制指令自定义方法包括下列步骤:在家用电器处于自定义模式的情形下,获取用户的初始语音信息;判断初始语音信息是否合格;根据初始语音信息是否合格的判断结果,选择性地根据初始语音信息生成自定义控制指令。本发明根据初始语音信息是否合格的判断结果,选择性地根据初始语音信息生成自定义控制指令,用户只需要按照自己的语言表达习惯就能够准确地激活自定义控制指令,满足了不同语言、不同用户的使用需求。
2023-08-21 -
风笛
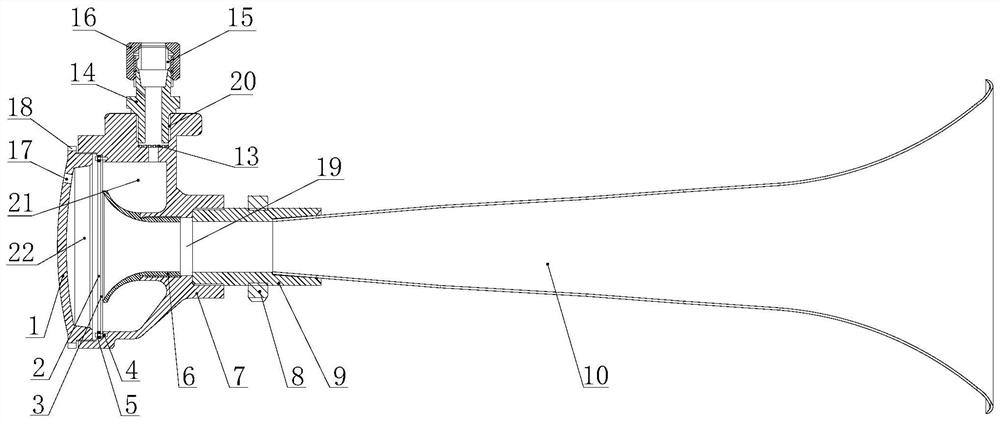
本发明提供了一种风笛,属于发声设备技术领域,包括风笛座、发声结构、喇叭、调频座以及风源连接部,本发明提供的风笛,使用时,将风源或者压缩气源连接于风源连接部上,气体穿过风源连接部进入到风笛座内的第一气室内,气体在第一气室内与发声结构相互作用,使发声结构变形并通过喇叭发出声音,发声结构的变形并恢复的频率形成风笛的发声频率,通过调节调频座伸入开口腔的距离改变发声结构与调频座之间的空间,使得发声结构朝向第二气室的变形量不同,发声结构回复原形的时间随着第二气室空间大小而变化,进而改变风笛的频率。
2023-08-21 -
一种机车司机作业标准语音识别装置及其语音识别方法
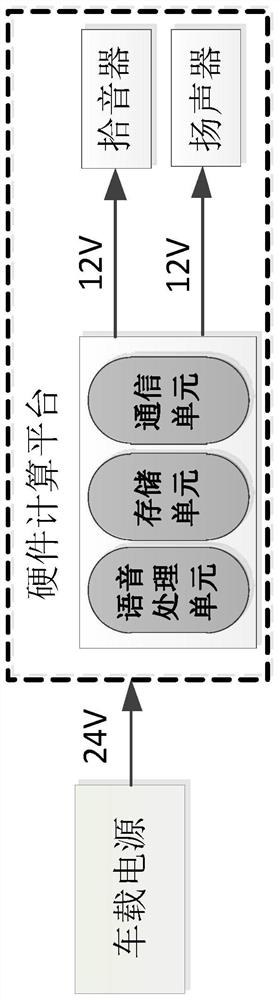
本发明公开了一种机车司机作业标准语音识别装置,包括拾音器、扬声器和硬件计算平台,所述拾音器采集机车司机室的语音数据,所述扬声器播报语音对司机进行反馈,所述硬件计算平台包括语音处理单元、储存单元和通信单元,所述语音处理单元包括特征提取模块和语音识别模块,所述储存单元将所述语音识别步骤的语音识别结果和其相关数据进行储存,所述通信单元用于实现所述硬件计算平台和外部设备的通信。
2023-08-21