计算存储装置和用于操作计算存储装置的方法
文献发布时间:2024-07-23 01:35:12
本申请要求于2023年1月3日在韩国知识产权局提交的第10-2023-0000554号韩国专利申请的优先权以及由此产生的所有权益,所述韩国专利申请的内容通过引用全部包含于此。
技术领域
本公开涉及计算存储装置和用于操作计算存储装置的方法。
背景技术
半导体存储器件包括易失性存储器件和非易失性存储装置。虽然易失性存储器装置具有高读取和写入速度,但是易失性存储器装置在断电时可丢失它们存储的内容。相反,由于非易失性存储器装置即使在断电时也保留它们存储的内容,因此非易失性存储器装置被用于无论电力是否被供应都存储需要(或期望)保持的内容。
例如,易失性存储器装置包括静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)等。非易失性存储器装置即使在断电时也保留它们存储的内容。例如,非易失性存储器装置包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)、闪存、相变RAM(PRAM)、磁性RAM(MRAM)、电阻式RAM(RRAM)、铁电式RAM(FRAM)等。闪存可被分类为NOR闪存和NAND闪存。
发明内容
本公开的示例实施例提供了一种具有提高的操作性能的计算存储装置和用于操作所述装置的方法。
然而,本公开的示例实施例不限于在此阐述的示例实施例。通过参照以下给出的本公开的详细描述,本公开的以上和其他方面对于本公开所属领域的普通技术人员将变得更加清楚。
根据本公开的示例实施例,一种用于操作计算存储装置的方法,所述方法包括:由存储控制器从第一主机装置接收第一计算命名空间设置指令;由存储控制器从第二主机装置接收第二计算命名空间设置指令;由存储控制器从第一主机装置接收第一程序;由存储控制器从第二主机装置接收第二程序;由存储控制器接收融合执行命令,融合执行命令指示使用第一计算命名空间中的第一程序来处理第一计算,并且指示响应于处理第一计算的第一计算结果,使用第二计算命名空间中的第二程序来处理第二计算;由第一加速器处理第一计算;由存储控制器将通过处理第一计算获得的第一计算结果存储在缓冲器存储器中;响应于存储在缓冲器存储器中的数据量超过范围,由存储控制器将存储在缓冲器存储器中的数据提供给与第一加速器不同的第二加速器;以及由第二加速器对从缓冲器存储器提供的数据处理第二计算。
根据本公开的另一示例实施例,提供了一种计算存储装置,所述计算存储装置包括:非易失性存储器,被配置为存储数据;存储控制器,被配置为:控制非易失性存储器;第一加速器,包括在第一计算命名空间中,并被配置为:通过使用从第一主机装置提供的第一程序根据从第一主机装置接收的第一执行命令来对数据处理第一计算;以及第二加速器,包括在第二计算命名空间中,并被配置为:通过使用从第二主机装置提供的第二程序根据从第二主机装置接收的第二执行命令来对数据处理第二计算,其中,存储控制器被配置为:接收融合执行命令,融合执行命令指示使用第一计算命名空间中的第一程序来处理第一计算,并且指示响应于处理第一计算的第一计算结果,使用第二计算命名空间中的第二程序来处理第二计算;控制第一加速器,使得对数据处理第一计算;将通过处理第一计算获得的第一计算结果存储在缓冲器存储器中;响应于存储在缓冲器存储器中的数据量超过范围,将存储在缓冲器存储器中的数据提供给第二加速器;并且控制第二加速器,使得对存储在缓冲器存储器中的数据处理第二计算。
根据本公开的另一示例实施例,提供了一种计算存储装置,所述计算存储装置包括:非易失性存储器,被配置为存储数据;存储控制器,被配置为:控制非易失性存储器;第一加速器,在第一计算命名空间中,并被配置为:通过使用从第一主机装置提供的第一程序根据从第一主机装置接收的第一执行命令来对数据处理第一计算;第二加速器,在第二计算命名空间中,并被配置为:通过使用从第二主机装置提供的第二程序根据从第二主机装置接收的第二执行命令来对数据处理第二计算;以及易失性存储器,被配置为:存储在非易失性存储器中存储的数据的至少一部分,其中,存储控制器被配置为:接收融合执行命令,融合执行命令指示使用第一计算命名空间中的第一程序来处理第一计算,并且指示响应于处理第一计算的第一计算结果,使用第二计算命名空间中的第二程序来处理第二计算;控制第一加速器,使得对存储在易失性存储器中的数据处理第一计算;将通过处理第一计算获得的第一计算结果存储在与易失性存储器不同的缓冲器存储器中;响应于存储在缓冲器存储器中的数据量超过范围,将存储在缓冲器存储器中的数据提供给第二加速器;控制第二加速器,使得对存储在缓冲器存储器中的数据处理第二计算;并且将通过处理第二计算获得的计算结果存储在易失性存储器中。
附图说明
通过参照附图详细描述本公开的示例实施例,本公开的以上和其他方面和特征将变得更加清楚,其中:
图1是根据一些示例实施例的存储器系统的框图;
图2是图1的非易失性存储器的框图;
图3是图1的存储控制器和非易失性存储器的框图;
图4是示出图2的存储器单元阵列的示例电路图;
图5是示出根据一些示例实施例的存储器系统的操作的流程图;
图6至图9是用于解释图5中所示的存储器系统的操作的示图;
图10是示出根据一些示例实施例的存储器系统的操作的流程图;
图11至图14是用于解释图10中所示的存储器系统的操作的示图;
图15是示出根据一些示例实施例的存储器系统的效果的示图;
图16至图19是用于描述根据一些示例实施例的存储器系统的操作的示图;以及
图20是根据一些示例实施例的包括存储装置的数据中心的示图。
具体实施方式
在下文中,将参照附图描述根据本公开的技术精神的示例实施例。
图1是根据一些示例实施例的存储器系统的框图。
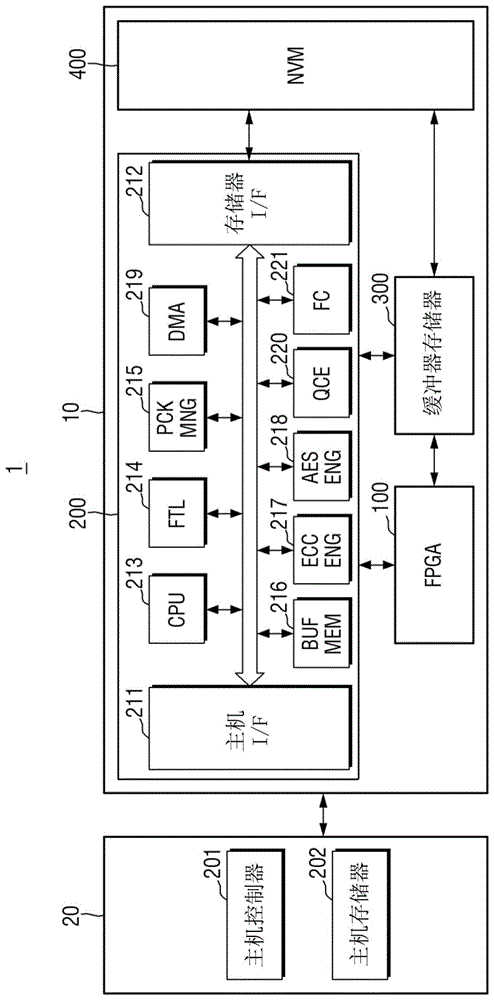
参照图1,存储器系统1可包括主机装置20和存储装置10。
主机装置20可包括主机控制器201和主机存储器202。主机控制器201可控制主机装置20的总体操作。在一些示例实施例中,主机控制器201可包括由多个虚拟机(VM)驱动的多个实体或租户。由不同的虚拟机驱动的实体或租户可独立地控制存储装置10。
主机存储器202可临时地存储从外部发送的数据、将被发送到存储装置10的数据或者从存储装置10发送的数据。在一些示例实施例中,主机装置20可被实现为应用处理器(AP)。然而,示例实施例不限于此。
存储装置10可以是例如计算存储装置。
存储装置10可包括现场可编程门阵列(FPGA)100、存储控制器200、缓冲器存储器300和非易失性存储器400。
存储装置10可包括用于根据来自主机装置20的请求来存储数据的存储介质。作为一个示例,存储装置10可包括固态驱动器(SSD)、嵌入式存储器和可移除的外部存储器中的至少一个。当存储装置10是SSD时,存储装置10可以是符合非易失性存储器快速(NVMe)标准的装置。当存储装置10是嵌入式存储器或外部存储器时,存储装置10可以是符合通用闪存(UFS)标准或嵌入式多媒体卡(eMMC)标准的装置。存储装置10和主机装置20均可生成并发送符合采用的标准协议的包。
当存储装置10的非易失性存储器400包括闪存时,闪存可包括二维(2D)NAND存储器阵列或三维(3D)(或垂直)NAND(VNAND)存储器阵列。作为另一示例,存储装置10可包括各种其他类型的非易失性存储器。例如,磁性RAM(MRAM)、自旋转移力矩MRAM、导电桥接RAM(CBRAM)、铁电式RAM(FeRAM)、相位RAM(PRAM)、电阻式存储器(电阻式RAM)以及各种其它类型的存储器可被应用于存储装置10。
FPGA 100可对存储在缓冲器存储器300中的数据执行各种类型的计算、运算等。在一些示例实施例中,FPGA 100可包括基于从主机装置20提供的执行命令(EX CMD)对存储在缓冲器存储器300中的数据执行各种类型的计算、运算等的多个加速器。
FPGA 100可通过使用映射到硬件逻辑配置的算法,来使用临时存储在缓冲器存储器300中的数据执行计算。在一些示例实施例中,FPGA 100可在没有主机装置20的干预的情况下使用存储在非易失性存储器400中的数据来执行计算。
存储控制器200可包括主机接口(I/F)211、存储器接口(I/F)212和中央处理器(CPU)213。此外,存储控制器200还可包括闪存转换层(FTL)214、包管理器(PCK MNG)215、缓冲器存储器(BUF MEM)216、纠错码(ECC)引擎217、高级加密标准(AES)引擎(AES ENG)218、直接存储器访问(DMA)引擎219、队列控制引擎(QCE)220和流控制器(FC)221。
存储控制器200还可包括加载有闪存转换层(FTL)214的工作存储器,并且针对非易失性存储器(NVM)400的数据写入和数据读取操作可由执行闪存转换层的CPU 213控制。
主机接口211可将包发送到主机装置20和从主机装置20接收包。从主机装置20发送到主机接口211的包可包括将被写入到非易失性存储器400的命令或数据等,并且从主机接口211发送到主机装置20的包可包括对命令的响应、从非易失性存储器400读取的数据等。
存储器接口212可发送将被写入到非易失性存储器400的数据,或者可接收从非易失性存储器400读取的数据。存储器接口212可被实现为符合标准协定(诸如,Toggle或开放NAND闪存接口(ONFI))。
闪存转换层214可执行各种功能(诸如,地址映射、损耗均衡(wear-leveling)和垃圾收集)。换句话说,闪存转换层214可被配置为执行地址映射、损耗均衡和垃圾收集。地址映射操作是将从主机装置20接收的逻辑地址转换为用于将数据实际地存储在非易失性存储器400中的物理地址的操作。损耗均衡是用于通过平均地使用非易失性存储器400中的块来防止或减少特定块的过度劣化的技术。例如,可通过用于平衡物理块的擦除计数的固件技术来实现磨损均衡。垃圾收集是用于通过将块的有效数据复制到新块然后擦除现有块来确保非易失性存储器400中的可用容量的技术。
包管理器215可生成与主机装置20商定的接口的协议对应的包,或者可从自主机装置20接收的包解析各种信息。
缓冲器存储器216可临时地存储将被写入到非易失性存储器400的数据或将从非易失性存储器400读取的数据。缓冲器存储器216可被设置在存储控制器200中,或者可被设置在存储控制器200外部。
ECC引擎217可对从非易失性存储器400读取的数据执行错误检测和校正功能。具体地,ECC引擎217可生成用于将被写入到非易失性存储器400的数据的奇偶校验位,并且如上所述生成的奇偶校验位可与写入的数据一起被存储在非易失性存储器400中。当从非易失性存储器400读取数据时,ECC引擎217可使用与读取的数据一起从非易失性存储器400读取的奇偶校验位来校正读取的数据的错误,并可输出其错误已被校正的读取数据。
AES引擎218可使用对称密钥算法对输入到存储控制器200的数据执行加密操作和解密操作中的至少一个。
DMA引擎219可从缓冲器存储器300读取或获取数据块,使得FPGA 100的加速器可执行计算。尽管在附图中示出DMA引擎219被包括在存储控制器200中,但是示例实施例不限于此,并且DMA引擎219可被实现在FPGA 100内部,或者可被实现在存储控制器200外部。
队列控制引擎220可管理从主机装置20提供的执行命令。队列控制引擎220可根据从包括在存储装置10中的多个加速器之中的主机装置20提供的执行命令来选择加速器以处理计算,并可控制选择的加速器根据执行命令来处理计算。稍后将描述其具体操作。
尽管在附图中示出队列控制引擎220被包括在存储控制器200中,但是示例实施例不限于此,并且队列控制引擎220可被实现在FPGA 100内部,或者可被实现在存储控制器200外部。
流控制器221可在从主机装置20提供的执行命令是融合执行命令(fusedexecution command)时被使用。例如,当从主机装置20提供的执行命令是融合执行命令时,可由流控制器221在最小化或减少对缓冲器存储器300的访问的同时以高速执行根据融合执行命令的多个计算处理。
尽管在附图中示出流控制器221是与DMA引擎219分离的附加组件,但是示例实施例不限于此,并且如果必要,流控制器221可在与DMA引擎219集成时被实现。稍后将对流控制器221进行详细描述。
缓冲器存储器300可缓冲存储在非易失性存储器400中的数据。此外,缓冲器存储器300可缓冲从FPGA 100传送的数据(例如,已经经受加速器计算处理后的数据)。也就是说,当FPGA 100使用存储在非易失性存储器400中的数据时,缓冲器存储器300可临时地存储它,使得FPGA 100可使用存储在非易失性存储器400中的数据。在一些示例实施例中,缓冲器存储器300可包括例如易失性存储器(诸如,动态随机存取存储器(DRAM)),但是示例实施例不限于此。
非易失性存储器400可存储从主机装置20提供的数据和当FPGA 100执行计算时所需(或可选地,使用)的数据。在下文中,将更详细地描述非易失性存储器400的示例实施例。
图2是图1的非易失性存储器的框图。
参照图2,非易失性存储器400可包括存储器单元阵列410、地址解码器(ADDR解码器)420、电压生成器430、读取/写入电路440、控制逻辑电路450等。
存储器单元阵列410可通过字线WL连接到地址解码器420。存储器单元阵列410可通过位线BL连接到读取/写入电路440。存储器单元阵列410可包括多个存储器单元。例如,在行方向上布置的存储器单元可连接到同一字线WL,并且在列方向上布置的存储器单元可连接到同一位线BL。
地址解码器420可通过字线WL连接到存储器单元阵列410。地址解码器420可在控制逻辑电路450的控制下(例如,控制逻辑电路450可接收控制命令CTRL CMD)进行操作。地址解码器420可从存储控制器200接收地址ADDR。地址解码器420可从电压生成器430接收操作(诸如,编程或读取)所需(或可选地,使用)的电压。
地址解码器420可对接收到的地址ADDR之中的行地址进行解码。地址解码器420可使用解码后的行地址来选择字线WL。解码后的列地址DCA可被提供给读取/写入电路440。例如,地址解码器420可包括行解码器、列解码器、地址缓冲器等。
电压生成器430可在控制逻辑电路450的控制下生成访问操作所需(或可选地,使用)的电压。例如,电压生成器430可生成执行编程操作所需(或可选地,使用)的编程电压和编程验证电压。例如,电压生成器430可生成执行读取操作所需(或可选地,使用)的读取电压,并生成执行擦除操作所需(或可选地,使用)的擦除电压和擦除验证电压。此外,电压生成器430可将执行每个操作所需(或可选地,使用)的电压提供给地址解码器420。
读取/写入电路440可通过位线BL连接到存储器单元阵列410。读取/写入电路440可与存储控制器200交换数据DATA。读取/写入电路440可在控制逻辑电路450的控制下进行操作。读取/写入电路440可从地址解码器420接收解码后的列地址DCA。读取/写入电路440可使用解码后的列地址DCA来选择位线BL。
例如,读取/写入电路440可将接收到的数据DATA编程到存储器单元阵列410中。读取/写入电路440可从存储器单元阵列410读取数据,并将读取的数据提供给外部(例如,存储控制器200)。例如,读取/写入电路440可包括组件(诸如,感测放大器、写入驱动器、列选择电路、页缓冲器等)。也就是说,读取/写入电路440可将从存储控制器200接收的数据DATA缓冲在页缓冲器中,并将缓冲后的数据DATA编程到存储器单元阵列410。
控制逻辑电路450可连接到地址解码器420、电压生成器430和读取/写入电路440。控制逻辑电路450可控制非易失性存储器400的操作。控制逻辑电路450可响应于从存储控制器200提供的控制信号CRTL和命令CMD(例如,写入命令和读取命令)而进行操作。
图3是图1的存储控制器和非易失性存储器的框图。
参照图3,存储装置10可包括存储控制器200和非易失性存储器400。存储装置10可支持多条通道CH1至CHm,并且存储控制器200和非易失性存储器400可通过多条通道CH1至CHm连接。例如,存储装置10可被实现为存储装置(诸如,固态驱动器(SSD))。
非易失性存储器400可包括多个非易失性存储器装置NVM11至NVMmn。非易失性存储器装置NVM11至NVMmn中的每个(或可选地,中的至少一个)可通过对应的路径连接到多条通道CH1至CHm中的一条。例如,非易失性存储器装置NVM11至NVM1n可通过路径W11至W1n连接到第一通道CH1,非易失性存储器装置NVM21至NVM2n可通过路径W21至W2n连接到第二通道CH2,非易失性存储器装置NVMm1至NVMmn可通过路径Wm1至Wmn连接到第m通道CHm。在一个示例实施例中,非易失性存储器装置NVM11至NVMmn中的每个(或可选地,中的至少一个)可被实现为能够根据来自存储控制器200的单独的命令进行操作的任意的存储器单元。例如,非易失性存储器装置NVM11至NVMmn中的每个(或可选地,中的至少一个)可被实现为芯片或裸片,但是本公开不限于此。
存储控制器200可通过多条通道CH1至CHm将信号发送到非易失性存储器400和从非易失性存储器400接收信号。例如,存储控制器200可通过通道CH1至CHm将命令CMDa至CMDm、地址ADDRa至ADDRm以及数据DATAa至DATAm传送到非易失性存储器400,或者可从非易失性存储器400接收数据DATAa至DATAm。
存储控制器200可通过通道来选择连接到对应的通道的非易失性存储器装置中的一个,并且可将信号发送到选择的非易失性存储器装置和从选择的非易失性存储器装置接收信号。例如,存储控制器200可在连接到第一通道CH1的非易失性存储器装置NVM11至NVM1n之中选择非易失性存储器装置NVM11。存储控制器200可通过第一通道CH1将命令CMDa、地址ADDRa和数据DATAa发送到选择的非易失性存储器装置NVM11,或者可从选择的非易失性存储器装置NVM11接收数据DATAa。
存储控制器200可通过不同的通道并行地将信号发送到非易失性存储器400和从非易失性存储器400接收信号。例如,存储控制器200可在通过第一通道CH1将命令CMDa发送到非易失性存储器400的同时,通过第二通道CH2将命令CMDb发送到非易失性存储器400。例如,存储控制器200可在通过第一通道CH1从非易失性存储器400接收数据DATAa的同时,通过第二通道CH2从非易失性存储器400接收数据DATAb。
存储控制器200可控制非易失性存储器400的总体操作。存储控制器200可通过将信号发送到通道CH1至CHm来控制连接到通道CH1至CHm的非易失性存储器装置NVM11至NVMmn中的每个(或可选地,中的至少一个)。例如,存储控制器200可通过将命令CMDa和地址ADDRa发送到第一通道CH1来控制非易失性存储器装置NVM11至NVM1n中的选择的一个。
非易失性存储器装置NVM11至NVMmn中的每个(或可选地,中的至少一个)可在存储控制器200的控制下进行操作。例如,非易失性存储器装置NVM11可根据提供给第一通道CH1的命令CMDa、地址ADDRa和数据DATAa来对数据DATAa进行编程。例如,非易失性存储器装置NVM21可根据提供给第二通道CH2的命令CMDb和地址ADDRb来读取数据DATAb,并可将读取的数据DATAb传送到存储控制器200。
尽管图3示出非易失性存储器400通过m条通道与存储控制器200通信并包括与通道对应的n个非易失性存储器装置,但是通道的数量和连接到一条通道的非易失性存储器装置的数量可以以各种方式被改变。
图4是示出图2的存储器单元阵列的示例电路图。
参照图4,多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33可被布置在基底上的第一方向x和第二方向上。多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33可具有沿第三方向z上延伸的形状。多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33可共同地连接到形成在基底上或者形成在基底中的公共源极线CSL。
公共源极线CSL被示出为在第三方向z上连接到多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33的最下端。然而,公共源极线CSL在第三方向z上电连接到多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33的最下端就足够了,并且公共源极线CSL不限于被物理地安置在多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33的下端。此外,多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33在此附图中被示出为以3×3阵列布置,但是布置在存储器单元阵列410中的多个单元串的布置形状和数量不限于此。
单元串NS11、NS12和NS13中的一些可连接到第一地选择线GSL1。单元串NS21、NS22和NS23中的一些可连接到第二地选择线GSL2。单元串NS31、NS32和NS33中的一些可连接到第三地选择线GSL3。
此外,单元串NS11、NS12和NS13中的一些可连接到第一串选择线SSL1。单元串NS21、NS22和NS23中的一些可连接到第二串选择线SSL2。单元串NS31、NS32和NS33中的一些可连接到第三串选择线SSL3。
多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33中的每个(或可选地,中的至少一个)可包括连接到串选择线中的每个(或可选地,中的至少一个)的串选择晶体管SST。此外,多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33中的每个(或可选地,中的至少一个)可包括连接到地选择线中的每条(或可选地,中的至少一个)的地选择晶体管GST。
多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33中的每个(或可选地,中的至少一个)中的地选择晶体管的一端可连接到公共源极线CSL。此外,多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33中的每个(或可选地,中的至少一个)可具有在地选择晶体管与串选择晶体管之间在第三方向z上顺序地堆叠的多个存储器单元。尽管图中未示出,但多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33中的每个(或可选地,中的至少一个)可包括地选择晶体管与串选择晶体管之间的虚设单元。此外,包括在每个串中的串选择晶体管的数量不限于此附图。
例如,单元串NS11可包括设置在第三方向z上的最下端处的地选择晶体管GST11、在第三方向z上顺序地堆叠在地选择晶体管GST11上的多个存储器单元M11_1至M11_8、以及在第三方向z上堆叠在最上的存储器单元M11_8上的串选择晶体管SST11。此外,单元串NS21可包括设置在第三方向z上的最下端处的地选择晶体管GST21、在第三方向z上顺序地堆叠在地选择晶体管GST21上的多个存储器单元M21_1至M21_8、以及在第三方向z上堆叠在最上的存储器单元M21_8上的串选择晶体管SST21。此外,单元串NS31可包括设置在第三方向z上的最下端处的地选择晶体管GST31、在第三方向z上顺序地堆叠在地选择晶体管GST31上的多个存储器单元M31_1至M31_8、以及在第三方向z上堆叠在最上的存储器单元M31_8上的串选择晶体管SST31。其他串的配置也可与其类似。
在第三方向z上距基底或地选择晶体管相同高度处的存储器单元可通过每条字线共同地电连接。例如,形成在与存储器单元M11_1、M21_1和M31_1相同高度处的存储单元可连接到第一字线WL1。此外,形成在与存储器单元M11_2、M21_2和M31_2相同高度处的存储单元可连接到第二字线WL2。在下文中,由于连接到第三字线WL3至第八字线WL8的存储器单元的布置和结构与以上类似或相同,因此其描述将被省略。
多个单元串NS11、NS21、NS31、NS12、NS22、NS32、NS13、NS23和NS33的每个串选择晶体管的一端可连接到位线BL1、BL2或BL3。例如,串选择晶体管SST11、SST21和SST31可连接到沿第二方向y上延伸的位线BL1。连接到位线BL2或BL3的其他串选择晶体管的描述也与以上类似或相同,因此其描述将被省略。
与一条串(或地)选择线和一条字线对应的存储器单元可形成一个页。写入操作和读取操作可基于页来执行。每个页中的存储器单元中的每个(或可选地,中的至少一个)可存储两个或更多个位。写入到每个页的存储器单元的位可形成逻辑页。
存储器单元阵列410可被设置为三维存储器阵列。三维存储器阵列可单片地形成在具有设置在基底(未示出)上的有源区域和在存储器单元的操作中涉及的电路的存储器单元的阵列的一个或多个物理层级上。在存储器单元的操作中涉及的电路可被安置在基底内或被安置在基底上。单片地形成表示三维阵列的每个层级的层可被直接地沉积在三维阵列的下层级层上。
图5是示出根据一些示例实施例的存储器系统的操作的流程图。图6至图9是用于说明图5中所示的存储器系统的操作的示图。
参照图1和图5,主机装置20将指示设置用于处理主机装置20的命令的计算命名空间(CNS)的设置指令发送到存储控制器200(步骤S100)。
然后,已经接收到设置指令的存储控制器200在存储装置10中设置用于处理主机装置20的命令的计算命名空间(CNS)(步骤S110)。
参照图6,在一些示例实施例中,计算命名空间(CNS)可包括命令队列510、队列控制引擎(QCE)520、DMA引擎530、加速器540和缓冲器存储器(例如,DRAM)550。然而,示例实施例不限于此,如果必要,计算命名空间(CNS)的一些示出的组件可被省略,并且未示出的组件可被添加到计算命名空间(CNS)。
例如,在一些示例实施例中,计算命名空间(CNS)可被配置为包括命令队列510、DMA引擎530和加速器540。
命令队列510可存储从主机装置20提供的用于驱动加速器540的执行命令。在一些示例实施例中,执行命令可以是例如符合非易失性存储器快速(NVMe)标准的执行命令。在一些示例实施例中,执行命令可以是符合NVMe技术建议书(TP)4091(NVMe TP 4091计算程序命令集规范)的执行命令,但是示例实施例不限于此。
命令队列510可顺序地存储从主机装置20提供的执行命令,并且可以以例如先进先出(first-in-first-out,FIFO)方式输出存储的执行命令。
在一些示例实施例中,命令队列510可被设置在例如缓冲器存储器216(参见图1)中。在一些示例实施例中,可通过使用SRAM来实现缓冲器存储器216(参见图1)以实现命令队列510,但是示例实施例不限于此。
队列控制引擎520可管理存储在命令队列510中的执行命令。队列控制引擎520可获取存储在命令队列510中的执行命令,并控制加速器540根据获取的执行命令来执行计算。
当确定加速器540处于空闲状态或能够执行计算处理时,队列控制引擎520可控制加速器540根据存储在命令队列510中的执行命令来处理计算。
在一些示例实施例中,队列控制引擎520可将命令队列510管理为循环队列,并且当队列索引增大时识别新的执行命令已经被存储。
在一些示例实施例中,可以以图1的存储控制器200中的队列控制引擎220的形式来实现队列控制引擎520,但是示例实施例不限于此。
DMA引擎530可从缓冲器存储器550读取或获取数据,使得加速器可根据执行命令来处理计算。在一些示例实施例中,可以以图1的存储控制器200中的DMA引擎219的形式来实现DMA引擎530,但是示例实施例不限于此。
加速器540可以以例如FPGA的形式(使用FPGA)来实现,并且可在队列控制引擎520的控制下根据执行命令来处理计算。在一些示例实施例中,图1的FPGA 100可被用于实现加速器540。在一些示例实施例中,多个加速器540可被布置,并且加速器540可被用于设置不同的计算命名空间(CNS)。
缓冲器存储器550可提供加速器540根据执行命令处理计算所需(或可选地,使用)的数据,并可存储加速器540的计算处理结果。在一些示例实施例中,缓冲器存储器550可被实现为例如DRAM。在一些示例实施例中,可使用图1的缓冲器存储器300来实现缓冲器存储器550,但是示例实施例不限于此。
尽管以上已经描述了其中以硬件的形式实现命令队列510、队列控制引擎520、DMA引擎530和加速器540的示例实施例,但是示例实施例不限于此。如果必要,命令队列510、队列控制引擎520、DMA引擎530和加速器540中的至少一个可在被实现为软件时进行操作。
已经接收到设置指令的存储控制器200可响应于设置指令,在存储装置10中设置所需(或可选地,使用)的计算资源作为用于处理主机装置20的命令的计算命名空间(CNS)。计算命名空间(CNS)可以是符合NVMe标准的计算命名空间(CNS),但是示例实施例不限于此。
此外,表示处理主机装置20的命令所需(或可选地,使用)的存储装置10中的计算资源的集合的计算命名空间(CNS)是区别于用于划分和管理非易失性存储器400(参见图1)的区域的NVM命名空间、或者用于划分和管理缓冲器存储器300(参见图1)的区域的存储器命名空间的另外的概念。
参照图1和图5,已经完成计算命名空间(CNS)的设置的存储控制器200向主机装置20响应:计算命名空间(CNS)的设置已经完成(步骤S120)。
接下来,主机装置20指示存储控制器200加载在设置的计算命名空间(CNS)中将被使用的程序(步骤S130)。然后,响应于此,存储控制器200将程序加载到设置的计算命名空间(CNS)中(步骤S140),并且向主机装置20响应:程序的加载已经完成(步骤S150)。
例如,参照图7,主机装置20指示存储控制器200将程序加载在第一计算命名空间CNS1的槽0中(步骤S130)。响应于此,存储控制器200将程序加载在第一计算命名空间CNS1的槽0中(步骤S140),并且向主机装置20响应:程序的加载已经完成(步骤S150)。
使用存储装置10中的计算资源定义的所示的计算命名空间CNS1和CNS2是区别于如上所述的用于划分和管理非易失性存储器NVM的区域的NVM命名空间NVM NS1和NVM NS2、或者用于划分和管理缓冲器存储器的区域的存储器命名空间MNS1和MNS2的概念。
接下来,参照图1和图5,主机装置20指示存储控制器200激活加载的程序(步骤S160)。响应于此,存储控制器200激活加载的程序(步骤S170),并且向主机装置20响应:程序激活已经完成(步骤S180)。
例如,参照图8,主机装置20指示存储控制器200激活加载在第一计算命名空间CNS1的槽0中的程序(步骤S160)。如果程序被加载在第一计算命名空间CNS1的槽0和槽1两者中,则主机装置20可指示存储控制器200激活加载在第一计算命名空间CNS1的槽0和槽1中的任意一个中的程序。
响应于用于激活加载在第一计算命名空间CNS1的槽0中的程序的指令,存储控制器200激活加载在第一计算命名空间CNS1的槽0中的程序(步骤S170),并且向主机装置20响应:激活已经完成(步骤S180)。
接下来,参照图1和图5,主机装置20使用激活后的程序将执行命令发送到存储控制器200(步骤S190)。响应于此,存储控制器200根据接收到的执行命令来处理计算(步骤S200),并且向主机装置20响应:根据执行命令的计算处理已经完成(步骤S210)。
例如,参照图9,从主机装置20接收的执行命令被存储在命令队列510中,并且队列控制引擎520获取存储在命令队列510中的执行命令(步骤S201)。
然后,队列控制引擎520控制DMA引擎530,使得加速器540可根据获取的执行命令来处理计算(步骤S202)。DMA引擎530控制缓冲器存储器(例如,其可与图1的缓冲器存储器300对应,并且在以下描述中被称为“DRAM”)和加速器540(步骤S203),使得存储在DRAM中的输入数据IDATA被提供给加速器540(步骤S204)。
此后,加速器540根据获取的执行命令对输入数据IDATA处理计算,并将作为其结果的处理后数据PDATA存储在DRAM中(步骤S205)。此时,加速器540可使用预先在计算命名空间中激活的程序根据获取的执行命令来处理计算。由加速器540处理的计算可以是例如数据压缩、数据解压缩、数据过滤、数据值比较等,但是示例实施例不限于此。
这里,存储在DRAM中的输入数据IDATA可以是存储在非易失性存储器400(参见图1)中的数据之中的计算处理所需(或可选地,使用)的并且加载在DRAM中的数据。此外,在一些示例实施例中,如果必要,存储在DRAM中的处理后数据PDATA可再次被存储在非易失性存储器400(参见图1)中。
图10是示出根据一些示例实施例的存储器系统的操作的流程图。图11至图14是用于说明图10中所示的存储器系统的操作的示图。
参照图1和图10,在本示例实施例中,主机装置可包括第一虚拟机(VM)21和第二虚拟机22。也就是说,在本示例实施例中,虚拟机21和22中的每个(或可选地,中的至少一个)可被用作主机装置。
参照图1和图10,与第一租户相关联的第一虚拟机21将指示设置用于处理第一虚拟机21的命令的第一计算命名空间CNS1的设置指令发送到存储控制器200(步骤S300)。
参照图1和图11,已经接收到设置指令的存储控制器200在存储装置10中设置用于处理第一虚拟机21的命令的第一计算命名空间CNS1。在一些示例实施例中,第一计算命名空间CNS1可包括命令队列510a、队列控制引擎520a、DMA引擎530a、加速器540a和缓冲器存储器550。
在一些示例实施例中,除了队列控制引擎520a和缓冲器存储器550之外,第一计算命名空间CNS1还可被设置为包括命令队列510a、DMA引擎530a和加速器540a。
此时,命令队列510a存储从第一虚拟机21提供的执行命令,并且第一计算命名空间CNS1的组件被用于根据从第一虚拟机21接收的执行命令来处理计算。
参照图1和图10,已经完成第一计算命名空间CNS1的设置的存储控制器200向第一虚拟机21响应:第一计算命名空间CNS1的设置已经完成。在下文中,为了描述的简洁,对上述响应信号的冗余描述(图5的步骤S120、步骤S150、步骤S180和步骤S210)将被省略。此外,可从以上参照图5的描述中充分地推断的操作的详细说明在图10中被省略。
接下来,与第二租户相关联的第二虚拟机22将指示设置用于处理第二虚拟机22的命令的第二计算命名空间CNS2的设置指令发送到存储控制器200(步骤S310)。
参照图1和图11,已经接收到设置指令的存储控制器200在存储装置10中设置用于处理第二虚拟机22的命令的第二计算命名空间CNS2。在一些示例实施例中,第二计算命名空间CNS2可包括命令队列510b、队列控制引擎520b、DMA引擎530b、加速器540b和缓冲器存储器550。
在一些示例实施例中,除了队列控制引擎520b和缓冲器存储器550之外,第二计算命名空间CNS2可被设置为还包括命令队列510b、DMA引擎530b和加速器540b。
此时,命令队列510b存储从第二虚拟机22提供的执行命令,并且第二计算命名空间CNS2的组件被用于根据从第二虚拟机22接收的执行命令来处理计算。
接下来,参照图1和图10,第一虚拟机21指示存储控制器200加载在第一计算命名空间CNS1中将被使用的第一程序(步骤S320)。然后,第二虚拟机22指示存储控制器200加载在第二计算命名空间CNS2中将被使用的第二程序(步骤S330)。
例如,参照图12,第一虚拟机21可指示存储控制器200将第一程序PRG1加载在第一计算命名空间CNS1的槽0中,并且响应于此,存储控制器200可将第一程序PRG1加载在第一计算命名空间CNS1的槽0中,并且向第一虚拟机21响应:第一程序PRG1的加载已经完成。
此外,第二虚拟机22可指示存储控制器200将第二程序PRG2加载在第二计算命名空间CNS2的槽0中,并且响应于此,存储控制器200可将第二程序PRG2加载在第二计算命名空间CNS2的槽0中,并且向第二虚拟机22响应:第二程序PRG2的加载已经完成。
接下来,参照图1和图10,第一虚拟机21指示存储控制器200激活加载在第一计算命名空间CNS1中的第一程序PRG1(步骤S340)。然后,第二虚拟机22指示存储控制器200激活加载在第二计算命名空间CNS2中的第二程序PRG2(步骤S350)。
此外,例如,第一虚拟机21和第二虚拟机22中的至少一个使用激活后的第一程序和第二程序将融合执行命令发送到存储控制器200(步骤S360)。
例如,参照图13,可通过参照包括在执行命令CMD1、CMD2、CMD3和CMD4中的每个(或可选地,中的至少一个)中的融合位FBIT来识别融合执行命令。例如,执行命令CMD1和执行命令CMD4可以是因为其融合位FBIT具有位值0而单独处理的执行命令,并且执行命令CMD2和执行命令CMD3可以是因为其融合位FBIT具有位值1而彼此相关联地处理的融合执行命令。
在一些示例实施例中,可通过以不同方式参照包括在执行命令CMD1、CMD2、CMD3和CMD4中的每个(或可选地,中的至少一个)中的融合位FBIT来识别融合执行命令。例如,当执行命令的融合位FBIT的位值是0时,对应的执行命令可被识别为单独处理的执行命令,并且当执行命令的融合位FBIT的位值是1时,稍后提供的n(n是自然数)个执行命令可被识别为融合执行命令。
也就是说,通过参照包括在执行命令CMD1、CMD2、CMD3和CMD4中的每个(或可选地,至少一个)中的融合位FBIT来简单地识别融合执行命令,并且其具体的识别方法不限于所示的示例实施例。
包括执行命令CMD2和执行命令CMD3的融合执行命令可以是在根据执行命令CMD2的计算将被处理的情况下指示(或表示)使用第一计算命名空间CNS1中的第一程序PRG1来处理第一计算的执行命令,并且然后在根据执行命令CMD3的计算将被处理的情况下响应于其计算结果(使用第一程序PRG1处理第一计算)指示(或表示)使用第二计算命名空间CNS2中的第二程序PRG2处理第二计算的执行命令。例如,融合执行命令也可以是符合NVMe标准的执行命令。
例如,当执行命令CMD2是与数据解密相关的命令并且执行命令CMD3是与数据过滤相关的命令时,包括执行命令CMD2和执行命令CMD3的融合执行命令可以是指示(或表示)这样的执行命令:在第一计算命名空间CNS1中使用与数据解密相关的第一程序PRG1来执行数据解密,并且然后指示(或表示)在第二计算命名空间CNS2中使用用于根据预定的(或可选地,期望的)标准过滤数据的第二程序PRG2来执行解密数据的过滤。
接下来,参照图1和图10,存储控制器200使用其中第一程序PRG1被激活的第一计算命名空间CNS1和其中第二程序PRG2被激活的第二计算命名空间CNS2,根据接收到的融合执行命令来处理计算(步骤S370)。
例如,参照图14,执行命令CMD2被存储在命令队列510a中,并且执行命令CMD3被存储在命令队列510b中。
队列控制引擎520a控制DMA引擎530a根据存储在命令队列510a中的执行命令CMD2来处理计算。因此,存储在缓冲器存储器550中的输入数据IDATA被发送到加速器540a的输入缓冲器SR1(例如,SRAM1)(步骤S372)。加速器540a根据执行命令CMD2来处理第一计算并将其结果输出到加速器540a的输出缓冲器SR2(例如,SRAM2),并且例如,存储在输出缓冲器SR2中的数据在DMA引擎530a的控制下被发送到流控制器221的缓冲器存储器221a(步骤S373)。
队列控制引擎520b控制DMA引擎530b根据存储在命令队列510b中的执行命令CMD3来处理计算。当存储在流控制器221的缓冲器存储器221a中的数据量(根据执行命令CMD2经受第一计算的数据)超过预定的(或可选地,期望的)范围时,DMA引擎530b将存储在流控制器221的缓冲器存储器221a中的数据发送到加速器540b的输入缓冲器SR3(例如,SRAM3)(步骤S374)。在一些示例实施例中,当流控制器221的缓冲器存储器221a充满数据时,DMA引擎530b可将存储在流控制器221的缓冲器存储器221a中的数据传送到加速器540b的输入缓冲器SR3。此外,在一些示例实施例中,当存储在缓冲器存储器221a中的数据量超过预定的(或可选地,期望的)范围时,流控制器221可将存储在缓冲器存储器221a中的数据传送到加速器540b的输入缓冲器SR3。
加速器540b根据执行命令CMD3处理第二计算并将其结果输出到输出加速器540b的缓冲器SR4(例如,SRAM4),并且例如,存储在输出缓冲器SR4中的数据在DMA引擎530b的控制下以处理后数据PDATA的形式被存储在缓冲器存储器550中(步骤S375)。
例如,当执行命令CMD2是数据解密命令并且执行命令CMD3是数据过滤命令时,存储在缓冲器存储器550中的加密输入数据IDATA(输入数据可以是例如从非易失性存储器400(参见图1)发送的数据)可在由加速器540a解密时被存储在流控制器221的缓冲器存储器221a中,并且解密数据可由加速器540b根据预定的(或可选地,期望的)标准进行过滤,并且解密并过滤后的数据可以以处理后数据PDATA的形式被存储在缓冲器存储器550中。
在一些示例实施例中,缓冲器存储器550可包括DRAM。加速器540a的输入缓冲器SR1和输出缓冲器SR2、加速器540b的输入缓冲器SR3和输出缓冲器SR4、以及流控制器221的缓冲器存储器221a可包括SRAM。然而,本公开的示例实施例不限于此。
图15是示出根据一些示例实施例的存储器系统的效果的示图。
图15是示出在与上述存储器系统不同的存储器系统中根据融合执行命令处理计算的操作的示图。参照图15,在与上述存储器系统不同的存储器系统中,在存储在缓冲器存储器982中的输入数据IDATA经受根据由加速器(ACC#1)980进行的第一计算的处理之后,其结果以中间数据MDATA的形式被存储在缓冲器存储器982中。此外,在存储在缓冲器存储器982中的中间数据MDATA经受根据由加速器(ACC#2)981进行的第二计算的处理之后,其结果以处理后数据PDATA的形式被存储在缓冲器存储器982中。也就是说,如果包括在融合执行命令中的执行命令的数量是m(m是大于或等于2的自然数),则需要(或可选地,使用)对包括DRAM的缓冲器存储器982进行至少2m次访问。
对缓冲器存储器982的过度访问可不利地影响计算存储装置的计算性能,从而劣化计算存储装置的操作性能。另一方面,在根据本示例实施例的计算存储装置中,不需要以中间数据MDATA的形式被存储在缓冲器存储器982中或从缓冲器存储器982读取中间数据MDATA,使得计算存储装置的操作性能可被改善。
图16至图19是用于描述根据一些示例实施例的存储器系统的操作的示图。在以下描述中,在关注差异的同时,对上述示例实施例的冗余描述将被省略。
参照图16,根据本示例实施例的存储器系统2的流控制器222可包括第一缓冲器存储器(B1)222a和第二缓冲器存储器(B2)222b。
将如下描述存储器系统2的操作。
DMA引擎530a控制缓冲器存储器550(步骤S401),并且存储在缓冲器存储器550中的输入数据IDATA被发送到加速器540a的输入缓冲器SR1(步骤S402)。加速器540a根据第一执行命令对存储在输入缓冲器SR1中的数据处理计算,并将其结果输出到输出缓冲器SR2,并且存储在输出缓冲器SR2中的数据在DMA引擎530a的控制下被发送到流控制器222的第一缓冲器存储器222a(步骤S403)。因此,如图17中所示,数据被顺序地存储在第一缓冲器存储器222a中。
当存储在第一缓冲器存储器222a中的数据量超过预定的(或可选地,期望的)范围时(例如,当第一缓冲器存储器222a充满时),DMA引擎530a或流控制器222将存储在第一缓冲器存储器222a中的数据发送到加速器540b的输入缓冲器SR3(步骤S404)。同时,例如,存储在加速器540a的输出缓冲器SR2中的数据在DMA引擎530a的控制下被发送到流控制器222的第二缓冲器存储器222b。也就是说,如图18中所示,可同时地或同期的执行将存储在第一缓冲器存储器222a中的数据发送到加速器540b的输入缓冲器SR3的操作以及将从加速器540a的输出缓冲器SR2发送的数据存储在第二缓冲器存储器222b中的操作。
此后,如果存储在第二缓冲器存储器222b中的数据量超过预定的(或可选地,期望的)范围(例如,如果第二缓冲器存储器222b充满),则DMA引擎530a或流控制器222将存储在第二缓冲器存储器222b中的数据发送到加速器540b的输入缓冲器SR3。同时,例如,存储在加速器540a的输出缓冲器SR2中的数据在DMA引擎530a的控制下被发送到流控制器222的第一缓冲器存储器222a。也就是说,如图19中所示,可同时地或同期地执行将存储在第二缓冲器存储器222b中的数据发送到加速器540b的输入缓冲器SR3的操作以及将从加速器540a的输出缓冲器SR2发送的数据存储在第一缓冲器存储器222a中的操作。
接下来,加速器540b根据第二执行命令对存储在输入缓冲器SR3中的数据处理计算,并将其结果输出到输出缓冲器SR4,并且例如,存储在输出缓冲器SR4中的数据在DMA引擎530b的控制下以处理后数据PDATA的形式被存储在缓冲器存储器550中(步骤S405)。
也就是说,在本示例实施例中,在切换流控制器222的第一缓冲器存储器222a和第二缓冲器存储器222b时传送数据,使得在短时间内以比实际所需(或可选地,使用)的缓冲器存储器的量更少的量执行所需(或可选地,使用)的操作是可行的。
图20是根据一些示例实施例的包括存储装置的数据中心的示图。
参照图20,数据中心3000是收集各种类型的数据并提供服务的设施,并可被称为数据存储中心。数据中心3000可以是用于操作搜索引擎和数据库的系统,或者可以是在政府机构或公司(诸如,银行)中使用的计算系统。数据中心3000可包括应用服务器3100至3100n和存储服务器3200至3200m(例如,n和m中的每个可以是大于1的整数)。根据一些示例实施例,应用服务器3100至3100n的数量和存储服务器3200至3200m的数量可被不同地选择,并且应用服务器3100至3100n的数量和存储服务器3200至3200m的数量可彼此不同。
应用服务器3100或存储服务器3200可包括处理器3110和3210以及存储器3120和3220中的至少一个。当描述作为示例的存储服务器3200时,处理器3210可控制存储服务器3200的总体操作,并且访问存储器3220以执行加载在存储器3220中的指令和/或数据。存储器3220可以是双倍数据速率同步DRAM(DDR SDRAM)、高带宽存储器(HBM)、混合存储器立方体(HMC)、双列直插式存储器模块(DIMM)、傲腾(Optane)DIMM和/或非易失性DIMM(NVDIMM)。根据示例实施例,包括在存储服务器3200中的处理器3210的数量和存储器3220的数量可被不同地选择。在一个示例实施例中,处理器3210和存储器3220可被设置为处理器-存储器对。在一个示例实施例中,处理器3210的数量和存储器3220的数量可以是不同的。处理器3210可包括单核处理器或多核处理器。存储服务器3200的以上描述可被类似地应用于应用服务器3100。根据一个示例实施例,应用服务器3100可不包括存储装置3150。存储服务器3200可包括至少一个存储装置3250。包括在存储服务器3200中的存储装置3250的数量可被不同地选择。
在一些示例实施例中,存储装置3250可包括参照图1至19描述的存储装置10。
应用服务器3100至3100n和存储服务器3200至3200m可通过网络3300彼此通信。网络3300可使用光纤通道(FC)、以太网等来实现。在这种情况下,FC可以是用于相对高速度的数据传输的介质,并且提供高性能/高可用性的光交换机可被使用。存储服务器3200至存储服务器3200m可根据网络3300的访问方法被提供为文件存储设备、块存储设备或对象存储设备。
在一个示例实施例中,网络3300可以是只存储网络(诸如,存储区域网络(SAN))。作为一个示例,SAN可以是使用FC网络并根据FC协议(FCP)来实现的FC-SAN。又例如,SAN可以是使用传输控制协议/互联网协议(TCP/IP)网络并根据互联网小型计算机系统接口(iSCSI)(通过TCP/IP的SCSI或互联网SCSI)协议来实现的IP-SAN。在另一示例实施例中,网络3300可以是通用网络(诸如,TCP/IP网络)。例如,网络3300可根据协议(诸如,通过以太网的FC(FCoE)、网络附加存储(NAS)、通过网络的NVMe(NVMe-of)等)来实现。
在下文中,将聚焦于应用服务器3100和存储服务器3200来给出描述。应用服务器3100的描述也可被应用于另外的应用服务器3100n,存储服务器3200的描述也可被应用于另外的存储服务器3200m。
应用服务器3100可通过网络3300将由用户或客户端请求存储的数据存储到存储服务器3200至3200m中的一个中。此外,应用服务器3100可通过网络3300从存储服务器3200至3200m中的一个获取由用户或客户端请求读取的数据。例如,应用服务器3100可被实现为网络服务器、数据库管理系统(DBMS)等。
应用服务器3100可通过网络3300访问包括在另外的应用服务器3100n中的存储器3120n或存储装置3150n,或者可通过网络3300访问包括在存储服务器3200至3200m中的存储器3220至3220m或存储装置3250至3250m。因此,应用服务器3100可对存储在应用服务器3100至3100n和/或存储服务器3200至3200m中的数据执行各种操作。例如,应用服务器3100可执行用于在应用服务器3100至3100n和/或存储服务器3200至3200m之间移动或复制数据的命令。此时,数据可从存储服务器3200至3200m的存储装置3250至3250m被直接传送到应用服务器3100至3100n的存储器3120至3120n,或通过存储服务器3200至3200m的存储器3220至3220m被传送到应用服务器3100至3100n的存储器3120至3120n。为了安全或隐私,通过网络3300移动的数据可以是加密数据。
参照作为示例的存储服务器3200,接口(I/F)3254可提供处理器3210与控制器(CTRL)3251之间的物理连接和网络接口卡(NIC)3240与控制器3251之间的物理连接。例如,接口3254可以以存储装置3250与专用线缆直接连接的直连附加存储(DAS)方法被实现。此外,例如,接口3254可被实现为各种类型的接口(诸如,高级技术附件(ATA)、串行ATA(SATA)、外部SATA(e-SATA)、小型计算机系统接口(SCSI)、串行附接SCSI(SAS)、外围组件互连(PCI)、PCI快速(PCIe)、NVM快速(NVMe)、IEEE 1394、通用串行总线(USB)、安全数字(SD)卡、多媒体卡(MMC)、嵌入式多媒体卡(eMMC)、通用闪存(UFS)、嵌入式通用闪存(eUFS)和/或紧凑型闪存(CF)卡接口等)。
存储服务器3200还可包括交换机3230和NIC 3240。交换机3230可在处理器3210的控制下选择性地将处理器3210连接到存储装置3250,或者可选择性地将NIC 3240连接到存储装置3250。类似地,应用服务器3100还可包括交换机3130和NIC 3140。
在一个示例实施例中,NIC 3240可包括网络接口卡、网络适配器等。NIC 3240可通过有线接口、无线接口、蓝牙接口、光接口等来连接到网络3300。NIC 3240可包括内部存储器、数字信号处理器(DSP)、主机总线接口等,并且可通过主机总线接口连接到处理器3210和/或交换机3230。主机总线接口可被实现为上述接口3254的示例中的一个。在一个示例实施例中,NIC 3240可与处理器3210、交换机3230和存储装置3250中的至少一个集成。
在存储服务器3200至存储服务器3200m或应用服务器3100至3100n中,处理器可将命令发送到存储装置3150至3150n、存储装置3250至3250m、或者存储器3120至3120n、存储器3220至3220m,以编程或读取数据。在这种情况下,数据可以是已经通过纠错码(ECC)引擎的纠错的数据。数据可以是已经通过数据总线反转(DBI)或数据屏蔽(DM)被处理的数据,并且可包括循环冗余码(CRC)信息。为了安全或隐私,数据可以是加密数据。
存储装置3150至存储装置3150n和存储装置3250至3250m可响应于从处理器接收的读取命令而将控制信号和命令/地址信号发送到NAND闪存装置3252至3252m。因此,当数据从NAND闪存装置3252至3252m被读取时,读取使能(RE)信号可用于被输入为数据输出控制信号,并且可用于将数据输出到数据队列(DQ)总线。数据选通信号(DQS)可使用RE信号来生成。命令和地址信号可根据写入使能(WE)信号的上升沿或下降沿被锁存在页缓冲器中。
控制器3251可总体控制存储装置3250的操作。在一个示例实施例中,控制器3251可包括静态随机存取存储器(SRAM)。控制器3251可响应于写入命令而将数据写入到NAND闪存3252,或者响应于读取命令而从NAND闪存3252读取数据。例如,可从存储服务器3200中的处理器3210、其他存储服务器3200m的处理器3210m或应用服务器3100至3100n中的处理器3110至3110n提供写入命令和/或读取命令。DRAM 3253可临时存储(缓冲)将被写入NAND闪存3252的数据或从NAND闪存3252读取的数据。此外,DRAM 3253可存储元数据。这里,元数据是由控制器3251生成以管理用户数据或NAND闪存装置3252的数据。为了安全或隐私,存储装置3250可包括安全元件(SE)。
以上公开的任意元件和/或功能块可包括处理电路(诸如,包括逻辑电路的硬件;硬件/软件组合(诸如,执行软件的处理器);或其组合)或在处理电路中实现。例如,包管理器215、主机控制器201、控制逻辑电路450、存储控制器200、加速器540、处理器3110、3210和控制器3251可被实现为处理电路。处理电路具体可包括但不限于中央处理器(CPU)、算术逻辑单元(ALU)、数字信号处理器、微计算机、现场可编程门阵列(FPGA)、片上系统(SoC)、可编程逻辑单元、微处理器、专用集成电路(ASIC)等。处理电路可包括诸如晶体管、电阻器、电容器等中的至少一个的电子组件。处理电路可包括诸如逻辑门的电子组件,逻辑门包括与门、或门、与非门、非门等中的至少一个。
(一个或多个)处理器、(一个或多个)控制器和/或处理电路可被配置为通过被专门编程为执行动作或步骤(诸如,利用FPGA或ASIC)来执行那些动作或步骤,或者可被配置为通过执行从存储器接收的指令来执行动作或步骤,或它们的组合。
在总结具体实施方式时,本领域技术人员将理解的是,在基本不脱离本公开的原理的情况下,可对优选的示例实施例进行许多变化和修改。因此,公开的发明的优选示例性实施例仅在一般性和描述性意义上被使用,而不是出于限制的目的。
- 用于调整、制造、以及操作无线电收发信机、移动收发信机、基站收发信机的调整电路和装置、方法、以及计算机程序、和用于计算机程序或指令的存储设备
- 一种浴室加热装置和用于控制浴室加热装置的方法、设备、电子设备及计算机可读存储介质
- 适用于移动终端截图方法、装置、计算装置及存储介质
- 分层存储方法、分层存储装置及计算机可读存储介质
- 计算机资源的费用搜索方法、装置、计算机装置及存储介质
- 存储控制器、计算存储装置以及计算存储装置的操作方法
- 用于基于计算装置模式选择操作系统的混合计算装置、方法以及非暂时性计算机可读存储介质