用于改造大豆脂肪酸组分的基因突变体及其应用
文献发布时间:2023-06-19 10:41:48
技术领域
本发明属于植物基因工程技术领域,具体地,涉及用于改造大豆脂肪酸组分的基因突变体及其应用。
背景技术
大豆(Glycine mas L.Merrill)起源于中国,是世界上重要的油料和经济作物之一,也是人类植物油和植物性蛋白的主要来源。随着生活水平的提高以及饮食结构的改善,人们对优质大豆油的需求日益增长,培育高品质大豆成为大豆育种的重要目标之一。大豆油约占我国植物食用油消费的40%,大豆脂肪酸的组分及其配比决定大豆油脂的品质,其主要由棕榈酸(16:0)、硬脂酸(18:0)、油酸(18:1)、亚油酸(18:2)和亚麻酸(18:3)5种脂肪酸组成,分别约占大豆脂肪酸总量的10%、4%、18%、55%和13%。其中,硬脂酸、棕榈酸为饱和脂肪酸;油酸、亚油酸、亚麻酸为不饱和脂肪酸。饱和脂肪酸不容易被人体消化吸收,易引起肥胖症及心脑血管疾病。亚油酸、亚麻酸是多不饱和脂肪酸,稳定性差,在高温加工时易氧化,使营养价值降低,影响油的品质,在工业上的加氢反应也易产生对人体有害的反式脂肪酸。而油酸作为一种单不饱和脂肪酸,性质稳定,抗氧化作用强,在人体的脂类代谢中能降低有害胆固醇,保持有益胆固醇,从而减缓动脉粥样硬化,有效预防心血管疾病发生的机率。所以,油酸是平衡油脂营养及化学稳定性矛盾的首选脂肪酸。因此,提高油酸的相对含量,增加油酸/亚油酸的比值,已成为大豆品质改良育种的重要目标之一。
在脂肪酸合成途径中,Δ12-脂肪酸脱饱和酶(deltatwelve fatty aciddesaturase 2enzyme,FAD2)是催化油酸转化为亚油酸的关键酶。已有研究表明抑制FAD2基因表达从而降低种子中脂肪酸脱氢酶的活性,便能抑制油酸向亚油酸转化,从而使种子中的油酸增加。目前,拟南芥、棉花、向日葵、大豆等植物中的FAD2基因已经被克隆。大豆中存在两类FAD2基因,即FAD2-1和FAD2-2(FAD2-2A,FAD2-2B,FAD2-2C、FAD2-2D和FAD2-2E),其中FAD2-1又包含FAD2-1A和FAD2-1B,这两个基因在种子中特异性表达,是决定种子油酸含量的两个主要基因。
同时,改良大豆油品质的另一常用手段是通过降低亚麻酸含量来减少多不饱和脂肪酸的比例,而FAD3是催化亚油酸转化为亚麻酸的关键酶。大豆FAD3基因家族由三个成员组成,分别为FAD3A,FAD3B,和FAD3C。由于FAD3A基因在大豆籽粒发育过程中大量表达,因此,它是影响大豆油脂中亚麻酸含量的主要因素。
CRISPR/Cas9系统是近几年开发的一种准确、便捷、高效率的生物基因组编辑方法。通过向导RNA的介导和Cas9蛋白的切割来实现对靶基因的定点编辑。该技术不仅对基因功能的研究提供了新思路,更广泛的应用于生物医药的研发和农作物的遗传改良等领域。目前,CRISPR/Cas9系统已经成功应用在拟南芥、水稻、玉米、小麦、大豆等植物中。CRISPR/Cas9基因编辑技术不仅能够快速、便捷的实现基因的靶向突变,更能高效的聚合作物某些优良农艺性状,为作物育种提供创新高效的新途径。
发明内容
针对上述问题,本发明的目的一在于提供用于改造大豆脂肪酸组分的基因突变体,目的二在于提供所述基因突变体在获得高油酸油料作物方面的应用。
为了实现上述目的,本发明采用的具体方案为:
用于改造大豆脂肪酸组分的基因突变体,所述突变体为单基因突变体或多基因突变体,所述单基因突变体是发生FAD2-1B基因突变;所述多基因突变体是发生FAD2-1B基因和其他基因的联合突变,所述其他基因为FAD2-1A基因和FAD3A基因中的一种或两种;
所述FAD2-1A基因的突变位点是将核苷酸序列如SEQ ID NO:06所示基因的第523-540位的18个碱基替换为28个碱基;所述FAD2-1B基因的突变位点是将核苷酸序列如SEQ IDNO:07所示基因的第265位的A突变为G,同时在第269和270位之间插入一个A碱基;所述FAD3A基因的突变位点是在核苷酸序列如SEQ ID NO:08所示基因的第53位至第57位发生5个碱基的缺失。
具体地,所述FAD2-1A基因的突变位点是将核苷酸序列如SEQ ID NO:06所示基因的第523-524位的CC替换成TA、第526-527位的TT替换成AA、在第529位和第530位之间插入AAAAT、在第531位和第532位之间插入ATA、在第532位和第533位之间插入A、第539-540位的AA替换成TCT。
本发明还提供所述的基因突变体在获得高油酸油料作物方面的应用。
有益效果:
本发明利用CRISPR/Cas9基因编辑系统实现了对GmFAD2-1A,GmFAD2-1B和GmFAD3A基因的定点编辑,通过对油酸含量显著增加且实现三基因纯合突变的植株进行测序和基因比对,获取了GmFAD2-1A,GmFAD2-1B和GmFAD3A基因同时发生突变的突变位点信息,该突变信息指示了CRISPR/Cas9基因编辑系统的定点编辑位点,同时表明该突变条件下获得的功能缺失型突变体能够在脂肪酸合成途径中有效抑制油酸向亚油酸、亚油酸向亚麻酸的转化,使得油酸含量显著增加,为高油酸含量的大豆或其他油料作物的品质育种工作提供了一种全新的途径,具有良好的应用前景。
附图说明
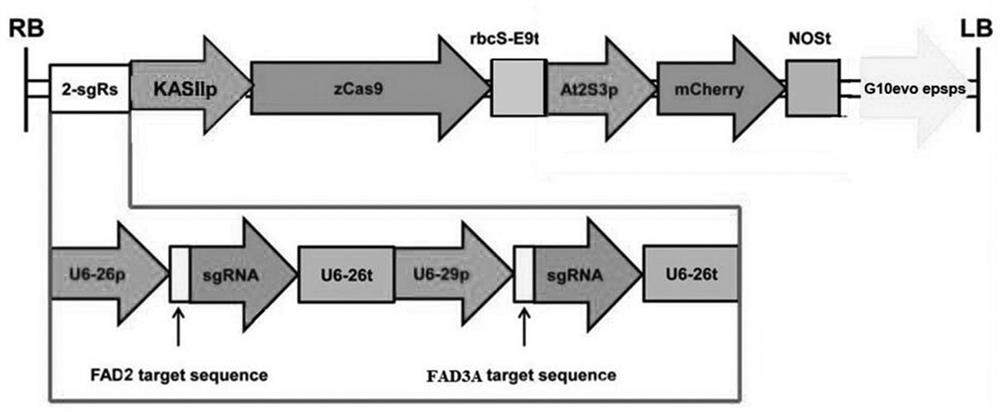
图1是双靶点CRISPR/Cas9双元表达载体KP的构建示意图;其中,RB/LB表示T-DNA左右边界;KASIIp为拟南芥KASII基因的启动子;rbcS-E9t为rbcS E9基因的终止子;2-sgRs为两个sgRNA组成的表达组件;zCas9为玉米密码子优化的Cas9蛋白基因;U6-26p和U6-29p为两个拟南芥U6基因的启动子;U6-26t为U6-26基因的终止子;At2S3p为拟南芥2S3基因的启动子;mCherry为mCherry荧光蛋白基因;NOSt为NOS基因的终止子;G10evo epsps为草甘膦抗性基因;
图2是是双靶点CRISPR/Cas9双元表达载体EP的构建示意图;其中,RB/LB表示T-DNA左右边界;EC1.2p为EC1.2基因的启动子;rbcS-E9t为rbcS E9基因的终止子;2-sgRs为两个sgRNA组成的表达组件;zCas9为玉米密码子优化的Cas9蛋白基因;U6-26p和U6-29p为两个拟南芥U6基因的启动子;U6-26t为U6-26基因的终止子;At2S3p为拟南芥2S3基因的启动子;mCherry为mCherry荧光蛋白基因;NOSt为NOS基因的终止子;G10evo epsps为草甘膦抗性基因;
图3是KP转基因株系中KP-1株系的T2代大豆籽粒和亲本(CK)的脂肪酸组分的比较图;其中,C16:0,C18:0,C18:1,C18:2与C18:3分别代表棕榈酸,硬脂酸,油酸,亚油酸和亚麻酸;
图4是KP转基因株系中KP-2株系的T2代大豆籽粒和亲本(CK)的脂肪酸组分的比较图;其中,C16:0,C18:0,C18:1,C18:2与C18:3分别代表棕榈酸,硬脂酸,油酸,亚油酸和亚麻酸;
图5是KP转基因株系中KP-3株系的T2代大豆籽粒和亲本(CK)的脂肪酸组分的比较图;其中,C16:0,C18:0,C18:1,C18:2与C18:3分别代表棕榈酸,硬脂酸,油酸,亚油酸和亚麻酸;
图6是KP转基因株系中KP-6、KP-8株系的T2代大豆籽粒和亲本(CK)的脂肪酸组分的比较图;其中,C16:0,C18:0,C18:1,C18:2与C18:3分别代表棕榈酸,硬脂酸,油酸,亚油酸和亚麻酸;
图7是5个KP转基因株系(KP-3,KP-8,KP-6,KP-1和KP-2)的T2代单株中FAD3A基因突变位点的聚丙烯酰胺凝胶电泳分析结果;图中数字标注的举例说明:KP-3-42和KP-3-41是KP-3株系的两个T1代植株,而3,9,12,13则是KP-3-42的T2代单株,同理4,8,9,10是KP-3-41的T2代单株,其他株系的数字标注方式类同;图中WT表示亲本(皖豆28),M为DNA Marker(图中显示的两个条带大小分别为250bp和500bp);结果的详细说明参见[0059];
图8是KP-3-42-3后代三个单株中FAD2-1A,FAD2-1B和FAD3A基因突变位点的序列特征图;(A)为FAD2-1A gRNA、CDS(编码区)及三个单株的FAD2-1A基因PCR扩增产物的序列比较分析,最上部代表大豆FAD2-1A的基因组结构图,最右边是三个单株FAD2-1A基因PCR扩增产物的测序图(因三个单株的PCR扩增产物完全相同,仅以其中的一个测序峰图作为代表);(B)和(C)是三个单株的FAD2-1B和FAD3A基因PCR扩增产物的序列比较分析图,其余说明和(A)图类同;
图9是KP-1-25-7后代三个单株中FAD2-1A,FAD2-1B和FAD3A基因突变位点的序列特征图;其余说明和图8类同;
图10是5个KP转基因株系(KP-3,KP-8,KP-6,KP-1和KP-2)的T2代单株中Cas9转基因的PCR扩增产物琼脂糖凝胶电泳结果;图中数字标注的举例说明:KP-3-42和KP-3-41是KP-3株系的两个T1代植株,而3,9,12,13则是KP-3-42的T2代单株,同理4,8,9,10是KP-3-41的T2代单株,其他株系的数字标注方式类同;图中CK1表示阴性对照,即没有Cas9转基因的亲本(皖豆28),CK2表示阳性对照,即含有Cas9转基因的植株,M为DNA Marker(最底部的条带大小为250bp,随后分别为500bp,750bp,1000bp,1500bp等),Cas9转基因的PCR扩增产物为500bp以上的一个条带,小于250bp的条带则是引物二聚体,而非Cas9转基因的PCR扩增产物。
具体实施方式
利用CRISPR/Cas9系统对大豆FAD2-1A,FAD2-1B和FAD3A基因进行定点编辑从而获得高油酸大豆株系,包括以下步骤:
步骤一:构建CRISPR/Cas9基因编辑载体:将原编辑载体中的潮霉素抗性筛选标记替换为草甘膦筛选标记;设计引物ZYP22(SEQ ID NO:01)和ZYP23(SEQ ID NO:02)克隆拟南芥AtKAS II基因的启动子S1(SEQ ID NO:03)以替换原编辑载体中的EC1.2启动子来驱动Cas9基因的表达,将EC1.2启动子驱动的载体命名为EP,而AtKASII启动子驱动的载体命名为KP。
步骤二:gRNA靶点选择:对大豆FAD2-1A和FAD2-1B的基因序列进行比对,在相似的区域进行手动设计靶点,选取靶位点S2(SEQ ID NO:04);对大豆FAD3A、FAD3B和FAD3C的基因序列进行比对,在大豆FAD3A的序列特异性区域进行手动设计靶点,选取靶位点S3(SEQID NO:05)。其中,大豆FAD2-1A,FAD2-1B和FAD3A基因的序列在参考NCBI数据库提供的信息的基础上进行了克隆,其实际的序列分别为S4(SEQ ID NO:06),S5(SEQ ID NO:07)和S6(SEQ ID NO:08)。
步骤三:根据所设计的靶位点合成构建载体相关引物ZYP40(SEQ ID NO:09),ZYP41(SEQ ID NO:10),ZYP42(SEQ ID NO:11)和ZYP43(SEQ ID NO:12),见表1。
步骤四:双靶点CRISPR/Cas9基因编辑载体(如图1和图2)的构建程序具体如下:
(1)gRNA表达盒组装:以高保真酶稀释100倍的pCBC-DT1T2为模板进行四接头引物(ZYP40,ZYP41,ZYP42和ZYP43)PCR扩增并纯化回收PCR产物。
(2)靶点与载体组装:同时用BsaI酶切步骤(1)中的扩增产物与步骤一中构建的载体EP和KP,T4连接酶组装最终载体,获得双靶点CRISPR/Cas9基因编辑载体。
(3)转化大肠杆菌感受态,Kan板筛选,菌落PCR鉴定。
步骤五:步骤四中鉴定为正确的单克隆,抽提质粒,测序正确后转化农杆菌。
步骤六:利用步骤五得到的农杆菌介导大豆转化,转化方法参考美国Iowa StateUniversity,Plant Transformation Facility使用的农杆菌介导的大豆子叶节转化法。
步骤七:对T2代转基因大豆籽粒进行脂肪酸组分分析,通过与野生型植株进行比较,获得油酸含量较高的转基因植株株系。
步骤八:挑选各株系中油酸含量高的大豆籽粒进行种植,并进行分子鉴定和测序分析,筛选获得大豆FAD2-1A,FAD2-1B和FAD3A基因同时发生突变且不含有Cas9基因的非转基因植株。
上述步骤所涉及的引物的序列表如下表1所示。
表1:引物序列表。
实验结果证明,利用拟南芥AtKASII基因的启动子启动Cas9蛋白基因的表达相较于EC1.2基因的启动子可以大大提高CRISPR/Cas9系统在大豆转化体系中的基因编辑效率;通过CRISPR/Cas9基因编辑系统对大豆FAD2-1A,FAD2-1B和FAD3A基因进行编辑后,三基因均发生纯合突变,获得的大豆突变体与亲本相比,油酸含量显著增加。
下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述。
实施例1:转基因大豆植株的获得
根癌农杆菌的电击转化:取构建完成的CRISPR/Cas9基因编辑载体EP和KP各1mL分别加入根癌农杆菌EHA105感受态细胞中混匀,转移至电击杯中。将电击杯放入电击仪的样品槽中,按电击杯电极间距尺寸选择合适的电压进行电击(2.0mm,2500V)。向电击完成的根癌农杆菌中加入1mL不含抗生素的YEP液体培养基,混匀再转入已灭菌的1.5mL离心管中,28℃培养约3h。将菌液4000rpm离心3min,弃上清。混匀残余YEP液体培养基与沉淀菌体,均匀涂布到含有12mg/L利福平和50mg/L卡那霉素的YEP固体培养基平板上,正面向上放于28℃培养箱中1h至菌液完全吸收,然后倒置培养约36-48h至菌落出现。挑取单菌落(经PCR检测,确认为分别含有EP和KP质粒的克隆)摇菌24h,即为根癌农杆菌侵染液。所得菌液保存于以1:1体积比与50%甘油混合保存于-80℃。
外植体的准备与共培养:利用农杆菌介导大豆的转化,转化方法参考美国IowaState University,Plant Transformation Facility使用的农杆菌介导的大豆子叶节转化法(2004;Euphytica 136:167-179)。大豆种子采用氯气干法灭菌16h后播种到萌发培养基上,28℃光照(光周期18h/6h,光照强度140μmol m
筛选与再生:共培养后,将外植体转移到不含筛选剂的芽诱导培养基上。用透气胶带封口并转移到培养室(24℃,光周期18h/6h,光照强度140μmol m
按照此实施例,共获得了4个EP转基因阳性株系和8个KP转基因阳性株系。
实施例2:利用脂肪酸组分分析方法筛选突变的大豆籽粒
参考Zheng等(2003;Plant Cell 15:1872-1887)的方法对获得的T2代大豆种子进行脂肪酸组分的分析,具体的实施步骤如下:
(1)固定大豆籽粒,用干净的刀片在远离种脐的一端沿着平行于种脐的方向切取占大豆总体积1/4的子叶(约40mg),切碎后置于2ml进口离心管中,加入玻璃珠,再加入内标C17:0(溶解于正己烷,现配现用)。其余部分的籽粒种植于预先准备好的基质中(深度约1cm),种脐朝下,以供后续进行分子鉴定;
(2)盖紧盖子,于组织破碎仪中进行破碎处理,离心;
(3)转移上清至安捷伦小瓶中,进行甲酯化处理;
(4)甲酯化结束后加入适宜浓度的NaCl溶液和正己烷即可上样进行分析。
分析结果显示,4个EP转基因株系,其油酸含量均与野生型无显著差别,而8个KP转基因株系中有5个株系(KP-1、KP-2、KP-3、KP-6和KP-8)的油酸含量显著高于野生型,其中,油酸含量最高的株系其平均值达到了84.71%,油酸/亚油酸的比值为76.32(野生型的油酸/亚油酸的比值仅有0.47)(图3-图6)。此结果表明,在大豆转基因体系中用拟南芥KASII基因的启动子来驱动Cas9蛋白基因的表达,可以大大提高CRISPR/Cas9编辑系统的基因编辑效率。
实施例3:转基因阳性植株FAD2-1A,FAD2-1B和FAD3A基因编辑位点的检测,同时对Cas9蛋白基因的有无进行检测
经脂肪酸组分分析后,选取油酸含量大于80%的种子进行种植,选取的同一株系中不同种子间的油酸含量相同或相近。获得KP转基因T2代植株,提取KP转基因T2代植株叶片的基因组DNA。
然后,以基因组DNA为模板,设计引物以使扩增产物为靶序列附近150-250bp的序列,进行常规的PCR反应。设计的引物如下表2所示。
表2:引物序列表。
最后,PCR产物采用聚丙烯酰胺凝胶电泳法检测靶序列的突变与否。具体电泳方法如下:
配制40ml 8%的PAGE胶:10.67ml 30%丙烯酰胺/甲叉双丙烯酰胺溶液(29:1)和4ml 10×TBE,加水定容到40ml,摇匀后加入400μl的10%APS(过硫酸铵)和20μl的TEMED,混匀。沿着玻璃板一端缓慢加入配置好的胶液,使得胶面略高于制胶框,随即插入50孔梳子。待胶凝固后在电泳槽中加入1×TBE直至液面达指定高度。每个胶孔中加入1.5μl PCR产物,用200V电压进行电泳,根据DNA大小选择适宜的电泳时间。电泳停止后将胶用自来水清洗数次并加入0.1%硝酸银溶液,置于摇床10min,用自来水清洗数次,加入显色液继续于摇床上反应10min直至显色。
同时,采用常规PCR检测T2代植株中Cas9蛋白基因的有无。以基因组DNA为模板,引物设计为Cas9蛋白基因特异序列,PCR产物采用1%琼脂糖凝胶电泳检测。
图7中以FAD3A的聚丙烯酰胺凝胶电泳检测为例,只含有与野生型条带迁移率相同的PCR产物的植株被判定为未突变或者只发生了碱基替换的植株(如图7中的KP-8-66-3单株),既含有与野生型条带迁移率相同的条带又含有与野生型条带迁移率不同的条带的植株被判定为杂合突变植株(如图7中的KP-1-26-2单株),而只含有与野生型条带迁移率不同的条带的植株则被判定为纯合突变植株(如图7中KP-3-42-3单株)。以同样的聚丙烯酰胺凝胶电泳检测分析方法对FAD2-1A和FAD2-1B基因的突变位点纯合性进行鉴定。根据聚丙烯酰胺凝胶电泳检测结果及油酸含量的分析结果,选取少数基因型(PCR产物的迁移率)相同的单株,对FAD2-1A,FAD2-1B和FAD3A基因进行进一步PCR扩增与测序分析,其中包括KP-3-42和KP-1-25两个株系的后代(其后代中油酸含量均高达85-57%,而普通大豆中油酸含量在25%左右)。然后将测序结果与野生型FAD2-1A,FAD2-1B和FAD3A基因的核酸序列进行比对,分析结果显示KP-3-42和KP-1-25(分别源于KP-3和KP-1两个株系)的后代中这三个基因均发生了纯合突变,其突变位点的序列信息如图8和图9所示。其中,对于三基因纯合突变植株KP-3-42-3,在GmFAD2-1A,GmFAD2-1B和GmFAD3A基因上均发生了突变,具体如下:
将核苷酸序列如SEQ ID NO:06所示的GmFAD2-1A基因的第523-540位的18个碱基替换为28个碱基;具体地,所述FAD2-1A基因的突变位点是将核苷酸序列如SEQ ID NO:06所示基因的第523-524位的CC替换成TA、第526-527位的TT替换成AA、在第529位和第530位之间插入AAAAT、在第531位和第532位之间插入ATA、在第532位和第533位之间插入A、第539-540位的AA替换成TCT。
将核苷酸序列如SEQ ID NO:07所示的GmFAD2-1B基因的第265位的A突变为G,同时在第269和270位之间插入一个A碱基;
在核苷酸序列如SEQ ID NO:08所示的GmFAD3A基因的第53位至第57位发生5个碱基AGGAA的缺失。
Cas9蛋白基因检测结果显示(图10),所检测的69个T2代植株中有22株已经不带有Cas9基因,而我们筛选得到的两株纯合突变植株也同时不带有Cas9基因,即非转基因植株。
需要说明的是,以上所述的实施方案应理解为说明性的,而非限制本发明的保护范围,本发明的保护范围以权利要求书为准。对于本领域技术人员而言,在不背离本发明实质和范围的前提下,对本发明作出的一些非本质的改进和调整仍属于本发明的保护范围。
SEQUENCE LISTING
<110> 浙江农林大学、杭州瑞丰生物科技有限公司
<120> 用于改造大豆脂肪酸组分的基因突变体及其应用
<130> 1
<160> 12
<170> PatentIn version 3.3
<210> 1
<211> 30
<212> DNA
<213> 人工合成
<400> 1
atcatgccat ggagatttca ggtgaaagtg 30
<210> 2
<211> 30
<212> DNA
<213> 人工合成
<400> 2
atcatgccat ggggcataaa aaggaagagg 30
<210> 3
<211> 1581
<212> DNA
<213> 拟南芥
<400> 3
agatttcagg tgaaagtgaa aactttgctt ctttcaaaag gtgttcatgg atagtggata 60
agcagcaata cctgaacaca cttgtatcac tttgtgtatc tatctaattc ctttgatatt 120
gaagtagtaa tgttgatttt gatgggctca taccgaacga atcagaaatc gacaagtgtg 180
agatagtatg tatgtgtgca taaaataggc tggtttagct gggaatggtg atgcgaaaat 240
ggaatgttag gtatgagaga gcttacccac tttgactctt tccatgcata ttcgcttgct 300
cccctctttc ctgcttcctc tgttttcttt tattccattt ccatcactta aaaacaaaac 360
aaaaaacctg aactcttggg ttggatttca aaccaacata aaccaattct ctaatacaac 420
ttggtttgat acaatattag agctacttga tgtgtgtaat gtttcgatca gtaggaaaaa 480
caaatcacgt gtatcctatc aaacttttga ttatacacaa gtcaaaagag acattcattg 540
tgtgaattta atgaatttga ggggtctatt atatttatta gtcagcttta acgtatcaaa 600
tccatgactt ttatcaatgt tttttcttct tttctttctg gatctacttc ccaataccat 660
caccggaccg gaccacttga tgatcttcct atttatgaac actactacta gtaaactcat 720
gtataaaata cgtactttat acgtgtattt ctgaagatta gtcacttcaa aaaatcatga 780
gagtaataaa tgttaaaaaa aaaaacagtg gcgctccttt gccatatcac tatcccaagt 840
ctgtaacact tcactgccac aaaaacaaaa aacaagtaat ccaaaataaa ataatgattt 900
tccaagtgtc cttccttcga ttaaaccgag gtcaccaaat ctgtgtatgt aacaaaaatt 960
gtagtggaac atattgaatc agcagcgtta ctgtataatt attttttgat tatatcatta 1020
catcaacata aattatgatt tcctatcatt ctgtgaaatt actgttttca attttgtgat 1080
ttgtacttga aaactaaacc taataaaaga aaataagtta ggaatatttt gttttttagt 1140
tttgaaaagt ggggctattt tttgataaaa tatcatcaac tttaacaaaa atagataaaa 1200
aggttatagt atatattttt tagttacaaa attgagattg agataaaaat aaataaaatt 1260
taatggtcat cgataatatt gagatttgaa gtgtcgattg gtatttgtat agtgttgtat 1320
ctctctctct ctctctctgt ctgtttgttt cagagaagga tttttggcgt ctccacgcac 1380
gatttaacgc atcgaagctc tctgcacgct tcctgaaaga gagagagaag agagagatcg 1440
cagatcgatt tctcttaaat ctctcgtgaa tcccatttgc cttctctctg ctagattctc 1500
tcttcttctc ttcacccatt tctcgctttc tcctttgttc tctcatctgg gttcttctca 1560
aagcctcttc ctttttatgc c 1581
<210> 4
<211> 20
<212> DNA
<213> 人工合成
<400> 4
ttcactgttg gccaactcaa 20
<210> 5
<211> 20
<212> DNA
<213> 人工合成
<400> 5
aaaggaagct tttgatccca 20
<210> 6
<211> 1584
<212> DNA
<213> 大豆
<400> 6
atggtaaatt aaattgtgcc tgcacctcgg gatatttcat gtggggttca tcatatttgt 60
tgaggaaaag aaactcccga aattgaatta tgcatttata tatccttttt catttctaga 120
tttcctgaag gcttaggtgt aggcacctag ctagtagcta caatatcagc acttctctct 180
attgataaac aattggctgt aatgccgcag tagaggacga tcacaacatt tcgtgctggt 240
tactttttgt tttatggtca tgatttcact ctctctaatc tctccattca ttttgtagtt 300
gtcattatct ttagattttt cactacctgg tttaaaattg agggattgta gttctgttgg 360
tacatattac acattcagca aaacaactga aactcaactg aacttgttta tactttgaca 420
cagggtctag caaaggaaac aacaatggga ggtagaggtc gtgtggccaa agtggaagtt 480
caagggaaga agcctctctc aagggttcca aacacaaagc caccattcac tgttggccaa 540
ctcaagaaag caattccacc acactgcttt cagcgctccc tcctcacttc attctcctat 600
gttgtttatg acctttcatt tgccttcatt ttctacattg ccaccaccta cttccacctc 660
cttcctcaac ccttttccct cattgcatgg ccaatctatt gggttctcca aggttgcctt 720
ctcactggtg tgtgggtgat tgctcacgag tgtggtcacc atgccttcag caagtaccaa 780
tgggttgatg atgttgtggg tttgaccctt cactcaacac ttttagtccc ttatttctca 840
tggaaaataa gccatcgccg ccatcactcc aacacaggtt cccttgaccg tgatgaagtg 900
tttgtcccaa aaccaaaatc caaagttgca tggttttcca agtacttaaa caaccctcta 960
ggaagggctg tttctcttct cgtcacactc acaatagggt ggcctatgta tttagccttc 1020
aatgtctctg gtagacccta tgatagtttt gcaagccact accaccctta tgctcccata 1080
tattctaacc gtgagaggct tctgatctat gtctctgatg ttgctttgtt ttctgtgact 1140
tactctctct accgtgttgc aaccctgaaa gggttggttt ggctgctatg tgtttatggg 1200
gtgcctttgc tcattgtgaa cggttttctt gtgactatca catatttgca gcacacacac 1260
tttgccttgc ctcattacga ttcatcagaa tgggactggc tgaagggagc tttggcaact 1320
atggacagag attatgggat tctgaacaag gtgtttcatc acataactga tactcatgtg 1380
gctcaccatc tcttctctac aatgccacat taccatgcaa tggaggcaac caatgcaatc 1440
aagccaatat tgggtgagta ctaccaattt gatgacacac cattttacaa ggcactgtgg 1500
agagaagcga gagagtgcct ctatgtggag ccagatgaag gaacatccga gaagggcgtg 1560
tattggtaca ggaacaagta ttga 1584
<210> 7
<211> 1324
<212> DNA
<213> 大豆
<400> 7
atggtcatga tttcactctc tctaatctgt cacttccctc cattcatttt gtacttctca 60
tatttttcac ttcctggttg aaaattgtag ttctcttggt acatactagt attagacatt 120
cagcaacaac aactgaactg aacttcttta tactttgaca cagggtctag caaaggaaac 180
aataatggga ggtggaggcc gtgtggccaa agttgaaatt cagcagaaga agcctctctc 240
aagggttcca aacacaaagc caccgttcac tgttggccaa ctcaagaaag ccattccacc 300
gcactgcttt cagcgttccc tcctcacttc attgtcctat gttgtttatg acctttcatt 360
ggctttcatt ttctacattg ccaccaccta cttccacctc ctccctcacc ccttttccct 420
cattgcatgg ccaatctatt gggttctcca aggttgcatt cttactggcg tgtgggtgat 480
tgctcacgag tgtggtcacc atgccttcag caagtaccca tgggttgatg atgttgtggg 540
tttgaccgtt cactcagcac ttttagtccc ttatttctca tggaaaataa gccatcgccg 600
ccaccactcc aacacgggtt cccttgaccg tgatgaagtg tttgtcccaa aaccaaaatc 660
caaagttgca tggtacacca agtacctgaa caaccctcta ggaagggctg cttctcttct 720
catcacactc acaatagggt ggcctttgta tttagccttc aatgtctctg gcagacccta 780
tgatggtttt gctagccact accaccctta tgctcccata tattcaaatc gtgagaggct 840
tttgatctat gtctctgatg ttgctttgtt ttctgtgact tacttgctct accgtgttgc 900
aactatgaaa gggttggttt ggctgctatg tgtttatggg gtgccattgc tcattgtgaa 960
cggttttctt gtgaccatca catatctgca gcacacacac tatgccttgc ctcactatga 1020
ttcatcagaa tgggattggc tgaggggtgc tttggcaact atggacagag attatgggat 1080
tctgaacaag gtgtttcacc acataactga tactcatgtg gctcaccatc ttttctctac 1140
aatgccacat taccatgcaa cggaggcaac caatgcaatg aagccaatat tgggtgagta 1200
ctaccgattt gatgacacac cattttacaa ggcactgtgg agagaagcaa gagagtgcct 1260
ctatgtggag ccagatgaag gaacatccga gaagggcgtg tattggtaca ggaacaagta 1320
ttga 1324
<210> 8
<211> 3868
<212> DNA
<213> 大豆
<400> 8
atggttaaag acacaaagcc tttagcctat gctgctaata atggatacca aaaggaagct 60
tttgatccca gtgctcctcc accgtttaag attgcagaaa tcagagttgc aataccaaaa 120
cattgctggg tcaagaatcc atggagatcc ctcagttatg ttctcaggga tgtgcttgta 180
attgctgcat tgatggctgc tgcaagtcac ttcaacaact ggcttctctg gctaatctat 240
tggcccattc aaggaacaat gttctgggct ctgtttgttc ttggacatga ttggtaatta 300
attaatttgt tgttactttt ttgttataat atgaatctca cacactgctt tgttatgcct 360
acctcatttc atttggcttt agacaactta aatttgagat ctttattatg ttttttgctt 420
atatggtaaa gtgattcatt cttcacattg aattgaacag tggccatgga agcttttcag 480
acagcccttt tctaaatagc ctggtgggac acatcttgca ttcctcaatt cttgtgccat 540
accatggatg gttagttcat cccggctttt ttgtttgtca ttggaagttc ttttattgat 600
tcaattttta tagcgtgttc ggaaacgcgt ttcagaaaat aatgaaatac atcttgaatc 660
tgaaagttat aacttttagc ttcattgtca ttgaaagttc ttttattaat tatattttta 720
ttgcgtgttt ggaatcccat ttgagaaata agaaatcacg tttaaaatgt gaaagttata 780
actattaact tttgactaaa cttgaaaaaa tcacattttt gatgtggaac caaatctgat 840
ttgagaacca agttgatttt gatggatttt gcaggagaat tagccacaga actcaccatc 900
aaaatcatgg acacattgag aaaggatgaa tcctgggttc cagtatgtga ttaactactt 960
cctctatagt tatttttgat tcaattaaat ttatttattt aataagttca agaaaaaagg 1020
aatctttata cttcatgata aagctgttct tgaacatttt ttttttgtca ttatcttagt 1080
taaccgagaa gatttacaag aatctagaca acatgacaag acttgttaga ttcactgtgc 1140
catttccatt gtttgtgtat ccaatttatt tggtgagtgc tttttttttt ttacttggaa 1200
gactacaaca cattattatt attataatat ggttcaaatc aatgactttt aatttctttg 1260
tgatgtgcac tccattttca gttctcaaga agccccggaa aggaaggttc tcacttcaat 1320
ccctacagca atctgttccc acccagtgag agaaagggaa tagcaatatc aacactgtgt 1380
tgggttacca tgttttctat gcttatctat ctctccttca taactagtcc agttctattg 1440
ctcaagctct atggaattcc atattgggta attaaattac tcttacatta ctttttcctc 1500
ttttttttta tgggtcttaa ctagtatcac aaaaatattg gttaaaaaat tttaaaaaaa 1560
tatttattat gtaaatcata aaagaacata aaaaaaatga tgaataacat aattttcgtc 1620
tcttattaaa aatattttta ttttaaattt cttaatcaat atatttagaa tctggttaac 1680
attttttgaa tatttcaatt ctccaattaa aaatttgaaa tagtcaccat taattatgta 1740
attgtttgaa cacgtgcaga tatttgttat gtggctggac tttgtcacat acttgcatca 1800
ccatggtcat catcagaaac tgccttggta tcgcggcaag gtaacaaaaa taaatagaaa 1860
atagtgagtg aacacttaaa tgttagatac taccttcttc ttcttttttt ttttttgagg 1920
ttaatgctag ataatagcta gaaagagaaa gaaagacaaa tataggtaaa aataaataat 1980
ataacctggg aagaagaaaa cataaaaaaa gaaataatag agtctacgta atgtttggat 2040
ttttgagtga aatggtgttc acctaccatt actcaaagat tctgttgtct acgtagtgtt 2100
tggactttgg agtgaaatgg tgttcaccta ccattactca gattctgttg tgtcccttag 2160
ttactgtctt atattcttag ggtatattct ttattttaca tccttttcac atcttacttg 2220
aaaagatttt taattattca ttgaaatatt aacgtgacag ttaaattaaa ataataaaaa 2280
attcgttaaa acttcaaata aataagagtg aaaggatcat catttttctt ctttctttta 2340
ttgcgttatt aatcatgctt ctcttctttt ttttcttcgc tttccaccca tatcaaattc 2400
atgtgaagta tgagaaaatc acgattcaat ggaaagctac aggaactttt tttgttttgt 2460
ttttataatc ggaattaatt tatactccat tttttcacaa taaatgttac ttagtgcctt 2520
aaagataata tttgaaaaat taaaaaaatt attaatacac tgtactacta tataatattt 2580
gacatatatt taacatgatt ttctattgaa aatttgtatt tattattttt taatcaaaac 2640
ccataaggca ttaatttaca agacccattt ttcatttata gctttacctg tgatcattta 2700
tagctttaag ggacttagat gttacaatct taattacaag taaatattta tgaaaaacat 2760
gtgtcttacc ccttaacctt acctcaacaa agaaagtgtg ataagtggca acacacgtgt 2820
tgcttttttg gcccagcaat aacacgtgtt tttgtggtgt acaaaaatgg acaggaatgg 2880
agttatttaa gaggtggtct cacaactgtg gatcgtgact atggttggat caataacatt 2940
caccatgaca ttggcaccca tgttattcac catcttttcc ctcaaattcc tcattatcac 3000
ctcgttgaag cggtatattt tactattatt actcacctaa aaagaatgca attagtacat 3060
ttgttttatc tcttggaagt tagtcatttt cagttgcatg attgtaatgt tctctctatt 3120
tttaaaccat gttttcacac ctacttcgtt taaaataaga atgtggatac tattctaatt 3180
tctattaact tcttttaaaa aataatgtaa aactagtatt aaaaaagagg aaatagatta 3240
cactctacta atactaatag tataaaaaaa attacattgt tattttatca caaataatta 3300
tatataatta atttttacaa tcattatctt aaaagtcatg tatgatatac agtttttaca 3360
tgctttggta cttattgtaa agttagtgat ttattcatta tttatgttat ataattggca 3420
taaatatcat gtaaccagct cactatacta taatgggaac ttggtggtga aaggggttta 3480
caaccctctt ttctaggtgt aggtgctttg atacttctgg tcccttttta tatcaatata 3540
aattatattt tgctgataaa aaaaacatta ttaatatata atcattaact tctttaaaaa 3600
ccgtacctaa aactttatat tattaaaaag aagattgaga tcagcaaaag aaaaaaaaat 3660
taacagtcat ttgaattcac tgcagacaca agcagcaaaa tcagttcttg gagagtatta 3720
ccgtgagcca gaaagatctg caccattacc atttcatcta ataaagtatt taattcagag 3780
tatgagacaa gaccacttcg taagtgacac tggagatgtg gtttattatc agactgattc 3840
tctgcacctt cactcgcacc gagactga 3868
<210> 9
<211> 39
<212> DNA
<213> 人工合成
<400> 9
atatatggtc tcgattgtga gttggccaac agtgaagtt 39
<210> 10
<211> 41
<212> DNA
<213> 人工合成
<400> 10
tgtgagttgg ccaacagtga agttttagag ctagaaatag c 41
<210> 11
<211> 43
<212> DNA
<213> 人工合成
<400> 11
aacaaaggaa gcttttgatc cccaatctct tagtcgactc tac 43
<210> 12
<211> 37
<212> DNA
<213> 人工合成
<400> 12
attattggtc tcgaaacaaa ggaagctttt gatcccc 37
- 用于改造大豆脂肪酸组分的基因突变体及其应用
- 一种大豆GmEF1B基因突变体植株及其制备方法及应用