一种基于熵的CV-MABAC高血压年龄段预测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及风险评估预测技术领域,具体涉及一种基于熵的CV-MABAC高血压年龄段预测方法。
背景技术
预防和管理高血压可以很好地促进居民的健康,减少中风等相关疾病的发生,从而提高居民的生活质量。高血压与居民的饮食习惯、运动、睡眠、工作和生活环境,以及遗传、血压测量、年龄等有关。为了更好地服务居民,开发社区医生信息管理系统,以便管理高血压等慢性疾病居民的健康。在管理过程中,开发了血压变化预测功能管理模块。为了更好地实现这一功能,开发了基于早期专家经验的分析判断系统。
高血压风险评估方面,其中,基于早期专家经验的分析判断系统是一种不确定系统,在进行评估和决策时,通常会引入交叉熵来衡量和判别信息。熵作为一种强大的工具,被广泛用于复杂和不确定系统的测量,然而尽管这些交叉熵度量在解决各种实际复杂问题方面是有效的,但它们无法度量两个区间值q-rung正射模糊集(IVq-ROFS)之间的差异,影响复杂问题决策的精确性。
发明内容
为解决上述问题,本发明提供一种基于熵的CV-MABAC高血压年龄段预测方法。
为实现上述目的,本发明提供了如下的技术方案。
一种基于熵的CV-MABAC高血压年龄段预测方法,包括以下步骤:
根据居民各项指标的检查结果,通过多个专家评价该居民首次确诊高血压的年龄,获得分年龄段的评价矩阵A
基于满意度交叉熵确定各专家权重,将标准化后的各评价矩阵A
根据区间值q-rung正射模糊变异系数方法,获得每个指标的属性权重,根据属性权重对集合矩阵进行加权,计算获得加权后的平均矩阵
根据加权平均矩阵,获取边界近似面积矩阵G=(g
式中CE(·,·)为交叉熵运算;
计算各年龄段的总边界交叉熵,其中总边界交叉熵的最大的年龄段为该居民首次诊断为高血压时年龄段。
优选地,所述居民各项指标的检查结果包括血压测量值、收缩压和扩张血压;所述多个专家评价该居民首次确诊高血压的年龄的评价依据为血压测量值、遗传、肥胖、生活习惯和工作生活压力五个指标。
优选地,所述获得分年龄段的评价矩阵A
假设有m个备选方案,即首次诊断为高血压的年龄段,X={x
其中,重量信息w和λ是事先未知的,对于每个专家来说,备选方案的评估数据看作是IVqROFN的决策矩阵A
当
决策矩阵A
其中,
优选地,所述基于满意度交叉熵确定各专家权重,将各评价矩阵A
设
专家的平均意见被视为小组的意见,如下式所示:
获得群体意见矩阵的正理想点和负理想点;
获取交叉熵
通过下式分别获得每个专家意见的总体平均交叉熵度和专家的平均意见:
将正理想和负理想交叉熵的综合运算,获得
当0≤φ
导出权重λ
式中,λ
优选地,所述根据区间值q-rung正射模糊变异系数方法,获得每个指标的属性权重,包括以下步骤:
计算加权平均值
当
求均方差σ
获取变异系数cv
获取属性权重w
优选地,所述基于集合矩阵,计算获得加权后的平均矩阵
式中,
优选地,所述根据加权平均矩阵,获取边界近似面积矩阵,如下式所示:
式中,
本发明的有益效果:
本发明提出一种基于熵的CV-MABAC高血压年龄段预测方法,该方法引入了区间值q-rung正射空气模糊交叉熵测度、基于满意度的区间值q-ung正态空气模糊交叉熵值和区间值q-rung正形空气模糊边界交叉熵。IVq ROFN开发的BCE和SCE是新概念和强大的信息处理工具。随后,建立了基于交叉熵测度的改进MABAC方法,该方法基于所提出的交叉熵和SCE获取专家权重和属性权重,对高血压预测管理系统进行研究,其中最优方案与专家的实际预测结果一致,能够有效和准确地进行预测。
附图说明
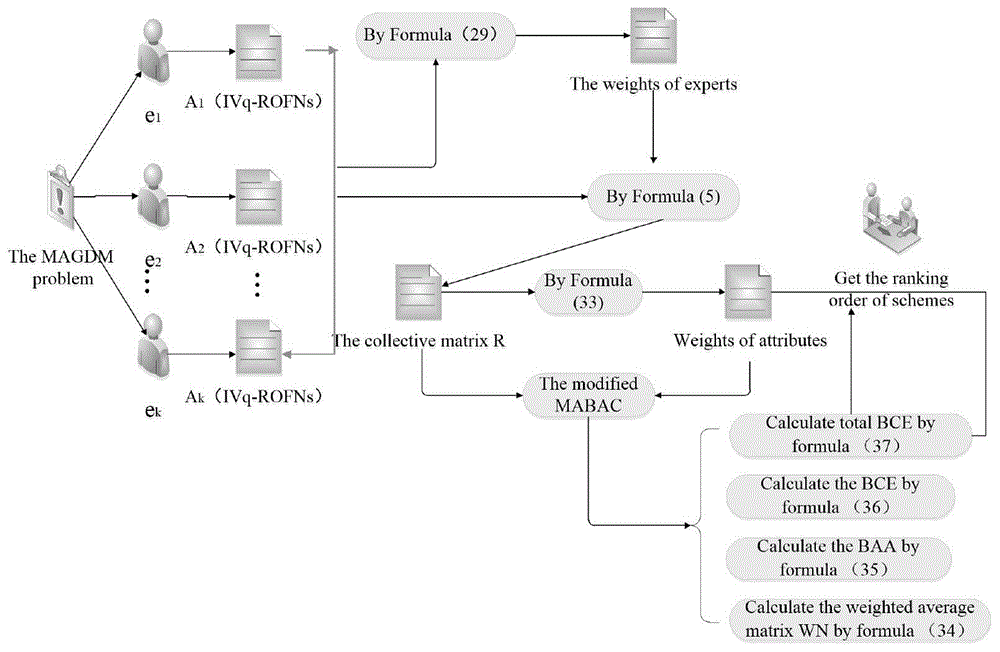
图1是本发明实施例的一种基于熵的CV-MABAC高血压年龄段预测方法的流程图;
图2是本发明实施例的不同交叉熵下100个随机IVq-ROFN的结果;
图3是本发明实施例的100个随机IVq-ROFN的BCE结果;
图4是本发明实施例的使用不同交叉熵度量的100个随机IVq-ROFN的结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
本发明的一种基于熵的CV-MABAC高血压年龄段预测方法,如图1所示,具体步骤如下:
S1:获取居民体检检查结果;根据检查结果,通过多个专家评价该居民首次确诊高血压的年龄,获得分年龄段的评价矩阵A
假设有m个备选方案,即高血压所处年龄段,X={x
其中,重量信息w和λ是事先未知的,对于每个专家来说,备选方案的评估数据看作是IVqROFN的决策矩阵A
当
决策矩阵A
其中,
S2:基于满意度交叉熵确定各专家权重,将各评价矩阵A
设
专家的平均意见被视为小组的意见,如下式所示:
获得群体意见矩阵的正理想点和负理想点;
获取交叉熵
通过下式分别获得每个专家意见的总体平均交叉熵度和专家的平均意见:
将正理想和负理想交叉熵的综合运算,获得
当0≤φ
导出权重λ
式中,λ
S3:根据区间值q-rung正射模糊变异系数方法,获得属性的权重,并基于集合矩阵,计算获得加权后的平均矩阵
根据区间值q-rung正射模糊变异系数方法,获得属性的权重,包括以下步骤:
计算加权平均值
当
求均方差σ
获取变异系数cv
获取属性权重w
优选地,基于集合矩阵,计算获得加权后的平均矩阵
当
S4:获取边界近似面积矩阵G=(g
当
在每个备选方案,即高血压所处年龄段和边界近似面积矩阵之间进行比较,通过下式计算并导出边界交叉熵矩阵P=(p
式中CE(·,·)为交叉熵运算;
计算BCE矩阵的总值P=(p
S5:根据备选方案的大小获得备选方案的排名,该居民首次诊断为高血压时年龄段。
具体的:
(一)广义正交模糊集
定义1:设X为论域,X中的IVq-ROFS可引入为
A={(x,u
满足:
定义2:对于一个IVq-ROFN a=([u
精度函数定义为
给定两个IVq-ROFNs
(1)如果S(a
(2)如果S(a
(3)如果S(a
如果H(a
如果H(a
定义3:设
定义4:设
(二)区间值广义正交模糊熵
本实施例提出了IVq-ROFNs的交叉熵的概念,并分别给出区间值q阶正形模糊PCE和NCE。最后,提出了IVq-ROFNs的BCE和SCE的新概念。
1、区间值q阶正直模糊交叉熵测度
交叉熵是熵的重要组成部分之一,它衡量系统之间的差异程度。
定义5:两个IVq-ROFNs
式中,
定理1.设CE(a
(1)0≤CE(a
(2)CE(a
(3)CE(a
证明:
当
and/>
同时,当
相似,当
根据偏导数,函数
(2)根据IVq-ROFNs的定义,
(3)根据交叉熵的定义,a
2、满意度熵
为便于决策者判断,提出了表示IVq-ROFN与理想点交点的正理想交叉熵(PCE)和负理想交叉熵(NCE),如定义6和定义7所示。根据IVq-ROFNs的定义,在决策过程中([1,1],[0,0])和([0,0],[1,1])分别代表完全赞成和完全反对的意见,两者的熵值均为0。因此,本实施例以这两点为参照点,将其他任意IVq-ROFN与它们之间的交叉熵视为正理想熵。
定义6:对于一个IVq-ROFNs
任意IVq-ROFNs a=([u
同时发现,当IVq-ROFN为([0,0],[0,0]),其犹豫度最大
定义7:对于一个IVq-ROFN
NCE表示每个IVq-ROFN与参考点之间的差异程度NI=([0,0],[0,0]),其差值越小,表示IVq-ROFN的不确定程度越大。
基于已开发的PCE和NCE,并进一步发展了IVq-ROFNs的基于折衷的交叉熵来表示的相对重要性PCE和NCE通过参数θ。
定义8:对于一个IVq-ROFN
CP(a)=θPCE(a)+(1-θ)NCE(a),(0≤θ≤1) (11)
这很容易找到0≤CP(a)≤1,根据决策者的风险偏好,推导出基于妥协的交叉熵。在定义8的基础上,设计了基于满意度的交叉熵(SCE),如定义9所示。
定义9:IVq-ROFN的SCE
显然地,
为了进一步验证所提出的SCE的可行性,本节主要研究在q=3和θ=0.5时随机生成100个IVq-ROFN,对CES、NCE、CP和SCE进行比较分析,如图2所示。
显然,这些IVq-ROFNs的PCE和NCE值分别分布在CP值的上下两侧。但当PCE值小于NCE值时,CP值仍然分布在两者之间,SCE值将显著高于PCE值。由此可以明显发现,PCE和NCE过于极端,可能会扭曲决策结果。相反,CP是折衷的,它有时不能反映IVq-ROFN的偏差。与之相比,SCE更适合于度量IVq-ROFN之间的差异程度,本实施例将进一步使用该方法来获取专家权重。
3、IVq-ROFNs的边界交叉熵测度
PCE和NCE作为强有力的信息手段,能够有效地解决现实生活中的各种决策问题。然而,在建立参考点进行实际比较和分类时,利用PCE和NCE进行聚类比较费力。因此,我们将参考点作为划分其他点的边界,每个点与这个点之间的差值由交叉熵来推导,称为边界交叉熵(boundary cross-entropy,BCE),定义10中表示。假设以某一点为参考点,根据参考点确定边界线,则大于参考点的数分布在边界线以上,小于参考点的数分布在边界线以下。
定义10:设A是n个元素的IVq-ROFN集合,
当CE(a
从图3中很容易看出,100个随机IVq ROFN的BCE值根据参考点分为两部分。BCE值的一部分高于参考点,另一部分低于参考点。也就是说,所开发的IVq ROFN的BCE可以很好地判断一个IVq ROF是在边界线上、边界线上还是边界线之下。显然,开发的BCE可以有效地捕捉各种IVq ROFN之间的差异。
类似地,交叉熵可以以对数或指数的形式处理,如下所示。
/>
与等式(14)和(15)相比,本实施例设计的BCE可以更清楚地区分IVq ROFN之间的特征差异。同样,我们使用Python随机生成100个IVq ROFN并设置参考点
从图4中可以发现,这三个交叉熵度量可以对100个IVq ROFN进行分类和比较,这些点分别位于边界上方、下方和上方。然而,这三种交叉熵测量结果之间的偏差明显不同。由公式(14)计算的BCE值距离边界最远,但边界线以上的BCE之间的差异非常小。而BCE值与由公式(15)获得的边界之间的距离小于由公式(13)获得的距离。显然,公式(13)中引入的BCE不仅能够更好地对IVq ROFN进行分类,而且能够反映相似IVq ROF之间的差异。
本实施例中:
一位50岁的居民,他的父母在65岁之前就患有高血压。体检结果如下:血压测量值:收缩压:138mmHg;扩张血压:88mmHg;这个居民经常抽烟喝酒,而且他超重。平时,他的工作和生活压力不大,也没有相关的疾病。在不改变现有生活习惯的情况下,请了四位专家来预测这位首次被诊断为高血压的居民的年龄。这里将年龄阶段划分为5个范围,x
表1.e
表2.e
表3.e
表4.e
改进后MABAC方法的决策结果
根据开发的方法,可以预测首次诊断为高血压病的居民的年龄阶段。考虑到表1-4中的所有指标都是效益类型,它们不需要标准化。在这种情况下,本实施例认为q和θ的值q=2,θ=0.5,那么本实施例可以得到专家权重λ
λ
接下来,本实施例通过公式(5)对专家A
表5.集体矩阵R
随后,由确定属性权重w
w
计算加权平均矩阵WN,如表6所示。
表6.加权平均矩阵WN
/>
根据加权平均矩阵WN,可由公式(35)计算出各方案的BAA:
g
g
g
g
g
然后可以确定备选方案和BAA的边界交叉熵矩阵P,如表7所示。
表7.备选项的边界交叉熵矩阵P和BAA
最后,计算各备选方案的总边界交叉熵S
S
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。