工业过程的多尺度残差卷积与LSTM融合性能评估方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于自动化过程控制领域,特别涉及到一种工业工程的多尺度残差卷积与长短时记忆网络(MRCNN-LSTM)融合故障诊断方法。
背景技术
现代工业过程系统是目前社会生产中必不可少的一种基础设备,其对社会的发展和进步起着至关重要的作用。为了提高工业设备的生产效率和减少资源浪费,及时发现并诊断出故障的类型就显得非常的必要。因此,一个好的工业过程故障诊断方法对工业生产具有十分重要的意义。
现代故障诊断技术的产生对保障工业过程的生产安全,减少资源浪费发挥了重要的作用,其先后发展出了基于模型的方法,基于知识推理的方法和基于数据驱动的方法。基于模型的方法和基于知识推理的方法由于自身的局限性,对当前具有高维性、非线性、间歇性以及动态性等特点的复杂工业过程数据并不能取得令人满意的结果。基于数据驱动的方法由于局限性较小,只依赖于过往的故障数据,因此得到了较好的发展和应用。
基于数据驱动的方法可以进一步分为基于多元统计的方法、浅层学习方法以及深度学习方法。基于多元统计的方法和浅层学习的方法是工业过程常用的方法之一,但是面对工业数据中的高维性、非线性数据时,并不能取得令人满意的效果。深度学习技术是在浅层学习的基础上发展而来,其摆脱了传统方法需要手工提取特征的繁琐步骤,能够端到端自动的提取原始数据中非线性高维特征,不仅如此,深度学习还解决了浅层学习容易过拟合、陷入局部最优、梯度消散以及泛化能力弱等问题,对非线性、间歇性以及动态性等复杂工业过程也具有较好的诊断精度。
深度学习相较于传统方法具有巨大的优势,其利用多隐层的网络结构直接对输入的数据样本进行有效分析并提取隐藏的数据特征信息,非常适用于大规模复杂的工业过程数据,是目前故障诊断领域研究的热点。但是不可否认的是,每种深度学习模型都有其自身的优缺点,其整体的诊断精度有待进一步提高。目前基于深度学习的故障诊断方法在工业过程的应用主要存在以下问题:
当模型深度达到一定层数后,会发生模型退化问题;
不能有效的提取数据中隐藏的时序性特征;
不能有效的提取数据不同尺寸的特征。
发明内容
为了解决上述问题,需要提供一种能够克服上述问题的工业过程故障诊断方法。
本发明的目的是针对现有工业过程故障诊断方法中存在的问题,提出了一种能够有效提取数据不同尺寸特征和时序性特征,并且能避免模型退化的融合多尺度残差卷积与LSTM网络的工业过程故障诊断方法。
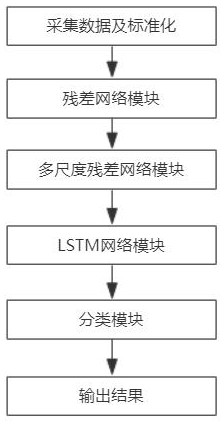
本发明在传统卷神经网络的基础上,分别构建多尺度卷积神经网络和LSTM网络,并将残差学习嵌入到模型中。整个模型由残差模块、多尺度残差模块、LSTM模块以及分类模块所组成。
本发明的具体实施步骤包括:
步骤一、以频率f
数据预处理是指对数据集进行离差标准化处理(Min-maxnormalization),该方法可以对采集的原始信号数据集进行线性变化,使数据样本落在[0,1]区间,相关转换函数如下:
式中min{·}表示原始数据中的最小值,max{·}表示样本数据中的最大值,x
故障样本打标签是指对数据集进行one-hot编码,又称为一位有效编码,其使用N位状态寄存器来对N个故障进行编码,每个故障都有各自独立的寄存器位,且在任意时刻,只有其中一位有效。
步骤二、构建多尺度残差卷积与LSTM网络故障诊断模型;
多尺度残差卷积与LSTM网络模型主要由残差模块、多尺度残差模块、LSTM模块以及分类模块所组成,其中:
残差模块由两个卷积层与BN层叠加组成,卷积层对数据进行卷积运算,采用relu激活函数,padding采用same表示填充输入,使得输出与输入具有相同的长度,并使用L2正则化技术,其中卷积层的卷积运算如下式所示:
x
式中x
BN层对输入数据进行批归一化操作,使得输出数据的均值0,方差为1。相关操作如下:
式中
L2正则化,进一步减少模型的过拟合现象,具体表示如下:
式中N表示样本数,y
残差模块的输出结果输入到最大池化层中,其相关计算如下:
h=max(c(t)) (6)
式中h表示池化层的输出,c(t)表示输入特征中每个神经元的数值集合,t∈[1,2,…,n],表示第t个神经元;
多尺度残差模块分别采用卷积核大小为1×1卷积、1×3卷积、1×5卷积的残差模块并行连接,从而提取输入数据中不同尺寸的特征信息,将提取到的特征数据y
LSTM模块由各为两层的LSTM网络、BN层以及最大池化层叠加组成,采用tanh激活函数,输出结果输入到分类模块中,tanh激活函数具体计算公式如下:
分类模块由多个全连接层与dropout层交替组成,全连接层将卷积网络提取到的局部特征进行展平加权,输入到dropout层;
全连接层具体计算公式如下:
y=W*x+b (8)
式中W表示权重,b表示偏置,x表示输入神经元,y表示加权后的输出。
dropout层以概率p随机丢弃网络中的神经元,加强模型的泛化能力,之后将输出结果输入到Softmax分类层;
Softmax分类层将输入特征进行分类运算,其计算公式如下:
式中
步骤三、利用划分好的训练集训练多尺度残差卷积与LSTM网络模型;
将上述划分好的训练集输入到MRCNN-LSTM模型中进行训练,以故障类型标签作为所述模型的输出,将输出标签与真实标签的交叉熵作为损失函数,利用优化器进行反向传播,更新整个模型的参数,优化损失函数。
步骤四、将分割好的测试集输入到训练好的模型中,进行故障识别,输出诊断结果,Softmax回归分类器的输出可以反映模型预测的故障类型。
与现有的工业过程故障诊断方法相比,本发明具有以下有益效果:
本发明提出了一种融合多尺度卷积与LSTM网络的工业过程故障诊断模型,该模型克服了单一深度学习模型容易造成特征信息丢失的缺点。其中的多尺度残差模块能够自适应的沿着信号的时间轴进行多分支并行提取数据中丰富互补的非线性、高维空间特征,同时能保留数据的时序性特征;LSTM模块能够利用其较好的处理时序性数据的特点,进一步提取输入数据的时序特征;
残差学习的引入使得模型能够更好的学习数据的深层和浅层特征,加快网络的收敛速度,避免模型的性能退化问题;
由于所提模型是基于CNN的,因此该模型继承了CNN具有强大特征提取能力的优点,它能以端到端的形式从未经处理的原始信号中提取数据的高维特征,并识别故障类型。
附图说明
图1为本发明所提故障诊断模型的实施流程图;
图2为本发明所提模型的结构示意图;
图3a和图3b分别为本发明所提模型在训练过程中的损失率和准确率曲线;
图4a和图4b分别为测试集原始数据和本发明所提模型输出后数据的二维散点图;
图5所示为本发明的模型与四种对比模型的测试集准确率曲线。
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
工业焦化炉是一种典型的工业过程系统,其是一种立管式加热炉,它对化工原料的深加工具有不可替代的作用,其燃料一般用高压瓦斯气。工作时气体分别从南北两侧进入焦化炉,原料渣油分别从南北两侧送入焦化炉对流室预加热约330℃,然后一起送入分馏塔底,与焦化炉塔顶来的油气接触并传热传质;在此过程中混合油料中较轻的成份蒸发,上升至精馏段进行分离,而原料中蜡油以上馏分与来自焦炭塔顶油气中被冷凝的成份一起流入塔底。约360℃的分馏塔底油经加热炉辐射进料泵分两路送至加热炉辐射室迅速加热至495℃,之后进入焦炭塔进行裂解反应。
本次实例验证中在焦化炉中预先设计了几种常见的不同类型的故障,具体故障情况与标签对应关系如表1所示
表1:
图1是本发明所提出的融合多尺度残差卷积与LSTM网络的工业过程故障诊断方法的实施流程图,图2是其具体的结构示意图,其具体包括以下步骤:
步骤1、采集工业焦化炉中8个主要的过程变量的运行数据,建立一个含有8个变量,5种类型故障的数据集,在每个故障状况下采集1850个样本数据,另外采集2000个正常状态样本,从中随机选择1850个样本与故障样本一起构成实验数据。对采集的数据集进行数据预处理,在此基础上对故障类型进行编号打标签,设置对应的关系,之后从中随机抽取80%的样本作为训练集,其余20%样本作为测试集。
数据预处理是指对数据集进行离差标准化处理(Min-maxnormalization),该方法可以对采集的原始信号数据集进行线性变化,使数据样本落在[0,1]区间,相关转换函数如下:
式中min{·}表示原始数据中的最大值,max{·}表示样本数据中的最小值,x
故障样本打标签是指对数据集进行one-hot编码,又称为一位有效编码,其使用N位状态寄存器来对N个故障进行编码,每个故障都有各自独立的寄存器位,且在任意时刻,只有其中一位有效。
步骤二、构建多尺度残差卷积与LSTM网络故障诊断模型;
多尺度残差卷积与LSTM网络模型主要由残差模块、多尺度残差模块、LSTM模块以及分类模块所组成,其中:
残差模块由两个卷积层与BN层叠加组成,卷积层对数据进行卷积运算,采用relu激活函数,padding采用same表示填充输入,使得输出与输入具有相同的长度,并使用L2正则化技术,卷积核数量为64,卷积核大小为1x5,其中卷积层的卷积运算如下式所示:
x
式中x
BN层对输入数据进行批归一化操作,使得输出数据的均值0,方差为1,从而提升模型的泛化能力,加快模型的收敛速度和训练速度,在一定程度上能够避免模型在训练过程中出现梯度爆炸或梯度消失问题,使网络模型训练时的稳定性和抗过拟合能力得到加强。其相关计算如下:
式中
L2正则化技术可以进一步减少模型的过拟合现象,其优化问题可以由下式表示:
式中N表示样本数;y
残差模块的输出结果输入到最大池化层中,最大池化层可以防止网络过拟合,提高模型泛化能力,减少数据维数,加快计算速度,其相关计算如下:
h=max(c(t)) (6)
式中h表示池化层的输出,c(t)表示输入特征中每个神经元的数值集合,t∈[1,2,…,n],表示第t个神经元;
多尺度残差模块分别采用卷积核大小为1×1、1×3、1×5,卷积核数量为64的残差模块并行连接,从而提取输入数据中不同尺寸的特征信息,将提取到的特征数据y
LSTM模块由各为两层的LSTM网络、BN层以及最大池化层叠加组成,采用tanh激活函数,单元数分别为64和128,其能够进一步提取数据的时序性特征,减少数据特征的信息丢失,输出结果输入到分类模块中,tanh激活函数具体计算公式如下:
分类模块由两层Dropout层和全连接层交替连接,两层Dropout层的大小按顺序分别为0.3和0.2,两层全连接层的节点数按顺序分别为256和6。全连接层将卷积网络提取到的局部特征进行展平加权,输入到dropout层;
全连接层的计算公式如下所示:
y=W*x+b (8)
式中W表示权重,b表示偏置,x表示输入神经元,y表示加权后的输出;
dropout层以概率p随机丢弃网络中的神经元,加强模型的泛化能力,之后将输出结果输入到Softmax分类层;
Softmax分类层将输入特征进行分类运算,其计算公式如下:
式中
步骤三、利用划分好的训练集训练多尺度残差卷积与LSTM网络模型;
将上述划分好的训练集输入到MRCNN-LSTM模型中进行训练,以故障类型标签作为所述模型的输出,将输出标签与真实标签的交叉熵作为损失函数,利用Adam优化器进行反向传播,更新整个模型的参数,优化损失函数。该优化算法能够沿梯度下降最快的方向快速达到模型的全局最优点,能以较少的网络迭代次数达到最好的训练效果。
步骤四、将分割好的测试集输入到训练好的模型中,进行故障识别,输出诊断结果,Softmax回归分类器的输出可以反映模型预测的故障类型。
为了更好的说明本发明的技术效果,本次实验分别采用CNN、ResCNN、CNN-LSTM以及MRCNN作为对比实验,上述都是目前取得较好效果的网络模型,为了实验结果的可对比性,四种对比模型的参数设置基本与本发明相同。
本次实验中采用Keras库和python3.5实现本发明所提出的融合多尺度残差卷积与LSTM网络模型以及四个对比模型,模型训练时的迭代次数都设置为100,批次大小设置为64,损失函数选择交叉熵损失函数,初始学习率设置为0.001,并且每迭代30次学习率下降十分之一。
本次实验的训练集准确率与损失率以及测试集准确率与损失率如图3a和图3b所示,可以看出训练过程中没有出现过拟合以及欠拟合现象,表明本发明所提模型的结构及参数设置是合理的。图4a和图4b分别为测试集原始数据和本发明所提模型输出后数据的二维散点图,从中可以看出本发明模型能够较好的分类故障类型,只有极少数样本被错分。
表2是五种模型对每种故障类型具体的精确率(P)和召回率(R),以微平均精确率和召回率两个评价指标可以看出,本发明所提出模型的微平均精确率和召回率是五种模型最高的,达到97.80%,显示出本发明所提模型具有突出的诊断精度。具体到每种故障类型可以发现,除了故障2,MRCNN-LSTM对其他五种类型的微平均精率和召回率都得到不同程度的提升。
表2:
本发明与四个对比模型的测试集准确率曲线如图5所示,可以明显的看出本发明模型的准确率曲线相较于对比模型有较为明显的提升,其曲线几乎全程在对比模型曲线的上方,尤其在30次迭代后,模型的准确率开始全面领先四种对比模型,并一直保持到训练结束。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
- 工业过程的多尺度残差卷积与LSTM融合性能评估方法
- 多尺度融合并行稠密残差卷积神经网络图像去噪方法