一种面向热点话题的渐进式观点抽取方法和系统
文献发布时间:2023-06-19 13:26:15
技术领域
本发明属于人工智能领域,具体涉及一种面向热点话题的渐进式观点抽取方法和系统。
背景技术
随着智能终端的普及,社交媒体已经成为人们表达观点和情感的常用平台,而社交文本作为web2.0时代的主要信息表现形式,包含微博推文、贴吧帖子、知乎评论等,包含着网民们对于特定热点话题不同的观点以及情感。在舆情分析、电商销售等领域,抽取用户关于特定话题的观点、视角和情感信息已经成为一项重要但又极具挑战的任务。但现有观点抽取算法主要依靠统计模型或者神经网络,在复杂多变的社交媒体数据情况下,难以高效、准确地抽取观点信息。
当前大多数的观点抽取方法都是基于统计模型相关方法(参考文献:Zhuang L,Jing F,Zhu X Y."Movie review mining and summarization."[C]//Proceedings ofthe 15th ACM international conference on Information and knowledgemanagement.2006:43-50),即将整个观点抽取问题视为序列标注问题,通过复杂人工标注或者神经网络模块抽取相关特征,这些特征包括句法依存关系、词性标注、领域词向量等,再使用隐马尔可夫模型或条件随机场得到目标输出序列。基于统计模型方法依赖于复杂的手工特征,且领域迁移性能较差,在社交文本观点抽取任务场景中难以得到广泛实际应用。
随着神经网络的兴起,其对于复杂特征拟合能力受到人们青睐,相关研究人员开始使用神经网络模型来进行观点抽取。例如,相关工作(参考文献:Ma D,Li S,Wu F,etal."Exploring sequence-to-sequence learning in aspect term extraction."[C]//Proceedings of the 57th Annual Meeting of the Association for ComputationalLinguistics.2019:3538-3547.)提出将观点三元组抽取任务建模为端到端序列输出,使用基于长短时记忆神经单元和注意力机制来捕捉观点元素间复杂关系,但端到端模型结构过于复杂不易于迭代,而关于特定话题的相关讨论观点分布是不均衡的——大部分人都持有相似观点,依赖标注数据的复杂神经模型在不均衡数据集表现不佳。Peng等人(参考文献:Peng H,Xu L,Bing L,et al."Knowing what,how and why:A near complete solutionfor aspect-based sentiment analysis."[C]//Proceedings of the AAAI Conferenceon Artificial Intelligence:volume 34.2020:8600-8607.)则提出将观点三元组抽取任务拆分为两个阶段完成,第一阶段抽取词语和情感信息,第二阶段再进行相关元素组合。阶段式方法虽能有效简化模型结构,但容易引起级联错误,割裂了子任务间相互联系。
发明内容
本发明针对上述问题,提出了一种面向热点话题的渐进式观点抽取方法和系统。该方法和系统利用存储在事件结构图中的历史信息来帮助观点抽取,并通过渐进式框架实现构建和更新事件结构图,历史信息通过双重注意力机制融入神经网络模型中,完成对同一热点话题下新文本进行高质量的观点抽取。
本发明通过以下技术手段实现解决上述技术问题:
一种面向热点话题的渐进式观点抽取方法,包括以下步骤:
S01、提供先验知识:将热点话题下的社交文本分成多个阶段,给出对应话题的视角类别集合和部分观点,对于每个视角类别,添加少量能够反映类别信息的种子词汇。
S02、构造种子事件结构图:基于上述的先验知识构建种子事件结构图,图中包含观点信息结点以及代表观点间关系的边。
S03、观点抽取模型训练和预测:结合上一阶段更新后的事件结构图或种子事件结构图对当前阶段文本流进行训练和预测,训练结束后给出当前阶段文本流的预测结果。
S04、基于人机协同的新观点确认:使用基于词语相似度的词语聚类过滤算法对预测结果进行过滤,过滤掉已经存在于事件结构图中的观点,将新观点提交给专家进行确认。
S05、事件结构图更新:将专家返回的确认结果进行筛选,去掉标记为不合格的观点,将合格观点添加到事件结构图中,再次返回至S03,如此循环进行直至观点抽取模型达到收敛,将收敛后的观点抽取模型的预测结果作为最终的观点抽取结果。
本发明通过事件结构图和渐进式框架,利用历史信息帮助同一热点话题下新文本观点抽取,实现了热点话题下高质量观点抽取。
所述S01中,如果热点话题具有一般性、普适性,那么专家可以直接给出相关先验信息,如果热点话题具有较高的专业性,则需要学习相关专业知识,并邀请领域专家,再给出较为准确的先验知识。具体地,所述S01中,由人类专家根据自身知识对特定话题给出视角类别集合S={ac
所述S02中,首先对观点三元组(视角词、观点词和情感词)内部元素连边,再基于相似度计算判断观点的视角类别,如果观点与该视角类别的相似度计算结果大于给定阈值
具体地,所述S02中,通过以下步骤来构造事件结构图中词汇结点之间的连边:
2.1)构建观点内部连边,将观点三元组中元素——视角词、观点词和情感词at
2.2)计算视角词与视角类别的相似度,对于每个视角词at
其中,categoryScore
2.3)判断视角词视角类别,如果视角词i与视角类别k分数大于阈值σ,那么将类别k结点与视角词i连边。
2.4)将所有视角类别结点与头结点root连边,增强图的连通性。
所述S03中,将输入文本进行枚举得到由连续token构成的区块隐表示Sp
其中W
具体地,所述步骤S03中,通过如下步骤得到文本观点三元组抽取结果:
3.1)得到视角词和观点词,使用预训练模型BERT得到输入序列中每个token的向量表示,使用一一枚举的方法得到由连续token构成区块的隐表示Sp
3.2)基于事件结构图生成证据向量,筛选掉标记为null的区块,视角词区间和观点词区间两两组合构成情感分析元组候选集S
其中,
η为调节注意力的超参数,W
E=∑
3.3)元组合法性判断和情感计算,将候选元组与证据向量进行拼接,通过前馈神经网络进行标签r∈R∪null概率计算,R为预定义情感类别,null表示元组元素之间无任何情感联系。
所述S04中,本发明对S03的输出结果进行基于相似度的词语聚类算法得到候选新观点集合,先对图中已有观点进行k-means聚类,接着计算候选元组词语与聚类结果中每个簇的cosine相似度。判断相似度值是否小于给定的阈值θ,如果都低于阈值则加入新观点候选集合Φ,反之丢弃。将集合Φ交由专家进行判断,判断结果为Y则视为新观点,否则丢弃。确认后的新观点使用S02所述方法得到视角类别加入事件结构图中。
具体地,步骤S04中,通过如下步骤得到更新后的事件结构图:
4.1)筛选新观点,对事件结构图的视角词和观点词使用k-means方法聚类,聚类结果每个簇中词语表示的平均值作为簇的向量表示。计算抽取模型结果与每个簇的cosine相似度,并使用sigmoid函数转化。如果元组与所有簇的相似度值都低于阈值θ,那么加入新观点候选集合Φ。
4.2)确认新观点,将新观点候选集合交Φ于专家进行判断,判断结果为Y则为新观点,否则丢弃。
4.3)更新事件结构图,将新观点添加到事件结构图中,增加相应的结点和连边。并使用步骤S03中所述方法添加视角类别和视角词连边。
所述S05中,使用S04中更新后的事件结构图继续完成下一阶段语料的训练和预测任务,直至S03中的观点抽取模型达到收敛。
一种采用上述方法的面向热点话题的渐进式观点抽取系统,其包括:
种子事件结构图构造模块,用于基于先验知识构建种子事件结构图,图中包含观点信息结点以及代表观点间关系的边;其中先验知识包括将热点话题下的社交文本分成多个阶段,给出对应话题的视角类别集合和部分观点,对于每个视角类别添加少量能够反映类别信息的种子词汇;
观点抽取模型训练和预测模块,用于结合上一阶段更新后的事件结构图或种子事件结构图对当前阶段文本流进行观点抽取模型的训练和预测,训练结束后给出当前阶段文本流的预测结果;
基于人机协同的事件结构图更新模块,用于使用基于词语相似度的词语聚类过滤算法对观点抽取模型的预测结果进行过滤,过滤掉已经存在于事件结构图中的观点,将新观点提交给专家进行确认,将专家返回的确认结果进行筛选,去掉标记为不合格的观点,将合格观点添加到事件结构图中以对事件结构图进行更新,再次返回至观点抽取模型训练和预测模块,如此循环进行直至观点抽取模型达到收敛,将收敛后的观点抽取模型的预测结果作为最终的观点抽取结果。
与现有技术相比,本发明的积极效果为:对于特定热点话题,巧妙地使用历史信息来帮助新文本的观点抽取,无需大量的标注数据和复杂的人工特征,有效地减缓了不均衡数据带给模型的影响。其主要创新点在于以下两个方面:
(1)为了利用同一话题下历史评论信息,进而更加准确地挖掘观点信息,创新性地提出了事件结构图的概念。在抽取模块中,使用双重注意力机制从事件结构图中提取证据向量帮助模型进行观点抽取训练和预测。
(2)受到人类认识事件过程的启发,提出了基于事件结构图的渐进式框架。首先由专家提供的先验知识构造种子事件结构图,接着抽取模块使用前一阶段的事件结构图对当前文本流进行训练和预测,再基于人机协同的事件结构图更新模块使用预测结果更新事件结构图,如此训练往复直至抽取模型收敛。
附图说明
图1为本发明提出的事件结构图示例;
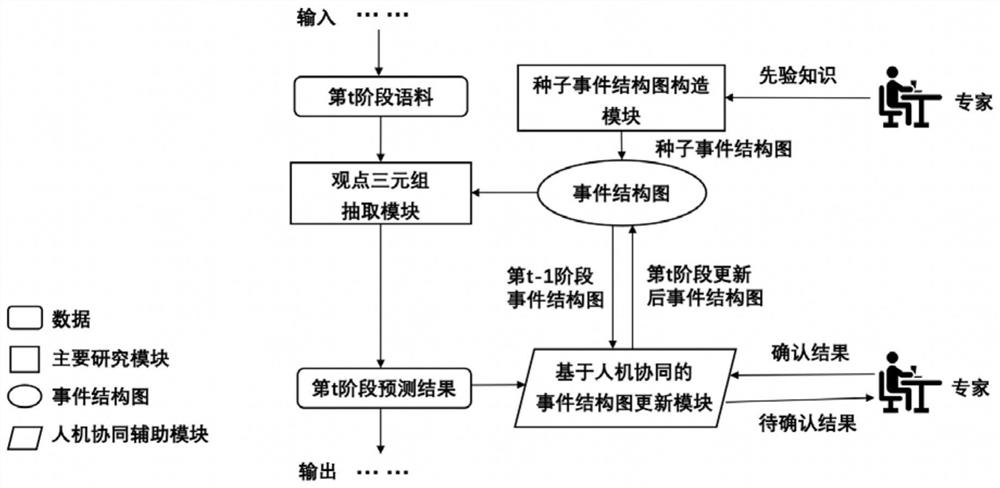
图2为本发明提出的基于事件结构图的渐进式框架示意图;
图3为步骤S03中的观点三元组抽取模型结构示意图;
图4为本发明的渐进式训练和普通训练效果对比图。
具体实施方式
为了使本技术领域的人员更好地理解本发明,以下结合附图和具体实例进一步详细描述本发明,但不构成对本发明的限制。
图2为本发明实施例的基于事件结构图的渐进式框架示意图。参照图2内容,本实施例具体包括以下步骤:
S01、提供先验知识。将热点话题下的社交文本分成多个阶段,给出每个阶段对应话题的视角类别集合和部分观点,对于每个视角类别,添加少量能够反映类别信息的种子词汇。以餐厅评论为主题的相关信息为例,可设置如下先验知识:
视角类别1:服务、服务员、服务生、被服务、小费、派送
视角类别2:食物、葡萄酒、菜单、寿司、晚餐、盘子
在关于餐厅评论的文本中,给出了两个视角类别——服务和食物作为例子,每个视角类别下给出相关种子词作为类别的描述。更进一步,使用少量标注数据来构造种子事件结构图。例如(派送,方便地,正向)、(服务员,慢吞吞地,负向)、(食物,还行,中立)、(蛋糕,美味,正向)、(烘焙,难忘地,正向)等。
S02、构造种子事件结构图。基于上述的先验知识构建种子事件结构图,图中包含观点信息结点以及代表观点间关系的边。
图1为本发明提出的事件结构图示例。图1中,与头结点连接的是视角类别结点,与视角类别节点连接的是视角词结点,与视角词节点连接的是观点词结点,与观点词节点连接的是情感词结点。视角词、观点词和情感词构成观点三元组。
根据视角类别判别方法,S01中观点可以得到如表1所示结果.
表1
设定阈值σ为0.6,那么可以得到观点词对应的视角类别分别为服务、服务、食物、食物、食物,将对应的视角类别结点与视角词结点连边,并将所有的视角类别结点与头结点连边。
S03、观点抽取模型训练与预测。对于当前文本流假定有两条数据,分别为"蛋糕很美味并且很甜。"和"服务员既吵又粗心。"。其标注的标签分别为(蛋糕,很美味,正向)、(蛋糕,很甜,正向)、(服务员,吵,负向)、(服务员,粗心,负向)。
模型训练和预测的过程如图3所示,包括以下步骤:
1)基于区块表示的词汇抽取。
先得到每个token的隐表示,这里可以使用预训练模型或者长短时记忆网络。基于token表示,枚举当前句子所有可能区块表示,此处区块是由单个或者连续几个token构成的区间,本发明枚举时添加最长长度限制l
2)基于事件结构图的证据向量生成。
对1)中得到的词汇抽取结果进行区块对组合,组合时对同一数据中的视角词集合和观点词集合两两配对,同时配对时限制区块边界不重叠,将两词中间的文本作为上下文特征拼接到表示中,如下面公式所示:
其中f(at
E=∑
其中,为了更好的丰富结点信息,本发明在事件结构图上使用图卷积神经网络(Graph Convolutional Network,GCN),并允许图中自环的存在。
3)基于证据向量的情感分析。
每个候选元组得到对应的证据向量后,通过拼接作为整个元组的最终向量表示,利用前馈神经网络计算元组的合法性标签,如下公式所示:
J=loss
4)本阶段数据经过多次迭代后完成训练,再对训练数据进行预测,得到预测结果:(蛋糕,很美味,正向),(蛋糕,很甜,正向),(服务员,吵,正向),(服务员,粗心,负向)。
S04、基于人机协同的新观点确认。对S03阶段产生输出结果进行基于相似度的聚类方法进行过滤,对事件结构图中已有观点进行k-means聚类,得到四个观点簇——前三条观点构成三个簇,后两条观点构成一个簇,以(蛋糕,很美味)为例,其与三个簇的相似度分数分别为0.12,0.15,0.56,0.82,设定阈值θ为0.6,那么将其归于最后一个簇中。经过上述过程,保留下(服务员,吵,正向),(服务员,粗心,负向)作为新观点侯选集交于专家判别。专家判别(服务员,粗心,负向)判别结果为Y,而(服务员,吵,正向)为错误观点。
S05、事件结构图更新。将(服务员,粗心,负向)作为新观点更新到图中,首先使用S02所述的视角类别分类方法,得到其对应的视角类别为服务,增加粗心结点和相应连边。将更新后的事件结构图替换上一阶段的旧图,再次返回步骤S03,以此帮助下一阶段的观点抽取,如此循环进行直至抽取模型收敛。
为了验证渐进式框架和抽取模型的有效性,本发明分别在四个公开数据集上进行了相关实验。四个公开数据集是Res14、Res15、Res16和Lap14,其分别来自于国际语义评测大会SemEval 2014、2015和2016,Res和Lap分别代表数据集来自于餐馆和笔记本电脑销售领域。衡量指标本文使用准确率(precision)、召回率(recall)和F1值。
本发明首先与去掉渐进式更新模块的方法进行对比,如图4所示。结果显示随着更多与话题相关的文本被分析和加入事件结构图,模型性能获得持续提升,并在事件结构图规模到达一定程度时趋于稳定。
此外,本发明寻找了一些近期具有代表性的相关性工作作为基准模型,分别是阶段式观点抽取方法Kwhw(参考文献:Peng H,Xu L,Bing L,et al.Knowing what,how andwhy:A near complete solution for aspect-based sentiment analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence:volume 34.2020:8600-8607.),整体式观点抽取方法JET(参考文献:Xu L,Li H,Lu W,et al.Position-aware tagging for aspect sentiment triplet extraction[J].arXiv preprintarXiv:2010.02609,2020.)。详细数据见表2,由表2可见,相较于基准模型,本发明中提到的模型几乎在所有数据集上取得最佳效果。
表2.本发明与基准模型在四个公开数据集上结果(%),其中Ours
基于同一发明构思,本发明的另一实施例提供一种采用上述方法的面向热点话题的渐进式观点抽取系统,其包括:
种子事件结构图构造模块,用于基于先验知识构建种子事件结构图,图中包含观点信息结点以及代表观点间关系的边;其中先验知识包括将热点话题下的社交文本分成多个阶段,给出对应话题的视角类别集合和部分观点,对于每个视角类别添加少量能够反映类别信息的种子词汇;观点抽取模型训练和预测模块,用于结合上一阶段更新后的事件结构图或种子事件结构图对当前阶段文本流进行观点抽取模型的训练和预测,训练结束后给出当前阶段文本流的预测结果;基于人机协同的事件结构图更新模块,用于使用基于词语相似度的词语聚类过滤算法对观点抽取模型的预测结果进行过滤,过滤掉已经存在于事件结构图中的观点,将新观点提交给专家进行确认,将专家返回的确认结果进行筛选,去掉标记为不合格的观点,将合格观点添加到事件结构图中以对事件结构图进行更新,再次返回至观点抽取模型训练和预测模块,如此循环进行直至观点抽取模型达到收敛,将收敛后的观点抽取模型的预测结果作为最终的观点抽取结果。
其中各模块的具体实施过程参见前文对本发明方法的描述。
基于同一发明构思,本发明的另一实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
基于同一发明构思,本发明的另一实施例提供一种计算机可读存储介质(如ROM/RAM、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
上述实施例仅为例示性说明本发明的原理及其功效,而非用于限制本发明的范围。任何熟于此技术的本领域技术人员均可在不违背本发明的技术原理及精神下,对实施例作修改与变化。本发明的保护范围应以权力要求书所述为准。
- 一种面向热点话题的渐进式观点抽取方法和系统
- 一种中文的观点、评价信息的属性-观点对抽取方法