基于可重构密码算法的共享平衡算子循环阵列映射方法
文献发布时间:2023-06-19 19:20:08
技术领域
本发明涉及基于可重构密码算法的共享平衡算子循环阵列映射方法,属于信息安全技术领域。
背景技术
随着信息技术的发展及创新,信息爆炸时代应用对数据的处理能力需求不断提升,而传统的计算方式主要有两种:一种是专用集成电路(ApplicationSpecificIntegratedCircuit,ASIC),因其专用性及生产特性,导致其一旦投入生产则硬件电路无法改变,随着硅制造工艺复杂度的不断提升,一次性投入代价变得极为昂贵,因此,当ASIC产量达不到一定规模时,全定制的ASIC加速单元只能被少数拥有大量应用场合的计算逻辑采用;另一种是通用处理器(GeneralPurposeProcessor,GPP),通过指令集方式执行特定的计算任务,通过修改指令集序列完成不同功能计算任务,而硬件电路无需进行修改,因此GPP具有良好的灵活性。但是,GPP为了完成一个计算任务,需从存储器中读取指令和数据,并进行译码和执行,指令每次执行都需要很大的性能开销,所以GPP的性能一般远远落后于ASIC。
可重构计算本质上可以看作是“在GPP高灵活性和ASIC高性能之间的折衷,时间计算和空间计算的一种结合”。同时,可重构计算也是灵活性和面积/功耗之间的折衷,有着比ASIC更好的灵活性。可重构体系结构是一类可编程的逻辑器件,其中处理单元是类似于ALU的大的逻辑阵列,互连结构是基于总线的。这与现场可编程阵列FPGA有着鲜明的对比,可重构处理器具有灵活性和可编程性,同时其面积更小,所需的配置位也更少。对于一些需要可编程性和灵活性都有一定要求的场合而言可重构体系架构是最合适的选择,许多商业和学术界已经提出一些配套的编译器来应用可重构系统。
密码算法的计算特点将直接影响目标可重构处理器的结构设计,密码算法大致分为分组密码算法、流密码算法和摘要算法等类别,摘要算法的密文长度固定且不可逆,主要应用在一致性验证、数字签名以及安全认证等方面,分组密码算法和流密码算法都是可逆的密码算法,可以用于所有的加解密场景,其中分组密码算法是人们使用最广泛的密码算法类型。密码算法会被用来对大量数据进行相同形式的加密或解密,因此和普通的程序片段不一样的是,密码算法在计算阵列上的一次映射通常会被多组数据使用。在分组密码算法的多种加密模式中,ECB模式是最常使用的模式之一,在这种模式下,后一组数据的加密对前一组数据的加密结果没有依赖,因此多组数据可以进行流水计算,由此可见流水计算的性能对密码算法的性能有着巨大的影响,因此目标阵列结构中必须支持流水计算的功能。
相比而言,自动映射具有速度快、效果好的特点,避免了手工映射的缺点,因此成为可重构系统中不可或缺的一部分,并且传统的成熟的编译技术不能直接用在可重构映射问题上,使得自动映射技术成为目前可重构领域中的研究热点。
目前,面向专用领域的可重构处理器结构的研究是一个热点方向,而密码算法广泛的应用场景,使得面向密码算法的可重构处理器成为其中的一个典型代表。普通的计算为了实现一般的功能,其计算形式往往简单明了,而密码算法作为安全领域的算法,为了提高密文的安全程度,必须尽量将密文和明文解耦,因此通常都会进行大量且错综复杂的数据计算,可见相比普通计算来说,对密码算法进行手动映射在对映射人员的要求、映射时间和映射效果等方面的缺点都有过之而无不及。不仅对映射人员要求高,时间周期长,循环通信差,而且映射效果不好,映射流水性能较差。目前阶段,针对密码算法可重构技术的研究更多地偏向于其阵列结构的研究,其他的也有针对具体密码算法的手动映射方案的研究,但是对于密码算法来说对循环体内以及循环体外的研究是最重要的一部分,因此面向密码算法的可重构处理器循环计算算子映射技术的研究还十分迫切,其重要性不言而喻。基于以上背景,面向信息安全的可重构密码芯片的编译器后端的映射设计已经成为研究关注的一个热点问题。但目前尚无令人满意的解决方案。
发明内容
针对现有映射技术不够成熟的情况下,对映射人员要求高,时间周期长,循环通信差、映射效果不好以及映射流水性能差等问题,本发明针对循环体内以及多轮循环体间的数据通信进行分析设计,提出一种基于可重构密码算法的共享平衡算子循环阵列映射方法。
为了达到上述目的,本发明提供如下技术方案:
一种基于可重构密码算法的共享平衡算子循环阵列映射方法,包括如下步骤:
步骤一:计算当前运算所有路径的路径长度,根据当前路径与最大路径的路径长度差,获得每条路径的MII;
步骤二:判断当前处理的算子是否是多扇出算子,如果是,则进入步骤三;如果不是,则采用平衡节点算子降低该算子引导的路径的MII;
步骤三:对于多扇出算子,计算该算子引导的所有路径的MII的最小值,采用平衡节点算子作为共享平衡节点算子降低该MII最小值;
步骤四:多扇出算子引导的路径减去最短路径后,判断当前共享平衡节点算子是否为多扇出算子,重复步骤二和步骤三,直至该多扇出算子引导路径的MII均降至最低;
步骤五:遍历当前运算的所有路径,重复步骤二到步骤四,直至所有路径的MII均降至最低,运算结束。
进一步的,所述步骤四和步骤五中MII均消除为0。
进一步的,所述采用平衡节点算子的方式包括:加入一个平衡节点算子进行数据的传递。
进一步的,所述平衡节点算子采用线性基本逻辑计算单元BFU。
进一步的,在针对整张映射图采用平衡节点算子优化时,首先优化数据路径中最长的两条输入路径;当最长的两条路径达到平衡之后再选择次长的输入路径进行优化分析,直至整张图的输入算子路径平衡或MII降至最低。
进一步的,多扇出算子路径中的共享平衡节点算子在多条路径中被共用。
进一步的,在多轮循环中,通过存储数据单元SREG进行传递数据通信,使得第二轮循环的每个输入算子接收到的输入数据都是独立的,第二轮的循环保留第一轮循环的性能指标。
进一步的,判断当循环轮内存在数据依赖关系时,使用SREG替代MEM作为中间存储器。
进一步的,在本轮的数据传递完成后释放SREG,并给出空闲标志。
进一步的,SREG的使用优先级为:密码算法内轮循环的数据依赖优先级最高,密码算法之间的数据依赖优先级其次,SREG的特性移位功能优先级最低。
与现有技术相比,本发明具有如下优点和有益效果:
1.本发明采用平衡节点算子方式对映射图进行优化,使其拥有最小的迭代间隔和最大的流水性能,解决了手工配置流水性能差的问题,节约了大量的人力脑力劳动,不需要人工计算手动添加平衡算子节点。
2.本发明采用共享平衡节点算子的方案处理多扇出的算子平衡节点,解决了多扇出算子单元映射在资源限制的情况下映射失败的问题,使得计算资源最小化以及性能最大化。
3.采用存储数据单元SREG进行传递数据通信,解决了循环体间数据的通信占用较多传递算子资源的问题,节约了大量的硬件资源,进一步提升了流水性能。
附图说明
图1为本发明映射过程的输入有向数据流图DFG。
图2为本发明插入传递平衡算子延长输入路径。
图3为本发明映射图MII优化过程示例。
图4为本发明传递算子的共享示例。
图5为优化的可重构高性能编译器示例。
图6为本发明SREG模块单元模式图。
具体实施方式
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
面向信息安全的可重构系统芯片编译器的设计,包括:前端的原语输入,中间文件的优化以及后端的映射三个重要过程。其中,在后端的映射方案过程中,针对不同的硬件架构有不同的映射方案,影响编译器效果的指标主要是编译器的性能,而影响性能的关键技术指标是映射图的并行计算性能。可重构处理器的后端映射的输入是针对有向的数据流图(DataFlow Graph,DFG)进行映射处理到硬件架构上的。图1是由编译器前端产生的中间过程表示的数据依赖关系的图,它是一个有向的数据流图,代表了数据的方向及数据所执行的计算逻辑功能,密码算法依据给定的数据流图依次执行即可得到最终的加密结果。图中,箭头表示数据流向,圈内代表可执行的逻辑运算操作,可实现的逻辑分别有加法,基本算术逻辑运算,移位操作以及乘法运算。其中每个算子都有三个输入两个输出。图1中,AU,SU,MU分别是加法运算单元,移位运算单元和乘法运算单元。映射图的并行计算性能是指在可重构计算中,多个无依赖的计算单元可以同时计算的能力,这样的计算能力在一定程度上反映了映射方案的并行程度,称之为并行计算能力。由于密码算法属于计算密集型的算法,而计算阵列的大小以及硬件的资源是有限的,硬件的每次重构通常由8个线性基本逻辑计算单元,4个查找表单元和1个位置换单元组成,一个密码算法完整的数据流图往往需要进行多次的重构才能实现,因此可以将数据流图按照密码算法的特点进行拆分成初始计算轮,循环迭代轮以及输出前处理轮。由于密码算法的复杂性则循环迭代轮将花费大量的时间,因此循环迭代轮是整个映射方案的设计核心。而每轮循环之间是相似或者是相同的,因此普遍的做法是将一轮循环作为子图进行映射方案的探索,最后通过迭代复制的方式实现整张数据流图的映射迭代实现。本发明从单个循环的并行映射方案以及多轮循环间的数据迭代出发,设计一种面向信息安全的并行流水气泡的映射方案。
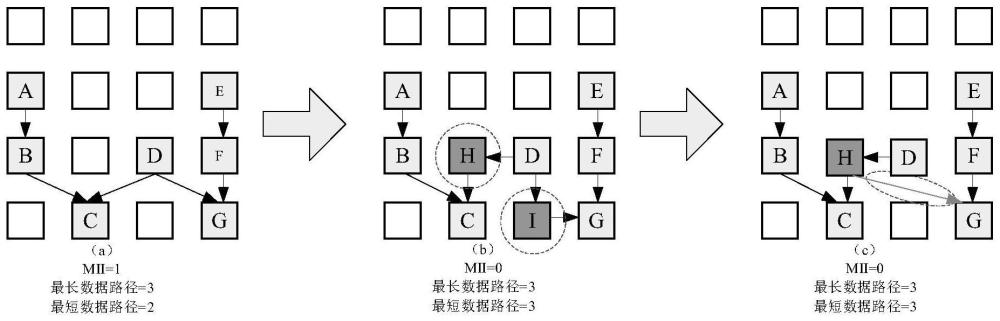
一张给定的映射图携带了密码算法数据间的依赖关系以及所进行的操作,通过对路由以及阵列中其他参数的调整依然可以对映射图作进一步的优化。在以往的研究中,在面对特殊约束的情况下存在优化不足甚至映射失败的情况,本发明针对循环体内以及多轮循环体间的数据通信进行分析设计,提出一种共享平衡算子节点的循环映射方案。图2是一个固定的映射图,A->B->D和C->D为两条数据计算传输路径,通过插入平衡节点算子的方法延长短的数据流输入路径长度,由图可以看出,若图中每个节点计算都花费1个时间周期,由于到达125D节点所经过的路径长度不同,因此到达的时间也不相同。在流水型的可重构计算中,每个周期的计算单元阵列都不是同一个,因此只要本次的计算不对上一次迭代过程的数据造成影响,则下一次迭代计算可以提前启动,从而提高流水性能。将两次迭代计算之间的周期称为迭代间隔(IterationInterval,II),其中,II越小则流水性能越高,因此本发明提高流水性能的方法就变成了寻找最小迭代间隔(MinIterationInterval,MII)。当MII为0时,代表下一次迭130代会在上一次迭代启动后立马启动,此时拥有最小的迭代间隔,同时会拥有最大的流水性能。
图2中A->B->D需要3个周期,C->D需要2个周期此时的MII应为1,若下一次的迭代计算在上一次的计算启动的下一周期就开始,即MII=0,则C的数据在B到达的同时进行了更改,从而使得D数据产生计算错误,因此需要加入一个平衡节点算子进行数据的传递,使得输入数据的多个计算路径相等,此时的MII为0,映射图将拥有最小的迭代间隔和最大的流135水性能。
平衡节点算子统一选用BFU(线性基本逻辑计算单元),该算子在使用时可以起到单周期数据传递的作用,对于SBOX(查找表单元)和BENES(位置换单元)这两个算子,在进行数据处理时需要指定的资源配置支持,采用这两个算子做数据传递有资源冲突和性能降低的风险。BFU共有8个,编译优化时随机选择空闲BFU作为平衡节点算子。在采用BFU作140为平衡节点算子时,一个BFU在单周期内可消除1个MII,在一个RCA(重构运算单元)周期内,空闲的BFU可进行串联消除MII,但不可重复使用一个BFU,因此,一个RCA周期可消除最大8个MII值。
通过分析可以得知,最小迭代间隔MII为触发周期最晚的算子输入路径长度与触发周期最早的算子输入路径长度的差,当MII为0时,则意味着触发算子的路径长度一致,此时拥145有平衡的算子路径输入,可以达到最大的流水性能。如图3所示,描述的是给定的一整张映射图的插入平衡节点算子示例,针对整张映射图来说,通过插入传递节点算子进行平衡算子路径输入的方案,首先优化数据路径中最长的两条输入路径,最长的两条路径达到平衡之后再选择次长的输入路径进行优化分析,直至整张图的输入算子路径平衡为止。然而,对于密码算法这种计算密集型算法来说,其数据流图中的一个节点被多条路径使用的情况比较普遍,150将这一类的节点算子被称之为多扇出的节点。插入算子节点平衡算子来提高性能这一方案对于单扇出的算子输出非常有效,但是对于多扇出的算子节点来说可能会造成不必要的资源性能开支,甚至可能在资源有限的情况下导致算法映射失败等问题。因此,本发明提出一种共享平衡节点算子的方案来处理这种多扇出的算子平衡节点问题。共享平衡节点算子的实现方案步骤如下:
155步骤一:计算当前运算所有路径的路径长度,根据当前路径与最大路径的路径长度差,
获得每条路径的MII。
步骤二:判断当前处理的算子是否是多扇出算子,如果是,则进入步骤三;如果不是,则采用平衡节点算子消除该算子引导的路径的MII。
步骤三:对于多扇出算子,计算该算子引导的所有路径的MII的最小值,采用平衡节点160算子消除该MII最小值。此时平衡节点算子称为共享平衡节点算子。
步骤四:多扇出算子引导的路径减去最短路径后,判断当前共享平衡节点算子是否为多扇出算子,重复步骤二和步骤三,直至该多扇出算子引导路径的MII均消除为0。
步骤五:遍历当前运算的所有路径,重复步骤二到步骤四,直至所有路径的MII均消除为0,运算结束。
165需要说明的是,“MII=0”条件为理想目标,但不一定能通过编译优化满足,但只要尽量优化后让MII变小,即有利于提升性能。
示例如下:如图4(a)所示,是一张给定的具有多扇出算子的数据流图,其中D节点为多扇出的节点,对于这种类型的算子传统的做法是将该算子按照每一条不同的路径进行分析,
如图4(b)直接在每条路径上插入平衡节点算子的方式来降低MII,从而提高流水性能。但170是在某些资源紧缺的情况下,会带来一系列的性能问题,对于可重构计算单元来说,每一行的算子输入来源均可是上一行的输出,本行的输出以及存储单元,因此对于节点D,其在多条路径上插入的平衡节点算子充当的作用是一样的,因此将多扇出算子路径的传递算子进行多条路径共用,如图4(c)所示,从而使得计算资源最小化以及性能最大化。
相较于普通平衡节点算子,共享平衡节点算子在算子资源上进行了优化,多扇出算子越175多,优化力度越大。在加密算法这类计算密集型算法中,共享平衡节点方案取得的优势非常显著。在本发明中,采用共享平衡节点算子对面向密码算法的可重构高性能编译器进行优化,如图5所示,以8个BFU(基本运算单元),4个SBOX(非线性置换表)和1个BENES(比特置换)作为基本算子,构成一个RCA(重构运算单元)。BFU实现了密码算法中的大部分基本运算,如SU支持逻辑移位和算数移位功能;LU支持基本异或功能;AU支持加减法运180算;MU支持乘法运算。这些运算不需要额外的资源配置信息,三个输入在不同的重构配置下能够得到两个输出结果。SBOX实现了查找表的功能,为密码算法中的非线性运算提供便利。BENES支持大小端转换功能,保证数据在不同处理器上的正确性。在这些算子中,SBOX和BENES需要额外的资源配置,在每一次RCA运行之前需要将资源配置载入,需要消耗一定的时间。RCA的实际运算由编译器进行配置,性能和资源开销也由编译器的优化力度决定。185在硬件方面,密码可重构运算模块作为外设挂载在硬件系统中,编译配置码可通过PCIe总线写入,也可通过系统AXI总线写入。在实际加密过程中,编译器由共享平衡节点算子生成的重构配置所带来的资源优化和性能优化都有较大的提升。
在探索一个密码算法的映射方案时,虽然首先的探索对象是其中的一轮循环,但是映射的整个过程是对多轮循环以及循环体外多轮循环的整体映射,因此还应考虑多轮循环的通信190对算法性能带来的影响。由于硬件逻辑特性,每一行的算子输入只能来源于上一行算子和本行算子的输出以及存储单元,因此在循环体间就可能存在无法进行数据通信的问题,如果增加一个循环体的输出必须在最后一行,输入必须在起始行的限制,可能由于这样苛刻的限制条件而使得映射找不到最佳映射方案而导致映射失败。本发明通过存储数据单元SREG进行传递数据通信,从而保证第二轮循环的每个输入算子接收到的输入数据都是独立的,这样保195证了第二轮的循环仍然保留第一轮循环的性能指标,如图6所示,是SREG的原理图,它共有三种工作模式,分别是1*16个独立的读写模块,4*4个带有移位功能的模块以及1*16个带有移位功能的模块,其具有16个独立的存储单元,每一行都有四个写端口,同时包含存储和移位的功能,对类似于哈希算法此类带有向量移位的算法有着重要意义,相比于MEM存储单元来说,SREG在本行写入下一行即可读出正确的数据,因此不会造成数据的延迟,减200少了数据通信的连线以及增加额外算子的使用,同时保证了数据的正确传输通信。SREG在编译生成的过程中:
首先,判断加密算法的循环轮内是否存在数据依赖关系,若存在,则考虑使用SREG替代MEM作为中间存储器。
其次,考虑SREG的释放问题,作为快速存储器,同样容量的SREG的资源消耗必然大205于MEM,考虑到SREG的重用特性,本轮的数据传递完成后需要释放SREG,并给出空闲标志。
最后,考虑SREG使用优先级的问题,密码算法内轮循环的数据依赖优先级最高,密码算法之间的数据依赖其次,SREG的特性移位等功能优先级最低。
以上设计规则所设计的SREG,在实际的通用密码算法重构编译过程中,起到了很好的210数据传递作用。在本设计的密码算法编译时,AES-CBC加密模式的每一轮加密的密文作为第二轮加密的初始数据,传统编译器为了保证循环之间的一致性,判断密文作为结果输出的同时,需要采用存储器进行数据存储,导致下一轮的初始数据无法立即获得,为了保证算法的正确性,编译器采用添加空轮运算方式,降低了运算效率。而添加了SREG结构后,该问题通过SREG快速存取的特性得到了很好的解决。
215本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 一种面向可重构计算阵列的算子映射系统及方法
- 一种面向可重构计算阵列的算子映射系统及方法