一种基于实时流计算的停电数据分析处理方法及装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及电网数据处理领域,特别涉及一种基于实时流计算的停电数据分析处理方法及装置。
背景技术
随着社会经济的发展和人们对美好生活日益增加的需求,电网作为电能的载体,也在经历着革新与转型。大数据和云计算的研究是电网技术研究中一个非常重要的分支,随着电网客户的服务渠道多元化,在如今海量的实时电力数据中,如何准确的实时的提取需要的数据并对数据进行计算和处理,实现大数据的合理应用与高效利用成为了当前亟待解决的问题。
发明内容
为了解决现有技术中存在的上述问题,本发明的目的是为了提供一种采用sqoop分布式抽取、依托OGG和Kafka的组合能力,将Spark与MapReduce结合以实现实时的电力大数据的高效利用的基于实时流计算的停电数据分析处理方法。
为了实现上述目的,本发明采用了以下的技术方案:
本发明提供了一种基于实时流计算的停电数据分析处理方法,包括:
采用sqoop分布式抽取从实时数据库中采集实时数据,传输至分布式文件系统中;
采用Spark Streming计算引擎和Mapreduce计算引擎对分布式文件系统中的数据进行处理,生成停电结果数据;
对上述停电结果数据进行应用。
在一种实施方式中,上述实时数据库为关系型数据库。
在一种实施方式中,上述采用sqoop分布式抽取从实时数据库中采集实时数据,传输至分布式文件系统中,包括:
采用OGG将上述实时数据库中的实时数据同步复制到MySQL集群中;
对于MySQL集群中每一个MySQL服务器的数据,通过ETL分别同步至MPP数据仓库,其中,上述MPP数据仓库采用Kafka作为数据源;
采用sqoop分布式抽取,获取上述MPP数据仓库中的增量分区表;
将上述增量分区表传输至Hadoop分布式文件系统中。
在一种实施方式中,上述采用Spark Streming计算引擎和Mapreduce计算引擎对分布式文件系统中的实时数据进行处理,生成停电结果数据,包括:
对于存储在HDFS中的实时电力数据,采用基于HDFS环境上运行的spark框架进行内存计算,利用Spark Streming计算引擎和Flink计算引擎实现实时流计算,采用基于HDFS的Mapreduce计算引擎进行计算任务流组合,控制数据在不停的数据处理规则中单线流转,将计算后的结果汇总后得到停电结果数据。
在一种实施方式中,上述方法还包括:
将上述停电结果数据写入hadoop分布式文件系统中。
本发明还提供了一种基于实时流计算的停电数据分析处理装置,包括:
实时数据库,用于存储停电事件引发的实时数据;
数据采集模块,用于基于上述实时数据库,采用sqoop分布式抽取采集实时数据,传输至分布式文件系统中;
数据处理模块,用于采用spark计算引擎和Mapreduce计算引擎对分布式文件系统中的实时数据进行处理,生成停电结果数据;
数据应用模块,用于对上述停电结果数据进行应用。
在一种实施方式中,上述实时数据库为关系型数据库。
在一种实施方式中,上述数据采集模块包括:
复制子模块,用于采用OGG将上述实时数据库中的实时数据同步复制到MySQL集群中;
同步子模块,用于对于MySQL集群中每一个MySQL服务器的数据,通过ETL分别同步至MPP数据仓库,其中,上述MPP数据仓库采用Kafka作为数据源;
抽取子模块,用于采用sqoop分布式抽取,获取上述MPP数据仓库中的增量分区表;
传输子模块,用于将上述增量分区表传输至Hadoop分布式文件系统中。
在一种实施方式中,上述数据处理模块包括:
对于存储在HDFS中的实时电力数据,采用基于HDFS环境上运行的spark框架进行内存计算,利用Spark Streming计算引擎和Flink计算引擎实现实时流计算,采用基于HDFS的Mapreduce计算引擎进行计算任务流组合,控制数据在不停的数据处理规则中单线流转,将计算后的结果汇总后得到停电结果数据。
在一种实施方式中,上述装置还包括:
写入模块,用于将上述停电结果数据写入hadoop分布式文件系统中。
本发明提供的上述技术方案的有益效果至少包括:
本发明的一种基于实时流计算的停电数据分析处理方法及装置,采用sqoop分布式抽取进行实时数据库与分布式文件系统之间的数据传输,依托了OGG和Kafka的组合能力,解决了实时数据的同步需求,通过MapReduce计算引擎承载一体化分布式数据计算能力,支撑高效的实时数据处理计算的需求,利用分布式的思想和方法,应用流式计算的SparkStreming组件,对海量“流”式数据进行实时处理,解决实时数据计算数据交互问题,实现了TB级别数据量的实时数据的同步与计算,万级计算任务在30分钟内完成。同时,基于对实时数据的计算与分析,提高了停电监测分析及预警能力,提升了停电事件的精准的服务能力。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍。通过阅读参照以下附图所作的对非限制性实施例的详细描述,本申请的其它特征、目的和优点将会变得更明显。
图1为本发明实施例提供的一种基于实时流计算的停电数据分析处理方法的流程示例图;
图2为本发明实施例提供的Spark与HDFS结合的整体架构图;
图3为本发明实施例提供的一种基于实时流计算的停电数据分析处理装置的结构示例图。
具体实施方式
为了更好地理解本申请,将参考附图对本申请的各个方面做出更详细的说明。应理解,这些详细说明只是对本申请的示例性实施方式的描述,而非以任何方式限制本申请的范围。在说明书全文中,相同的附图标号指代相同的元件。表述“和/或”包括相关联的所列项目中的一个或多个的任何和全部组合。
在附图中,为了便于说明,已稍微调整了元素的大小、尺寸和形状。附图仅为示例而并非严格按比例绘制。如在本文中使用的,用语“大致”、“大约”以及类似的用语用作表近似的用语,而不用作表程度的用语,并且旨在说明将由本领域普通技术人员认识到的、测量值或计算值中的固有偏差。另外,在本申请中,各步骤处理描述的先后顺序并不必然表示这些处理在实际操作中出现的顺序,除非有明确其它限定或者能够从上下文推导出的除外。
还应理解的是,诸如“包括”、“包括有”、“具有”、“包含”和/或“包含有”等表述在本说明书中是开放性而非封闭性的表述,其表示存在所陈述的特征、元件和/或部件,但不排除一个或多个其它特征、元件、部件和/或它们的组合的存在。此外,当诸如“...中的至少一个”的表述出现在所列特征的列表之后时,其修饰整列特征,而非仅仅修饰列表中的单独元件。此外,当描述本申请的实施方式时,使用“可”表示“本申请的一个或多个实施方式”。并且,用语“示例性的”旨在指代示例或举例说明。
除非另外限定,否则本文中使用的所有措辞(包括工程术语和科技术语)均具有与本申请所属领域普通技术人员的通常理解相同的含义。还应理解的是,除非本申请中有明确的说明,否则在常用词典中定义的词语应被解释为具有与它们在相关技术的上下文中的含义一致的含义,而不应以理想化或过于形式化的意义解释。
需要说明的是,在不冲突的情况下,本申请中的实施方式及实施方式中的特征可以相互组合。下面将参考附图并结合实施方式来详细说明本申请。
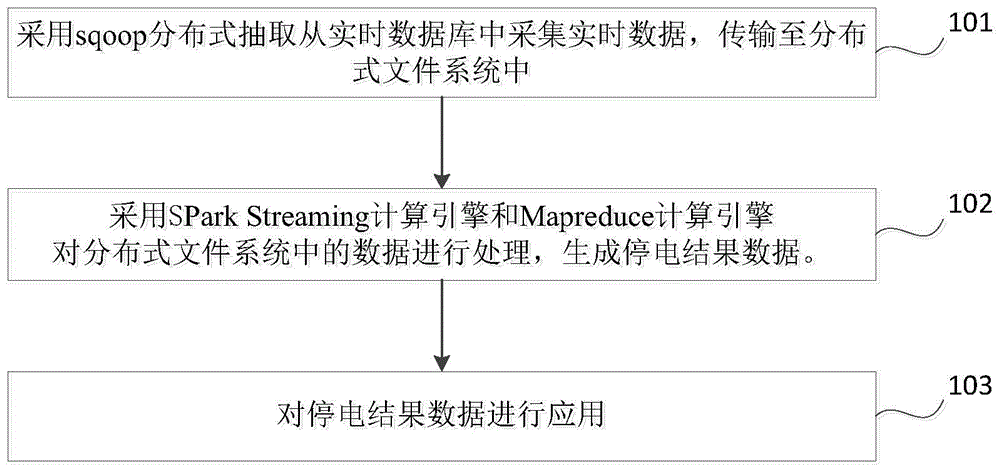
如图1所示,本发明提供了一种基于实时流计算的停电数据分析处理方法,包括:
步骤101,采用sqoop分布式抽取从实时数据库中采集实时数据,传输至分布式文件系统中。
在一种实施方式中,上述实时数据库为关系型数据库。作为示例,实时数据库包括但不限于基础支撑平台数据库、呼叫平台数据库、业务支撑系统数据库等。
在一种实施方式中,上述采用sqoop分布式抽取从实时数据库中采集实时数据,传输至分布式文件系统中,包括:
第一步,采用OGG将上述实时数据库中的实时数据同步复制到MySQL集群中;其中,上述实时数据为结构化数据,实时数据中存在全量数据和增量数据。具体地,采用OGG将增量数据同步复制到MySQL集群中。作为示例,实时数据包括但不限于抢修工单数据、停电相关数据、话务信息数据等。其中,OGG(Oracle GoldenGate)用于实时数据集成和复制,能够实现大量数据的实时捕捉、变换和投递,实现实时数据库与MySQL集群的数据同步,保持亚秒级的数据延迟。
第二步,对于MySQL集群中每一个MySQL服务器的数据,通过ETL分别同步至MPP数据仓库,其中,上述MPP数据仓库采用Kafka作为数据源。具体地,对于MySQL集群中每一个MySQL服务器的数据,经过抽取、转换、加载、清洗至MPP数据仓库中。在这个过程中,将分散、凌乱、标准不统一的电网数据整合,为后续企业对于数据的处理提供分析依据。
其中,MySQL集群是MySQL适合于分布式计算环境的高可用、高冗余版本,允许在1个集群中运行多个MySQL服务器。
其中,MPP数据仓库是采用MPP架构的数据库。这里,MPP架构将任务并行的分散到多个服务器和节点上,对于MySQL集群中每一个MySQL服务器的数据通过ETL将各自部分的结果汇总在一起整合形成最终的增量分区表。
其中,ETL(Extract-Transform-Load)用来描述将数据从MySQL集群经过抽取(extract)、转换(transform)、加载(load)、清洗至MPP数据仓库的过程。
其中,Kafka是一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,可以处理用户在网站中的所有动作流数据,MPP数据仓库采用Kafka作为数据源以实时获取用户在电网相关的所有网站中所有的动作流数据。
第三步,采用sqoop分布式抽取,获取上述MPP数据仓库中的增量分区表。具体地,对于MPP数据仓库中的增量数据,以增量分区表的形式存储。作为示例,根据业务需求,采用sqoop分布式抽取,获取MPP数据仓库中当前时间的增量分区表。其中,sqoop是用于将MPP数据仓库中的数据导入到Hadoop分布式文件系统中的工具。
第四步,将上述增量分区表传输至Hadoop分布式文件系统(HDFS)中。具体地,sqoop将上述增量分区表中的所有数据作为实时电力数据抽取并存储至至Hadoop分布式文件系统,打印并存储抽取日志。
在上述第一步至第四步的数据采集过程中,通过OGG将数据同步到Kafka,采用Sqoop将数据传输到HDFS分布式存储的数据库中,依托OGG和Kafka的组合能力,解决了实时数据的同步需求。
步骤102,采用Spark Streming计算引擎和Mapreduce计算引擎对分布式文件系统中的数据进行处理,生成停电结果数据。具体地,将Spark与HDFS结合,形成一种分布式集群环境,整体架构如图2所示。
在一种实施方式中,上述采用Spark Streming计算引擎和Mapreduce计算引擎对分布式文件系统中的实时数据进行处理,生成停电结果数据,包括:
对于存储在HDFS中的实时电力数据,采用基于HDFS环境上运行的spark框架进行内存计算,利用Spark Streming计算引擎和Flink计算引擎实现实时流计算,采用基于HDFS的Mapreduce计算引擎进行计算任务流组合,控制数据在不停的数据处理规则中单线流转,将计算后的结果汇总后得到停电结果数据。
其中,Spark实际上是对Hadoop分布式文件系统的补充,可以在Hadoop分布式文件系统中并行运行。
其中,Spark Streming计算引擎可以实现高吞吐量的、具备容错机制的实时流数据的处理,Spark Streming在内部的处理机制是,对实时接收的数据,根据一定的时间间隔拆分成一批批的批数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
其中,Flink计算引擎以数据并行和流水线方式执行任意数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序,因此本申请的技术方案将Spark Streming计算引擎和Flink计算引擎结合共同处理实时流数据。采用基于HDFS的Mapreduce计算引擎进行计算任务流组合,采用工作流方式管理数据接入、数据计算等任务,实现任务配置式串并行执行,进行过程可视化监控。
在一种实施方式中,在步骤102后,上述基于实时流计算的停电数据分析处理方法还包括:
将上述停电结果数据写入hadoop分布式文件系统中。具体地,对上述停电结果数据进行数据存储,写入hadoop分布式文件系统中,同时,还需要将上述停电结果数据存储至缓存数据库和/或关系型数据库中。
步骤103,对上述停电结果数据进行应用。
在一种实施方式中,上述对上述停电结果数据进行应用,包括:
第一步,上述停电结果数据中包括监测分析、监控预警、态势监控和统计报表所需的轻度汇总数据。
第二步,基于上述轻度汇总数据进行监控监测分析和监控预警及报送,生成监控监测分析结果和监控预警及报送结果。作为示例,上述监控监测分析包括但不限于抢修工单态势监控、停电时长监控分析等;上述监控预警及报送包括但不限于停电风险预警发送、抢修热点区域预警等。
在一些实施例中,基于上述轻度汇总数据进行抢修工单态势的监控监测分析具体包括:
将抢修工单态势的量化评估值作为y(t),该量化值是反映停电抢修工单生成率、影响覆盖率及其抢修完成该工单的停电消解率综合性量化指标,数值越高则停电抢修工单生成率和影响覆盖率越大且抢修完成工单的停电消解率越低;反之,抢修工单态势的量化评估值的数值越低则停电抢修工单生成率和影响覆盖率越小且抢修完成工单的停电消解率越高。进而,从所述轻度汇总数据中统计所述停电抢修工单生成率、停电影响覆盖率以及抢修完成工单停电消解率作为因变量z(t),获得抢修工单态势的量化评估值y(t)和停电抢修工单生成率、停电影响覆盖率以及抢修完成工单停电消解率的因变量z(t)的n组训练样本的模型训练集合{y
进而,建立抢修工单态势的机器学习回归模型,该模型的描述为:
y(t)=μ(t)+∫z(s)β(s,t)ds+∈(t)式(1)
代入以上模型训练集合的训练样本可得:
y
上式中,β(s,t)为回归系数函数,是s,t的一个二元函数,可以解释为对给定t,放在因变量z在s处的值z(s)上的权重,式中s和t均为时间,μ(t)为截距函数,从而∫z(s)β(s,t)ds是通过积分得到的一个时间函数,∈
进而,使用基函数对抢修工单态势的机器学习回归模型以及损失函数进行拟合,具体来说,使用基函数向量θ(t)将回归系数函数β(s,t)和截距函数μ(t)分别展开为:
其中:K1、K2为将β(s,t)展开时采用基的个数,K1、K2数值越大越逼近β(s,t),C为由矩阵元素c
进而,抢修工单态势的机器学习回归模型可以表示为矩阵型模型的形式,如下式(7):
Y(t)=ZBθ(t)+E(t)式(7)
其中,
第三步,将上述监控监测分析结果和监控预警及报送结果推送到大屏和/或PC端进行可视化展示。其中,通过对定量化预测的抢修工单态势量化评估值进行可视化展示以及监测分析,能够准确预测停电事故及其抢修进度的时变性的发展态势,为分析、评估和抢修调度提供定量依据。
本发明提供的上述技术方案的有益效果至少包括:
本发明的一种基于实时流计算的停电数据分析处理方法,采用sqoop分布式抽取进行实时数据库与分布式文件系统之间的数据传输,依托了OGG和Kafka的组合能力,解决了实时数据的同步需求,通过MapReduce计算引擎承载一体化分布式数据计算能力,支撑高效的实时数据处理计算的需求,利用分布式的思想和方法,应用流式计算的SparkStreming组件,对海量“流”式数据进行实时处理,解决实时数据计算数据交互问题,实现了TB级别数据量的实时数据的同步与计算,万级计算任务在30分钟内完成。同时,基于对实时数据的计算与分析,通过建立机器学习回归模型定量化预测抢修工单态势的量化评估值,提高了停电监测分析及预警能力,提升了停电事件的精准的服务能力。
如图3所示,本发明还提供了一种基于实时流计算的停电数据分析处理装置,包括:
实时数据库201,用于存储停电事件引发的实时数据;
数据采集模块202,用于基于上述实时数据库,采用sqoop分布式抽取采集实时数据,传输至分布式文件系统中;
数据处理模块203,用于采用spark计算引擎和Mapreduce计算引擎对分布式文件系统中的实时数据进行处理,生成停电结果数据;
数据应用模块204,用于对上述停电结果数据进行应用。
在一种实施方式中,上述实时数据库201为关系型数据库。
在一种实施方式中,上述数据采集模块202包括:
复制子模块,用于采用OGG将上述实时数据库中的实时数据同步复制到MySQL集群中;
同步子模块,用于对于MySQL集群中每一个MySQL服务器的数据,通过ETL分别同步至MPP数据仓库,其中,上述MPP数据仓库采用Kafka作为数据源;
抽取子模块,用于采用sqoop分布式抽取,获取上述MPP数据仓库中的增量分区表。
传输子模块,用于将上述增量分区表传输至Hadoop分布式文件系统中。
在一种实施方式中,上述采用spark计算引擎和Mapreduce计算引擎对分布式文件系统中的实时数据进行处理,生成停电结果数据,包括:
对于存储在HDFS中的实时电力数据,采用基于HDFS环境上运行的spark框架进行内存计算,利用Spark Streming计算引擎和Flink计算引擎实现实时流计算,采用基于HDFS的Mapreduce计算引擎进行计算任务流组合,控制数据在不停的数据处理规则中单线流转,将计算后的结果汇总后得到停电结果数据。
在一种实施方式中,在数据处理模块203后,上述装置还包括:
写入模块205,用于将上述停电结果数据写入hadoop分布式文件系统中。
本发明提供的上述技术方案的有益效果至少包括:
本发明的一种基于实时流计算的停电数据分析处理装置,采用sqoop分布式抽取进行实时数据库与分布式文件系统之间的数据传输,依托了OGG和Kafka的组合能力,解决了实时数据的同步需求,通过MapReduce计算引擎承载一体化分布式数据计算能力,支撑高效的实时数据处理计算的需求,利用分布式的思想和方法,应用流式计算的SparkStreming组件,对海量“流”式数据进行实时处理,解决实时数据计算数据交互问题,实现了TB级别数据量的实时数据的同步与计算,万级计算任务在30分钟内完成。同时,基于对实时数据的计算与分析,提高了停电监测分析及预警能力,提升了停电事件的精准的服务能力。
以上说明书中描述的只是本发明的具体实施方式,各种举例说明不对本发明的实质内容构成限制,所属技术领域的普通技术人员在阅读了说明书后可以对以前所述的具体实施方式做修改或变形,而不背离本发明的实质和范围。
- 一种基于分布式流计算的数据处理方法及系统
- 一种实时定位处理方法及装置
- 一种规则的实时处理方法、装置、规则引擎及存储介质
- 基于数据分析的资金处理方法、装置、存储介质和设备
- 基于流计算引擎的实时标签处理方法和装置
- 一种基于知识图谱与停电大数据分析的停电故障研判方法