基于安全强化学习的高超声速飞行器最优控制方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及飞行器控制技术领域,具体涉及一种基于安全强化学习的高超声速飞行器最优控制方法。
背景技术
高超声速飞行器是速度大于5马赫的飞行器,这也被认为是确保成本效益和可靠进入空间的最优前途的技术之一。由于其巨大的军事和民用价值,高超声速飞行器正成为各军事强国的焦点。与传统飞行器相比,高超声速飞行器的特性受到复杂飞行环境的影响,大气和气动特性的预测也存在很大的问题。尽管一些高超声速飞行器已经成功飞行,包括NASA X-43A和X-51A实验飞行器,但是由于推进系统、空气动力学和结构动力学之间相互作用的复杂性,为高超声速飞行器设计一个鲁棒和高效的飞行控制方案仍然是一个具有挑战性的问题。
关于高超声速飞行器一些常用的控制方案,例如:滑模控制、反步控制、模糊控制、基于线性二次调节器的控制、线性参数变化控制、动态面控制和神经网络控制等等,尽管已经研究了这些非线性控制方案,并取得了许多有意义的成果,但大多数现有的方法通常开发具有固定参数和已知系统模型的控制器。即在参数不确定和环境干扰条件下,现有的大多数非线性控制方案都没有解决高超声速飞行器的自适应控制问题。为高超声速飞行器提供一种基于计算智能的在线学习控制方案,将学习和适应能力融合到飞行控制器中,是一种更有前途的控制方案。
另一方面,在实际应用中,飞行器飞行过程中的安全问题也是不可忽视的关键问题。在安全关键应用中,控制器设计的一个基本问题是被控系统的能力,不仅实现安全和稳定性,而且满足自定义的性能。在实践中,由于机身和推进系统之间的非线性耦合效应,为了维持超燃冲压发动机的预期运行,高超声速飞行器的状态应该始终在约束的范围内。同时,还应限制俯仰速率,以防止高超声速引起的剧烈震动。因此,在设计高超声速飞行器自适应在线学习控制方案时,应进一步考虑全状态约束。
发明内容
本发明实施例的目的在于提供一种基于安全强化学习的高超声速飞行器最优控制方法,属于在线学习的控制方法,可以同时保证飞行器在飞行过程中状态的安全性。
本发明实施例是这样实现的,一种基于安全强化学习的高超声速飞行器最优控制方法,包括如下具体步骤:
步骤1,建立高超声速飞行器纵向动力学模型。
建立高超声速飞行器纵向动力学模型为:
其中,V,h,γ,α,Q分别表示飞行器的速度,高度,航迹角,攻角以及俯仰角速度,m为飞行器质量,I
其中,
其中,Φ,δ
步骤2,将高超声速飞行器纵向动力学模型化简为一般的仿射非线性系统模型。
将高超声速飞行器的纵向动力学模型分解为速度子系统与高度子系统,并进一步化简为一般的仿射非线性系统模型。
将速度子系统化简为:
其中,
其中,Δ
将高度子系统化简为:
其中,
其中,Δ
不失一般性,速度子系统和高度子系统可以归纳为
其中,对于速度子系统,x=x
对于高度子系统,x=[x
f(x)=[f
g(x)=[g
步骤3,提出一种基于障碍函数的系统变换,将全状态安全约束问题转化为无约束优化问题。
将高超声速飞行器纵向动力学的全状态约束在安全区域内,即具有全状态约束的高超声速飞行器的安全控制问题。描述如下:
问题1(具有全状态约束的安全控制问题):
考虑系统(3),找到控制策略u,对于每个x(0),在状态约束x
最小化,其中a
在此基础上,提出了基于障碍函数的系统变换,将给出的具有非对称的全状态约束的安全控制问题转化为稳定性问题,具体描述如下:
定义1(障碍函数):定义在(a,b)上的函数
其中,a和b是满足a<0<b的两个常数。此外,障碍函数在区间(a,b)上是可逆的,即
并有
考虑系统(3),定义基于障碍函数的状态转换如下:
那么,
根据定义1,下式成立
其中,
因此,变换后的变量z=[z
其中,F(z)=[F
假设1:系统(6)满足:
1)F(z)是李普希兹的,F(0)=0,对z∈Ω
2)G(z)在Ω
3)在紧集Ω
在上文中,我们引入障碍函数,将系统(3)转化为等价系统(6)。下面,我们引入一个新的问题,以解决问题1的全状态约束。
问题2(最优控制问题):找到控制策略u使得代价函数
最小化,其中r(z,u)=Q(z)+u
给定一个可容许控制策略u,定义哈密尔顿量为
其中,
然后,对代价函数V(z)求导得到贝尔曼方程为
考虑最优代价函数,表示为
根据最优的必要条件
可得最优控制策略u
假设2:对于可容许控制策略u,非线性李雅普诺夫方程(8)具有局部光滑解
具有全状态约束的问题1和无约束最优问题2等价的条件由以下引理给出。
引理1:若假设1和假设2成立,并且控制策略u
1)只要系统(3)的初始状态x
2)若函数Γ(x)和Q(z)满足Γ(x)=Q(z),代价函数(4)和(7)等价。
步骤4,采用安全强化学习算法在执行-评价框架下设计近似最优控制器。
通过应用评价网络和执行网络实现在线安全强化学习算法设计近似最优控制器。
首先,评价网络:
求解哈密尔顿-雅可比-贝尔曼方程的最初步骤是通过采用如下一个评价网络局部逼近最优代价函数:
其中,
价值函数V
其中,
给定最优控制策略u
其中,σ是N维向量表示为
贝尔曼方程残差可表示为
根据代价函数梯度近似(9)可以看出,贝尔曼近似误差ε
最优值函数V
然后,对于一个给定的控制策略u,哈密尔顿量近似误差描述为
定义评价网络的权重估计误差为
为了使得当
/>
其中,α
其次,执行网络:
由于最优控制策略由最优代价函数梯度
利用具有自适应评价网络权值
为了保证李雅普诺夫意义上的稳定性,控制策略用如下执行网络来表示
其中,
执行网络学习规则由下面的误差决定
执行网络的目标是使下列目标函数最小化
利用梯度下降算法,可以得到执行网络的权值更新律为
定义执行网络的权值估计误差为
稳定性分析:
假设3:以下结论在紧集Ω
1)未知的评价网络理想权值
2)评价网络和执行网络的近似误差有上界,即||ε
3)评价网络和执行网络的激活函数有上界,即||φ
4)评价网络和执行网络的近似误差梯度和激活函数梯度有上界,即
5)残差有上界,即||ε
步骤5,引入一种鲁棒项来补偿由执行-评价框架引入的神经网络逼近误差,设计基于安全强化学习的鲁棒近似最优控制器并分析稳定性。
由于神经网络逼近误差ε
其中,k
则整个控制输入为
u
将(37)应用到系统(6)中,那么可得到
定理2:考虑系统(6),控制输入(37),评价网络和执行网络的权值更新律分别由(13)和(18)表示。选取执行网络初始权值,建立初始容许控制。之后,通过提出的在执行-评价框架下的安全强化学习算法解决问题2,使得存在集合
证明:考虑定理1中相同的李雅普诺夫函数,并对其求偏导,可得
选取定理1中的α
/>
对上式两边积分,可得
因为(41)式的右边是有限的,利用Barbalat引理,我们得到
接下来我们将证明当t→∞时,||u
当t→∞时,||z||→0,||u
其中,δ
本发明针对高超声速飞行器的全状态约束问题,提出一种基于安全强化学习的高超声速飞行器最优控制方法,主要有益效果在于:
1、这是一种基于计算智能的在线学习控制方案,将学习和适应能力融合到飞行控制器中;
2、该方法可以在保证系统的平衡点是渐近稳定的同时,能不违反设定的全状态的约束范围;
3、该方法设计的控制器所产生的控制输入能在小范围内接近最优控制输入。
附图说明
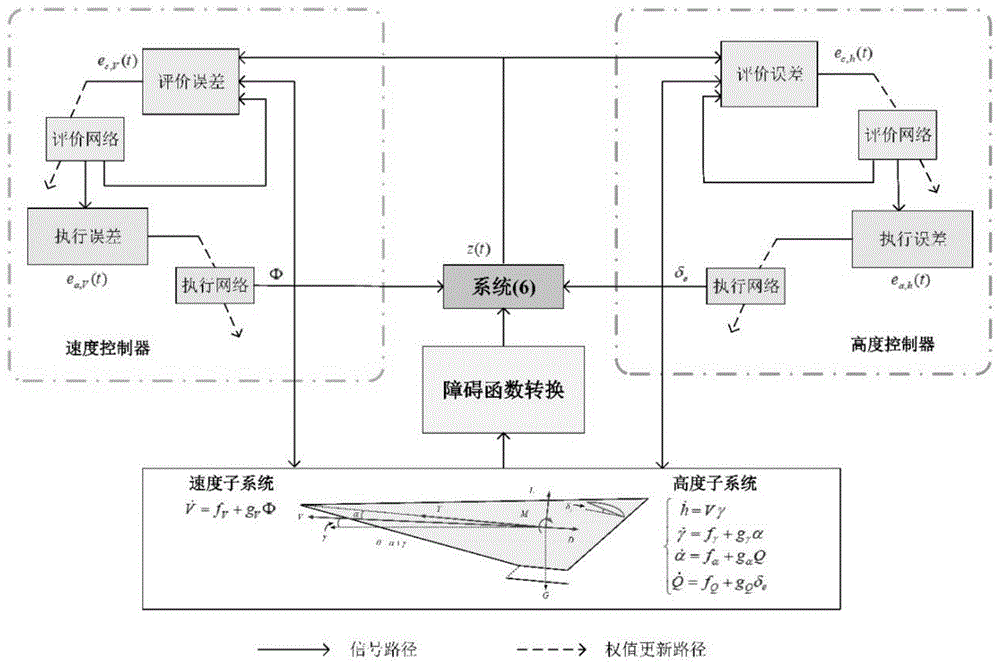
图1是基于安全强化学习的高超声速飞行器最优控制方法的主流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述。
如图1所示,一种基于安全强化学习的高超声速飞行器最优控制方法,首先,建立高超声速飞行器纵向动力学模型,并化简为一般的仿射非线性系统模型。其次,提出了一种基于障碍函数的系统变换,将全状态安全约束问题转化为无约束优化问题。然后,采用安全强化学习算法在执行-评价框架下设计近似最优控制器。最后,引入了一种鲁棒项来补偿由执行-评价框架引入的神经网络逼近误差,设计基于安全强化学习的鲁棒近似最优控制器。同时,利用李雅普诺夫技术对闭环系统进行了稳定性分析,证明基于安全强化学习的鲁棒近似最优控制器能够保证平衡点的渐近稳定,以及其产生的控制输入在小范围内接近于最优控制输入。
所述方法包括如下具体步骤:
步骤1,建立高超声速飞行器纵向动力学模型。
建立高超声速飞行器纵向动力学模型为:
其中,V,h,γ,α,Q分别表示飞行器的速度,高度,航迹角,攻角以及俯仰角速度,m为飞行器质量,I
其中,
其中,Φ,δ
步骤2,将高超声速飞行器纵向动力学模型化简为一般的仿射非线性系统模型。
将高超声速飞行器的纵向动力学模型分解为速度子系统与高度子系统,并进一步化简为一般的仿射非线性系统模型。
将速度子系统化简为:
其中,
其中,Δ
将高度子系统化简为:
其中,
其中,Δ
不失一般性,速度子系统和高度子系统可以归纳为
其中,对于速度子系统,x=x
对于高度子系统,x=[x
f(x)=[f
g(x)=[g
步骤3,提出一种基于障碍函数的系统变换,将全状态安全约束问题转化为无约束优化问题。
将高超声速飞行器纵向动力学的全状态约束在安全区域内,即具有全状态约束的高超声速飞行器的安全控制问题。描述如下:
问题1(具有全状态约束的安全控制问题):
考虑系统(3),找到控制策略u,对于每个x(0),在状态约束x
最小化,其中a
在此基础上,提出了基于障碍函数的系统变换,将给出的具有非对称的全状态约束的安全控制问题转化为稳定性问题,具体描述如下:
定义1(障碍函数):定义在(a,b)上的函数
其中,a和b是满足a<0<b的两个常数。此外,障碍函数在区间(a,b)上是可逆的,即
并有
考虑系统(3),定义基于障碍函数的状态转换如下:
那么,
根据定义1,下式成立
其中,
因此,变换后的变量z=[z
/>
其中,F(z)=[F
假设1:系统(6)满足:
1)F(z)是李普希兹的,F(0)=0,对z∈Ω
2)G(z)在Ω
3)在紧集Ω
在上文中,我们引入障碍函数,将系统(3)转化为等价系统(6)。下面,我们引入一个新的问题,以解决问题1的全状态约束。
问题2(最优控制问题):找到控制策略u使得代价函数
最小化,其中r(z,u)=Q(z)+u
给定一个可容许控制策略u,定义哈密尔顿量为
其中,
然后,对代价函数V(z)求导得到贝尔曼方程为
考虑最优代价函数,表示为
根据最优的必要条件
可得最优控制策略u
假设2:对于可容许控制策略u,非线性李雅普诺夫方程(8)具有局部光滑解
具有全状态约束的问题1和无约束最优问题2等价的条件由以下引理给出。
引理1:若假设1和假设2成立,并且控制策略u
1)只要系统(3)的初始状态x
2)若函数Γ(x)和Q(z)满足Γ(x)=Q(z),代价函数(4)和(7)等价。
证明:
1)由假设1和假设2可知存在一个正定的连续可微的最优代价函数V
x
因此,给定控制策略u
2)考虑基于障碍函数的状态转换(5),假设x
J(x(0),u)=V(z(0),u).。
步骤4,采用安全强化学习算法在执行-评价框架下设计近似最优控制器。
通过应用评价网络和执行网络实现在线安全强化学习算法设计近似最优控制器。
首先,评价网络:
求解哈密尔顿-雅可比-贝尔曼方程的最初步骤是通过采用如下一个评价网络局部逼近最优代价函数:
其中,
价值函数V
其中,
其中,σ是N维向量表示为
贝尔曼方程残差可表示为
根据代价函数梯度近似(9)可以看出,贝尔曼近似误差ε
最优值函数V
然后,对于一个给定的控制策略u,哈密尔顿量近似误差描述为
定义评价网络的权重估计误差为
为了使得当
其中,α
其次,执行网络:
由于最优控制策略由最优代价函数梯度
利用具有自适应评价网络权值
为了保证李雅普诺夫意义上的稳定性,控制策略用如下执行网络来表示
其中,
执行网络学习规则由下面的误差决定
执行网络的目标是使下列目标函数最小化
利用梯度下降算法,可以得到执行网络的权值更新律为
定义执行网络的权值估计误差为
/>
稳定性分析:
假设3:以下结论在紧集Ω
1)未知的评价网络理想权值
2)评价网络和执行网络的近似误差有上界,即||ε
3)评价网络和执行网络的激活函数有上界,即||φ
4)评价网络和执行网络的近似误差梯度和激活函数梯度有上界,即
5)残差有上界,即||ε||
定理1:考虑系统(6),控制输入(17),评价网络和执行网络的权值更新律分别由(13)和(18)表示。选取执行网络初始权值,建立初始容许控制。之后,通过提出的在执行-评价框架下的安全强化学习算法解决问题2使得存在集合
证明:考虑下面的李雅普诺夫函数
V(t)=V
其中,
对V
根据(16),(20)式可重写为
根据贝尔曼方程,可得
将(22)代入(21),可得
根据假设3,有
应用杨氏不等式,可得
/>
那么,
对V
定义
对V
根据(18)得到,
应用杨氏不等式,得到
进而,进一步得到
最后,结合(27),(29)和(30)可得
其中,
因此,
并且有下列不等式成立
/>
因此,状态z和权值估计误差
接下来,我们将证明当t→∞时,||u
当t→∞时,(34)式有上界为||u
步骤5,引入一种鲁棒项来补偿由执行-评价框架引入的神经网络逼近误差,设计基于安全强化学习的鲁棒近似最优控制器并分析稳定性。
由于神经网络逼近误差ε
其中,k
则整个控制输入为
u
将(37)应用到系统(6)中,那么可得到
定理2:考虑系统(6),控制输入(37),评价网络和执行网络的权值更新律分别由(13)和(18)表示。选取执行网络初始权值,建立初始容许控制。之后,通过提出的在执行-评价框架下的安全强化学习算法解决问题2,使得存在集合
证明:考虑定理1中相同的李雅普诺夫函数,并对其求偏导,可得
选取定理1中的α
对上式两边积分,可得
因为(41)式的右边是有限的,利用Barbalat引理,我们得到
接下来我们将证明当t→∞时,||u
当t→∞时,||z||→0,||u
其中,δ
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于深度强化学习的高超声速飞行器规避制导方法
- 一种基于强化学习的高超声速飞行器轨迹规划方法