一种基于地质预训练模型的命名实体识别方法及系统
文献发布时间:2024-01-17 01:24:51
技术领域
本发明涉及地质文本识别领域,尤其涉及一种基于地质预训练模型的命名实体识别方法及系统。
背景技术
随着数据驱动创新发展的不断深入,对持续暴增的海量文本数据进行知识挖掘与利用更加迫切与重要。命名实体识别(NER)是自然语言处理(NLP)重要的任务之一,其目的是从文本中对实体进行识别与分类。在地质领域的NER中,需要识别的实体包括矿物、岩石、地层、地质构造、地质年代等。预训练语言模型(PLMs)是高效精准识别命名实体的重要基础。利用预训练语言模型能够将复杂的文本知识准确完整地映射到向量空间,得到富含语义信息的表征,为下游模型(比如卷积神经网络)的特征学习提供向量支撑。
NER目前的实现方法可以总结为基于规则、传统机器学习、深度学习三类方法。基于规则的方法因依赖的规则需要大量的领域知识以及人工导致效率低、可拓展性差。基于机器学习的方法因需要大量的人工标注、泛化能力弱等问题导致整体性能不佳。而基于PLMS的深度学习方法,是当前主流的方向。
但是下游模型(如BiLSTM-CRF)进行特征学习的重要基础是表征向量中语义丰富。这一点对于垂直领域NER至关重要。因此在很多垂直领域针对这一问题训练了相应的领域预训练模型,比如生物医学领域的BioBERT,临床医学领域的ClinicalBERT,科学领域的SCIBERT,在金融领域的FinBERT,地理领域的GeoBERT。
此外,预训练模型表征能力的强弱很大程度决定于在预训练阶段该模型学习到的知识。上述的领域预训练模型融入的是语句文本中非结构化知识,而Yu等提出的Jaket模型以及Zhang等提出的SMedBERT融入的是知识图谱,促进了预训练模型的发展。但预训练模型在进行文本表征的时所需的知识是全方面的,包括了汉字的字形、读音特征、文本的语义特征、以及知识库中的结构化知识。而现有的模型并没有考虑到汉字特征对于文本识别的影响,导致文本识别的精确度不高。
发明内容
为解决上述技术问题,本发明提供一种基于地质预训练模型的命名实体识别方法,包括步骤:
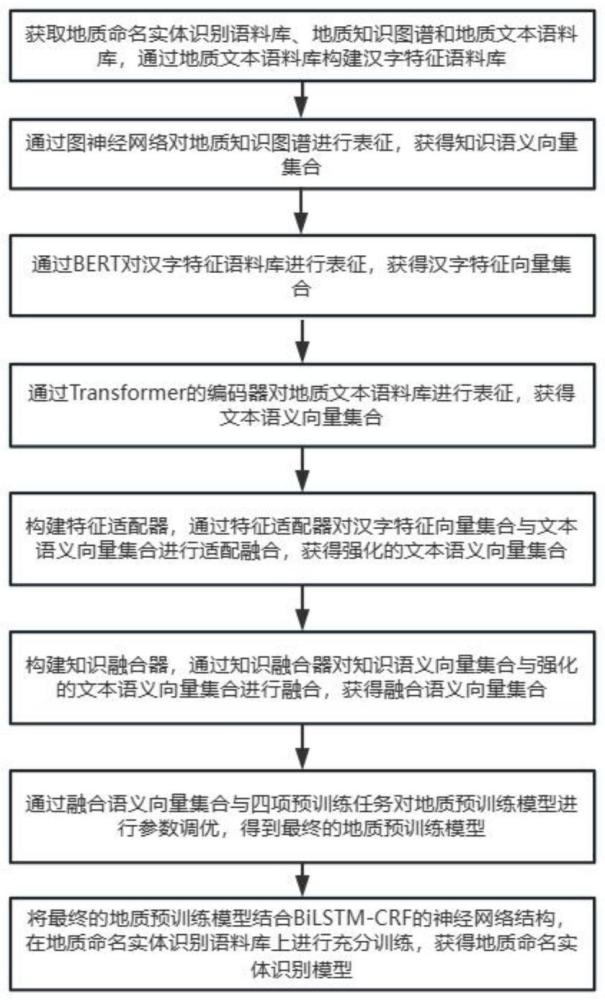
S1:获取地质命名实体识别语料库、地质知识图谱和地质文本语料库,通过地质文本语料库构建汉字特征语料库;
S2:通过图神经网络对地质知识图谱进行表征,获得知识语义向量集合;
S3:通过BERT对汉字特征语料库进行表征,获得汉字特征向量集合;
S4:通过Transformer的编码器对地质文本语料库进行表征,获得文本语义向量集合;
S5:构建特征适配器,通过特征适配器对汉字特征向量集合与文本语义向量集合进行适配融合,获得强化的文本语义向量集合;
S6:构建知识融合器,通过知识融合器对知识语义向量集合与强化的文本语义向量集合进行融合,获得融合语义向量集合;
S7:通过融合语义向量集合与四项预训练任务对地质预训练模型进行参数调优,得到最终的地质预训练模型;
S8:将最终的地质预训练模型结合BiLSTM-CRF的神经网络结构,在地质命名实体识别语料库上进行充分训练,获得地质命名实体识别模型。
优选的,所述汉字特征向量集合中的汉字特征向量包括:拼音特征向量、偏旁特征向量和笔画特征向量。
优选的,步骤S5具体为:
S51:将第α个汉字的文本语义向量记为A
P
B
其中,α为汉字的编号,β为笔画的编号,m为最大笔画数量,P
S52:将文本语义向量分别与拼音特征向量P
S53:计算获得拼音特征向量P
S54:通过V
S55:将H
G
其中,G
优选的,拼音特征参数V
V
V
其中,W
优选的,相关性M
其中,V
优选的,步骤S6具体为:
S61:强化的文本语义向量记为G
S62:计算获得G
其中,U
S63:引入标识向量
其中,G
通过注意力机制计算获得G
其中,
S64:通过
S65:通过
S66:通过N
优选的,所述四项预训练任务包括:掩码预测模型训练、下一句预测训练、实体分类训练和关系预测训练。
一种基于地质预训练模型的命名实体识别系统,包括:
语料库构建模块,用于获取地质命名实体识别语料库、地质知识图谱和地质文本语料库,通过地质文本语料库构建汉字特征语料库;
知识语义向量获取模块,用于通过图神经网络对地质知识图谱进行表征,获得知识语义向量集合;
汉字特征向量获取模块,用于通过BERT对汉字特征语料库进行表征,获得汉字特征向量集合;
文本语义向量获取模块,用于通过Transformer的编码器对地质文本语料库进行表征,获得文本语义向量集合;
文本语义向量强化模块,用于构建特征适配器,通过特征适配器对汉字特征向量集合与文本语义向量集合进行适配融合,获得强化的文本语义向量集合;
向量融合模块,用于构建知识融合器,通过知识融合器对知识语义向量集合与强化的文本语义向量集合进行融合,获得融合语义向量集合;
参数调优模块,用于通过融合语义向量集合与四项预训练任务对地质预训练模型进行参数调优,得到最终的地质预训练模型;
识别模型训练模块,用于将最终的地质预训练模型结合BiLSTM-CRF的神经网络结构,在地质命名实体识别语料库上进行充分训练,获得地质命名实体识别模型。
一种存储设备,所述存储设备存储指令及数据用于实现所述的基于地质预训练模型的命名实体识别方法。
一种基于地质预训练模型的命名实体识别设备,包括:处理器及存储设备;所述处理器加载并执行存储设备中的指令及数据用于实现所述的基于地质预训练模型的命名实体识别方法。
本发明具有以下有益效果:
1、本发明提出了一种特征适配器,将汉字特征在预训练阶段融入地质预训练模型,通过汉字特征辅助模型对语义的学习,提升了模型的训练效果;
2、本发明提出了一种知识融合器,将地质知识图谱融入到地质预训练模型中,从而对地质预训练模型进行知识增强,提高了模型的表征能力;
3、本发明将最终的地质预训练模型与BiLSTM-CRF网络进行结合,进一步提高了地质文本识别的精确度。
附图说明
图1为本发明实施例方法流程图;
图2为地质命名实体识别模型结构图;
本发明的实现、功能特点及优点将结合实施例、参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
参照图1,本发明提供一种基于地质预训练模型的命名实体识别方法,包括步骤:
S1:获取地质命名实体识别语料库、地质知识图谱和地质文本语料库,通过地质文本语料库构建汉字特征语料库;
S2:通过图神经网络对地质知识图谱进行表征,获得知识语义向量集合;
S3:通过BERT对汉字特征语料库进行表征,获得汉字特征向量集合;
S4:通过Transformer的编码器对地质文本语料库进行表征,获得文本语义向量集合;
S5:构建特征适配器,通过特征适配器对汉字特征向量集合与文本语义向量集合进行适配融合,获得强化的文本语义向量集合;
S6:构建知识融合器,通过知识融合器对知识语义向量集合与强化的文本语义向量集合进行融合,获得融合语义向量集合;
S7:通过融合语义向量集合与四项预训练任务对地质预训练模型进行参数调优,得到最终的地质预训练模型;
S8:将最终的地质预训练模型结合BiLSTM-CRF的神经网络结构,在地质命名实体识别语料库上进行充分训练,获得地质命名实体识别模型。
进一步的,步骤S1中的地质文本语料库有以下三项来源:(1)中文地质报告。地质报告中富含矿物、岩石、地质构造等元素在性质、分布、关系各方面描述性文本,且内容集中。因此,本发明收集大量地质报告,设计提取程序自动提取。(2)地质期刊论文摘要。本发明搜集34种地质期刊论文摘要。这部分内容的特点在于文本中干扰模型训练的元素较少,提取后不需要复杂的数据清洗便可以直接用于训练。(3)地学学位论文摘要。地学学位论文摘要也被包含在本发明的语料库中。本发明搜集161所大学和科研机构的地质学学位论文的摘要,进一步扩充语料库。在提取文本的过程中,本发明忽略表格信息、图像信息和其他非地质或非语句的内容。为保证语句的通顺度以及地质学内容的较高权重,本发明删除语料中不通顺的语句,并将文本中的序号、标记、数值等特殊符号统一转成了字母N。通过上述预处理,构建高质量地质文本语料库。
进一步的,地质文本具备包含地质专业术语与通用领域的特点,而BERT在通用领域已经体现出了其优越性。因此,本发明通过BERT来对地质预训练模型进行参数初始化,从而在通用领域训练得到的参数基础上继续融入地质特征与知识,全方面有效加强地质预训练模型对地质文本的表征能力。
进一步的,所述汉字特征向量集合中的汉字特征向量包括:拼音特征向量、偏旁特征向量和笔画特征向量。
具体的,基于地质文本语料库,可构建与之对应的汉字特征语料库。汉字所包含的特征分为三个部分:拼音、偏旁、笔画。充分结合汉字特征能够有效提升模型性能。比如汉字“士”和“土”结构相似,结合拼音能够辅助模型学习汉字正确的语义。同时,较多汉字为象形文字,比如“火”、“山”,将汉字的结构特征融入地质预训练模型能够增强地质预训练模型的表征能力。
进一步的,针对汉字多项特征,本发明提出一种特征适配器,加入BERT各层Transformer的编码器之间,在训练过程中完成语义与汉字特征的适配与融合,如步骤S5所示;
步骤S5具体为:
S51:将第α个汉字的文本语义向量记为A
P
B
其中,α为汉字的编号,β为笔画的编号,m为最大笔画数量,P
S52:将文本语义向量分别与拼音特征向量P
S53:计算获得拼音特征向量P
S54:通过V
S55:将H
G
其中,G
进一步的,在特征适配器中,为分别将拼音特征向量和笔画特征向量与语义向量对齐,需要对拼音特征向量和笔画特征向量进行非线性变换;
拼音特征参数V
V
V
其中,W
进一步的,因各个特征向量对汉字的贡献度不同,引入注意力机制计算各特征向量对于汉字的相关性;
相关性M
其中,V
进一步的,为有效融合地质知识图谱的知识语义向量与基于汉字特征强化的文本语义向量,本发明设计了一种知识融合器进行融合操作,如步骤S6所示;
步骤S6具体为:
S61:强化的文本语义向量记为G
S62:计算获得G
其中,U
S63:引入标识向量
其中,G
通过注意力机制计算获得G
其中,
S64:通过
S65:通过
S66:通过N
进一步的,所述四项预训练任务包括:掩码预测模型训练、下一句预测训练、实体分类训练和关系预测训练。
具体的,在得到富含多方面特征与知识的融合语义向量集合后,通过融合语义向量集合对地质预训练模型依次完成掩码预测模型(MLM)训练、下一句预测(NSP)训练、实体分类训练和关系预测训练,分别从字、句、实体、关系四个层面进行模型预训练,得到最终的地质预训练模型(GeoBERT-KE)。
进一步的,最终的地质预训练模型(GeoBERT-KE)相比较于通用领域预训练模型在地质文本的表征方面,能够有效减小语义丢失,语义表征更加准确,语义信息更加丰富;为了使得文本识别更加精确,本发明构建了以最终的地质预训练模型结合BiLSTM-CRF的神经网络结构,即GeoBERT-KE-BiLSTM-CRF,如图2所示;
采用GeoBERT-KE将输入到系统的文本的语义映射到高维空间向量,完成文本编码;BiLSTM将文本编码结果作为输入,学习观测序列上的依赖关系,最后再用CRF习得状态序列的关系并得到答案;BiLSTM由一个正向和一个反向长短时记忆网络(LSTM)组成,该结构能够结合地质文本上下文学习地质实体的特征,同时,能够输出对于每个标签的分数;将该分数输入到CRF中,利用CRF实现向最终的预测标签添加一些在训练中学习到的约束,以确保预测结果的有效性;
通过地质命名实体识别语料库对该神经网络结构进行充分训练,得到地质命名实体识别模型,通过地质命名实体识别模型的预测结果对文本中的实体进行标注,以可视化方式呈现识别结果,并对结果进行保存。
本发明提供一种基于地质预训练模型的命名实体识别系统,包括:
语料库构建模块,用于获取地质命名实体识别语料库、地质知识图谱和地质文本语料库,通过地质文本语料库构建汉字特征语料库;
知识语义向量获取模块,用于通过图神经网络对地质知识图谱进行表征,获得知识语义向量集合;
汉字特征向量获取模块,用于通过BERT对汉字特征语料库进行表征,获得汉字特征向量集合;
文本语义向量获取模块,用于通过Transformer的编码器对地质文本语料库进行表征,获得文本语义向量集合;
文本语义向量强化模块,用于构建特征适配器,通过特征适配器对汉字特征向量集合与文本语义向量集合进行适配融合,获得强化的文本语义向量集合;
向量融合模块,用于构建知识融合器,通过知识融合器对知识语义向量集合与强化的文本语义向量集合进行融合,获得融合语义向量集合;
参数调优模块,用于通过融合语义向量集合与四项预训练任务对地质预训练模型进行参数调优,得到最终的地质预训练模型;
识别模型训练模块,用于将最终的地质预训练模型结合BiLSTM-CRF的神经网络结构,在地质命名实体识别语料库上进行充分训练,获得地质命名实体识别模型。
本发明提供一种存储设备,所述存储设备存储指令及数据用于实现所述的基于地质预训练模型的命名实体识别方法。
本发明提供一种基于地质预训练模型的命名实体识别设备,包括:处理器及存储设备;所述处理器加载并执行存储设备中的指令及数据用于实现所述的基于地质预训练模型的命名实体识别方法。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 命名实体识别模型训练方法、命名实体识别方法及装置
- 一种基于Lattice LSTM和语言模型的命名实体识别方法
- 一种基于预训练模型和递进式卷积网络的命名实体识别方法
- 一种基于生物医学领域预训练模型的命名实体识别方法