片上网络处理系统
文献发布时间:2024-04-18 19:58:30
技术领域
本发明总体上涉及计算机科学和硬件架构,并且更具体地说涉及新颖的片上网络(Network on Chip,NoC)处理系统。
背景技术
除了其他方面,本发明涉及新颖的片上网络(NoC)处理系统,所述系统可能尤其可用于海量信号处理、图像和/或视频处理应用、雷达应用、神经网络实施方案和/或其它技术应用。
在计算机科学和工程中,计算机架构定义了包括处理器能力和存储器的计算机系统的功能性、组织和实施。
通常,处理器是响应和处理驱动计算机系统的指令的逻辑电路系统。处理器连同存储器一起被视为计算机中的主要且最关键的集成电路(IC)芯片,因为它会执行大多数基本算术、逻辑和I/O操作,以及为在计算机系统中运行的其它芯片和部件分配命令。
在下文中,计算机系统或处理器系统将与数据处理系统的表达可互换地使用,因为任何计算机系统的主要总体目的和应用是执行数据处理。
响应于集成电路制造技术的密度和效率的指数级增长所产生的商业机会,通常存在对计算机系统的改进的持续需求。
发明内容
一般目标是提供在计算机科学中和用于数据处理系统的改进。
特定目标是提供高效的片上网络(NoC)处理系统。
根据第一方面,提供被配置成执行数据处理的片上网络(NoC)处理系统。NoC处理系统被配置成用于与可连接到处理系统的控制处理器互连。
NoC处理系统包括经组织成多个集群的多个微码可编程处理元件(PE),每一集群包括大量可编程PE,每一微码可编程处理元件的功能性由与处理元件相关联的微程序存储器中的内部微码定义。
可编程处理元件的多个集群布置于片上网络(NoC)上,片上网络具有根和多个外围节点,其中处理元件的多个集群布置在片上网络的外围节点处,且片上网络可在根处连接到控制处理器。
每一集群还包括由集群内的大量可编程处理元件共享的集群控制器(CC)和相关联集群存储器(CM)。每一集群的集群存储器被配置成在可连接控制处理器的控制下存储至少从片上或片外数据源接收的微码,且集群内的每一处理元件被配置成从相关联集群存储器请求微码。
每一集群的集群控制器被配置成响应于来自相应处理元件的请求而使微码能够从相关联集群存储器传送到集群内处理元件的至少一子集。
以此方式,获得针对在片上网络上实施而设计的高效处理系统。举例来说,所提出的技术提供具有分布式处理的基于微码的片上网络处理系统,并且更具体来说能够实现高效微码分发。
换句话说,所提出的技术提供具有处理元件(PE)的集群的基于微码的片上网络数据处理系统,其中每一PE的功能性由相关联微程序存储器中的内部微码定义,且每一集群具有集群控制器和相关联集群存储器,并且集群存储器被配置成存储至少微码,且每一PE被配置成请求微码,且集群控制器随后响应于所述请求而使微码从CM传送到PE。
应当理解,所提出的技术可以促进大量分布式处理元件的可编程功能性的反复(如果需要)的快速改变,特别是通过将微码分发到基于树的片上网络结构的多个集群的集群存储器,其中每一集群的每一处理元件可以自身在需要时从相关联集群存储器请求微码。
举例来说,如经由片上网络由控制处理器指示或发起的每一处理元件可以被配置成通过向对应集群的集群控制器请求(来自处理元件)从相关联集群存储器取回微码。
可替换地,处理系统可以在两个独立阶段中实现微码的分发:与集群存储器在可连接控制处理器的控制下存储从片上或片外数据源接收的微码相关的初始分发阶段,以及由每一集群中的单独处理元件控制或至少发起的又一基于请求的分发阶段。
所提出的技术也可以提供关于功率消耗、面积效率、处理量、资源利用率、处理速度和/或代码密度的优点。
所提出的NoC处理系统一般可适用且可用于广泛多种技术应用中的数据处理。
当阅读下文的具体实施方式时将理解本发明的其它优点。
附图说明
通过参见与附图结合在一起的以下描述,可以最好地理解本发明以及其另外的目的和优点,其中:
图1A是示出根据实施例的包括加速器的系统的实例的示意图。
图1B是示出根据实施例的包括加速器的系统的另一实例的示意图。
图1C是示出根据实施例的包括加速器的系统的又一实例的示意图。
图1D是示出根据实施例的基于若干加速器的分层树网络的系统的实例的示意图。
图2是使用神经网络创建经训练模型的实例的示意性图示。
图3是使用编译器用于编译模型的实例的示意性图示。
图4是将模型加载到加速器中的实例的示意性图示。
图5是基于输入数据运行或执行加速器中的模型以产生所得输出数据的实例的示意性图示。
图6A是示出NoC处理系统的实例的示意图,所述处理系统被配置成用于与可连接到所述处理系统的控制处理器互连。
图6B是数据处理系统和/或加速器系统的非限制性实例的示意性图
图7是非限制性实例NoC结构的示意性图示。
图8是PE集群的组织的非限制性实例的示意性图示。
图9是包括根部分和NoC的总体系统架构的非限制性实例的示意性图示。
图10是包括集群控制器和集群存储器以及接口的PE集群的非限制性实例的示意性图示。
图11是示出PE阵列及其根系统的一半的实例的示意性布局草图,所述根系统包括RM、GPP和接口。
图12是示出包括集群存储器(CM)的集群控制器(CC)的实例的示意图。
图13是示出相关数据转换的实例的示意图。
图14是示出PE请求仲裁器的实例的示意图。
图15A是示出集群的物理布局的实例的示意性布局草图。
图15B是示出根据实施例的被实施为四个双核模块的8芯模块的电路组件的实例的示意图。
图15C是示出根据实施例的双核模块的实例的示意图。
图16A是示出分发网络的相关部分的实例的示意图。
图16B是示出收集网络的相关部分的实例的示意图。
图16C是示出具有PE对的系统的实例的示意性框图,并且还示出PE(核心)如何连接到集群控制器。
图16D是示出具有两个MAC块的PE核心的实例的示意性框图,专注于新的所谓的向量引擎,并且还有所使用地址计数器的细节。
图16E是示出PE核心的实例的示意性框图,同样专注于新的所谓向量引擎,在此具有四个MAC块。
图17A-D是示出针对每一MAC循环如何将新的一对字节从暂存器传送到MAC单元的实例的示意图。
图17E是示出从本地数据缓冲器读取MAC单元的乘法阶段的实例的示意图。
图18是示出PE对的实例的框图。
图19是示出根据实施例的计算机实施方案的实例的示意图。
图20是示出MAC资源中的一些的实例的示意图。
图21A-C是示出二维和三维CONV的实例的示意图:x/y平面中的重叠3x3范围。
图22是示出三个层的融合的实例的示意图。
图23A-B是示出具有一些众所周知的处理器的核(核心)设计的效率比较的示意图。
图24是示出IM3000处理器的实例的示意图。
图25是示出双核处理器系统的内部组织的实例的的示意图,专注于算术部分。
图26是示出总体双核系统(排除控制单元)的实例的示意图。
图27是示出集群存储器-PE连接的实例的示意图。
图28是示出划分成若干区的总体输入图像的实例的示意图。
图29是用于将传入图像的数据重新布置并分发以便由多个处理集群进行处理的方法的实例的示意性流程图。
图30是示出将传入图像重新布置并转置成经转置的输出数据以用于传送到集群的实例的示意性框图。
具体实施方式
在下文中,将结合实例实施例的说明性附图描述这些各种方面的非限制性实例。
当提及特定数量(例如,数据大小、元件数目、处理速度、时钟频率等等)时,这些数字/数量通常应当被解释为仅仅是希望从实际视点提供直观的技术理解的非限制性实例。
一般,数据处理架构或系统可以被视为硬件机器。举例来说,所述硬件机器可被称为数据流加速器或简称为加速器,例如,包括不同的处理器,如稍后将更详细地解释。有时,此类系统也被称作多核数据流机器。将描述和示出总体架构以及处理器的交互工作、数据流和用于通过系统以及相关联编译器和固件支持和/或控制此类数据流的配置的实例。
为了更好的理解,以用于此类硬件机器或加速器的一些实例应用的简要概述开始可能是有用的。
如所提到,加速器可以用于人工智能,例如用于卷积神经网络(CNN)的实施,而且用于海量数字信号处理,例如用于雷达应用,以及其它类型的数据流处理。
在雷达应用中,包括汽车雷达,雷达数据提取器可以从使用可每微秒执行数百万次乘法/加法运算的加速器系统获益。用于雷达数据提取器的原理也可以用于声纳和/或激光雷达。处理通常由快速傅立叶变换(FFT)主导,且可以包括测距FFT、多普勒FFT、恒定误警率(CFAR)滤波、方位角估计和/或仰角估计。
另一应用是用于大规模MIMO天线阵列的波束成形。去往/来自天线阵列元件的数字复值(“I/Q”)信号可以通过乘以复值“旋转因子”而相移。类似于通过透镜或棱镜的不同光路的不同时间延迟,通过正确选择的常数的这些相移可在不同方向上产生波束。通过添加具有不同相移集合的信号,若干波束可同时存在(叠加原理)。需要高频率的多次乘法,这适合于小处理器的阵列。
存在可用所提出的硬件加速器技术构建的广泛多种系统和/或装置,本文将给出其中的一些实例。
举例来说,本文可提到特定类型的存储器、接口、连接和/或其它电路,但应理解,所提出的技术一般并不限于此,而是一般可适用的。
图1A是例如USB盘的系统的实例的示意性图示,所述系统基本上包括加速器10和标准双倍数据速率(DDR)存储器电路的集成电路(IC)。
图1B是与图1A的系统类似但适合于视频和/或千兆位以太网(GbE)连接的系统的实例的示意性图示。举例来说,这可用于构建例如适合用于智能汽车传感器的紧凑系统,其具有海量信号处理和卷积神经网络并通过带时间戳的千兆位以太网进行通信。该系统应当还能够同时与海量信号处理(例如,基于FFT的信号处理)和神经网络技术配合作用。
图1C是具有DDR模块和加速器10的外围组件互连高速(PCIe)板的实例的示意性图示,例如经由主机计算机PCIe槽而具有图像输入/输出和额外存储。举例来说,这可以可用于病理图像分析的工作站,其中所述板还将进行JPEG2000解压缩并生成非常高分辨率标注的显示图像。例如,其可以具有其自身的到图像数据库的25G/100G以太网连接。
图1D是供用作数据中心或用于数据中心的高性能系统的实例的示意性图示,具有若干加速器IC 10的分层树网络。举例来说,在根处,该树可具有高带宽存储器(HBM)和/或通过融合以太网进行远程直接内存访问(RoCE)。
图2是使用神经网络例如CNN创建经训练模型的实例的示意性图示。举例来说,加速器可以用作用于神经网络训练的计算机外围设备,尽管其主要针对推理(其另一方面也可被视为神经网络训练循环的部分)。
图3是使用编译器用于编译模型的实例的示意性图示。例如,编译器可被视为计算机程序,其可作为服务提供;编译器即服务(Complier as aService,CaaS)。
图4是将模型加载到加速器的实例的示意性图示。例如,在加载其系统软件之后(包括抽象机),加速器可将目标代码加载到片上主存储器中且将模型参数文件加载到片外辅助存储器(例如,DDR或HBM)中。
图5是基于例如传感器数据作为输入在加速器中运行或执行模型以产生相关输出数据的实例的示意性图示。例如,输入数据可来自汽车摄像机或雷达,但可替代地数据源可以是例如用于癌症诊断的高分辨率病理图像。例如,高分辨率显示驱动可以低额外成本与加速器集成。
现将结合说明性实例描述所提出的与片上网络(NoC)处理系统相关的技术,并且接着更详细涉及与总体数据处理系统相关的各种实例。
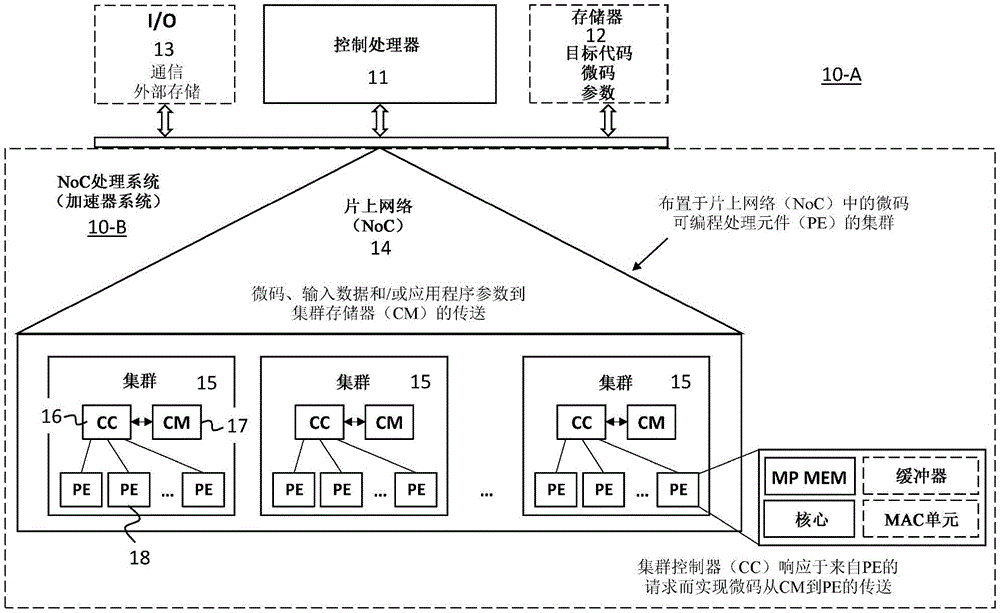
图6A是示出NoC处理系统的实例的示意图,所述处理系统被配置成用于与可连接到处理系统的控制处理器互连。
根据第一方面,提供有被配置成执行数据处理的片上网络(NoC)处理系统10-B。NoC处理系统10-B被配置成用于与可连接到处理系统10-B的控制处理器11互连。
NoC处理系统10-B包括组织成多个集群15的多个微码可编程处理元件(PE)18,每一集群15包括大量可编程PE 18,每一微码可编程处理元件18的功能性由与处理元件相关联的微程序存储器MP MEM中的内部微码定义。
可编程处理元件18的多个集群15布置于片上网络(NoC)14上,片上网络14具有根和多个外围节点,其中处理元件18的多个集群布置在片上网络14的外围节点处,并且片上网络14可在根处连接到控制处理器11。
每一集群15还包括由集群内的众多可编程处理元件18共享的集群控制器(CC)16和相关联集群存储器(CM)17。每一集群15的集群存储器17被配置成在可连接控制处理器11的控制下存储至少从片上或片外数据源接收的微码,并且集群15内的每一处理元件18被配置成从相关联集群存储器17请求微码。
每一集群15的集群控制器16被配置成实现响应于来自对应处理元件18的请求将微码从相关联集群存储器17传送到集群15内的处理元件18的至少一子集。
以此方式,获得设计用于在片上网络上实施的高效处理系统。举例来说,所提出的技术提供具有分布式处理的基于微码的片上网络处理系统,并且更具体来说实现高效微码分发。
举例来说,如经由片上网络由控制处理器指示或发起的每一处理元件可以被配置成通过向对应集群的集群控制器的请求(来自处理元件)从相关联集群存储器取回微码。
可替换地,处理系统可以在两个独立阶段中实现微码的分发:与集群存储器在可连接控制处理器的控制下存储从片上或片外数据源接收的微码相关的初始分发阶段,以及由每一集群中的单独处理元件控制或至少发起的又一基于请求的分发阶段。
不过,在两种情况下,每一处理元件被配置成通过向对应集群控制器的请求从相关联集群存储器取回微码,进而实现将微码从集群存储器传送到处理元件。
应当理解,控制处理器11不必然形成所要求的NoC处理系统10-B的部分。换句话说,NoC处理系统可以(但不必须)包括控制处理器,如稍后将举例说明。因此,所提出的技术涵盖具有或不具有控制处理器的NoC IP块。
换句话说,所提出的技术提供具有处理元件(PE)的集群的基于微码的片上网络处理系统,其中每一PE的功能性由相关联微程序存储器中的内部微码定义,并且每一集群具有集群控制器和相关联集群存储器,且集群存储器被配置成至少存储微码,并且每一PE被配置成请求微码,且集群控制器随后响应于所述请求而实现微码从CM向PE的传送。
在某种意义上,处理系统在两个阶段中实现微码的分发:与集群存储器在可连接控制处理器的控制下存储从片上或片外数据源接收的微码相关的初始阶段,以及由每一集群中的单独处理元件控制或至少发起的又一基于请求的阶段。
举例来说,系统可被设计成使得PE之间不存在直接连接,并且集群之间不存在直接连接。
如所解释,系统中的传送可以是受控制处理器控制的集群存储器与根之间的传送,或由PE请求和发起的PE与其相应集群存储器之间的传送。在某种意义上,CC服务于PE,而不是控制它们。
举例来说,总体系统中的编程控制一方面集中于可在根处连接的控制处理器,另一方面集中于微编程的PE。
可连接控制处理器通常控制总体数据流应用程序的数据处理,包括控制根与集群之间的信息传送。
系统中的信息的分发,例如微码但任选地还有待处理的输入数据、系数、中间数据块的存储和结果的输出,可被视为部分地由根处的可连接控制处理器控制,并且部分地由每一集群中的单独处理元件控制或至少发起。
在特定实例中,每一处理元件18具有被配置成从集群存储器17接收微码的来自存储器的数据的寄存器,微码可经由来自存储器的数据的寄存器传送到处理元件18的微程序存储器。
例如,每一处理元件18可以被配置成将微码从来自存储器的数据的寄存器传送到处理元件18的微程序存储器。
有利的是,NoC处理系统10-B可以例如被配置成用于使得微码的至少部分能够同时广播到集群15的至少一子集的集群存储器17。
例如,NoC处理系统10-B可以被配置成由所述可连接控制处理器11控制,所述可连接控制处理器被允许控制微码、输入数据和/或用于数据流应用程序的应用程序参数传送到集群存储器17中的选定位置,以及来自和去往集群存储器17的中间数据的传送和/或由集群存储器17所得结果的传送。可选地,至少选定集群15的处理元件18可以被配置成如例如经由集群控制器16由控制处理器11指示或发起而使用它们已接收到的微码和应用程序参数来开始输入数据的处理。
举例来说,每一处理元件18可以被配置成执行其微程序存储器中的微码以控制将由处理元件执行的数据流应用程序的算法/算术工作的专用部分的执行。
举例来说,NoC处理系统10-B可以被配置成用于使得控制处理器11能够控制将与处理元件18执行算法/算术工作同时执行的在根与集群15之间的至少部分的数据传送。
在一特定实例中,每一处理元件18可以包括一个或多个乘累加(MAC)单元以用于执行MAC运算,并且MAC运算的执行由本地微码和/或源自与处理元件18相关联的微程序存储器和/或另外由微程序存储器中的微码的执行产生的对应控制位控制。
可选地,NoC处理系统10-B包括开关块,用于连接到片上网络14的数据通道,通向和来自布置于片上网络14的外围节点处的可编程处理元件18的集群。NoC处理系统10-B可以包括NoC寄存器,用于临时保存经由开关块待分发到处理元件18的集群15的数据,和/或用于保存来自处理元件的集群的数据。
在后一种情况,这可用于将数据从一个集群传回到一个或多个其它集群(而不需要集群之间的任何直接连接),或能够将数据传送到板载存储器以用于临时存储和稍后传送回到一个或多个集群,或用于将数据转发到外部存储器或主机计算机。
举例来说,开关块可以包括大量开关和控制逻辑,所述控制逻辑用于控制所述大量开关以支持通过片上网络14的数据通道的一组不同传送模式。
片上网络14可以是连接开关块与集群的星形网络,具有到每一集群的点对点通道。
在特定实例中,NoC处理系统10-B还包括控制网络,用于传送与将通过片上网络14执行的数据传送相关的命令和/或状态信息和/或用于控制集群控制器16。用于发起处理元件(18)取回和/或执行微码的命令或指令可以经由控制网络传送。
举例来说,如由通过片上网络14来自控制处理器11的命令控制,集群控制器16可以被配置成保持集群的处理元件18处于复位或保持/等待模式直到用于处理元件18的微码已存储于相关联集群存储器17中为止,并且接着激活处理元件18,其中每一处理元件18当在复位或保持/等待模式之后启动时被配置成输出对微码的请求到集群控制器16。
举例来说,起初处理元件18处于复位或保持/等待模式,且控制处理器11确保传送微码以用于存储于集群存储器17中。在特定实例中,控制处理器11例如通过NoC 14中的控制网络将命令发送到集群控制器16,进而致使集群控制器激活对应集群15的处理元件18并且实现处理元件18的计时。当例如由于系统启动或由于微编程的改变,处理元件18在复位或保持/等待模式之后启动时,所述处理元件输出对微码的请求和/或数据到集群控制器16。
举例来说,控制处理器可以随后通过NoC 14中的控制网络命令集群使用它们已接收到的微码和输入数据和参数开始处理。
如稍后将举例说明,集群控制器16可以例如包括多个接口,包括:与片上网络14的NoC接口16-1,与集群内的处理元件18的PE接口16-2,以及与集群的集群存储器17的CM接口16-3(参见图10)。
如所提到,可连接控制处理器11可以是与NoC 14集成于相同芯片上的片上处理器。可替换地,可连接控制处理器11可以是可连接以用于控制NoC 14的外部处理器。
在后一种情况,外部处理器可以是计算机或服务器处理器,其中控制处理器11的至少部分的功能性由计算机程序在由计算机或服务器处理器执行时执行。
控制处理器11可以是被配置成执行本文所描述的任务的任何合适的处理器。
在特定实施例中,可连接控制处理器11可以被配置成执行目标代码,其表示由编译器创建的数据流模型,用于使得控制处理器11能够控制以预定义次序将微码、输入数据和数据流应用程序的应用程序参数传送到集群15的处理元件18用于执行,并且接收和递送最终结果。
举例来说,数据流模型可以是卷积神经网络(CNN)数据流模型和/或数字信号处理(DSP)数据流模型,包括逐层执行的多个数据处理层。
举例来说,集群控制器16可以被配置成从集群内的多个处理元件18的至少一子集接收被称为集群广播请求的请求,用于将微码和/或数据从集群存储器17广播到多个处理元件的所述至少一子集。集群控制器16可以被配置成仅在已经从参与广播的多个处理元件的所述至少一子集的所有处理元件18接收到广播请求之后,响应于所接收到的集群广播请求而发起微码和/或数据的广播。
举例来说,片上网络14可以被组织为星形网络或胖树网络,具有作为中心中枢的根,以及到达多个外围节点的分支或分支的层次结构,所述多个外围节点也被称作叶节点,其中设置处理元件18的多个集群15。
应当理解,所提出的技术可以促进大量分布式处理元件的可编程功能性的反复的快速改变,特别是通过将微码分发到基于树的片上网络结构的多个集群的集群存储器,其中每一集群的每一处理元件可以自身在需要时从相关联集群存储器请求微码。每一处理元件可随后借助于所接收到的微码执行其自身的数据处理,包括数据传送和功能操作。
如所指示,NoC处理系统10-B可以例如是加速器系统10;用于总体数据处理系统的10-B。
如图6A中进一步示出,控制处理器11可以具有对存储器12的访问。在特定实例中,可由控制处理器11访问的存储器12可以包括由编译器创建的目标代码,并且控制处理器11可以被配置成从存储器12访问目标代码且执行目标代码以用于控制数据流应用程序的数据处理,包括控制根与片上网络14的集群之间的数据传送。以此方式,控制处理器11可以被配置成当执行目标代码时控制以下各项到集群存储器17中的选定位置的传送:i)微码,ii)输入数据,以及ⅲ)用于数据流应用程序的应用程序参数,以及传送中间数据和/或来自集群存储器17的结果。
应当理解,控制处理器11(与其相关联存储器12)可以被视为可连接到NoC 14的中心中枢或根,即使控制处理器经由中间单元(例如一个或多个开关、总线和/或寄存器)可连接到NoC。
可由控制处理器11访问的存储器12可以是任何合适的存储器或存储器单元的集合。举例来说,存储器可以包括至少一个存储器单元,被实施为关于数据处理系统的外部存储器和/或集成存储器。存储器可以是板载的(例如,SRAM)、外部DRAM和/或其组合。存储器还可部分地通过ROM实施,其在IC实施中提供较快的启动且具有高面积效率。
通常,总体数据处理系统10-A还可包括互连控制处理器11、存储器12、片上网络14和/或一个或多个输入/输出(I/O)接口13的数据总线。
通常,在每一集群中,相关输入数据和应用程序参数在总体数据流应用程序需要时从相关联集群存储器17传送到处理元件18。
通常,根据微码和对应应用程序参数处理输入数据。应用程序参数连同微码一起影响和/或控制如何处理输入数据。
举例来说,总体数据处理系统10-A可以例如被配置成在系统启动时将目标代码与虚拟机一起加载到存储器中,其中数据处理系统被配置成在控制处理器11上运行虚拟机以用于执行目标代码。
在特定实例中,至少选定的集群15可以被配置成响应于来自可连接控制处理器11的命令而使用它们已接收到的微码和应用程序参数开始处理输入数据。
为了对某些方面的更深入理解,在下文中将结合多个非限制性实例描述所提出的技术。
图6B是加速器系统的非限制性实例的示意性图示,所述加速器系统包括在连接到例如根存储器12-1(例如,宽片上SRAM)和/或其它存储器单元等存储器的所谓的片上网络(NOC)14中的PE集群15,和控制处理器11,以及DDR接口13-1、PCIe接口13-2和高速以太网接口13-3。
图7是被组织为唯一配置星形网络(或胖树网络)的NoC结构的非限制性实例的示意性图示,具有在中间的根(中心中枢)和到达叶节点的分支(或分支层次结构)。
图8是PE集群的组织的非限制性实例的示意性图示。
图9是包括根部分和NoC的总体系统架构的非限制性实例的示意性图示。
图10是PE 18的集群15的非限制性实例的示意性图示,包括集群控制器16和集群存储器17以及接口16-1、16-2和16-3。
通常,大量数据将以极高的速度流过该加速器。其中不应当涉及经编程处理器核心,除了在高层级控制这些流外,即建立流,开始流,以及在错误的情况下重复流。举例来说,这可以通过片上通用(可编程或可微编程)处理器(GPP)完成。
通过片上网络(NoC)的流终止于许多集群存储器(CM)中,所述集群存储器又由可以被实施为处理器核心的许多处理元件(PE)共享。集群作为平铺块的规则阵列布置于IC芯片上。每一平铺块具有其自身的时钟;其无需与除了作为其时钟源的其自身的NoC连接之外的任何事物同步。在平铺块内部是多个双PE的块,所述多个双PE具有从进入集群的时钟信号产生的时钟信号且可使用两倍于NoC以及集群控制器和CM的时钟频率。
在电子器件且特别是同步数字电路中,时钟信号通常在高状态与低状态之间振荡,且像节拍器一样用于协调数字电路的动作。
大体来说,时钟信号由时钟发生器产生。虽然可以使用更复杂的布置,但最常见的时钟信号呈具有50%工作循环的方波的形式,通常具有固定的恒定频率。使用时钟信号来进行同步的电路可在上升沿或下降沿或在双倍数据速率的情况下在时钟循环的上升沿和下降沿变为活动状态。
算法/算术工作(作为数据流应用程序的数据处理的部分)通常由PE执行。它们针对每一层进行的工作通常并不非常复杂(几乎仅是乘累加的长序列),但数据访问模式在数据流模型的层与层之间不同,且每一层需要极大量数据的处理。
系统的其余部分的主要任务通常是在每个循环中利用尽可能多的PE,这意味着在每个时钟循环中为其提供数千个操作数,即每秒许多万亿/兆的操作数,且尽可能当PE在进行有用工作时执行根与集群之间的数据传送。
高利用率需要谨慎的规划,这是由编译器自动完成的,所述编译器处理例如CNN模型描述以产生用于虚拟机(也被称为抽象机)的目标代码程序,例如解译器程序,其通过所需的运行时间支持而类似于具有专用指令库的计算机来动作。
此指令库是编译器与GPP软件之间的接口。编译器还需要知道可用PE微码的规范,即可用现成的变换的库。编译器开发者可在需要时建议新的此类功能以用于某一模型的优化。最常见的CNN模型可通过相当小的一系列变换类型执行,但用于解译音频信号的例如递归神经网络(RNN)的一些网络也使用一些不太常见的类型。
在系统启动时将目标代码和抽象机加载到GPP的主存储器中(图4)并且随后执行目标代码。
通常,系统处理以每秒许多图像的速率输入的图像。处理的目的是“推断”,即从输入数据得出结论,例如识别传入图像中描绘的对象或情形。
如果一切都正确地设定,则CNN模型的执行序列--每秒多次的用于每一推断的数百亿运算--确切地是相同的每一时间;序列自身中不存在数据相依性,仅在其计算的结果中存在。
数字处理器主要由其指令库指定,所述指令库是机器指令类型的集合。机器指令通常由许多位字段组成。这些中的一个含有操作码,其它可含有地址偏移、寄存器编号或数据。机器指令是所存储可执行目标代码的构建块,所述目标代码由汇编程序的编译器从由编程者写出的源代码文本产生。
大体来说,也被称作微码控制处理器的可微编程的处理器是其中处理器的机器指令由内部微程序存储器(即,控制存储器,通常为只读存储器)中的微码指令序列执行的处理器。这些序列是内部处理器设计的部分,且通常由处理器设计小组开发。因此,可微编程的处理器是不应与“微处理器”的表达混淆的特殊类型的处理器,微处理器仅意味着处理器被构建为集成电路。
一方面的机器指令与另一方面的微码指令之间在性质和功能方面存在不同的差异。
自然地,可微编程的处理器也可以构建为集成电路,但微处理器按照定义未配备有用于控制其内部操作的微程序。
在可微编程的处理器中,正常程序是从微码字(也被称作微指令)产生处理器的控制信号。这些可被认为是由位或位字段组成的字,其各自表示由其在字中的位置界定的控制信号,且每一字指定在当前时钟循环期间将产生的相应信号电平。微码字形成存储于特殊微程序存储器(也被称作控制存储器)中的微程序,且微程序因此控制处理器核心的细节,因为其控制执行硬件以获取和执行机器指令。这对应于经微编程的即微码控制的处理器。
在可微编程的处理器中,因此在正常程序与执行硬件之间存在额外的控制层级。此层级通常将程序的机器指令当作数据,在微码指令的控制下将所述数据带入执行单元且在其上操作。因此应当理解,机器指令(通常存储于外部RAM存储器中)与微码指令(存储于内部微程序存储器中)之间存在实质差异,微码指令用于控制执行硬件以获取和执行机器指令。
此处的描述稍微简化,但更复杂的细节并不需要本发明构思所建议的总体系统、本文提出的配置和程序的任何显著改变。
举例来说,编译器的设计可首先考虑简化描述,并且接着在其施加到真实模型和新微码时被精炼以用于处理元件对其尽可能有效地处理。
虽然描述主要集中于乘累加(MAC)运算,但在需要时还可使用例如ADD和MAX等其它(较简单)运算。
描述的一些部分主要限于PE外部的系统部分,以及这些系统部分如何在正确时间以数据块、参数和代码服务于PE,使得尽可能多的PE可连续工作尽可能多的时间。
有时这可能是困难的,但对本文描述的系统不一定如此。可以在编译器和PE微码中解决问题;它们无需影响本文所描述的总体系统的要求,因为其可如由编译器已产生的代码所指定以任何给定次序传送块进出集群,而不需要知道它们含有什么。
此情况的实例是在附录中描述的层融合。在一些情况下,加速器中的CNN模型或FFT算法的最有效执行可能要求在层的执行期间修改PE中的微码缓冲器的内容多于一次,并且我们并非始终在下一层上开始之前完成一个层。
另一实例是雷达数据提取,其中PE可执行整个FFT,并且可通过使用管线式且并联的多个PE来增加大小和时延。此处,层是较小的,且PE的暂存器因此可同时在其暂存器中存储两个完整层或两个层的相当大的部分。随后可从第一个到第二个并且接着从第二个到第一个等等进行变换,避免PE外部的中间数据存储。在其中层不完整的情况,两个或更多个PE可并行地工作。它们随后需要经由共享集群存储器与集群中的其它PE交换数据,并且如果使用多于一个集群,则集群需要交换数据。这极类似于针对CNN需要的数据交换。
特别参见图6,DDR4可以用于FPGA版本,但在IC设计中可能将不受关注。存储器容量是初步的且对于不同实施方案无需是相同的。时钟频率可受到当前使用的技术的限制,例如,对于其假设0.8V供电的SRAM。以较低电压可实现增加的效率,但随后将需要减少频率。额外总线可以用于外围接口。例如,具有16个集群和/或每集群一半数目的PE的较小系统可以用相同IP块的其它布置来构建。
应当理解,所提出的技术不限于这些具体实例中的任一个,而是受基本构思的一般理解所限制。
所提出的技术和/或其不同方面是基于发明人的多个洞察(其中的一些可以取决于考虑哪个方面而为可选的):
●为了例如处理图像或执行更一般的处理任务,通过使用例如本发明的PE等许多处理元件,将图像划分成矩形区且将区指派到每一集群和/或每一PE是自然的。随后惯例是将集群和/或PE连接到所谓的网状网络中,特别是因为所述区在许多情况下需要与相邻区交换数据。不过,已认识到标准网状网络对于大规模数据输入和输出不是很高效。
发明人已认识到与使用标准网状网络相比,例如具有集群中集群的星形网络配置的极特定实施方案合适得多,特别是当需要改进的可伸缩性/扩展性时。作为本发明活动的部分,发明人能够分析且精确确定对于大量数据的快速且功率高效的输入和输出需要的是什么。为了管理相邻者之间的通信和数据交换而提出的所谓的开关块(参见下文)可像对于网状网络一样有效地处理此情况,特别是当大多数或全部PE以相同的同步速度操作时,但所提出的星形网络配置提供出色的可伸缩性/可扩展性性质,而几乎没有在多个星形网络内使用多个星形网络或者在一个星形网络内使用一个星形网络的任何限制。
在特定方面,所提出的技术进一步建议使用用于节点的共同存储资源,且通过基于集群中集群(也可被视为“星形网络内的星形网络”)的配置,也可提供不同水平的存储,当系统大小和进而数据量以及对应数据带宽增加时这是极有益的。
●发明人的另一洞察是关于待执行的MAC运算。通常,存在使用管线化的多个MAC单元,且每一单元可以给定循环时间开始MAC运算,所述给定循环时间例如时钟频率的一个周期。总过程的执行时间无法短于MAC运算的所需数目乘以此循环时间并除以MAC单元的数目。为了能够接近该极限,操作数的转发(通常是极复杂的过程)必须是有效的。发明人已认识到最快配置(以MAC循环的数目计)是如下的一种配置:可以i)使用尽可能多的MAC单元(即,为其提供操作数),且ii)尽可能多的“隐藏”时间以使操作数就位。换句话说,在与MAC单元工作的相同时间期间执行数据运输,即同时数据运输和MAC执行。
●应当执行多个MAC运算,每一运算对来自不同数据结构的两个操作数进行运算,所述两个操作数应当例如从连接到MAC单元的输入的快速SRAM同时读取。SRAM存取和MAC运算需要一些量的能量,这取决于例如SRAM和MAC单元设计以及制造技术等因素。此处的洞察是除上述因素之外,最高效节能的系统设计是将正确操作数最有效地提供和/或转发到SRAM存储器的一种系统设计。
●使图像在集群存储器中的准备就位绝非微不足道,但发明人已认识到,借助于特殊的转置程序和对应硬件块可实现在极短时间量内的有效存储器缓冲和划分成区。
●集群中集群,具有每一层级上的广播:
作为非限制性数字实例,一个集群中的64个PE消耗的字节/秒的峰值总数目是3070亿(具有2.4GHz PE时钟)。这比共享集群存储器可以合理地具有的带宽大得多,并且PE的高利用率因此要求操作数必须存储于本地暂存器中且尽可能地再使用。
暂存器有许多且它们必须较小。由于精益设计,例如使用单端口SRAM,在暂存器正从共享集群存储器加载时PE无法使用其MAC。为了高利用率,此加载与所加载数据的高速消耗相比必须快。
幸而大多数传送的内容是对于所有PE相同的内核参数。它们已经经由NoC广播到CM,且它们将在需要时(且以较小部分)从每一CM(本地)广播到其PE。这大大减少了CM的带宽要求,但对于PE不是这样。
不过,PE仅需要其自身的相对小的其它数据的部分,其对于正在处理的其张量的部分(通常是x和y维度的小部分且延伸通过z维度的全部或部分)是本地的。但PE有时需要重复读取CM内容。
传送机制应当是高效的并具有极高带宽。发明人已认识到其可以有利地利用(本地)广播,即将此数据同时传送到所有PE由此快得多,并且CM与PE之间的连接必须比NoC通道与PE数据路径的连接更宽。
举例来说,关于所提出的NoC的特殊特征是除以“星形”网络连接之外,节点还具有在具有“行和列”或等效阵列配置的阵列中的特定位置,且在中枢中提供开关,所述开关被设计成让我们以许多特定方式中的一种将所有节点有效地连接到其它节点。一种此类方式可以是每个节点可以向其右边的最近相邻者进行发送且从其左边的最近相邻者进行接收(列和行的阵列中),同时另一方式可以是每个节点可向其下方的最近相邻者进行发送且从其上方的最近相邻者进行接收。换句话说,每个节点可在阵列的特定方向上向其最近相邻者进行发送,且在阵列的另一(例如,相反)特定方向上从其最近相邻者进行接收。对于阵列中的边缘节点,这些传送可越过边缘到达相对侧。在某种意义上,此“分层次结构”配置可被视为模拟“环面互连”的唯一配置的类型的星形网络。
为了本发明的更好理解,现将参考所提出的技术的继续描述和阐释,特定关注于神经网络(CNN)应用和其中的推断过程。然而应谨记,神经网络仅是所提出的数据流加速器的许多可能应用领域之一。
操作的架构原理的实例
实例-加速器硬件、固件和编译器
如所提到,加速器是硬件机器,包括两个(或更多个)种类的可编程处理器。一个种类是在根处的GPP,另一个种类用于许多处理元件(PE)中的每一个中。这两个处理器类型的详细功能性--例如GPP的指令集和PE中的高速计算--可以由内部微码定义,所述内部微码在本文通常称为固件。固件主要对于GPP也可以指代类似于软件而开发的代码,使用软件指令,但属于硬件(例如,接口)的低层级控制并且连同微码一起经常存储于ROM中。
在通常的应用中,大量数据(例如,数十千兆字节/秒或更多)流过此加速器。其中无法涉及经编程处理器核心,除了在高层级控制这些流外,即建立流,开始流,且在错误的情况下重复流。举例来说,这可以通过片上通用(可编程或可微编程)处理器(GPP)完成。
在最适合于作为集群中的集群构建的较小加速器或较大系统的一部分的加速器设计的变体中,GPP与加速器的其余部分不在相同芯片上。举例来说,通常为高速PCI或USB3.2或USB4的高带宽接口可以随后用于将外部GPP连接到控制NoC的逻辑(电路系统)。加速器的一般功能与本文描述的相同。不过,在此变体中用例如PC或服务器处理器等一般数字计算机代替GPP可能是实用的,在此情况下通过计算机程序模拟GPP功能并且关于GPP硬件设计的所描述细节并不适用。图1A可用此系统的变体构建,在此情况下DDR5IC(作为一实例)将可能由于可使用计算机存储器而省略。在集群的集群的情况下,DDR5 IC可以保持作为“子集群本地”存储器,且GPP则将不会被计算机代替,而是替代的例如FPGA,其非常适合于连接许多此类加速器集群且处理所述集群与例如高带宽存储器(HBM)DRAM等辅助存储装置之间的数据的高处理量。
在一些实例实施例中,控制处理器可以甚至被视为分布式处理器系统,例如具有一些片上的部分和一些片外的部分。
通过片上网络(NoC)的流通常终止于许多集群存储器(CM)中,所述集群存储器又由许多处理元件(PE)共享。举例来说,集群作为平铺块的规则阵列布置于IC芯片上。每一平铺块具有其自身的时钟;其无需与除了作为其时钟源的其自身的NoC连接之外的任何其它同步。在平铺块内部是例如32个双PE的块,所述双PE的时钟信号是从NoC的中枢进入集群控制器的两个时钟信号产生。
PE执行几乎所有算术工作,且其细节由本地微码单独地控制。在一实例系统中,可能存在4096个PE,64个集群中的每一个中有64个PE(32对),或更通常而言针对K个集群总计K x M个PE,每一个集群包含M个PE,其中K和M是等于或大于2的整数值。对于许多应用,可为有利的是使系统具有至少16个集群,每一集群包含至少16个PE(例如,8个双核(心)),总计256个PE。它们针对每一层进行的工作通常并不非常复杂(几乎仅是乘累加的长序列),但数据存取模式在数据流模型的层与层之间不同,并且每一层需要极大量数据的处理。编译器和GPP的职责是保证微码、数据和系数的相关块(在卷积神经网络的情况下主要是内核元素)在当PE需要它们的时间点在所有集群存储器中处于合适位置,且照管必须输送离开存储器的数据,所述数据待存储并稍后取回或者将作为结果递送。
如先前所提及,系统的主要任务是在每个循环中利用尽可能多的PE,这意味着在每个时钟循环中为所有PE的算术资源供应总计成千上万的操作数--在本文描述的实例系统中这将意味着每秒大约数百万亿的操作数--且尽可能当PE在进行有用的算术工作时执行根与集群之间至少部分的数据传送。
高利用率需要谨慎的规划,这是由编译器自动完成的,所述编译器处理例如CNN模型描述的数据流模型描述以产生用于虚拟机(也被称为抽象机)的目标代码程序,例如解译器程序,其通过所需的运行时间支持像具有专用指令库的计算机一样运行。
此指令库是编译器与GPP软件之间的接口。在本实例中,编译器还需要知道可用PE微码的规范,即可用现成的变换的库。编译器开发者可在需要时建议新的此类功能以用于某一模型的优化。最常见的CNN模型可通过相当小的一系列变换类型执行,但用于解译音频信号的例如递归神经网络(RNN)的一些网络也使用一些不太常见的类型。
在系统启动时将目标代码和抽象机加载到GPP的主存储器中且随后执行目标代码。
通常,它处理以每秒许多图像的速率输入的图像。举例来说,处理的目的可以是所谓的“推断”,即从输入数据得出结论,例如识别传入图像中描绘的对象或情形。
如果一切都正常,则数据流模型(例如,CNN模型)的执行序列--每秒多次的用于每一推断的数百亿运算--确切地是相同的每一时间;序列自身中不存在数据相依性,仅在其计算的结果中存在。
实例-CNN模型的编译
模型
大体来说,可以开放地由研究人员和由工业公司连续创建CNN模型以用于其专有用途。
实例模型可被视为数据流曲线图,其通过一系列变换处理通常为3维数据结构的输入数据集,每一个变换通常产生输入到下一变换的另一3维数据结构。模型指定用于每一变换的操作和参数。
不过,模型设计自身不给出参数;实际上通过针对特定任务进行“训练”,例如对图像中的对象进行分类,来“学习”参数。训练通过重复循环而产生参数值,所述循环需要与在推断中使用的那些数据流操作相同种类的数据流操作,且可利用相同加速器。
以由若干已知开源框架中的一者定义的格式来指定CNN模型。
模型连同参数一起可以被编译为适合于执行的形式。存在用于此过程的第一步骤的一些开源工具,与最终步骤相比,对硬件的依赖程度可能更低。
参数大部分是已经通过训练而学习的权重系数。编译器可以原样地使用权重系数,或者可指示编译器将权重系数量化到较低精度以减少计算工作。作为最后步骤,也可通过编译器压缩参数文件以减少其大小。
通常模型的处理是非条件性的,不存在数据相依性,序列是固定的,且变换是彼此独立的;每一层应该在下一层开始之前完成(但有时可通过修改此情形而节省能量并得到相同结果--所谓的层融合)。有时变换的结果被存储并稍后被取回,且在过程中稍后与另一层组合。在递归神经网络(RNN)中也存在反馈,即结果可被反馈以与在过程中较早产生的层组合。
数据结构(“张量”)具有x、y、z维度(宽度、高度、深度)。模型指定每一数据结构的维度以及它们如何在x/y平面中彼此对准(与指定如何完成“填补”相同)。模型还指定将对张量进行的变换。
编译器
术语“编译器”在此处可以用于工具链,需要所述工具链以创建加载到加速器系统中的文件以使加速器系统执行由数据流模型的呈标准语言的规范界定的其任务。所述链的尾部部分是硬件。
编译器创建用于加速器执行的目标代码。此代码主要描述加速器内的数据块的高速传送,服务于待由PE进行的处理。不过,CNN编译器通常不负责编译描述变换的细节的任何源代码。那些细节由需要手动编码的短微程序逐个循环地控制。这较类似于硬件设计,尽管像软件一样完全可配置。幸而它们是极紧凑的,且存在经良好证实的元汇编工具以从人类可理解的源代码产生它们。使预定义微程序可用于编译器,所述编译器选择合适的一个来使用,这取决于模型针对待编译的层或层序列需要的是什么。
微编码的变换可选自替代方案的特定有限列表,且连同任何相关联功能参数(指定存取模式等)和CM地址一起插入二进制输出或在二进制输出中引用,例如在何处找到权重(系数)以及在何处存储结果。
主要变换仅具有三个类型,且其中两个可以通过两个功能参数(大小和步长)来修改。例如取决于维度/尺寸的相对大小,还存在用于在其之间进行选择的这些变换的特定替代变体。编译器将通常需要进行适当选择。
变换中的一些可使用修剪,由编译器应能够利用的特殊微程序版本支持。
编译器还必须辨识何时可使用层融合,并决定如何在其产生的“二进制”(目标代码)文件中实施层融合。
(所述文件无需是极紧凑的,因为其大小和其造成的解译开销与正常软件相比是可忽略的。因此,其不必是“二进制的”,而可以是可读文本。)
当创建用于执行的详细固定调度时,编译器必须对过程进行建模,使得其例如精确知道集群存储器的哪个部分可用作新参数的目的地。
输入图像的细分
编译器的另一任务是产生GPP处理数据输入所需要的代码。对于摄像头输入,GPP将通常需要在其控制先前图像的推断过程的同时接收数字化摄像机视频信号且在DDR中以规定的方式存储图像。当已接收整个图像且先前推断完成时,GPP应控制加速器硬件以在完全NoC速度下将新图像传送到集群存储器。
应当如何进行图像的细分可由编译器决定,通过此规则:通过宽度和高度中的最长者的对等分将图像划分成两个相等半部。这总计进行六次,即针对每一细分重复直到给定水平的划分为止。此实例导致将图像细分为64个相等矩形,其条件是在对等分之前所有尺寸是平均的。如果它们不是平均的,则在第一次对等分之前通过按需要进行填补来简单地放大图像。
实例-GPP软件
GPP通常在系统启动时从DDR引导,并且接着还加载抽象机,所述抽象机将执行由编译器产生的目标代码。此目标代码是这里所指的词“软件”和“程序”,且据说GPP要执行的内容是通过抽象机(其有效地代替GPP的指令集)间接进行。
目标代码在运行时间期间通常驻留于GPP主存储器中,且主要控制进出CM的传送。
存在此软件要处理的主要两个过程。一个是表示图像或雷达信号的数据的在规则中断下的输入,所述输入可能需要经预处理(按比例缩放、量化)且存储直到其以所需要格式完成并且可在高带宽下递送到NoC为止。
此过程还通过将图像划分为例如64个区来重新布置图像,每一CM一个区。作为所述重新布置的最后部分,通过转置(TRANSPOSE)块将图像从DDR传送到CM。这可以在仅几毫秒内完成。在所述传送中不涉及(发起所述传送除外)的GPP与此同时开始在摄像速度下以时间共享方式接收下一图像,且将在先前图像的处理期间以特殊的重新组织的方式将所述下一图像写入到DDR中。
第二过程是一旦CM已经加载有新图像就开始的推断。
推断过程按需要的次序加载模型参数。从RM加载模型参数将是高效节能的,但这可能不具有所需要的容量。其可随后从DDR或直接从非易失性存储装置(例如,快闪存储器)加载。将用于快闪存储器并且还用于摄像机(以及显示器和音频(如果使用))的可能接口是USB 3.2。片上MRAM是可能的非易失性存储器替代方案,其可用于目标IC制造技术GF22FDX,还有GF 12FDX,其为自然的下一步骤,具有简单的迁移以用于性能和效率的进一步改进。
GPP主存储器中的目标代码是DNN或DSP数据流模型的表示,其由编译器逐层地创建以便给予GPP其需要知道的所有内容(但没有别的内容),以在整个过程中以正确的次序将微码和参数和输入数据传送到NoC,且在结束时接收和递送结果。
GPP无需知道哪个是微码以及哪个是模型参数,其仅需要知道源和目的地位置以及要传送的块的长度。此信息已由编译器在目标代码中指定。
当集群存储器容量不足时,在过程中的某些固定点(由编译器预先确定)存储/取回中间数据也将涉及GPP程序代码。此存储将使用根存储器(RM)以得到最高带宽和最低功率消耗,但在需要的情况下将使用外部存储器--DDR或可能经由以太网的远程存储--在此情况下RM中的FIFO缓冲可使NoC传送时间较短。
用于层的微码通常将放置于CM中的地址0处;即PE通常在开始执行之前将给定数目的字获取到其微码缓冲器的位置。针对每一层变换进行微码的传送可以是实际的。应注意,用于先前变换的微码通常不再被需要并且可被覆写。如果在CM中存在足够空间用于微码,则用于若干层的微码可以一起传送,或甚至驻留,即仅在系统启动时加载。PE可在微程序控制下按需要从CM下载新微码序列。
在变换的处理之前,其权重参数也必须从根传送到CM,应注意确保没有重要内容被覆写。
GPP通过标签网络(TagN)命令集群使用它们已接收到的微码和参数开始处理图像。
当第一处理步骤完成时,GPP继续解译代码,这将可能使其传送某种新微码,覆写用过的微码(不再需要)且可以通过NoC命令一些数据传送。
过程将以相同方式继续,首先传送微码,随后是参数,并且接着开始处理。这是逐层进行的,直到数据流模型的结束。随后结果在集群存储器中且将适当地组装和输出。
GPP软件还将包括用于DDR和I/O接口块的驱动器。也可使用由市售IM3000处理器支持的所有接口。具有一个或几个16-PE或64-PE IP块的DSP加速器的较小Al可以用作片上系统(SoC)装置的部分,其中GPP除本文描述的作用之外还有更多的“通用”作用。对于此系统,可使用1Gbps以太网(例如,具有Imsys自身的接口IP)而不是较高速度以太网接口。
实例-根存储器
可以使用高带宽缓冲器来均衡总线客户端之间的数据流,且片上SRAM也是用于中间数据的共同存储的优选资源,因为其比使用外部DDR更高效节能。还将使根存储器可从GPP经由512位宽总线连接至其片上主存储器进行间接存取。GPP可随后使用根存储器作为高速辅助存储器且经由所述高速辅助存储器还将数据块传送到所有其它总线客户端/从所有其它总线客户端传送数据块。
RM--以及在需要时的外部DDR--可以用于在推断过程期间的临时存储,且容量因此大于缓冲所需的容量。RM经由总线连接到NoC树的根。带宽应当优选地匹配PE一起需要的带宽以及DDR可提供的带宽两者。
用于待处理的层的程序代码和参数通常对于所有参与集群是相同的,且因此广播到集群存储器。广播比不同内容向NoC的不同叶的传送更快。在传送用于层的数据之前进行此广播是实际的,因为应用程序数据可能需要分若干个批次加载和处理。
集群(尚未断开)是否“参与”可以通过集群控制逻辑中的触发器来指示。
实例-中央总线
具有高处理量(每秒许多千兆字节)的所有传送穿过由总线仲裁器控制的512位宽总线。仲裁器接收请求且确认来自总线客户端的信号,并确定其中的哪一个将使其输出在总线上启用且哪一个将读取总线内容。仲裁器根据又由GPP控制的协议进行操作。
总线的客户端包括以下各项中的一者或多者:
●NoC寄存器
●根存储器
●GPP主存储器
●高速接口
○PCIe
○10G/25G/100G以太网
○USB 3.2
●DDR接口
●转置块。
初始图像加载
图像的初始加载经常是最大的NoC传送,且其较难以“隐藏”,因为其需要在第一变换之前进行。
输入通常是图像,但其也可以是例如来自雷达RF单元的A/D转换器的一组信号。对于汽车摄像机,图像可以是20MB且帧速率为20fps,即执行时间应当是50ms或更少。病理图像系统可具有许多GB的图像大小,因而当然接受更长的执行时间。
来自摄像机的图像的接收在整个帧循环中在时间上展开,并且对于雷达帧也是此情况。整个图像需要在其高效处理可开始之前存在于加速器中。这是因为CNN的层必须严格地按顺序处理,即一个变换需要在下一变换可被处理之前完成(至少对于部分的层)。
因此,在我们处理一个图像的同时,在50ms的帧时间期间,我们从摄像机接收用于下一图像的输入数据并将其存储于操作存储器(例如,DDR)中。我们接着将其尽可能快地传送到集群存储器。我们可以比摄像机处理量快10倍来进行此操作,这给我们留下超过90%的帧时间来处理图像。我们不需要NoC和总线的全部带宽来进行此传送,因此我们可能够使其与先前结果(通常小于图像)向高速I/O接口中的一个的递送(经由RM中和/或接口块中的缓冲器)重叠。
图像应当以适合于将其加载到集群存储器中的方式存储于操作存储器(例如,DDR)中。不过,不可能完全这样做,因为总线上的邻近字节连接到不同集群,且在DDR中的写入必须在16个连续字节的块中进行。
我们需要进行的重新布置以两个步骤完成。当将数据写入DDR时执行第一步骤;这完成以使得每一传入扫描线被分成与跨图像宽度存在的区一样多的部分,且这些部分不是按顺序存储,而是以将位于下部的区放置于比上部区更高的地址的方式存储,且使得当以正常地址次序读出数据时行部分以所需次序出现。第二步骤以希望的方式分解16字节序列。这可以通过转置(TRANSPOSE)块进行。
开关块此处应当仅将NoC寄存器的每一字节传送到其对应的集群,正如模式3一样。
最终结果的高效递送将需要经历类似的重新布置,但是沿相反方向。
转置块
我们可经由高速接口,例如PCIe或USB 3.2从摄像头/摄像机或雷达接收器得到图像。我们可以使用根存储器的一部分作为FIFO缓冲器来均衡流,且从该处传送到DRAM。
为了改进的性能且为了DRAM的高效使用,期望存储数据为长连续序列(16字节),同时我们为了以高速向所有集群传送需要将这些序列拆分并重新布置字节,使得我们可同时向所有集群发送对应字节。
举例来说,当图像在DRAM中是完整的且到了将其发送到集群存储器的时间时,我们经由转置块进行所述传送,这通过取入1024字节并以合适方式改变其次序来解决问题,所述合适方式是矩阵转置运算。
我们需要此硬件块用于将图像的不同部分高效分发到不同集群以用于处理,但其还可用于其它任务。矩阵转置有时是需要的且无法由普通处理器有效地执行,特别是对于DRAM中的数据。看起来似乎硬件转置块对于DNN训练所需要的矩阵相乘可以变得有价值。这种运算对于2维FFT也是重要的。
举例来说,转置块可被视为例如16*64个元件的矩阵,每一元件是8位寄存器。寄存器以行和列互连,且数据(完整字节)可水平和竖直地移位通过矩阵。我们始终在DRAM中读取和写入16字节序列。在我们进行读取时,我们从右边在宽度上以16字节移位。通过64个移位步骤,我们填充矩阵,且可随后将其清空到512位寄存器且到集群上。
传送数据进出此块的逻辑应当允许我们在发现有用的情况下以不同方式使用所述逻辑,可能在两个方向上并且还无需DRAM,例如,转置来自和去往根存储器的矩阵。
例如,所述块的原生设计可以使用16*64*8=8192个触发器,其以两种替代可选择的方式连接为移位寄存器。举例来说,它们将全部在块操作的同时在1200MHz下计时。不过,存在更好的方式来这样做,其将触发器计时事件的数目从(64+16)*8192=655360减少到仅64*16*8+16*64*8=16384。定制布局将是优选的,被组织为8个相同“位片”块,其类似于正常RAM阵列(64*16)布置且使用标准RAM单元作为触发器。计数器是驱动多路分用器,其控制单元类似于控制正常RAM阵列的字行和位行,差别在于存在替代的字行和位行--在一个模式中为水平/竖直且在另一模式中为竖直/水平。数字硬件设计领域的技术人员应当清楚可以如何进一步开发此情形以使得可以在需要时可选择地改变通过块的流的方向(输入/输出)。
实例-片上网络
根与集群之间的数据传送使用独特设计的星形网络,尽管物理上在IC上其将布置为如图11示出以及在图7中示意性地示出的分层树。其控制逻辑集中在根处。集群存储器是网络叶,且这些集群存储器中的每一个还由例如64个(或更一般来说M个)PE(例如,32对PE)存取,如图8所示。64PE集群的说明性非限制性实例可替代地被配置成充当四个16PE集群,每一集群具有存储器容量的1/4。这对于一些数据流模型可以是优选的。应理解,通过N的任何细分(即,1/N)是可行的。
对于正研究的参考CNN,必须在根系统与集群之间传送每秒几乎10千兆字节的平均值。此传送的约83%是向外的,从根到集群。为了良好利用率,其应当以比此平均值高得多的速率传送。
在此特定实例中,数据通过64字节宽通道传送,每集群一个通道,因为通常数兆字节的大块针对每一层从根传送到CM(尽管其大部分由广播的内核值组成,这意味着相同内容在所有通道上传送)。
通道形成星形片上网络(NoC)。举例来说,峰值总传送速率在1200兆传输率/秒(MT/s)下是76.8GB/s,即其需要进行向外传送约10*0.83/76.8=~11%的时间而向内传送为2.2%。
传送可以通过单独地传送的控制信息来发起。此控制通信是在称为标签网络(TagN)的不同网络上以位串行方式传送,所述网络被构造成分层树,在其分支点中具有逻辑。数据与控制之间的分离具有若干优点;其中节省时间的两个优点是传送可以在另一传送期间设置,以及错误传送可被停止并重新开始而无延迟。
星形NoC的中枢与TagN树的根在相同的位置,且两个网络是一起路由的。
实例-控制网络(标签网络-TagN)
TagN通过携带控制信息来补充NoC。其利用NoC的时钟和再生站,且因此可在相同高频率下操作。其使用一个输出线和一个输入线,在所述输出线上串行地传送命令和相关联参数,在所述输入线上接收命令响应和中断请求。它们不是同时使用,而是其中的一者在另一者使用的同时保持为低。仅当命令已设定允许其的状态位并且所述命令已结束且集群见到向外的标签行为低时允许向根未经请求发送,即中断请求。
TagN线遵循NoC数据和时钟线,但其不是星形网络。TagN传出信号在再同步之后在从NoC树中的每一分支点的两个向外方向上继续,且因此同时到达所有集群,对所有集群具有相同控制信息。
根是主控,集群控制器是从属。GPP可使用8个字节从一个到全部来寻址集群的任何群组,每一集群一个位,并且接着向寻址到的集群发送命令。命令可涉及要进行的传送。其可提前发出,甚至是当先前数据传送在进程中时,且给予集群所需要的参数,即方向、开始地址和长度。数据传送自身可稍后由短命令触发而无需寻址。
命令也可涉及从集群读取状态信息。随后,在此命令之后,当TagN线为低时,寻址到的集群控制器(CC)在向内时钟线上输出其时钟(如果其并未由于向内数据传送而已经激活)且在其向内TagN线上发送其响应。
向内TagN线当它们在分支点中组合时一起被求或,从而允许一个集群在其它集群空闲时使其信号通过。如果预期响应仅可为0或1,则读取命令可发出到多于一个CC,且随后在分支点中逻辑上组合(与/或)响应。取决于由命令选择的极性,响应可意味着全部都响应或全部都不响应。
实例-NoC
可以通过自主逻辑控制器(状态机)在低电平下控制高带宽数据传输,所述自主逻辑控制器由计数器和门逻辑构建并用根时钟(例如,1200MHz)计时。这些自主逻辑控制器从GPP的“I/O总线”接收简单命令且向其递送状态信息,所述总线是直接由GPP微程序控制且由指令集中的I/O指令支持的简单20信号接口。
片上网络(NoC)是高速(例如)8位宽半双工数据通道的星形网络,每一集群一个数据通道。通道可以使用每位一个信号线,或类似于标签网络在每一方向上一个信号线。这取决于物理设计,且其不改变系统工作的方式。这些信号作为分层树来路由,这具有的效果是所有路径可具有相同长度。
为了达到每信号线的高带宽,使用高传送速率(例如,1.2GT/s),且使用遵循相同路径的时钟信号以规则间隔再生信号且在每一分支点中重新同步。这些再生点之间的距离不长于每一集群平铺块的延伸,这意味着针对平铺块的内部逻辑指定的高时钟频率1.2GHz也可用于NoC传送。遵循通道轨迹的时钟信号可以是例如600MHz对称方波,其中两个边缘都用于计时。时钟转变之间的间隔因此不短于数据或标签信号的那些间隔。具有较高频率的第二时钟信号可以相同方式分发。其将用于创建PE所需要的本地较高频率时钟。
向外时钟信号的源是还用于根系统的时钟。向外时钟信号遵循树的分支,且其由每一集群控制器接收和使用,所述集群控制器还将向外时钟信号用于产生用于其PE的时钟。向外时钟因此始终在作用中。
对于向内数据,每一集群在需要时在其NoC连接中的单独线上发送其时钟作为向内时钟信号。这在每一分支点(两个实际上相同的时钟在此会合)中的再生时减少到一个向内时钟。在根处,此时钟用以锁存所有64*8个数据信号,然后它们才通过根时钟进入NoC寄存器。对于再同步的一般信息可参考[1]。
在特定实例中,去往/来自每一集群的数据作为完整CM字传送,此处为16字节单元,即字节宽NoC通道上的16个传送的序列。此序列可(通过在控制寄存器中设定位)扩展到17个循环,在此情况下额外字节是基于所述16个数据字节的LRC代码(纵向冗余校验)。在过程的一些(可能为许多)时间点,NoC传送速率不需要是最高可能的(因为PE正忙于处理),且随后应当选择此模式。当然如果不需要最高可能速度,则在其它情况下也可以选择此模式。其(至少)由监控服务质量的过程使用。如果需要高可靠性,则CC应当通过请求(通过标签网络)块的重新传送来对数据传送错误作出反应。标签线将通常在传送期间自由用于此类请求,且因此传送可立即停止,而无需等待块的结束。
“隐藏”传送
在PE通过较早已经传送的代码和参数和/或通过它们自身在本地CM中已经创建的数据(激活)来工作的同时,NoC传送经常可通过完成被“隐藏”。如果此先前开始的工作需要充分多的循环,则其可以完全“覆盖”NoC传送时间,所述时间则将不增加到总执行时间。不过,我们必须通过充分利用集群存储器而尽可能地避免NoC传送。
这需要使用相关DNN模型进行研究。关于层融合的描述,参见附录A。
实例-集群存储器的PE共享
举例来说,如果使用2.4GHz PE时钟,则由一个集群中的64个PE消耗的字节/秒的峰值总数目是3070亿。这比共享集群存储器可以合理地具有的带宽大得多,并且PE的高利用率因此要求操作数必须存储于本地暂存器中且尽可能地再使用。
通常,暂存器有许多且它们必须较小。由于精益设计,PE无法在暂存器正从共享集群存储器加载时使用其MAC。为了高利用率,此加载与所加载数据的高速消耗相比必须要快。
幸而大多数传送的内容是对于所有PE相同的内核参数。它们已经经由NoC广播到CM,并且它们将在需要时(且以较小部分)从每一CM广播到其PE。这大大减少CM的带宽要求,但对于PE不是这样。
然而,PE仅需要其自身的相对小的其它数据的部分,其对于正在处理的其张量的部分(通常是x和y维度的小部分且延伸通过z维度的全部或部分)是本地的。但PE有时需要重复读取CM内容。
传送机制必须是高效的且具有极高带宽。其必须利用广播,即将此类数据同时传送到所有PE且因而快得多,并且特别是在从CM到PE的方向上的CM与PE之间的连接必然比NoC通道和PE数据路径的所述连接宽得多。
实例-PE微码
例如,64个(或更一般来说M个,其中M是整数)PE连接到每一集群存储器(CM),例如如图10所示。
在PE中完成的工作优选地主要以纯微码进行编码,尽管有时可使用类似于软件指令的事物,因为为此需要的功能在基本PE核心中是固有的且可得到更紧凑的代码。然而,“指令集”则针对当前任务所定义将通常是极小且极特殊的(“域特定”)。PE可在运行时间中有效地替换其微码的部分。这对于神经网络处理是理想的,所述神经网络处理由大数据结构的不同变换的长序列组成。
GPP不需要知道关于此代码的任何内容。GPP将在需要时将其传送到集群存储器中,恰类似于其当需要时传送CNN内核(或FFT系数)。PE将随后将代码获取到其微码缓存,恰如同它们将操作数(张量和内核元素)获取到其暂存器。CM中的微码通常针对每一新层被覆写,恰如同不再需要的操作数。
实例-处理量对时延;时钟频率
所描述的加速器设计具有许多处理器核心且针对处理量而优化。举例来说,所提出的处理器核心设计是完全微程序控制的且通常不具有L1高速缓存,这使得其时钟频率极度取决于SRAM块可支持的频率。以与SRAM速度相同的速率已经开发了逻辑的速度,且逻辑设计的时钟频率限制不像具有给定大小的存储器块的时钟频率限制那样固定。当决定转变到较精细技术的处理器的目标时钟频率时,因此研究所需要SRAM块的可能时钟频率是足够的。
此研究假定制造技术是GlobalFoundries 22FDX,对于其可通过供应电压和偏置电压的适当选择,以减少时钟频率(即,较长时延)为代价实现每瓦的较高处理量。我们此处假定,对于设定时钟频率限制的那些SRAM,供应电压是0.8V。
已使用来自SRAM IP厂商的存储器编译器针对许多配置生成SRAM性能数据。对于性能最重要的是PE时钟,我们将其选择为对于小的暂存器SRAM合理的尽可能的高。不过,对于大得多的存储器CM和RM,我们需要使用更大且更高效的SRAM实例且那些实例具有较低频率限制。集群控制器(CC)可将CM频率加倍以产生用于其PE的时钟。
对于具有最大能量效率的实施方案,应当减少供应电压。其可例如减少到0.5V或可能甚至0.4V,但频率则需要减少,可能减少到二分之一。为了实现相同处理量,PE的数目则将必须通过加倍集群的数目而加倍,这将几乎加倍加速器的总硅面积。但每次推断的能量消耗将减少,这意味着尽管电压减半,但供应电流将减少。每mm2需要的供应电流与针对0.8V的设计相比将小得多,且生成的热量将减少甚至更多。不过,制造成本将增加。
通过0.8V供应电压,NoC可以1.2GHz计时且PE以2.4GHz计时,从而导致可达~20万亿次操作/秒(Top/s)=~10Tmac/s。
在下文中,将描述多个非限制性实施方案实例。
实施方案实例
实例-GPP及其接口
举例来说,类似于在根处的双核处理器的例如GPP等控制处理器可以配备有ISAL指令集,具有用于处理以下各项中的一者或多者的增加指令:
●加速器控制
●向量和矩阵运算
●数据压缩/解压缩
●信号处理(FFT)
●Java和Python解译
●接口
●测试
●初始程序加载
●安全性
●监控
●调试/除错。
举例来说,GPP可以是附录A中描述的类型的处理器的通用变体,类似于现有“Imsys”65nm IC的双核处理器,使用存储器共享的专利方法(美国专利8,060,727,“Microprogrammed processor having multiple processor coresusing time-sharedaccess to a microprogram control store”,其在此被援引加入本文)并且还包括在稍后的180nm测试芯片中实施的功率管理功能。
例如,其负责系统启动、调试/除错支持、诊断、故障监控、安全性、功率管理、I/O接口控制,以及数据流过程的执行的高级控制。
其可以具有固件ROM存储器,所述存储器具有用于上文所提到的功能的特殊微码且实施软件指令集架构(ISAL+ISAJ)以分别用于其LLVM标准指令集和用于Java/Python的直接字节代码解译。大部分微码是经良好证实的,且可以通过合适的修改和重新编译来使用。
ROM还可包括软件层级代码(从C/C++或其它语言编译的固件),用于I/O控制、基本OS功能等。
在此实例中,用于GPP的主存储器(PM)也是片上的。GPP将其视为一个128位宽存储器,从其可读取含有多达16个指令字节或数据字节的128位微指令或相同大小字,或者其可写入或读取-修改-写入多达16个数据字节。不过,举例来说,PM可以包括ROM(如果这是16Kx 128,则其<0.56mm2)和四个128位宽SRAM。当GPP逐步通过其PM地址范围的RAM部分中的连续地址时,在其逐步通过地址到SRAM实例之前其逐步通过SRAM实例数目。
PM的RAM部分具有到加速器的中央总线的512位宽接口。当通过此接口传送数据时,传送的四个128位字将具有从GPP所见的连续地址。
通过此接口,GPP可有效地在根存储器中读取和写入,且当与主机系统交换数据块时可使用根存储器作为缓冲器。其可经由根存储器发起NoC与高速接口(包含DDR)之间的参数和数据的高速传送,但自身无法以此数据速率读取或写入。GPP可发出命令且读取系统的根部分中的低层级控制器的状态,且经由NoC还到达集群控制器且间接到达PE。
GPP可经由低层级控制器使用所述两个网络来询问和控制PE,例如用于调试/除错。因此,其可寻址集群存储器(CM),且通过访问存储器映射的寄存器而与给定PE且与集群控制器两者通信(例如,以得到请求注意的PE的ID)。
CM接口处的逻辑对用于此的特殊地址进行解码,即,存储器映射的寄存器用于通过NoC直接访问PE。这些地址在接近于0的范围中,默认微程序开始地址也在其中。
统一存储器
举例来说,GPP可以具有两个核心,所述两个核心以专利方式(美国专利8,060,727)共享控制存储和主存储器。通过又一新的开发,这些也是统一的,意味着微码包含于主存储器中。统一存储器包括作为一个存储器进行存取的ROM和SRAM,其中ROM和SRAM占用不同的地址范围。
在特定实例中,微码中的一些是用于上述功能的专用经优化代码,且其它微码实施软件指令集架构(ISAL+ISAJ)以分别用于LLVM优化标准指令集和用于Java/Python的直接字节代码解译。许多的此微码是经良好证实的,并且可通过仅小的修改和重新编译来使用。
举例来说,统一存储器可以是128位宽并且可以高频率存取。通过使用可部分地同时存取,即具有部分重叠的循环时间的若干存储器实例,对SRAM字的存取频率有时可高于每一存储器实例的最大SRAM存取频率。这特别适用于存取微码。每一核心具有用于微码的缓冲器。其将在需要时通常将128位微指令的序列传送到此缓冲器。最经常地,这将是用于实施不足够小和/或足够频繁以包含于存储器的ROM部分中的指令的微码。此情形的一个重要优点是微码的持续开发不受专用微码SRAM的大小的限制。针对软件和数据需要的主存储器始终大于针对专用微码SRAM的合理的存储器。
缓冲器中的微码的替换由ROM中的微码控制,有时是自动控制,稍微类似于Imsys的JVM实施中的评估堆栈缓冲器的自动微编程处置,且有时通过由编译器插入的命令来发起。
在一特定实例中,ISAL指令集含有超过1100个操作码,且指令可以包含一个或多个字节,从不多于16个。编译器将目标代码设置成128位字的序列,各自含有尽可能多的指令可被打包到字中,即,指令从不越过16字节边界。
GPP核心将此类字读取到预取缓冲器中,所述核心从所述预取缓冲器读取要执行的指令。
举例来说,ROM不仅含有微码。其还含有软件层级类型的代码(从C/C++或其它软件编程语言编译的系统软件),以用于I/O控制、基本OS功能等。
因此,片上统一主存储器(PM)被GPP视为一个128位宽存储器,从其可读取含有多达16个指令字节或数据字节的128位微指令或相同大小字,或其可写入或读取-修改-写入多达16个数据字节。不过,PM可以包含ROM(如果这是16K x 128,则其<0.056mm2)和四个128位宽SRAM。当GPP逐步通过其PM地址范围的RAM部分中的连续地址时,在其逐步通过地址到SRAM实例之前其逐步通过SRAM实例数目,这允许较高存取频率。逻辑检测在相同实例中连续存取是否完成且相应地调整存取时间。
外围接口
可包含或至少提供用于IM3000的外围接口的所有逻辑和微码作为可选的IP块。这包括在Imsys Velox和一些Qulsar产品中在片上或片外可用的接口中的任一个,例如,视频/音频输入/输出、高效可配置高分辨率TFT显示器驱动(例如,用于病理工作站),和具有IEEE1588时戳的千兆以太网(可能在汽车系统中受到关注)。核心中的一个负责加速器的内部操作,另一个用于I/O、系统监控等。
芯片上将可能不存在来自IM3000的任何模拟电路,但仍可使用Σ-ΔADC和DAC设计的数字部分;其串行位流接口则将分别连接到外部积分器/比较器和滤波器。这是在现代微控制器中最近介绍的技术(例如参见来自ST的AN4990,“Getting started with sigma-delta digital interface(以Σ-Δ数字接口开始)”)。
一些GPIO将保留,具有到定时器系统的连接以用于PWM输入/输出、时间戳等,且SPI/I2C和UART串行接口也将保留。
DRAM接口也应当保留于硅中以简化旧版固件,虽然其可能在未来加速器系统中消失。(逻辑的成本是低的,因为所有其复杂性是在微码中,且芯片将具有空间容纳许多板(pad)。)
将不需要10/100Mbps以太网,因为我们而是会选择1Gbps以太网,其迄今为止仅实施于FPGA中。两者都是Imsys设计且经良好证实。
来自这些设计的CRC硬件可能还可以用作单独块,更一般来说,转变成类似于Hyperstone的“Galois Factory coprocessor”的东西,其可用于校验和的高效计算。这可能是值得的,因为需要检查大量的固定参数信息。
调试/除错、启动、功率管理、非易失性存储器
调试/除错端口将存在。还将存在用于可被选择作为引导源的相关闪存芯片的接口,包括eMMC和SPI闪存。不过,如果数百万的参数需要非易失性存储器,则将使用具有较高带宽的装置,例如SSD,且这些可通过PCIe或USB 3.2存取。还应当考虑可用于GF 22FDX制造工艺的片上MRAM。
GPP子系统将具有其自身的电源域;将可能在任何别的东西被供电之前对其供电。存在至少一个第3方标准电池库,用于切换IC的不同部分的供应电压并改变偏置电压以得到功率消耗与性能之间的最佳折衷,并且GPP会根据需要使用此类电池用于控制芯片的不同区的操作点。GPP还会测量芯片温度并且会将其考虑在功率管理中。
GPIO和SPI接口将可用于控制外部电源,以确保安全启动和操作。IO总线将被带出,从而允许I/O系统的外部扩展以用于DMA和经编程I/O。这将在具有加速器IC的集群的系统中例如在当FPGA连接于根处时情况下使用。
DMA
DMA控制器可以使用软性划分成若干FIFO缓冲器的缓冲存储器,每I/O通道一个缓冲器。大小和方向由微码设定。例如,10/100Mbps以太网使用两个输入通道和一个输出通道。每一通道具有:I/O侧,由自动逻辑与外部装置交换请求/确认信号来控制;以及由微程序控制的处理器侧,其监控计数器状态而不涉及软件。将修改DMA系统以使得可创建预留于512位宽根存储器中的FIFO缓冲器区域,且通过这些缓冲器将可能设置I/O单元之间以及I/O单元与NoC之间的传送。此类传送不应通过GPP,但此处理器处理对其的高级控制和监控。GPP可经由其主存储器向/从这些缓冲器、并且还向/从根存储器的任何其它部分传送数据,所述主存储器可通过中央总线与根存储器交换数据,每次64字节。
DDR
DDR接口可以是第3方DDR5接口块。DDR5是今年将变为可用的极大地改进的一代产品。DDR5部件可以是16位宽,并且在高达12.8GB/s带宽下可具有多达8GB容量。标准模块具有两个独立通道,每一通道32位宽,且在高达51GB/s总带宽下可具有多达64GB容量。
我们也可能需要考虑具有用于DDR4的替代接口,因为我们不知道何时将引入用于汽车温度范围的DDR5。(DDR4可用于高达125℃。)此处我们针对两个情况主要选择16位宽度,这意味着我们使用一个部件而不是模块。一个部件可给予我们用于此大小的系统的足够容量和带宽。应注意,我们可以从这些系统中的若干系统构建更大系统,通过PCIe接口“在根方向上”扩展。在此扩展的系统中,根可由高端FPGA控制且使用较大存储装置,例如,多个DDR模块或高带宽存储器(HBM)堆栈和/或通过以太网的远程DMA(RoCE)。
应注意如果使用标准DDR模块而不是单个部件,则根存储器容量较不重要,因为DDR可接管其许多作用而不会降低速度,但DRAM存取比对片上RAM的存取消耗更多电力。
DDR5标准中包含对错误校正码(ECC)和错误检查和擦除(ECS)的片上支持。假定其类似于GDDR5中那样工作,其基于64位突发产生ECC的8位,即针对16字节的每一序列2个字节,且由于其构建到芯片中,因此即使我们使用仅一个部件而不是具有4或8个部件的模块,它也应当工作。据推测,整个奇偶校验位生成和分析是内置的。(“DDR5的特征还有单裸片错误校正码、封装后修复、错误透明度模式和读取/写入循环冗余校验模式。”)
用于外部I/O的接口块
以太网
如所提到,在无进一步开发的情况下,GPP可配备有对于IM3000处理器存在的经证实接口中的任一个。这包含千兆位以太网(包含精度时戳,其可用于汽车以太网)。
对于较高速度以太网(10G/25G/100G),第3方IP块将介接到加速器中的512位中央总线。芯片边缘将具有用于两个(?)SFP28端口的连接,所述端口可用于两个以太网替代方案。
高速PCI(PCIe)
将使用用于5.0代的第3方接口块。其带宽是每道3.94GB/s。四个道将是足够的;总带宽则将是15.7GB/s。非易失性存储器可附接到此接口;现在存在具有多达5GB/s的可用的SSD。
USB 3.2和USB4
这作为第3方IP块也可能受到关注。USB 3.2是新的极大地改进的一代产品。其使用新的紧凑型C连接器,且可传送多达2.4GB/s且在任一方向上供应电流。其可以与许多种类的外围设备(包含用于监控器的HDMI转换器)一起使用。建议在芯片上包含两个USB 3.2接口,或可能更适当的,包含作为下一代进一步改进的标准的USB4。
实例-将GPP连接到集群的网络
用于控制和数据的网络是分开的,但共享时钟信号和物理路由。它们可以包含以下各项中的一者或多者:
●控制(标签)网络
●NoC寄存器和控制器
●开关块
●数据通道。
实例-控制(标签)网络
此网络用于传送命令和状态信息。这可以涉及将在NoC上完成的数据传送,或集群控制器的控制,所述集群控制器处置CM及其到集群的PE的接口。
标签网络使用位串行通信且被组织为分层树,在每一分支点中具有逻辑(用于向内线)。其将二分之一双工1位宽通道添加到二分之一双工8位宽数据通道的1到64集束。
在连接到集群的最外链路中,存在一个8位宽数据通道和一个1位宽标签/控制通道,但在树的下一层级中,存在两个8位宽数据通道和仍然仅一个标签通道。对于更接近于根的每一层级,数据通道的数目加倍。最终,在树的树干中存在64个数据通道和一个标签通道。
用于数据通道的时钟线--每个链路中的向外时钟和向内时钟--也用于标签网络。放大和再同步对于数据通道和标签通道以相同方式进行。不过,数据通道信号在树的分叉点中不改变,它们仅被转发,而传出标签信号复制到两个传出分支,且向内标签信号通过求或而组合。
数据传送的开始
虽然两个网络(即控制网络(TagN)和数据网络(NoC))共享资源且一起路由,但在任一时间点在它们上传送的内容一般不直接相关。不过,存在一个例外--NoC上的数据块传送的启动。当用于数据传送的所有需要的控制信息已通过标签线传送并且根想要触发实际传送时,其发出短开始命令。当这结束时,数据传送开始。如果集群控制逻辑的高效解决方案需要,则在传送第一字节之前可存在固定延迟(几个时钟循环)。集群控制器已经知道传送的长度(始终为16字节的整倍数)。发送方和接收方进而知道传送何时完成。
NoC寄存器和控制器
通过由根时钟(1200MHz)计时的高速控制逻辑-有限状态机(FSM)在低电平下控制高带宽数据传输。此控制逻辑通常包含于开关块中。所述控制逻辑从GPP的“I/O总线”接收简单命令且向其递送状态信息,所述总线是直接由GPP微程序控制且由指令集中的I/O指令支持的简单20信号接口。
NoC寄存器的目的是为开关块和NoC通道保证用于任何传送的完整时钟循环,无论哪一个总线客户端与NoC通信。另一重要目的是在广播期间保持数据。
从中央总线或从开关块加载寄存器。
这些块和寄存器和两个网络由上文所提到的控制逻辑控制,所述控制逻辑还选择哪一者应当驱动总线以及哪一种模式应当用于开关。
开关块
开关块可以被视为片上网络的部分。除上述控制逻辑之外,此块还可以包含例如512个(更一般来说J个,其中J是大于或等于2的整数)更多或更少的相同开关,以及用于控制那些开关以支持下文描述的各种传送模式所需要的额外逻辑:
1.广播
2.在RM或DDR中存储CM数据
3.将所存储数据取回到CM(还用于初始图像加载)
4.交换重叠数据
5.超立方体。
数据主要在集群存储器与片上根存储器(RM)或DDR之间传送。DDR的替代方案可以是经由例如PCIe或高速以太网存取的其它存储介质。特别对于模式1,非易失性存储装置(闪存)可用于参数。
对于模式1和3,方向是朝向集群向外,对于模式2,方向是从集群向内,而对于其它模式,方向是向内紧接着向外。
举例来说,RM可以是512位宽且通过根时钟(1200MHz)计时,并且一个此类RM字可在每一时钟循环中由NoC通道传送。字随后划分成64个字节,每一集群一个字节。
下文描述NoC数据传送和对应操作块及其使用的不同模式的实例:
模式1
开关块具有专用于支持广播的某种逻辑。这是8位宽多路复用器,从512位(64字节)宽NoC寄存器每次选择一个字节且将其并行地发送到所有64个集群。每一集群从而以全带宽例如1200MB/s接收数据,总共77GB/s,而NoC中枢从例如根存储器或DDR读取仅18,75百万字/秒,即使用<1.6%的中央总线的循环。
使用广播用于完全连接的层
完全连接的层的高效处理需要所有集群交换少量数据,通常为一个字节,使得每个集群在其存储器中得到所有此数据。这可以通过使所有集群首先同时将其字节发送到NoC寄存器(如模式2中),并且接着通过广播接收所有64个字节(模式1)来容易地实现。如果需要多于一个字节(如今已不常见),则此过程当然可以重复。
模式2和3
模式2用于从集群发送数据以用于存储于RM或DDR(或可能连接到PCIe的外部存储装置)中,而模式3稍后用于取回所述数据。每一集群将使其数据存储为一个字节列,即在许多64字节字中的每一中的某一字节位置中。此次序对于经由NoC的取回是完美的,即使其原本可能不方便。
在所有集群与存储器之间交换数据。每一集群保存一些数据(全部同时保存相同的量),并且接着它们取回相同数据。这类似于给予每一集群其自身的辅助存储器,一个字节宽,其中所述辅助存储器可存储数据,并且接着以相同次序(或在需要的情况下可能不同的次序)取回数据。这不是用于从外部接收图像或递送最终结果的自然次序,因为每一512位存储器字含有对于集群中的每一个的一个字节。
集群无需知道在何处进行存储的地址(对于所有均相同)。根存储器由若干专用地址计数器中的一个寻址,所述计数器可由其相应用户(控制器)加载且(可能)读取。访问存储器经常通过自动地步进计数器来关联。
存在存储多个数据字的两种自然方式。地址计数器硬件可容易地支持这两者。一种是LIFO(逐字地后进先出),类似于在堆栈上放置对象,其在一些情况下较简单(参见模式4),但存储器字是在不同方向上写入和读取。另一种是对每一存取字始终增加地址,但这需要更多的管理。存储器则经常划分成可以被分配和解除分配的若干扇区。
模式4
对于2维和3维卷积,区需要向右一个步长发送一些数据,且向下一个步长发送一些其它数据。这是需要与右边和下方的相邻区共享的重叠边缘数据。另外,需要共享斜向右下的拐角元件,但这可以两个步骤(右+下)来完成。举例来说,开关块可以包含512个开关,其类似于具有共享控制的铁路道岔工作。举例来说,三个数据传送设定可以用于卷积神经网络或类似数据流应用的执行:
●无改变(正常设定);
●如果是出站,则在正x方向上移动到下一区,否则相反;以及
●如果出站,则在负y方向上移动到下一区,否则相反。
第一设定用于所有传送,除了相邻区之间的重叠数据的交换之外。使用此正常设定,所有集群可使用完全NoC带宽,即每集群1200MB/s同时存储和取回根存储器中的数据,总计~770亿字节/秒去往/来自根存储器。
使用第二和第三设定,消息可在区之间传送。这是模式4。
所有区使用正常设定将其消息(整数数目的集群存储器字)一致地发送到根存储器,并且接着将开关设定为“右”或“下”。消息随后通过开关块传送回到所需目的地,且将开关复位到正常。通过使用第二设定或第三设定用于向根存储器传送且使用正常设定用于传回,可以沿相反方向进行传送。
应注意,对于传送多个字(即,每集群多个字节,当传送集群存储器字时将始终是这种情况),LIFO堆栈方式的存储在此情况下是合适的。
模式5
即使对于典型CNN推断过程不需要,超立方体类型的数据交换在一些算法中也是有用的。这可通过一组多个(例如,6个)设定来实现。关于如此的超立方体构思的更多信息,可参考...。例如,对于所有a、b、c、d、e,特定设定在具有二进制ID号abcde0与abcde1的集群之间交换数据,这意味着集群#0和#1交换数据,而且#2和#3交换数据,且#4和#5交换数据等等。每一偶数集群与具有相同ID号的集群交换数据,除了其最低有效位是1外。另一设定以相同方式工作,除了编号为abcd0e的所有集群与具有相同a、b、c、d、e的编号为abcd1e的集群交换数据外。其它设定以相同方式工作,具有其它的位位置。因此,六个设定中的第一个在偶数集群与奇数集群之间交换数据,而第六设定在32个最低数字与32个最高数字之间交换数据。
通过使用这些设定,我们可以在七个循环中让每个集群从其在6维超立方体中的6个最近相邻者中的每一个接收一个字节。第一循环将一个字节从每一集群传送到NoC寄存器,且随后六个循环将通过六个不同的成对交换而复制回。
NoC网络的数据通道的实例
NoC通道在根与集群之间传送数据字节。在根处,源/目的地是512位NoC寄存器,其中每一字节位置对应于64(M)个集群中的一个。在每一集群中,目的地/源是集群控制器(CC)中的16个八位寄存器中的一个。
这16个寄存器是按顺序使用的,且当它们都已从NoC通道接收数据时,累积的128位字(16x8)被写入CM。如果沿相反方向传送,则所述16个寄存器从CM加载且其内容随后通过通道按顺序传送。
为简单起见,NoC传送涉及所有集群(除非一些集群被停用而不参与),且每一集群同时做与所有其它集群相同的事。
网络的路由
图11是示出PE阵列及其根系统的一半的实例的示意性布局草图,包括RM、GPP和接口。第二半部在右边,仅示出其小部分。两个半部是相同的,除了其到根的网络链路的方向不同外。在此实例中,1024个PE(512x 2)由NoC连接。虽然具有不同结构,但NoC数据网络和标签网络是一起路由的。
例如,可通过将两个512PE块(各自具有一对PE,类似于双核心块)放在一起,用分支点替换中央系统,并且接着用新中央系统用更大的RM复制上方或下方的所得1024PE块作为其间的水平块,来构建2048PE系统。这可以重复,水平地复制,再次以竖直定向的中心块创建4096PE系统,类似于图11中所示。
举例来说,网络树在每一端点处连接集群平铺块(在其中点),且每一平铺块具有32个PE对。所有集群连接具有到根连接的相同路径长度。每一CM划分成十六个2Kx128位SRAM实例。PE对和CM接近于CC,其NoC连接在平铺块的中间。在中间还存在用于CC和所有64个PE的时钟发生器。其从NoC连接得到其时序。每一PE将存储器实例视为具有128位的32K字的一个存储器。
在此实例中,NoC是连接开关块与64(或更一般来说K>2)个集群的星形网络,具有连接到每一集群的(8位宽)信号路径。在集群末端,数据向/从各自为8位的16个寄存器中的一个传送。这些一起形成16字节寄存器,所述寄存器在简单仲裁器(也被称作分配器或存取控制器)的控制下在某些时间点与集群存储器交换数据,所述仲裁器还控制集群存储器与共享所述集群存储器的64个PE之间的传送。与集群存储器和仲裁器相关联的还有多路复用器/多路分用器(或对应)逻辑,其基于多循环传送中的当前状态而选择8位寄存器。
举例来说,8位宽NoC路径或通道中的每一个是点对点连接。由于通信仅是二分之一双工,因此两个方向可以使用再生点之间的相同信号线。不过,接收端中的空闲驱动器将可能添加到负载,这意味着将需要较高信号电流。可能较好的替代方案将是使用两条线,这两者仅驱动接收器输入。未使用的驱动器则应当在沿相反方向的传送期间将其线驱动为低。所述线将随后充当屏蔽件,从而允许线更靠近在一起。这将恰好类似于两个标签线,在分叉点中以不同方式组合的那些除外,而NoC数据通道仅被转发/向前。
在一特定实例中,数据通道信号可以在集群平铺块之间以树状模式路由,且它们是在沿着其路径的每个分叉点处由触发器(或消耗较少电力的锁存器)使用与数据信号一起行进的时钟信号来再生。时钟和数据信号还在这些点之间的每个平铺块拐角中放大。这允许与在平铺块中内部使用的数据传送速率一样高的数据传送速率。由于再同步带来的增加时延并不重要,因为典型数据块是大的。
根系统在数据通道的另一端中使用相同频率。这应当也不是问题,因为根逻辑的尺寸不大于集群平铺块,且GPP构建于与PE相同的基本处理器核心上。
在计算机技术、电子器件和同步数字电路中,时钟信号在高状态与低状态之间交替,且类似于节拍器而用于协调电路的动作。
通常,时钟信号由时钟发生器产生。虽然可以使用更复杂的设置,但最常见时钟信号中的一个是具有50%工作循环的方波,通常具有固定的恒定频率。使用时钟信号来进行同步的电路可在上升沿、下降沿或在双数据速率状况下在时钟周期的上升沿中和下降沿中变得有源。
具有足够复杂性的大多数集成电路(IC)使用时钟信号以便使电路的不同部分同步。在一些情况下,可能需要多于一个时钟周期来执行动作。随着IC变得更复杂,向所有电路供应准确且同步的时钟的问题变得越来越困难。
时钟信号还可以被门控,即,与启用或停用用于电路的某一部分的时钟信号的控制信号组合。此技术经常用以通过将数字电路的部分在它们不在使用中时有效地关闭来节省电力,但这样的代价是复杂性增加。
在实例实施例中,来自根的时钟信号包含于信号集束中。信号是对称的,且其频率是根和集群平铺块时钟频率的二分之一,但其两个边缘用于对通过通道的字节传送进行计时。
出站(outbound)时钟由集群接收和使用,不仅用于从NoC进行接收,而且用以产生用于集群控制器(CC)和CM的内部时钟。CC还接收与第一时钟同步的较高频率时钟信号,且其将两个时钟分发到所有其PE,所述PE在实例系统中使用两倍的CM频率且还对于逻辑的部分使用四倍的CM频率。
当NoC将方向改变为入站(inbound)(此改变通常通过首先进入空闲状态而完成)时,集群将使用其自身的时钟用于朝向根传送数据。此向内时钟信号将类似于向外时钟跟随数据线集束,但是沿相反方向。此时钟将在根处用于接收入站数据。
NoC传送
与信号线一起路由的时钟由传输侧产生,但在树的根处的星形的中枢发起所有传送。举例来说,PE独立于NoC而工作;它们不与NoC接触。编译器必须组织工作,以使得PE将在它们需要时和/或具有用以写入其结果的空间时存取CM中的代码和数据和参数。
应注意,NoC传送的时延(由沿着信号路径的信号的重复再同步造成)并不重要(由于高频率和大数据块);重要的是带宽是足够的。
举例来说,可能存在可为大规模的三种类型的传送,涉及在所有参与集群中的存储器容量的大部分:
1.将例如内核等代码和应用程序参数广播到集群的至少一子集或所有集群;
2.单独数据内容从根向集群的至少一子集或所有集群的传送(例如,当分发输入图像时或当从存储装置取回前馈层时);以及
3.将单独数据内容从集群的至少一子集或所有集群传送到根(例如,当存储前馈层或递送推断的结果时)。
在叶处我们实际上需要的带宽取决于在PE执行操作的同时我们通过传送可“隐藏”多少传送时间,当然还有我们可容许多少额外时间用于传送。举例来说,在开始将存在我们无法隐藏的一些传送。
在根处我们想要带宽至少匹配于我们将使用的(例如,DDR)存储器的带宽。举例来说,64位宽DDR5模块可具有多达51GB/s的带宽,而16位宽DDR5部件可具有12,8GB/s。我们的77GB/s的根带宽似乎是良好选择。如所提到,有可能通过优化供应电压和偏置电压的选择来在速度与能量效率之间做折衷。应注意,这些电压在系统的不同部分中可不同,且至少偏置电压可甚至动态地改变,即在推断过程的不同阶段中不同。
传送速率
如所提到,传送时延并不重要。不过,传送速率是重要的。如果CM内容再使用的次数较高,则NoC将不限制MAC运算可执行的速率。对于上述类型2和3的传送,我们可以随后在叶处适应较低带宽。
不过,在某些周期期间,例如,在输入图像的初始加载期间,当数据的缺乏阻碍处理时,NoC带宽将肯定影响总执行时间。
图像的初始加载可能涉及数据的特殊重新布置以便将此快速加载到集群存储器中。
数据对准
通过NoC的所有数据传送使用128位字。将参数块对准到NoC寄存器的宽度(512位),即四个128位字可能是实际的,这简化了广播,如用于开关块的模式1的说明中所见。广播则将仅使用512位字。NoC每时钟周期向/从每一集群传送两个字节,这意味着512位字将各自需要32个时钟周期。
实例-集群存储器和集群控制器
集群的框图
再次参见图10,集群控制器(CC)可以处理集群存储器(CM)以及到NoC和PE的接口。其从NoC CLK_OUT得到其时钟。其功能是由分别来自标签线和PE的命令控制。
集群存储器(CM)
举例来说,CM可以是32K x 128位存储器。其通过从来自NoC接口的向外时钟信号产生的CC时钟进行计时。到CM的时钟被门控,使得CM电流消耗被限于当不存取CM时的泄漏电流。
举例来说,对集群中的64(或更一般来说M)个PE,CM可以是共享随机存取辅助存储器,其中它们在其相应微程序的控制下读取和写入16字节扇区,类似于CPU如何读取和写入磁盘上的扇区。将PE示意图与ImsysIM3000的示意图进行比较表明了其对应于作为主存储器而不是辅助存储器的外部DRAM存储器;IM3000从DRAM读取指令。执行数据流应用程序的PE从CM加载微码以用于一个变换,例如卷积,并且接着在内部执行所述变换。此微码当执行时或进而激活的专用电路系统通过发出CC执行的请求而执行CM中的读取和写入存取。
微码加载通常不应当作为普通读取完成,因为相同CM存取还可用于以相同微码加载集群中的其它PE。这随后通过本地广播完成。当PE已指示它们准备好时,此功能由CC控制。应注意,本地广播功能与NoC广播完全不相关。
本地广播-也被称为集群广播-不仅用于微码,而且用于当应当向所有PE发送其它CM内容时将其它CM内容复制到PE,例如内核。
CM仲裁(分配/存取)
可每CC时钟周期存取CM一次,用于一个128位宽字去往或来自PE接口逻辑或NoC接口逻辑的传送。
从CC可见,PE接口逻辑服务于64(或更一般来说M)个PE且具有比NoC接口高得多的带宽。其因此需要物理上更宽。并且,序列短得多,从而需要更频繁地传送宽CM地址。因此,宽数据接口也用于地址,而不是如NoC设计中那样使用单独控制通道。
PE与CM之间的数据传送具有例如128位(16字节)的完全CM字宽,且可在每个可用时钟周期中传送一个CM字。NoC传送序列不得中断,且NoC接口逻辑需要的CM存取因此具有优先级。不过,NoC接口逻辑仅可使用至少16个循环/周期中的一个,因为NoC通道每时钟传送仅一个字节,CM字的十六分之一。这意味着在NoC传送期间16个循环/周期中的15个可用于PE传送而无需LRC。如果NoC不在作用中,则可使用所有循环/周期。在具有LRC的NoC传送期间,NoC将使用每个第17循环/周期用于CM存取,这意味着17个循环/周期中的16个可用于PE传送。
实例-NoC<=>CM数据传送
如果NoC不具有去往/来自此集群的进行中的传送,则将不会为其浪费循环/周期,且PE则自由使用所有CM循环/周期。如果存在NoC传送,则NoC将具有优先级,即使其可以由此从任何进行中的PE<=>CM传送序列窃取循环也是如此。原因是我们原本在NoC接口中需要FIFO缓冲器,因为高速NoC传送无法中断。
如果NoC和PE对CM存取都没有任何需要,则通过时钟门控来停用CM SRAM的计时以节省电力。
应注意PE<=>CM和CM<=>NoC传送从不直接相关;PE和NoC两者仅与CM交换数据,且彼此不直接交换数据。
在一特定实例中,CC的NoC接口部分将CM寻址为32K x 128,即具有15位地址且具有16字节数据宽度。NoC数据通道接口仅为8位宽,这意味着针对给予NoC的每个CM存取在16个CC时钟循环/周期中传送16个字节。
CC中的计数器选择16个八位寄存器中的哪一个与NoC 8位通道连接。此计数器还在NoC传送期间每16(或17)个时钟循环/周期发起这些寄存器与CM之间的完整128位字的传送。只要数据块长度计数器不是零,此过程就不中断地继续。计数器在环绕时递减长度计数器,所述长度计数器对每个传送的16字节块进行计数。块长度始终是16字节的整数倍数。
与由NoC使用的那些相比,即循环/周期的至少15/16(或如果使用LRC,则为16/17),其它CM循环/周期可用于PE<=>CM传送。所有时钟循环/周期可用于轮询PE。
可选的NoC错误校验:用于通过NoC传送128位字的16循环序列可扩展到17个循环。这是否应当进行是由根处的用于NoC的控制寄存器中以及还有其已分发到的CC中的位连同其它控制信息一起经由标签网络来控制。如果已选择扩展序列,则第17字节是基于16个数据字节的LRC代码(纵向冗余校验)。在过程中的一些点,NoC传送速率不需要是尽可能最高,且随后应当选择此模式。当然如果不需要尽可能最高的速度,则在其它情况下也可以选择此模式。其(至少)由监控服务质量的过程使用。如果需要高可靠性,则CC应当通过请求(通过标签网络)块的重新传送来对错误作出反应。
CM<=>PE与CM<=>NoC传送之间的差异
PE在星形网络中类似于集群自身那样连接。每一CM及其64个PE之间的传送可以是类似于NoC传送的单播或广播(多播),但它们是不同地执行且不与NoC传送直接相关。
已传送到CM的块在该处可用于PE,所述PE可在其自身微码的控制下在需要时读取所述块的部分。还存在本地广播功能,数据通过所述功能可从CM同时广播到所有其PE。
与NoC传送相比,每次传送少得多的字节,但相同数据经常传送多次。使用相同传送速率,但在每一传送循环/周期中传送更多位。CM=>PE流的平均总强度因此比根=>CM流的平均总强度高得多,但数据行进的物理距离短得多,因为本地读取或广播在集群平铺块内本地传送数据。由PE中的微码请求传送。
通过两个CC数据接口的传送因此是不连接的。本地广播需要快得多,因为相同数据多次传送到PE。较高带宽的另一重要原因是不同于CM<=>NoC传送,CM<=>PE传送无法隐藏,即,PE在它们参与此传送的同时无法执行MAC运算。
当CM中的块的一部分将广播到PE时,是CC控制所述传送,但恰类似于在单独传送的情况下,CC仅在已由PE请求之后这样做。在1.2GHz的频率下,每一CC与所有其PE并行地传送16个字节。在4096-PE系统中,PE一起每秒接收64*64*16=65536字节12亿次,即总计78.6万亿字节/秒,这比总NoC带宽高约十倍。
集群控制器(CC)
图12是示出包括集群存储器(CM)的集群控制器(CC)的实例的示意图。CC基本上是控制CM及其到NOC和PE的接口的逻辑电路。此块的任务可以包含以下各项中的一者或多者:
●使用(用于读取)用于传送的16字节宽接口和12亿次传送/秒,执行来自PE的读取和写入请求。
●执行从CM到PE的本地广播。
●执行且响应于来自标签线的命令。这些通常指定在根与CM之间要进行的NoC传送。当开始时,这些传送具有优先级且将从不延迟;另一方面,它们仅可使用CM循环的1/16或1/17。(它们对性能的影响因此是小的,前提是它们可“隐藏”,即当PE正在作用中进行其处理的同时执行。)
●产生用于其32个PE对的2.4GHz时钟,并且还在每当向内NoC数据传送和/或对向内标签线的响应或中断请求需要时产生向内NoC时钟。
实例-集群控制器接口
时钟信号
举例来说,向外时钟输入可以接收从根以NoC数据通道分发的1200MHz时钟,或从其中可产生1200MHz时钟的600MHz对称方波。这用于将时钟驱动到CM和CC,包含其NoC、标签和PE接口。还接收较高频率时钟信号且将其分发到PE,这在实例系统中需要2400MHz和4800MHz。
还将接收第二信号。取决于物理设计考虑,其具有CM时钟的频率的两倍或四倍,且旨在用于本地PE时钟信号的产生。PE逻辑使用CM时钟频率的两倍,但PE中的MAC单元使用PE时钟频率的两倍。两个时钟信号从CC传递到PE,通过将它们组合可创建用于其控制逻辑和MAC单元的两个时钟信号。
当在其标签线输出或NoC数据输出上发送时,CC输出从CC时钟驱动的向内时钟信号。
实例-命令/控制/标签接口(用于与根系统交换控制信息)
到CC的传入标签线,即向外标签线,是由向外时钟计时的串行数据信号。其传送命令和参数(例如,CM字中的地址和块长度)。在无限制的情况下,此传送可与先前发起的NoC传送重叠。不存在相依性,不同之处在于NoC传送在其可开始之前必须已经由GPP通过经由标签线到集群的消息进行设置。始终是GPP在两个方向上请求NoC传送,但入站传送是从集群端计时。
来自CC的传出标签线,即向内标签线,从集群向GPP发送消息。这些是中断请求或对先前在向外标签线上发送的命令的响应。向内消息由向内时钟计时,恰类似于向内NoC数据传送。仅在需要时驱动此时钟线。
实例-NoC接口(用于与根系统交换数据块)
图13是示出相关数据转换的实例的示意图。举例来说,NoC接口可以通过128个触发器传送数据,所述触发器从NoC侧可视为16个八位宽寄存器且从CC侧可视为一个128位寄存器。
取决于传送方向,2路多路复用器选择用于8位寄存器的输入。
当从NoC接收数据时,NOC字节POS计数器(NOC BYTE POSCOUNTER)将跟踪多少字节已经加载到寄存器中(每时钟循环/周期一个字节)。当从NoC接收时,解码器对计数器进行解码,且其输出对到每一8位寄存器的时钟进行门控,使得每次仅计时一个寄存器且进而节省能量。
当已经填充所有16个八位寄存器时,在下一循环中在由地址计数器产生的地址处将完整128位字写入到CM中。
如果未选择纵向冗余校验(LRC)模式,则这将是其中再次填充第一字节寄存器的相同循环(除非这是序列中的最后128位字)。如果选择LRC模式,则将存在第17循环,其传送LRC值。所述值存储到第17个8位寄存器中,所述寄存器随后与所接收16个数据字节的XOR累积和进行比较,且如果存在差则设定错误触发器。这将致使CC通过经由标签线请求中断而向GPP报告错误。
实例-PE请求仲裁器
图14是示出PE请求仲裁器的实例的示意图。例如,通过将关于其32位宽向内数据接口的信息输出到CC且升高请求信号(REQ)可以由PE来请求PE传送。此信号由PE请求仲裁器接收,所述仲裁器按请求PE的单元编号的次序处理请求,从最后服务的单元编号跳过到已激活其请求的下一单元的编号。
可能存在加速器系统的任何数目(多达64或更一般来说M个)已提出其请求的PE,且在检测到请求之前可能花费一些时钟循环/周期,在罕见情况下可达~80个。随后从通过桶形移位器同时查看所有传入请求的优先级解码器立即获得单元编号。
意图是按增加的单元编号次序服务于所有PE单元,前提是其全部已激活REQ信号(即,真)。当已服务于一个PE时,则应当服务于具有下一较高单元编号(从63环绕到0)的一个PE,前提是其REQ为真。如果不是,那么应当服务于下一个,前提是其REQ为真,等等。如果不存在作用中REQ,则不应当进行任何操作。不过,我们并不想由于步进通过为假的REQ信号而浪费时间。
举例来说,64个传入REQ信号可以馈送到或门以确定其中的任一个是否在作用中,且只有这样才启用下文提到的寄存器所述计时。但所述门不是必要的;在无所述门的情况下可避免不必要的活动。
考虑64个REQ信号按顺时针次序布置成圆,其中位置编号=单元编号。信号通过桶形移位器,所述桶形移位器的输出可视为单元编号的类似的圆。移位器由寄存器中的6位无符号数字控制。如果所述数字是零,则输出圆与输入一模一样,单元编号在相同位置。如果数字(假设称其为N)在范围1..63中,则所有输出单元编号在输出圆中逆时针移位N个位置。
桶形移位器输出馈送到优先级编码器,所述优先级编码器输出6位无符号数字。此数字可以是:
=1,前提是位置1中的信号为真,否则
=2,前提是位置2中的信号为真,否则
=3,前提是位置3中的信号为真,否则
…
=63,前提是位置63中的信号为真,否则
=0。
当正服务于一个单元时,其单元编号保留在寄存器中。其REQ信号因此存在于“输出圆”中的位置0。来自下一较高单元编号的REQ在位置1中,等等。
因此,除非所有REQ信号为假,否则优先级编码器的输出上的数字是在沿着圆的位置中顺时针到为真的下一REQ信号的距离,跳过其间的假REQ信号。通过将此数字添加到寄存器的内容,我们得到要服务的下一PE的单元编号。
如果请求FIFO已满,则PE请求仲裁器等待。当存在空间时,其将新单元编号计时到其寄存器中(除非预期更多字,如下所述),进而设定用于寻找下一请求的编号的新参考。
服务于PE请求
在FIFO中存储请求
请求仲裁器的寄存器中的单元编号控制收集网络(其为分发在PE阵列中以减少布线的逻辑门的树)且进而选择与传入请求有关的信息。此信息将被计时到32位宽FIFO中。
请求的第一字包含从选定PE的微程序到请求FIFO的请求类型代码。在写入的情况下,其还包含要写入的数据,如上文所描述。
在读取的情况下,在请求FIFO中不存在要写入的数据;仅使用一个字。目的地对请求PE是已知的。其可以是以下各项中的一者或多者:
●微码,在此情况下一个完整微指令从CM直接传送到PE的微码缓冲器。
●暂存器,在此情况下CM字传送到PE的存储器数据寄存器(MDR)块中的来自存储器数据(DFM)寄存器,并且接着在2个PE时钟循环/周期=1个CC/CM时钟循环/周期中传送到暂存器的一半中的16个连续字节位置。
●ALUREGS,也经由DFM,以与暂存器类似的方式。
如果所接收的字是自从仲裁器中的寄存器计时时起的第一字,即含有请求代码的字,则来自寄存器的单元编号连同通过收集网络接收的信息一起存储。举例来说,所述信息因此可以仅使用所述32位的至多26位,因为必须为单元编号预留六个位位置。
所述26位可以包含:
●用于请求类型的代码
●给出请求的长度的3位数字(读取由仅一个字组成,但128位写入总共由五个字组成)
●15位CM地址(可能更多)
单字请求,例如读取,将释放PE请求仲裁器以搜索新请求。
举例来说,128位写入请求将禁止到仲裁器中的寄存器的时钟,将长度加载到长度计数器中,随后通过收集网络从相同PE读取下一字,当存在空间时将其存储于FIFO中,且递减长度计数器。这将重复直到长度计数器为零。
每当接收到字时,ACK脉冲将发送到请求单元。PE应当随后撤下其REQ且自由改变其数据输出。在多字请求的情况下,PE和CC都知道有更多会出现,且不需要REQ信号来保持仲裁器指向相同PE。如果PE有属于相同请求的另一字要发送,则其紧接在ACK之后输出所述字,且在其输出上保持所述字直到其得到下一ACK脉冲。
执行请求
如果FIFO不是空,则将读取和处理最旧的字。
如果是读取,则所有需要的信息都在FIFO输出处的一个字中--PE单元编号和CM地址--且在CM中执行读取存取且将128位字发送到分发网络。通过所述网络的传送将在跟随CM读取循环的时钟循环/周期期间进行,但这是管线式的,使得来自PE单元的读取请求可以CM能够具有的完全最大时钟频率下执行。
用信号发送向PE的递送
举例来说,PE需要知道其DFM何时已从CC加载。接口中对于此应当不需要信号;PE可感测(通过微指令可选择的新条件)加载何时已完成,且在链接(多循环)读取请求的情况下立即照管DFM内容。
PE与CC之间的高带宽数据接口
为了保持64个PE的MAC单元在大部分时间忙碌--即向其馈送大量数据(例如,每秒大于3000亿个操作数)--CC必须具有到每一PE的多个(例如,128个)向外数据信号线。类似于NoC,这需要在我们可指定信号接口之前关于物理布局的一些考虑。
实例-CM与PE之间的物理连接
举例来说,考虑128个CM输出。CM中的读取循环在这些输出上产生一个128位字。这是16字节。假设我们想要所有这些字在一个循环/周期中传送到一个PE,且在下一循环/周期中出现的下一字传送到下一PE,等等。
假设我们集中于第一次提到的循环/周期。我们通过一系列开关将数据传送到其目的地。我们在循环的开始已经知道应当如何控制这些,因此通过每一开关的信号延迟仅仅是一个门延迟。举例来说,PE可以物理上布置为双核心块的一个或多个阵列,例如G x H阵列,其中G和H是等于或大于2的整数(例如,8x4阵列,或实际上两个4x4阵列),分别在CC逻辑的左侧和右侧上。第一组开关在CC中且将128位宽信号路径划分为两个树:左和右。开关在这些方向中的一个方向上引导信号,在另一方向上前进的信号并不从其空闲状态改变。第二组开关类似地将4x4半阵列划分为两个部分,且第三组将信号引导到至少2个(例如,4个)双核心平铺块的群组的中心(例如,4个双核心平铺块将对应于8个PE),其中每一所述平铺块在拐角中具有其在群组的中心处的连接。举例来说,可能存在128位宽8路多路分用器(DEMUX)将数据直接分发到8个PE。
除了目的地寄存器中之外,没有触发器被计时。没有信号改变(即,消耗能量),沿着作用中信号路径的那些信号除外。
不过,如所描述,此方法单独地并不支持向所有PE每循环/周期广播一个完整字,而这是我们想要能够做的。但对于广播也可以利用对此方法需要的所有信号线,放置于它们用于此目的的适当位置。有可能修改对在从CM朝向PE的方向上使用的开关的控制。举例来说,我们可以配置每一开关以使得其让信号通过两个输出。所有信号将随后通过到所有PE。不需要额外硬件。在广播期间消耗当然将较高,因为更多节点将改变。
当从CM读取时,我们将以类似方式对到接收器的时钟启用信号进行门控。如果进行广播,则将启用到所有接收器的时钟,但否则仅应当接收数据的PE使其寄存器被计时。
集群的物理布局
图15A是示出集群的物理布局的实例的示意性布局草图。这可能对于专用IC比对于FPGA更相关。集群的PE布置于两个矩形区域中,放置于集群控制器的相对侧上。举例来说,这些区域各自具有16个双PE。每一此类双核心块(在图中标记为DC)使所有信号连接(分发网络、收集网络和时钟信号)集中于DC块的一个角落,而四个所述块以其连接角落在一起进行放置。这些8个PE连接点(CC的每一侧上四个)通过形成两个阵列中的每一阵列中的树的信号链路连接到CC。
图15B是示出根据实施例的被实施为四个双核心平铺块的8核心块的电路组件的实例的示意图。举例来说,双核心平铺块可以是矩形,其开关接口在角落。这些角落可以随后靠近在一起放置,且通过多端口开关接合。包含开关的共享电路系统还具有时钟生成电路系统,用于产生用于四个双核心块的时钟信号。时钟发生器通常被锁定到从中央主控制器分发的参考时钟。
图15C是示出根据实施例的双核心平铺块的实例的示意图。在此实例中,每一核心是基于被配置成执行存储于共享本地存储器中的微码的控制单元。
每一核心对应于处理元件,所述处理元件被配置成执行微码以通过核心内的算术逻辑控制总体数据流应用程序的算术工作的专用部分的执行。在此实例中,存在NoC路由器,但这可以被将若干双核心平铺块连接到NoC的多端口开关代替。每一核心包含用于输入数据和/或内核参数的至少两个本地数据缓冲器。在此实例中,内核可以存储于ALU REG中,例如,以与存储于另一数据缓冲器(例如暂存器)中的输入数据进行卷积。举例来说,算术逻辑可在所有其RAM块中直接读取和写入。数据可在暂存器、本地存储器和DMA缓冲器之间以高速流式传输。
合适的传送宽度
举例来说,计算示出RefNet逐点层中的平均向量深度是187个元素(字节),且我们通过规划的暂存器设计针对此类平均向量对我们从CM读取的每元素(字节)执行14.6个MAC运算。
两个此类向量的点积通常在传送到CM之前转换成单个激活数据字节,但其计算需要例如187个MAC运算,且因此需要从CM读取平均187/14.6=12.8个字节。
因此,平均来说,每一PE从CM读取与其写入到CM的字节的12.8倍一样多的字节。从CM到PE的数据传送路径因此不需要与另一方向的带宽一样高的带宽。
我们可以从CM到PE并行地明确读取完全CM宽度128位(基于到暂存器的每字节的MAC、暂存器的编号,以及用于暂存器和CM的最大频率的预期比率),但写入可通过较窄通道进行。其应当是128位的合适的细分,且CC可以收集这些较窄部分字以形成将写入于CM中的完整128位字。
不过,虽然读取始终需要连续字节的长序列,但是对于写入不是这样。要写入的数据将每次一个字节创建,且在输出元素之间将存在许多循环/周期时间。PE可以组装要写入的16字节字,但即使这完成,我们也可以通过使从PE到CC的数据通道较窄来节省区域,且每次仅传送完整CM字宽的合适部分。此部分应当多于一个字节(否则总写入数据传送时间将长于总读取传送时间);其应当是至少2个但可能4个或8个字节。
由于必须支持1个字节的元素大小(其将是最常见大小),我们必须能够将单个字节写入到CM中。这样做的消耗最少能量的方式将是将一个字节传送到CC且让CC将所述字节在合适字节位置写入到CM中,而在所述字节位置之外不激活CM。这要求CM SRAM实例为8位宽或具有字节启用输入。
如果这些替代方案都不是合适的,则我们需要能够在CM中进行读取-修改-写入。这可以在CC中在内部完成,或者其可以通过首先经由PE的128位DFM寄存器进行读取,且接着修改该处的一个字节而完成。在要写入的下一字节将在同一16字节CM字中的常见情况下,回写可以等待直到稍后时间。CC将与此同时服务于其它PE,所述其它PE将通常进行相同操作。当PE以此CM字通过时,其执行针对一个CM字的写入请求。如果写入通道是2/4/8字节宽,则除用于传送写入请求和CM地址的一个初始循环/周期之外,此传送还将需要8/4/2个时钟循环/周期用于传送。
四个字节,即32位,似乎是从PE到CC的写入数据通道的物理宽度的良好选择。对于将使用包含请求缓冲器的相同物理资源的元数据(请求代码、地址、...),两个字节是不足够的。与使用两个字节相比,四个字节将写入传送花费的时间减少到二分之一,且减少到计算对应输出所需要的读取传送花费的时间的三分之一。八个字节在某种程度上节省更多时间,但收益可能不值得所需要的额外硬件。
使用向外数据线还用于向内传送将是可能的,但这将不会减少逻辑。这将节省用于线的一些占据面积,但不是很多,因为向内宽度是较小的。举例来说,其将节省20%,而不是如NoC的情况那样的50%。
信号传送的宽度因此通常是从CC向外128位(分发网络)和朝向CC向内32位(收集网络)。
分发网络
分发网络对于本地广播和单独读取都必须是高效的。在两种情况下,在每个CC时钟循环/周期中从CM传送128位的新CM字。对于本地广播,集群中的所有PE接收相同128位,而对于读取,当PE在附近同步中操作时经常充当循环(round-robin)计数器的在轮询机制中的寄存器可以在每个时钟循环/周期中提前且指出应当接收字的一个PE。
图16A是示出分发网络的相关部分的实例的示意图。该图示出分发网络的二分之一中的逻辑的示意图,即CC左边或右边的树。形成图15的布局中的树的线对应于图16A的示意图中的信号线。应注意在此实例中,示意图示出128个位位置中的一个位位置。示意图对于每一位置是相同的。左边的逻辑对PE编号的5个最低有效位进行解码且在需要时启用所有路径,所述逻辑由所有128个位置共享,且因而汲取的电力是可忽略的。到网络中的门的控制信号在数据位之前到达,使得由所传送数据位之间的转变造成的能量被限于所启用的路径。通过使PE单元编号在格雷码(Gray code)序列中前进,即每次改变仅一个计数器位位置,可以节省一些电力。
在本地广播的情况下,网络中的所有门打开,如示意图中所示(信号enable_all为真),使得数据同时到达所有PE。
收集网络
图16B是示出收集网络的相关部分的实例的示意图。举例来说,来自64个PE中的每一个的32个向内数据线形成收集网络。其用于传送对CC的请求以及将在CM中写入的数据。选择数据的门以与分发网络的那些门类似的方式分发,即在每一32PE阵列中存在:四个4输入32位宽多路复用器(MUXES),在4个双PE平铺块的群组中的角落的每一会合点处有一个;随后是将这些组合为两个信号集束的两个2输入32位宽多路复用器;随后是选择去往最终2输入32位宽多路复用器的信号的一个2输入32位宽多路复用器,所述最终多路复用器在两个32PE阵列之间进行选择。更一般来说,这对应于分层级的多路复用器的层次结构。
另外,存在来自每一PE的一个REQ信号和到每一PE的两个ACK信号。
实例-CM与PE之间的数据传送
分发网络(读取或本地广播)
例如并行的128位的数据在一个CM时钟循环/周期期间从CM读取,且在下一循环/周期期间通过若干层级中的驱动器传送到PE。在物理实施中这些驱动器可以是如图中所示的“与”门,但详细设计应当针对效率进行优化。存在用于每一位位置的驱动器树,其中CM数据位在根处进入。
在简单读取传送的情况下,在传送的循环/周期期间启用通过门的一个路径。路径是根据PE单元编号选择的,且位递送到所述PE的DFM寄存器的对应位输入。在向所有PE的本地广播的情况下,启用到所有PE的路径。
与简单地始终驱动所有目的地相比,此设计的优点是仅沿着实际上使用的路径消耗电力。
收集网络(请求,和在写入的情况下的数据)
在请求的情况下,请求代码的源是微指令中的字段。CM地址是从PE中的存储器地址计数器中的一个(对应于IM3000中的四组MEM地址计数器中的一个)获取。
在请求代码和参数的传送后,在一个或多个循环/周期中传送要写入的数据。所指示的字数目大于零,且这将致使请求仲裁器使用于收集网络的控制寄存器保持不变,直到指定数目的字已经传送为止。这通过用于多字广播和读取的相同机制来控制。
举例来说,要写入的数据可能是四个字,即一个CM字,其以四个部分传送。其通常是从寄存器集合ALUREGS或暂存器获取,复制到MDR中的DTM(到存储器的数据)寄存器,且从该处由收集网络获取。
实例-来自PE的请求
举例来说,请求被编码为32位字。这些是当CC已检测到来自PE的引发的请求标志时通过32位宽收集网络收集。位被编号为31..0。位#29、13和6是备用位,从而允许在需要时延伸字段中的任一个。位5..0仅由CB请求使用。
请求可能是链接的,使得在轮到下一PE之前可一起服务于一系列请求。这将需要请求字中的位。存在用于此的空间;当前为请求类型代码预留的三位中仅使用两位。在多字广播和多字读取请求链接之后通过分发网络递送128位字,并且以其数据构成写入请求的五个32位字通过收集网络传送也是这样。
请求代码可首先已经在到请求FIFO的输入处解码,但仅出于选择用于到FIFO的位5..0的源的目的。对于CB请求,选择收集网络位,但对于所有其它请求代码,选择单元编号寄存器的内容。当接收到数据字时,在写入(WR)请求后,选择收集网络位。
包含在WR请求后的数据字的请求穿过FIFO,且在其输出处它们被解码和处理,如下所述。
实例-集群广播(CB请求;到许多PE的相同数据块)
如果当CB状态为假时CC从请求FIFO读取此请求,则CC设定CB状态且从“请求者的数目-1”字段加载其广播计数器。
如果当CB状态为真时CC接收到此请求,则如果广播计数器=0,则其执行请求,否则其递减广播计数器。
执行此请求意味着从“CM地址”字段加载“用于PE的地址计数器(ADDR CTR FORPE)”且从“字计数-1”字段加载字计数器(框图中未图示),并且接着以全时钟频率从CM读取所请求数目的字,在给定地址中开始,通过分发网络将每一字同时(在当存取下一字时的循环/周期中)发送到所有PE(尽管仅请求者将通过使用其“启用广播”FF来启用其相应DFM寄存器的加载),且当这全部完成时复位CB状态。两个计数器对每一传送字分别递增和递减。
注释:
1.是最后的CB请求触发服务,但它们全部相同且它们进入CC的次序并不重要。
2.接收PE将知道它们何时已接收到序列。它们当其DFM已加载且接着在下一循环/周期中不再次加载时检测到此情况;这设定受测试且接着由微程序复位的PE中的条件FF。
3.如果所请求的字数目是一,即“字计数-1”是零,则仅一个字从CM传送到PE。这对于CC并非实际上是特殊情况,但对于PE是这样:如果其已请求此单字广播,则其可让其微程序继续直到其需要广播字为止,并且接着仅在其仍未到达时才等待。这不同于多字传送,因为微程序随后需要针对字的高频突发进行准备,微程序必须在所述高频突发到达时立即将其传输到PE中的内部目的地。
此请求的使用:
举例来说,PE当其需要接收其它PE也将需要且应当同时接收的微码或数据时发出此请求。当发出请求时,PE还设定向MDR块告知预期广播的触发器。如果此触发器未设定,即PE不参与广播,则当广播执行时将不加载DFM寄存器。
当CM中的128位字的块(微码或内核元素)待传送到所有参与PE时使用集群广播请求(CB)。通常,此块先前已通过NoC上的广播传送传送到CM(但也可能存在其它使用情况)。这两个传送是分开的;其它传送可以在其之间完成。从根传送到CM的块将经常是大的,且将通过集群广播或读取功能以小部分传送到PE。在集群内本地的这些传送中完全不涉及根。
通过集群广播,每一PE可按顺序接收若干存储器字,每时钟循环/周期一个字,且随后必须能够以所述速率将那些字传送到其目的地。微码缓冲器和暂存器是用于存储器字序列的广播的重要目的地。CC不需要知道PE在内部如何以及在何处传送所接收的字;这将在PE部分中描述。
当PE针对CB准备好时,其将通过CB请求向CC告知此情形,并且接着不再发出请求直到CB已完成为止。为简单起见,直到那时PE应当不进行任何动作。其DFM突然被加载对于它必须是没问题的,且这限制了它可以被允许做什么。甚至更多的限制是广播将是到微码缓冲器、暂存器或ALUREG的多字传送,且在那些情况中将在若干循环/周期中的每一循环/周期中加载DFM,且PE控制逻辑必须随后准备立即进行所需要的内部传送。
CB请求具有三个参数。它们包含CM地址和恰如读取请求的要传送的字的数目。对于CB特殊的参数是指定应当接收广播的PE的数目的参数。其可以全部是64,但其也可以更少,低至2。可能存在不涉及的PE,且它们应当能够在无不必要的干扰的情况下进行其工作。应当接收集群广播传送的所有PE发出相同请求,即,它们由CC接收的次序并不重要。
请求FIFO存储传入请求,且按次序处理从FIFO退出的那些请求。如由CC中通过第一CB请求设定且通过最后一个CB请求复位的状态触发器所指示,CB在作用中或不在作用中。如果不在作用中,且CB请求是从FIFO输出,则CC将CB状态设定为作用中,且开始计数CB请求。不采取其它动作。当CB处于作用中且从FIFO接收到另一CB请求时,则递减计数器。也是当CB处于作用中时,照常地服务于其它请求。当CB请求使计数器到达零时,执行此CB请求--即数据从CM读取且通过分发网络传送--且状态触发器被复位。
已请求CB的PE已设定指示此情况的触发器,且分发网络将信号分发到所有PE,告诉它们这是CB传送。此信号无论如何在整个网络中都是需要的;其为图中被命名为“启用全部”的信号。其输入到每个双PE平铺块的角落的4向多路分用器(DEMUX)。仅已设定其自身触发器的PE将加载广播数据字。
当CC已经解码请求时,其将用来自请求的字计数参数加载其PE侧字计数器(必须与其NoC侧计数器分开,因为PE和NoC传送是独立的且将重叠)。其将随后针对传送的每一字递减此计数器。当计数器到达零时,请求的处理完成,且“CB作用中(CB active)”和“启用_全部(enable_all)”触发器被复位。
在PE的DFM寄存器中接收字。如果它们多于一个,则它们必须立即(即,在下一时钟循环/周期中)在PE内移动。暂存器、ALUREGS、微程序存储器和配置寄存器是用于CB传送的正常目的地。PE内的传送仅涉及PE且将在下文的PE部分中描述。
实例-读取(RD请求;PE负载数据块)
执行此请求意味着在给定地址中开始从CM读取所请求数目的字,通过分发网络将每一字发送到请求PE。对于CB以相同方式加载和使用两个计数器。除了所需的一个路径之外,通过分发网络的所有路径保持空闲以节省能量,且仅接收PE启用其DFM寄存器的计时。
对于上述CB请求的注释2和3也适用于此请求。
此请求的使用:
类似于CB,PE输出具有CM地址和字计数的读取请求(RD)代码。从PE中的四个地址寄存器中的一个递送地址。PE随后等待,准备好以全CM时钟频率接收128位字的流。
CC连同请求PE的单元编号一起存储插入最右边位置中的请求,作为请求FIFO中的一个字。当此字退出FIFO且经解码时,执行CM读取循环/周期,且来自CM的数据字通过分发网络输出,其中到请求PE的路径被启用。没有其它路径被启用,因为由CB使用的启用全部信号为假。
字序列从CM读取且传送到请求PE,如上文对于CB所描述。字的计数以相同方式进行。
在PE的DFM寄存器中接收字。如果它们多于一个,则它们必须立即(即,在下一时钟循环/周期中)在PE内移动。暂存器、ALUREGS、微程序存储器和配置寄存器是用于RD传送的正常目的地。PE内的传送仅涉及PE且将在下文的PE部分中描述。
实例-对CM的写入(WR请求:PE存储数据字)
当从FIFO接收到此请求时,CC检查其在FIFO中是否还具有至少四个字。如果否,那么其等待。当条件为真时,其将给定地址从“CM地址(CMaddress)”字段加载到其“用于PE的地址计数器(ADDR CTR FOR PE)”中,且其从FIFO读取四个32位字。为了对这些字进行计数,其可使用用于CB和RD的字计数器。“字计数-1”字段因此含有000011,即数字3。这四个字被加载到128位“数据到CM(data-to-CM)”寄存器,所述寄存器在框图中将插入于FIFO与“写入数据多路复用器(WRITE DATA MUX)”之间。随后执行CM写入存取。
此请求的使用:
PE输出具有CM地址的写入请求(WR)代码。从PE中的四个地址寄存器中的一个递送地址。这将致使四个32位字通过收集网络传送,且插入到FIFO中,直接跟随请求字,所述请求字当插入到FIFO中时被补充有单元编号,恰如同其它请求。
PE请求仲裁器保持于单元编号上,且收集网络进而将来自PE的路径保持打开,直到全部五个32位字已经插入到FIFO中为止。可能需要一个或多个额外循环/周期,因为FIFO可能不立即具有用于全部五个字的空间。在此情形下,CC逻辑不得被阻止(即,必须可用于/被启用用于)继续读取和处理来自FIFO的较早请求。
当CC逻辑已从FIFO读取所有五个字时,其将由四个32位字给出的128位数据在给定地址写入到CM中。
其随后用信号通知PE写入已执行。
取决于如何实施CM,存在至少两个进行写入的方式。如果其使用32位宽SRAM实例,则四个32位字中的每一个可如其从FIFO读取那样写入到合适的SRAM实例中。如果CM由128位宽SRAM构建,则需要寄存器,其中128位字是从四个较小字组装。
实例-读取-修改-写入(PE存储字的部分)
将经常关注在CM中写入少于一个128位字。存在这样做的一般方法,即通过使用RD和随后的WR,以及在两者之间进行DFM内容的任何(微程序控制的)修改。
可能需要以较少数据传送活动来这样做,例如,通过连同请求代码和地址一起仅包含数据字节和字节位置,且让读取-修改-写入在CM附近本地执行。这可以涉及在上文的WR的说明结束时提到的128位寄存器。CC逻辑将随后从CM填充此寄存器,不同之处在于将实际上从所传送数据字节得到其内容的选定字节位置,并且接着将组装的字写回到CM。
实例-处理元件(PE)
在特定实例中,PE(核心)成对布置。举例来说,微程序存储器可以在所述对中的两个PE之间共享,且时钟驱动器可以在例如四对PE之间共享。存在多个新颖特征,包含由核心共享的时钟产生。
图16C是示出具有PE对(即,双核心)的子系统的实例的示意性框图,且其还示出PE(核心)如何通过一组信号接口连接到集群控制器。
每一核心与一个或多个存储器数据寄存器(MDR)介接和/或协作,所述一个或多个存储器数据寄存器又经由收集网络和分发网络连接到集群控制器。
在此实例中,两个核心共享微程序存储器。每一核心进一步与用于数据和/或应用程序参数的暂存器(也被称作本地缓冲器)、MAC电路系统(包括一个或多个MAC单元)和用于接收MAC电路系统的输出的FIFO缓冲器介接和/或协作。
图16D是示出集中于新的所谓向量引擎的具有两个MAC块的PE核心的实例的示意性框图,还有所使用地址计数器的细节(它们是相同的且独立地受控制)。
图16E是示出也集中于新的所谓向量引擎的在此具有四个MAC块的PE核心的实例的示意性框图。
实例-新的向量乘法资源(暂存器+MAC)
具有地址计数器的暂存器SRAM
例如,此处假设集群控制器(CC)和集群存储器(CM)以fc=1.2GHz计时且PE以2*fc=2.4GHz计时。每一乘法器以4*fc=4.8GHz的频率开始乘法。在FPGA版本中频率将较低,但具有相同的关系。举例来说,两个地址计数器中的每一个指向一个32位字。最高有效地址位可选择两个SRAM实例的上部或下部,暂存器的对应半部(左或右)由其组成。这是当数据被读出到乘法器时进行(如果存在两个乘法器)。不过,当从集群存储器对暂存器进行写入时,两个SRAM实例被启用,使得两个32位字同时写入。举例来说,如果使用四个乘法器,则这也在将数据读取到乘法器时进行。
术语“暂存器(scratchpad)”对应于本地数据缓冲器,且因此有时被称为“数据缓冲器”或简称“缓冲器”。
计数器可使用存储于寄存器中的两个不同步长来步进。计数器中的地址也可存储于影子寄存器中且稍后取回。
实例-将数据块从CM写入到SRAM中:
块将向暂存器的左边一半或右边一半传送(我们传送数据或内核(系数)字节,而不是两者同时传送)。我们将在所述部分的上部和下部SRAM实例中同时写入。另一半部中的写入将以对应方式进行。我们不存取的两个SRAM实例不应使其时钟在作用中。
数据块由16字节字组成,且从DFM寄存器传送。在多字传送的常见情况中,这是以全CM时钟频率进行。PE因此具有两个PE时钟循环/周期,其中将每一字移动到其最终目的地。在这些循环/周期中的第一个中,其将读取DFM中的字节7..0,且将字节3..0传送到上部SRAM及将字节7..4传送到同一半部中的下部SRAM。参见图16D/E。其还将步进地址计数器(其寻址此半部中的两个SRAM实例)。在第二循环/周期中,其将读取DFM中的字节15..8,且将字节11..8传送到上部SRAM及将字节15..12传送到同一半部中的下部SRAM,且再次步进地址计数器。
随后这将以DFM中的新16字节字进行重复。示出了如何将此字写入到相同SRAM实例中。过程继续直到块的结束。
实例-将向量相乘
在下文中,例如“向量”、“行”和“向量元素”等术语将以本领域技术人员通常为其指派的含义来使用。
(“经修改Booth”类型的)乘法器基于三个乘法器位的重叠群组而形成部分乘积行,进而与简单二进制乘法相比减少行的数目。随后通过类似于其它乘法器中的加法器树将行相加在一起,且设计与32位宽累加器融合。乘法器-累加器(MAC)单元针对将有符号8位数字相乘而优化,但具有用于其它数字格式的模式,所述其它数字模式例如bfloat16,其需要用于每一向量元素的两个字节。可使用其它数字格式,而不需要乘累加单元外部的硬件的改变。
单元划分成管线级,且以比PE的其它部分更高的频率计时。
四个SRAM实例中的两个是同时存取的,但与写入相比是以不同方式进行;存取每一半部(左和右)中的一个SRAM实例。我们在两个最上部实例与两个最下部实例之间交替,使得我们按其存储的次序读取数据和系数(内核元素)。从SRAM实例中的任一个所见,读取的频率则将是PE时钟频率的二分之一,即,1.2GHz。来自读取存取的两个32位字将保持于寄存器中达两个PE时钟循环/周期,即四个乘法器循环/周期。
在四个乘法器的情况下,我们以全PE时钟频率对所有SRAM实例进行计时,但我们仍保持寄存器中的数据达两个PE时钟循环/周期。我们因此需要两组四个寄存器,其交替地计时。我们让两个乘法器使用从上部两个SRAM实例取得其输入的寄存器组,而另两个乘法器使用从下部两个SRAM实例取得其输入的寄存器组。
每一乘法器在所述两个输入上具有4路字节宽多路复用器,且4-计数器控制多路复用器以按次序选择每一寄存器的四个字节。用于乘法器的数据在寄存器中稳定达两个PE时钟循环/周期,且通过乘法器时钟计时且经同步到集群时钟(即,每隔一个PE时钟循环/周期)的计数器将此时间划分为四个等份,用于寄存器组的两个寄存器中的字节#0、1、2、3。每一乘法器进而对用于每一PE循环/周期的两对字节进行读取和相乘。
两个地址计数器一起步进,而不是像当写入时的情况那样仅一个步进。用于其中的一个(用于数据的一个)的寻址模式也可能不同于另一个(用于系数的一个)的寻址模式。
在四个乘法器的情况下,一对乘法器在偶数PE循环/周期处开始且另一对在奇数循环/周期处开始。在累加器的输出处的结果也将类似于此在交替循环/周期中出现,但它们在每N个相乘循环/周期,即N/2个PE时钟循环/周期中出现仅一次,其中N是每一向量中的字节元素的数目。结果,累加总和,即标量乘积(或“点积”)将是例如4字节宽,且它们将每次一个字节从MAC输出,其中首先是最低有效字节。
因此,来自两个MAC的乘积字节#0将一起到达。在四个MAC的情况下,来自另一对MAC的字节#0将随后到达。随后字节#1将以相同方式到达,随后是用于两个或全部四个MAC的#2和#3。
结果字节传送到PE核心中的ALU且在微码的控制下经处理。
实例-PE核心
在一特定实例中,除新颖部分之外,核心的基本常规功能性可以基于良好证实的Imsys处理器核心,其剥离掉对于PE不需要的功能。此剥离可以导致移除到核心的大多数连接,仅留下图16C-E的框图中示出的那些连接。下文给出对这些信号及其连接的一些注解,在图16C的左上方开始:
在此实例中,不使用DRAM接口,而是核心将含有CM地址的读取/写入请求传送到4字节宽DTM(到存储器的数据)寄存器,所述寄存器也用于待写入的数据。来自CM的所请求数据被接收于16字节宽DFM(来自存储器的数据)寄存器中。在新块存储器数据寄存器(MDR)中包含两个存储器数据寄存器。通常,每一核心具有一组MDR寄存器。
从CC接收复位和时钟信号。两个核心从共同块得到其时钟,所述共同块产生且驱动用于四个双PE平铺块的复位和时钟信号。
两个核心彼此独立地工作,但它们共享含有控制两个核心的代码的微程序RAM(MPRAM)。微码的加载仅由核心中的一个处理。128位宽微指令从DFM到MPRAM的传送在两个PE循环/周期,即一个CM时钟循环/周期中完成,其方式类似于数据传送到暂存器。
“正常”微指令花费两个时钟循环/周期来执行。两个核心轮流从MPRAM读取微指令且进而可彼此独立地执行,尽管它们共享MPRAM资源。核心已经修改以允许可使用更多时钟循环/周期的微指令。这对于多字节操作数的运算是有用的。此加速器使用极快的管线式乘法器解决方案,从而允许一个微指令在每一时钟循环/周期中数百次执行涉及乘法-累加运算的同一运算集合,而无循环开销时间。
暂存器或本地输入缓冲器不同于较早的Imsys处理器设计。其为32位宽且具有例如2KB或4KB容量(取决于MAC单元的数目等而为最佳的),且划分成具有单独地址计数器的两个半部。每一半部进一步按深度划分成两个,使得其由(至少)两个SRAM实例构成,所述实例可单独地存取或作为一个存储器来存取。
实例-存储器数据寄存器(MDR)
这由通过分发网络从CM接收数据的128位宽DFM寄存器和通过收集网络向CC发送命令且向CM发送数据的32位宽DTM寄存器组成。
PE具有用于在一个CM循环/周期(两个PE时钟循环/周期)中将整个16字节DFM内容复制到其暂存器的装置,且因此能够以全CM时钟频率接收多个字。16字节字放置于暂存器的数据或内核半部中,在以作为16的整倍数的字节地址开始的任何位置处。暂存器是通过地址计数器寻址,所述地址计数器可从微指令加载且以各种方式步进。每一对中的核心中的一个可类似地将DFM复制到微程序存储器。
实例-暂存器中的读取和写入
作为实例,我们在此将假定我们对乘法器读取且我们从DFM寄存器(我们已从CM加载)写入。
图17A-D是示出针对每一MAC循环如何将新的一对字节从暂存器传送到MAC单元的实例的示意图。在此实例中,在相乘的同时,SRAM循环/周期是MAC循环/周期的两倍长,但如果我们具有两个乘法器,则在每一SRAM循环/周期中从暂存器的每一半部读取四个字节。应注意,每一半部由两个SRAM实例组成,一个上部和一个下部,且它们交替地进行存取。如果我们具有四个乘法器,则我们以全PE时钟频率对SRAM进行计时(这应当无论如何都是可能的,因为当写入时期望这样做),且我们通常同时从暂存器的所有四个部分进行读取。
举例来说,每次加载暂存器的仅一半。在其它时间点加载另一半。应注意,当查看所述半部中的一个半部时,我们在一个SRAM循环/周期中加载4个字节,而我们当从此半部向MAC读取数据时每SRAM循环/周期只读取2个字节。因此,我们的加载速度是原来的两倍,且因此实现上文计算的较高利用率。
我们可以通过使用2端口SRAM增加此种类的MAC利用率,因为我们随后可接着在乘法器工作的同时填充暂存器,但这可能成本超过4KB单端口SRAM。FPGA系统将给我们机会来测试2端口和容量的加倍,因为我们用于暂存器的BlockRAM将实际上具有我们打算使用的容量的两倍,且它们也可以被配置成支持2端口接口。
图17E是示出从用于MAC单元的乘法阶段的本地数据缓冲器进行读取的实例的示意图。如先前指示,有可能在每个PE时钟循环/周期中从所有四个本地数据缓冲器(例如,SRAM)进行读取。在此实例中,我们每个PE时钟循环/周期在两个MAC块中开始乘法:偶数循环/周期中的MAC 0、1,和奇数循环/周期中的MAC 2、3。每一MUL寄存器是每两个PE时钟循环/周期加载一次。乘法器通常由PE时钟频率的两倍来计时,且它们在每一乘法器时钟循环/周期中各自读取一对字节,即对每一输入加载循环/周期是四对。在乘法过程的开始之后的一些循环/周期(由MAC单元的管线深度造成的延迟),每一MAC将在每个PE时钟循环/周期中累加两个新元素乘积。
ALU
举例来说,ALU可以具有由微指令中的3位字段控制的8个不同函数。此字段可以增加到4位,且将添加更多函数。这些包含最大值和最小值以及由参数寄存器控制的激活函数,所述参数寄存器将在包含ReLU和S型(sigmoid)的相关函数当中进行选择。S型函数和神经网络中常见的其它非线性函数将通过小ROM或SRAM中的查找表实现。
ALUREGS
举例来说,这是包括64个八位寄存器的寄存器集合。微码可指定将对ALUREGS和/或暂存器和/或DFM寄存器中具有不同字节长度的数据要执行的移动或者1操作数或2操作数运算,以及结果的目的地,所述目的地可以是ALUREGS、暂存器或DTM寄存器。
举例来说,数据从DFM到ALUREGS的移动(即,复制)是由一个微指令完成,所述微指令从DFM加载1到16个连续字节。微指令中的字段指定DFM中和ALUREGS中的开始字节位置,以及要传送的字节数目和ALUREGS中的字节位置步进的方向。
控制单元
控制单元从较早的Imsys处理器承袭其逻辑,但微指令字增加到128位,以允许对此处描述的新功能性的控制。单元含有循环计数器和子例程堆栈。其还含有用于除错/调试的供应,它们将整体包含于GPP处理器中但在PE中将简化。
控制存储区(CS)
此单元含有控制存储区(CS),也被称为微程序存储器,例如存储128位宽微指令的SRAM。CS无需极深;如果我们仅需要进行DNN推断,则16或32个字可为足够的。如果我们需要的更多,则我们可添加与较小SRAM并联的较大ROM;ROM比SRAM更密集若干倍。
举例来说,核心应当能够进行其微码SRAM的初始加载。如果使用ROM,则这不是问题,且此解决方案用于GPP。如果PE不具有ROM,则从集群存储器中的固定地址(=0)加载多个微指令所需要的短微程序序列是由合成门逻辑的块产生。
GPP和PE将使用Imsys的共享控制存储区以及对于GPP还共享其主存储器的专利方法。
新功能性:统一存储器
此特征通常对于GPP比对于PE更相关,且因此已经结合GPP进行描述。但应当理解,统一存储器概念一般可以适用于任何处理器。
微指令
微指令控制PE在微指令循环/周期期间应当做什么。
普通微指令循环/周期由两个时钟循环/周期组成。到将执行的下一微指令的地址是在第一时钟循环/周期期间基于当前微指令(存储于管线寄存器中)中的控制位和选定条件而确定,且在第二时钟循环/周期期间所述微指令从CS读取且存储于管线寄存器中。定序的控制仅使用微指令的128位的小部分;其它用以控制PE的资源,即选择用于ALU的功能、在暂存器和ALUREGS中将进行读取和写入的地址等等。
普通2时钟微指令可例如在暂存器中的一个地址处读取数据,并且接着在另一地址写入所述数据,且同时对ALUREGS中的两个字节进行ALU运算并存储结果,并且还进行任何种类的序列控制功能,例如若干种类的循环、子例程调用或多路(解码)分支中的一者。
新功能性
加速器工作的主要部分将由特别类型的微指令执行,其功能对每一时钟脉冲重复直到达到停止条件(通常来自循环计数器)为止。管线寄存器将加载仅一次,且在重复时不需要确定下一地址。
将正常地确定在重复之后的下一地址。微指令具有用于序列控制的正常字段,其可指定例如从子例程的分支或返回;除了那些微指令字段之外还指定“特别类型(extraordinary type)”。
此新的特殊重复类型可以不仅用于向量运算,而且用于多字节操作数的简单ALU运算,例如相加。随后将在微指令中的新位和新的小计数器的控制下对到操作数的地址进行自动定序。
当微指令以此方式控制花费许多时钟循环/周期但仅参与处理器中的算术逻辑的部分的过程,例如具有数百个元素的向量的标量积的计算时,则额外改进将贡献于硬件的较高利用率且进而较短的更高处理量:将控制执行此特定过程的部分的微指令位则不是直接连接的,而是经由从微指令字加载的寄存器连接的。这允许微程序在过程执行的同时继续其它工作。
微码执行的开始
当PE开始执行新变换(例如,CONV层或层的部分)时,其始终从其CS中的地址0开始读取微码。
微码将经常使用子例程。这些存储于CS中的较高地址处,在最高地址处通常是最有用的。当替换微程序或其部分时,从地址0和按需要一样多的字存储新代码,覆写较早代码。当运行时,新代码可利用已经存储的尚未被覆写的子例程(或代码的其它区段)。为了利用此技术,编译器需要在整个过程中跟踪CS内容。这当然不是必要的;为简单起见可以替换全部内容以用于每一新变换。对于大模型,差别将不大,因为数据结构比微码大得多,且操作数目比要加载的微程序字的数目大得多。
实例-请求PE中的实体与其CC接口之间的传送
举例来说,这是通过将请求字放置于DTM寄存器中且向集群控制器(CC)提出请求标志信号而通过微码来完成。
去往/来自暂存器的传送
先前已经描述这些请求。在CB或RD请求的情况下,PE检测请求的数据何时到达且将其传送到暂存器。在WR请求的情况下,PE将32位数据连同请求代码和CM地址一起写入到DTM寄存器中。当字已写入到CM中时PE将从CC得到信号。此信号将设定微程序可测试的标志(flag)。
微码的加载
举例来说,可以使用CB或RD请求类型,但PE通常将所接收数据从DFM寄存器直接传送到微程序存储器而不是暂存器。
加载通常在CS中的地址0开始,且继续直到已达到所需计数为止。在每一CC时钟循环/周期,即两个PE时钟循环/周期中加载一个128位字。
当例如由于系统启动,PE在复位之后启动时,其将CB请求输出到CC。如果PE对不具有ROM,则所接收字的加载必须通过不受微码控制的逻辑完成,因为尚未存在要在CS SRAM中读取的任何微码。在复位之后的自动请求指定最大长度,即将加载整个CS。PE控制单元中的循环计数器用于在加载时寻址CS,且其在第一加载完成时将停止于零。控制随后传递到CS SRAM。地址0含有待执行的第一微指令。
在某种意义上,处理元件通过其自身的内部控制主动请求其微码从集群存储器的传送。
实例-重要的基元操作
我们在此处将集中于“CONV”层,其为在深度神经网络中使用的最常见且最高要求的层。
每一层将张量变换为另一张量。张量是具有x索引=0..X-1、y索引=0..Y-1和z=0..Z-1的3维数据结构,其中X、Y、Z分别是按元素数目测得的宽度、高度和深度。
我们假定标量元素是单个字节。如果PE中的MAC单元为其配备,则系统可有效地处置其它数字格式。我们计划对其进行开发以任选地处置重要格式,而不使其面积增加太多。多字节格式将随后花费更多时间来操作,但操作数的传输也将较慢,且设计因此仍可在其硬件的利用率方面得到良好平衡。
操作数以“z主序”存储,即每一z向量的元素以自然次序依序存储。向量随后以x坐标次序存储,而水平x/z层级随后以y坐标次序存储。
CONV层的处理
张量可被视为:
1)具有宽度=X和高度Y的2维阵列,其中每一阵列元素是1维向量,此处称为“z向量”,具有沿着张量的深度维度的Z标量元素。
可替代地,张量可被视为:
2)Z“特征图”,其为标量元素的2维x/y阵列,张量的每一z坐标对应一个。
卷积将输入张量的小部分最经常是z向量乘以滤波器内核,所述滤波器内核是具有恒定元素(参数)的相同大小和形状的数据结构。乘法是“点积”,即由两个向量的对应元素的乘积的总和组成的标量积。
·
·
应注意,由MAC单元产生的标量积在此处不是两个线性地布置的向量的点积,而是两个小矩阵的点积。它们仍是乘积的总和,尽管寻址模式不仅仅是简单序列。这些模式需要从CM中相隔较远的(通常)三个不同范围加载数据。内核元素当然以简单序列次序存储。
相邻累加在x/y平面中重叠,且这是集群针对其区的边缘需要交换数据(“边缘数据”)的原因。应记住,每一张量在x和y维度中划分成区的阵列,每一集群一个区。
·
图18是示出PE对的实例的框图。举例来说,PE可以是在GPP中使用的相同双核心设计的变体。除错已被简化,且定时器、I/O总线、外围接口等已经移除,且到主存储器和DMA缓冲器的接口已经组合且重新设计作为到共享集群存储器的接口。微程序存储器已减少到由双核心对共享的小缓冲器。然而应注意,所述两个核心是独立的且不一定存取缓冲器中的相同字。
PE具有硬接线初始ID编号,且它们具有与根通信的命令和状态寄存器。不存在直接连接,因此此类通信通过CC。其可使用标签网络,或可替代地,其可使用CM,使用PE-CM接口和NoC。在后一种情况下,需要一些简单的信号交换,而这可使用标签网络。
为了测试PE,GPP可将自测试微程序广播到集群存储器中,启动PE,且读取结果。其也可将此用于对单独PE进行除错(类似于使用其除错端口),改变其ID编号,将其接通/断开等等。
集群存储器在需要时经由NoC接收微码。此代码是针对待处理的层优化的特殊微码,且通常连同用于所述层的参数一起广播。特殊微码比使用普通CPU指令高效得多,因为普通CPU指令必须被获取且解码且必须仅以与指令集架构(ISA)一致的更受限方式来利用寄存器和暂存器。集群中的PE基本上与GPP兼容,且如果需要,则它们可能够执行用于Java和Python的ISAL指令和字节代码。
不过,对于PE更有用的是利用特殊代码,或针对指令集开发的微码的可能选定部分,例如,仅当需要某些算术指令时用于这些指令的执行代码。举例来说,ISAL指令集含有用于加法的52个指令和用于乘法的34个指令,以及对应数目的用于所有标准数据类型的减法、除法、逻辑和移位运算的指令。包含IEEE 754浮点数和双精度浮点数。
加速器还将需要对通常不具有处理器的优化支持的数据格式的操作。这些操作可以按需要经微编码,且随后将与标准操作一样高效。一个实例是具有Q15格式的实部和虚部分量的复数的乘法。这已经过开发和验证(作为FFT的部分)且将在50纳秒中以1200MHz微指令频率执行。还已开发具有Q15的一个操作数和uint16的另一操作数的变体。通过牺牲常规舍入可进一步减少执行时间。可通过利用PE中的新特征来实现高得多的加速,其在一些情况(例如,向量运算)下将运算的速率加倍到2400MHz。
举例来说,将以额外效率支持新的Bfloat16格式,尽管硬件改变限于MAC逻辑。其将执行例如每PE的12亿次MAC运算/秒。这应当还针对训练给出加速器竞争性性能,所述训练需要的精度比推断需要的精度更高。
实例-初始化、除错等
PE微码
举例来说,CC可以保持其PE处于复位直到其已正确地发起为止,这包含使用于所有PE的初始微码存储于CM中,以地址0开始。
当例如由于系统启动,PE在复位之后启动时,其将CS_load请求输出到CC。这必须由不受微码控制的逻辑完成,因为其控制存储区(CS)尚未加载。CS_load请求具有指定应当加载的字的数目的参数。在复位之后的自动请求指定最大值,即将加载整个CS。微程序计数器用于在加载的同时寻址CS,且其在第一加载完成时将停止于零。
当PE开始执行新变换(例如,CONV层或层的部分)时,其始终从其CS中的地址0开始读取微码。
微码将经常使用子例程。这些存储于CS中的较高地址处,在最高地址处通常是最有用的。当替换微程序时,只要需要就从地址0写入新代码。当运行时,新代码利用未被覆写的已经存储的子例程。编译器需要在整个过程中跟踪CS内容。
将了解,本文所描述的方法、程序和布置可以多种方式实施、组合和重新布置。
本文所描述的步骤、功能、程序、模块和/或块可使用任何常规技术以硬件实施,例如离散电路或集成电路技术,包含通用处理器技术、定制微处理器技术和/或专用应用的电路系统。
替代地或作为补充,本文所描述的步骤、功能、程序、模块和/或块中的至少一些可以软件实施,例如以任何计算机代码的计算机程序,还包含用于通过例如一个或多个处理器或处理单元等合适的处理电路系统执行的机器代码和/或微码。
处理电路系统的实例包含但不限于一个或多个微处理器、一个或多个数字信号处理器(DSP)、一个或多个中央处理单元(CPU)、视频加速硬件和/或任何合适的可编程逻辑电路系统,例如一个或多个现场可编程门阵列(FPGA)或者一个或多个可编程逻辑控制器(PLC)。
还应理解,有可能再使用其中实施所提出的技术的任何常规装置或单元的一般处理能力。也有可能再使用现有软件,例如通过现有软件的重新编程或通过添加新软件组件。
也有可能提供基于硬件与软件的组合的解决方案。实际的硬件-软件分割可由系统设计者基于多个因素来决定,包含处理速度、实施的成本和其它要求。
图19是示出根据一个实施例的计算机实施的实例的示意图。在此特定实例中,本文所描述的步骤、功能、程序、模块和/或块中的至少一些以计算机程序125;135实施,所述计算机程序加载到存储器120中以用于通过包含一个或多个处理器110的处理电路系统执行。处理器110和存储器120彼此互连以实现正常的软件执行。可选的输入/输出装置140也可以互连到处理器110和/或存储器120以实现例如输入参数和/或所得输出参数等相关数据的输入和/或输出。
术语‘处理器’应当在广义上被解释为能够执行程序代码或计算机程序指令以执行特定处理、确定或计算任务的任何系统或装置。
包含一个或多个处理器110的处理电路系统因此被配置成当执行计算机程序125时执行例如本文所描述的定义明确的处理任务。
处理电路系统不必专用于仅执行上述步骤、功能、程序和/或块,而是也可以执行其它任务。
在一特定实施例中,计算机程序125;135包括指令,所述指令在由所述处理器110执行时致使处理器110或计算机100执行本文所描述的任务。
所提出的技术还提供包括计算机程序的载体,其中所述载体是电子信号、光学信号、电磁信号、磁信号、电信号、无线电信号、微波信号或计算机可读存储介质中的一者。
举例来说,软件或计算机程序125;135可以被实现为计算机程序产品,其通常携带在或存储于非暂时性计算机可读介质120;130上,尤其是非易失性介质。计算机可读介质可以包含一个或多个可装卸式或非可装卸式存储器装置,包含但不限于只读存储器(ROM)、随机存取存储器(RAM)、压缩光盘(CD)、数字多功能光盘(DVD)、蓝光光盘、通用串行总线(USB)存储器、硬盘驱动器(HDD)存储装置、闪存、磁带,或任何其它常规存储器装置。计算机程序因此可以加载到计算机或等效处理装置的操作存储器中以用于通过其处理电路系统执行。
本文提出的程序流当由一个或多个处理器执行时可以被视为计算机流。对应装置可以被定义为一组功能模块,其中由处理器执行的每一步骤对应于功能模块。在此情况下,功能模块被实施为在处理器上运行的计算机程序。
驻留于存储器中的计算机程序因此可以被组织为适当功能模块,所述功能模块被配置成在由处理器执行时执行本文所描述的至少部分的步骤和/或任务。
可替代地,有可能主要通过硬件模块或替代地通过硬件来实现功能模块,在相关模块之间具有合适的互连。特定实例包含一个或多个合适配置的处理器和其它已知电子电路,例如,经互连以执行专用功能的离散逻辑门,和/或如先前所提及的专用集成电路(ASIC)。可使用的硬件的其它实例包含输入/输出(I/O)电路系统和/或用于接收和/或发送信号的电路系统。软件对硬件的程度纯粹是实施选择。
上述实施例应理解为本发明的几个说明性实例。本领域的技术人员将理解,在不偏离本发明的范围的情况下可以对实施例作出各种修改、组合和改变。具体来说,在技术上可能的情况下,不同实施例中的不同部分解决方案可在其它配置中组合。
参考文献
1.Efficient High-Speed On-Chip Global Interconnects,
附录A
数字实例-推断机器所需要的极高处理量
此处的数字不是精确的,也不在任何意义上为限制性的,但对于汽车应用是代表性的。
问题1
解决方案:使用1 000 000 000 000/500 000 000=2000个乘法器。这在现在对于现代CMOS制造技术是可能的。
问题2
我们需要更仔细观察这些模型,且我们随后发现设计可始终利用所有乘法器的可配置系统实际上是不可能的。因此我们需要创建具有更多乘法器的系统,且部分时间可使用多于2000个乘法器,以补偿将使用少于2000个乘法器的时间。为了限制系统的成本,我们需要限制物理乘法器的数目,即,我们需要针对我们具有的乘法器保持利用率较高。
实例-用于内循环的硬件
所有乘法是“内积”的部分,也称为“点积”,即Σ(a
图20是示出MAC资源中的一些的实例的示意图。
作为一方面解决方案或部分解决方案,可行的是连接每一乘法器输出与加法器和累加器寄存器(长于a和b操作数,以避免当总和变得较大时的溢出)。因而我们减少将乘积移动到其目的地的需要;我们仅需要移动累加的总和。移动c因而对于内循环不再是问题。
仍相关的是在每一循环/周期中产生用于每一乘法器的新“a”操作数和新“b”操作数,否则乘法器在所述循环/周期中是空闲的,且这必须通过使多于2000个乘法器在另一时间点工作来补偿。
来自不同源的操作数a和b当乘法器开始其乘法时必须在乘法器的输入处就绪。因此,它们必须在先前循环/周期期间产生。循环/周期仅为2ns,意味着每一操作数必须来自单独的本地存储器实例。这些与乘法器输入之间的寄存器必须保持用于乘法的操作数,而存储器产生下一操作数集合。
在下文中,将描述分配和布置这些资源的可能方式的实例。两个存储器是暂存器和ALUREGS,且乘法(MULT)、加法(ADD)和累加器(ACCUMULATOR)包含于所设想处理器的MBM块中。
乘累加(MAC)块可以所有标准数字格式运算。通过int8、uint8或Q7格式,其在每个机器循环/周期中进行一个MAC运算。较长格式花费更多循环/周期。将可能的是每两个机器周期进行bfloat16运算。此增加与输入字节数目的加倍一致,即,不需要MAC块外的任何改变。
可能的改进
●可针对高频优化存储器实例AMEM和BMEM,且随后重新设计MAC逻辑以匹配于所述频率,即使这需要额外管线步骤(简单方式是在乘法和加法块之间插入寄存器),且即使此高频无法在此小系统外使用也是如此。此处将示出此类改变可以是绝对值得的。
●除优化SRAM实例之外,我们还可每微指令作出两个存取--这是不难的;事实上,每一微指令可能已经在这些存储器中进行两个连续存取,尽管这尚未用以向乘法器两次递送操作数。乘法器当然必须重新设计以能够在较短间隔接收操作数,但这可以更多管线步骤进行(我们不需要担心此处的时延)。
●作为此方向的额外步骤,可修改AMEM和BMEM以使得它们各自可每读取循环/周期递送两个连续字节,使得两个MAC单元可并行地工作。
其累加器将随后在它们已完成其求和之后相加在一起。此原理当然可以用更多MAC单元扩展(尽管收益递减)。
其它运算
有时,层逐元素地相加,且有时,来自累加器的部分总和需要累加。还需要用于偏置加法、量化和激活函数的运算。这些运算比乘累加(MAC)运算的频率小得多。除此处示出的算术资源之外,核心中还存在ALU块,且现有微码可使用此用于多种运算选择。
问题3
为了得到高利用率,可能需要以一定方式加载输入数据缓冲器,所述方式与我们使用所加载的内容的时间相比花费极少的额外时间。可示出实际上可以满足此要求。让我们首先查看RefNet中的第一层3维卷积层的处理的内循环。
图21A、C是示出二维和三维CONV的实例的示意图:x/y平面中的重叠3x3范围。
图21A示出输入图像中的像素。每一像素通常由RGB编码中的3个元素(红色,绿色,蓝色)组成,即输入张量中存在3个通道。
图21B示出相同像素,但具有指示输出中的对应元素的x/y位置的星形。每一星形表示32个输出元素,因为输出张量中存在32个通道。包围每一星形且通过粗体轮廓标记的3x3像素区域是通过星形标记的输出在其内得到其输入值的范围。如此处可见,这些范围彼此重叠,且因此大多数像素不仅是一个区域的部分,而且是2个或4个区域的部分。
图21C更清楚地示出此情况。此处,点和星形在中心已被数字代替,所述数字示出每一像素作为其部分有多少不同的乘积求和。平均值是(4+2+2+1)/4=2.25。不过,此类求和是以不同内核完成32次。每一输入数据元素因此平均使用32*2.25=72次。
在一实例设计中,我们可在一个机器循环/周期中将2个字节加载到暂存器。(该处的源可为本地或外部存储器或DMA缓冲器。)加载字节花费的时间因此是0.5个循环/周期,且随后在72个循环/周期中使用字节--加载时间是对字节操作的时间的0.7%。我们可进一步改进此情况。现有存储器接口和DMA缓冲器可以被集群存储器接口代替。
情形事实上比此处描述的更好,因为(仅)在此层中,每一输入数据元素不是一个字节,而是两个字节(即,每一像素是3*2=6个字节)。内核元素仍是一个字节。一乘二字节乘法需要两个循环/周期,因此数据元素的加载时间是操作时间的0.35%。
不过,我们还需要查看内核元素,即去往其它乘法器输入的操作数流。内核由3x3x3元素组成,且这些所有均是单字节。存在32个不同内核,每一输出通道一个。
我们现在需要决定哪一个是两个输入缓冲器中的哪一个。
举例来说,暂存器的容量可以是1024字节,而ALUREGS的容量可以是仅32字节。有可能将数据放在暂存器中且将内核放在ALUREGS中。然而,这导致为了最大利用率对图像的细分的某些限制。考虑核心的一些改进,针对我们在此处论述的特定层,这将有利于将数据放在ALUREGS中且将内核放在暂存器中。
一个此类改进是暂存器的大小的加倍。另一改进是能够将若干(可能多达16个)字节并行地加载到ALUREGS中。
这些改进中的任一者将使得将数据放在ALUREGS中且将内核放在暂存器中是优选的。例如,我们此处将假定ALUREGS的大小是64字节。
在特定实例中,每一像素由3个元素组成,此处(别处没有)每一元素是2字节。一个求和需要3*3像素=3*3*3*2=54个数据字节和3*3*3=27个内核字节。为了计算用于一个x/y位置的所有输出元素,我们需要用于以所述位置为中心的3*3像素区的54个数据字节,且我们需要(27字节)*(32个输出通道)=864个内核字节。因此,我们应当在ALUREGS中加载这54个数据字节,且在暂存器中加载这864个内核字节,并且接着基于此计算32个输出元素。乘法-累加运算将需要27*2*32=1728个机器循环/周期。加载54+864=918个字节花费918/2=459个机器循环/周期。不过,可再使用所有内核字节。在计算一个输出向量(用于此x/y位置的32个输出元素),我们移动到下一个的位置。假设在正x方向上移动,即从上方图中的一个星形到右边的下一星形。我们保持32个内核,且我们也可保持我们用于先前计算的3*3*3数据体积中的最右边列,因为它现将变为新3*3*3数据体积中的最左边列。因此,在我们可开始下一求和之前,我们需要仅加载3个像素,即18字节。这可以继续直到我们到达图像的最右边边缘为止。
因此,忽略开始的较大负载,我们加载18个字节,并且接着运算达1728个循环/周期。这是99%的利用因数。它需要在三个不同微程序循环之间切换,具有索引的不同排列。我们可以认为这是不值得的,在此情况下我们需要每输出元素一次加载54个而不是18个字节。利用率则将是97%。应注意,内核的初始加载甚至无法将利用率减少百分之零点一,因为其针对整个图像(3,4百万像素)仅进行一次。
其它层
我们将以此详细方式检查所有其它类型的层,以确保此处描述的硬件针对那些层也可达到极高利用率。直到那时我们都假定情况如此。
层融合
一些卷积层产生具有许多通道的张量--我们可允许其到达无法将其本地存储的深度,且仍避免将其远程存储。区的直列式布置经常可用于层的“融合”,进而避免了昂贵的片外传送的需要。这是因为即使当具有逐深度的细分时,也可以在无数据交换或具有极有限数据交换的情况下通过多于一个层来处理区。“扩张”层的大输出张量将随后连同随后的瓶颈层中的“压缩”一起处理,每次一个深度细分。大张量则将从不需要整体地存储,且CM中的本地存储将足够。
瓶颈序列
在我们研究的CNN模型中,三个CONV层的“瓶颈”序列重复多次,其负责针对一个推断执行需要的312亿次MAC运算中的249亿次(79.7%)。
我们因此通过集中于此重要序列来开始我们的研究。我们的目标是示出我们可如何达到高利用率,同时使得对平铺块阵列外部且特别是IC外部的中间存储的需要最小化。
融合瓶颈序列
瓶颈序列的三个卷积(逐点/逐深度/逐点)可以融合,意味着它们是一起执行的。我们可接着减少对数据传送和存储的需要;事实上,我们可处理比图22中的两个大张量甚至更大的张量而不需要将其任何部分从PE的阵列传送出。
图22是示出三个层的融合的实例的示意图。
有两件事我们需要考虑:一个是我们应当分发工作以使得我们的PE的几乎100%始终贡献有用工作。另一个是我们应当避免不必要的工作重复。
两个逐点卷积主导序列,每一卷积为MAC运算的45.7%。它们都需要48*288=13824字节用于其本地存储器中的内核。当需要内核时从根广播内核。第一卷积的内循环执行48个MAC运算288次。最后卷积中的对应循环执行288个MAC运算48次。
实例处理器
图23A-B是示出具有一些众所周知的处理器的核心设计的效率比较的示意图。所述比较涉及功率消耗、处理速度和代码密度。
图23A示出关于功率消耗的比较(与ARM Cortex-M4相比),而图23B示出关于代码大小的比较(与Intel x86相比)。
在下表中,示出与ARM 920T相比的Java性能。
图24是示出IM3000处理器的实例的示意图。举例来说,GPP可配备有在IM3000中可用的所有资源(除了无法与其一样进行迁移的模拟部分外)。
图25是示出双核处理器系统的内部组织的实例的集中于算术部分的示意图。GPP可以例如使用此设计的双核版本,其已在65nm技术中进行硅验证。
举例来说,可以在控制单元中的微指令的控制下由算术单元获取和执行软件指令,每机器循环/周期一个。每一此类微指令可彼此独立地控制大多数资源,从而节省循环/周期且进而节省时间和能量。微指令因此可在一个机器循环/周期中执行较简单CPU的指令序列的等效物。单循环/周期实例将获取两个8位数字,步升/步降其地址,将数字相乘,将乘积添加到累加器,步进目的地地址,且递减和测试循环计数。灵活性和效率的另一实例是浮点算术,具有针对不同格式的效率,其中短格式导致较少循环/周期。
图26是示出排除控制单元的总体双核系统的实例的示意图。在图26中,示出此双核芯片的算术部分。每一核心还具有类似于图25的左边部分示出的控制单元的控制单元,不同之处在于微程序存储器(称为控制存储区)是共享的--一个核心使用偶数循环/周期,另一个使用奇数循环/周期。
可参见共同拥有的美国专利8,060,727,该文献在此被援引加入本文。
此实例处理器具有类似于高分辨率图形和图像压缩/解压缩的功能,其例如在病理成像系统中是重要的。这些功能也较适合于本发明的多核系统。
处理器核心组合了灵活的微编程控制与精益(窄数据宽度)算术单元。这在处理器中极不寻常,可能是独特的,且对于神经网络和大规模信号处理是用于多核心加速器的处理元件(PE)的完美配合。
重要特性是部分可写的内部微码,其还可以以之前尚未考虑过的组合和序列来利用硬件资源,以作出高频环路中的许多不同操作。
举例来说,可在单个核心内部执行完整64点基数4FFT算法,而无需存取用于指令或临时数据的存储器。这与紧凑大小一起不仅对于大规模信号处理(例如在雷达数据提取器中)是极有用的,而且对于AI加速器中的处理元件(PE)也是极有用的。
已研究此应用且下文描述一些结果。
竞争者尚未证实具有类似特性的核心。它们使用更简单处理元件而无需灵活控制微编程工具。
所提出的技术的特性包含以下中的一者或多者:
●面积效率(其灵活地针对所有任务以不同方式利用精益硬件,从而减少对昂贵专用硬件块的需要),
●灵活性(其硬件由具有许多自由度的微码控制,提供通过标准指令集无法得到的效率),
●能量效率(出于上述原因)。
DNN的实例优点可以来自:
●较高处理量--由于微编程控制的灵活性,MAC块及其相关联存储器块的较高利用率,
●较低成本--精益算术单元允许每单位硅面积更多核心,以及
●通过对数据传送活动的需要减少而带来的较高能量效率,特别是在片外传送中。
高MAC利用率可以来自:
●工作负载的灵活分割,以用于向所有或几乎所有MAC单元的高效分发,
●在也利用MAC块的不可避免的循环/周期期间进行大部分必要传送的能力。
减少的数据传送活动可以来自:
●暂存器,以减少用于每一MAC单元的馈送的活动,
●每集群的本地存储器,以减少重叠子矩阵的影响,
●灵活的控制,以通过层融合消除许多长距离传送。
通过以下中的一者或多者,这些优点是可能的:
●处理元件(PE)中的灵活微编程处理器核心,
●可缩放的分层树片上网络(NoC),以及
●间接通过集群存储器(CM)的NoC到PE连接。
为了执行一般应用,可能必须在用于例如字节代码、解译器、堆栈和堆的不同存储器地址范围之间有效地切换。此随机地址切换可能是困难的,不仅是由于内部DRAM行存取时延,而且是对于窄数据路径必须针对宽DRAM地址使用若干循环/周期。
为了加速不同地址范围之间的最常见跳转,有可能使用多个替代寄存器用于较高部分的地址,包含确定DRAM行地址的部分。
类似于一般计算,数据流处理经常需要从几个不同地址范围有效地读取数据序列。上述替代地址寄存器可用于此,其方式同于它们可用于在DRAM中的不同行地址之间来回切换。
通用计算机通过具有高速缓存存储器来解决缓慢随机寻址的问题,在紧凑处理器中具有高速缓存存储器是不合意的(因为这些高速缓存存储器通常使用比处理器核心自身更多的面积)。替代地(无高速缓存),重要的是使用暂存器以补偿数据高速缓存的缺乏,且使用大量微码以补偿指令高速缓存。暂存器和微码对于加速器PE都极有用,正常高速缓存存储器对其来说肯定不是一种选择。
PE和CM
图27是示出集群存储器-PE连接的实例的示意图。在此实例中,集群存储器(CM)不是DRAM,但存在具有序列的第一存取的延迟以及频繁地址范围切换的类似潜在问题,因为CM是共享的且比处理器数据路径更宽。举例来说,可能存在共享CM的64个PE,且如果它们需要存取相同SRAM实例中的不同地址,则它们无法同时这么做。当PE需要存取单独数据(即,不存取与其它PE相同的地址)时,其面临上文针对IM3000所提及的两个困难--每当其想要存取新存储器字中的字节时,其必须等待轮到它。
对硬件开发的额外注释
我们已看见由MAC及其输入缓冲器存储器界定的小系统当在做其工作的主要部分(几乎全部)时完全独立地工作,所述主要部分实际上也是在加速器中执行的所有算术工作。这是典型任务:
1.加载代码、参数和数据(如果尚未存在;经常仅需要新数据或新参数)
2.随后进行MAC工作,如果利用率较高,则其主导执行时间
3.随后执行激活函数等且递送结果。
这在推断过程期间通常重复许多次,每一次具有许多MAC运算。完全执行序列--数千个PE中的总计数十亿次运算--是预先已知的且固定的;没有什么是数据相依的。
加载到PE输入缓冲器中的数据可以来自PE属于的集群中的集群存储器。由PE产生的结果递送到所述相同存储器。PE自身可通过存储于ROM+RAM中的其微码来控制这些传送。ROM代码可以包含从集群存储器加载微码在RAM中所需要的控制(加载的代码的大小比数据和内核的大小小得多)。
在特定实例中,每一PE具有“信箱寄存器”,存储器数据寄存器(MDR),类似于IM3000 DFM(来自存储器的数据)的扩展版本,16字节长,用于从集群存储器接收数据,且使用相同寄存器还作为DTM(到存储器的数据)以用于集群存储器获取输出数据。
举例来说,MAC单元可以具有简单接口,让人想起存钱罐。当启用时其每时钟接收两个字节(操作数对),这几乎就是全部。在用于向量乘法的所有操作数对已传送到其之后,输入被停用,且结果在其输出处(在几个额外循环/周期之后)可用(存钱罐可被空),直到输入再次被启用为止。
MAC单元也可以在物理层级经优化,以在与最大暂存器频率匹配的频率下获得最佳能量效率。
实例-PE的要求和初步描述
所有CONV层基本上由两个数据结构中的对应元素的乘法组成,一个数据结构含有实际数据,通常是来自先前层的输出,而另一数据结构含有常数。我们可将两个乘法操作数分别称为“数据”和“内核”元素。
两个结构都存储于共享集群存储器CM中,且其部分必须从该处复制到64个PE中的本地SRAM,因为这些中的乘法一起将以用于每一CM读取循环/周期的可能128次乘法的速率完成。
此高比率是可能的,因为每个数据元素将乘以许多内核元素,且每个内核元素将乘以许多数据元素。利用这两个事实可使得用于加载两种元素的时间相对于用于将元素相乘的时间是可忽略的。
PE需要可独立地寻址的两个快速本地SRAM。其中的每一个应当具有足够大小以实现对另一SRAM的内容的良好再使用。
我们使用单端口SRAM(双端口为两倍大),这意味着我们无法在乘法器读取时进行写入。SRAM可能已被组织以用于比读取更宽的写入,以减少在SRAM加载的同时乘法器必须等待的时间。然而,当考虑不同SRAM配置的面积和能量消耗时,使得有可能在正常情况中并行地加载多于两个字节似乎是不值得的。
各自具有16位的512个字的两个SRAM似乎是最佳选择。由于两个数据结构的元素几乎始终是按顺序地址次序使用的,因此我们可在每隔一个乘法循环/周期中读取2+2字节并使用它们用于两个连续乘法。
对于加载,我们可以使得有可能在一个写入循环/周期中加载四个字节,对每一SRAM加载两个字节。不过,应注意,如果我们具有来自仅一个数据结构的数据,则我们仅可加载两个字节。正常情况是我们需要替换SRAM中的仅一个中的数据--通常是含有内核的一个SRAM。
在下文论述的常见情况下,我们偏向于替换内核,因为那些内核对所有64个PE是相同的且因此可通过广播分发。存在广播数据是合适的且让PE与不同内核集合一起工作的其它情况,且硬件也允许此情况。暂存器的数据部分和内核部分则交换角色。
我们在SRAM中写入的数据来自存储器数据寄存器(MDR),其由于较早请求而已经从集群控制器(CC)加载。MDR含有16个字节。因此将花费8个写入循环/周期来将其内容传送到SRAM中的一个。
如先前描述,输入数据可能必须重新布置和/或变换以用于实现高效计算/并行化。
图28是示出划分成若干区的总体输入图像的实例的示意图。
所提出的技术提供适于多核并行化的图像数据重新布置和/或变换过程。
在特定实例中,参考图29的示意性流程图,提供用于重新布置和分发传入图像的数据以用于由数目K≥4的处理集群进行处理的计算机实施的方法。传入图像具有多条扫描线,每一扫描线被布置为多个数据单元。
用于输入图像的基本程序的实例可以简单概括如下:
步骤S1:将所述传入图像逻辑上分割为对应于处理集群数目的K个均匀区,其中所述K个区通过以下操作由数目R≥2的行和数目C≥2的列界定:
-将每一扫描线划分为数目C≥2的均匀线段,线段的长度等于区的宽度;
-将每一线段划分为数目W≥2的数据单元,每一数据单元具有数目Q≥2的字节,即Q字节数据单元;以及
-界定用于每一区的数目H≥2的扫描线的区高度;
步骤S2:在具有大小对应于所述数据单元的存储器位置的存储器中存储来自相对于彼此交错的不同区的数据单元,而传入图像的区的每一行的每一线段的连续数据单元以K个存储器位置的偏移进行存储以使得连续数据单元相隔K个存储器地址而存储;
步骤S3:将存储于所述存储器中的K数目的Q字节数据单元的每一组合转置成Q数目的K字节字的经转置组合,每一K字节字包含每集群一个字节;
步骤S4:将每一K字节字的字节并行地传送到所述处理集群,每集群一个字节。
图30是示出将传入图像重新布置且转置成经转置的输出数据以用于传送到集群的实例的示意性框图。
总体系统200涉及用于执行受控传送数据块/单元进入存储器220的特定存储器地址的处理器或等效控制电路系统210。总体系统200还涉及被配置成执行所需的转置操作且转发经转置的数据以用于后续传送到集群的转置块230。
通过一个或多个可选的合适接口,数据单元根据一组规则存储于例如DRAM的存储器210中,所述规则是基于将传入图像在逻辑上分割成对应于处理集群的数目的K个均匀区。K个区由数目R≥2的行和数目C≥2的列界定。
如所提到,每一扫描线被划分成数目C≥2的均匀线段,线段的长度等于区的宽度,且每一线段被划分成数目W≥2的数据单元,每一数据单元具有数目Q≥2的字节,即Q字节数据单元,且针对每一区界定数目H≥2的扫描线的区高度。
数据单元存储于存储器220中,使得来自不同区的数据单元相对于彼此交错,而传入图像的区的每一行的每一线段的连续数据单元以K个存储器位置的偏移进行存储,使得连续数据单元相隔K个存储器地址而存储。
系统还被配置成将存储于存储器220中的K数目的Q字节数据单元的每一组合转置成Q数目的K字节字的经转置的组合,每一K字节字包含每集群一个字节。举例来说,这可由转置块230执行。
系统还被配置成将每一K字节字的字节并行地传送到处理集群,每集群一个字节。
在特定实例中,为了相机图像(静态或视频)的高效分割,在每一帧循环/周期(例如,50ms)期间,一个视频数据帧被传送到存储器(例如,DRAM),且根据某些规则(基于图像的逻辑分割)放置于该处。例如16字节的每一群组存储于一地址中,所述地址取决于其在区中的位置,而且取决于区的水平和竖直位置。
在下一帧循环/周期期间处理存储的图像。举例来说,处理以经由转置块从存储器的传送开始。每一集群将随后以正确的次序接收其完整图像的部分。
- 一种用于神经网络的片上存储处理系统
- 一种用于神经网络的片上存储处理系统