一种可燃物易燃性评估方法、装置、设备及存储介质
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及易燃性评估预测技术领域,具体涉及一种可燃物易燃性评估方法、装置、设备及存储介质。
背景技术
野火是全球生态系统中最重要的自然干扰过程之一,大面积火灾的发生对生态、经济都会带来无法估量的伤害,而伴随火灾的发生产生的大量温室气体在一定程度上也影响着人类的健康。
野火发生概率以及蔓延速度主要受到气候、地形与可燃物易燃性的影响。其中气候和地形的时空分布比较稳定,相关数据的获取也比较容易。因此,准确评估预测各区域可燃物易燃性在评估和预警野火风险的研究中占有关键地位。
现有技术中在进行可燃物易燃性评估过程中由于不同植被类型所对应的植被因子差距较大,无视这种差别在进行模型训练时会导致模型分辨率下降进而影响可燃物易燃性的评估结果。
发明内容
在进行可燃物易燃性评估过程中由于不同植被类型所对应的植被因子差距较大,无视这种差别在进行模型训练时会导致模型分辨率下降进而影响可燃物易燃性的评估结果的问题,本发明提供一种可燃物易燃性评估方法、装置、设备及存储介质。
第一方面,本发明技术方案提供一种可燃物易燃性评估方法,包括如下步骤:
在监测的遥感数据中提取研究区域的植被数据和历史火点数据;植被像元包括森林像元、灌木像元和草原像元;
从提取的数据中获取模型训练时所需的指标因子;
将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;
将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数;
获取研究区域设定位置的像元点并提取该像元点位置的指标因子输入训练后的模型计算出该像元点的可燃物易燃性年变化曲线。
作为本发明技术方案的进一步限定,从提取的数据中获取模型训练时所需的指标因子的步骤之后包括:
将获取的指标因子进行相关性分析,并根据分析结果筛选得到应用的指标因子。
作为本发明技术方案的进一步限定,将获取的指标因子进行相关性分析,并根据分析结果筛选得到应用的指标因子的步骤包括:
使用皮尔森相关系数对各指标因子进行两两相关性分析计算得到皮尔森相关系数矩阵;
将皮尔森相关系数矩阵中相关系数大于设定阈值对应的指标因子从提取的数据中去除,剩余指标因子为应用的指标因子;
公式如下:
式中,X、Y分别表示两组数据,ρ
作为本发明技术方案的进一步限定,指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值以及火灾发生前一时刻的可燃物含水率与该植被像元全年平均可燃物含水率的比率;
应用的指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值。
作为本发明技术方案的进一步限定,将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型的步骤包括:
将筛选得到的应用的指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型。
作为本发明技术方案的进一步限定,将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数的步骤包括:
将应用的指标因子数据按照植被像元的不同划分为森林像元数据集、灌木像元数据集和草原像元数据集;
分别将森林像元数据集、灌木像元数据集和草原像元数据集中的数据按照设定比例划分成对应的训练数据和验证数据;
分别将训练数据带入Logistic模型进行模型训练并采用验证数据对训练的模型进行验证得到不同植被像元的模型参数。
第二方面,本发明技术方案提供一种可燃物易燃性评估装置,包括数据提取模块、指标因子获取模块、模型参数训练模块和评估执行模块;
数据提取模块,用于在监测的遥感数据中提取研究区域的植被数据和历史火点数据;植被像元包括森林像元、灌木像元和草原像元;
指标因子获取模块,用于从提取的数据中获取模型训练时所需的指标因子;
模型参数训练模块,用于将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数;
评估执行模块,用于获取研究区域设定位置的像元点并提取该像元点位置的指标因子输入训练后的模型计算出该像元点的可燃物易燃性年变化曲线。
作为本发明技术方案的进一步限定,该装置还包括相关性分析模块,用于将获取的指标因子进行相关性分析,并根据分析结果筛选得到应用的指标因子。
作为本发明技术方案的进一步限定,相关性分析模块包括分析计算单元和计算处理单元;
分析计算单元,用于使用皮尔森相关系数对各指标因子进行两两相关性分析计算得到皮尔森相关系数矩阵;
计算处理单元,用于将皮尔森相关系数矩阵中相关系数大于设定阈值对应的指标因子从提取的数据中去除,剩余指标因子为应用的指标因子;
公式如下:
式中,X、Y分别表示两组数据,ρ
作为本发明技术方案的进一步限定,指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值以及火灾发生前一时刻的可燃物含水率与该植被像元全年平均可燃物含水率的比率;
应用的指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值。
作为本发明技术方案的进一步限定,模型参数训练模块包括变量输入单元、像元数据集生成单元、数据集划分单元和参数训练优化单元;
变量输入单元,用于将筛选得到的应用的指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;
像元数据集生成单元,用于将应用的指标因子数据按照植被像元的不同划分为森林像元数据集、灌木像元数据集和草原像元数据集;
数据集划分单元,用于分别将森林像元数据集、灌木像元数据集和草原像元数据集中的数据按照设定比例划分成对应的训练数据和验证数据;
参数训练优化单元,用于分别将训练数据带入Logistic模型进行模型训练并采用验证数据对训练的模型进行验证得到不同植被像元的模型参数。
第三方面,本发明技术方案提供一种电子设备,所述电子设备包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;存储器存储有可被至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如第一方面所述的可燃物易燃性评估方法。
第四方面,本发明技术方案还提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行如第一方面所述的可燃物易燃性评估方法。
从以上技术方案可以看出,本发明具有以下优点:
针对存在相关性高的因子,会导致数据冗余,反应在模型上会产生过拟合现象的问题,需要对选取的指标因子进行相关性检验,以定量地分析指标因子之间的相关关系,去除相关性过高的指标因子,提高模型的精度。
针对植被像元的可燃物载荷与可燃物含水率两种植被因子存在差别(例如,与森林像元相比,灌木像元的可燃物载荷更集中于低值,而可燃物含水率更集中于高值)无视这种差别将所有数据输入到模型中训练,导致训练出的模型糅合了不同的特性,使模型的分辨能力下降的问题,本申请将数据分离为森林、灌木、草原三个数据集,将各自数据集按照设定比例划分训练数据和验证数据,得到三个适用于各自植被类型的模型,从而提高模型的精度。
此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
由此可见,本发明与现有技术相比,具有突出的实质性特点和显著地进步,其实施的有益效果也是显而易见的。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
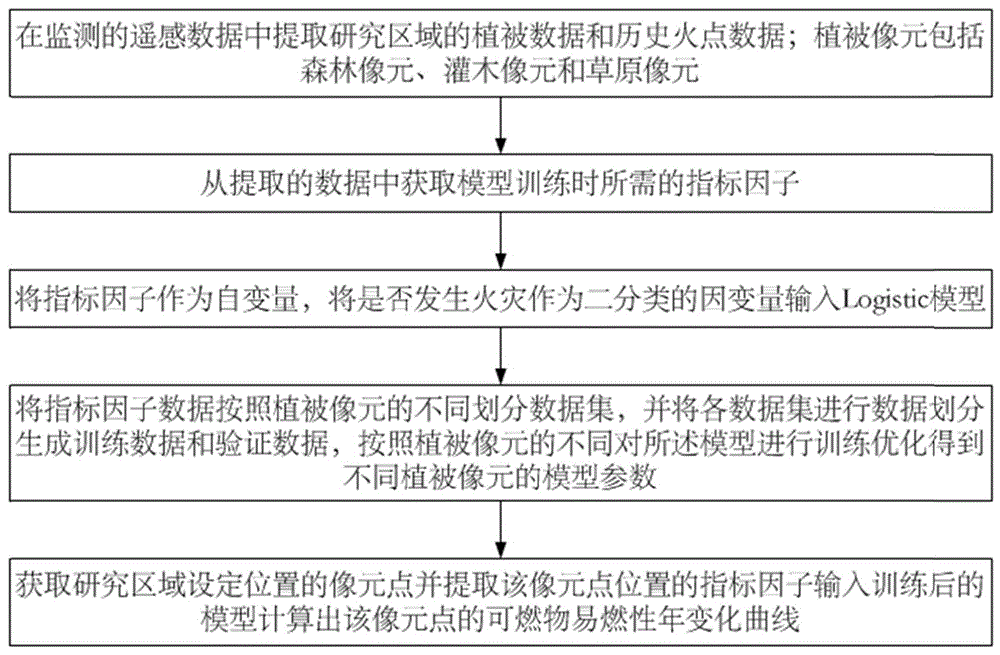
图1是本发明一个实施例的方法的示意性流程图。
图2是本发明一个实施例的装置的示意性框图。
具体实施方式
为了使本技术领域的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
如图1所示,本发明实施例提供一种可燃物易燃性评估方法,包括如下步骤:
步骤1:在监测的遥感数据中提取研究区域的植被数据和历史火点数据;植被像元包括森林像元、灌木像元和草原像元;
步骤2:从提取的数据中获取模型训练时所需的指标因子;
步骤3:将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;
步骤4:将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数;
步骤5:获取研究区域设定位置的像元点并提取该像元点位置的指标因子输入训练后的模型计算出该像元点的可燃物易燃性年变化曲线。
针对存在相关性高的因子,会导致数据冗余,反应在模型上会产生过拟合现象的问题,在有些实施例中,从提取的数据中获取模型训练时所需的指标因子的步骤之后包括:
步骤2-3:将获取的指标因子进行相关性分析,并根据分析结果筛选得到应用的指标因子。具体包括:
步骤2-3-1:使用皮尔森相关系数对各指标因子进行两两相关性分析计算得到皮尔森相关系数矩阵;
步骤2-3-2:将皮尔森相关系数矩阵中相关系数大于设定阈值对应的指标因子从提取的数据中去除,剩余指标因子为应用的指标因子;
公式如下:
式中,X、Y分别表示两组数据,ρ
需要说明的是,指标因子包括火灾发生当月的森林可燃物载荷FFL、火灾发生前一时刻的可燃物含水率FMC
DIF和ANO的计算方法如下:
DIF=FMC
森林可燃物载荷是指单位面积上所有可燃物的烘干重量,可燃物含水率是指可燃物含水量与其干重的比率,这两种因子都与林火的发生及行为有着密切关系;而另外两种因子,DIF可以在一定程度上反应可燃物含水率在火灾发生前的变化趋势。由于理论上可燃物含水率与可燃物易燃性成负相关关系,故当DIF值为正,即FMC
需要说明的是,在火点数据的提取上,选取MCD64A1产品中有效值点作为火点数据,并根据其像元值提取对应的指标因子。
在非过火点数据的提取上,需要提取与过火点等量的相同归类类型的非过火点。由于在实际情况中,火灾的发生与否除了受到植被因素的影响,同时也受到天气条件、地形等条件的影响,而部分引起森林火灾的火源,如人为因素和雷电等,通常具有较强的偶然性和不确定性。因此,在历史火点数据中过火信息表示为0的点并不代表该点的可燃物易燃性低。如果将这样的点作为非过火点加入到数据集中,就会降低数据之间的差异性,使模型的准确率受到影响。为此,我们需要对非过火点进行筛选。通过过火点时间分布特征,结合已知所研究区域的气候条件,可以推断出夏季时该区域的植被因子与冬季差别较大,其对应起火概率也较其他季节更低。所以,将这一时间段的指标因子作为数据集中的非过火点更具代表性,训练出的模型效果也会更好。因此,选择在6月和7月随机选取与过火点类型和数量相等的非过火点。最后,共得到了155对火点和非火点数据,其中36对为森林像元,35对为灌木像元,85对为草原像元。
在数据提取阶段所选择的指标因子更关心其与结果之间是否存在联系,对于不同因子之前的关系则考虑较少。如果存在相关性高的因子,就会导致数据冗余,从而使某些方面的信息在结果中的权重过高,反应在模型上就会产生过拟合现象,具体表现为模型的内部验证精度很高,外部验证精度则大幅降低。因此,需要对选取因子进行相关性检验,以定量地分析因子之间的相关关系,去除相关性过高的因子,提高模型的精度。
皮尔森相关系数的取值范围为-1到1的闭区间,其符号表示两组数据呈正相关还是负相关,负值表示两组数据呈负相关关系,正值则表示两组数据呈正相关关系。系数的绝对值表示两组数据相关性的强弱,绝对值越大相关性越强,1表示完全线性相关,0表示非线性相关。在统计学上,一般将系数值以0.2为长度划分为5个范围,用来表示5种不同水平的相关性。具体划分方式为0-0.19表示相关性处于极低水平,0.2-0.39表示相关性处于较低水平,0.4-0.59表示相关性处于中等水平,0.6-0.79表示相关性处于较高水平,0.8-1表示相关性处于极高水平。需要计算多组数据两两之间的相关性时,用矩阵的行和列表示参与计算的数据类型,就得到了皮尔森相关系数矩阵,该矩阵是一个对角线元素为1的实对称矩阵。对本次实验数据计算得到的皮尔森相关系数矩阵如表1所示。
表1
由表格所示,FFL数据与FMC
应用的指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值。
相应的,将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型的步骤包括:
将筛选得到的应用的指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型。
针对植被像元的可燃物载荷与可燃物含水率两种植被因子存在差别(例如,与森林像元相比,灌木像元的可燃物载荷更集中于低值,而可燃物含水率更集中于高值)无视这种差别将所有数据输入到模型中训练,导致训练出的模型糅合了不同的特性,使模型的分辨能力下降的问题;在有些实施例中,将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数的步骤包括:
步骤41:将应用的指标因子数据按照植被像元的不同划分为森林像元数据集、灌木像元数据集和草原像元数据集;
步骤42:分别将森林像元数据集、灌木像元数据集和草原像元数据集中的数据按照设定比例划分成对应的训练数据和验证数据;
步骤43:分别将训练数据带入Logistic模型进行模型训练并采用验证数据对训练的模型进行验证得到不同植被像元的模型参数。
本申请将数据分离为森林、灌木、草原三个数据集,将各自数据集按照设定比例划分训练数据和验证数据,得到三个适用于各自植被类型的模型,从而提高模型的精度。
将数据分离为森林、灌木、草原三个数据集,其中森林数据36对,灌木数据35对,草原数据85对,将这些数据集中各取80%带入到模型中进行训练,剩余20%用于验证,得到三个适用于各自植被类型的模型。经计算,Logistic回归模型所得到的森林、灌木、草原的可燃物易燃性模型的AUC值分别为0.86、0.78和0.56;与原模型对比可以发现,森林和灌木的Logistic回归模型的AUC值有较大幅度的提升。
如图2所示,本发明实施例提供一种可燃物易燃性评估装置,包括数据提取模块、指标因子获取模块、模型参数训练模块和评估执行模块;
数据提取模块,用于在监测的遥感数据中提取研究区域的植被数据和历史火点数据;植被像元包括森林像元、灌木像元和草原像元;
指标因子获取模块,用于从提取的数据中获取模型训练时所需的指标因子;
模型参数训练模块,用于将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数;
评估执行模块,用于获取研究区域设定位置的像元点并提取该像元点位置的指标因子输入训练后的模型计算出该像元点的可燃物易燃性年变化曲线。
在有些实施例中,该装置还包括相关性分析模块,用于将获取的指标因子进行相关性分析,并根据分析结果筛选得到应用的指标因子。
具体的,相关性分析模块包括分析计算单元和计算处理单元;
分析计算单元,用于使用皮尔森相关系数对各指标因子进行两两相关性分析计算得到皮尔森相关系数矩阵;
计算处理单元,用于将皮尔森相关系数矩阵中相关系数大于设定阈值对应的指标因子从提取的数据中去除,剩余指标因子为应用的指标因子;
公式如下:
式中,X、Y分别表示两组数据,ρ
指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值以及火灾发生前一时刻的可燃物含水率与该植被像元全年平均可燃物含水率的比率;
应用的指标因子包括火灾发生当月的森林可燃物载荷、火灾发生前一时刻的可燃物含水率、火灾发生前一时刻与火灾发生前两时刻的可燃物含水率的差值。
在有些实施例中,模型参数训练模块包括变量输入单元、像元数据集生成单元、数据集划分单元和参数训练优化单元;
变量输入单元,用于将筛选得到的应用的指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;
像元数据集生成单元,用于将应用的指标因子数据按照植被像元的不同划分为森林像元数据集、灌木像元数据集和草原像元数据集;
数据集划分单元,用于分别将森林像元数据集、灌木像元数据集和草原像元数据集中的数据按照设定比例划分成对应的训练数据和验证数据;
参数训练优化单元,用于分别将训练数据带入Logistic模型进行模型训练并采用验证数据对训练的模型进行验证得到不同植被像元的模型参数。
本发明实施例还提供一种电子设备,所述电子设备包括:处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信。通信总线可以用于电子设备与传感器之间的信息传输。处理器可以调用存储器中的逻辑指令,以执行如下方法:步骤1:在监测的遥感数据中提取研究区域的植被数据和历史火点数据;植被像元包括森林像元、灌木像元和草原像元;步骤2:从提取的数据中获取模型训练时所需的指标因子;步骤3:将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;步骤4:将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数;步骤5:获取研究区域设定位置的像元点并提取该像元点位置的指标因子输入训练后的模型计算出该像元点的可燃物易燃性年变化曲线。
此外,上述的存储器中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
本发明实施例提供一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质存储计算机指令,该计算机指令使计算机执行上述方法实施例所提供的方法,例如包括:步骤1:在监测的遥感数据中提取研究区域的植被数据和历史火点数据;植被像元包括森林像元、灌木像元和草原像元;步骤2:从提取的数据中获取模型训练时所需的指标因子;步骤3:将指标因子作为自变量,将是否发生火灾作为二分类的因变量输入Logistic模型;步骤4:将指标因子数据按照植被像元的不同划分数据集,并将各数据集进行数据划分生成训练数据和验证数据,按照植被像元的不同对所述模型进行训练优化得到不同植被像元的模型参数;步骤5:获取研究区域设定位置的像元点并提取该像元点位置的指标因子输入训练后的模型计算出该像元点的可燃物易燃性年变化曲线。
尽管通过参考附图并结合优选实施例的方式对本发明进行了详细描述,但本发明并不限于此。在不脱离本发明的精神和实质的前提下,本领域普通技术人员可以对本发明的实施例进行各种等效的修改或替换,而这些修改或替换都应在本发明的涵盖范围内/任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种高效除油剂及其制备方法
- 一种生活垃圾处理用除油剂及其制备方法
- 一种用于金属表面的除油剂及其制备方法
- 一种生质除油剂及其制备方法
- 一种改良生肌玉红膏油剂及其制备方法
- 一种利用改良生肌玉红膏油剂治疗放射性食管炎的方法