基于机器学习与博弈论的油井多层合采产量劈分方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于油井产量劈分技术领域,尤其涉及基于机器学习与博弈论的油井多层合采产量劈分方法。
背景技术
在石油天然气领域,研究分层产量有助于了解各小层的生产状况,认识地质储层和油气藏剩余油气分布规律,并对后期开发策略调整提供参考,因此建立一套高效准确,适用性强的产量劈分方法对油藏高效开发有着重要意义。
目前产量劈分的方法主要有地层系数法,产液剖面系数法,有效厚度法,渗流阻力系数法,突变理论法和数值模拟法等。地层系数法简单,参数选择单一,误差较大;产气剖面测试法所需的测试时间长,成本较高;产液剖面系数法劈分精度低、可信度差;有效厚度法没有考虑油藏的压差,物质平衡等因素;渗流阻力系数法无法确定影响因素对结果的作用大小,适用性差;突变理论法可靠性强、计算速度快,但是缺少对各个子系统中影响因素重要性的排序;数值模拟法计算过程复杂,运算速度慢,具有多解性。
机器学习算法可以综合考虑油藏动静态数据,参数选择多样,产量预测时间短,计算速度快,成本低。在产量预测的基础上,融合机器学习和基于博弈论的SHAP(SHapleyAdditive exPlanation)算法,可以挖掘各个因素于产量之间的复杂非线性关系,量化各个因素对结果的贡献程度,并做因素重要性排序。因而考虑融合机器学习和博弈论算法,通过各个小层对结果的贡献度确定各小层的劈分系数,从而对产量进行劈分,量化分层产量。
发明内容
本发明的目的在于提供一种基于机器学习与博弈论的油井多层合采产量劈分方法,以解决上述背景技术中提出的传统产量劈分方法精度较低、不确定性强和适应性差等问题。
为实现上述目的,本发明采用以下技术方案实现:
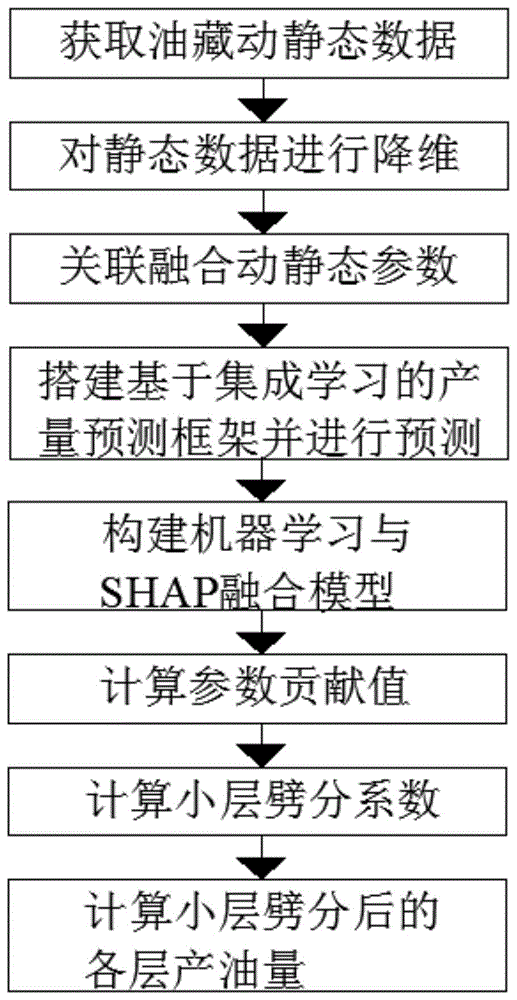
基于机器学习与博弈论的油井多层合采产量劈分方法,包括以下步骤:
S1、获取油井动静态参数作为数据集:获取油井每层的静态参数及获取油井月生产动态参数,对油井每层的静态参数降维计算为单个参数,将油井每层所代表的参数联合油井月生产动态参数作为单个油井总参数,该单个油井总参数作为单个样本,将所有油井的样本数据串联作为产量预测模型的数据集;
S2、搭建基于机器学习的产量预测模型:构建CatBoost产量预测模型,利用S1中数据集训练CatBoost产量预测模型,并进行产量预测结果预测;
S3、构建机器学习与SHAP融合模型:将CatBoost产量预测模型融入到基于博弈论算法的SHAP解释器中,得到CatBoost-SHAP融合模型;
S4、计算参数贡献值:利用CatBoost-SHAP融合模型计算单个样本中油井每层所代表的参数和各个动态参数对产量预测结果的贡献值;
S5、计算小层劈分系数;提取S4中油井每层所代表的参数对产量预测结果的贡献度的绝对值,计算小层劈分系数;
S6、计算小层劈分后的各层产油量;基于小层劈分系数获得油井各个小层的产油量。
优选地,所述S1中获取油井动静态参数作为数据集,具体包括如下步骤:
S101、获取油井动静态参数数据;
获取油井中小层的静态参数,每个小层均包括孔隙度、渗透率、有效储层厚度和原始含水饱和度的4个静态参数;获取油藏月生产动态参数,包括流压、套压、油压、含水率的4个动态参数;
S102、对每层静态参数数据进行降维;
设置τ值对油井每层所代表的参数进行表征,计算方法如下:
S103、关联融合动静态参数;
将每口油井的层数统一,且将油井每层所代表的参数联合油井月生产动态参数作为单个油井总参数。
优选地,所述S103中关联融合动静态参数,具体包括如下步骤:
S1031、统一小层数:选择所有油井中最大的小层数layerNumMax作为基准小层数,设定每口油井均有layerNumMax个小层,保持数据维度的一致性;
S1032、缺失数据补全:对于小层数layerNum S1033、动静态数据关联融合;将油井的动态参数与油井每层所代表的参数横向拼接,数据维度为4+layerNumMax;将所有油井的数据串联,形成维度为(x*n_ave)*(4+layerNumMax)的数据模块,即共有x*n_ave条样本,该数据模块即为CatBoost产量预测模型的数据集; 其中,x为所有油井数量,n_ave为不同油井监测生产动态变化的月数的平均值。 优选地,所述S2中搭建基于机器学习的产量预测模型,具体包括如下步骤: S201、数据集处理:将数据集按照8:2的比例随机划分为训练集和测试集; S202、CatBoost产量预测模型为基于多个对称决策树的集成模型,CatBoost产量预测模型的超参数设置为:树的最大深度max_depth=5,学习率learning_rate=0.1,迭代次数iterations=1000;利用训练集训练CatBoost产量预测模型; S203、以决定系数R2为CatBoost产量预测模型精度评判标准,利用测试集评估CatBoost产量预测模型预测效果,当R2>0.75时,认为CatBoost产量预测模型达到预测标准。 优选地,所述S3中构建机器学习与SHAP融合模型,具体如下: 建立基于树模型的SHAP解释器,将机器学习中的CatBoost集成算法融入到基于博弈论算法的SHAP解释器中,构建CatBoost-SHAP融合模型。 优选地,所述S4中计算参数贡献值,具体如下: 将输入到CatBoost产量预测模型的数据集输入到SHAP解释器中,利用SHAP解释器对训练好的CatBoost产量预测模型进行解释,计算得到单个样本中油井每层所代表的参数和各个动态参数对产量预测结果的贡献值;计算方法如下: 其中,f(x)表示待解释的CatBoost产量预测模型,g(•)表示SHAP解释器;φ 优选地,对油井每层所代表的参数和各个动态参数对产量预测结果的贡献值的绝对值进行降序排列,得到各个参数的重要性。 优选地,所述S5中计算小层劈分系数,具体如下: 提取油井每层所代表的参数对产量预测结果的贡献度的绝对值,并计算小层劈分系数Contribute,计算方法如下: 其中,S 优选地,所述S6中计算小层劈分后的各层产油量,具体如下: 将油井的月产油量Production 与现有技术相比,本发明的有益效果是: (1)、本发明中该方法首次将机器学习与博弈论融合模型应用于油井的产量劈分,在产量预测结果的基础上,通过SHAP算法量化各个小层的贡献度,并以此作为小层劈分系数,计算各层产量,为油井产量劈分提供了一套高效可行的方法,具有很好的技术价值和应用前景。 (2)、本发明中该方法综合考虑了油井的动态生产数据和静态储层数据,通过机器学习算法充分挖掘了动静态数据与产量之间的复杂非线性关系,计算速度快,成本低,避免了传统劈分方法参数选择单一的问题,并解决了部分劈分方法(如数值模拟法)耗时费力的问题,提高了产量劈分的精度。 (3)、本发明中该方法不仅可以量化各个因素对结果的贡献程度,还可以做因素重要性排序,从而确定不同井在不同时间下各个小层的贡献率大小,为后续小层开发提供指导。 附图说明 图1为本发明中基于机器学习与博弈论的油井多层合采产量劈分方法的流程图; 图2为本发明实施例2中的Well#2在2008年5月各个参数对产油量的贡献的示意图。 具体实施方式 下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。 实施例1: 参见图1,基于机器学习与博弈论的油井多层合采产量劈分方法,包括以下步骤: (1)获取油藏动静态数据。 获取储层中小层的静态参数,每个小层均包括孔隙度、渗透率、有效储层厚度和原始含水饱和度4个参数。假设某储层有m小层,则静态数据维度为m*4。 获取油藏月生产动态参数,包括流压、套压、油压、含水率,其中,流压、套压、油压、含水率这4个动态参数均为与时间相关的序列数据,假设监测油藏n个月的生产动态,则动态数据维度为n*4。 值得注意的是,该步骤的动静态参数可以根据油藏情况进行补充或替换,不局限于本实施例中列出的这几个参数。 (2)对静态数据进行降维。 综合考虑4个静态参数,设置τ值对储层参数进行表征,计算方法如下: 此时,静态数据维度由原来的m*4维降为m*1。 值得注意的是,该步骤中τ与具体的储层参数相关,不局限于本实施例中列出的4个参数,但在添加时,应考虑这些参数对产量的正负影响。若该参数与产量呈正相关关系,则将其放于分子,并与分子中其他参数相乘;若为负相关关系,则将参数放于分母,并与分母中其他参数相乘。 (3)关联融合动静态参数。该步骤主要有三个部分: 1)统一小层数,从而保持数据维度的一致性:假设某区块共有x口井{Well#1,Well#2,Well3#,…,Well#x},每口井的小层数分别为{layerNum1,layerNum2,layerNum3,…,layerNumx}。为了保持不同井数据维度的一致性,选择所有井中最大的小层数layerNumMax作为基准小层数,认为每口井均有layerNumMax个小层,即步骤(1)中的m=layerNumMax。进而基于步骤(2),获得单井的静态数据维度为layerNumMax*1,这样便解决了不同井的小层数目不同的问题。 2)缺失数据补全:由于使用了所有井中最大小层数作为基准小层数,因而对于小层数layerNum 3)动静态数据关联融合:关联融合方法如下: 首先对每口井的静态数据进行转置,数据维度由原来的layerNumMax*1转为1*layerNumMax。 然后将转置后的静态数据纵向复制n_i次(假设监测了油井Well#i n个月的动态变化),数据维度由1*layerNumMax转为n_i*layerNumMax。 进一步,将该油井的动态数据与复制后的静态数据横向拼接,数据维度为n_i*(4+layerNumMax)。 最后将所有井的数据串联,形成维度为(x*n_ave)*(4+layerNumMax)的数据模块,即共有x*n_ave条样本,其中n_ave为不同井监测生产动态变化的月数的平均值。该数据模块即为后续产量预测模型所需的数据集。 (4)搭建基于集成学习的产量预测框架并进行预测。 首先基于步骤(3)的数据集,将数据集按照0.8:0.2的比例随机划分为训练集和测试集,训练集用来训练机器学习模型,测试集用来评估机器学习预测效果。 然后利用鲁棒性和效率较高的CatBoost模型进行产量预测。该模型为基于多个对称决策树的集成模型,采用梯度提升算法,通过两个阶段构建新的树:第一阶段时选择树结构,第二个阶段是计算叶子节点的值。通过枚举不同的分割模式构建树,计算分割后的叶子节点的值,进而对得到的树进行计算评分,选择最佳的分割形式,从而构建成为新的树。进而设置模型的超参数,包括树的最大深度,学习率,和迭代次数等。 具体地,模型的超参数设置为:树的最大深度max_depth=5,学习率learning_rate=0.1,迭代次数iterations=1000。 最后以决定系数R2为模型精度评判标准,当R2>0.75时,认为模型达到预测标准,保存该预测模型。 (5)构建机器学习与SHAP融合模型。 建立基于树模型的SHAP解释器,将机器学习中的CatBoost集成算法融入到基于博弈论算法的SHAP解释器中,构建CatBoost-SHAP分析框架。 具体地,首先确定解释数据,一般的,解释数据与输入机器学习模型的数据集相同;然后将CatBoost模型保存为.model格式,该格式下模型的架构和相关权重值均得以保留;进而针对模型类型构建对应的解释器,在本发明中,采用树解释器对机器学习模型进行解释,包括解析树型结构,确定分支和节点的值;计算各个参数和各个样本的SHAP值;提供可视化结果等。 (6)计算参数贡献值。 计算某口井在某个时间下,各个特征参数的SHAP值。即将步骤(4)输入到机器学习的数据集输入到SHAP解释器中,进而用SHAP解释器对训练好的CatBoost模型进行解释,计算得到单个样本的SHAP值。计算方法如下: 其中,f(x)表示待解释的CatBoost产量预测模型,g(•)表示解释模型,利用解释模型对CatBoost模型的输出进行解释。解释模型的输入x′为原始模型输入x的简化,可通过映射函数进行转换x=h (7)计算小层劈分系数:取各个小层对单个样本结果的贡献度的绝对值,并计算小层劈分系数Contribute,计算方法如下: 其中,S (8)计算小层劈分后的各层产油量:计算某口井在某月小层劈分后的各层产油量,需要首先从动态生产数据中获取该样本的产油量数据Production Production 以此方法计算该井在其他时间下的产量劈分结果,以及其他井在不同时间下的产量劈分结果。 实施例2: 参见图1-2,以某油藏的基本参数进行说明,基于机器学习与博弈论的油井多层合采产量劈分方法,具体如下: (1)获取某油藏动静态数据。该油藏共有62口井,每口井均包括孔隙度、渗透率、有效储层厚度和原始含水饱和度4个静态参数和流压、套压、油压、含水率4个月生产动态参数。将某口井某个时间下的4个静态参数和4个动态参数作为一个样本,共6748个初始样本。 (2)对所有样本中的静态数据进行降维。综合考虑孔隙度、渗透率、有效储层厚度和原始含水饱和度这4个静态参数,设置τ值对储层参数进行表征,计算方法如下: 不同井的静态储层参数不同,以某个单井为例,该井第1小层的孔隙度为0.304、渗透率为0.356mD、有效储层厚度为2.2m、原始含水饱和度19.55%,则 (3)关联融合动静态参数。该步骤主要有三个部分: 1)统一小层数,从而保持数据维度的一致性:在该实施例中,共有62口井,编号为{Well#1,Well#2,Well3#,…,Well#62}。每口井的小层不完全相同,以四口井为例:Well#1有5小层,即layerNum1=5,分别为layer#1,layer#2,layer#3,layer#4,和layer#5。Well#2有4小层,即layerNum2=4,分别为layer#1,layer#3,layer#4,和layer#5。Well#3有4小层,即layerNum3=4,分别为layer#1,layer#3,layer#5,和layer#6。Well#4有6小层,即layerNum4=6,分别为layer#1,layer#2,layer#3,layer#4,layer#5,和layer#6。 为了保持不同井数据维度的一致性,选择所有井中最大的小层数layerNumMax作为基准小层数,在本实施例中,layerNumMax=6,即认为每口井均有6个小层,分别为{layer#1,layer#2,layer#3,layer#4,layer#5,和layer#6}。进而基于步骤(2),获得单井的静态数据维度为6*1。 2)缺失数据补全:由于使用了所有井中最大小层数作为基准小层数,因而对于小层数layerNum<6的井(如Well#1,Well#2,和Well#3)而言,存在部分小层数据缺失问题(Well#1缺少layer#6;Well#2缺少layer#2和layer#6;Well#3缺少layer#2,layer#4和layer#6),因而也无法获取缺失小层的τ值,因此需要补全该部分数据,保证数据的完整性。补全方法为:将原始资料中不存在的小层的τ值均设置为0,即对Well#1,将layer#6和layer#7的τ设置为0,其他井补全方法类似。 3)动静态数据关联融合:首先对每口井的静态数据进行转置,数据维度由原来的6*1转为1*6。然后将转置后的静态数据纵向复制n次。本实施例中,以Well#1为例,监测了该油井36个月的动态变化,则n=36,数据维度由1*6转为36*6。进一步的,将该油井的动态数据与复制后的静态数据横向拼接,数据维度为36*(4+6),即36*10维。最后将所有井的数据串联,形成维度为6748*10的数据模块,即共有6748条样本,该数据模块即为后续产量预测模型所需的数据集。 (4)搭建基于集成学习的产量预测框架并进行预测:基于步骤(3)的数据集,将数据集按照8:2的比例随机划分为训练集和测试集,即训练集有5398个样本,测试集有1350个样本。进而构建CatBoost模型,并利用CatBoost模型进行产量预测。CatBoost模型的超参数设置为:树的最大深度max_depth=5,学习率learning_rate=0.1,迭代次数iterations=1000。在本实施例中,R2=0.88>0.75,因而认为模型达到预测标准,以.model文件格式保存训练好的模型。 (5)构建机器学习与SHAP融合模型:建立基于树模型的SHAP解释器,将机器学习中的CatBoost集成算法融入到基于博弈论算法的SHAP解释器中,即将步骤(4)中保存的.model文件作为SHAP解释器中待解释的模型,从而形成CatBoost-SHAP分析框架。 (6)计算参数贡献值:计算某口井在某个时间下,各个特征参数的SHAP值。以Well#2为例,计算该井在2008年5月不同参数对结果的贡献值,即将步骤(4)输入到机器学习的数据集输入到SHAP解释器中,进而用SHAP解释器对训练好的CatBoost模型进行解释,计算得到单个样本的SHAP值,如图2所示。计算方法如下: 其中,f(x)表示待解释的CatBoost产量预测模型,g(·)表示SHAP解释模型,利用解释模型对CatBoost模型的输出进行解释。 计算结果如下(按照贡献度的绝对值降序排列):含水率=132.82,layer#2=22.86,套压=12.9,layer#4=9.55,layer#1=8.55,layer#3=7.21,油压=5.5,流压=4.6,layer#6=3.69,layer#5=0.14。 (7)计算小层劈分系数:取各个小层对单个样本结果的贡献度的绝对值,并计算小层劈分系数Contribute,计算方法如下: 其中,S 以Well#2为例,基于步骤(6)得到的是所有参数的贡献值的绝对值,将其中小层的贡献值提取出来,得到每个小层的|S (8)计算小层劈分后的各层产油量:在该实施例中,Well#2在2008年5月的月产油量为47m 计算结果为:Production 至此,便完成了油井的小层劈分。 以上所述,仅用于帮助理解本发明的方法及其核心要义,但本发明的保护范围并不局限于此,对于本技术领域的一般技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种硅片光刻版工艺
- 一种硅片裂片装置及硅片划片加工系统
- 一种硅片的处理方法及装置
- 一种光刻设备中的硅片承载装置
- 一种光刻设备中的硅片承载装置