结合生成对抗网络与神经网络的高炉煤气发生量预测方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及人工智能技术领域,更具体地说,涉及一种结合生成对抗网络与神经网络的高炉煤气发生量预测方法。
背景技术
随着我国经济的发展,人民生活在日益变好的同时,我国的环境污染和能源利用率低等问题日益严重,而其中尤其以钢铁企业这一能源消耗大户最为严重。
高炉煤气是钢铁生产过程中主要的二次能源,其特点是热值较低、自身性质不稳定,这使得高炉煤气的生产过程较为复杂而且产出量会有较大幅度的波动,较难控制。与钢铁生产过程中的其他副产品不同,高炉煤气的发生量常常会在正常生产过程结束后依然会有大量的剩余。另外,高炉煤气的发生量在生产过程中的过多或过少都会导致生产设备的停火,中断钢铁生产过程,造成安全隐患和原料浪费。因此,如果不能准确的预测高炉煤气发生量,不仅会让生产过程中存在安全问题,还会造成能源浪费和环境污染,并且还会产生经济损失。
当前我国大多数钢铁企业在实际生产过程中为使得各个生产环节高效运行,优化煤气系统中各项数值和指标,通常都需要对煤气运输管道中的各个用煤气用户的煤气产生量和消耗量进行实时的监测。然而,煤气系统容易因为生产状况的影响而发生多种复杂不稳定的情况使得煤气系统具有多变性,容易出现幅值较大的震荡现象使得系统不稳定。另外,由于煤气系统本身非常庞大,当工况改变时,无法实时地根据不同的情况来对煤气进行调度,并且煤气系统中设立的缓冲装置的缓冲能力有限,因此很难根据煤气系统本身来构建合适的机理预测模型。如今,大多数钢铁企业在炼钢生产过程中的高炉煤气调度依然依靠的是煤气调度专家自身的经验,因而存在预测不及时、预测精度低、能源利用率低、调度方案受个人主观影响大等问题,这严重影响了钢铁生产过程的效率和安全。
现存的能源管理模式无法实时的对高炉煤气的大幅波动作出调整,而且预测精度也较低,无法最终实现能源平衡,达到节能减排的目的。
发明内容
针对高炉煤气发生量预测中存在的上述问题,本发明提出了一种基于生成对抗网络和BP神经网络相结合的建模预测方法,以实现精确的高炉煤气发生量预测。
为了实现上述目的,现提出的方案如下:
一种结合生成对抗网络与神经网络的高炉煤气发生量预测方法,包括以下步骤:
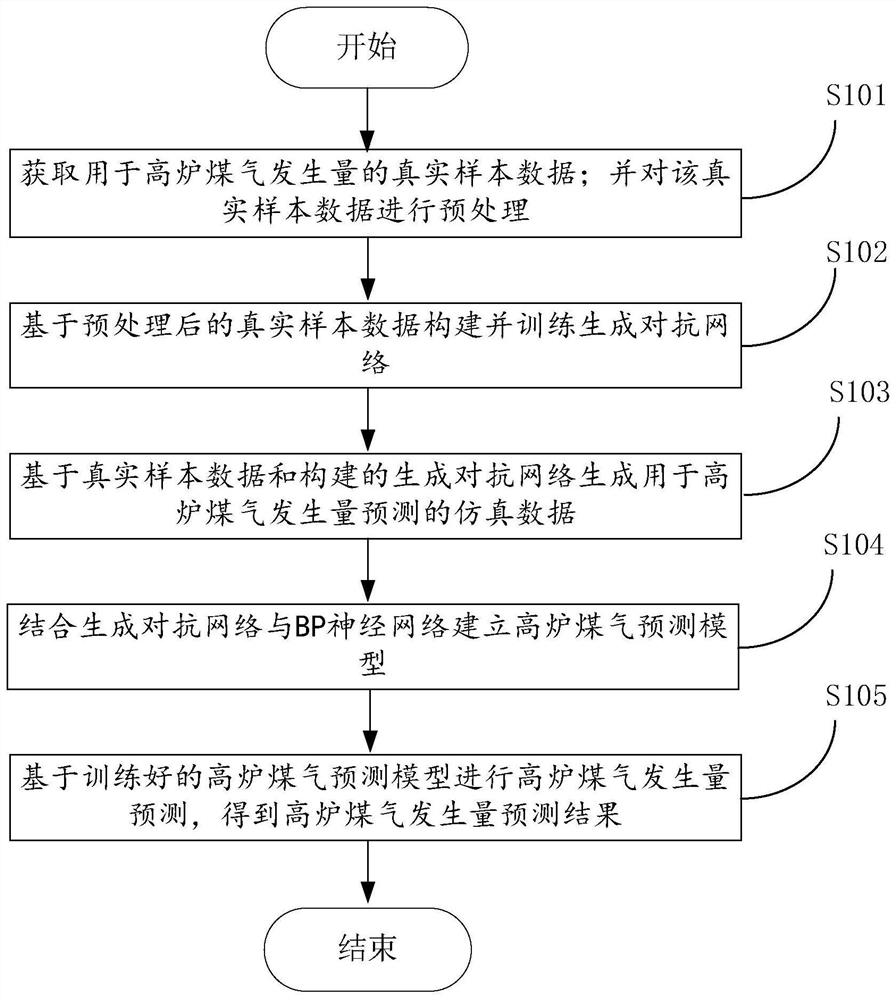
S101、获取用于高炉煤气发生量预测的真实样本数据;并对所述真实样本数据进行预处理;
S102、基于预处理后的真实样本数据构建并训练生成对抗网络;
S103、基于所述真实样本数据和所述生成对抗网络生成用于高炉煤气发生量预测的仿真数据;
S104、构建基于BP神经网络的高炉煤气发生量预测模型,并利用所述仿真数据和所述真实样本数据训练所述高炉煤气发生量预测模型;
S105、基于训练好的高炉煤气发生量预测模型进行高炉煤气发生量预测,得到高炉煤气发生量预测结果。
进一步地,所述预处理包括:
确定高炉煤气发生量预测模型的输入输出;所述输入包括:冷风流量、热风压力、富氧量和上一时间段的高炉煤气发生量;所述输出包括:高炉煤气发生量的预测值;
数据清洗与归一化;
剔除所述真实样本数据中的异常数据;
采用如下函数对所述真实样本数据进行归一化处理,将所述真实样本数据归一化为[0,1]区间上的值,函数的归一化公式为:
其中,x为数据归一化后得到的值,x
进一步地,所述生成对抗网络包括:生成网络和判别网络;所述生成网络和所述判别网络分别基于BP神经网络构建。
进一步地,所述训练生成对抗网络包括:
采用交替迭代训练的方法,先训练判别网络,用所述真实样本数据作为输入量,当输出都接近于1时,再训练生成网络,生成网络的输入量是一组随机生成的数据;在训练生成网络时,保持经过训练后的判别网络的参数不变,迭代更新生成网络的参数。
进一步地,所述判别网络的损失函数为:
生成网络的损失函数定义为:
其中,z为输入生成器的噪声数据;x为输入判别器的真实样本数据;D为判别网络;G为生成网络;z~p
进一步地,所述建立基于BP神经网络的高炉煤气发生量预测模型,包括:
确定BP神经网络隐含层节点;隐含层的节点个数的确定采用如下公式:
其中,m为隐含层节点个数;n为输入层节点个数;l为输出层节点个数。
从上述的技术方案可以看出,本发明公开的结合生成对抗网络与神经网络的高炉煤气发生量预测方法中,采用BP神经网络构建预测模型进行预测,同时构建生成对抗网络来增加样本数据;显著提高了预测的精确度,并且在平均绝对误差和平均误差率方面都有所减少。有效了解决钢铁生产过程中,若测得数据过少时BP神经网络预测精度较低的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例公开的一种结合生成对抗网络与神经网络的高炉煤气发生量预测方法的流程示意图;
图2为生成对抗网络的原理示意图;
图3为本发明实施例公开的一种生成网络实际结构示意图;
图4为本发明实施例公开的一种BP神经网络的结构示意图;
图5为本发明实施例公开的一种结合生成对抗网络与神经网络的高炉煤气发生量预测模型的示意图;
图6为本发明实施例公开的BP神经网络的5分钟预测结果;
图7为本发明实施例公开的BP神经网络的8分钟预测结果;
图8为本发明实施例公开的BP神经网络的15分钟预测结果;
图9为本发明实施例公开的基于生成对抗网络和BP神经网络建立的预测模型的5分钟预测曲线;
图10为本发明实施例公开的基于生成对抗网络和BP神经网络建立的预测模型的8分钟预测曲线;
图11为本发明实施例公开的基于生成对抗网络和BP神经网络建立的预测模型的15分钟预测曲线。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明以钢铁工业为背景,针对我国当前钢铁工业能源浪费严重和有害气体排放量大造成环境污染等问题,结合生成对抗网络和BP神经网络构建预测模型,基于实际生产过程中采样得到的真实现场数据,对高炉煤气这一炼钢工艺流程中重要的能源进行预测,实现了高炉煤气发生量的准确预测
参见图1,其示出了本发明实施例中的一种结合生成对抗网络与神经网络的高炉煤气发生量预测方法的流程示意图,该方法包括以下步骤:
S101、获取用于高炉煤气发生量的真实样本数据;并对该真实样本数据进行预处理;
其中,数据预处理包括:
a)确定高炉煤气发生量预测模型的输入输出;
输入:高炉煤气生成过程复杂,包含了众多的物理化学反应,钢铁生产过程中的许多因素都会影响高炉煤气发生量。通过分析钢铁厂生产过程,基于高炉煤气发生的机理分析可以发现,冷风流量、热风压力和富氧量这三个变量对高炉煤气发生量有较大的影响,因此将这三个变量作为预测模型的输入变量。
又因为高炉煤气发生量是时序数据,随着时间的变化会具有一定的周期性,所以历史数据会对未来的数据产生影响,因此将上一时间段的高炉煤气发生量也作为预测模型的一个输入变量。
输出:以高炉煤气发生量的预测值作为预测模型的输出。
b)数据清洗与归一化;
由于钢铁生产现场的状况复杂,由现场采集到的数据容易受到干扰,因此在构建高炉煤气发生量预测模型前需要对样本数据进行预处理,剔除异常的数据。
由于高炉煤气系统极其庞大,现场采集到的数据的量级通常达到了一万以上,若不进行数据归一化会影响神经网络的收敛速率,降低预测模型的预测效果。并且,用于训练神经网络的各个样本数据的数量级各不相同。因此,为了保证所有样本数据的地位平等,对清理后的数据进行归一化处理。采用如下函数对所有数据进行归一化处理,将数据归一化为[0,1]区间上的值,函数的归一化公式为:
其中,x为数据归一化后得到的值,x
S102、基于预处理后的真实样本数据构建并训练生成对抗网络;
监督学习的基础是要有大量的训练数据来作为样本,但是,在实际生产过程中常常会因为一些不可抗拒的原因,使得训练样本数据的数量较少。
生成对抗网络GAN是通过对抗过程构造的生成式模型。生成对抗模型的主要思想是博弈论中的零和博弈的思想,指博弈双方的利益之和为零,也就是一方有所得,则另一方必然会有所失。
生成对抗网络的结构即一个生成器(G)和一个判别器(D)所组成,生成对抗网络内部的对抗即生成器与判别器的对抗。生成器本质上是一个高炉煤气影响因素的样本生成器,负责寻找真实高炉煤气影响因素样本内部潜在的规律分布,从而将输入的噪声包装成一个与真实样本相近的样本,也就是输出包装过后的假样本。判别器本质上是一个二分类器,好比一个0-1分类器,负责判断输入的样本是真样本还是假样本,当输入的样本与真实样本越接近时,判别器的输出越接近于1,相反,则输出越接近0。
生成对抗网络的结构图如图2所示,判别器的输入包括真实的样本数据和生成器生成的包装过后的假的伪造样本数据。判别模型的目的就是尽可能的分辨输入的样本真伪。生成模型的输入只有随机噪声,生成模型的目的是将这一噪声包装成一个与真实样本数据接近的假样本数据来骗过判别模型。当判别器的输出接近于1时,即判别器认为输入的样本大部分都是真实的样本,就可以认为是生成器在这一时刻占了上风,生成的假样本骗过了判别器。相反,当判别器的输出都接近于0时,即判别器认为输入的样本大部分都是虚假的样本,则此时判别器占了上风,判断出了生成器所生成的假的样本。为了取得最终的胜利,判别器和生成器都需要不断地优化自己,提升自己生成假样本的能力和判别假样本的能力,这个自我优化的过程就是二者相互对抗的过程,最终两个网络将达到一个动态平衡的状态,这时判别器的输出将是一个接近于0.5的数。
S103、基于真实样本数据和构建的生成对抗网络生成用于高炉煤气发生量预测的仿真数据;
通过生成器和判别器之间的博弈,可以得到一个良好的样本真伪判别器或者样本生成器。通过本发明引入生成对抗网络的目的就是增加样本数据的容量来提高BP神经网络的预测效果,因此,也就希望生成器在博弈中获胜,可以生成与真实样本数据相近的假样本。
无论是生成器(G)还是判别器(D),本质上都可以利用神经网络来构建。其中,判别网络的损失函数定义为:
生成网络的损失函数定义为:
其中,z为输入生成器的噪声数据;x为输入判别器的真实样本数据;D为判别网络;G为生成网络;z~p
这个公式本质是一个最大最小的优化问题,判别器和生成器是分别进行优化的。首先对判别器D进行优化,判别网络的损失函数的第一项就是使得真样本x输入的时候,得到的结果越大越好,也就是越接近1越好。而对于假样本z,则希望得到的结果尽可能地小,也就是1-D(G(z))尽可能地大。这样就能使得判别器输出结果可以分辨样本的真假。
而对于生成器G的优化,因为生成网络的输入只有噪声样本z,因此生成网络的损失函数相比于判别网络只有一项,生成网络自然是希望生成的假样本可以越接近于1越好,但是为了在编程时予以方便,所以统一写成了1-D(G(z))。
因为生成网络和判别网络是两个神经网络,如果将两个网络同时进行训练,训练效果并不理想,而且会使得训练周期过长。本发明实施例中采用交替迭代训练的方法,首先,训练判别网络,用真实的样本数据来作为输入量,当输出都接近于1时,也就说明此时的判别网络能够对输入数据的规律分布有着比较好的判断,能够判别输入数据的真假。第二步就是训练生成网络,生成网络的输入量是一组随机生成的数据,为了检验生成网络生成的假样本的效果,将之前训练过的判别网络串接在生成网络之后,生成网络的实际结构图如图3所示。
生成器将处理包装过后的假样本输入给判别器中,由判别器的输出误差来更新网络参数。但是在更新参数的时候,应该保持判别网络的参数不变,仅仅更新生成器的参数,因为构造这个网络的目的是构造一个合适的生成器来生成样本数据,从而增加样本容量,所以应该保持之前经过训练之后的判别网络的参数不变,不断更新生成网络的参数,进行一定的迭代次数,当整个网络最后输出接近为1时,也就说明此时生成器生成的假样本已经可以骗过判别器,被认为是真实样本了,此时的生成器生成的数据就可以作为真实样本来使用了。
S104、结合生成对抗网络与BP神经网络建立高炉煤气预测模型;包括:构建基于BP神经网络的高炉煤气发生量预测模型,并利用仿真数据和真实样本数据训练该高炉煤气发生量预测模型。更具体地:
a)确定BP神经网络隐含层节点;
BP神经网络由三层全连接的神经网络构成,分别为一层输入层,一层隐含层和一层输出层。隐含层的节点个数的确定采用如下公式:
其中,m为隐含层节点个数;n为输入层节点个数;l为输出层节点个数;由此得到了一个由四个输入层节点,两个隐含层节点,一个输出层节点组成的BP神经网络。本发明实施例中构建的BP神经网络的结构图如图4所示。
b)建立高炉煤气预测模型;
以某钢厂现场采集的1600条数据为例建立BP神经网络的预测模型,由于用于训练的样本数据只有1600个,样本容量过小使得训练效果不佳,因此利用生成对抗网络来训练一个判别器和一个生成器,利用生成器来扩大样本容量用于BP神经网络的训练。
选择用于训练的上一时间段高炉煤气发生量、冷风流量、热风压力和富氧量各1200个作为训练判别网络的真实数据。
将生成网络生成的假数据、随机噪声输入判别网络来检验生成网络生成的假数据的效果。随着训练轮次的推进,可以发现判别网络损失函数逐渐衰减至1左右,说明此时的判别网络能够比较好的判断输入数据的真伪。生成网络的损失函数在降低,说明此时生成网络可以输出与真实数据规律分布相近的假数据,可以作为BP神经网络的输入数据用于训练。将生成对抗网络与BP神经网络串接起来就可以得到基于生成对抗网络和BP神经网络的高炉煤气预测模型,预测模型的结构图如图5所示。
S105、基于训练好的高炉煤气预测模型进行高炉煤气发生量预测,得到高炉煤气发生量预测结果。
本发明实施例中的结合生成对抗网络与神经网络的高炉煤气发生量预测方法中,利用生成对抗网络增大样本数据的方法可以显著提高预测的精确度,并且在平均绝对误差和平均误差率方面都有所减少。因此,利用生成对抗网络增加样本数据的方法能有效解决钢铁生产过程中,若测得数据过少时BP神经网络预测精度较低的问题。
下面以一个具体的示例对本发明中的结合生成对抗网络与神经网络的高炉煤气发生量预测方法进行说明。
选取某钢铁厂高炉在2017年9月19日当天进行生产过程中的一段时间内测得的数据进行实验仿真和测试。采样周期为5s,上一时间段高炉煤气发生量、冷风流量、热风压力和富氧量都分别采集100min的数据(1200个样本)作为训练样本来分别预测5min、8min和15min的高炉煤气发生量,其检验样本数据容量分别为60、96和180。采用的实验软件为Matlab,利用Matlab中的newff函数来建立一个BP神经网络,构建的神经网络参数为:最大训练次数1000次、网络训练目标0.001,网络学习率0.01,预测结果如图6~8所示,其中图6示出的是BP神经网络的5min的高炉煤气发生量预测结果;图7是BP神经网络的8min的高炉煤气发生量预测结果;图8是BP神经网络的15min的高炉煤气发生量预测结果。
为了更直观的检验预测效果,计算BP神经网络预测的平均绝对误差和平均误差率,计算结果如下表所示:
表1
其中,t表示预测时间;MAE(Mean Absolute Error)表示平均绝对误差;MPE(MeanPercentage Error)表示平均误差率。根据预测结果图和表1可以发现,当用于训练的样本数据的样本容量较小时,预测结果不太理想,生成的预测曲线相比于真实数据曲线也比较粗糙,误差较大。分析可能与用于训练的样本数据过少有关,为了获得比较理想的预测效果,需要想办法增大样本容量。
保持BP神经网络的网络参数都保持相同,即最大训练次数1000次、网络训练目标0.001,网络学习率0.01。利用生成网络将上一时间段高炉煤气发生量、冷风流量、热风压力和富氧量这四个样本数据容量都扩充到10000,然后分别预测之后5min、8min和15min的高炉煤气发生量,预测结果如图9~图11,其中图9示出的是基于生成对抗网络和BP神经网络建立的预测模型的5min的高炉煤气发生量预测结果;图10是基于生成对抗网络和BP神经网络建立的预测模型的8min的高炉煤气发生量预测结果;图11是基于生成对抗网络和BP神经网络建立的预测模型的15min的高炉煤气发生量预测结果。
为了更直观的检验预测效果,计算预测的平均绝对误差和平均误差率,并且将基于生成对抗网络和BP神经网络建立的预测模型计算出的结果与只利用了BP神经网络的计算结果相对比,计算结果如下表所示:
表2
其中奇数行为只使用了BP神经网络建立的预测模型的预测结果,偶数行为基于生成对抗网络和BP神经网络建立的预测模型的预测结果。t表示预测时间;MAE(MeanAbsolute Error)表示平均绝对误差;MPE(Mean Percentage Error)表示平均误差率。
最后,还需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 结合生成对抗网络与神经网络的高炉煤气发生量预测方法
- 基于煤气成份变化的高炉煤气发生量及其热值预测方法