一种基于胶囊图神经网络的二部图分类方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明属于计算机技术领域,更具体地,涉及一种基于胶囊图神经网络的二部图分类方法。
背景技术
近年来,电子商务平台和诸如微博之类的社交网络越来越影响到我们日常生活的方方面面,同时也产生着大量的数据。图作为大数据的一种重要表示结构,受到了广泛的关注,大量的研究工作致力于挖掘图结构数据中有价值的信息。其中,二部图在各个领域都很普遍。例如,用户和维基百科页面之间的用户-页面关系,其中边表示页面上用户的编辑动作,两类节点分别表示用户和页面,这种关系可以用二部图来表示。不同语言的用户和页面组成了不同的二部图,根据不同的语言,可以对这些二部图进行分类,并进一步挖掘出不同语言用户的习惯差异。此外,二部图分类还可以用于金融洗钱检测。比如将亚马逊等电子商务平台中已知的洗钱操作建模为二部图结构,学习这些二部图的特征表示,并进一步使用它们来检测其他潜在的洗钱操作,有利于金融风控。再如,在描述蛋白质结构时,可以将蛋白质二级结构之间的相互作用表示为二部图,二部图分类有助于发现蛋白质中的公共子结构。
针对图的分类问题,已经提出了多种方法。这些工作利用诸如多视图学习、强化学习、特征选择和图核等技术很好地实现了图分类。此外,在计算机视觉领域,Hinton等人提出了一种称为胶囊网络的方法,并在图像分类问题上取得了良好的表现。鉴于其优异的性能,Mallea等人通过在图上应用胶囊网络,在图分类任务上取得了优异的结果。然而,由于这些方法主要是针对单部图而设计的,由于二部图中同类顶点之间没有边连接,如果直接应用于二部图分类,就不能很好地保留同类型顶点之间的关系,难以取得优异的性能。
发明内容
为了克服上述现有方法的不足,本发明提供了一种基于胶囊图神经网络的二部图分类方法,改进了基于图神经网络的方法在二分图分类任务上的性能。
本发明的目的是通过以下技术方案实现的:一种基于胶囊图神经网络的二部图分类方法,包括以下步骤:
(1)将输入二部图记为G
其中,A
(2)对于图G中的节点i,它具有一个特征向量x
Z
其中,
因此将每一个节点的特征向量都转化为了初始胶囊
(3)用1层图卷积神经网络模型将当前胶囊层转化成对下一层胶囊层的投票系数,使用如下公式计算对下一胶囊层的投票系数:
其中,
(4)学习每一个投票系数对应的权重参数c,且要求同一胶囊i对下一层所有胶囊的投票系数权重之和为1,即
(4-1)使用softmax函数利用b来构造c:
其中,
(4-2)使用如下公式来累加带权投票系数并转换为第l+1层胶囊的特征向量:
其中,
(4-3)比较步骤(4-2)中获得的胶囊
迭代完成后,得到更加准确的胶囊j的特征向量,以及权重参数c的集合
(5)对所有第l+1层的胶囊执行步骤(4)的操作,得到所有第l+1层胶囊的特征向量,以及权重参数c对应的权重矩阵
(6)为了更好的保留第l层胶囊的特征,并将其传递到第l+1层胶囊层,在相邻胶囊层之间添加一个残差连接,使用如下公式计算:
其中,M(·)表示全局平均函数,得到第l+1层的胶囊Θ
(7)对隐藏胶囊层重复上述步骤(3)至步骤(6),直至类胶囊层,得到类胶囊
(8)根据模型特性,设计损失函数,利用损失函数计算出的误差指导模型参数的更新,利用Adam优化器训练模型。
进一步地,步骤(1)中构建单模投影图具体包括以下步骤:
(1-1)对于一类节点集合v
(1-2)对于v
(1-3)对于N(s
(1-4)对于N(t)中的节点s
(1-5)将
(1-6)判断
(1-7)重复上述步骤(1-4)至(1-6),直到N(t)中的所有节点被处理完;
(1-8)重复上述步骤(1-3)至(1-7),直到N(s
(1-9)重复上述步骤(1-2)至(1-8),直到v
(1-10)对于另一类节点集合v
进一步地,步骤(8)中损失函数具有如下特征:
损失函数由分类损失L
类胶囊
其中,
为了在训练过程中尽量保留原始图结构信息,以及保持训练的稳定性,使用重构损失来约束训练过程,其核心思想是解码类别胶囊层的邻接矩阵来获得一个和初始胶囊层邻接矩阵维度一致的矩阵A
Z
其中,Φ为掩模操作,
其中,A
最终,损失函数由如下公式计算得到:
L=L
其中,β为比例系数。
本发明还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述基于胶囊图神经网络的二部图分类方法中的步骤。
本发明还提供一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述基于胶囊图神经网络的二部图分类方法中的步骤。
本发明的有益效果为:本发明首次将胶囊网络应用于二部图分类任务。本发明首先对图数据进行单模投影,良好地保持了二部图的结构、性质和标记信息,使得模型能够更好地捕捉二部图中同一类顶点之间的关系。然后应用胶囊图神经网络执行分类任务,它能够显式地提取层次图表示信息。与最先进的现有方法相比,本发明显著提高了二分图分类的准确性。
附图说明
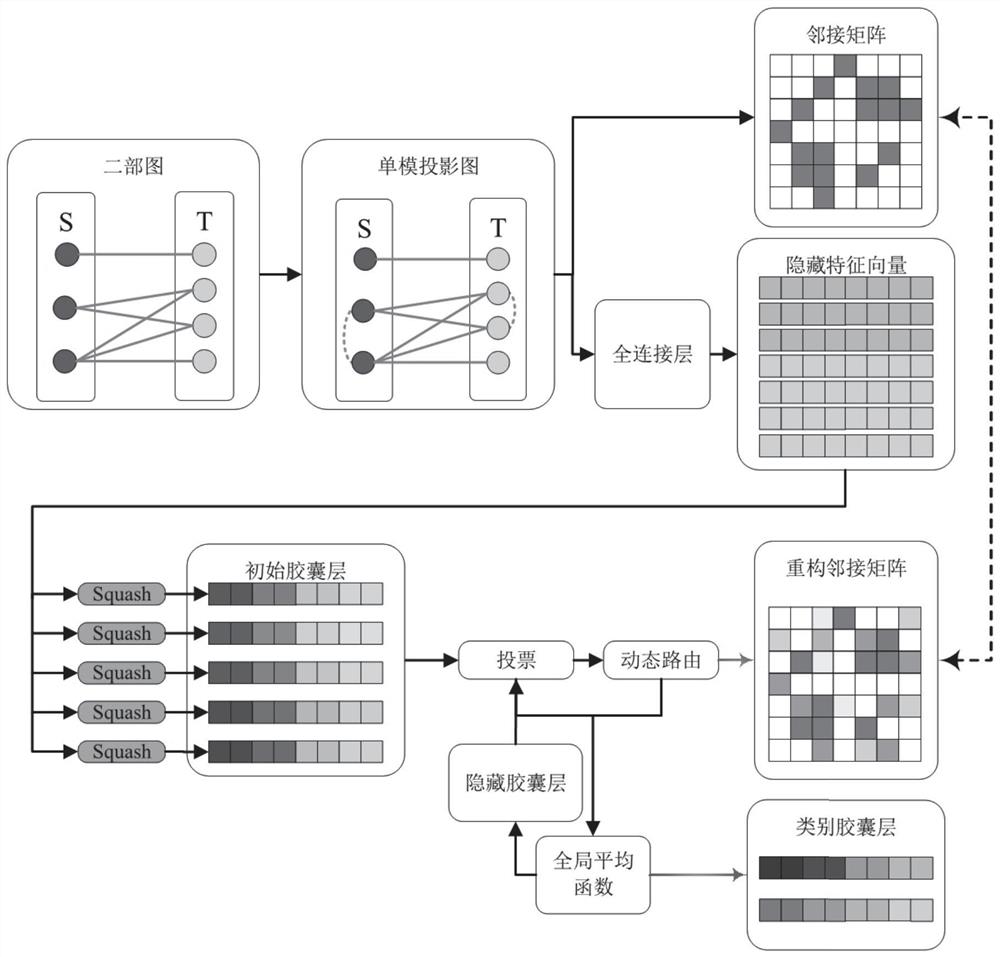
图1为本发明方法的模型框架示意图。
具体实施方式
为了使本发明的目的、特征和优点更加具体清楚,下面结合附图和具体实施方案对本发明的技术方案进行详细说明。
如图1所示,展示了本发明提出的一种基于胶囊图神经网络的二部图分类方法的模型框架,该方法包括以下步骤:
(1)将输入二部图记为G
其中,A
具体而言,本步骤所述的构建单模投影图,包括以下步骤:
(1-1)对于一类节点集合v
(1-2)对于v
(1-3)对于N(s
(1-4)对于N(t)中的节点s
(1-5)将
(1-6)判断
(1-7)重复上述步骤(1-4)至(1-6),直到N(t)中的所有节点被处理完;
(1-8)重复上述步骤(1-3)至(1-7),直到N(s
(1-9)重复上述步骤(1-2)至(1-8),直到v
对于另一类节点集合v
(2)对于图G中的节点i,它具有一个特征向量x
Z
其中,
因此将每一个节点的特征向量都转化为了初始胶囊
(3)用1层图卷积神经网络模型将当前胶囊层转化成对下一层胶囊层的投票系数,使用如下公式计算对下一胶囊层的投票系数:
其中,
(4)学习每一个投票系数对应的权重参数c,且要求同一胶囊i对下一层所有胶囊的投票系数权重之和为1,即
(4-1)使用softmax函数利用b来构造c:
其中,
(4-2)使用如下公式来累加带权投票系数并转换为第l+1层胶囊的特征向量:
其中,
(4-3)比较步骤(4-2)中获得的胶囊
迭代完成后,得到更加准确的胶囊j的特征向量,以及权重参数c的集合
(5)对所有第l+1层的胶囊执行步骤(4)的操作,得到所有第l+1层胶囊的特征向量,以及权重参数c对应的权重矩阵
(6)为了更好的保留第l层胶囊的特征,并将其传递到第l+1层胶囊层,在相邻胶囊层之间添加一个残差连接,使用如下公式计算:
Θ
其中,M(·)表示全局平均函数,得到第l+1层的胶囊Θ
(7)对隐藏胶囊层重复上述步骤(3)至步骤(6),直至类胶囊层,得到类胶囊
(8)根据模型特性,设计损失函数,利用损失函数计算出的误差指导模型参数的更新,利用Adam优化器训练模型。
具体而言,本步骤所述的损失函数采用如下设计方案:
损失函数由分类损失L
类胶囊
其中,
为了在训练过程中尽量保留原始图结构信息,以及保持训练的稳定性,使用重构损失来约束训练过程,其核心思想是解码类别胶囊层的邻接矩阵来获得一个和初始胶囊层邻接矩阵维度一致的矩阵A
Z
其中,Φ为掩模操作,
其中,A
最终,损失函数由如下公式计算得到:
L=L
其中,β为比例系数。
实施例1
在该实施例中,我们使用的数据集有:记录了用户对于迪维希语的维基词典页面的编辑行为的数据集“edit-dvwiktionary”和记录了用户对于斯瓦迪语的维基词典页面的编辑行为的数据集“edit-sswiktionary”,每一种数据集中都有众多的连通二部图作为图分类预测的对象,而每一个图中的两类结点分别表示用户和维基词典网页页面,结点之间的边表示用户与页面之间的编辑与被编辑关系,通过本发明所提出的方法,能够对以上两种数据类型之一的图数据进行分类,即判断出该组用户与页面的数据为用户在编辑哪种语言的维基词典,分类的具体实施方式包括以下步骤:
(1)将输入二部图记为G
(2)在图G中,表示用户的节点和表示页面的节点都会有一个用于表述其特征的特征向量,我们将节点i的特征向量标记为x
Z
得到节点i对应的胶囊为
因此将每一个节点的特征向量都转化为了初始胶囊
(3)用1层图卷积神经网络模型将将当前胶囊层转化成对下一层胶囊层的投票系数,使用如下公式计算对下一胶囊层的投票系数:
由此得到第l层胶囊对第l+1层胶囊的所有投票系数,该投票系数可视为上一层胶囊与下一层胶囊之间的关系,及用户与维基词典页面所拥有的更细微的特征与更大的特征之间的关系的一种表示。
(4)学习每一个投票系数对应的权重参数c,设置辅助参数b来构造c,初始时设置b=0,使用动态路由算法迭代R次,设置R=3,一次迭代过程包括子步骤(4-1)、(4-2)和(4-3):
(4-1)使用softmax函数利用b来构造c:
(4-2)使用如下公式来累加带权投票系数并转换为第l+1层胶囊的特征向量:
(4-3)比较步骤(4-2)中获得的胶囊
迭代完成后,得到更加准确的胶囊j的特征向量;例如当j代表迪维希语的维基词典,那么该类别胶囊的方向可视作它的原始图所拥有的迪维希语维基词典特征的表达情况,而其模长可视为它的原始图所拥有的迪维希语维基词典特征的表达强度。
(5)对所有第l+1层的胶囊执行步骤(4)的操作,得到所有第l+1层胶囊的特征向量和投票系数权重参数矩阵
(6)为了更好的在维基词典图中的大特征中保留小特征,在相邻胶囊层之间添加一个残差连接,使用如下公式计算:
Θ
得到第l+1层的胶囊Θ
(7)对隐藏胶囊层重复上述步骤(3)至步骤(6),直至类别胶囊层,得到类别胶囊层
(8)利用损失函数计算出的误差指导模型参数的更新,利用Adam优化器训练模型,损失函数通过如下式子计算:
L=L
其中:
(9)训练得到模型后,当向模型输入未知的用户编辑维基词典关系图,模型就会输出一个预测,预测其为迪维希语或是斯瓦迪语的用户编辑维基词典关系图。
在一个实施例中,提出了一种计算机设备,包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行上述各实施例中基于胶囊图神经网络的二部图分类方法中的步骤。
在一个实施例中,提出了一种存储有计算机可读指令的存储介质,计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述各实施例中基于胶囊图神经网络的二部图分类方法中的步骤。其中,存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取存储器(RAM,RandomAccess Memory)、磁盘或光盘等。
以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施例披露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
- 一种基于胶囊图神经网络的二部图分类方法
- 一种基于少数类加权图神经网络的不平衡节点分类方法