一种区块链架构下的联邦学习混合聚合机制
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种基于区块链和差分隐私放大机制的联邦学习混合聚合机制,属于机器学习安全域隐私技术领域。
背景技术
机器学习可以通过集中收集大量的数据和训练多个预测模型来为用户提供个性化的服务。然而,在实际应用中,数据通常分布在不同的组织中。联邦学习在本地训练后聚合用户的模型更新,而不是原始数据来更新全局模型,这解决了传统机器学习中的数据隔离问题,提供了更好的数据隐私,但仍然面临多种隐私攻击。
在联邦学习任务模型中,本地用户经过训练后将梯度作为模型的更新上传,梯度的维度会随着训练数据维度的增加而增加。为了提高更新效率,联邦学习的每次更新都会选择部分梯度上传,但这可能会泄露用户隐私,因为攻击者可以通过监听和基于背景知识的推断,对本地模型更新的内容及其上传者的身份进行隐私攻击,以获取用户更新的内容或定位用户记录。一般来说,用户隐私仍然面临来自用户身份、梯度指数和梯度内容的隐私威胁。
用户身份隐私指的是攻击者可以基于监听或推理攻击获得用户更新行为或身份信息。例如,攻击者基于信道监听和背景知识推测攻击,确定用户何时开始更新,用户是否参与某轮上传,或哪个更新对应于某个特定用户。梯度指数隐私是指攻击者根据获得的梯度指数推断出用户数据或身份的威胁。例如,攻击者确定某个梯度是否属于用户的较大梯度,或者某些信息是否包含在用户的训练数据中。梯度内容隐私是指攻击者根据获得的梯度内容推断用户训练数据的威胁。例如,攻击者根据某个特定用户的显著特征确定其是否参与上传,或根据多次更新的背景知识推断出用户隐私。
为了减轻联邦学习中的隐私威胁,差分隐私因为其严格的隐私约束被广泛用来对更新进行扰动以抵御各种推理攻击。在满足差分隐私的联邦学习模型中,一个受信任的中央服务器聚合来自用户的原始本地更新,并在发布全局模型之前执行隐私扰动。在更隐私的满足本地差分隐私的联邦学习模型中,用户可以同步或异步地扰动并上传他们的更新到一个不受信任的中央服务器,避免了隐私推断攻击。在减少联邦学习的隐私威胁的同时,差分隐私在数据可用性方面带来了新的问题。
一方面,基于扰动的差分隐私会降低联邦学习训练中的数据可用性。因为差分隐私通过引入隐私预算来调节扰动量,没有协调数据隐私和可用性的冲突。本地更新维度的增加导致分配给每个维度的预算降低,扰动增加,从而降低数据可用性。同时,本地差分隐私比差分隐私引入了更多的扰动。另一方面,大量的扰动给联邦学习数据评估带来了可用性问题,因为扰动引入的误差给用户更新的质量评估和联邦学习的激励机制带来了挑战。在联邦学习中,用户设备在进行本地模型训练、扰动和上传时产生了大量的开销。因此,合理的更新评估和激励机制对于提高用户参与更新的积极性是必要的。然而,大量的扰动使得服务器很难评估用户的更新并合理地分配用户的奖励。更糟糕的是,用于更新聚合和评估的中央服务器的隐私和可信度可能会被服务提供商、攻击者或恶意服务器所破坏。
为了解决服务器带来的隐私和数据评估的可用性问题,基于区块链的联邦学习被广泛研究,因为区块链网络结构可以消除中央服务器带来的单点故障和信任问题。同时,基于用户更新质量的区块链共识机制与联邦学习的激励机制不谋而合,这使得区块链网络的联邦学习模型更新可以高效部署。然而,基于区块链的联邦学习模型中每次更新质量的共识需要很高的计算开销。此外,本地差分隐私引入的扰动使基于区块链的联邦学习无法准确评估用户贡献以实现合理的奖励分配。因此,基于区块链的联邦学习并没有解决本地差分隐私带来的数据可用性降低的问题,这甚至削弱了基于区块链的联邦学习的共识机制。
发明内容
为了解决数据隐私和可用性方面的挑战,本发明提出了一种区块链架构下基于子采样、洗牌和沙普利值的联邦学习混合聚合机制,在确保数据可用性的同时增强用户隐私。使用网络中的本地服务器作为管理节点和矿工节点,将网络划分为多个由本地服务器和接入的终端设备组成的本地域,以及由多个本地服务器连接组成的域间区块链网络。为了在保证隐私性的同时提高训练中的数据可用性,在用户端对梯度进行满足本地差分隐私的扰动来保护梯度隐私,并对梯度进行子采样选取来放大保护梯度指数隐私;使用洗牌服务器对用户上传的梯度更新进行二次子采样和洗牌来放大保护用户身份隐私,进而减少扰动量,提高训练中的数据可用性。为了在保证隐私性的同时提高评估中的数据可用性,本地域内的更新在本地服务器处进行隐私聚合,然后本地服务器间使用沙普利值对聚合更新进行有效评估和区块链共识,实现基于本地域内隐私聚合和本地域间高效评估的混合聚合机制,在保证隐私的同时给每个本地域的更新上传者平均发放奖励。
为了达到上述目的,本发明采用的技术方案为:
一种区块链架构下的联邦学习混合聚合机制,具体是一种基于本地差分隐私和梯度选取的隐私保护和放大机制,基于子采样和洗牌的本地差分隐私放大机制,基于混合聚合和沙普利值的域间更新评估聚合机制,首先定义如表1所示的变量:
表1常用的变量及说明
/>
具体步骤如下:
(1)首先在用户收集本地训练数据后,基于网络内发布的联邦学习任务模型进行本地训练,得到模型更新梯度。为了提升数据隐私性和可用性,基于满足本地差分隐私的编码算法进行梯度选取,并使用满足本地差分隐私的扰动算法进行梯度扰动,然后使用本地服务器的公钥对梯度进行加密后发送给洗牌服务器。使选取后的梯度防御梯度指数攻击,扰动后的梯度防御梯度推测攻击,加密后的梯度防御来自本地服务器外的内容攻击。
基于本地差分隐私和梯度选取的隐私保护和放大机制的构建,具体过程如下:
(1.1)首先,用户在本地训练要上传的梯度更新。本地用户获取存储在本地服务器的联邦学习任务模型和全局参数,以本地存储的数据作为训练数据对联邦学习任务模型进行训练,并提取训练后的梯度;
(1.2)选取上传梯度。获取梯度选取的隐私预算ε
其中,x和x′表示相差一个梯度的相邻本地用户梯度更新;
分别表示对x和x′进行梯度选取后梯度属于高更新梯度的概率。
因此基于隐私预算ε
其中,
(1.3)对选取的梯度进行隐私扰动。获取梯度扰动的隐私预算ε
(1.4)计算和比较隐私放大约束。对于隐私放大前的本地差分隐私约束(ε
其中,
表示梯度子采样的取样参数;ε
(2)为了进一步提升数据隐私性和可用性,防御针对用户身份的隐私攻击,在洗牌服务器处基于更新子采样和洗牌机制对隐私进行进一步放大,断开更新记录与用户之间的关联性,达到身份隐私保护和提升可用性的目的;
洗牌服务器处的隐私放大具体过程如下:
(2.1)首先洗牌服务器收集足够多的用户更新。洗牌服务器设定t作为开始洗牌和子采样的阈值,使用户在域内达到最基础的t-匿名性;
(2.2)洗牌服务器收集到阈值t个用户更新后,收集用户ID,构建一个长度为t的随机洗牌序列对收集到的t个用户更新进行洗牌,并计算和比较洗牌的隐私放大效果。对于梯度选取后放大为(ε
δ
(2.3)对洗牌后的t个用户更新进行子采样。以均匀概率从t个洗牌后的用户更新中子采样s个用户更新,计算并比较子采样的隐私放大效果。对于洗牌后放大为(ε
δ=η
其中,
(3)本地服务器获取洗牌器收集的t个用户ID和洗牌并子采样后的s个用户更新,解密、聚合域内更新并与其他本地服务器进行全局联邦学习任务模型的混合聚合和基于沙普利值的域间更新评估;
混合聚合和更新评估的具体过程如下:
(3.1)本地服务器逐一解密并聚合用户更新,将聚合后的更新进行广播并接收其他本地服务器的聚合更新;
(3.2)本地服务器对一个时间区间内的聚合更新,以联邦学习任务模型的测试准确性为效用函数,计算各个节点的沙普利值并广播;
(3.3)沙普利值最高节点进行奖励分配和区块生成。按沙普利值给各个节点分配奖励,基于联邦学习的学习率和当前联邦学习任务模型参数聚合得到全局联邦学习任务模型,并生成新的区块节点加入区块链中;
(3.4)为保证用户隐私和奖励分配,给参与同一本地服务器域内更新聚合的用户平均分配奖励。
本发明的有益效果:联邦学习被广泛用于为用户提供个性化的服务中,而复杂的网络环境使得用户隐私很难得到保障。针对基于区块链的联邦学习机制,本发明通过本地隐私扰动的方式,基于梯度选取、子采样、洗牌等隐私放大机制在保证用户数据在训练中的梯度隐私性、梯度指数隐私性和用户身份隐私性的同时,保障了数据的可用性,即模型预测准确性;基于混合聚合和沙普利值的域间评估保证了用户数据在聚合中的隐私性的同时,保障了数据的可用性,即奖励合理分配。本发明在一定程度上解决了用户数据隐私可用均衡的问题。
附图说明
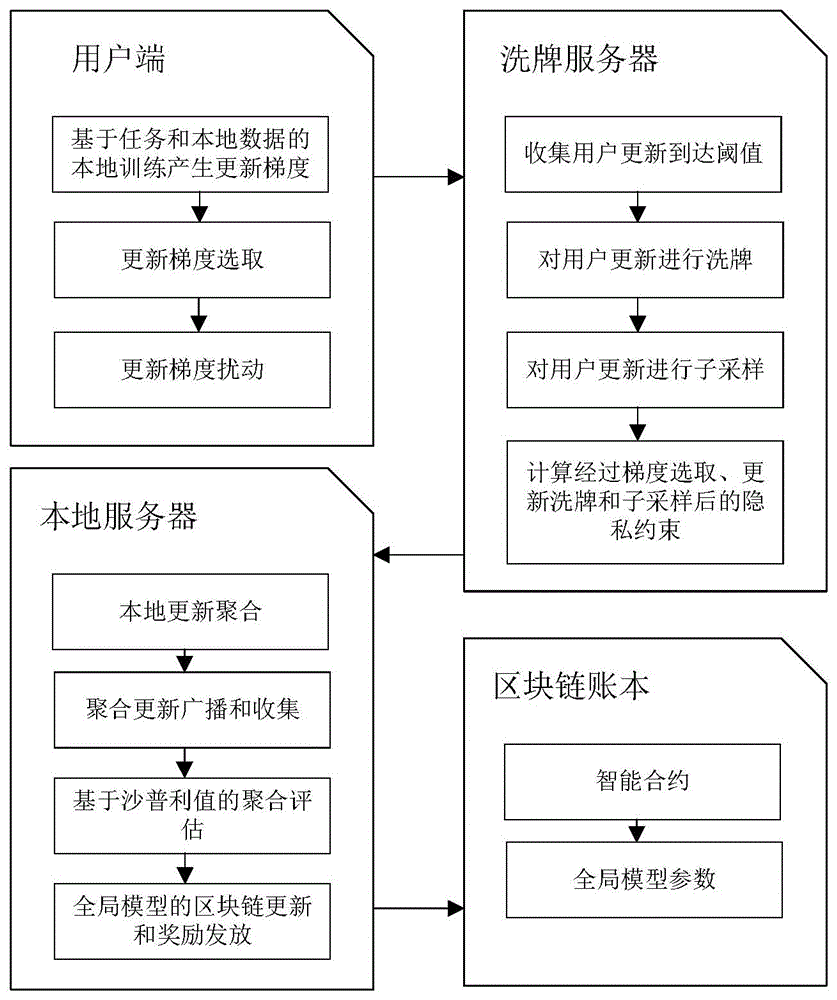
图1为本发明所述的区块链架构下的联邦学习混合聚合机制的组织结构图。
图2为本发明所述的用户端的满足隐私扰动和放大流程图。
图3为本发明所述的洗牌服务器的隐私放大流程图。
图4为本发明所述的混合聚合和更新评估流程图。
具体实施方式
为了将本发明的目的,技术方案和优点表达的更清晰明了,接下来将通过实实例和附图,对本发明做进一步的详尽的说明。一种区块链架构下的联邦学习混合聚合机制,本方法包括基于本地差分隐私和子采样的用户端隐私扰动和放大,基于洗牌和子采样的洗牌服务器端隐私放大,基于区块链和沙普利值的全局更新聚合和数据评估。
参照图2,用户端进行隐私扰动和隐私放大的具体运行过程如下:
步骤1.收集本地训练数据。
步骤2.从本地服务器处接收网络中的联邦学习任务,并基于本地训练数据进行训练,得到对全局模型进行更新的梯度x={g
步骤3.将梯度x={g
步骤4.将排序后梯度的前k位编码为1,后d-k位编码为0。
步骤5.基于梯度选取的隐私预算ε
其中,g
步骤6.按照选取概率依次对梯度进行概率选取,选取算法的输出不为1则继续执行步骤6,输出为1则进行下一步。
步骤7.将使用满足本地差分隐私的编码算法输出为1的梯度加入选取梯度集合。
步骤8.将选取的梯度个数与k比较。若选取的梯度个数小于k,则从步骤5开始执行,若选取的梯度个数大于等于k则继续执行下一步。
步骤9.对梯度进行截取。即对选取的梯度绝对值从大到小排列,将超过k位的梯度取消选取。
步骤10.基于本地扰动的隐私预算ε
y
其中,Lap表示拉普拉斯分布函数;y
步骤11.计算隐私放大约束,对于隐私约束为(ε
其中,
表示梯度子采样的取样参数;ε
参照图3,洗牌服务器的隐私放大的具体过程如下:
步骤12.洗牌服务器收集加密后的域内用户更新c
步骤13.将洗牌服务器存储的域内用户更新数量n(c
步骤14.收集并记录参与更新的t个域内用户的ID。
步骤15.使用随机数机制生成一个洗牌序列
步骤16.使用洗牌序列对子采样后的用户更新洗牌,得到洗牌后的用户更新p(c
步骤17.计算经过洗牌后的隐私放大约束,对于隐私约束为(ε
δ
步骤18.以相同概率对用户更新进行不放回取样,即当有t个更新时,每个更新被取样的概率为1/t,有t-1个更新时,每个更新被取样的概率为1/(t-1),以此类推。
步骤19.将取样的更新数量与s进行比较,若取样的更新个数小于s则继续执行步骤14,若取样更新个数等于s则继续进行下一步。
步骤20.计算经过子采样后的隐私放大约束,对于隐私约束为(ε
δ=η
其中,
步骤21.上传收集到的t个用户ID和子采样并洗牌后的s个用户更新给本地服务器。
参照图4,混合聚合和数据评估的具体运行过程如下:
步骤22.本地服务器收集来自域内洗牌器的用户ID和用户更新,使用私钥解密用户更新并对更新数值进行聚合,得到本地域内的聚合更新Z
步骤23.本地服务器向相连的其他本地服务器广播聚合后的域内更新,并收集来自其他本地服务器的广播更新;
步骤24.若收集更新的时间未到达一个更新区间的时间,则继续进行步骤23,若到达一个更新区间的时间,则进行下一步;
步骤25.本地服务器基于收集到的更新,计算每个本地服务器的沙普利值,计算公式如下:
其中,N表示本地服务器的个数;I={1,…,N}表示所有本地服务器的集合;i表示第i个本地服务器;S表示多个本地服务器的组合;u表示效用函数,即全局模型使用当前梯度更新后的测试准确率;
步骤26.接收其他节点广播的更新内容;
步骤27.各个节点判断选举沙普利值最高节点为模型更新和区块生成节点,是沙普利值最大的节点进行下一步,不是沙普利值最大节点直接进行步骤31;
步骤28.沙普利值最大节点作为全局模型更新节点,基于学习率对聚合更新进行全局聚合,对于学习率为r的联邦学习模型,全局聚合公式为:
/>
其中,Z
步骤29.沙普利值最大节点作为区块链生成和更新节点,使用聚合后的全局更新生成新的区块,连接上一区块的哈希地址加入区块链;
步骤30.沙普利值最大节点作为奖励分配和发放节点,获取模型更新的奖励,并将其按沙普利值分配给各个节点,并将各个节点的奖励以区块链交易的形式发放给各个本地服务器。按沙普利值进行奖励分配的公式为:
其中,reward表示本轮联邦学习更新聚合的奖励;reward
步骤31.本地服务器接收到奖励后,将奖励平均分配给每个参与更新的用户节点,对于第i个本地服务器,其域内用户的奖励分配公式为:
其中,reward
- 一种融合区块链状态分片和信誉机制的联邦学习架构构建的方法
- 基于区块链和信誉机制的高质量联邦学习系统及学习方法