基于Vision Transformer注意力筛选的行人重识别方法
文献发布时间:2024-01-17 01:27:33
技术领域
本发明利用了经过ImageNet预训练的深度学习模型Vision Transformer,同时针对本发明涉及的下游任务——行人重识别,使用一系列改进和方法帮助模型更好地识别行人。其中,行人重识别任务从属于计算机视觉中图像分类任务的子任务。
背景技术
近年来,随着智能监控设备的快速发展和公共安全需求的不断增长,在机场、社区、街道、校园等公共场所部署了大量摄像头。这些摄像机网络通常跨越大的地理区域,覆盖范围不重叠,每天产生大量的监控视频。我们使用这些视频数据来分析现实世界中行人的活动模式和行为特征,用于目标检测、多摄像机目标跟踪和人群行为分析等应用。行人重识别(Person Re-ID)以追溯到多目标多摄像机跟踪(multi-target multi-cameratracking,MTMCT tracking)问题,其目的是判断不同摄像机捕捉到的行人或同一摄像机不同视频片段的行人图像是否为同一行人。Person Re-ID从检测到的行人图像中构建一个大型图像数据集(Gallery),并使用探针图像(query)从中检索匹配的行人图像,因此PersonRe-ID也可以看作是一个图像检索任务。person Re-ID的关键是学习行人的判别特征,以区分具有相同身份和不同身份的行人图像。然而,在现实世界中,行人可能出现在多个地区的多个摄像头中,不同摄像头的视角、姿态、光照和分辨率的变化增加了行人识别特征的学习难度。
传统的行人重识别方法主要是人工提取固定的判别特征或学习更好的相似性度量(similarity measures),容易出错且非常耗时,极大地影响了行人Re-ID任务的准确性和实时性。2014年,深度学习首次应用于人Re-ID领域。
在Vision Transformer出现之前,在行人Re-ID领域,基于CNN的各类方法已经取得极大的成功。当Vision Transformer在NLP以及众多视觉领域取得进一步成就后,研究者们开始关注如何针对行人重识别的难点做出设计和改进。相比于基于CNN的方法,基于Vision Transformer的方法表现出以下几点优势:
1.由于Vision Transformer的结构中没有了CNN方法中才有的下采样操作,这对目前行人重识别数据集图像分辨率较低的现状来说,是一个很重要的改变,因为保留了完整的细节信息更有利于模型识别出一些特殊场景下的行人图像,例如当不同行人穿着颜色接近的衣物。
2.相比传统的CNN模型使用卷积操作只能具备一个较为局限的感受野,不能捕获到图像中两个较远的部位之间的依赖关系,不利于关注人体的各个部位。基于VisionTransformer的方法通过其全局多头注意力能够解决上述不足。
目前因为行人重识别的数据集特殊性和昂贵的人工数据标注代价,缺少大型的真实的并且复杂的数据集,因此无法充分发挥出Vision Transformer上限性能。同时在一些情况下,会出过拟合的问题导致模型不具备一定的泛化性能,可视化结果表现为过度聚焦于行人的某个显著部位。
发明内容
本发明针对目前基于Vision Transformer的行人重识别方法的不足,提出了一种基于Vision Transformer的注意力筛选的方法。通过将获得的具有高级语义信息的特征进行注意力筛选,使得包含较高注意力特征区域能够更好地整合在一起以帮助模型更好地训练,提升模型的识别精度。同时,本方法通过对筛选后的特征进行分割和编码,最后通过分类器获得相关预测分数,并计算它们的损失。在分配损失权重时,对于第四部分特征得到的损失,应分配一个相对较小值,因此模型能够在识别行人的显著特征时减少其它特征的干扰,也能更好地挖掘细粒度特征帮助识别。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤(1)、获取具有行人身份标签的行人图像,对图像进行图像增强操作,并对图像统一处理以保证模型能够接收图像集的输入。
步骤(2)、构建基于Vision Transformer的全局-局部特征抽取的行人重识别模型。所有预处理后的行人图像通过行人重识别模型中主干模型的两个分支(全局分支和局部分支)获得行人特征,并通过多个分类器获得行人身份预测。
步骤(3)、训练行人重识别模型,直到模型收敛。将得到的行人身份预测、行人重识别模型中主干模型输出的行人特征、行人身份标签计算损失,再使用随机梯度下降使得损失减少以帮助模型收敛。
步骤(4)、行人预测。获取多组没有参与训练的包含行人身份标签的行人图像,每个行人应该至少有两张图像。对图像集统一处理后,分别从每个行人图像中各抽取一张作为query,其余图像作为gallery。将query和gallery输入到模型中获得两组特征,计算这两组特征距离,找到gallery中与query最相似的图像。
进一步的,所述步骤(1)具体实现过程如下:
准备包含行人身份标签的图像数据集,该数据集通过行人检测模型、生成模型、人工标注三种方式获得。每一张图像应包含一个行人在摄像视角下完整图像。首先对图像做统一的增强处理:随机水平翻转、填充、随机部分裁剪、随机擦除、正则化,然后对图像裁剪成长高为256*128的图像。在输入到模型前需要保证样本均衡,即输入的每一批次图像应保证每一类行人的样本数目相同,根据经验可设置为4~8张图像。当原始行人图像不足要求数目时,进行随机复制,否则进行随机选择。
进一步的,所述步骤(2)具体实现过程如下:
构建基于Vision Transformer注意力筛选的行人重识别模型。首先构建Transformer块,它由多头自注意力方法(MSA)、层归一化(LN)和多层感知机(MLP)组成,单个Transformer块公式为:
Z′
Z
Transformer整体由L层Transformer块组成,其中Z
注意力则通过计算Q和K的相似度来完成寻址。Q和K计算出来的相似度反映了取出来的V值的重要程度,即权重,然后加权求和就得到了注意力值。自注意力机制在KQV模型中的特殊点在于K=Q=V,它们分别表示注意力机制过程中的query,key,value,这也是为什么取名自注意力机制。其中d
图像输入到Transformer块进行自注意力计算前需要将每一张图像分成多个patch(patch embedding);如一张图像为256*128*3,则需要将其分割成:
为了避免patch之间相关性被破坏,采用非重叠的patch embedding,具体公式如下:
其中,S是设定的步幅,H和W是图像的长和宽,N是进行非重叠分割得到的patch数量。
将处理后的张量加上初始化过的[CLS_TOKEN]和[POS_TOKEN]输入到模型中,具体公式实现如下:
其中,x
通过模型的倒数第二层和最后一层Transformer块分别获得特征Out
1.获取所有输入
2.依照最后维度最大值获得排序索引;
3.依照排序索引对所有输入
设定复制块,复制最后一层具有相同初始化参数的Transformer块,将排序重组后的重组特征根据最后第二维度均匀分割成四部分,后分别与
进一步的,所述步骤(3)具体实现过程如下:
将行人重识别数据集标签作为监督信息,同全局特征和局部特征共同计算困难三元组损失帮助训练网络。将全局特征和局部特征分别通过分类器得到预测分数,并使用交叉熵损失帮助训练模型。交叉熵损失公式具体如下:
其中,N为行人ID数,q
困难三元组损失通过随机采样P个身份,每个身份抽取K个实例,组成一个大小为P*K的minibatch;依次选取批次中的图片为锚点,选取距离最远的正样本和距离最近的负样本组成三元组训练网络,具体公式如下:
其中,f
局部分支中通过注意力筛选后会将整体特征分为多个局部特征,而均等分割的情况下,分割后的末尾特征应是行人的次要特征以及无关特征。在对该部分进行分类预测时,其置信度应是“不可靠的”,但同时可能存在的次要特征能够帮助模型识别出整体外表特征较为相近的个体,有利于对细粒度特征的挖掘,因此在该部分损失权重方面应分配一个相对较小值。具体公式如下:
其中,L
进一步的,所述步骤(4)具体实现过程如下:
得到稳定的模型后,获取未参与过训练的行人重识别数据集,要求每个行人至少获得包含两张图像。将所有图像经过统一处理后输入到模型中都能分别获取到全局和局部特征,需要将全局特征和前三个局部特征连接,具体公式如下:
f
计算所有query和gallery图像对应特征的欧式距离,以获得最相似的行人图像。
本发明有益效果如下:
本发明提出了一种基于Vision Transformer注意力筛选的行人重识别方法。使用基于Transformer的模型相比于CNN模型能够保留完整的细节信息,这在行人重识别领域是非常有用。目前大量的实验表明,Transformer的模型上限相比于CNN模型有极大的提升,这有利于提升行人重识别性能。使用全局-局部双分支结构,帮助模型关注人体各个部位,而不是主要显著部位,减少了数据不足带来的过拟合问题。使用注意力筛选方法,能够获取多有重点关注的特征,同时利用次要特征挖掘图像细粒度信息,提升模型的鲁棒性。
附图说明
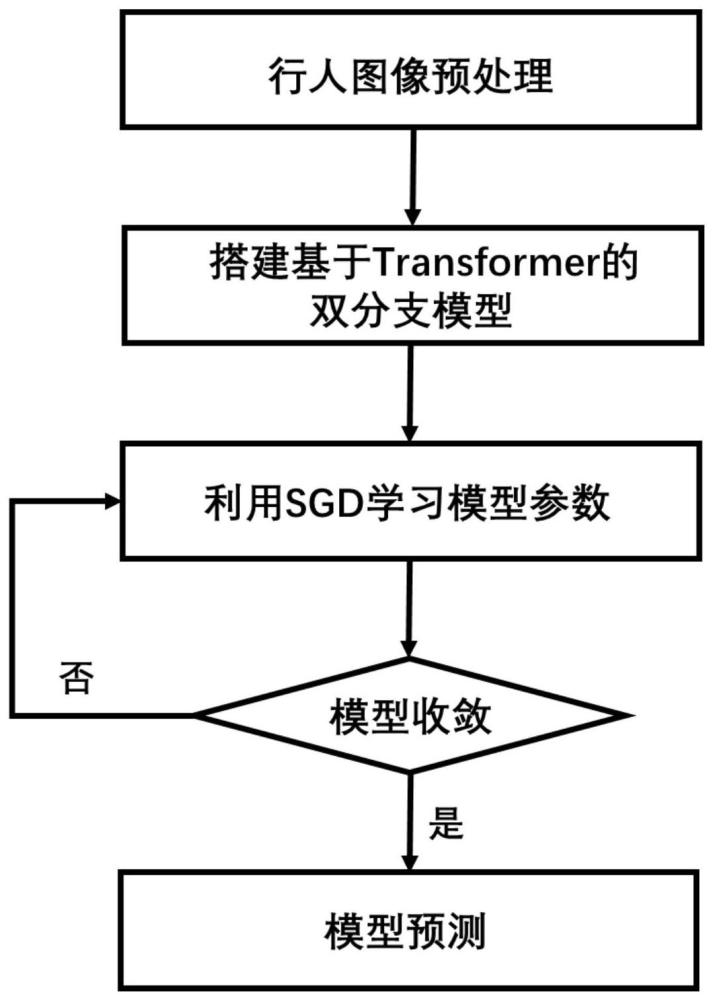
图1为本发明完整流程图。
具体实施方式
下面对本发明的详细参数做进一步具体说明。
本发明提供了一种针对有监督图像行人重识别的深度神经网络模型。图1为本发明的整体实施流程图。
步骤(1)中选择目前主流的人工数据集MSMT17和Market1501,选择其中训练集和相应的行人身份标签。由于数据集分辨率不完全统一,按照惯例统一设置为256*128后,需要将图像进行随机增强操作。由于每个身份包含的行人图像数量不完全相同,因此在每个训练批次中需要保证每个身份的行人图像数目一致。例如,在批次大小为64的行人图像数据中,可随机选取16个身份,并且每个身份应有4张图像,原始数据集中如果不足4张图像则通过随机复制方式获取,否则通过随机选取的方式得到。
步骤(2)中选择Vision Transformer的base版本作为基础模型,加载经过ImageNet数据集预训练的模型参数。复制最后一个Transformer块用于对局部特征编码,初始化多个batch正则化块和分类器用于预测行人。由于GPU数量和显存限制,选择使用pytorch框架中的分布式训练(DDP)和混合精度训练(FP16)帮助减少训练显存占用和提升训练速度。
2-1、每批次图像输入到图像中进行重叠patch embedding,依照公式:
当S为16时,是一般Transformer使用的非重叠patch embedding,本发明设置S=12。将patch和[CLS_TOKEN]和[POS_TOKEN]结合得到最终参与训练特征,具体公式如下:
将上述特征通过11个Transformer块获得特征Z
Z′
Z
2-2、将Z
2-3、将Z
步骤(3)中使用将最终全局特征和局部特征以行人重识别数据集标签作为监督信息,计算困难三元组损失帮助训练网络。将两类特征通过分类器得到预测分数,并使用交叉熵损失帮助训练模型。交叉熵损失公式具体如下:
N为行人ID数,q
困难三元组损失通过随机采样P个身份,每个身份抽取K个实例,组成一个大小为P*K的minibatch;依次选取批次中的图片为锚点,选取距离最远的正样本和距离最近的负样本组成三元组训练网络。具体公式如下:
局部分支中通过注意力筛选后会将整体特征分为多个局部特征,而均等分割的情况下,分割后的末尾特征应是行人的次要特征以及无关特征。在对该部分进行分类预测时,其置信度应是“不可靠的”,但同时可能存在的次要特征能够帮助模型识别出整体外表特征较为相近的个体,有利于对细粒度特征的挖掘,因此在该部分损失权重方面应分配一个相对较小值。具体公式如下:
步骤(4)中使用MSMT17和Market1501的测试集进行模型测试。具体过程是:
4-1、将所有图像进行统一裁剪和正则化,由于测试集数量相对较小,因此使用一块GPU并将批次大小设置为256,加快训练速度。
4-2、加载训练好的模型参数,将所有的query和gallery图像通过模型获得全局和局部特征。将各自的全局特征和前三组局部特征结合,具体公式如下:
f
query和gallery各自能获得对应的f
本发明提出了一种基于VisionTransformer注意力筛选的行人重识别方法。使用基于Transformer的模型相比于CNN模型能够保留完整的细节信息,这在行人重识别领域是非常有用。目前大量的实验表明,Transformer的模型上限相比于CNN模型有极大的提升,这有利于提升行人重识别性能。使用全局-局部双分支结构,帮助模型关注人体各个部位,而不是主要显著部位,减少了数据不足带来的过拟合问题。使用注意力筛选方法,能够获取多有重点关注的特征,同时利用次要特征挖掘图像细粒度信息,提升模型的鲁棒性。
实验表明,本发明的确具有一定提升效果。
- 一种基于Vision Transformer的跨域行人重识别方法
- 一种基于Vision MLP的行人重识别方法