一种基于标签语义信息感知的少样本命名实体识别方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于自然语言处理领域,具体涉及一种基于标签语义信息感知的少样本命名实体识别方法。
背景技术
命名实体识别是自然语言处理领域的一项基础任务,其主要目的在于从文本中提取特定实体,这些实体在下游任务中起着至关重要的作用。近年来,基于预训练语言模型的方法已成为命名实体识别领域的主流方法,并取得了较好地效果,但命名实体识别系统的开发仍然严重依赖于大量标注数据。然而在某些特定领域内,获取充足高质量标注数据的挑战不可忽视。因此,如何在少量标注样本的情况下实现有效的命名实体识别,已经成为当前领域一项重要的研究问题,即少样本命名实体识别。
少样本命名实体识别旨在使用少量的标注数据,识别模型未曾遇到过的实体类型。在该任务中,数据集使用N-way K-shot方式进行采样,并将其划分为支持集和查询集两部分,其中每条数据均有N个类别,每个类别有K个标注样本。支持集中包含一些数据样例,用于训练模型以区分目标实体和非实体,查询集则用于检验模型在支持集上所学到的知识。
随着对少样本命名实体识别的深入研究,出现了一阶段模型。Finn等人提出了与模型无关的元学习方法(MAML),该方法独立于模型,能够指导模型的学习过程,使得模型更快、更好地适应新任务,取得了显著的效果,为该领域的研究提供了新的切入点。Yang等人提出了StructShot模型,该方法基于查询集的单词距离来判断样本类型,并结合了维特比解码算法,通过将单词距离和维特比解码算法相结合,在解决样本类型判断问题上表现出色,为模型性能的提升带来了新的思路。此外,Das等人提出了一种基于对比学习的CONTaiNER模型,该模型采用高斯距离作为度量依据,为解决过拟合问题提供了一种有效的解决方案,增强了模型的鲁棒性。这些模型直接对序列进行分类来判断其所属实体类型。其中最具代表性的方法是基于原型网络的方法,该方法使用实体的中心点,即实体类型原型向量来表示该实体特征,并以此为依据判断样本的实体类型。这些模型容易实现,训练和推理的过程较为直接,适用于简单的领域。
然而,这些一阶段模型并未有效利用实体跨度信息,在面对复杂领域和罕见实体时表现不佳,存在泛化能力差、无法充分捕捉领域的细微差异等问题。针对上述问题,研究者们提出了先进行实体跨度检测,再判断跨度的实体类型的两阶段模型。Wang提出了SpanProto模型,通过将序列标记转换为跨度矩阵,帮助模型更好地专注于实体跨度信息,一定程度上提升了实体识别的性能。Ma等人则提出了一种分解的元学习方法,结合MAML算法来增强原型网络,帮助模型找到更好的向量表示空间,从而增强了模型的泛化能力,使得其在新任务上表现更出色。Wang等人提出了ESD模型,使用多头注意力机制对实体包含的跨度信息分别强化,并对强化后的向量进行交叉强化,同时在推理部分使用Beam Soft-NMS方法缓解了实体跨度冲突问题,在少样本命名实体识别中取得了显著的效果,提高了模型的性能。这种两阶段的设计使得模型能够更充分地利用可用数据,相比一阶段模型,它有更强的可解释性和更好的性能。
但是,通过对现有的两阶段模型分析,发现仍然存在如下问题:1)两阶段模型忽略了标签包含的语义信息,导致在第二阶段将样本判断为错误的实体类型;2)使用基于原型网络的方法计算损失时,只关注实体类型原型向量,忽略了不同样本之间的相似度,限制了模型对新样本的泛化能力。
针对上述问题,本发明提出了一种基于标签语义信息感知的少样本命名实体识别方法。该方法中的模型先获取句中所有的实体跨度,随后将相同实体类型的跨度与其对应的实体类型语义信息聚合为一个原型向量,将该原型向量作为锚点,从支持集中选取该实体类型的正样本代表和负样本代表,聚合为实体类型三元组,并依据样本到该三元组的距离进行预测。
发明内容
针对上述问题,本发明提供了一种基于标签语义信息感知的少样本命名实体识别方法,在构建实体类型原型向量时,将对应实体类型所包含的语义信息考虑在内,通过维度转换层将其与原型向量相融合;在对新样本进行实体识别时,将实体类型的正负样本与实体类型原型向量组成实体类型三元组,依据样本到三元组的距离对其进行分类。
为了达到上述目的,本发明采用了下列技术方案:
步骤1:对数据集进行预处理,并将其划分为包括查询集、支持集;
步骤2:构建适用于少样本命名实体识别的预训练学习模型,包括跨度识别、跨度分类两个阶段;
所述跨度识别从句子中提取跨度并获取跨度向量,包括:
1)文本编码层:对数据集进行编码,获得字符级别的向量表示和标签对应的向量表示;2)跨度编码层:获取句子的实体跨度和非实体跨度,并将其转换为对应的向量表示;3)跨度增强层:分别对支持集和查询集的跨度向量进行增强;
所述跨度分类对得到的跨度向量进行分类,包括:
1)三元组构造层:使用增强后的实体跨度向量构建实体类型原型向量,融入标签语义信息,并选取数个正样本和负样本,与锚点向量一同构建为实体类型三元组;2)实体分类层:计算查询集中每一个样本与每个实体类型三元组的距离,选取距离最近的三元组对应的类型作为该样本的实体类型;3)标签推理:通过计算样本到三元组的距离,将距离最近的三元组所属实体类型分给该样本,并根据对应的索引选择实体类型,组合得到对完整句子的解码结果。
进一步地,对数据集进行预处理包括数据采样、格式规范,具体为:
所述数据采样,即对命名实体识别的数据集进行N way K shot采样,通过从数据集中选择N个类别,并从每个类别中随机选取K个样本;
所述格式规范,即对采样后的数据进行统一的结构和表示约定。
进一步地,步骤2中文本编码层具体为:
将每一个长度为n的句子S输入BERT层,获取句子对应的向量表示S={s
进一步地,步骤2中跨度编码层具体为:
对于支持集和查询集中的每个句子,如果构造所有长度小于L的跨度,将所有非实体跨度分为三类:
1)该跨度为实体跨度的一部分,对应实体标签为entity-unrelated span;
2)该跨度与实体跨度有交叉,对应实体标签为entity-overlapped span;
3)该跨度与实体跨度完全无关,对应实体标签为entity-unrelated span;
如果构造得到的跨度数量大于N,则从所有跨度中随机选择N个构成跨度矩阵,其中L和N均为模型超参数,跨度初始化过程如下所示:
V
V
span
其中,S表示句子嵌入矩阵,start表示跨度矩阵的起始位置,end表示跨度矩阵的结束位置,V
进一步地,步骤2中跨度增强层具体为:
对于初始化的跨度向量对其进行增强,过程如下所示:
其中,MHA表示多头注意力机制,将span
进一步地,步骤2中三元组构造层具体为:
对于给定的实体类型c,首先从enhance_span
计算锚点向量,将集合S
其中|S
选择正样本负样本,对于每个锚点向量a
进一步地,步骤2中实体分类层使用样本到三元组的距离作为分类依据,具体为:
对于enhance-span
d
d
d
d
其中||·||表示欧氏距离,cos(.)表示余弦相似度。
进一步地,步骤2中标签推理具体为:
根据d
P={P
其中,P
构造一个长度与样本q中句子长度相同的实体标签序列r,其中所有位置默认均为非实体类型;根据样本q中包含的所有跨度和P中对应的预测结果,选择模型预测为实体的跨度,按照跨度索引位置将r中相应位置赋值为预测的实体类型,并跳过所有预测为非实体的跨度,最终得到预测结果r。
基于上述描述内容,本技术方案主要解决两个方面的技术难点:
第一,针对两阶段模型忽略了标签包含的语义信息,导致在第二阶段将样本判断为错误实体类型的问题,借助实体标签信息,在实体类型原型向量中融入实体标签的语义特征,从而缓解命名实体识别中的实体类型错误问题。
第二,计算样本与实体类型原型向量的距离时,考虑样本与该实体类型正负样本的相似度,并使用实体类型三元组增大了不同样本之间的距离,增强了模型的泛化能力。
与现有技术相比,本发明的有益效果如下:
本方法的模型通过将标签语义信息融入模型,缓解了两阶段命名实体识别中实体类型识别错误的问题。同时,在计算查询集中的样本与实体类型原型向量的距离时,构建了实体类型三元组,通过其中的正负样本约束模型,有效缓解了训练过程中的过拟合现象,增强了模型的泛化能力。
附图说明
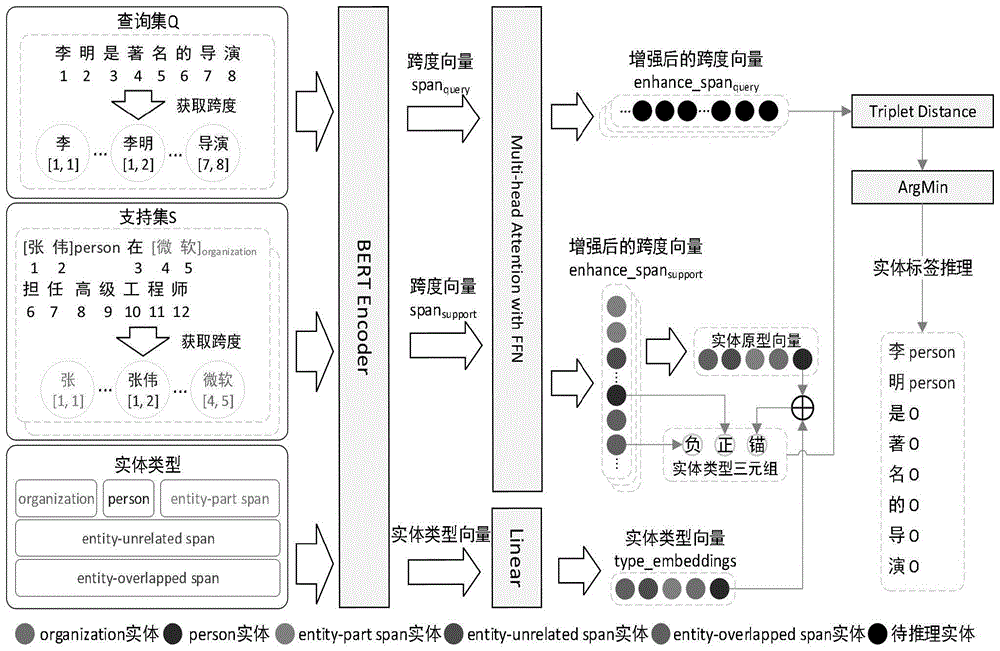
图1为少样本命名实体识别模型结构图。
具体实施方式
为了便于理解本发明,下面将对本发明进行更全面的描述。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
实施例1
一种基于标签语义信息感知的少样本命名实体识别方法,如图1所示,包括以下步骤:
步骤1:对数据集进行预处理,并将其划分为包括查询集、支持集,对数据集进行预处理包括数据采样、格式规范,
所述数据采样,即对命名实体识别的数据集进行N way K shot采样,通过从数据集中选择N个类别,并从每个类别中随机选取K个样本,从而帮助模型更好地理解并泛化处理各种不同类别的命名实体;
所述格式规范,即对采样后的数据进行统一的结构和表示约定,以确保模型能够在训练和推理阶段有效地解析和处理数据;
步骤2:构建适用于少样本命名实体识别的预训练学习模型,包括跨度识别、跨度分类两个阶段;
所述跨度识别从句子中提取跨度并获取跨度向量,包括:1)文本编码层:对数据集进行编码,获得字符级别的向量表示和标签对应的向量表示;2)跨度编码层:获取句子的实体跨度和非实体跨度,并将其转换为对应的向量表示;3)跨度增强层:分别对支持集和查询集的跨度向量进行增强。
所述跨度分类对得到的跨度向量进行分类,包括:1)三元组构造层:使用增强后的实体跨度向量构建实体类型原型向量,融入标签语义信息,并选取数个正样本和负样本,与锚点向量一同构建为实体类型三元组;2)实体分类层:计算查询集中每一个样本与每个实体类型三元组的距离,选取距离最近的三元组对应的类型作为该样本的实体类型;3)标签推理:通过计算样本到三元组的距离,将距离最近的三元组所属实体类型分给该样本,并根据对应的索引选择实体类型,组合得到完整句子的解码结果。
1.文本编码层
将每一个长度为n的句子S输入BERT层,获取句子对应的向量表示S={s
2.跨度编码层
对于支持集和查询集中的每个句子,首先构造所有长度小于L的跨度。其中,为了增强模型对非实体跨度的识别能力,将所有非实体跨度分为三类:
1)该跨度为实体跨度的一部分,对应实体标签为entity-unrelated span;
2)该跨度与实体跨度有交叉,对应实体标签为entity-overlapped span;
3)该跨度与实体跨度完全无关,对应实体标签为entity-unrelated span;
如果构造得到的跨度数量大于N,则从所有跨度中随机选择N个构成跨度矩阵。其中L和N均为模型超参数。跨度初始化过程如下所示:
V
V
span
其中,S表示句子嵌入矩阵,start表示跨度矩阵的起始位置,end表示跨度矩阵的结束位置,V
3.跨度增强层
对于初始化的跨度向量,其对该跨度所包含的向量信息表示仍不够完善,因此需要对其进行增强,过程如下所示:
其中,MHA表示多头注意力机制,将span
4.三元组构造层
对于给定的实体类型c,首先从enhance_span
计算锚点向量,将集合S
其中|S
选择正样本负样本。具体来说,对于每个锚点向量a
5.实体分类层:
对于enhance_span
d
d
d
d
其中||·||表示欧氏距离,cos(·)表示余弦相似度;并限制距离的最小值为0。
6.标签推理
在推理阶段,根据d
P={P
其中,p
构造一个长度与样本q中句子长度相同的实体标签序列r,其中所有位置默认均为非实体类型;根据样本q中包含的所有跨度和P中对应的预测结果,选择模型预测为实体的跨度,按照跨度索引位置将r中相应位置赋值为预测的实体类型,并跳过所有预测为非实体的跨度,最终得到预测结果r。
少样本命名实体识别模型分别在英文Few NERD、中文Few COMM和中国知网数据集三个数据集上与之前方法对比证明了框架识别模型的有效性,实验效果如下表1、表2和表3:
表1中文数据集实验结果
表2英文数据集实验结果
表3中国知网数据集实验结果
在检验不同模型层的贡献度时,消融实验结果如下表4:
表4消融实验结果
通过三个数据集上的少样本命名实体识别实验结果,结合模型的消融实验结果,证明了本方法在少样本命名实体识别的有效性和速度上都具有很好的表现。
在模型未见过的中国知网数据集上,现有的少样本命名实体识别模型表现较差,很难正确识别文本中包含的实体;而本方法通过将标签语义信息融入模型,缓解了两阶段命名实体识别中实体类型识别错误的问题,同时,在计算查询集中的样本与实体类型原型向量的距离时,构建了实体类型三元组,通过其中的正负样本约束模型,缓解了模型在少样本情况下的过拟合问题,证明了本方法具有更好的效果。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
- 一种基于Lattice LSTM和语言模型的命名实体识别方法
- 一种实体边界类别解耦的少样本命名实体识别方法与系统
- 基于多任务学习的少样本命名实体识别方法、装置及介质