一种小数据场景下尖晶石氧化物的可解释带隙预测方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及尖晶石氧化物数据生成技术领域,尤其是涉及一种小数据场景下尖晶石氧化物的可解释带隙预测方法。
背景技术
尖晶石氧化物因其独特的晶体结构和出色的物理化学性质,广泛应用于催化、电池、光伏、传感器等领域。在这些应用中,材料的带隙起着极为重要的作用,特别是在光催化和太阳能电池领域,带隙大小直接影响整体性能。因此,实验学家致力于寻找适宜带隙的尖晶石样品。
尖晶石氧化物的化学通式为AB
然而,由于近年来,随着一些材料数据库的不断壮大,机器学习(ML)技术在材料领域的应用显著改善了新材料研究中效率低下和预测不准的问题。对于多变量耦合映射函数,人类专家所能处理和获取的信息量是非常有限的,而ML可以从海量数据中自发地学习隐藏在背后的规律,不依赖于高深的专家知识,并已成功应用于许多新材料的设计和探索中。但现有的尖晶石氧化物可解释学习研究的数据质量差,且数据规模小,容易造成材料信息缺失。
因此,亟需研究一种可解释预测方法,实现高精度预测,并解决任意固定结构的材料信息缺失的问题。
发明内容
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种小数据场景下尖晶石氧化物的可解释带隙预测方法,通过采用阳离子取代法结合TPOT自动机器学习工具,用可解释学习从元素自身和原子物理量两个角度揭示了尖晶石氧化物带隙背后隐藏的因果关系,以便更好地探索新材料和优化材料性能。
本发明的目的可以通过以下技术方案来实现:
本发明提供一种小数据场景下尖晶石氧化物的可解释带隙预测方法,包括以下步骤:
S1:采用交集获取预测法将SNUMAT数据库和MP数据库结合训练机器学习模型,用于修正MP数据库的GGA带隙,并得到一个新数据集MPm;
S2:使用0.1的化学系数步长对尖晶石氧化物的A、B位点采用阳离子取代法,得到尖晶石氧化物的化学式集;
S3:使用CrabNet s模型并基于MPm中的数据进行训练,训练得到回归模型,并通过所述回归模型预测S2中得到的尖晶石氧化物的化学式集的带隙,从而揭示各尖晶石氧化物带隙之间的因果关系。
进一步地,S1中,所述交集获取预测法包括以下步骤:
S1-1:所述SNUMAT数据库的HSE带隙与MP的GGA带隙与之间的线性关系满足Eg
S1-2:按化学式与空间群对SNUMAT与MP进行聚合,得到交集,作为训练机器学习模型的数据集;
S1-3:将化学式衍生为145个与组成元素相关的特征,并考虑空间群特征;在SNUMAT数据库中除去S1-2中的交集,剩下的数据T1作为验证集;将S1-2中得到的交集按0.2的比例分割出测试集T2,剩余部分为训练集,训练得到分类模型;
S1-4:使用分类模型在新数据集中预测带隙是否为0。
进一步地,S2中,所述阳离子取代法的具体过程为:在保证A位与B位不会出现相同元素的情况下,按0.1的化学系数步长,每次对尖晶石氧化物的一个位点进行取代,直至被完全取代,获得阳离子取代后且未经处理的数据集;
获取尖晶石氧化物的化学式集的具体过程为:将阳离子取代后且未经处理的数据集中的数据按4:1的比例划分为训练集与测试集;使用TPOT训练分类器对训练集进行优化,优化至五折交叉验证的ROC_AUC的均值,得到尖晶石氧化物的化学式集。
进一步地,S3中,具体包括以下步骤:
S3-1:在CrabNet中加入空间群信息,并对原来的网络架构做出调整,获得CrabNets模型;
S3-2:从MPm数据库中分割出尖晶石氧化物作为测试集,其余数据用于五折交叉验证,对CrabNet s模型进行训练,采用验证、测试后的CrabNet s模型对经过阳离子取代后的尖晶石氧化物数据进行尖晶石氧化物的化学式集的带隙标签提取,从而揭示各尖晶石氧化物带隙之间的因果关系。
进一步地,S3-1中,所述CrabNet s模型的输入包括化学成分和对称信息,所述化学成分相关的输入包括原子序数衍生的矩阵以及化学计量数衍生的矩阵;
所述对称信息相关的输入由空间群编号衍生的矩阵SDM表示。
进一步地,所述化学成分相关的输入中的原子序数衍生的矩阵和化学计量数衍生的矩阵进行乘法运算,以达到用化学计量数对元素信息加权的目的。
进一步地,所述对称信息相关的输入由空间群编号衍生的矩阵SDM表示,所述对称信息相关输入的具体步骤为:
S3-1-1通过全连接层将空间群编号映射到高维空间,再用注意力层优化特征表示并得到输入矩阵SDM,得到元素信息的最终特征表示EDM′;
S3-2-2将S3-1-1中的最终特征表示EDM′与空间群编号衍生的矩阵SDM拼接,得到材料的全局信息表示GDM;
S3-2-3通过重复使用N次自注意力层优化全局信息的特征表示,得到最终的特征输入GDM′。
进一步地,S2-2中,所述数据集包括尖晶石氧化物和非尖晶石结构的三元材料及四元材料。
进一步地,所述尖晶石氧化物为正例,所述非尖晶石结构的三元材料及四元材料为负例。
进一步地,S1-2中,对于化学式和空间群一样的数据,则保留MP的GGA带隙与SNUMAT的GGA带隙绝对误差最小的一条。
与现有技术相比,本发明具有以下优点和有益效果:
1、本发明通过使用阳离子取代法,然后结合Tree-based Pipeline OptimizationTool(TPOT)自动机器学习工具,从14万的初始数据集中筛选了11万条尖晶石结构的材料。
2、本发明克服了尖晶石氧化物可解释学习研究的数据质量差,数据规模小的窘境,这种实验级的大数据生成方法不局限于尖晶石氧化物,而是可以解决任意固定结构的材料信息缺失的问题,在未来能为信息缺失的材料机器学习研究提供参考。
3、本发明加入了空间群信息和完善了模型的特征表达构建了新的网络架构CrabNet s,其表现相比原CrabNet s提高了大约5%,实现高精度预测。
附图说明
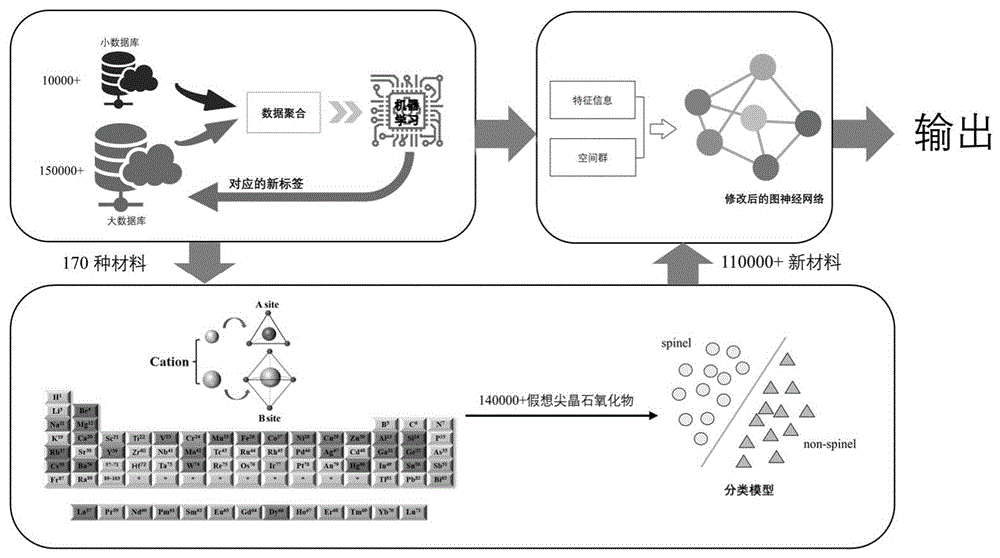
图1为一种小数据场景下尖晶石氧化物的可解释带隙预测方法的流程图;
图2为实施例1中修正MP数据库GGA带隙的前期数据分析图;
图3为实施例1中ZnBi
图4为实施例1中CrabNet s结构示意图。
具体实施方式
下面通过实施例对本发明的具体实施方式作详细说明,这些实施例在以本发明所述方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
下面结合附图和具体实施例,对本发明进行进一步阐述。本技术方案中如未明确说明的结构/模块名称、控制模式、算法、工艺过程或组成配比等特征,均视为现有技术中公开的常见技术特征。
实施例1
如图1所示,本实施例提供一种小数据场景下尖晶石氧化物的可解释带隙预测方法,包括以下步骤:
S1:如图2所示,结合图2中SNUMAT数据库中的HSE带隙与GGA带隙的散点图与分布图,两者之间的相关性与数据分布中存在的一致性。采用交集获取预测法将一个拥有上万HSE带隙的SNUMAT数据库和MP数据库结合,获得上万条尖晶石数据库训练机器学习模型,对这个数据库进行特征衍生,同时加入空间群特征,最终得到完整的数据集。然后使用分类模型预测带隙是否为0,再用回归模型预测非0带隙值,用于修正MP数据库的GGA带隙,得到一个新数据集MP m。所述交集获取预测法具体步骤包括:
S1-1:根据发现的GGA带隙与HSE带隙之间的线性关系Eg
S1-2:按化学式与空间群对SNUMAT与MP进行聚合得到一个交集,这个交集作为训练ML的数据集,该交集有10652条数据;对于化学式和空间群一样的数据,保留MP的GGA带隙与SNUMAT的GGA带隙绝对误差最小的一条。考虑到不同的计算方法带来些许误差是合理的,因此在去除了极少量的异常点后,两个数据库的GGA带隙的数据分布近乎一致。根据训练模型的数据与未知数据来自同一数据库能保证它们的分布一致,并以此保证模型对未知数据有较好的预测能力。因此,后续模型的训练过程中使用MP的GGA带隙而不考虑SNUMAT;
S1-3:为了得到更完善的信息,将化学式衍生为145个与组成元素相关的特征,如图2(c)中,同时考虑空间群特征,在SNUMAT数据库中除去S1-2中的交集,剩下的2222条数据作为验证集T1;将S1-2中得到的交集按0.2的比例分割出测试集T2,剩余部分为训练集,训练得到分类模型;
S1-4:使用分类模型在所述数据集中预测带隙是否为0,再用回归模型预测非0带隙值。
S2:考虑到A位点与B位点中的阳离子占据的是晶体结构中的空隙位置,所以每次只取代一个位点中的阳离子而保持另一个位点的阳离子不变,可以尽可能地让取代后的材料保持尖晶石相。使用0.1的化学系数步长对尖晶石氧化物的A、B位点采用阳离子取代法,得到尖晶石氧化物的化学式集。
所述阳离子取代法的具体过程为:在保证A位与B位不会出现相同元素的情况下,按0.1的化学系数步长,每次只对尖晶石氧化物的一个位点取代,直至该位点被完全取代。最终阳离子取代后未经处理的数据集大约有14万条;
获得尖晶石氧化物的化学式集的具体过程为:通过设置170个尖晶石氧化物为正例,从MP中找200个非尖晶石结构的三元材料及四元材料作为负例,构成一个训练分类器的数据集,将370条数据按4:1的比例划分为训练集与测试集;接着在训练集上使用TPOT训练分类器,每次训练的population参数设置为50,优化的目标为五折交叉验证的ROC_AUC的均值。经过十次迭代后,最佳模型的得分为0.99,而模型在测试集上的得分为0.94,说明分类器泛化能力良好。在此基础上,从14万的初始数据集中筛选了11万条尖晶石结构的材料,即获得尖晶石氧化物的化学式集。
Tree-based Pipeline Optimization Tool(TPOT)是一款非常强大自动机器学习工具,使用遗传算法来优化机器学习模型管道,自动构建最佳的机器学习管道,以解决各种回归和分类问题。
S3:考虑到无结构学习通常采用对目标变量求平均的一些方法在输入输出之间建立唯一映射,可能会导致对化合物性质的错误预测。而尖晶石正是存在多晶现象的典型化合物,若不解决这个问题则会导致模型的输出与尖晶石的真实带隙之间的误差过大,因此,对CrabNet网络在结构上进行调整,命名为CrabNet_s,使用CrabNet s模型对MPm训练得到回归模型,并通过所述回归模型预测S2中获得的尖晶石氧化物的化学式集的带隙,从而揭示各尖晶石氧化物带隙之间的因果关系,如图3和图4所示。具体包括以下步骤:
S3-1:在CrabNet中加入空间群信息,并对原来的网络架构做出调整,获得CrabNets模型;所述CrabNet s模型的输入包括化学成分和对称信息,所述化学成分相关的输入包括原子序数衍生的矩阵以及化学计量数衍生的矩阵,所述化学成分相关的输入中的原子序数衍生的矩阵和化学计量数衍生的矩阵进行乘法运算,以达到用化学计量数对元素信息加权的目的。所述对称信息相关的输入由空间群编号衍生的矩阵SDM表示,空间群编号是一个一维的信息,为了将其与成分信息的维度保持一致,具体步骤如下:
S3-2-1通过全连接层将空间群编号映射到高维空间,再用注意力层优化特征表示并得到输入矩阵SDM,得到元素信息的最终特征表示EDM′;
S3-2-2由于成分信息和对称性信息属于同一层次,将S3-1-1中的最终特征表示EDM′与空间群编号衍生的矩阵SDM拼接,得到材料的全局信息表示GDM;
S3-2-3通过重复使用N次自注意力层优化全局信息的特征表示,得到最终的特征输入GDM′。
S3-2:从MPm中分割出170个尖晶石氧化物作为测试集,其余数据用于五折交叉验证,用CrabNet s模型对S2-2中的11万条阳离子取代后尖晶石氧化物数据提取尖晶石氧化物的化学式集的带隙标签,从而揭示各尖晶石氧化物带隙之间的因果关系。
本发明用阳离子取代法生成了大量的新尖晶石材料,用机器学习修正了低质量数据并得到了一个实验级精度的数据集,最后引入图神经网络预测新尖晶石的带隙。本发明克服了尖晶石氧化物可解释学习研究的数据质量差,数据规模小的窘境,这种实验级的大数据生成方法不局限于尖晶石氧化物,而是可以解决任意固定结构的材料信息缺失的问题,本发明还提供了一个接近实验精度的数据集MP_m,并优化了无结构学习中的多晶问题,改进了CrabNet的模型性能。
上述的对实施例的描述是为便于该技术领域的普通技术人员能理解和使用发明。熟悉本领域技术的人员显然可以容易地对这些实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,不脱离本发明范畴所做出的改进和修改都应该在本发明的保护范围之内。
- 一种基于半监督图对比学习的心跳异常检测方法
- 一种针对大图的基于对比学习的半监督社区搜索方法