基于硬件实现的LDPC译码器实现方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明属于通信领域,具体涉及一种基于硬件实现的LDPC译码器实现方法。
背景技术
LDPC码(低密度校验码,Low Density Parity Check Code)最早在20世纪60年代由Robert G.Gallager在他的博士论文中提出,但限于当时的技术条件,缺乏可行的译码算法,此后的35年间基本上被人们忽略,其间由Tanner在1981年推广了LDPC码并给出了LDPC码的图表示,即后来所称的Tanner图。1993年Berrou等人发现了Turbo码,在此基础上,1995年前后MacKay和Neal等人对LDPC码重新进行了研究,提出了可行的译码算法,从而进一步发现了LDPC码所具有的良好性能,迅速引起强烈反响和极大关注。经过十几年来的研究和发展,研究人员在各方面都取得了突破性的进展,LDPC码的相关技术也日趋成熟,甚至已经开始有了商业化的应用成果,并进入了无线通信等相关领域的标准。
LDPC码是通过校验矩阵定义的一类线性码,为使译码可行,在码长较长时需要校验矩阵满足“稀疏性”,即校验矩阵中1的密度比较低,也就是要求校验矩阵中1的个数远小于0的个数,并且码长越长,密度就要越低。在众多纠错算法中,LDPC码由于其性能可以逼近香农极限,只需一次交互即可完成误码协商,且译码算法适合硬件实现等特点而被引入QKD纠错算法中。
对同样的LDPC码来说,采用不同的译码算法可以获得不同的误码性能。优秀的译码算法可以获得很好的误码性能,反之,采用普通的译码算法,误码性能则表现一般。
LDPC码的译码算法包括以下三大类:硬判决译码,软判决译码和混合译码。
1. 硬判决译码将接收的实数序列先通过解调器进行解调,再进行硬判决,得到硬判决0,1序列,最后将得到的硬判决序列输送到硬判决译码器进行译码。这种方式的计算复杂度固然很低,但是硬判决操作会损失掉大部分的信道信息,导致信道信息利用率很低,硬判决译码的信道信息利用率和译码复杂度是三大类译码中最低的。常见的硬判决译码算法有比特翻转(bit-flipping, BF)算法、一步大数逻辑(one-step majority-logic, OSMLG)译码算法。
2. 软判决译码可以看成是无穷比特量化译码,它充分利用接收的信道信息(软信息),信道信息利用率得到了极大的提高,软判决译码利用的信道信息不仅包括信道信息的符号,也包括信道信息的幅度值。信道信息的充分利用,极大地提高了译码性能,使得译码可以迭代进行,充分挖掘接收的信道信息,最终获得出色的误码性能。软判决译码的信道信息利用率和译码复杂度是三大类译码中最高的。最常用的软判决译码算法是和积译码算法,又称置信传播 (belief propagation, BP)算法。
3. 与上述的硬判决译码和软判决译码相比,混合译码结合了软判决译码和硬判决译码的特点,是一类基于可靠度的译码算法,它在硬判决译码的基础上,利用部分信道信息进行可靠度的计算。常用的混合译码算法有加权比特翻转(weighted BF, WBF)算法、加权OSMLG(weighted OSMLG, WMLG)译码算法。
上述三大类译码算法:硬判决译码实现简单,解码速度快,但是性能较差;软判决译码实现较为复杂,解码速度慢,但性能最佳;混合译码在解码性能、复杂度及解码速度三者间取得了较好的平衡,但其通用性较差,解码速度与硬判决译码相比有较大差距。因此,迫切需要一种通用性强、速度速度更快的LDPC译码器实现方法。
发明内容
为了提高LDPC译码器的速度及通用性,本发明提出了一种基于硬件实现的LDPC译码器实现方法。
本发明的技术方案如下:一种基于硬件实现的LDPC译码器实现方法,其特征在于,所述硬件包括:一组ROM,用于存储矩阵中非零元素的位置和大小;一组变量节点RAM,用于存储变量节点的值,变量节点RAM的数量等于扩展因子的大小;一组校验节点RAM,用于存储校验节点的值;一组临时缓存RAM,用于存储每一个行间临时的比较值,临时缓存RAM的数量等于扩展因子大小和矩阵每一行非零元素的最大值的乘积;依次设置的减法器、比较器及加法器。
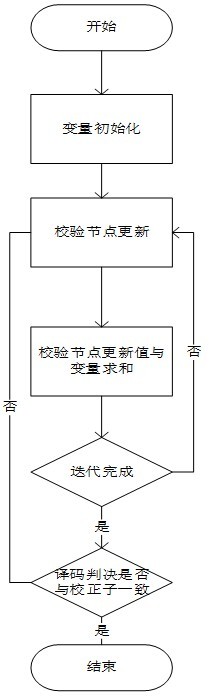
所述LDPC译码器实现方法的步骤如下:
步骤1.根据估计误码率选择初值,并更新到变量节点中,以扩展因子为分组,按流水线的方式存入变量节点RAM;
步骤2.根据扩展因子大小确定并行度的大小,每个变量节点RAM代表扩展因子中的一列,根据矩阵中非零元素的位置,取出相应深度的变量值,并根据偏移量进行排序,并与对应校验节点的值做差值;与同一行下一个非零元素的位置取出的值进行比较,比较次数等于该矩阵每一个行非零元素个数的最大值;比较完成后寻找并记录每一行中的最小值和次小值,然后将最小值相应位置的校验节点RAM存入次小值相应位置,取值、比较及存储均采用流水线操作方式;
步骤3.比较过程中将取出的变量值存储至变量节点临时缓存RAM,待比较完成后将相应的变量值和校验节点更新值进行求和,并存回变量节点RAM,完成变量的更新,待下一次校验节点更新时或者译码判决时使用;
步骤4.每一个基矩阵行更新后都对变量节点的值进行更新,当基矩阵每一行都迭代完成以后,直接对变量节点此时的值进行译码判决。
优选的:所述步骤1的初始化公式为
优选的:所述步骤2的校验节点更新公式为
若为第一次迭代则,
优选的:所述步骤3的变量节点更新公式为
本发明与传统方法相比,具有如下优点:通用性强,适用于任何准循环矩阵的译码;速度快,硬件实现,并删减去了变量节点迭代的过程,全程进行流水线操作,大大节省了迭代时间;硬件面积可控,若硬件资源较小,完全可以通过减小扩展因子的大小的方法构建译码器,不影响结构和功能的使用。
附图说明
图1为本发明实施例中译码器译码算法的流程图。
图2为本发明实施例中译码器结构示意图(并行模块中其中一个模块的结构)。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本申请,并不用于限定本申请。
存储资源消耗,需要一组ROM来存储矩阵中非零元素的位置和大小,一组变量节点RAM用来存储变量节点的值,变量节点RAM数量等于扩展因子的大小,一组校验节点RAM用来存储校验节点的值,一组临时缓存RAM用来存储每一个行间临时的比较值,临时缓存RAM数量等于扩展因子大小和矩阵每一行非零元素的最大值的乘积。公式中,i为列,j为行,
步骤1:根据估计误码率选择初值,并更新到变量节点中,才去以扩展因子为分组,流水线的方式存入变量节点RAM。初始化公式为:
步骤2:根据扩展因子大小确定并行度的大小,如IEEE扩展因子为96的矩阵,基矩阵为12X24大小,则变量节点RAM数量为96,深度为24,每个RAM代表扩展因子中的一列,一共96列,根据矩阵中非零元素的位置,取出相应深度的变量值,并根据偏移量进行排序,并与对应校验节点的值做差值(若为第一次迭代则减0,完成变量节点的更新),与同一行下一个非零元素的位置取出的值进行比较,包括符号的更新,补码原码的转换过程,比较次数等于该矩阵每一个行非零元素个数的最大值,若该行非零元素个数小于矩阵最大值,则对缺少的非零元素位置,补加最大值进行比较,不影响最终迭代结果。96行并行比较,比较完成后找到每一行中的最小值和次小值,并且记录最小值的位置,然后将最小值相应位置的校验节点RAM存入次小值其余位置的RAM存入最小值,取值、比较、存储均采用流水线的操作方式,确保速度最快。
校验节点更新公示如下:
若为第一次迭代则:
步骤3:比较过程中将取出的变量值存储缓存的RAM,待比较完成后将相应位置的变量值和校验节点更新值进行求和存回变量节点RAM,完成变量的更新,待下一次校验节点更新时或者译码判决时使用。
变量节点更新公示如下:
步骤4:一次迭代执行次数等于基矩阵的行数目。并且每一个基矩阵行更新后都对变量节点的值进行更新,即分层最小和方案,分层最小和方案收敛速度快,大大减少迭代的次数,当基矩阵每一行都迭代完成以后,可直接对变量节点此时的值进行译码判决,根据扩展因子大小决定一次判决的数据个数。若扩展因子大小为96。则每96列进行并行的判决(根据符号位的正负确定该值为0或1),每一组判决后即可进行译码判断,对量子密钥分发系统来说,译码判断即为变量与矩阵做乘积,每96组做一次乘机,由于是准循环矩阵,只需要根据偏移量对变量进行循环移位即可完成乘积过程,判决的过程和判断的过程同样采用流水线的方案,大大减少了判决和判断所需的时间。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。